27.06.2019
किसी कंप्यूटर में जानकारी एन्कोडिंग के सामान्य सिद्धांत। "कंप्यूटर पर एन्कोडिंग जानकारी"
अपने अच्छे काम को ज्ञान के आधार पर प्रस्तुत करना आसान है। नीचे दिए गए फॉर्म का उपयोग करें
छात्र, स्नातक छात्र, युवा वैज्ञानिक जो अपने अध्ययन और काम में ज्ञान आधार का उपयोग करते हैं, वे आपके लिए बहुत आभारी होंगे।
पर पोस्ट किया गया http://www.allbest.ru//
पर पोस्ट किया गया http://www.allbest.ru//
कंप्यूटर में जानकारी एनकोडिंग
एक आधुनिक कंप्यूटर संख्यात्मक, पाठ, ग्राफिक, ध्वनि और वीडियो जानकारी को संसाधित कर सकता है। कंप्यूटर में इन सभी प्रकार की जानकारी को बाइनरी कोड में प्रस्तुत किया जाता है, अर्थात, दो की क्षमता वाली एक वर्णमाला का उपयोग किया जाता है (कुल दो वर्ण 0 और 1)। यह इस तथ्य के कारण है कि विद्युत दालों के अनुक्रम के रूप में जानकारी प्रस्तुत करना सुविधाजनक है: कोई नाड़ी (0) नहीं है, एक नाड़ी (1) है। ऐसे कोडिंग को आमतौर पर बाइनरी कहा जाता है, और शून्य और लोगों के तार्किक अनुक्रम को मशीन भाषा कहा जाता है
मशीन बाइनरी कोड के प्रत्येक अंक में एक बिट के बराबर जानकारी की मात्रा होती है।
इस निष्कर्ष को मशीन वर्णमाला की संख्या को परिवर्तनीय घटनाओं के रूप में देखते हुए बनाया जा सकता है। बाइनरी अंक लिखते समय, आप केवल दो संभावित राज्यों में से एक की पसंद का एहसास कर सकते हैं, जिसका अर्थ है कि यह 1 बिट के बराबर जानकारी का वहन करता है। इसलिए, दो अंक जानकारी को 2 बिट्स, चार अंक - 4 बिट्स, आदि में ले जाते हैं। बिट्स में जानकारी की मात्रा निर्धारित करने के लिए, द्विआधारी मशीन कोड में अंकों की संख्या निर्धारित करना पर्याप्त है।
कोडिंग पाठ संबंधी जानकारी
वर्तमान में, अधिकांश उपयोगकर्ता पाठ जानकारी को संसाधित करने के लिए एक कंप्यूटर का उपयोग करते हैं, जिसमें वर्ण होते हैं: अक्षर, संख्या, विराम चिह्न, आदि।
परंपरागत रूप से, किसी एकल वर्ण को एनकोड करने के लिए, 1 बाइट के बराबर जानकारी का उपयोग किया जाता है, अर्थात, I \u003d 1 बाइट \u003d 8 बिट्स। एक सूत्र का उपयोग करना जो संभावित घटनाओं की संख्या को जोड़ता है और जानकारी की मात्रा I, कोई गणना कर सकता है कि कितने अलग-अलग वर्णों को एन्कोड किया जा सकता है (यह मानते हुए कि वर्ण संभावित घटनाएं हैं):
K \u003d 2I \u003d 28 \u003d 256,
अर्थात्, वर्णमाला की जानकारी को दर्शाने के लिए 256 वर्णों की क्षमता वाली वर्णमाला का उपयोग किया जा सकता है।
कोडिंग का सार यह है कि प्रत्येक वर्ण को असाइन किया गया है बाइनरी कोड 00000000 से 11111111 या इसके संबंधित दशमलव कोड 0 से 255 तक।
यह याद रखना चाहिए कि वर्तमान में, रूसी अक्षरों (KOI - 8, CP1251, CP866, Mac, ISO) को एन्कोड करने के लिए पांच अलग-अलग कोड टेबल का उपयोग किया जाता है, और एक टेबल का उपयोग करके एन्कोड किए गए ग्रंथों को अन्य एन्कोडिंग में सही ढंग से प्रदर्शित नहीं किया जाएगा। यह एक संयुक्त चरित्र एन्कोडिंग टेबल के एक टुकड़े के रूप में नेत्रहीन रूप से प्रतिनिधित्व किया जा सकता है।
विभिन्न बाइनरी वर्णों को एक ही बाइनरी कोड को सौंपा गया है।
|
बाइनरी कोड |
दशमलव कोड |
||||||
हालांकि, ज्यादातर मामलों में, उपयोगकर्ता द्वारा पाठ दस्तावेजों के ट्रांसकोडिंग का ध्यान रखा जाता है, और विशेष कार्यक्रम कन्वर्टर्स होते हैं जो अनुप्रयोगों में निर्मित होते हैं।
1997 के बाद से, माइक्रोसॉफ्ट विंडोज और ऑफिस के नवीनतम संस्करणों ने नए यूनिकोड एन्कोडिंग का समर्थन किया है, जो प्रति चरित्र 2 बाइट्स आवंटित करता है, और इसलिए, 256 वर्णों को नहीं, बल्कि 65,536 विभिन्न वर्णों को एनकोड करना संभव है।
एक प्रतीक के संख्यात्मक कोड को निर्धारित करने के लिए, आप या तो कोड तालिका का उपयोग कर सकते हैं, या, एक वर्ड 6.0 / 95 टेक्स्ट एडिटर में काम कर सकते हैं। ऐसा करने के लिए, मेनू से "सम्मिलित करें" - "प्रतीक" चुनें, जिसके बाद स्क्रीन पर प्रतीक डायलॉग बॉक्स दिखाई देता है। चयनित फ़ॉन्ट के लिए एक वर्ण तालिका संवाद बॉक्स में दिखाई देती है। इस तालिका के वर्णों को लाइन से लाइन में व्यवस्थित किया जाता है, क्रमिक रूप से बाएं से दाएं, स्पेस कैरेक्टर (ऊपरी बाएं कोने) से शुरू होकर "I" (निचले दाएं कोने) अक्षर के साथ समाप्त होता है।
विंडोज एन्कोडिंग (CP1251) में संख्यात्मक चरित्र कोड निर्धारित करने के लिए, माउस या कर्सर कुंजियों का उपयोग करके अपने इच्छित चरित्र का चयन करें, फिर कुंजी बटन पर क्लिक करें। उसके बाद, सेटिंग्स संवाद बॉक्स स्क्रीन पर दिखाई देता है, जिसमें चयनित वर्ण का दशमलव संख्यात्मक कोड निचले बाएं कोने में स्थित है।
1. दो ग्रंथों में समान वर्ण हैं। पहला पाठ रूसी में लिखा गया है, और दूसरा नागुरी जनजाति की भाषा में, जिसकी वर्णमाला में 16 वर्ण हैं। अधिक जानकारी किसके पाठ से मिलती है?
I \u003d K * a (पाठ की सूचना मात्रा एक वर्ण के सूचना भार द्वारा वर्णों की संख्या के उत्पाद के बराबर है)।
क्योंकि चूँकि दोनों ग्रंथों में समान वर्ण (K) हैं, अंतर वर्णमाला (a) के एक वर्ण की सूचना सामग्री पर निर्भर करता है।
2 ए 1 \u200b\u200b\u003d 32, अर्थात् ए 1 \u003d 5 बिट्स
2 ए 2 \u003d 16, अर्थात् ए 2 \u003d 4 बिट्स।
I1 \u003d K * 5 बिट्स, I2 \u003d K * 4 बिट्स।
तो, 5/4 बार रूसी में लिखे गए पाठ में अधिक जानकारी होती है।
2. संदेश की मात्रा, जिसमें 2048 अक्षर हैं, एमबी की 1/512 है। वर्णमाला की शक्ति का निर्धारण करें।
I \u003d 1/512 * 1024 * 1024 * 8 \u003d 16384 बिट्स। - संदेश की सूचना मात्रा बिट्स में परिवर्तित।
a \u003d I / K \u003d 16384/1024 \u003d 16 बिट्स - वर्णमाला के एक वर्ण पर आता है।
216 \u003d 65536 वर्ण - प्रयुक्त वर्णमाला की शक्ति।
यह वह वर्णमाला है जिसका उपयोग यूनिकोड एन्कोडिंग में किया जाता है, जिसे कंप्यूटर में प्रतीकात्मक सूचना के प्रतिनिधित्व के लिए एक अंतरराष्ट्रीय मानक बनना चाहिए।
ग्राफिक्स एनकोडिंग
1950 के दशक के मध्य में, बड़े कंप्यूटरों के लिए, जिनका उपयोग वैज्ञानिक और सैन्य अनुसंधान में किया गया था, पहली बार डेटा का चित्रमय प्रतिनिधित्व लागू किया गया था। वर्तमान में, पीसी का उपयोग करके ग्राफिक जानकारी को संसाधित करने के लिए तकनीकों का व्यापक रूप से उपयोग किया जाता है। ऑपरेटिंग सिस्टम के साथ शुरू होने वाले विभिन्न वर्गों के सॉफ्टवेयर के लिए ग्राफिकल यूजर इंटरफेस डी वास्तविक मानक बन गया है। यह संभवतः मानव मानस की संपत्ति के कारण है: विज़ुअलाइज़ेशन एक तेज समझ में योगदान देता है। कंप्यूटर विज्ञान के एक विशेष क्षेत्र में व्यापक उपयोग किया गया है, जो सॉफ्टवेयर और हार्डवेयर कंप्यूटिंग सिस्टम - कंप्यूटर ग्राफिक्स का उपयोग करके छवियों को बनाने और संसाधित करने के तरीकों का अध्ययन करता है। इसके बिना, न केवल कंप्यूटर, बल्कि काफी भौतिक दुनिया की कल्पना करना मुश्किल है, क्योंकि डेटा विज़ुअलाइज़ेशन का उपयोग मानव गतिविधि के कई क्षेत्रों में किया जाता है। एक उदाहरण के रूप में, प्रयोगात्मक विकास, दवा ( कंप्यूटेड टोमोग्राफी), अनुसंधान, आदि।
विशेष रूप से गहन रूप से, 80 के दशक में कंप्यूटर का उपयोग करके ग्राफिक जानकारी को संसाधित करने की तकनीक विकसित होने लगी। ग्राफिक जानकारी को दो रूपों में प्रस्तुत किया जा सकता है: एनालॉग या असतत। एक पेंटिंग, जिसका रंग लगातार बदलता रहता है, एक एनालॉग प्रतिनिधित्व का एक उदाहरण है, और एक इंकजेट प्रिंटर का उपयोग करके मुद्रित छवि और एक अलग रंग के व्यक्तिगत डॉट्स से मिलकर एक असतत प्रतिनिधित्व है। ग्राफिक छवि (विवेकाधिकार) को विभाजित करके, ग्राफिक जानकारी को एनालॉग रूप से असतत में बदल दिया जाता है। उसी समय, एन्कोडिंग किया जाता है - प्रत्येक तत्व को एक कोड के रूप में एक विशिष्ट मूल्य सौंपा जाता है। जब एक छवि एन्कोडिंग होती है, तो इसका स्थानिक विवेक होता है। इसकी तुलना बड़ी संख्या में छोटे रंग के टुकड़े (मोज़ेक विधि) से एक छवि बनाने के लिए की जा सकती है। पूरी छवि को अलग-अलग बिंदुओं में विभाजित किया गया है, प्रत्येक तत्व को उसके रंग का एक कोड सौंपा गया है। इस मामले में, एन्कोडिंग गुणवत्ता निम्न मापदंडों पर निर्भर करेगी: डॉट का आकार और उपयोग किए जाने वाले रंगों की संख्या। डॉट्स का आकार जितना छोटा है, और, इसलिए, छवि बड़ी संख्या में डॉट्स से बनी होती है, एन्कोडिंग गुणवत्ता जितनी अधिक होती है। अधिक रंगों का उपयोग किया जाता है (अर्थात, छवि बिंदु अधिक संभव स्थिति ले सकता है), प्रत्येक बिंदु पर अधिक जानकारी होती है, और इसलिए, एन्कोडिंग गुणवत्ता बढ़ जाती है। ग्राफिक ऑब्जेक्ट्स का निर्माण और भंडारण कई रूपों में संभव है - एक वेक्टर, भग्न या रेखापुंज छवि के रूप में। एक अलग विषय को 3 डी (तीन आयामी) ग्राफिक्स माना जाता है, जो वेक्टर और छवि निर्माण के रेखापुंज तरीकों को जोड़ती है। वह आभासी अंतरिक्ष में वस्तुओं के त्रि-आयामी मॉडल के निर्माण के तरीकों और तकनीकों का अध्ययन करती है। प्रत्येक प्रकार ग्राफिक जानकारी को एन्कोड करने के अपने तरीके का उपयोग करता है।
बिटमैप छवि।
एक आवर्धक कांच का उपयोग करके, आप देख सकते हैं कि एक काले और सफेद ग्राफिक छवि, उदाहरण के लिए एक अखबार से, सबसे छोटे डॉट्स होते हैं जो एक निश्चित पैटर्न बनाते हैं - एक रेखापुंज। 19 वीं शताब्दी में फ्रांस में चित्रकला में एक नई दिशा दिखाई दी - बिंदुवाद। उनकी तकनीक यह थी कि कैनवास पर ड्राइंग को बहु-रंगीन डॉट्स के रूप में ब्रश के साथ लागू किया गया था। इसके अलावा, ग्राफिक जानकारी को एन्कोडिंग के लिए छपाई में इस पद्धति का लंबे समय से उपयोग किया जाता है। तस्वीर के प्रसारण की सटीकता बिंदुओं की संख्या और उनके आकार पर निर्भर करती है। चित्र को बिंदुओं में विभाजित करने के बाद, बाएं कोने से शुरू करके, बाईं ओर से दाईं ओर की रेखाओं के साथ चलते हुए, आप प्रत्येक बिंदु का रंग सांकेतिक शब्दों में बदल सकते हैं। अगला, हम एक ऐसे बिंदु को एक पिक्सेल कहेंगे (इस शब्द का मूल अंग्रेज़ी संक्षिप्त नाम "पिक्चर एलिमेंट" - एक पिक्चर एलिमेंट) से जुड़ा है। एक रेखापुंज छवि की मात्रा पिक्सेल की संख्या को गुणा करके निर्धारित की जाती है (एक बिंदु की जानकारी मात्रा द्वारा, जो संभव रंगों की संख्या पर निर्भर करती है। छवि गुणवत्ता मॉनिटर के रिज़ॉल्यूशन द्वारा निर्धारित की जाती है। उच्चतर यह है कि रेखापुंज की पंक्तियों की संख्या जितनी अधिक होगी और लाइन में बिंदुओं की संख्या, उच्च छवि की गुणवत्ता)। पीसी मुख्य रूप से निम्नलिखित स्क्रीन रिज़ॉल्यूशन का उपयोग करते हैं: 640 द्वारा 480, 800 से 600, 1024 से 768 और 1280 से 1024 अंक, प्रत्येक बिंदु की चमक और इसके रैखिक निर्देशांक को पूर्णांक का उपयोग करके व्यक्त किया जा सकता है। , यह कहा जा सकता है कि यह एन्कोडिंग विधि छवि डेटा संसाधित करने के लिए एक बाइनरी कोड के उपयोग की अनुमति देता है।
यदि हम काले और सफेद चित्रों के बारे में बात करते हैं, तो, यदि आप हाफ़टोन का उपयोग नहीं करते हैं, तो पिक्सेल दो राज्यों में से एक लेगा: चमक (सफेद) और चमक (काला) नहीं। और चूंकि पिक्सेल के रंग के बारे में जानकारी को पिक्सेल कोड कहा जाता है, इसलिए मेमोरी का एक बिट इसे एनकोड करने के लिए पर्याप्त है: 0 - काला, 1 - सफेद। यदि रेखांकन को 256 रंगों के धूसर रंगों के संयोजन के रूप में माना जाता है (अर्थात, ये वर्तमान में आम तौर पर स्वीकार किए जाते हैं), तो किसी भी बिंदु की चमक को सांकेतिक शब्दों में बदलने के लिए एक आठ-बिट बाइनरी संख्या पर्याप्त है। कंप्यूटर ग्राफिक्स में, रंग अत्यंत महत्वपूर्ण है। यह दृश्य प्रभाव को बढ़ाने और छवि की जानकारी संतृप्ति को बढ़ाने के साधन के रूप में कार्य करता है। मानव मस्तिष्क द्वारा गठित रंग की भावना कैसे होती है? यह वस्तुओं को प्रतिबिंबित करने या विकिरण करने से रेटिना में प्रवेश करने वाले प्रकाश प्रवाह के विश्लेषण के परिणामस्वरूप होता है। यह आमतौर पर स्वीकार किया जाता है कि मानव रंग रिसेप्टर्स, जिन्हें शंकु भी कहा जाता है, तीन समूहों में विभाजित हैं, जिनमें से प्रत्येक केवल एक रंग - लाल, या हरा या नीला देख सकते हैं।
रंग मॉडल।
यदि हम रंगीन ग्राफिक छवियों के कोडन के बारे में बात करते हैं, तो हमें मुख्य घटकों में मनमाने रंग के अपघटन के सिद्धांत पर विचार करने की आवश्यकता है। वे कई कोडिंग सिस्टम का उपयोग करते हैं: एचएसबी, आरजीबी और सीएमवाईके। पहला रंग मॉडल सरल और सहज है, अर्थात यह मनुष्यों के लिए सुविधाजनक है, दूसरा कंप्यूटर के लिए सबसे सुविधाजनक है, और अंतिम मॉडल प्रिंटर के लिए CMYK है। इन रंग मॉडलों का उपयोग इस तथ्य के कारण है कि विकिरण द्वारा प्रकाश प्रवाह का गठन किया जा सकता है, जो "शुद्ध" वर्णक्रमीय रंगों का एक संयोजन है: लाल, हरा, नीला या उनका डेरिवेटिव। एडिक्टिव कलर रिप्रोडक्शन (रेडिएशन ऑब्जेक्ट्स का विशिष्ट) और सबट्रैक्टिव कलर रिप्रोडक्शन (रिफ्लेक्टिव ऑब्जेक्ट्स का विशिष्ट) के बीच एक अंतर किया जाता है। पहले प्रकार के ऑब्जेक्ट का एक उदाहरण एक मॉनिटर का कैथोड रे ट्यूब है, और दूसरा प्रकार एक प्रिंटिंग प्रिंट है। कोडिंग सूचना प्रतीक वर्णमाला
1) एचएसबी मॉडल को तीन घटकों की विशेषता है: ह्यू, संतृप्ति और चमक। इन घटकों को समायोजित करके बड़ी संख्या में कस्टम रंग प्राप्त किए जा सकते हैं। यह रंग मॉडल उन ग्राफिक संपादकों में सबसे अच्छा उपयोग किया जाता है, जिसमें चित्र स्वयं द्वारा बनाए गए होते हैं, बजाय समाप्त हुए लोगों द्वारा संसाधित किए गए। फिर, आपके बनाए गए कार्य को RGB रंग मॉडल में परिवर्तित किया जा सकता है, अगर इसे स्क्रीन इलस्ट्रेशन के रूप में उपयोग करने की योजना है, या CMYK, यदि मुद्रित किया जाता है, तो रंग मान को सर्कल के केंद्र से आने वाले वेक्टर के रूप में चुना जाता है। वेक्टर की दिशा कोणीय डिग्री में निर्दिष्ट की जाती है और रंग डाली निर्धारित करती है। रंग संतृप्ति वेक्टर की लंबाई से निर्धारित होती है, और रंग चमक एक अलग अक्ष पर सेट होती है, जिसमें से शून्य बिंदु काला होता है। केंद्र में बिंदु सफेद (तटस्थ) रंग से मेल खाती है, और परिधि के आसपास के बिंदु शुद्ध रंगों के अनुरूप हैं।
2) आरजीबी पद्धति का सिद्धांत इस प्रकार है: यह ज्ञात है कि किसी भी रंग को तीन रंगों के संयोजन के रूप में दर्शाया जा सकता है: लाल (लाल, आर), हरा (हरा, जी), नीला (ब्लू, बी)। इन घटकों की उपस्थिति या अनुपस्थिति के कारण अन्य रंग और उनके शेड प्राप्त किए जाते हैं। प्राथमिक रंगों के पहले अक्षरों द्वारा, सिस्टम को इसका नाम मिला - RGB। यह रंग मॉडल एडिटिव है, अर्थात किसी भी रंग को आप विभिन्न अनुपातों में प्राथमिक रंगों का संयोजन प्राप्त कर सकते हैं। जब प्राथमिक रंग का एक घटक दूसरे पर आरोपित होता है, तो कुल विकिरण की चमक बढ़ जाती है। यदि हम सभी तीन घटकों को मिलाते हैं, तो हमें एक ग्रे रंग मिलता है, जिसकी चमक में वृद्धि होती है, जिसमें सफेद रंग होता है।
256 टोन ग्रेडेशन पर (प्रत्येक डॉट 3 बाइट्स में एन्कोडेड है), न्यूनतम RGB मान (0,0,0) काले के अनुरूप हैं, और सफेद वाले निर्देशांक (255, 255, 255) के साथ अधिकतम के अनुरूप हैं। रंग घटक का बाइट मान जितना बड़ा होगा, यह रंग उतना ही शानदार होगा। उदाहरण के लिए, गहरे नीले रंग को तीन बाइट्स (0, 0, 128) और चमकदार नीले (0, 0, 255) के साथ एन्कोड किया गया है।
3) CMYK विधि का सिद्धांत। इस रंग मॉडल का उपयोग मुद्रण के लिए प्रकाशन तैयार करने के लिए किया जाता है। प्राथमिक रंगों में से प्रत्येक को एक अतिरिक्त रंग सौंपा गया है (प्राथमिक को सफेद करने के लिए पूरक)। अन्य प्राथमिक रंगों की एक जोड़ी को जोड़कर अतिरिक्त रंग प्राप्त करें। तो, लाल के लिए पूरक रंग हैं सियान (सियान, सी) \u003d हरा + नीला \u003d सफेद - लाल, हरा - मैजेंटा (मैजेंटा, एम) \u003d लाल + नीला \u003d सफेद - हरा, नीला के लिए - पीला (पीला, वाई) \u003d लाल + हरा \u003d सफेद - नीला। इसके अलावा, घटकों में एक मनमाना रंग के अपघटन का सिद्धांत बुनियादी और अतिरिक्त दोनों पर लागू किया जा सकता है, अर्थात, किसी भी रंग को लाल, हरे, नीले घटक के योग के रूप में या नीले, purpureal, पीले घटक के योग के रूप में दर्शाया जा सकता है। मूल रूप से, इस विधि को मुद्रण उद्योग में अपनाया जाता है। लेकिन वे अभी भी काले रंग का उपयोग करते हैं (ब्लॅकबिन, चूंकि पत्र बी पहले से ही नीले रंग में व्याप्त है, यह अक्षर K द्वारा दर्शाया गया है)। यह इस तथ्य के कारण है कि अतिरिक्त रंगों को ओवरलैप करने से शुद्ध काले रंग का उत्पादन नहीं होता है।
रंग ग्राफिक्स की प्रस्तुति के कई तरीके हैं:
क) पूर्ण रंग (ट्रू कलर);
c) इंडेक्स।
पूर्ण-रंग मोड में, प्रत्येक घटक की चमक को एन्कोड करने के लिए 256 मान (आठ बाइनरी बिट्स) का उपयोग किया जाता है, अर्थात, एक पिक्सेल (RGB सिस्टम में) के रंग को एनकोड करने में 8 * 3 \u003d 24 बिट्स लगते हैं। यह आपको विशिष्ट रूप से 16.5 मिलियन रंगों की पहचान करने की अनुमति देता है। यह मानव आंख की संवेदनशीलता के काफी करीब है। रंग ग्राफिक्स का प्रतिनिधित्व करने के लिए सीएमवाईके सिस्टम का उपयोग करते समय, आपके पास 8 * 4 \u003d 32 बाइनरी बिट्स होने चाहिए।
हाई कलर मोड 16-बिट बाइनरी नंबर का उपयोग करके एक एन्कोडिंग है, अर्थात, प्रत्येक बिंदु को एन्कोडिंग करते समय बाइनरी बिट्स की संख्या घट जाती है। लेकिन यह एन्कोडेड रंगों की सीमा को काफी कम कर देता है।
इंडेक्स कलर कोडिंग के साथ केवल 256 कलर टोन ट्रांसमिट किए जा सकते हैं। प्रत्येक रंग आठ डेटा बिट्स का उपयोग करके एन्कोड किया गया है। लेकिन चूंकि 256 मान मानव आंखों के लिए उपलब्ध रंगों की पूरी श्रृंखला को व्यक्त नहीं करते हैं, यह समझा जाता है कि ग्राफिक डेटा से एक पैलेट (लुक-अप टेबल) जुड़ा हुआ है, जिसके बिना प्रजनन अपर्याप्त होगा: समुद्र लाल हो सकता है और पत्तियां नीले रंग की हो सकती हैं। इस मामले में रेखापुंज बिंदु के कोड का अर्थ केवल रंग नहीं है, लेकिन पैलेट में केवल इसकी संख्या (सूचकांक) है। इसलिए शासन का नाम - सूचकांक।
Allbest.ru पर पोस्ट किया गया
इसी तरह के दस्तावेज
पाठ जानकारी को संसाधित करने के लिए साधन और प्रौद्योगिकियां: एमएस-डॉस संपादक, वर्ड पैड, नोटपैड, माइक्रोसॉफ्ट वर्ड। बाइनरी कोडिंग कंप्यूटर में पाठ जानकारी। रूसी पत्रों के लिए कोड तालिकाओं की किस्मों पर विचार: विंडोज, एमएस-डॉस, कोइ -8, मैक, आईएसओ।
टर्म पेपर, 04/27/2013 जोड़ा गया
एक पीसी, वैज्ञानिक और सैन्य अनुसंधान में आवेदन, ग्राफिक जानकारी प्रसंस्करण के लिए प्रौद्योगिकी: रूपों, सूचना के कोडन, इसके स्थानिक विवेक। निर्माण और ग्राफिक वस्तुओं का भंडारण, वेक्टर ग्राफिक्स के प्रसंस्करण के साधन।
सार, जोड़ा गया 11/28/2010
संख्या प्रणालियों का उपयोग करके संख्यात्मक जानकारी का प्रतिनिधित्व। प्रतीकात्मक, पाठ, संख्यात्मक और ग्राफिक जानकारी का कोडिंग। हार्ड ड्राइव डिवाइस; सीडी-रॉम ड्राइव। मुख्य विंडोज मेनू का उपयोग करना; प्रोग्रामिंग भाषाओं।
परीक्षण, जोड़ा गया 03/16/2015
एक बाइनरी सिस्टम में सूचना का प्रस्तुतीकरण। प्रोग्रामिंग में कोडिंग की आवश्यकता। ग्राफिक जानकारी, संख्या, पाठ, ध्वनि का कोडिंग। एन्क्रिप्शन और एन्क्रिप्शन के बीच अंतर। प्रतीकात्मक (पाठ) जानकारी की बाइनरी कोडिंग।
सार, जोड़ा गया 03/27/2010
ग्रंथों के साथ काम करने के लिए कार्यक्रम: एमएस-डॉस संपादक, वर्ड पैड, नोटपैड, शब्द, शब्द प्रोसेसर। प्रसंस्करण दस्तावेजों के लिए संपादक। प्रारूपण शैली। कंप्यूटर में पाठ जानकारी की बाइनरी एन्कोडिंग। संचालन तकनीकी प्रक्रिया इसकी प्रसंस्करण।
टर्म पेपर, 04/25/2013 जोड़ा गया
रैखिक और द्वि-आयामी कोडिंग का सार। बारकोड प्रमाणीकरण योजना। सूचना एन्कोडिंग विधियों का विश्लेषण। चेक अंक की गणना। बार कोडिंग इनपुटिंग और प्रोसेसिंग जानकारी की प्रक्रिया के स्वचालन के एक प्रभावी क्षेत्र के रूप में।
प्रस्तुति, जोड़ा गया 05/10/2014
डिजिटल रूप में छवियों का प्रतिनिधित्व करने के एक वेक्टर तरीके के विचार से परिचित होना। ग्राफिक ऑब्जेक्ट को एन्कोडिंग करने के लिए कमांड के अनुक्रम का विकास। मुख्य टीमें; ग्राफिक जानकारी, रेखापुंज और वेक्टर विकल्पों की बाइनरी कोडिंग।
प्रस्तुति, 05/01/2012 जोड़ी गई
सूचना की अवधारणा और इसके कोडिंग के मूल सिद्धांत, उपयोग की गई विधियाँ और तकनीक, उपकरण और कार्य। डिजिटल और पाठ्य, ग्राफिक और ऑडियो जानकारी के लिए कोडिंग प्रक्रियाओं की विशिष्ट विशेषताएं। कंप्यूटर का तार्किक आधार।
टर्म पेपर, 04/23/2014 को जोड़ा गया
प्रकृति, समाज, प्रौद्योगिकी में सूचना और सूचना प्रक्रिया। किसी व्यक्ति की सूचना गतिविधि। कोडिंग की जानकारी। एन्कोडिंग विधियाँ। छवि एन्कोडिंग। साइबरनेटिक्स में जानकारी। सूचना गुण। सूचना की मात्रा को मापना।
सार, जोड़ा गया 11/18/2008
कंप्यूटर विज्ञान में स्कूल पाठ्यक्रम में "कोडिंग सूचना" विषय रखें। कंप्यूटर विज्ञान में एक स्कूल पाठ्यक्रम में "सूचना कोडिंग" के अध्ययन के लिए सिफारिशें। "सूचना कोडिंग" विषय का अध्ययन करने के लिए डिडक्टिक सामग्री और कंप्यूटर विज्ञान पर एक पाठ्येतर घटना।
एक आधुनिक कंप्यूटर संख्यात्मक, पाठ, ग्राफिक, ध्वनि और वीडियो जानकारी को संसाधित कर सकता है। कंप्यूटर में इन सभी प्रकार की जानकारी को बाइनरी कोड में प्रस्तुत किया जाता है, अर्थात, दो की क्षमता वाली एक वर्णमाला का उपयोग किया जाता है (कुल दो वर्ण 0 और 1)। यह इस तथ्य के कारण है कि विद्युत दालों के अनुक्रम के रूप में जानकारी प्रस्तुत करना सुविधाजनक है: कोई नाड़ी (0) नहीं है, एक नाड़ी (1) है। इस तरह के कोडिंग को आमतौर पर बाइनरी कहा जाता है, और शून्य के तार्किक अनुक्रम और खुद को मशीन भाषा कहा जाता है।
मशीन बाइनरी कोड के प्रत्येक अंक में एक बिट के बराबर जानकारी की मात्रा होती है।
इस निष्कर्ष को मशीन वर्णमाला की संख्या को परिवर्तनीय घटनाओं के रूप में देखते हुए बनाया जा सकता है। बाइनरी अंक लिखते समय, आप केवल दो संभावित राज्यों में से एक की पसंद का एहसास कर सकते हैं, जिसका अर्थ है कि यह 1 बिट के बराबर जानकारी का वहन करता है। इसलिए, दो अंक जानकारी को 2 बिट्स, चार अंक - 4 बिट्स, आदि में ले जाते हैं। बिट्स में जानकारी की मात्रा निर्धारित करने के लिए, द्विआधारी मशीन कोड में अंकों की संख्या निर्धारित करना पर्याप्त है।
पाठ सूचना एन्कोडिंग
वर्तमान में, अधिकांश उपयोगकर्ता पाठ जानकारी को संसाधित करने के लिए एक कंप्यूटर का उपयोग करते हैं, जिसमें वर्ण होते हैं: अक्षर, संख्या, विराम चिह्न, आदि।
परंपरागत रूप से, किसी एकल वर्ण को एनकोड करने के लिए, 1 बाइट के बराबर जानकारी का उपयोग किया जाता है, अर्थात, I \u003d 1 बाइट \u003d 8 बिट्स। एक सूत्र का उपयोग करना जो संभावित घटनाओं की संख्या को जोड़ता है और जानकारी की मात्रा I, कोई गणना कर सकता है कि कितने अलग-अलग वर्णों को एन्कोड किया जा सकता है (यह मानते हुए कि वर्ण संभावित घटनाएं हैं):
K \u003d 2 I \u003d 2 8 \u003d 256,
अर्थात्, वर्णमाला की जानकारी को दर्शाने के लिए 256 वर्णों की क्षमता वाली वर्णमाला का उपयोग किया जा सकता है।
कोडिंग का सार यह है कि प्रत्येक वर्ण को 00000000 से 11111111 तक द्विआधारी कोड या इसके संबंधित दशमलव कोड को 0 से 255 तक सौंपा गया है।
यह याद रखना चाहिए कि वर्तमान में, रूसी अक्षरों (KOI - 8, CP1251, CP866, Mac, ISO) को एन्कोड करने के लिए पांच अलग-अलग कोड टेबल का उपयोग किया जाता है, और एक टेबल का उपयोग करके एन्कोड किए गए ग्रंथों को अन्य एन्कोडिंग में सही ढंग से प्रदर्शित नहीं किया जाएगा। यह एक संयुक्त चरित्र एन्कोडिंग टेबल के एक टुकड़े के रूप में नेत्रहीन रूप से प्रतिनिधित्व किया जा सकता है।
विभिन्न बाइनरी वर्णों को एक ही बाइनरी कोड को सौंपा गया है।
| बाइनरी कोड | दशमलव कोड | केओआई8 | SR1251 | SR866 | भार | आईएसओ |
| 11000010 | 194 | ख | - | - | टी |
हालांकि, ज्यादातर मामलों में, उपयोगकर्ता द्वारा पाठ दस्तावेजों के ट्रांसकोडिंग का ध्यान रखा जाता है, और विशेष कार्यक्रम कन्वर्टर्स होते हैं जो अनुप्रयोगों में निर्मित होते हैं।
1997 के बाद से, माइक्रोसॉफ्ट विंडोज और ऑफिस के नवीनतम संस्करणों ने नए यूनिकोड एन्कोडिंग का समर्थन किया है, जो प्रति चरित्र 2 बाइट्स आवंटित करता है, और इसलिए, 256 वर्णों को नहीं, बल्कि 65,536 विभिन्न वर्णों को एनकोड करना संभव है।
एक प्रतीक के संख्यात्मक कोड को निर्धारित करने के लिए, आप या तो कोड तालिका का उपयोग कर सकते हैं, या, एक वर्ड 6.0 / 95 टेक्स्ट एडिटर में काम कर सकते हैं। ऐसा करने के लिए, मेनू से "सम्मिलित करें" - "प्रतीक" चुनें, जिसके बाद स्क्रीन पर प्रतीक डायलॉग बॉक्स दिखाई देता है। चयनित फ़ॉन्ट के लिए एक वर्ण तालिका संवाद बॉक्स में दिखाई देती है। इस तालिका के वर्णों को लाइन से लाइन में व्यवस्थित किया जाता है, क्रमिक रूप से बाएं से दाएं, स्पेस कैरेक्टर (ऊपरी बाएं कोने) से शुरू होकर "I" (निचले दाएं कोने) अक्षर के साथ समाप्त होता है।
विंडोज एन्कोडिंग (CP1251) में संख्यात्मक चरित्र कोड निर्धारित करने के लिए, माउस या कर्सर कुंजियों का उपयोग करके अपने इच्छित चरित्र का चयन करें, फिर कुंजी बटन पर क्लिक करें। उसके बाद, सेटिंग्स संवाद बॉक्स स्क्रीन पर दिखाई देता है, जिसमें चयनित वर्ण का दशमलव संख्यात्मक कोड निचले बाएं कोने में स्थित है।
कार्य
- दो ग्रंथों में समान वर्ण हैं। पहला पाठ रूसी में लिखा गया है, और दूसरा नागुरी जनजाति की भाषा में है, जिसकी वर्णमाला में 16 वर्ण हैं। अधिक जानकारी किसके पाठ से मिलती है?
I \u003d K * a (पाठ की सूचना मात्रा एक वर्ण के सूचना भार द्वारा वर्णों की संख्या के उत्पाद के बराबर है)।
क्योंकि चूँकि दोनों ग्रंथों में समान वर्ण (K) हैं, अंतर वर्णमाला (a) के एक वर्ण की सूचना सामग्री पर निर्भर करता है।
2 ए 1 \u200b\u200b\u003d 32, अर्थात् ए 1 \u003d 5 बिट्स
2 a2 \u003d 16, अर्थात ए 2 \u003d 4 बिट्स।
I1 \u003d K * 5 बिट्स, I2 \u003d K * 4 बिट्स।
तो, 5/4 बार रूसी में लिखे गए पाठ में अधिक जानकारी होती है।
- संदेश की मात्रा, जिसमें 2048 वर्ण हैं, एमबी की 1/512 है। वर्णमाला की शक्ति का निर्धारण करें।
I \u003d 1/512 * 1024 * 1024 * 8 \u003d 16384 बिट्स। - संदेश की सूचना मात्रा बिट्स में परिवर्तित।
a \u003d I / K \u003d 16384/1024 \u003d 16 बिट्स - वर्णमाला के एक वर्ण पर आता है।
2 16 \u003d 65536 अक्षर - प्रयुक्त वर्णमाला की शक्ति।
यह वह वर्णमाला है जिसका उपयोग यूनिकोड एन्कोडिंग में किया जाता है, जो कंप्यूटर में प्रतीकात्मक सूचना के प्रतिनिधित्व के लिए एक अंतरराष्ट्रीय मानक बन जाना चाहिए।
ग्राफिक्स एनकोडिंग
1950 के दशक के मध्य में, बड़े कंप्यूटरों के लिए, जो वैज्ञानिक और सैन्य अनुसंधान में उपयोग किए गए थे, पहली बार डेटा का एक चित्रमय प्रतिनिधित्व लागू किया गया था। वर्तमान में, पीसी का उपयोग करके ग्राफिक जानकारी के प्रसंस्करण के लिए तकनीकों का व्यापक रूप से उपयोग किया जाता है। ऑपरेटिंग सिस्टम के साथ शुरू होने वाले विभिन्न वर्गों के सॉफ्टवेयर के लिए ग्राफिकल यूजर इंटरफेस डी वास्तविक मानक बन गया है। यह संभवतः मानव मानस की संपत्ति के कारण है: विज़ुअलाइज़ेशन एक तेज समझ में योगदान देता है। कंप्यूटर विज्ञान के एक विशेष क्षेत्र में व्यापक उपयोग किया गया है, जो सॉफ्टवेयर और हार्डवेयर कंप्यूटिंग सिस्टम - कंप्यूटर ग्राफिक्स का उपयोग करके छवियों को बनाने और संसाधित करने के तरीकों का अध्ययन करता है। इसके बिना, न केवल कंप्यूटर, बल्कि काफी भौतिक दुनिया की कल्पना करना मुश्किल है, क्योंकि मानव गतिविधि के कई क्षेत्रों में डेटा विज़ुअलाइज़ेशन का उपयोग किया जाता है। एक उदाहरण प्रायोगिक विकास, चिकित्सा (कंप्यूटेड टोमोग्राफी), शोध आदि है।
विशेष रूप से गहन रूप से, 80 के दशक में कंप्यूटर का उपयोग करके ग्राफिक जानकारी को संसाधित करने की तकनीक विकसित होने लगी। ग्राफिक जानकारी को दो रूपों में प्रस्तुत किया जा सकता है: एनालॉग या असतत। एक पेंटिंग, जिसका रंग लगातार बदलता रहता है, एक एनालॉग प्रतिनिधित्व का एक उदाहरण है, और एक इंकजेट प्रिंटर का उपयोग करके मुद्रित छवि और एक अलग रंग के व्यक्तिगत डॉट्स से मिलकर एक असतत प्रतिनिधित्व है। ग्राफिक छवि (विवेकाधिकार) को विभाजित करके, ग्राफिक जानकारी को एनालॉग रूप से असतत में बदल दिया जाता है। उसी समय, एन्कोडिंग किया जाता है - प्रत्येक तत्व को एक कोड के रूप में एक विशिष्ट मूल्य सौंपा जाता है। जब एक छवि एन्कोडिंग होती है, तो इसका स्थानिक विवेक होता है। इसकी तुलना बड़ी संख्या में छोटे रंग के टुकड़े (मोज़ेक विधि) से एक छवि बनाने के लिए की जा सकती है। पूरी छवि को अलग-अलग बिंदुओं में विभाजित किया गया है, प्रत्येक तत्व को उसके रंग का एक कोड सौंपा गया है। इस मामले में, एन्कोडिंग गुणवत्ता निम्न मापदंडों पर निर्भर करेगी: डॉट का आकार और उपयोग किए जाने वाले रंगों की संख्या। डॉट्स का आकार जितना छोटा है, और, इसलिए, छवि बड़ी संख्या में डॉट्स से बनी होती है, एन्कोडिंग गुणवत्ता जितनी अधिक होती है। अधिक रंगों का उपयोग किया जाता है (अर्थात, छवि बिंदु अधिक संभव स्थिति ले सकता है), प्रत्येक बिंदु पर अधिक जानकारी होती है, और इसलिए, एन्कोडिंग गुणवत्ता बढ़ जाती है। ग्राफिक ऑब्जेक्ट्स का निर्माण और भंडारण कई रूपों में संभव है - एक वेक्टर, भग्न या रेखापुंज छवि के रूप में। एक अलग विषय को 3 डी (तीन आयामी) ग्राफिक्स माना जाता है, जो वेक्टर और छवि निर्माण के रेखापुंज तरीकों को जोड़ती है। वह आभासी अंतरिक्ष में वस्तुओं के त्रि-आयामी मॉडल के निर्माण के तरीकों और तकनीकों का अध्ययन करती है। प्रत्येक प्रकार ग्राफिक जानकारी को एन्कोड करने के अपने तरीके का उपयोग करता है।
बिटमैप छवि
एक आवर्धक कांच का उपयोग करके, आप देख सकते हैं कि एक काले और सफेद ग्राफिक छवि, उदाहरण के लिए एक अखबार से, सबसे छोटे डॉट्स होते हैं जो एक निश्चित पैटर्न बनाते हैं - एक रेखापुंज। 19 वीं शताब्दी में फ्रांस में चित्रकला में एक नई दिशा दिखाई दी - बिंदुवाद। उनकी तकनीक यह थी कि कैनवास पर ड्राइंग को बहु-रंगीन डॉट्स के रूप में ब्रश के साथ लागू किया गया था। इसके अलावा, ग्राफिक जानकारी को एन्कोडिंग के लिए छपाई में इस पद्धति का लंबे समय से उपयोग किया जाता है। तस्वीर के प्रसारण की सटीकता बिंदुओं की संख्या और उनके आकार पर निर्भर करती है। चित्र को बिंदुओं में विभाजित करने के बाद, बाएं कोने से शुरू करके, बाईं ओर से दाईं ओर की रेखाओं के साथ चलते हुए, आप प्रत्येक बिंदु का रंग सांकेतिक शब्दों में बदल सकते हैं। अगला, हम एक ऐसे बिंदु को एक पिक्सेल कहेंगे (इस शब्द का मूल अंग्रेज़ी संक्षिप्त नाम "पिक्चर एलिमेंट" - एक पिक्चर एलिमेंट) से जुड़ा है। एक रेखापुंज छवि की मात्रा पिक्सेल की संख्या को गुणा करके निर्धारित की जाती है (एक बिंदु की जानकारी मात्रा द्वारा, जो संभव रंगों की संख्या पर निर्भर करती है। छवि गुणवत्ता मॉनिटर के रिज़ॉल्यूशन द्वारा निर्धारित की जाती है। उच्चतर यह है कि रेखापुंज की पंक्तियों की संख्या जितनी अधिक होगी और लाइन में बिंदुओं की संख्या, उच्च छवि की गुणवत्ता)। पीसी मुख्य रूप से निम्नलिखित स्क्रीन रिज़ॉल्यूशन का उपयोग करते हैं: 640 द्वारा 480, 800 से 600, 1024 से 768 और 1280 से 1024 अंक, प्रत्येक बिंदु की चमक और इसके रैखिक निर्देशांक को पूर्णांक का उपयोग करके व्यक्त किया जा सकता है। , यह कहा जा सकता है कि यह एन्कोडिंग विधि छवि डेटा संसाधित करने के लिए एक बाइनरी कोड के उपयोग की अनुमति देता है।
यदि हम काले और सफेद चित्रों के बारे में बात करते हैं, तो, यदि आप हाफ़टोन का उपयोग नहीं करते हैं, तो पिक्सेल दो राज्यों में से एक लेगा: चमक (सफेद) और चमक (काला) नहीं। और चूंकि पिक्सेल के रंग के बारे में जानकारी को पिक्सेल कोड कहा जाता है, इसलिए मेमोरी का एक बिट इसे एनकोड करने के लिए पर्याप्त है: 0 - काला, 1 - सफेद। यदि रेखांकन को 256 रंगों के धूसर रंगों के संयोजन के रूप में माना जाता है (अर्थात, ये वर्तमान में आम तौर पर स्वीकार किए जाते हैं), तो किसी भी बिंदु की चमक को सांकेतिक शब्दों में बदलने के लिए एक आठ-बिट बाइनरी संख्या पर्याप्त है। कंप्यूटर ग्राफिक्स में, रंग अत्यंत महत्वपूर्ण है। यह दृश्य प्रभाव को बढ़ाने और छवि की जानकारी संतृप्ति को बढ़ाने के साधन के रूप में कार्य करता है। मानव मस्तिष्क द्वारा गठित रंग की भावना कैसे होती है? यह वस्तुओं को प्रतिबिंबित करने या विकिरण करने से रेटिना में प्रवेश करने वाले प्रकाश प्रवाह के विश्लेषण के परिणामस्वरूप होता है। यह आमतौर पर स्वीकार किया जाता है कि मानव रंग रिसेप्टर्स, जिन्हें शंकु भी कहा जाता है, तीन समूहों में विभाजित हैं, जिनमें से प्रत्येक केवल एक रंग - लाल, या हरा या नीला देख सकते हैं।
रंग मॉडल
यदि हम रंगीन ग्राफिक छवियों के कोडन के बारे में बात करते हैं, तो हमें मुख्य घटकों में मनमाने रंग के अपघटन के सिद्धांत पर विचार करने की आवश्यकता है। वे कई कोडिंग सिस्टम का उपयोग करते हैं: एचएसबी, आरजीबी और सीएमवाईके। पहला रंग मॉडल सरल और सहज है, जो एक व्यक्ति के लिए सुविधाजनक है, दूसरा कंप्यूटर के लिए सबसे सुविधाजनक है, और अंतिम मॉडल प्रिंटर के लिए सीएमवाईके है। इन रंग मॉडलों का उपयोग इस तथ्य के कारण है कि विकिरण द्वारा प्रकाश प्रवाह का गठन किया जा सकता है, जो "शुद्ध" वर्णक्रमीय रंगों का एक संयोजन है: लाल, हरा, नीला या उनका डेरिवेटिव। एडिक्टिव कलर रिप्रोडक्शन (रेडिएशन ऑब्जेक्ट्स का विशिष्ट) और सबट्रैक्टिव कलर रिप्रोडक्शन (रिफ्लेक्टिव ऑब्जेक्ट्स का विशिष्ट) के बीच एक अंतर किया जाता है। पहले प्रकार के ऑब्जेक्ट का एक उदाहरण एक मॉनिटर का कैथोड रे ट्यूब है, और दूसरा प्रकार एक प्रिंटिंग प्रिंट है।
1) एचएसबी मॉडल को तीन घटकों की विशेषता है: ह्यू, संतृप्ति और चमक। इन घटकों को समायोजित करके बड़ी संख्या में कस्टम रंग प्राप्त किए जा सकते हैं। यह रंग मॉडल उन ग्राफिक संपादकों में सबसे अच्छा उपयोग किया जाता है, जिसमें चित्र स्वयं द्वारा बनाए गए होते हैं, बजाय समाप्त हुए लोगों द्वारा संसाधित किए गए। फिर, आपके बनाए गए कार्य को RGB रंग मॉडल में परिवर्तित किया जा सकता है, अगर इसे स्क्रीन इलस्ट्रेशन के रूप में उपयोग करने की योजना है, या CMYK, यदि मुद्रित किया जाता है, तो रंग मान को सर्कल के केंद्र से आने वाले वेक्टर के रूप में चुना जाता है। वेक्टर की दिशा कोणीय डिग्री में निर्दिष्ट की जाती है और रंग डाली निर्धारित करती है। रंग संतृप्ति वेक्टर की लंबाई से निर्धारित होती है, और रंग चमक एक अलग अक्ष पर सेट होती है, जिसमें से शून्य बिंदु काला होता है। केंद्र में बिंदु सफेद (तटस्थ) रंग से मेल खाती है, और परिधि के आसपास के बिंदु शुद्ध रंगों के अनुरूप हैं।
2) आरजीबी पद्धति का सिद्धांत इस प्रकार है: यह ज्ञात है कि किसी भी रंग को तीन रंगों के संयोजन के रूप में दर्शाया जा सकता है: लाल (लाल, आर), हरा (हरा, जी), नीला (ब्लू, बी)। इन घटकों की उपस्थिति या अनुपस्थिति के कारण अन्य रंग और उनके शेड प्राप्त किए जाते हैं। प्राथमिक रंगों के पहले अक्षरों द्वारा, सिस्टम को इसका नाम मिला - RGB। यह रंग मॉडल एडिटिव है, अर्थात किसी भी रंग को आप विभिन्न अनुपातों में प्राथमिक रंगों का संयोजन प्राप्त कर सकते हैं। जब प्राथमिक रंग का एक घटक दूसरे पर आरोपित होता है, तो कुल विकिरण की चमक बढ़ जाती है। यदि हम सभी तीन घटकों को मिलाते हैं, तो हमें एक ग्रे रंग मिलता है, जिसकी चमक में वृद्धि होती है, जिसमें सफेद रंग होता है।
256 टोन ग्रेडेशन पर (प्रत्येक डॉट 3 बाइट्स में एन्कोडेड है), न्यूनतम RGB मान (0,0,0) काले के अनुरूप हैं, और सफेद वाले निर्देशांक (255, 255, 255) के साथ अधिकतम के अनुरूप हैं। रंग घटक का बाइट मान जितना बड़ा होगा, यह रंग उतना ही शानदार होगा। उदाहरण के लिए, गहरे नीले रंग को तीन बाइट्स (0, 0, 128) और चमकदार नीले (0, 0, 255) के साथ एन्कोड किया गया है।
3) CMYK विधि का सिद्धांत। इस रंग मॉडल का उपयोग मुद्रण के लिए प्रकाशन तैयार करने के लिए किया जाता है। प्राथमिक रंगों में से प्रत्येक को एक अतिरिक्त रंग सौंपा गया है (प्राथमिक को सफेद करने के लिए पूरक)। अन्य प्राथमिक रंगों की एक जोड़ी को जोड़कर अतिरिक्त रंग प्राप्त करें। तो, लाल के लिए पूरक रंग हैं सियान (सियान, सी) \u003d हरा + नीला \u003d सफेद - लाल, हरा - मैजेंटा (मैजेंटा, एम) \u003d लाल + नीला \u003d सफेद - हरा, नीला के लिए - पीला (पीला, वाई) \u003d लाल + हरा \u003d सफेद - नीला। इसके अलावा, घटकों में एक मनमाना रंग के अपघटन का सिद्धांत बुनियादी और अतिरिक्त दोनों पर लागू किया जा सकता है, अर्थात, किसी भी रंग को लाल, हरे, नीले घटक के योग के रूप में या नीले, purpureal, पीले घटक के योग के रूप में दर्शाया जा सकता है। मूल रूप से, इस विधि को मुद्रण उद्योग में अपनाया जाता है। लेकिन वे अभी भी काले रंग का उपयोग करते हैं (ब्लॅकबिन, चूंकि पत्र बी पहले से ही नीले रंग में व्याप्त है, यह अक्षर K द्वारा दर्शाया गया है)। यह इस तथ्य के कारण है कि अतिरिक्त रंगों को ओवरलैप करने से शुद्ध काले रंग का उत्पादन नहीं होता है।
रंग ग्राफिक्स की प्रस्तुति के कई तरीके हैं:
क) पूर्ण रंग (ट्रू कलर);
बी) उच्च रंग;
c) इंडेक्स।
पूर्ण-रंग मोड में, प्रत्येक घटक की चमक को एन्कोड करने के लिए 256 मान (आठ बाइनरी बिट्स) का उपयोग किया जाता है, अर्थात, एक पिक्सेल (RGB सिस्टम में) के रंग को एनकोड करने में 8 * 3 \u003d 24 बिट्स लगते हैं। यह आपको विशिष्ट रूप से 16.5 मिलियन रंगों की पहचान करने की अनुमति देता है। यह मानव आंख की संवेदनशीलता के काफी करीब है। रंग ग्राफिक्स का प्रतिनिधित्व करने के लिए सीएमवाईके सिस्टम का उपयोग करते समय, आपके पास 8 * 4 \u003d 32 बाइनरी बिट्स होने चाहिए।
उच्च रंग मोड 16-बिट बाइनरी संख्याओं का उपयोग करके एन्कोडिंग है, अर्थात, प्रत्येक बिंदु को एन्कोडिंग करते समय बाइनरी बिट्स की संख्या घट जाती है। लेकिन यह एन्कोडेड रंगों की सीमा को काफी कम कर देता है।
इंडेक्स कलर कोडिंग के साथ, केवल 256 कलर शेड्स ट्रांसमिट किए जा सकते हैं। प्रत्येक रंग आठ डेटा बिट्स का उपयोग करके एन्कोड किया गया है। लेकिन चूंकि 256 मान मानव आंखों के लिए उपलब्ध रंगों की पूरी श्रृंखला को व्यक्त नहीं करते हैं, यह समझा जाता है कि एक पैलेट (लुक-अप टेबल) ग्राफिक डेटा से जुड़ा हुआ है, जिसके बिना प्रजनन अपर्याप्त होगा: समुद्र लाल हो सकता है और पत्तियां नीले रंग की हो सकती हैं। इस मामले में रेखापुंज बिंदु के कोड का अर्थ केवल रंग नहीं है, लेकिन पैलेट में केवल इसकी संख्या (सूचकांक) है। इसलिए शासन का नाम - सूचकांक।
प्रदर्शित रंगों की संख्या (के) और उनके एन्कोडिंग (ए) के लिए बिट्स की संख्या के बीच पत्राचार सूत्र द्वारा पाया जा सकता है: के \u003d 2 ए।
स्क्रीन पर प्रदर्शित छवि का बाइनरी कोड वीडियो मेमोरी में संग्रहीत किया जाता है। वीडियो मेमोरी एक इलेक्ट्रॉनिक वाष्पशील मेमोरी डिवाइस है। वीडियो मेमोरी का आकार डिस्प्ले के रिज़ॉल्यूशन और रंगों की संख्या पर निर्भर करता है। लेकिन इसकी न्यूनतम मात्रा निर्धारित की जाती है ताकि छवि का एक फ्रेम (एक पृष्ठ) फिट बैठता है, अर्थात। पिक्सेल कोड के आकार द्वारा संकल्प के उत्पाद के परिणामस्वरूप।
वी मिन \u003d एम * एन * ए।
एक आठ-रंग पैलेट का बाइनरी कोड।
सोलह-रंग पैलेट आपको उपयोग किए गए रंगों की संख्या बढ़ाने की अनुमति देता है। यहां 4-बिट पिक्सेल एन्कोडिंग का उपयोग किया जाएगा: प्राथमिक रंगों के 3 बिट्स + 1 बिट तीव्रता। उत्तरार्द्ध एक ही समय में तीन बुनियादी रंगों की चमक को नियंत्रित करता है (तीन इलेक्ट्रॉन बीम की तीव्रता)।
एक सोलह रंग पैलेट का बाइनरी कोड।
| रंग | के घटक | |||
| को | डब्ल्यू | सी | तीव्र | |
| लाल | 1 | 0 | 0 | 0 |
| ग्रीन | 0 | 1 | 0 | 0 |
| नीला | 0 | 0 | 1 | 0 |
| नीला | 0 | 1 | 1 | 0 |
| बैंगनी | 1 | 0 | 1 | 1 |
| चमकीला पीला | 1 | 1 | 0 | 1 |
| ग्रे (सफेद) | 1 | 1 | 1 | 0 |
| गहरे भूरे रंग का | 0 | 0 | 0 | 1 |
| चमकीला नीला | 0 | 1 | 1 | 1 |
| चमकीला नीला | 0 | 0 | 1 | 0 |
| … | ||||
| चमकदार सफेद | 1 | 1 | 1 | 1 |
| काला | 0 | 0 | 0 | 0 |
प्राथमिक रंगों की तीव्रता के अलग-अलग नियंत्रण के साथ, प्राप्त रंगों की संख्या बढ़ जाती है। तो 24 बिट्स की रंग गहराई के साथ एक पैलेट प्राप्त करने के लिए, प्रत्येक रंग के लिए 8 बिट्स आवंटित किए जाते हैं, अर्थात, तीव्रता का 256 स्तर संभव है (K \u003d 28)।
बाइनरी कोड एक 256-रंग पैलेट है।
वेक्टर और भग्न चित्र
वेक्टर छवि एक ग्राफिक ऑब्जेक्ट है जिसमें प्राथमिक सेगमेंट और आर्क्स शामिल हैं। छवि का मूल तत्व रेखा है। किसी भी वस्तु की तरह, इसके निम्नलिखित गुण हैं: आकृति (सीधी रेखा, वक्र), मोटाई।, रंग, शैली (धराशायी, ठोस)। बंद लाइनों में भरने की संपत्ति होती है (या तो अन्य वस्तुओं के साथ, या चयनित रंग के साथ)। अन्य सभी वेक्टर ग्राफिक्स ऑब्जेक्ट लाइनों से बने होते हैं। चूंकि रेखा को गणितीय रूप से एकल ऑब्जेक्ट के रूप में वर्णित किया गया है, वेक्टर ग्राफिक्स के माध्यम से ऑब्जेक्ट को प्रदर्शित करने के लिए डेटा की मात्रा रास्टर ग्राफिक्स की तुलना में बहुत छोटी है। वेक्टर छवि के बारे में जानकारी एक नियमित अल्फ़ान्यूमेरिक के रूप में एन्कोडेड है और विशेष कार्यक्रमों द्वारा संसाधित की जाती है।
वेक्टर ग्राफिक्स बनाने और संसाधित करने के लिए निम्न GRs सॉफ्टवेयर टूल्स से संबंधित हैं: CorelDraw, Adobe Illustrator, साथ ही वेक्टरएज़र (ट्रैसर) - वेक्टर छवियों को रेखापुंज छवियों को परिवर्तित करने के लिए विशेष पैकेज।
भग्न ग्राफिक्स वेक्टर की तरह गणितीय गणना के आधार पर। लेकिन वेक्टर के विपरीत, इसका मूल तत्व गणितीय सूत्र ही है। यह इस तथ्य की ओर जाता है कि कोई भी वस्तु कंप्यूटर की मेमोरी में संग्रहीत नहीं होती है और छवि केवल समीकरणों के अनुसार बनाई जाती है। इस पद्धति का उपयोग करके, आप सरल नियमित संरचनाओं का निर्माण कर सकते हैं, साथ ही जटिल चित्र भी बना सकते हैं जो परिदृश्य की नकल करते हैं।
कार्य
यह ज्ञात है कि कंप्यूटर वीडियो मेमोरी में 512 केबी की क्षमता है। स्क्रीन का रिज़ॉल्यूशन 640 बाय 200 है। स्क्रीन के कितने पेज एक साथ पैलेट के साथ वीडियो मेमोरी में फिट होंगे
क) 8 रंगों का;
बी) 16 रंग;
ग) 256 रंग?
130 शेड जानकारी को एन्कोड करने के लिए कितने बिट्स की आवश्यकता होती है? यह गणना करना आसान है कि 8 (वह है, 1 बाइट), क्योंकि 7 बिट्स का उपयोग करके आप ह्यू नंबर को 0 से 127 तक बचा सकते हैं, और 8 बिट्स 0 से 255 तक स्टोर करते हैं। यह देखना आसान है कि यह एन्कोडिंग विधि इष्टतम नहीं है: 130 255 से कम है। कैसे एक ड्राइंग के बारे में जानकारी कॉम्पैक्ट करने के लिए जब यह एक फ़ाइल के लिए लिखा है, अगर आप जानते हैं कि
ए) एक ही समय में आंकड़े में १६ figure में से केवल १६ कलर शेड्स शामिल हैं;
b) आकृति में एक ही समय में सभी 130 शेड्स शामिल हैं, लेकिन विभिन्न रंगों के साथ छायांकित बिंदुओं की संख्या बहुत भिन्न होती है।
ए) यह स्पष्ट है कि 4 बिट्स (आधा बाइट) 16 रंगों के बारे में जानकारी संग्रहीत करने के लिए पर्याप्त हैं। हालाँकि, जब से ये 16 शेड 130 से चुने गए हैं, उनके पास संख्याएँ हो सकती हैं जो 4 बिट्स में फिट नहीं होती हैं। इसलिए, हम पैलेट विधि का उपयोग करते हैं। हमारे ड्राइंग में उपयोग किए जाने वाले शेड्स के लिए 1 से 15 तक 16 "स्थानीय" संख्याएं असाइन करें और पूरे ड्राइंग को 2 पॉइंट प्रति बाइट पर रेट करें। और फिर हम इस जानकारी को जोड़ते हैं (फ़ाइल के अंत में) एक पत्राचार तालिका जिसमें शेड संख्या के साथ 16 जोड़े बाइट्स होते हैं: 1 बाइट इस आकृति में हमारा "स्थानीय" नंबर है, दूसरा इस छाया की वास्तविक संख्या है। (जब बाद के बजाय, ह्यू के बारे में एन्कोडेड जानकारी का उपयोग किया जाता है, उदाहरण के लिए, एक लाल, हरे, नीले कैथोड रे ट्यूब की "इलेक्ट्रॉन बंदूकें" की चमक के बारे में जानकारी, ऐसी तालिका एक रंग पैलेट होगी)। यदि चित्र काफी बड़ा है, तो परिणामस्वरूप फ़ाइल की मात्रा में लाभ महत्वपूर्ण होगा;
बी) चित्र के बारे में जानकारी प्राप्त करने के लिए सबसे सरल एल्गोरिदम को लागू करने का प्रयास करें। तीन रंगों को असाइन करें जिन्होंने न्यूनतम अंकों की संख्या को छायांकित किया, कोड 128 - 130, और शेष शेड्स - कोड 1 -127। हम एक फाइल में लिखेंगे (जो इस मामले में बाइट्स का एक क्रम नहीं है, लेकिन एक ठोस बिट स्ट्रीम है) 1 से 127 की संख्या वाले रंगों के लिए सात-बिट कोड। बिट स्ट्रीम में शेष तीन रंगों के लिए, हम एक साइन-नंबर - सात-बिट 0 - और तुरंत लिखेंगे। दो-बिट "स्थानीय" नंबर के बाद, और फ़ाइल के अंत में हम "स्थानीय" और वास्तविक संख्या के पत्राचार की एक तालिका जोड़ते हैं। चूंकि कोड 128 - 130 वाले शेड दुर्लभ हैं, इसलिए कुछ सात-बिट शून्य होंगे।
ध्यान दें कि इस समस्या में प्रश्न प्रस्तुत करना अन्य समाधानों को बाहर नहीं करता है, छवि की रंग संरचना के संदर्भ के बिना - संग्रह:
क) एक ही रंगों में चित्रित डॉट्स के अनुक्रम के चयन और संख्याओं (रंग), (मात्रा) की एक जोड़ी के साथ इन दृश्यों में से प्रत्येक के प्रतिस्थापन के आधार पर (यह सिद्धांत पीसीएक्स के ग्राफिक प्रारूप को रेखांकित करता है);
बी) पिक्सेल लाइनों की तुलना करके (पहले पृष्ठ पर बिंदुओं की संख्या के अंक की रिकॉर्डिंग, और बाद की पंक्तियों के लिए केवल उन बिंदुओं की संख्या को दर्ज करना जिनकी छाया पिछली पंक्ति में समान स्थिति में बिंदुओं के रंगों से भिन्न होती है - यह जीआईएफ प्रारूप का आधार है);
सी) भग्न छवि पैकिंग एल्गोरिथ्म (YPEG प्रारूप) का उपयोग करना। (IO 6.1999)
ऑडियो एन्कोडिंग
दुनिया विविध प्रकार की ध्वनियों से भरी हुई है: घड़ी की टिक-टिक और मोटरों की गड़गड़ाहट, हवाओं की गड़गड़ाहट और पत्तियों की सरसराहट, पक्षियों का गायन और लोगों की आवाज। आवाज़ें कैसे पैदा होती हैं और वे क्या हैं, इस बारे में लोगों ने बहुत पहले ही अनुमान लगाना शुरू कर दिया था। यहां तक \u200b\u200bकि प्राचीन यूनानी दार्शनिक और वैज्ञानिक - विश्वकोशवादी अरस्तू, टिप्पणियों के आधार पर, ध्वनि की प्रकृति की व्याख्या करते हुए, विश्वास करते हैं कि ध्वनि शरीर वैकल्पिक हवा और दुर्लभता का अनुकूलन बनाता है। तो, एक ऑसिलेटिंग स्ट्रिंग या तो हवा का निर्वहन करती है या हवा को संकुचित करती है, और हवा की लोच के कारण, ये बारी-बारी से प्रभाव अंतरिक्ष में आगे प्रेषित होते हैं - परत से परत तक, लोचदार तरंगें उत्पन्न होती हैं। हमारे कान तक पहुंचते हुए, वे ईयरड्रम पर काम करते हैं और ध्वनि की उत्तेजना पैदा करते हैं।
कान से, एक व्यक्ति लोचदार तरंगों को 16 हर्ट्ज से 20 किलोहर्ट्ज़ (1 हर्ट्ज - प्रति सेकंड 1 दोलन) तक की सीमा में कहीं न कहीं एक आवृत्ति होने पर मानता है। इसके अनुसार, किसी भी माध्यम में लोचदार तरंगें जिनकी आवृत्तियां संकेतित सीमा के भीतर होती हैं, ध्वनि तरंगें या केवल ध्वनि कहलाती हैं। ध्वनि के अध्ययन में, जैसे अवधारणाएँ लहजाऔर लयध्वनि। किसी भी वास्तविक ध्वनि, चाहे वह वाद्ययंत्रों का बजाना हो या किसी व्यक्ति की आवाज हो, निश्चित आवृत्तियों के साथ कई हार्मोनिक कंपनों का एक अजीब मिश्रण है।
दोलन, जिसमें सबसे कम आवृत्ति होती है, मौलिक स्वर कहलाता है, अन्य - ओवरटोन।
टिम्ब्रे - एक विशेष ध्वनि में निहित एक अलग संख्या में ओवरटोन, जो इसे एक विशेष रंग देता है। एक स्वर और दूसरे के बीच का अंतर न केवल संख्या के आधार पर निर्धारित होता है, बल्कि मूलभूत स्वर की ध्वनि के साथ ओवरटोन की तीव्रता से भी होता है। यह समय के अनुसार है कि हम पियानो और वायलिन, गिटार और बांसुरी की आवाज़ को आसानी से पहचान सकते हैं और किसी परिचित व्यक्ति की आवाज़ को पहचान सकते हैं।
एक संगीतमय ध्वनि को तीन गुणों द्वारा विशेषता दी जा सकती है: टिमब्रे, यानी ध्वनि का रंग, जो कंपन के आकार, पिच, प्रति सेकंड कंपन की संख्या (आवृत्ति) और मात्रा के आधार पर निर्धारित होता है, जो कंपन की तीव्रता पर निर्भर करता है।
विभिन्न क्षेत्रों में वर्तमान में कंप्यूटर का व्यापक रूप से उपयोग किया जाता है। ध्वनि जानकारी का प्रसंस्करण, संगीत कोई अपवाद नहीं था। 1983 तक, सभी संगीत रिकॉर्ड विनाइल रिकॉर्ड और कॉम्पैक्ट कैसेट पर जारी किए गए थे। वर्तमान में, सीडी का व्यापक रूप से उपयोग किया जाता है। यदि आपके पास एक कंप्यूटर है जिस पर एक स्टूडियो साउंड कार्ड स्थापित है, तो मिडी कीबोर्ड और माइक्रोफ़ोन जुड़ा हुआ है, आप विशेष संगीत सॉफ़्टवेयर के साथ काम कर सकते हैं।
पारंपरिक रूप से, इसे कई प्रकारों में विभाजित किया जा सकता है:
- विशिष्ट साउंड कार्ड और बाहरी उपकरणों के साथ काम करने के लिए डिज़ाइन किए गए विभिन्न उपयोगिताओं और ड्राइवरों;
- ऑडियो संपादक जो ध्वनि फ़ाइलों के साथ काम करने के लिए डिज़ाइन किए गए हैं, आपको उनके साथ कोई भी संचालन करने की अनुमति देता है - भागों में विभाजन से लेकर प्रसंस्करण प्रभाव;
- सॉफ्टवेयर सिंथेसाइज़र, जो अपेक्षाकृत हाल ही में दिखाई दिए और केवल शक्तिशाली कंप्यूटर पर सही ढंग से काम करते हैं। वे आपको विभिन्न ध्वनियों और अन्य के निर्माण के साथ प्रयोग करने की अनुमति देते हैं।
पहले समूह में सभी ऑपरेटिंग सिस्टम उपयोगिताओं शामिल हैं। इसलिए, उदाहरण के लिए, 95 और 98 जीतने के लिए साउंड / रिकॉर्डिंग साउंड, सीडी और मानक मिडी फ़ाइलों को चलाने के लिए अपने मिक्सर और उपयोगिताओं हैं। साउंड कार्ड स्थापित करके, आप इसके प्रदर्शन का परीक्षण करने के लिए इन कार्यक्रमों का उपयोग कर सकते हैं। उदाहरण के लिए, फोनोग्राफ कार्यक्रम को तरंग-फाइलों (विंडोज प्रारूप में ध्वनि रिकॉर्डिंग फ़ाइलों) के साथ काम करने के लिए डिज़ाइन किया गया है। इन फ़ाइलों में एक्सटेंशन .WAV होता है। यह कार्यक्रम टेप रिकॉर्डर के साथ काम करने के तरीकों के समान ध्वनि रिकॉर्डिंग तकनीकों को खेलने, रिकॉर्ड करने और संपादित करने की क्षमता प्रदान करता है। फोनोग्राफ के साथ काम करने के लिए कंप्यूटर से माइक्रोफ़ोन कनेक्ट करना उचित है। यदि आपको ध्वनि रिकॉर्डिंग करने की आवश्यकता है, तो आपको ध्वनि की गुणवत्ता निर्धारित करने की आवश्यकता है, क्योंकि ध्वनि रिकॉर्डिंग की अवधि इस पर निर्भर करती है। ध्वनि की संभावित अवधि रिकॉर्डिंग गुणवत्ता जितनी अधिक होती है, उतनी ही कम होती है। औसत रिकॉर्डिंग गुणवत्ता के साथ, आप 60 सेकंड तक चलने वाली फ़ाइलें बनाकर भाषण को संतोषजनक रूप से रिकॉर्ड कर सकते हैं। लगभग 6 सेकंड एक रिकॉर्डिंग की अवधि होगी जिसमें एक संगीत सीडी की गुणवत्ता होगी।
लेकिन साउंड कोडिंग का क्या? बचपन से, हमें विभिन्न मीडिया पर संगीत रिकॉर्डिंग के साथ सामना किया गया है: फोनोग्राफ रिकॉर्ड, कैसेट, सीडी, आदि। वर्तमान में ध्वनि रिकॉर्ड करने के दो मुख्य तरीके हैं: एनालॉग और डिजिटल। लेकिन किसी माध्यम पर ध्वनि रिकॉर्ड करने के लिए, इसे विद्युत संकेत में परिवर्तित करने की आवश्यकता होती है।
यह एक माइक्रोफोन का उपयोग करके किया जाता है। सरलतम माइक्रोफोन में एक झिल्ली होती है जो ध्वनि तरंगों के संपर्क में आने पर दोलन करती है। एक कॉइल झिल्ली से जुड़ा होता है, एक चुंबकीय क्षेत्र में झिल्ली के साथ समकालिक रूप से आगे बढ़ता है। एक वैकल्पिक विद्युत प्रवाह कॉइल में होता है। वोल्टेज परिवर्तन ध्वनि तरंगों को सटीक रूप से दर्शाते हैं।
माइक्रोफोन आउटपुट में दिखाई देने वाली वैकल्पिक विद्युत धारा को कहा जाता है अनुरूपसंकेत। विद्युत संकेत के संबंध में, "एनालॉग" का अर्थ है कि यह संकेत समय और आयाम में निरंतर है। यह ध्वनि तरंग के आकार को सटीक रूप से दर्शाता है जो हवा के माध्यम से यात्रा करता है।
ध्वनि की जानकारी असतत या अनुरूप रूप में प्रस्तुत की जा सकती है। उनका अंतर यह है कि जानकारी की एक असतत प्रस्तुति के साथ, भौतिक मात्रा स्टेप वाइज ("सीढ़ी") बदलती है, मूल्यों का एक निश्चित सेट लेती है। यदि जानकारी को एनालॉग रूप में प्रस्तुत किया जाता है, तो भौतिक मात्रा अनंत मान ले सकती है जो लगातार बदल रहे हैं।
एक विनाइल रिकॉर्ड ऑडियो जानकारी के एनालॉग स्टोरेज का एक उदाहरण है, क्योंकि ऑडियो ट्रैक लगातार अपना आकार बदलता रहता है। लेकिन एनालॉग टेप रिकॉर्डिंग में एक बड़ी खामी है - उम्र बढ़ने का मीडिया। एक वर्ष के लिए, एक फोनोग्राम जिसमें उच्च आवृत्तियों का एक सामान्य स्तर था, उन्हें खो सकता है। जब खेला जाता है तो कई बार विनाइल रिकॉर्ड गुणवत्ता खो देते हैं। इसलिए, डिजिटल रिकॉर्डिंग को प्राथमिकता दी जाती है।
80 के दशक की शुरुआत में, सीडी दिखाई दीं। वे ऑडियो जानकारी के असतत भंडारण का एक उदाहरण हैं, क्योंकि सीडी के ऑडियो ट्रैक में विभिन्न परावर्तन वाले खंड होते हैं। सैद्धांतिक रूप से, ये डिजिटल डिस्क हमेशा के लिए रह सकते हैं यदि वे खरोंच नहीं हैं, अर्थात। उनके लाभ यांत्रिक उम्र बढ़ने के लिए स्थायित्व और गैर-संवेदनशीलता हैं। एक और लाभ यह है कि डिजिटल डबिंग के दौरान ध्वनि की गुणवत्ता का कोई नुकसान नहीं होता है।
मल्टीमीडिया साउंड कार्ड्स पर आप एनालॉग माइक्रोफोन प्राइम्प्लीफायर और मिक्सर पा सकते हैं।
ऑडियो सूचना का डिजिटल-से-एनालॉग और एनालॉग-टू-डिजिटल रूपांतरण
संक्षेप में ध्वनि को एनालॉग से डिजिटल रूप में परिवर्तित करने की प्रक्रियाओं पर विचार करें और इसके विपरीत। साउंड कार्ड में जो कुछ हो रहा है उसका अनुमानित विचार ध्वनि के साथ काम करते समय कुछ त्रुटियों से बचने में मदद कर सकता है।
माइक्रोफोन के साथ ध्वनि तरंगों को एक वैकल्पिक वैकल्पिक विद्युत संकेत में परिवर्तित किया जाता है। यह ध्वनि पथ से गुजरता है और एनालॉग-टू-डिजिटल कनवर्टर (एडीसी) में प्रवेश करता है - एक उपकरण जो सिग्नल को डिजिटल रूप में परिवर्तित करता है।
एक सरलीकृत रूप में, एडीसी के संचालन का सिद्धांत निम्नानुसार है: यह निश्चित अंतराल पर संकेत के आयाम को मापता है और आगे गुजरता है, पहले से ही डिजिटल पथ के साथ, संख्याओं का एक क्रम जो आयाम में परिवर्तन के बारे में जानकारी ले जाता है।
एनालॉग-टू-डिजिटल रूपांतरण के दौरान, कोई भौतिक रूपांतरण नहीं होता है। एक फिंगरप्रिंट या नमूना, जो ऑडियो पथ में वोल्टेज के उतार-चढ़ाव का एक डिजिटल मॉडल है, विद्युत संकेत से हटा दिया जाता है। यदि इसे आरेख के रूप में चित्रित किया जाता है, तो यह मॉडल स्तंभों के अनुक्रम के रूप में प्रस्तुत किया जाता है, जिनमें से प्रत्येक एक निश्चित संख्यात्मक मूल्य से मेल खाता है। एक डिजिटल सिग्नल स्वाभाविक रूप से असतत है - अर्थात् रुक-रुक कर, इसलिए डिजिटल मॉडल एनालॉग सिग्नल के आकार से बिल्कुल मेल नहीं खाता है।
एक नमूना एक एनालॉग सिग्नल के आयाम के दो मापों के बीच का समय अंतराल है।
सचमुच, नमूना अंग्रेजी से "नमूना" के रूप में अनुवादित किया गया है। मल्टीमीडिया और पेशेवर ध्वनि शब्दावली में, इस शब्द के कई अर्थ हैं। समय अंतराल के अलावा, एक नमूना को डिजिटल डेटा का कोई अनुक्रम भी कहा जाता है जो एनालॉग-टू-डिजिटल रूपांतरण द्वारा प्राप्त किया गया था। रूपांतरण प्रक्रिया को ही नमूनाकरण कहा जाता है। रूसी तकनीकी भाषा में वे इसे कहते हैं नमूना।
डिजिटल साउंड एक डिजिटल-से-एनालॉग कनवर्टर (डीएसी) का उपयोग करके आउटपुट है, जो आने वाले डिजिटल डेटा के आधार पर, संबंधित समय के इंस्टेंट पर आवश्यक आयाम का एक विद्युत संकेत उत्पन्न करता है।
नमूने के विकल्प
महत्वपूर्ण नमूने पैरामीटर आवृत्ति और बिट गहराई हैं।
आवृत्ति - प्रति सेकंड एनालॉग सिग्नल के आयाम के माप की संख्या।
यदि नमूना आवृत्ति ऑडियो श्रंखला की ऊपरी सीमा की आवृत्ति से दोगुनी से अधिक नहीं है, तो उच्च आवृत्तियों पर नुकसान होगा। यह बताता है कि एक ऑडियो सीडी के लिए मानक आवृत्ति 44.1 kHz है। चूंकि ध्वनि तरंगों का दोलन रेंज 20 हर्ट्ज से 20 किलोहर्ट्ज़ तक होता है, इसलिए प्रति सेकंड सिग्नल माप की संख्या समान अवधि में दोलनों की संख्या से अधिक होनी चाहिए। यदि ध्वनि तरंग की आवृत्ति की तुलना में नमूना आवृत्ति बहुत कम है, तो माप के बीच के समय में संकेत आयाम कई बार बदलने का प्रबंधन करता है, और यह इस तथ्य की ओर जाता है कि डिजिटल फिंगरप्रिंट एक अराजक डेटा सेट को वहन करता है। डिजिटल-से-एनालॉग रूपांतरण में, ऐसा नमूना मुख्य संकेत संचारित नहीं करता है, लेकिन केवल शोर पैदा करता है।
नए ऑडियो डीवीडी सीडी प्रारूप में, सिग्नल को एक सेकंड में 96,000 बार मापा जाता है, अर्थात। 96 kHz की एक नमूना आवृत्ति लागू करें। मल्टीमीडिया अनुप्रयोगों में हार्ड ड्राइव पर स्थान बचाने के लिए अक्सर निम्न आवृत्तियों का उपयोग किया जाता है: 11, 22, 32 kHz। यह श्रव्य आवृत्ति रेंज में कमी की ओर जाता है, जिसका अर्थ है कि जो सुना जाता है उसका एक मजबूत विरूपण है।
यदि एक ग्राफ के रूप में हम 1 kHz की ऊंचाई के साथ एक ही ध्वनि प्रस्तुत करते हैं (एक पियानो के सातवें सप्तक तक एक नोट लगभग इस आवृत्ति से मेल खाती है), लेकिन एक अलग आवृत्ति (साइनसॉइड के निचले हिस्से को सभी ग्राफ़ पर नहीं दिखाया गया है) पर नमूना किया जाता है, तो अंतर दिखाई देगा। क्षैतिज अक्ष पर एक विभाजन, जो समय दिखाता है, 10 नमूनों से मेल खाता है। पैमाना वही है। यह देखा जा सकता है कि 11 kHz की आवृत्ति पर, ध्वनि तरंग के लगभग पांच दोलन हर 50 नमूनों के लिए होते हैं, अर्थात साइन लहर की एक अवधि को केवल 10 मानों के साथ प्रदर्शित किया जाता है। यह एक बहुत गलत संचरण है। उसी समय, अगर हम 44 kHz की नमूना आवृत्ति पर विचार करते हैं, तो साइनसॉइड की प्रत्येक अवधि के लिए पहले से ही लगभग 50 नमूने हैं। इससे आप एक अच्छी गुणवत्ता का संकेत प्राप्त कर सकते हैं।
क्षमता इंगित करता है कि एनालॉग सिग्नल के आयाम में क्या सटीकता होती है। जिस सटीकता के साथ सिग्नल आयाम का मूल्य हर बार डिजिटलीकरण के दौरान प्रसारित होता है, वह डिजिटल-से-एनालॉग रूपांतरण के बाद सिग्नल की गुणवत्ता को निर्धारित करता है। तरंग बहाली की सटीकता थोड़ी गहराई पर निर्भर करती है।
आयाम मान को एनकोड करने के लिए, बाइनरी कोडिंग सिद्धांत का उपयोग किया जाता है। ध्वनि संकेत को विद्युत दालों (बाइनरी जीरो और वाले) के अनुक्रम के रूप में प्रस्तुत किया जाना चाहिए। आमतौर पर, आयाम मानों का 8, 16-बिट या 20-बिट प्रतिनिधित्व का उपयोग किया जाता है। निरंतर ऑडियो सिग्नल के बाइनरी कोडिंग में, इसे असतत सिग्नल स्तरों के अनुक्रम से बदल दिया जाता है। कोडिंग गुणवत्ता नमूना आवृत्ति (प्रति इकाई समय सिग्नल स्तर के माप की संख्या) पर निर्भर करती है। नमूनाकरण की आवृत्ति में वृद्धि के साथ, सूचना के द्विआधारी प्रतिनिधित्व की सटीकता बढ़ जाती है। 8 kHz की आवृत्ति पर (प्रति सेकंड माप की संख्या 8000 है), नमूना ऑडियो सिग्नल की गुणवत्ता रेडियो प्रसारण की गुणवत्ता से मेल खाती है, और 48 kHz की आवृत्ति पर (प्रति सेकंड माप की संख्या 48000) है, एक ऑडियो सीडी की ध्वनि की गुणवत्ता।
यदि आप 8-बिट एन्कोडिंग का उपयोग करते हैं, तो आप एनालॉग सिग्नल के आयाम को डिजिटल डिवाइस की गतिशील रेंज के 1/256 (2 8 \u003d 256) के आयाम को बदलने की सटीकता प्राप्त कर सकते हैं।
यदि आप ऑडियो सिग्नल के आयाम का प्रतिनिधित्व करने के लिए 16-बिट एन्कोडिंग का उपयोग करते हैं, तो माप सटीकता 256 गुना बढ़ जाएगी।
आधुनिक कन्वर्टर्स में, यह 20-बिट सिग्नल कोडिंग का उपयोग करने के लिए प्रथागत है, जो आपको ध्वनि की उच्च-गुणवत्ता वाले डिजिटलीकरण की अनुमति देता है।
सूत्र K \u003d 2 a को याद करें। यहाँ K सभी प्रकार की ध्वनियों की संख्या है (विभिन्न सिग्नल स्तरों या राज्यों की संख्या) जो बिट्स में ध्वनि कोडिंग का उपयोग करके प्राप्त की जा सकती हैं
लेकिन यह डेटा केवल उस सिग्नल के लिए सही है जिसका अधिकतम स्तर 0 dB है। यदि आपको 16 बिट की क्षमता के साथ 6 डीबी के स्तर के साथ एक सिग्नल का नमूना लेने की आवश्यकता है, तो केवल 15 बिट्स वास्तव में इसके आयाम को एन्कोडिंग के लिए रहेंगे। यदि संकेत 12 डीबी पर है, तो 14 बिट्स। जैसे ही सिग्नल स्तर बढ़ता है, इसके डिजिटलीकरण की क्षमता बढ़ जाती है, जिसका अर्थ है कि गैर-रेखीय विरूपण का स्तर कम हो जाता है (तकनीकी साहित्य में "मात्रा का शोर" मौजूद है), जो बदले में, प्रत्येक डीबी के स्तर को 1 बिट से घटाता है।
वर्तमान में, एक नया घरेलू डिजिटल ऑडियो डीवीडी प्रारूप दिखाई दिया है, जो 24-बिट रिज़ॉल्यूशन और 96 kHz की एक नमूना आवृत्ति का उपयोग करता है। इसका उपयोग करके, आप 16-बिट एन्कोडिंग के उपर्युक्त नुकसान से बच सकते हैं।
आधुनिक डिजिटल ऑडियो डिवाइस 20-बिट कन्वर्टर्स से लैस हैं। ध्वनि 16-बिट बनी हुई है, निम्न स्तर पर रिकॉर्डिंग की गुणवत्ता में सुधार के लिए उच्च-बिट कन्वर्टर्स स्थापित किए जाते हैं। ऑपरेशन का उनका सिद्धांत निम्नानुसार है: मूल एनालॉग सिग्नल को 20 बिट्स के रिज़ॉल्यूशन के साथ डिजिटल किया जाता है। फिर, डीएसपीपी डिजिटल सिग्नल प्रोसेसर अपनी क्षमता 16 बिट तक कम करता है। इस मामले में, एक विशेष गणना एल्गोरिथ्म का उपयोग किया जाता है, जिसके साथ आप निम्न-स्तरीय संकेतों के विरूपण को कम कर सकते हैं। डिजिटल-से-एनालॉग रूपांतरण के दौरान रिवर्स प्रक्रिया देखी जाती है: एक विशेष एल्गोरिथ्म का उपयोग करते समय बिट क्षमता 16 से 20 बिट तक बढ़ जाती है जो आपको आयाम मानों को अधिक सटीक रूप से निर्धारित करने की अनुमति देता है। यही है, ध्वनि 16-बिट बनी हुई है, लेकिन ध्वनि की गुणवत्ता में सामान्य सुधार है।
कार्य
- गणना करें कि आपके हार्ड ड्राइव या आवृत्ति पर रिकॉर्ड किए गए किसी अन्य डिजिटल मीडिया पर एक मिनट का डिजिटल ऑडियो कितना स्थान लेगा
- 44.1 kHz;
- 11 kHz;
- 22 kHz;
- 32 kHz
और 16 बिट्स।
ए) यदि 16 बिट्स (2 बाइट्स) के रिज़ॉल्यूशन के साथ एक मोनो सिग्नल 44.1 kHz की आवृत्ति के साथ दर्ज किया जाता है, तो हर मिनट एनालॉग-टू-डिजिटल कनवर्टर 441000 * 2 * 60 \u003d 529000 बाइट्स (लगभग 5 एमबी) डेटा का उत्पादन करेगा, जो एनालॉग सिग्नल के आयाम कंप्यूटर में दर्ज है। हार्ड ड्राइव के लिए।
यदि आप एक स्टीरियो सिग्नल रिकॉर्ड करते हैं, तो 1,058,000 बाइट्स (लगभग 10 एमबी)
बी) आवृत्तियों 11, 22, 32 kHz के लिए, गणना समान रूप से की जाती है।
- एक मोनो-ऑडियो फ़ाइल में कौन सी सूचना की मात्रा होती है, जिसकी अवधि 1 सेकंड है, औसत ध्वनि गुणवत्ता (16 बिट, 24 हर्ट्ज) के साथ?
16 बिट्स * 24000 \u003d 384000 बिट्स \u003d 48000 बाइट्स \u003d 47 kBytes
- 20-बिट एन्कोडिंग और 44.1 kHz की एक नमूना आवृत्ति के साथ 20 सेकंड तक चलने वाली स्टीरियो ऑडियो फ़ाइल की मात्रा की गणना करें।
20 बिट्स * 20 * 44100 * 2 \u003d 35280000 बिट्स \u003d 4410000 बाइट्स \u003d 4.41 एमबी
- पुराने 8-बिट साउंड कार्ड का उपयोग करते समय ध्वनि स्तर की संख्या निर्धारित करें।
समाधान।:
के \u003d २ 8 \u003d २५६।
स्वतंत्र कार्य
(ए) पहला विकल्प, बी) दूसरा)।
1. एक उदाहरण दीजिए
क) ऑडियो जानकारी प्रस्तुत करने का एक एनालॉग तरीका;
बी) ऑडियो जानकारी प्रस्तुत करने का एक असतत तरीका।
2. क्या कहा जाता है
ए) नमूना दर (नमूना);
बी) नमूना।
3. वर्णन करें
क) बाइनरी साउंड कोडिंग का सिद्धांत क्या है;
b) बाइनरी साउंड कोडिंग की गुणवत्ता किन मापदंडों पर निर्भर करती है।
भाषा: रूसी
प्रारूप: वेब दस्तावेज़
05.07.2011 6892 0 0
थीम। "कंप्यूटर पर जानकारी एन्कोडिंग।"
सबक उद्देश्य:
शैक्षिक:
कोडिंग जानकारी की प्रक्रिया के बारे में छात्रों की समझ बनाने के लिए;
छात्रों को विभिन्न प्रकार के कोड दिखाएं;
सूचना के प्रस्तुतीकरण के एक रूप से दूसरे में संक्रमण के एक तरीके के रूप में छात्रों के बीच ट्रांसकोडिंग संचालन की एक अवधारणा बनाने के लिए;
एक व्यक्ति के आसपास के कोडों की विविधता के साथ छात्रों को परिचित करने के लिए, कोडिंग जानकारी की भूमिका।
कोडिंग जानकारी की भूमिका को चिह्नित करें।
बच्चों को एन्क्रिप्टेड जानकारी डिकोड करना सिखाएं।
अपने ज्ञान को व्यवहार में लाना सिखाना।
विषय और "कोड", "कोडिंग", "डिकोडिंग" की मूल अवधारणाओं पर ज्ञान की एक प्रणाली बनाने के लिए
तालिका का उपयोग करने की क्षमता विकसित करना
एक पाठ संपादक में एक तालिका के साथ काम दिखाएं
विषय में रुचि बढ़ाएं।
शैक्षिक:
छात्रों के बीच जानकारी कोडिंग की प्रक्रिया की समझ बनाने के लिए।
विभिन्न प्रकार के कोडिंग दिखाएं।
बाइनरी कोडिंग जानकारी के लाभों की पहचान करें।
विकास:
किसी दिए गए विषय पर बोलने, विश्लेषण करने और तार्किक रूप से सोचने के लिए छात्रों की क्षमता विकसित करना जारी रखें।
पीसी कौशल विकसित करना जारी रखें।
शैक्षिक:
छात्रों में विषय में रुचि, संज्ञानात्मक जरूरतों के गठन को तेज करने के लिए।
एक दूसरे के साथ मैत्रीपूर्ण संबंध में छात्रों को शिक्षित करना जारी रखें।
पाठ प्रकार: अनुसंधान तत्वों के साथ नई सामग्री के अध्ययन में एक सबक और व्यावहारिक काम में अर्जित ज्ञान का प्रारंभिक समेकन।
सबक चरण:
संगठनात्मक चरण - 1 मिनट।
ज्ञान नियंत्रण - 5 मिनट।
नई सामग्री की व्याख्या - 19 मिनट।
होमवर्क - 1 मिनट।
शारीरिक मिनट - 1 मिनट।
व्यावहारिक कार्य - 11 मिनट।
परावर्तन - 1 मिनट।
पाठ सारांश, ग्रेडिंग - 1 मिनट।
1. संगठनात्मक क्षण।
संदेश विषय, लक्ष्य और पाठ के उद्देश्य।
2. ज्ञान नियंत्रण - 5 मिनट।
1. जानकारी क्या है? (सूचना हमारे आसपास की दुनिया के बारे में जानकारी है (जो कुछ भी हमें घेरती है)।
2. एक व्यक्ति सूचना के साथ क्या कार्य करता है? (एक व्यक्ति लगातार सूचना प्राप्त करने और संचारण, भंडारण और प्रसंस्करण से संबंधित कार्य करता है।)
3. कोई व्यक्ति जानकारी कैसे संग्रहीत करता है? (मन में जानकारी का भंडारण - स्वयं (आंतरिक जानकारी) - यादृच्छिक अभिगम स्मृति; बाह्य स्मृति (दीर्घकालिक)। एक व्यक्ति की स्मृति और मानव जाति की स्मृति भी है)। (प्रस्तुति देखें, स्लाइड 2)
4. आप किस आधुनिक मीडिया से वाकिफ हैं? (चुंबकीय - विनचेस्टर, फ्लॉपी डिस्क; लेजर डिस्क - सीडी और डीवीडी, फ्लैश कार्ड)।
आइए निम्नलिखित पर ध्यान दें। एक आदमी हमें कुछ बताने की कोशिश कर रहा है, लेकिन हम उसे समझ नहीं सकते। आपको क्या लगता है वह इस इशारे से हमें बताना चाहता है? (संख्या 5 दिखाता है, दिखाता है कि सब कुछ ठीक है, शुभकामनाएँ भेजता है)
लेकिन हम यह सुनिश्चित करने के लिए नहीं कह सकते हैं कि वह वास्तव में हमें क्या बताना चाहता है, क्योंकि विभिन्न देशों में समान इशारों का अर्थ पूरी तरह से अलग है। और इन देशों के लोगों को सही ढंग से समझने के लिए क्या किया जाना चाहिए? (इशारों को जानने के लिए, यह जानने के लिए कि उनका क्या मतलब है, क्या कार्रवाई, वस्तु, घटना इन इशारों द्वारा एन्कोडेड है)। आइए विचार करें और यह जानने की कोशिश करें कि आपके उत्तरों में सबसे महत्वपूर्ण क्या है और पाठ का विषय निर्धारित करें। (मुख्य बात - एक इशारा का मतलब अलग-अलग अवधारणाएं हो सकता है, फिर - इस इशारे के तहत इनकोडिंग क्या है, पाठ का विषय
3. नई सामग्री की व्याख्या - 19 मिनट।
बाहरी दुनिया से हमें जो जानकारी मिलती है, वह पारंपरिक संकेतों या बहुत अलग भौतिक प्रकृति के संकेतों के रूप में हमारे सामने आती है। यह प्रकाश, ध्वनि, गंध, स्पर्श है, ये शब्द, चिह्न, प्रतीक, इशारे और चाल हैं।
जानकारी के प्रसारण के लिए, हमें (रिसीवर) न केवल संकेत प्राप्त करना होगा, बल्कि इसे डिक्रिप्ट भी करना होगा। तो, अलार्म को सुनकर, व्यक्ति समझता है कि जागने का समय आ गया है; फ़ोन कॉल - किसी को आपसे बात करने की आवश्यकता है; स्कूल की घंटी - लंबे समय से प्रतीक्षित परिवर्तन के छात्रों को सूचित करता है।
विभिन्न संकेतों की सही अवधारणा के लिए, कोड विकास या कोडिंग की आवश्यकता होती है।
(प्रस्तुति देखें, स्लाइड 5)
दोस्तों, चलो कोड क्या है, कोडिंग की परिभाषाएँ लिखते हैं।
कोड सूचना का प्रतिनिधित्व करने के लिए प्रतीकों की एक प्रणाली है।
कोडिंग - कुछ कोड का उपयोग करके जानकारी की प्रस्तुति का गठन। (या हम यह कह सकते हैं कि कोडिंग सूचना के एक रूप से दूसरे में प्रस्तुति के लिए एक संक्रमण है, जो भंडारण, संचरण या प्रसंस्करण के लिए अधिक सुविधाजनक है)।
प्रतिलोम परिवर्तन को डिकोडिंग कहा जाता है।
दोस्तों, अपनी नोटबुक में लिखें कि:
डिकोडिंग एन्कोडेड जानकारी की सामग्री को पुनर्प्राप्त करने की प्रक्रिया है।
एन्कोडिंग विधि उस उद्देश्य पर निर्भर करती है जिसके लिए इसे किया जाता है।
(प्रस्तुति देखें, स्लाइड 6)
जानकारी को एन्कोड करने के तीन मुख्य तरीके हैं:
1. ग्राफिक - चित्र या आइकन का उपयोग करना;
2. संख्यात्मक - संख्याओं का उपयोग करना;
3. चरित्र - पाठ के समान वर्णमाला के पात्रों का उपयोग करना।
कई कोड हमारे जीवन में बहुत मजबूती से हैं।
तो संख्यात्मक जानकारी अरबी, रोमन अंकों में एन्कोडेड है।
संचार के लिए, हम कोड का उपयोग करते हैं - रूसी, चीन में - चीनी।
किसी भी संगीत कार्य को संगीत संकेतों में एन्कोड किया गया है, और प्लेयर स्क्रीन पर आप एक ग्राफ़ का उपयोग करके जोर से या शांत ध्वनि देख सकते हैं।
अक्सर ऐसा होता है कि जानकारी को संक्षिप्त और संक्षिप्त रूप में प्रस्तुत करने की आवश्यकता होती है। फिर चित्रलेखों को लागू करें, उदाहरण के लिए, स्टोर के दरवाजे पर, पार्क में डंडे पर, सड़क पर।
जानकारी प्रसारित करने के लिए, लोग विशेष कोड के साथ आए, इनमें शामिल हैं: ब्रेल, मोर्स कोड।
संख्या का उपयोग वस्तुओं की संख्या के बारे में जानकारी दर्ज करने के लिए किया जाता है। नंबर विशेष साइन सिस्टम का उपयोग करके लिखे जाते हैं, जिन्हें नंबर सिस्टम कहा जाता है।
संख्या प्रणाली - वर्णों के एक विशिष्ट सेट का उपयोग करके संख्या लिखने के लिए तकनीकों और नियमों का एक सेट।
सब संख्या प्रणाली दो बड़े समूहों में विभाजित हैं: स्थिति और nepozitsionnyh.
स्थिति - किसी संख्या के प्रत्येक अंक का मात्रात्मक मूल्य इस बात पर निर्भर करता है कि किस स्थान (स्थिति या श्रेणी) में एक या अन्य अंक दर्ज किया गया है।
गैर-स्थिति - किसी संख्या के अंक का मात्रात्मक मूल्य इस बात पर निर्भर नहीं करता है कि किस स्थान (स्थिति या श्रेणी) में एक या अन्य अंक दर्ज किया गया है।
सबसे आम गैर-स्थितीय संख्या प्रणाली रोमन है। प्रयुक्त संख्याओं के रूप में: I (1), V (5), X (10), L (50), C (100), D (500), M (1000)।
किसी संख्या का मान संख्या में अंकों के योग या अंतर के रूप में परिभाषित किया जाता है।
MCMXCVIII \u003d 1000+ (1000-100) + (100-10) + 5 + 1 + 1 + 1 \u003d 1998
पहली स्थिति संख्या प्रणाली का आविष्कार प्राचीन बेबीलोन में किया गया था, और बेबीलोन का क्रमांकन था छह दशमलव, यानी। इसमें साठ अंकों का इस्तेमाल किया गया था!
XIX सदी में, काफी व्यापक बारहवें भाग संख्या प्रणाली। वर्तमान में सबसे आम है दशमलव, बाइनरी, अष्टभुजाकार और हेक्साडेसिमल संख्या प्रणाली।
स्थितीय संख्या प्रणालियों में एक संख्या का प्रतिनिधित्व करने के लिए उपयोग किए जाने वाले विभिन्न वर्णों की संख्या को संख्या प्रणाली का आधार कहा जाता है।
संख्या प्रणाली
आधार
संख्या की वर्णमाला
दशमलव
0, 1, 2, 3, 4, 5, 6, 7, 8, 9
बाइनरी
0, 1
अष्टभुजाकार
0, 1, 2, 3, 4, 5, 6, 7
हेक्साडेसिमल
0, 1, 2, 3, 4, 5, 6, 7, 8, 9, ए, बी, सी, डी, ई, एफ
संख्या प्रणालियों का पत्राचार:
दशमलव
बाइनरी
100
101
110
111
अष्टभुजाकार
हेक्साडेसिमल
दशमलव
बाइनरी
1000
1001
1010
1011
1100
1101
1110
1111
अष्टभुजाकार
हेक्साडेसिमल
बाइनरी टेक्स्ट एन्कोडिंग
60 के दशक से शुरू होकर, कंप्यूटर का उपयोग अधिक से अधिक टेक्स्ट की जानकारी को संसाधित करने के लिए किया जाने लगा, और अब दुनिया के अधिकांश पीसी पर टेक्स्ट जानकारी के प्रसंस्करण के साथ कब्जा कर लिया गया है।
परंपरागत रूप से, किसी एकल वर्ण को एन्कोड करने के लिए, सूचना की मात्रा \u003d 1 बाइट (1 बाइट \u003d 8 बिट्स) का उपयोग किया जाता है।
कोडिंग के लिए एकल चरित्र अपेक्षित एक बाइट जानकारी।
यह देखते हुए कि प्रत्येक बिट 1 या 0 मान लेता है, हमें यह पता चलता है कि 1 बाइट की मदद से 256 विभिन्न वर्णों को एन्कोड किया जा सकता है। (२ (\u003d २५६)
एन्कोडिंग यह है कि प्रत्येक वर्ण को 00000000 से 11111111 (या 0 से 255 तक एक दशमलव कोड) के लिए एक अद्वितीय बाइनरी कोड सौंपा गया है।
यह महत्वपूर्ण है कि प्रतीक को एक विशिष्ट कोड असाइन करना समझौते का विषय है, जो कोड तालिका द्वारा तय किया गया है।
एक तालिका जिसमें सीरियल नंबर (कोड) को कंप्यूटर वर्णमाला के सभी प्रतीकों को सौंपा जाता है, टी कहलाता है एन्कोडिंग तालिका.
विभिन्न प्रकार के कंप्यूटरों के लिए, विभिन्न एन्कोडिंग का उपयोग किया जाता है। आईबीएम पीसी के प्रसार के साथ, एक एन्कोडिंग टेबल एक अंतरराष्ट्रीय मानक बन गया है ASCII (सूचना मानक के लिए अमेरिकी मानक कोड) - सूचना विनिमय के लिए अमेरिकी मानक कोड।
इस तालिका में केवल पहली छमाही मानक है, अर्थात्। 0 (00000000) से 127 (0111111) तक की संख्या वाले वर्ण। इसमें लैटिन वर्णमाला, संख्या, विराम चिह्न, कोष्ठक और कुछ अन्य वर्णों के अक्षर शामिल हैं।
शेष 128 कोड विभिन्न संस्करणों में उपयोग किए जाते हैं। रूसी एन्कोडिंग में रूसी वर्णमाला के प्रतीक रखे जाते हैं।
वर्तमान में, रूसी अक्षरों (KOI8, CP1251, CP866, Mac, ISO) के लिए 5 अलग-अलग कोड टेबल हैं।
वर्तमान में, नया अंतर्राष्ट्रीय यूनिकोड मानक व्यापक है, जो प्रत्येक चरित्र को दो बाइट्स आवंटित करता है। इसका उपयोग करते हुए, आप 65536 (216 \u003d 65536) विभिन्न वर्णों को एन्कोड कर सकते हैं।
ASCII मानक भाग तालिका
ASCII विस्तारित कोड तालिका
4. PHYSMINUTE
बंद आँखों के साथ अंतरिक्ष में ड्रा करें:
दिल
दौर
पत्र एम
वर्ग
त्रिकोण
स्लीपरों
5. होमवर्क
सीज़र कोड का उपयोग करके पाठ को एनकोड करें (1 पत्र आगे)
शब्दों को एनकोड करें।
एक दूसरे को कोड किए गए अक्षर लिखें।
6. व्यावहारिक कार्य "संख्याओं और प्रतीकों का कोडिंग"
I. प्रोग्राम कैलकुलेटर का उपयोग करके नंबर कोड करना।
अपने डेस्कटॉप पर कैलकुलेटर प्रोग्राम खोलें।
इंजीनियरिंग दृश्य (मुख्य मेनू में - दृश्य / इंजीनियरिंग) का चयन करें।
एन्कोडिंग विधि (डेसी-दशमलव, बिन - बाइनरी) को स्विच करना, तालिका में भरें।
तालिका भरने के बाद, प्रोग्राम विंडो बंद करें।
दशमलव एन्कोडिंग विधि
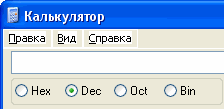
150
बाइनरी कोडिंग विधि
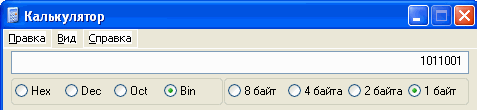
1011
10101010
द्वितीय। इंटरनेट एक्सप्लोरर में कैरेक्टर एनकोडिंग
डेस्कटॉप पर नामांकन फ़ाइल खोलें।
यदि पाठ को समझा नहीं जा सकता है, तो इसे किस कोड के साथ इनकोड किया गया है (मुख्य मेनू में, VIEW / Encoding चुनें) ____________________________ लिखें
एन्कोडिंग प्रकार को सिरिलिक (डॉस) में बदलें। क्या मैं इसे पढ़ सकता हूं? __________
सिरिलिक (विंडोज) को एन्कोडिंग के प्रकार को बदलें। क्या मैं इसे पढ़ सकता हूं? __________
दृश्य / एन्कोडिंग / इसके अतिरिक्त का उपयोग करते हुए, एन्कोडिंग विधियों की संख्या को नीचे लिखें और लिखें - _______________।
प्रोग्राम विंडो बंद करें।
तृतीय। एक कार्यक्रम में चरित्र एनकोडिंगमाइक्रोसॉफ्ट वर्ड
1. डेस्कटॉप पर माइक्रोसॉफ्ट वर्ड खोलें।
2. INSERT / प्रतीक मुख्य मेनू का उपयोग करते हुए, प्रतीक कोड को परिभाषित करें और तालिका में भरें।
प्रतीक
कोड (सिरिलिक डिकोड)
3. सिंबल प्रतीक विंडो बंद करें।
4. छोटे संख्यात्मक कीपैड और ALT कुंजी का उपयोग करके, कोड द्वारा वर्णों की पहचान करें:
प्रतीक
कोड (सिरिलिक डॉस)
157
130
140
7. परावर्तन।
तो दोस्तों, कृपया मुझे बताएं कि आपने पाठ में आज क्या सीखा:
इसे एक पर्यायवाची होने दें
वर्तनी के नियम
1. संज्ञा - एन्कोडिंग
2. दो शब्द - विशेषण
3. तीन शब्द - क्रिया
4. चार शब्द (चार अलग-अलग शब्द, दो वाक्यांश या एक वाक्य) - वस्तु के लिए आपका व्यक्तिगत दृष्टिकोण
5. एक शब्द - एक पर्यायवाची (निष्कर्ष, निष्कर्ष)
8. पाठ को सारांशित करना, ग्रेड सेट करना - 1 मिनट।
कंप्यूटर में किसी भी प्रकार की जानकारी का आंतरिक प्रतिनिधित्व द्विआधारी है।
· बिट - न्यूनतम इकाई मात्रा जानकारी एक बाइनरी अंक के बराबर है।
एक बिट का अर्थ अर्थ के रूप में प्रतिनिधित्व किया जा सकता है:
प्रश्न के जवाब में "हां" या "नहीं" का विकल्प;
- "एक संकेत / कोई संकेत नहीं है";
सत्य / असत्य।
एक बिट दो वस्तुओं को एनकोड कर सकता है।
सूचना की एक इकाई के रूप में बिट बहुत छोटा है, इसलिए, बिट - बाइट्स से प्राप्त जानकारी की मात्रा की एक और अधिक सामान्य इकाई - लगातार उपयोग की जाती है।
· बाइट - कंप्यूटर मेमोरी पढ़ने / लिखने की न्यूनतम इकाई, 8 बिट्स के बराबर:
1 बाइट \u003d 8 बिट्स।
इस स्थिति में, बिट्स को दाएं से बाएं, 0 वें अंक से शुरू किया जाता है।
एक बाइट में 256 वस्तुओं को रखा जा सकता है ( 2 8 = 256 ), जबकि प्रत्येक 256 वस्तुएं 256 8-अंकीय बाइनरी संख्याओं में से एक के अनुरूप होंगी।
1 किलोबाइट \u003d 1 Kb \u003d 1K \u003d 1024 बाइट्स।
1 मेगाबाइट \u003d 1 एमबी \u003d 1 एम \u003d 1024 Kb।
1 गीगाबाइट \u003d 1 जीबी \u003d 1 जी \u003d 1024 एमबी।
1 टेराबाइट \u003d 1 टीबी \u003d 1 टी \u003d 1024 जीबी।
कंप्यूटर में विभिन्न प्रकार की सूचनाओं की प्रस्तुति
कंप्यूटर में संसाधित जानकारी के प्रकार:
न्यूमेरिक;
पाठ,
ग्राफिक,
पीए।
मूल रूप के बावजूद, कंप्यूटर में सभी जानकारी संख्यात्मक रूप में प्रस्तुत की जाती है।
एक पीसी में सांख्यिक जानकारी एन्कोडिंग
एक पीसी पर संख्याओं का प्रतिनिधित्व करने के लिए कई विकल्प हैं। संख्या पूर्णांक और आंशिक, सकारात्मक और नकारात्मक हो सकती है।
धनात्मक पूर्णांक 0 से 255 तक बाइनरी नंबर सिस्टम में सीधे प्रतिनिधित्व किया जा सकता है, जबकि वे कंप्यूटर की मेमोरी में एक बाइट पर कब्जा कर लेंगे।
|
बाइनरी कोड |
|
नकारात्मक पूर्णांक एक विशेष तरीके से प्रतिनिधित्व किया जाता है: एक नकारात्मक संख्या का संकेत आमतौर पर सबसे महत्वपूर्ण बिट के साथ एन्कोड किया जाता है, शून्य को प्लस, माइनस के रूप में एकता के रूप में व्याख्या की जाती है। चूंकि एक बिट पर कब्जा कर लिया जाएगा, -127 से +127 तक की संख्या में पूर्णांक संख्या को एक बाइट के साथ एन्कोड किया जा सकता है। पूर्णांक का प्रतिनिधित्व करने का यह तरीका कहा जाता है प्रत्यक्ष कोड .
नकारात्मक पूर्णांक को एनकोड करने का एक तरीका भी है रिवर्स कोड । इस स्थिति में, सकारात्मक संख्याएं प्रत्यक्ष कोड में सकारात्मक संख्याओं के साथ मेल खाती हैं, और ऋणात्मक संख्याओं को द्विआधारी संख्या 1 0000 0000 से संबंधित सकारात्मक संख्या से घटाकर प्राप्त किया जाता है, उदाहरण के लिए, संख्या -7 कोड 1111 1000 प्राप्त करेगा। बड़ी रेंज के इंटीजर को डबल-बाइट और चार-बाइट मेमोरी पतों में दर्शाया गया है। ।
कम्प्यूटिंग मशीनें प्रतिनिधित्व के दो रूपों का उपयोग करती हैं आंशिक बाइनरी संख्या :
प्राकृतिक रूप या निश्चित बिंदु रूप में;
सामान्य रूप में या फ्लोटिंग पॉइंट (डॉट) फॉर्म में।
निश्चित बिंदु सभी नंबरों को सभी नंबरों के लिए एक निरंतर अल्पविराम स्थिति के साथ अंकों के अनुक्रम के रूप में दर्शाया गया है, पूर्णांक को अंश से अलग किया गया है।
उदाहरण । संख्या को m: n के रूप में दर्शाया जाए, जहाँ m संख्या के पूर्णांक भाग में (दशमलव बिंदु से पहले) बिट्स की एक निश्चित संख्या है, संख्या के भिन्न भाग (दशमलव बिंदु के बाद) में बिट्स की एक निश्चित संख्या है।
उदाहरण के लिए, m \u003d 3, n \u003d 6, तो इस तरह के बिट ग्रिड में लिखे गए नंबरों में फॉर्म है:
213, 560000; + 004, 021025; - 000, 007345.
हालांकि, यह प्रतिनिधित्व मुख्य रूप से पूर्णांकों के लिए उपयोग किया जाता है, क्योंकि जब एक ऑपरेशन का परिणाम इस तरह के बिट ग्रिड की सीमाओं को छोड़ देता है, तो आगे की गणना अपना अर्थ खो देती है।
चल बिन्दु सभी संख्याओं को संख्याओं के दो समूहों के रूप में प्रदर्शित किया जाता है। संख्याओं के पहले समूह को मंटिसा कहा जाता है, दूसरा - क्रम में। इसके अलावा, मंटिसा का पूर्ण मूल्य 1 से कम होना चाहिए, और ऑर्डर पूर्णांक होना चाहिए।
सामान्य दृश्य फ्लोटिंग पॉइंट फॉर्म में एक संख्या को निम्न रूप में दर्शाया जा सकता है:
एन = सांसद आर
जहाँ एम संख्या का मंटिसा (M of) है< 1);
आर - संख्या का क्रम (आर एक पूर्णांक है);
पी - संख्या प्रणाली का आधार।
उदाहरण । पिछले उदाहरण से संख्याएँ हैं:
0, 21356 10 3 ; + 0, 402102510 1 ; - 0, 73450010 -2 .
प्रस्तुति के सामान्य रूप में संख्या प्रदर्शन की एक विशाल श्रृंखला है और आधुनिक पीसी में इसका आधार है।
बाइनरी नंबर सिस्टम के अलावा, बाइनरी-दशमलव नंबर सिस्टम भी व्यापक हो गया है। इस प्रणाली में, सभी दशमलव अंकों को अलग-अलग चार बाइनरी अंकों के साथ एन्कोड किया जाता है और इस रूप में क्रमिक रूप से एक के बाद एक लिखा जाता है।
मैदान के द्वारा कई बिट्स या बाइट्स का एक क्रम कहा जाता है।
पीसी निरंतर और परिवर्तनीय लंबाई के क्षेत्रों को संसाधित कर सकता है।
निरंतर लंबाई के क्षेत्र :
शब्द - 2 बाइट्स;
डबल शब्द - 4 बाइट्स;
विस्तारित शब्द - 8 बाइट्स;
एक शब्द 10 बाइट्स लंबा।
चर-लंबाई वाले खेत 0 से 256 बाइट्स तक किसी भी आकार के हो सकते हैं, लेकिन आवश्यक रूप से बाइट्स की संख्या का एक अभिन्न गुणक है।
1) डबल शब्द - 4 बाइट्स \u003d 32 बिट्स
3) एक शब्द 10 बाइट लंबा - 80 बिट्स
|
क्रम |
अपूर्णांश |
इस स्थिति में, S साइन फ़ील्ड है:
यदि S \u003d 0, संख्या the 0
यदि S \u003d 1, संख्या< 0.

