29.01.2019
बाइनरी डेटा एन्कोडिंग। डेटा एन्कोडिंग
विभिन्न प्रकारों से संबंधित डेटा के साथ काम को स्वचालित करने के लिए, उनकी प्रस्तुति फ़ॉर्म को एकजुट करना बहुत महत्वपूर्ण है - इसके लिए, आमतौर पर एक चाल का उपयोग किया जाता है कोडिंग, वह है, एक प्रकार के डेटा की अभिव्यक्ति दूसरे प्रकार के डेटा के माध्यम से। प्राकृतिक मानव भाषाएँ - यह भाषण के माध्यम से विचारों को व्यक्त करने के लिए एक अवधारणा कोडिंग प्रणाली के अलावा कुछ भी नहीं है। भाषाओं के करीब बकल (ग्राफिक प्रतीकों का उपयोग करते हुए भाषा घटकों के लिए कोडिंग प्रणाली)। इतिहास दिलचस्प जानता है, यद्यपि असफल, "सार्वभौमिक" भाषा और वर्णमाला बनाने का प्रयास करता है। जाहिरा तौर पर, उन्हें पेश करने के प्रयासों की विफलता इस तथ्य के कारण है कि राष्ट्रीय और सामाजिक संस्थाएं स्वाभाविक रूप से समझती हैं कि सार्वजनिक डेटा की कोडिंग प्रणाली में बदलाव से अनिवार्य रूप से सामाजिक तरीकों (यानी, कानूनी और नैतिक मानकों) में बदलाव होगा, और यह सामाजिक उथल-पुथल के कारण हो सकता है। ।
एक सार्वभौमिक कोडिंग टूल की एक ही समस्या प्रौद्योगिकी, विज्ञान और संस्कृति की व्यक्तिगत शाखाओं में काफी सफलतापूर्वक लागू होती है। उदाहरणों में गणितीय अभिव्यक्ति रिकॉर्डिंग प्रणाली, टेलीग्राफ वर्णमाला, समुद्री ध्वज वर्णमाला, अंधे के लिए ब्रेल और बहुत कुछ शामिल हैं।
एक कंप्यूटर प्रणाली भी मौजूद है - इसे कहा जाता है बाइनरी कोडिंग और केवल दो वर्णों के अनुक्रम द्वारा डेटा की प्रस्तुति पर आधारित है: 0 और 1. ये वर्ण कहलाते हैं बाइनरी नंबर अंग्रेजी में - बाइनरी अंक या संक्षिप्त हिट (बिट)।
एक बिट दो अवधारणाओं को व्यक्त कर सकता है: 0 या 1 (हाँ या कोई काला नहीं या सफेद सच या एक झूठ और एम। पी।)। यदि बिट्स की संख्या दो तक बढ़ जाती है, तो चार अलग-अलग अवधारणाएं पहले ही व्यक्त की जा सकती हैं:
तीन बिट्स आठ अलग-अलग मानों को एनकोड कर सकते हैं:
000 001 010 011 100 101 110 111
एक-एक करके सिस्टम में बिट्स की संख्या बढ़ाना बाइनरी कोडिंग, हम इस प्रणाली में व्यक्त किए जा सकने वाले मानों की संख्या को दोगुना कर देते हैं, अर्थात सामान्य सूत्र का रूप है:
जहाँ N- स्वतंत्र एन्कोडेड मूल्यों की संख्या;
टी - इस प्रणाली में बिट कोडिंग को अपनाया गया।
पूर्णांक और वास्तविक संख्या का कोडिंग
इंटेगर इनकोडेड हैं बाइनरी कोड पर्याप्त सरल - बस एक पूर्णांक लें और इसे आधा में विभाजित करें जब तक कि भागफल एकता के बराबर न हो। प्रत्येक भाग के अवशेषों का सेट, अंतिम भागफल के साथ दाईं से बाईं ओर लिखा गया, दशमलव संख्या का एक द्विआधारी एनालॉग बनाता है।
इस प्रकार, 19 \u003d 10011;
पूर्णांक को 0 से 255 तक एनकोड करने के लिए, बाइनरी कोड के 8 बिट्स (8 बिट्स) होना पर्याप्त है। सोलह बिट्स आपको पूर्णांक को ० से ६५,५३५ तक, और २४ बिट्स - १६.५ मिलियन से अधिक विभिन्न मानों की अनुमति देता है।
80-बिट कोडिंग का उपयोग वास्तविक संख्याओं को एनकोड करने के लिए किया जाता है। संख्या को पहले परिवर्तित किया जाता है सामान्यीकृत रूप:
3,1415926 =0,31415926-10"
300 000 = 0,3 10 6
123 456 789 = 0,123456789 10 10
संख्या के पहले भाग को कहा जाता है अपूर्णांश, और दूसरा - सुविधा। 80 बिट्स में से अधिकांश मंटिसा (संकेत के साथ) के भंडारण के लिए आरक्षित हैं और कुछ निश्चित संख्या में बिट्स विशेषताओं को संग्रहीत करने के लिए आवंटित किए गए हैं (साइन के साथ भी)।
पाठ डेटा एन्कोडिंग
यदि वर्णमाला का प्रत्येक वर्ण एक विशिष्ट पूर्णांक (उदाहरण के लिए, एक सीरियल नंबर) के साथ जुड़ा हुआ है, तो एक द्विआधारी कोड का उपयोग करके आप एन्कोड कर सकते हैं और पाठ जानकारी। आठ बिट्स 256 विभिन्न वर्णों को एनकोड करने के लिए पर्याप्त हैं। यह आठ बिट्स के विभिन्न संयोजनों को अंग्रेजी और रूसी भाषाओं के सभी वर्णों के साथ व्यक्त करने के लिए पर्याप्त है, दोनों लोअरकेस और अपरकेस, साथ ही विराम चिह्न, बुनियादी अंकगणितीय संचालन के प्रतीक और कुछ आम तौर पर स्वीकृत विशेष वर्ण, उदाहरण के लिए "with"।
तकनीकी रूप से, यह बहुत सरल दिखता है, लेकिन संगठनात्मक कठिनाइयों में हमेशा काफी सुधार हुआ है। कंप्यूटर प्रौद्योगिकी के विकास के शुरुआती वर्षों में, वे आवश्यक मानकों की कमी से जुड़े थे, लेकिन आजकल वे इसके विपरीत, एक साथ संचालन और परस्पर विरोधी मानकों की प्रचुरता के कारण होते हैं। पूरी दुनिया के लिए एक ही तरह से पाठ डेटा को एनकोड करने के लिए, समान कोडिंग टेबल की आवश्यकता होती है, और यह अभी तक राष्ट्रीय वर्णमाला के पात्रों के बीच विरोधाभास के साथ-साथ एक कॉर्पोरेट प्रकृति के विरोधाभासों के कारण संभव नहीं है।
अंग्रेजी भाषा के लिए, जिसने संचार के अंतरराष्ट्रीय माध्यम के वास्तविक तथ्य पर कब्जा कर लिया है, विरोधाभासों को पहले ही हटा दिया गया है। यू.एस. मानकीकरण संस्थान (एएनएसआई - अमेरिकन नेशनल स्टैंडर्ड इंस्टीट्यूट) एक कोडिंग प्रणाली में डाल दिया ASCII (सूचना मानक के लिए अमेरिकी मानक कोड)। सिस्टम में ASCII दो कोडिंग तालिकाएँ नियत हैं - बुनियादी और बढ़ाया।बेस टेबल 0 से 127 तक के कोड के मूल्यों को ठीक करता है, और विस्तारित संख्या 128 से 255 तक की संख्या वाले वर्णों को संदर्भित करता है।
आधार तालिका के पहले 32 कोड, जो शून्य से शुरू होते हैं, हार्डवेयर निर्माताओं (मुख्य रूप से कंप्यूटर और प्रिंटिंग डिवाइस के निर्माता) को दिए जाते हैं। तथाकथित नियंत्रण कोडजो किसी भी भाषा के प्रतीकों के अनुरूप नहीं हैं, और, तदनुसार, इन कोडों को स्क्रीन पर या प्रिंटिंग डिवाइस पर प्रदर्शित नहीं किया जाता है, लेकिन उन्हें अन्य डेटा के आउटपुट द्वारा नियंत्रित किया जा सकता है।
कोड 32 से शुरू होकर कोड 127 तक, अंग्रेजी वर्णमाला वर्ण, विराम चिह्न, संख्या, अंकगणितीय संचालन और कुछ सहायक वर्णों के कोड रखे गए हैं।
अन्य देशों में इसी तरह के टेक्स्ट एन्कोडिंग सिस्टम विकसित किए गए हैं। इसलिए, उदाहरण के लिए, यूएसएसआर में, इस क्षेत्र में कोइ -7 कोडिंग प्रणाली संचालित है (सात अंकों का सूचना विनिमय कोड)। हालांकि, उपकरण और कार्यक्रमों के निर्माताओं के समर्थन ने अमेरिकी कोड लाया ASCII अंतर्राष्ट्रीय मानक के स्तर, और राष्ट्रीय कोडिंग सिस्टम को कोडिंग सिस्टम के विस्तारित, दूसरे हिस्से में "स्टेप बैक" करना पड़ा, कोड के मूल्यों को 128 से 255 तक परिभाषित किया गया। इस क्षेत्र में एकल मानक की अनुपस्थिति ने एक साथ अभिनय एन्कोडिंग की बहुलता पैदा की। केवल रूस में ही आप तीन वर्तमान एन्कोडिंग मानकों और दो अधिक पुराने लोगों को निर्दिष्ट कर सकते हैं।
उदाहरण के लिए, रूसी भाषा का वर्ण एन्कोडिंग, जिसे एन्कोडिंग के रूप में जाना जाता है विंडोज-1251, Microsoft द्वारा "बाहरी रूप से" पेश किया गया था, लेकिन रूस में इस कंपनी के ऑपरेटिंग सिस्टम और अन्य उत्पादों के व्यापक वितरण को देखते हुए, यह गहराई से उलझा हुआ और व्यापक वितरण पाया गया। यह एन्कोडिंग विंडोज प्लेटफॉर्म पर चलने वाले अधिकांश स्थानीय कंप्यूटरों पर उपयोग की जाती है।
एक अन्य आम एन्कोडिंग को कोइ -8 कहा जाता है (सूचना विनिमय कोड, आठ अंक) - इसकी उत्पत्ति पूर्वी यूरोप में पारस्परिक आर्थिक सहायता परिषद के समय से हुई है। आज, KOI-8 एन्कोडिंग का उपयोग रूस में और रूसी इंटरनेट क्षेत्र में कंप्यूटर नेटवर्क में व्यापक रूप से किया जाता है।
अंतर्राष्ट्रीय मानक, जो रूसी वर्णमाला के पात्रों के एन्कोडिंग के लिए प्रदान करता है, एन्कोडिंग कहा जाता है आईएसओ (अंतर्राष्ट्रीय मानक संगठन)। व्यवहार में, इस एन्कोडिंग का उपयोग शायद ही कभी किया जाता है।
ऑपरेटिंग सिस्टम चलाने वाले कंप्यूटरों पर MS-DOS, दो और एनकोडिंग कार्य कर सकते हैं (एन्कोडिंग GOST और एन्कोडिंग GOST-विकल्प)। उनमें से पहले को व्यक्तिगत कंप्यूटर प्रौद्योगिकी के आगमन के शुरुआती वर्षों में भी अप्रचलित माना जाता था, लेकिन दूसरा आज भी उपयोग किया जाता है।
रूस में संचालित होने वाले टेक्स्ट डेटा एन्कोडिंग सिस्टम की बहुतायत के कारण, चौराहा डेटा रूपांतरण की समस्या उत्पन्न होती है - यह कंप्यूटर विज्ञान के सामान्य कार्यों में से एक है।
यूनिवर्सल टेक्स्ट एन्कोडिंग सिस्टम
यदि हम पाठ डेटा को एन्कोडिंग के लिए एक एकीकृत प्रणाली बनाने से जुड़े संगठनात्मक कठिनाइयों का विश्लेषण करते हैं, तो हम यह निष्कर्ष निकाल सकते हैं कि वे कोड (256) के एक सीमित सेट के कारण होते हैं। इसी समय, यह स्पष्ट है कि यदि, उदाहरण के लिए, आप वर्णों को आठ-बिट बाइनरी संख्याओं के साथ नहीं, बल्कि बड़ी संख्या में अंकों के साथ सांकेतिक शब्दों में बदलना करते हैं, तो संभव कोड मानों की सीमा बहुत बड़ी हो जाएगी। 16-बिट कैरेक्टर एन्कोडिंग पर आधारित ऐसी प्रणाली को कहा जाता था सार्वभौमिक - UNICODE सोलह अंक 65 536 विभिन्न वर्णों के लिए अद्वितीय कोड प्रदान करते हैं - यह क्षेत्र एक तालिका में ग्रह पर अधिकांश भाषाओं के पात्रों को रखने के लिए पर्याप्त है।
इस दृष्टिकोण की तुच्छ स्पष्टता के बावजूद, इस प्रणाली के लिए एक सरल यांत्रिक संक्रमण एक लंबा समय कंप्यूटर प्रौद्योगिकी के अपर्याप्त संसाधनों (कोडिंग प्रणाली में) के कारण संयमित यूनिकोड सभी पाठ दस्तावेज़ स्वचालित रूप से दो बार लंबे हो जाते हैं)। 90 के दशक के उत्तरार्ध में, तकनीकी साधन संसाधन प्रावधान के आवश्यक स्तर पर पहुंच गए, और आज हम एक सार्वभौमिक कोडिंग प्रणाली में दस्तावेजों और सॉफ्टवेयर के क्रमिक हस्तांतरण को देख रहे हैं। अलग-अलग उपयोगकर्ताओं के लिए, इसने सॉफ्टवेयर के साथ विभिन्न कोडिंग सिस्टम में निष्पादित दस्तावेजों के समन्वय की चिंताओं को और बढ़ा दिया है, लेकिन इसे संक्रमण काल \u200b\u200bकी कठिनाइयों के रूप में समझा जाना चाहिए।
ग्राफिक्स एनकोडिंग
यदि आप एक काले और सफेद ग्राफिक छवि को एक अखबार या पुस्तक में एक आवर्धक कांच के साथ मुद्रित करते हुए देखते हैं, तो आप देख सकते हैं कि इसमें छोटे डॉट्स होते हैं जो एक विशेषता पैटर्न कहते हैं रेखापुंज (अंजीर। 1)।
अंजीर। 1. रेखापुंज - ग्राफिक जानकारी एन्कोडिंग की एक विधि, लंबे समय से छपाई उद्योग में स्वीकार की गई है
चूंकि रेखीय निर्देशांक और प्रत्येक बिंदु (चमक) के व्यक्तिगत गुणों को पूर्णांक का उपयोग करके व्यक्त किया जा सकता है, यह कहा जा सकता है कि रेखीय कोडिंग बाइनरी कोड का उपयोग ग्राफिक डेटा का प्रतिनिधित्व करने की अनुमति देता है। वर्तमान में, यह आमतौर पर काले और सफेद चित्रों को भूरे रंग के 256 रंगों के साथ संयोजन के रूप में प्रस्तुत करने के लिए स्वीकार किया जाता है, और इस प्रकार, एक आठ-बिट बाइनरी संख्या आमतौर पर किसी भी बिंदु की चमक को एन्कोड करने के लिए पर्याप्त है।
रंग ग्राफिक्स सांकेतिक शब्दों में बदलना करने के लिए अपघटन सिद्धांत मुख्य घटकों पर मनमाना रंग। जैसे कि घटक तीन प्राथमिक रंगों का उपयोग करते हैं: लाल (रेड, आर), ग्रीन (ग्रीन, जी) और नीला (ब्लू, बी)। व्यवहार में, यह माना जाता है (हालांकि सैद्धांतिक रूप से यह पूरी तरह सच नहीं है) कि मानव आंखों को दिखाई देने वाला कोई भी रंग इन तीन प्राथमिक रंगों को यांत्रिक रूप से मिलाकर प्राप्त किया जा सकता है। ऐसी कोडिंग प्रणाली को एक प्रणाली कहा जाता है। आरजीबी प्राथमिक रंगों के नाम के पहले अक्षर द्वारा।
यदि हम प्रत्येक मुख्य घटक की चमक को एन्कोड करने के लिए 256 मानों (आठ बाइनरी बिट्स) का उपयोग करते हैं, जैसा कि ग्रेस्केल ब्लैक-एंड-व्हाइट छवियों के लिए प्रथागत है, तो 24 बिट्स को एक बिंदु के रंग को एन्कोडिंग पर खर्च करना होगा। इसी समय, कोडिंग प्रणाली 16.5 मिलियन विभिन्न रंगों की एक अस्पष्ट परिभाषा प्रदान करती है, जो वास्तव में मानव आंख की संवेदनशीलता के करीब है। 24-बिट रंग ग्राफिक्स मोड कहा जाता है पूरा रंग (ट्रू कलर)।
प्राथमिक रंगों में से प्रत्येक को एक अतिरिक्त रंग के साथ जोड़ा जा सकता है, अर्थात्, ऐसा रंग जो प्राथमिक रंग को सफेद रंग के लिए पूरक करता है। यह देखना आसान है कि किसी भी प्राथमिक रंग के लिए, अन्य प्राथमिक रंगों के एक जोड़े के योग से बनने वाला रंग पूरक होगा। तदनुसार, पूरक रंग हैं: नीला (सियान, सी) बैंगनी (मैजेंटा, एम) और पीला ( पीला, वाई)। घटक घटकों में एक मनमाना रंग के अपघटन के सिद्धांत को न केवल प्राथमिक रंगों पर लागू किया जा सकता है, बल्कि अतिरिक्त लोगों पर भी लागू किया जा सकता है, अर्थात, किसी भी रंग को सियान, मैजेंटा और पीले घटकों के योग के रूप में दर्शाया जा सकता है। रंग कोडिंग की इस पद्धति को मुद्रण उद्योग में स्वीकार किया जाता है, लेकिन चौथी स्याही का उपयोग छपाई उद्योग में भी किया जाता है - काला (ब्लैक, के)। इसलिए, इस कोडिंग सिस्टम को चार अक्षरों से दर्शाया जाता है सीएमवाईके (काला रंग पत्र द्वारा इंगित किया गया है कश्मीर क्योंकि पत्र पहले से ही नीले रंग के कब्जे में), और इस प्रणाली में रंगीन ग्राफिक्स का प्रतिनिधित्व करने के लिए, आपके पास 32 बिट्स होने चाहिए। इस विधा को भी कहा जाता है पूरा रंग। (ट्रू कलर)।
यदि आप प्रत्येक बिंदु के रंग को एन्कोड करने के लिए उपयोग किए जाने वाले बिट्स की संख्या को कम करते हैं, तो आप डेटा की मात्रा को कम कर सकते हैं, लेकिन एन्कोडेड रंगों की सीमा काफी कम हो जाती है। 16-बिट बाइनरी नंबर के साथ कलर कोडिंग को मोड कहा जाता है ऊँचा रंग
जब आठ डेटा बिट्स का उपयोग करके रंग जानकारी एन्कोडिंग की जाती है, तो केवल 256 रंग टोन प्रसारित किए जा सकते हैं। इस रंग कोडिंग विधि को कहा जाता है सूचकांक। नाम का अर्थ यह है कि, मानव आँख के लिए उपलब्ध रंगों की पूरी श्रृंखला को व्यक्त करने के लिए 256 मान पूरी तरह से अपर्याप्त हैं, रेखापुंज के प्रत्येक बिंदु का कोड अपने आप में रंग को व्यक्त नहीं करता है, लेकिन केवल इसकी संख्या (सूचकांक) में कुछ देखने की मेज कहा जाता है पैलेट। बेशक, इस पैलेट को ग्राफिक डेटा पर लागू किया जाना चाहिए - इसके बिना, आप किसी स्क्रीन या पेपर पर जानकारी को पुन: प्रस्तुत करने के तरीकों का उपयोग नहीं कर सकते (अर्थात, आप कर सकते हैं, बेशक, इसका उपयोग करें, लेकिन अधूरा डेटा के कारण, प्राप्त जानकारी पर्याप्त नहीं होगी: पेड़ों पर पत्ते लाल हो सकते हैं। और आकाश हरा है)।
ऑडियो एन्कोडिंग
ऑडियो जानकारी के साथ काम करने की तकनीक और तरीके कंप्यूटर तकनीक में नवीनतम रूप में आए। इसके अलावा, संख्यात्मक, पाठ और ग्राफिक डेटा के विपरीत, ध्वनि रिकॉर्डिंग में समान रूप से लंबा और सत्यापित कोडिंग इतिहास नहीं था। परिणामस्वरूप, द्विआधारी कोड के साथ ऑडियो जानकारी एन्कोडिंग के तरीके मानकीकरण से दूर हैं। कई व्यक्तिगत कंपनियों ने अपने कॉर्पोरेट मानकों को विकसित किया है, लेकिन सामान्य शब्दों में, दो मुख्य क्षेत्रों को प्रतिष्ठित किया जा सकता है।
एफएम विधि (फ्रीक्वेंसी मॉड्यूलेशन) इस तथ्य के आधार पर कि सैद्धांतिक रूप से किसी भी जटिल ध्वनि को विभिन्न आवृत्तियों के सरल हार्मोनिक संकेतों के अनुक्रम में विघटित किया जा सकता है, जिनमें से प्रत्येक एक नियमित साइन लहर है, और इसलिए संख्यात्मक मापदंडों द्वारा वर्णित किया जा सकता है, अर्थात एक कोड। प्रकृति में, ऑडियो सिग्नल में एक निरंतर स्पेक्ट्रम होता है, अर्थात, वे एनालॉग होते हैं। हार्मोनिक श्रृंखला में उनका विस्तार और असतत डिजिटल संकेतों के रूप में प्रस्तुति विशेष उपकरणों द्वारा की जाती है - एनालॉग-टू-डिजिटल कन्वर्टर्स (एडीसी)। एक संख्यात्मक कोड द्वारा एन्कोडेड ध्वनि को पुन: प्रस्तुत करने के लिए उलटा रूपांतरण किया जाता है डिजिटल से एनालॉग कन्वर्टर्स (DACs)। ऐसे परिवर्तनों के साथ, एन्कोडिंग विधि से जुड़ी जानकारी हानि अपरिहार्य है, इसलिए ध्वनि की गुणवत्ता आमतौर पर काफी संतोषजनक नहीं होती है और इलेक्ट्रॉनिक संगीत की रंग विशेषता के साथ सबसे सरल संगीत वाद्ययंत्र की ध्वनि की गुणवत्ता से मेल खाती है। उसी समय, यह एन्कोडिंग विधि एक बहुत ही कॉम्पैक्ट कोड प्रदान करती है, और इसलिए यह उन वर्षों में भी आवेदन मिला जब कंप्यूटर सुविधाओं के संसाधन स्पष्ट रूप से अपर्याप्त थे।
टेबुलर वेव विधि ( वेव-तालिका) संश्लेषण बेहतर तकनीकी विकास के वर्तमान स्तर से मेल खाता है। इसे सीधे शब्दों में कहें, तो हम कह सकते हैं कि पहले से तैयार तालिकाओं में कई अलग-अलग संगीत वाद्ययंत्रों के लिए ध्वनियों के नमूने संग्रहीत किए जाते हैं (हालांकि न केवल उनके लिए)। प्रौद्योगिकी में, ऐसे नमूनों को कहा जाता है नमूने हैं। संख्यात्मक कोड उपकरण के प्रकार, इसकी मॉडल संख्या, पिच, अवधि और ध्वनि की तीव्रता, इसके परिवर्तन की गतिशीलता, पर्यावरण के कुछ मापदंडों जिसमें ध्वनि होती है, साथ ही ध्वनि की विशेषताओं को दर्शाते हुए अन्य पैरामीटर भी व्यक्त करते हैं। चूंकि "वास्तविक" ध्वनियों का उपयोग नमूनों के रूप में किया जाता है, इसलिए संश्लेषण से उत्पन्न ध्वनि की गुणवत्ता बहुत अधिक होती है और वास्तविक संगीत वाद्ययंत्र की ध्वनि की गुणवत्ता के लिए पहुंचती है।
बुनियादी डेटा संरचनाएँ
बड़े डेटा सेट के साथ काम करने पर डेटा को स्वचालित करना आसान होता है आदेश दिया, यही है, वे एक दी गई संरचना बनाते हैं। डेटा संरचना के तीन मुख्य प्रकार हैं: रैखिक, श्रेणीबद्ध और सारणीबद्ध। उन्हें एक नियमित पुस्तक के उदाहरण पर माना जा सकता है।
यदि आप एक पुस्तक को अलग शीट में लेते हैं और उन्हें मिलाते हैं, तो पुस्तक अपना उद्देश्य खो देगी। वह डेटा सेट का प्रतिनिधित्व करना जारी रखेगी, लेकिन उससे जानकारी प्राप्त करने के लिए पर्याप्त तरीका खोजना आसान नहीं है। (स्थिति और भी बदतर होगी यदि प्रत्येक पत्र को अलग से पुस्तक से काट दिया जाए - इस मामले में शायद ही इसे पढ़ने के लिए कोई पर्याप्त तरीका हो।)
यदि हम सही क्रम में पुस्तक की सभी शीट एकत्र करते हैं, तो हमें सबसे सरल डेटा संरचना मिलती है - रैखिक। आप पहले से ही इस तरह की किताब पढ़ सकते हैं, हालांकि आपको आवश्यक डेटा खोजने के लिए शुरुआत से ही इसे एक पंक्ति में पढ़ना होगा, जो हमेशा सुविधाजनक नहीं होता है।
त्वरित डेटा पुनर्प्राप्ति के लिए, वहाँ है पदानुक्रमित संरचना। उदाहरण के लिए, पुस्तकों को भागों, वर्गों, अध्यायों, अनुच्छेदों आदि में विभाजित किया गया है, एक निचले स्तर की संरचना के तत्वों को उच्च स्तर की संरचना के तत्वों में शामिल किया गया है: अनुभागों में अध्याय, अनुच्छेदों के अध्याय आदि शामिल हैं।
बड़े सरणियों के लिए, एक पदानुक्रमित संरचना में डेटा की खोज एक रैखिक एक की तुलना में बहुत सरल है, हालांकि, यहां, नेविगेशन, देखने की आवश्यकता के साथ जुड़ा हुआ है। व्यवहार में, कार्य इस तथ्य से सरल है कि अधिकांश पुस्तकों में एक सहायक क्रॉस है तालिकाएक रेखीय संरचना के तत्वों के साथ एक रेखीय संरचना के तत्वों को जोड़ना, अर्थात्, पृष्ठ संख्याओं के साथ अनुभागों, अध्यायों और पैराग्राफों को जोड़ना। अनुक्रमिक पढ़ने के लिए डिज़ाइन की गई एक साधारण श्रेणीबद्ध संरचना वाली पुस्तकों में, इस तालिका को आमतौर पर कहा जाता है सामग्री की तालिका और एक जटिल संरचना वाली पुस्तकों में जो चयनात्मक पढ़ने की अनुमति देता है, इसे कहा जाता है सामग्री।
1.6। डेटा और उनकी कोडिंग
भंडारण मीडिया
डेटा सूचना का द्वंद्वात्मक घटक है। वे पंजीकृत संकेत हैं। इसके अलावा, भौतिक पंजीकरण विधि किसी भी हो सकती है: भौतिक निकायों के यांत्रिक आंदोलन, उनके आकार या सतह की गुणवत्ता के मापदंडों में परिवर्तन, विद्युत, चुंबकीय, ऑप्टिकल विशेषताओं में परिवर्तन, रासायनिक संरचना और (या) रासायनिक बांडों की प्रकृति, एक इलेक्ट्रॉनिक प्रणाली की स्थिति में बदलाव और बहुत कुछ।
पंजीकरण विधि के अनुसार, डेटा को विभिन्न प्रकार के मीडिया पर संग्रहीत और परिवहन किया जा सकता है। सबसे आम भंडारण माध्यम, हालांकि सबसे किफायती नहीं, जाहिरा तौर पर कागज है। इसकी सतह की ऑप्टिकल विशेषताओं को बदलकर डेटा को कागज पर दर्ज किया जाता है। ऑप्टिकल गुणों में परिवर्तन (एक निश्चित तरंग दैर्ध्य रेंज में सतह परावर्तन में परिवर्तन) का उपयोग उन उपकरणों में भी किया जाता है जो प्लास्टिक मीडिया पर लेजर बीम के साथ एक परावर्तक कोटिंग (सीडी-रोम) के साथ रिकॉर्ड करते हैं। जैसा कि मीडिया चुंबकीय गुणों में परिवर्तन का उपयोग करता है, चुंबकीय टेप और डिस्क का उल्लेख किया जा सकता है। एक वाहक की सतह पदार्थों की रासायनिक संरचना को बदलकर डेटा रिकॉर्डिंग का व्यापक रूप से फोटोग्राफी में उपयोग किया जाता है। जैव रासायनिक स्तर पर, वन्यजीवों में डेटा का संचय और संचरण होता है।
भंडारण मीडिया हमारे लिए अपने हित में नहीं है, लेकिन जानकारी के गुण बहुत ही निकटता से इसके वाहक के गुणों से संबंधित हैं। किसी भी माध्यम को एक रिज़ॉल्यूशन पैरामीटर (माध्यम के लिए अपनाई गई माप की इकाई में दर्ज की गई डेटा की मात्रा) और एक डायनामिक रेंज (अधिकतम और न्यूनतम रिकॉर्ड किए गए संकेतों के आयाम के आयामों का लघुगणक अनुपात) द्वारा चित्रित किया जा सकता है। संपूर्णता, उपलब्धता और विश्वसनीयता जैसे सूचना गुण अक्सर इन मीडिया गुणों पर निर्भर करते हैं। इसलिए, उदाहरण के लिए, हम इस तथ्य पर भरोसा कर सकते हैं कि एक फ्लॉपी डिस्क पर रखे गए समान डेटाबेस की तुलना में सीडी पर रखे गए डेटाबेस में सूचना की पूर्णता सुनिश्चित करना आसान है, क्योंकि पहले मामले में प्रति यूनिट लंबाई में डेटा रिकॉर्डिंग घनत्व है। रास्ते बहुत अधिक हैं। औसत उपभोक्ता के लिए, पुस्तक में जानकारी की उपलब्धता सीडी पर समान जानकारी की तुलना में काफी अधिक है, क्योंकि सभी उपभोक्ताओं के पास आवश्यक उपकरण नहीं हैं। और, अंत में, यह ज्ञात है कि एक प्रोजेक्टर में एक स्लाइड को देखने का दृश्य प्रभाव कागज पर मुद्रित एक समान चित्रण को देखने से बहुत अधिक है, क्योंकि संचरित प्रकाश में ल्यूमिनेन्स संकेतों की सीमा प्रतिबिंबित प्रकाश की तुलना में अधिक परिमाण के दो से तीन आदेश हैं।
मीडिया को बदलने के लिए डेटा परिवर्तित करने का कार्य कंप्यूटर विज्ञान के सबसे महत्वपूर्ण कार्यों में से एक है। कंप्यूटिंग सिस्टम की लागत की संरचना में, भंडारण मीडिया के साथ काम करने वाले डेटा के इनपुट और आउटपुट के लिए डिवाइस हार्डवेयर की लागत को आधा कर देते हैं।
डेटा संचालन
सूचना प्रक्रिया के दौरान, डेटा को एक तरीके से दूसरे तरीके में परिवर्तित किया जाता है। डेटा प्रोसेसिंग में कई अलग-अलग ऑपरेशन शामिल होते हैं। वैज्ञानिक और तकनीकी प्रगति के विकास और मानव समाज में संबंधों की सामान्य जटिलता के साथ, प्रसंस्करण डेटा की श्रम लागत में लगातार वृद्धि हो रही है। सबसे पहले, यह उत्पादन और समाज के प्रबंधन के लिए शर्तों की निरंतर जटिलता के कारण है। दूसरा कारक, जो संसाधित डेटा की मात्रा में सामान्य वृद्धि का कारण बनता है, वैज्ञानिक और तकनीकी प्रगति के साथ भी जुड़ा हुआ है, अर्थात्, नए डेटा वाहकों के उद्भव और कार्यान्वयन की तीव्र गति, डेटा के भंडारण और वितरण के साधन।
संभावित डेटा संचालन की संरचना में, निम्नलिखित मुख्य को प्रतिष्ठित किया जा सकता है:
डेटा संग्रह - निर्णय लेने के लिए सूचना की पर्याप्त पूर्णता सुनिश्चित करने के लिए डेटा का संचय;
डेटा का औपचारिककरण - एक दूसरे के साथ तुलना करने के लिए विभिन्न स्रोतों से डेटा को एक ही रूप में लाना, अर्थात्, उनकी पहुंच का स्तर बढ़ाने के लिए;
डेटा फ़िल्टरिंग - "अतिरिक्त" डेटा को फ़िल्टर करना जो निर्णय लेने के लिए आवश्यक नहीं है; उसी समय, "शोर" का स्तर कम किया जाना चाहिए, और डेटा की विश्वसनीयता और पर्याप्तता बढ़नी चाहिए;
डेटा को क्रमबद्ध करना - उपयोग में आसानी के लिए दिए गए विशेषता के अनुसार डेटा का आदेश देना; जानकारी की उपलब्धता बढ़ जाती है;
डेटा ग्रुपिंग - प्रयोज्य में सुधार के लिए दिए गए आधार पर डेटा का संयोजन; जानकारी की उपलब्धता बढ़ जाती है;
डेटा संग्रह - एक सुविधाजनक और आसानी से सुलभ रूप में डेटा भंडारण का संगठन; डेटा भंडारण की आर्थिक लागत को कम करने के लिए कार्य करता है और समग्र रूप से सूचना प्रक्रिया की विश्वसनीयता बढ़ाता है;
डेटा संरक्षण - डेटा की हानि, प्रजनन और संशोधन को रोकने के उद्देश्य से उपायों का एक सेट;
डेटा परिवहन - सूचना प्रक्रिया के दूरस्थ प्रतिभागियों के बीच डेटा का रिसेप्शन और ट्रांसमिशन (वितरण और वितरण); जबकि कंप्यूटर विज्ञान में डेटा स्रोत को आमतौर पर सर्वर कहा जाता है, और उपभोक्ता को क्लाइंट कहा जाता है;
डेटा रूपांतरण - डेटा को एक रूप से दूसरे में या एक संरचना से दूसरे में स्थानांतरित करना। डेटा रूपांतरण अक्सर माध्यम के प्रकार में परिवर्तन के साथ जुड़ा होता है, उदाहरण के लिए, पुस्तकों को साधारण कागज के रूप में संग्रहीत किया जा सकता है, लेकिन आप इसके लिए इलेक्ट्रॉनिक रूप और माइक्रोफिल्म दोनों का उपयोग कर सकते हैं। कई डेटा रूपांतरण की आवश्यकता उनके परिवहन के दौरान भी उत्पन्न होती है, खासकर अगर यह इस प्रकार के डेटा के परिवहन के लिए अभिप्रेत नहीं है। एक उदाहरण के रूप में, हम उल्लेख कर सकते हैं कि टेलीफोन नेटवर्क चैनलों के माध्यम से डिजिटल डेटा धाराओं के परिवहन के लिए (जो मूल रूप से केवल संकीर्ण आवृत्ति रेंज में एनालॉग संकेतों के प्रसारण के लिए उन्मुख थे), डिजिटल डेटा को एक तरह के ध्वनि संकेतों में बदलना आवश्यक है, जो कि विशेष उपकरण हैं - टेलीफोन मॉडेम।
यहां दिए गए विशिष्ट डेटा संचालन की सूची पूरी तरह से दूर है। दुनिया भर में लाखों लोग डेटा के निर्माण, प्रसंस्करण, परिवर्तन और परिवहन में लगे हुए हैं, और प्रत्येक कार्यस्थल पर वे सामाजिक, आर्थिक, औद्योगिक, वैज्ञानिक और सांस्कृतिक प्रक्रियाओं के प्रबंधन के लिए आवश्यक अपने विशिष्ट कार्यों को करते हैं। संभावित संचालन की एक पूरी सूची असंभव है, और आवश्यक नहीं है। अब हमारे लिए एक और निष्कर्ष महत्वपूर्ण है: सूचना के साथ काम करना भारी श्रमसाध्य हो सकता है, और इसे स्वचालित करने की आवश्यकता है।
बाइनरी डेटा एन्कोडिंग
विभिन्न प्रकारों से संबंधित डेटा के साथ काम को स्वचालित करने के लिए, उनकी प्रस्तुति फ़ॉर्म को एकजुट करना बहुत महत्वपूर्ण है - इसके लिए, कोडिंग तकनीक का आमतौर पर उपयोग किया जाता है, अर्थात्, एक प्रकार के डेटा की अभिव्यक्ति दूसरे प्रकार के डेटा के माध्यम से। प्राकृतिक मानव भाषाएं भाषण के माध्यम से विचारों को व्यक्त करने के लिए अवधारणाओं को संहिताबद्ध करने से ज्यादा कुछ नहीं हैं। भाषा एबीसी के निकट हैं (ग्राफिक प्रतीकों का उपयोग करते हुए भाषा घटकों के लिए कोडिंग सिस्टम)। इतिहास दिलचस्प जानता है, यद्यपि असफल, "सार्वभौमिक" भाषा और वर्णमाला बनाने का प्रयास करता है। जाहिरा तौर पर, उन्हें पेश करने के प्रयासों की विफलता इस तथ्य के कारण है कि राष्ट्रीय और सामाजिक संस्थाएं स्वाभाविक रूप से समझती हैं कि सार्वजनिक डेटा की कोडिंग प्रणाली में बदलाव से अनिवार्य रूप से सामाजिक तरीकों (यानी, कानूनी और नैतिक मानकों) में बदलाव होगा, और यह सामाजिक उथल-पुथल के कारण हो सकता है। ।
एक सार्वभौमिक कोडिंग टूल की एक ही समस्या प्रौद्योगिकी, विज्ञान और संस्कृति की व्यक्तिगत शाखाओं में काफी सफलतापूर्वक लागू होती है। उदाहरणों में एक गणितीय अभिव्यक्ति रिकॉर्डिंग प्रणाली, टेलीग्राफ वर्णमाला, समुद्री ध्वज वर्णमाला, अंधे के लिए ब्रेल और बहुत कुछ शामिल है।
अंजीर। 1.8। विभिन्न कोडिंग प्रणालियों के उदाहरण
एक कंप्यूटर प्रणाली भी मौजूद है - इसे बाइनरी कोडिंग कहा जाता है और यह केवल दो वर्णों के अनुक्रम द्वारा डेटा की प्रस्तुति पर आधारित है: 0 और 1. इन वर्णों को बाइनरी अंक कहा जाता है, अंग्रेजी में - बाइनरी अंक, या, संक्षेप में, बिट (बिट)।
दो अवधारणाओं को एक बिट के साथ व्यक्त किया जा सकता है: 0 या 1 (हां या नहीं, काला या सफेद, सच्चा या गलत, आदि)। यदि बिट्स की संख्या दो तक बढ़ जाती है, तो चार अलग-अलग अवधारणाएं पहले ही व्यक्त की जा सकती हैं:
तीन बिट्स आठ अलग-अलग मानों को एनकोड कर सकते हैं:
000 001 010 011 100 101 110 111
एक बाइनरी कोडिंग सिस्टम में बिट्स की संख्या बढ़ाकर, हम इस सिस्टम में व्यक्त किए जा सकने वाले मूल्यों की संख्या को दोगुना कर देते हैं।
पूर्णांक और वास्तविक संख्या का कोडिंग
पूर्णांक को 0 से 255 तक एनकोड करने के लिए, बाइनरी कोड के 8 बिट्स (8 बिट्स) होना पर्याप्त है।
……………….
सोलह बिट्स आपको पूर्णांक को 6 से 65535 तक और 24 बिट्स को एन्कोड करने की अनुमति देते हैं - 16.5 मिलियन से अधिक विभिन्न मूल्य।
80-बिट कोडिंग का उपयोग वास्तविक संख्याओं को एनकोड करने के लिए किया जाता है। इस स्थिति में, संख्या पहले से सामान्यीकृत रूप में परिवर्तित हो जाती है।
3.1415926 \u003d 0.3141592610
300,000 \u003d 0.3 · 106
123 456 789 \u003d 0.123456789109
संख्या के पहले भाग को मंटिसा कहा जाता है, और दूसरे को विशेषता कहा जाता है। 80 बिट्स में से अधिकांश मंटिसा (संकेत के साथ) के भंडारण के लिए आरक्षित हैं और कुछ निश्चित संख्या में बिट्स विशेषताओं को संग्रहीत करने के लिए आवंटित किए गए हैं (साइन के साथ भी)।
पाठ डेटा एन्कोडिंग
यदि वर्णमाला का प्रत्येक वर्ण एक विशिष्ट पूर्णांक (उदाहरण के लिए, एक सीरियल नंबर) के साथ जुड़ा हुआ है, तो बाइनरी कोड का उपयोग करके आप पाठ संबंधी जानकारी को भी एन्कोड कर सकते हैं। आठ बिट्स 256 विभिन्न वर्णों को एनकोड करने के लिए पर्याप्त हैं। यह आठ बिट्स के विभिन्न संयोजनों के साथ अंग्रेजी और रूसी वर्णमाला के सभी वर्णों को व्यक्त करने के लिए पर्याप्त है, दोनों लोअरकेस और अपरकेस, साथ ही विराम चिह्न, बुनियादी अंकगणितीय संचालन के प्रतीक, और कुछ आम तौर पर स्वीकृत विशेष वर्ण, उदाहरण के लिए प्रतीक "“ "।
तकनीकी रूप से, यह बहुत सरल दिखता है, लेकिन संगठनात्मक कठिनाइयों में हमेशा काफी सुधार हुआ है। कंप्यूटर प्रौद्योगिकी के विकास के शुरुआती वर्षों में, वे आवश्यक मानकों की कमी से जुड़े थे, लेकिन आजकल वे इसके विपरीत, एक साथ संचालन और परस्पर विरोधी मानकों की प्रचुरता के कारण होते हैं। पूरी दुनिया के लिए पाठ डेटा को उसी तरह से एन्कोड करने के लिए, समान कोडिंग तालिकाओं की आवश्यकता होती है, और यह राष्ट्रीय वर्णमाला के पात्रों के बीच विरोधाभास के साथ-साथ एक कॉर्पोरेट प्रकृति के विरोधाभासों के कारण अभी तक संभव नहीं है।
अंग्रेजी भाषा के लिए, जिसने संचार के अंतरराष्ट्रीय माध्यम के वास्तविक तथ्य पर कब्जा कर लिया है, विरोधाभासों को पहले ही हटा दिया गया है। अमेरिकन नेशनल स्टैंडर्ड इंस्टीट्यूट (ANSI) ने ASCII (अमेरिकन स्टैंडर्ड कोड फॉर इंफॉर्मेशन इंटरचेंज) कोडिंग सिस्टम की शुरुआत की। ASCII प्रणाली में, दो कोडिंग टेबल तय की गई हैं: मूल और उन्नत। बेस टेबल 0 से 127 तक के कोड के मूल्यों को ठीक करता है, और विस्तारित संख्या 128 से 255 तक की संख्या वाले वर्णों को संदर्भित करता है।
आधार तालिका के पहले 32 कोड, जो शून्य से शुरू होते हैं, हार्डवेयर निर्माताओं (मुख्य रूप से कंप्यूटर और प्रिंटिंग डिवाइस के निर्माता) को दिए जाते हैं। इस क्षेत्र में, तथाकथित नियंत्रण कोड रखे जाते हैं, जो किसी भी भाषा वर्ण के अनुरूप नहीं होते हैं, और तदनुसार, ये कोड स्क्रीन पर या प्रिंटिंग डिवाइस पर प्रदर्शित नहीं होते हैं, लेकिन वे यह नियंत्रित कर सकते हैं कि अन्य डेटा आउटपुट कैसे है।
कोड 32 से शुरू होकर कोड 127 तक, अंग्रेजी वर्णमाला वर्ण, विराम चिह्न, संख्या, अंकगणितीय संचालन और कुछ सहायक वर्णों के कोड रखे गए हैं। बेस टेबल aSCII एनकोडिंग 1.1 में दी गई।

अन्य देशों में इसी तरह के टेक्स्ट एन्कोडिंग सिस्टम विकसित किए गए हैं। इसलिए, उदाहरण के लिए, इस क्षेत्र में यूएसएसआर में एक कोडिंग सिस्टम KOI-7 (सूचना विनिमय कोड, सात अंकों) था। हालांकि, उपकरण और सॉफ्टवेयर निर्माताओं के समर्थन ने अमेरिकी ASCII कोड को एक अंतरराष्ट्रीय मानक के स्तर पर ला दिया, और राष्ट्रीय कोडिंग सिस्टम को कोडिंग सिस्टम के दूसरे, विस्तारित हिस्से को "स्टेप बैक" करना पड़ा, जो कोड के मूल्यों को 128 से 255 तक परिभाषित करता है। इस क्षेत्र में एकल मानक की अनुपस्थिति एक साथ संचालन की बहुलता के कारण हुई। एन्कोडिंग। केवल रूस में ही आप तीन वर्तमान एन्कोडिंग मानकों और दो अधिक पुराने लोगों को निर्दिष्ट कर सकते हैं।
उदाहरण के लिए, रूसी भाषा के पात्रों की एन्कोडिंग, जिसे विंडोज -1251 एन्कोडिंग के रूप में जाना जाता है, को Microsoft द्वारा "बाहरी रूप से" पेश किया गया था, लेकिन रूस में इस कंपनी के ऑपरेटिंग सिस्टम और अन्य उत्पादों का व्यापक वितरण दिया गया, यह गहराई से घिर गया और व्यापक वितरण पाया गया (तालिका 1.2) )। यह एन्कोडिंग विंडोज प्लेटफॉर्म पर चलने वाले अधिकांश स्थानीय कंप्यूटरों पर उपयोग की जाती है। यह वर्ल्ड वाइड वेब के रूसी क्षेत्र में वास्तविक रूप से मानक बन गया है।

एक अन्य सामान्य एन्कोडिंग को केओआई -8 (सूचना विनिमय कोड, आठ-अंक) कहा जाता है - इसकी उत्पत्ति पूर्वी यूरोपीय देशों की म्युचुअल आर्थिक सहायता परिषद (तालिका 1.3) के समय से होती है। इस एन्कोडिंग के आधार पर, एन्कोडिंग KOI8-P (रूसी) और KOI8-U (यूक्रेनी) अब मान्य हैं। आज, KOI8-R एन्कोडिंग रूस में कंप्यूटर नेटवर्क और रूसी इंटरनेट क्षेत्र की कुछ सेवाओं में व्यापक रूप से उपयोग की जाती है। विशेष रूप से, रूस में यह ई-मेल संदेश और समाचार समूह में वास्तविक मानक है।

अंतर्राष्ट्रीय मानक, जो रूसी वर्णमाला के प्रतीकों के एन्कोडिंग के लिए प्रदान करता है, एन्कोडिंग आईएसओ (अंतर्राष्ट्रीय मानक संगठन) कहा जाता है। व्यवहार में, इस एन्कोडिंग का उपयोग शायद ही कभी किया जाता है (तालिका 1.4)।

MS-DOS ऑपरेटिंग सिस्टम चलाने वाले कंप्यूटरों पर, दो और एनकोडिंग (GOST एन्कोडिंग और GOST वैकल्पिक एन्कोडिंग) काम कर सकते हैं। उनमें से पहले को व्यक्तिगत कंप्यूटर प्रौद्योगिकी के आगमन के शुरुआती वर्षों में भी अप्रचलित माना जाता था, लेकिन दूसरा आज भी उपयोग किया जाता है (तालिका 1.5 देखें)।

रूस में संचालित होने वाले टेक्स्ट डेटा एन्कोडिंग सिस्टम की बहुतायत के कारण, चौराहा डेटा रूपांतरण की समस्या उत्पन्न होती है - यह कंप्यूटर विज्ञान के सामान्य कार्यों में से एक है।
यूनिवर्सल टेक्स्ट एन्कोडिंग सिस्टम
यदि हम पाठ डेटा को एन्कोडिंग के लिए एक एकीकृत प्रणाली बनाने से जुड़े संगठनात्मक कठिनाइयों का विश्लेषण करते हैं, तो हम यह निष्कर्ष निकाल सकते हैं कि वे कोड (256) के एक सीमित सेट के कारण होते हैं। इसी समय, यह स्पष्ट है कि यदि, उदाहरण के लिए, आप वर्णों को आठ-बिट बाइनरी संख्याओं के साथ नहीं, बल्कि बड़ी संख्या में अंकों के साथ सांकेतिक शब्दों में बदलना करते हैं, तो संभव कोड मानों की सीमा बहुत बड़ी हो जाएगी। 16-बिट वर्ण एन्कोडिंग पर आधारित ऐसी प्रणाली को सार्वभौमिक - UNICODE कहा जाता था। सोलह अंक 65,536 विभिन्न वर्णों के लिए अद्वितीय कोड प्रदान करते हैं - यह क्षेत्र एक तालिका में ग्रह पर अधिकांश भाषाओं के पात्रों को रखने के लिए पर्याप्त है।
इस दृष्टिकोण की तुच्छ स्पष्टता के बावजूद, इस प्रणाली के लिए एक सरल यांत्रिक संक्रमण कंप्यूटर प्रौद्योगिकी के अपर्याप्त संसाधनों (UNICODE कोडिंग प्रणाली में, सभी पाठ दस्तावेज़ स्वचालित रूप से लंबे समय तक दो बार हो जाते हैं) के कारण लंबे समय तक वापस आयोजित किया गया था। 90 के दशक के उत्तरार्ध में, तकनीकी साधन संसाधन प्रावधान के आवश्यक स्तर पर पहुंच गए, और आज हम एक सार्वभौमिक कोडिंग प्रणाली के लिए दस्तावेजों और सॉफ्टवेयर का क्रमिक हस्तांतरण देख रहे हैं। अलग-अलग उपयोगकर्ताओं के लिए, इसने सॉफ्टवेयर के साथ अलग-अलग कोडिंग सिस्टम में निष्पादित दस्तावेजों के समन्वय की चिंताओं को और बढ़ा दिया है, लेकिन इसे संक्रमण काल \u200b\u200bकी कठिनाइयों के रूप में समझा जाना चाहिए।
ग्राफिक्स एनकोडिंग
यदि आप मैग्निफाइंग ग्लास का उपयोग करते हुए अखबार या पुस्तक में छपी एक ब्लैक-वाइट ग्राफिक छवि को देखते हैं, तो आप देख सकते हैं कि इसमें छोटे डॉट्स होते हैं, जो एक विशेषता पैटर्न बनाते हैं जिसे रैस्टर (चित्र 1.9) कहा जाता है।

अंजीर। 1.9। एक रेखापुंज ग्राफिक जानकारी एन्कोडिंग की एक विधि है,
लंबे समय से मुद्रण उद्योग में स्वीकार किए जाते हैं
चूंकि रेखीय निर्देशांक और प्रत्येक बिंदु (चमक) के व्यक्तिगत गुणों को पूर्णांक का उपयोग करके व्यक्त किया जा सकता है, यह कहा जा सकता है कि रेखीय कोडिंग बाइनरी कोड का उपयोग ग्राफिक डेटा का प्रतिनिधित्व करने की अनुमति देता है। वर्तमान में, यह आमतौर पर काले और सफेद चित्रों को भूरे रंग के 256 रंगों के साथ संयोजन के रूप में प्रस्तुत करने के लिए स्वीकार किया जाता है, और इस प्रकार, एक आठ-बिट बाइनरी संख्या आमतौर पर किसी भी बिंदु की चमक को एन्कोड करने के लिए पर्याप्त है।
रंगीन ग्राफिक छवियों को एनकोड करने के लिए, मुख्य घटकों में मनमाने रंग के अपघटन के सिद्धांत को लागू किया जाता है। तीन मुख्य रंगों का उपयोग ऐसे घटकों के रूप में किया जाता है: लाल (लाल, आर), हरा (हरा, जी) और नीला (नीला, बी)। व्यवहार में, यह माना जाता है (हालांकि सैद्धांतिक रूप से यह पूरी तरह सच नहीं है) कि मानव आंखों को दिखाई देने वाला कोई भी रंग इन तीन प्राथमिक रंगों को यांत्रिक रूप से मिलाकर प्राप्त किया जा सकता है। इस तरह के कोडिंग सिस्टम को प्राथमिक रंगों के नामों के पहले अक्षरों द्वारा आरजीबी सिस्टम कहा जाता है।
यदि हम प्रत्येक मुख्य घटक की चमक को एन्कोड करने के लिए 256 मान (आठ बाइनरी अंक) का उपयोग करते हैं, जैसा कि ग्रेस्केल ब्लैक-एंड-व्हाइट छवियों के लिए प्रथागत है, तो 24 बिट्स को एक बिंदु के रंग को एन्कोडिंग पर खर्च करना होगा। इसके अलावा, कोडिंग प्रणाली 16.5 मिलियन विभिन्न रंगों की एक अस्पष्ट परिभाषा प्रदान करती है, जो वास्तव में मानव आंख की संवेदनशीलता के करीब है। 24 बाइनरी बिट्स का उपयोग करके रंगीन ग्राफिक्स की प्रस्तुति के मोड को पूर्ण रंग (ट्रू कलर) कहा जाता है।
प्राथमिक रंगों में से प्रत्येक को एक अतिरिक्त रंग के साथ जोड़ा जा सकता है, अर्थात्, ऐसा रंग जो प्राथमिक रंग को सफेद रंग के लिए पूरक करता है। यह देखना आसान है कि किसी भी प्राथमिक रंग के लिए, अन्य प्राथमिक रंगों के एक जोड़े के योग से बनने वाला रंग पूरक होगा। तदनुसार, पूरक रंग हैं: सियान (सियान, सी), मैजेंटा (मैजेंटा, एम), और पीला (पीला, वाई)। घटक घटकों में एक मनमाना रंग के अपघटन के सिद्धांत को न केवल प्राथमिक रंगों पर लागू किया जा सकता है, बल्कि अतिरिक्त लोगों पर भी लागू किया जा सकता है, अर्थात, किसी भी रंग को सियान, मैजेंटा और पीले घटकों के योग के रूप में दर्शाया जा सकता है। रंग कोडिंग की इस पद्धति को मुद्रण उद्योग में स्वीकार किया जाता है, लेकिन चौथी स्याही का उपयोग मुद्रण उद्योग में भी किया जाता है - काला (काला, के)। इसलिए, इस कोडिंग सिस्टम को चार अक्षरों CMYK द्वारा इंगित किया जाता है (K अक्षर से काले रंग को निरूपित किया जाता है, क्योंकि अक्षर B पहले से ही नीले रंग से व्याप्त है), और इस प्रणाली में रंगीन ग्राफिक्स का प्रतिनिधित्व करने के लिए, आपके पास 32 बाइनरी अंक होना चाहिए। इस विधा को पूर्ण रंग (ट्रू कलर) भी कहा जाता है।
यदि आप प्रत्येक बिंदु के रंग को एनकोड करने के लिए उपयोग किए जाने वाले बिट्स की संख्या को कम करते हैं, तो आप डेटा की मात्रा को कम कर सकते हैं, लेकिन एन्कोडेड रंगों की सीमा काफी कम हो जाती है। 16-बिट बाइनरी संख्या वाले रंग ग्राफिक्स को एन्कोडिंग करना उच्च रंग मोड कहा जाता है।
जब आठ डेटा बिट्स का उपयोग करके रंग जानकारी एन्कोडिंग की जाती है, तो केवल 256 रंग टोन प्रसारित किए जा सकते हैं। कलर कोडिंग की इस विधि को इंडेक्स कहा जाता है। नाम का अर्थ यह है कि, चूंकि मानव आंखों के लिए उपलब्ध रंगों की पूरी श्रृंखला को व्यक्त करने के लिए 256 मान पूरी तरह से अपर्याप्त हैं, प्रत्येक रेखापुंज का कोड रंग को स्वयं व्यक्त नहीं करता है, लेकिन केवल एक पैलेट नामक लुक-अप तालिका में इसकी संख्या (सूचकांक) है। बेशक, इस पैलेट को ग्राफिक डेटा पर लागू किया जाना चाहिए - इसके बिना, आप किसी स्क्रीन या पेपर पर जानकारी को पुन: प्रस्तुत करने के तरीकों का उपयोग नहीं कर सकते (अर्थात, आप, बेशक, इसका उपयोग कर सकते हैं, लेकिन अधूरे डेटा के कारण, प्राप्त जानकारी पर्याप्त नहीं होगी: पेड़ों पर पत्ते लाल हो सकते हैं। और आकाश हरा है)।
ऑडियो एन्कोडिंग
ऑडियो जानकारी के साथ काम करने के लिए तकनीक और तरीके कंप्यूटर तकनीक में नवीनतम रूप में आए। इसके अलावा, संख्यात्मक, पाठ्य और ग्राफिक डेटा के विपरीत, ध्वनि रिकॉर्डिंग में समान रूप से लंबा और सत्यापित कोडिंग इतिहास नहीं था। नतीजतन, द्विआधारी कोड के साथ ऑडियो जानकारी एन्कोडिंग के तरीके मानकीकरण से दूर हैं। कई व्यक्तिगत कंपनियों ने अपने कॉर्पोरेट मानकों को विकसित किया है।
व्याख्यान संख्या 4।
बाइनरी डेटा एन्कोडिंग
विभिन्न प्रकार से संबंधित डेटा के साथ काम को स्वचालित करने के लिए, उनकी प्रस्तुति फॉर्म को एकजुट करना बहुत महत्वपूर्ण है। इसके लिए, आमतौर पर कोडिंग तकनीक का उपयोग किया जाता है, अर्थात्। एक प्रकार के डेटा की अभिव्यक्ति दूसरे प्रकार के डेटा के माध्यम से।
कोडिंग सिस्टम के उदाहरण: मानव भाषा, अक्षर (ग्राफिक अक्षरों का उपयोग करके एक भाषा कोडिंग), गणितीय अभिव्यक्ति लिखना, टेलीग्राफ मोर्स कोड, नेत्रहीनों के लिए ब्रेल कोड, समुद्री ध्वज वर्णमाला आदि।
कंप्यूटिंग में एक कोडिंग सिस्टम भी मौजूद है - इसे बाइनरी कोडिंग कहा जाता है और यह केवल दो वर्णों के अनुक्रम द्वारा डेटा की प्रस्तुति पर आधारित है: 0 और 1. इन वर्णों को द्विआधारी अंक या बिट्स कहा जाता है।
एक बिट दो अवधारणाओं को व्यक्त कर सकता है: 0 या 1 (हां या नहीं, काला या सफेद, सच्चा या गलत, आदि)। यदि आप बिट्स की संख्या दो तक बढ़ाते हैं, तो आप पहले से ही चार अलग-अलग अवधारणाओं को व्यक्त कर सकते हैं - 00 01 10 11. तीन बिट्स पहले से ही आठ अलग-अलग अवधारणाओं को एन्कोड कर सकते हैं - 000 001 010 100 101 101 101 111।
बाइनरी कोडिंग सिस्टम में बिट्स की संख्या को एक से बढ़ाकर, आप एन्कोड किए जा सकने वाले मानों की संख्या को दोगुना कर सकते हैं: एन=2 मैं जहाँ मैं - अंकों की संख्या एन - मूल्यों की संख्या।
कंप्यूटर संख्यात्मक, पाठ, ग्राफिक, ऑडियो और वीडियो डेटा को संसाधित कर सकता है। इन सभी प्रकार के डेटा को विद्युत दालों के अनुक्रम में एन्कोड किया गया है: एक नाड़ी (1) है, कोई नाड़ी (0), अर्थात। शून्य और लोगों के एक क्रम में। शून्य और लोगों के ऐसे तार्किक अनुक्रम को मशीन भाषा कहा जाता है।
संख्या प्रणाली
एक संख्या प्रणाली क्या है?
स्थितिगत और गैर-स्थितिगत संख्या प्रणाली हैं।
nepozitsionnyh सिस्टम, एक अंक का वजन (यानी, वह योगदान जो किसी संख्या के मूल्य पर करता है) संख्या के रिकॉर्ड में उसकी स्थिति पर निर्भर नहीं करता है। तो, रोमन अंक प्रणाली में, संख्या thirtyII (बत्तीस) में, किसी भी स्थिति में संख्या X का वजन केवल दस है।
अवस्था का संख्या प्रणाली, प्रत्येक अंक का वजन संख्या का प्रतिनिधित्व करने वाले अंकों के अनुक्रम में उसकी स्थिति (स्थिति) के आधार पर भिन्न होता है। उदाहरण के लिए, 757.7 के बीच, पहले सात का अर्थ है 7 सौ, दूसरा - 7 इकाइयाँ, और तीसरा - एक इकाई का 7 दसवां भाग।
संख्या 757.7 के बहुत अंकन का अर्थ है अभिव्यक्ति का संक्षिप्त संकेतन
700 + 50 + 7 + 0,7 = 7 10 2 + 5 10 1 + 7 10 0 + 7 10 -1 = 757,7.
किसी भी स्थिति संख्या प्रणाली को इसकी नींव की विशेषता है।
सिस्टम की नींव के लिए, आप कोई भी प्राकृतिक संख्या ले सकते हैं - दो, तीन, चार, आदि। नतीजतन, अनगिनत स्थितियां संभव हैं: बाइनरी, टर्नरी, चतुर्धातुक, आदि। आधार के साथ संख्या प्रणालियों में से प्रत्येक में संख्याएं लिखना क्ष संक्षिप्त संकेतन का अर्थ है
एक n-1 क्ष n-1 + क n-2 क्ष n-2 + ... + ए 1 क्ष 1 + क 0 क्ष 0 + क -1 क्ष -1 + ... + क -m क्ष -m ,
जहाँ एक मैं - संख्या प्रणाली के अंक; n और मीटर - क्रमशः पूर्णांक और भिन्नात्मक अंकों की संख्या।
कंप्यूटर के साथ संचार करने के लिए विशेषज्ञ कौन सी संख्या प्रणाली का उपयोग करते हैं?
दशमलव के अतिरिक्त, आधार वाले सिस्टम पूरे 2 की शक्ति, यानी:
बाइनरी (संख्या 0, 1 का उपयोग किया जाता है);
अष्टक (संख्या 0, 1, ..., 7 का उपयोग किया जाता है);
हेक्साडेसिमल (शून्य से नौ तक पहले पूर्णांकों के लिए, अंक 0, 1, ..., 9 का उपयोग किया जाता है, और अगले संख्याओं के लिए दस से पंद्रह तक, अंक ए, बी, सी, डी, ई, एफ का उपयोग किया जाता है)।
लोग दशमलव प्रणाली का उपयोग क्यों करते हैं और कंप्यूटर बाइनरी का उपयोग करते हैं?
लोग दशमलव प्रणाली को पसंद करते हैं, शायद इसलिए कि प्राचीन काल से वे उंगलियों पर गिने जाते थे, और लोगों के हाथों और पैरों पर दस उंगलियां होती हैं। हमेशा और हर जगह नहीं, लोग दशमलव संख्या प्रणाली का उपयोग करते हैं। चीन में, उदाहरण के लिए, लंबे समय तक वे पांच अंकों की संख्या प्रणाली का उपयोग करते थे।
और कंप्यूटर एक बाइनरी सिस्टम का उपयोग करते हैं क्योंकि इसमें अन्य प्रणालियों पर कई फायदे हैं:
इसके कार्यान्वयन के लिए, दो स्थिर राज्यों के साथ तकनीकी उपकरणों की आवश्यकता होती है (एक वर्तमान है - कोई वर्तमान, चुंबकित - चुंबकित नहीं है, आदि), और नहीं, उदाहरण के लिए, दस के साथ, जैसे दशमलव में;
केवल दो राज्यों के माध्यम से जानकारी की प्रस्तुति विश्वसनीय और शोर-प्रतिरक्षा है;
जानकारी के तार्किक परिवर्तनों को करने के लिए बूलियन बीजगणित के तंत्र का उपयोग करना संभव है;
बाइनरी अंकगणित दशमलव की तुलना में बहुत सरल है।
बाइनरी सिस्टम का नुकसान संख्याओं को लिखने के लिए आवश्यक बिट्स की संख्या में तेजी से वृद्धि है।
कंप्यूटर ऑक्टेल और हेक्साडेसिमल नोटेशन का उपयोग क्यों करते हैं?
एक बाइनरी सिस्टम जो कंप्यूटर के लिए सुविधाजनक है, इसकी वजह से मनुष्यों के लिए असुविधाजनक है बोझिल और असामान्य रिकॉर्ड.
दशमलव प्रणाली से बाइनरी और इसके विपरीत संख्याओं का रूपांतरण मशीन द्वारा किया जाता है। हालांकि, पेशेवर रूप से कंप्यूटर का उपयोग करने के लिए, किसी को शब्द मशीन को समझना सीखना चाहिए। इसके लिए, ऑक्टल और हेक्साडेसिमल सिस्टम विकसित किए जाते हैं।
इन प्रणालियों में संख्या लगभग दशमलव के रूप में आसानी से पढ़ी जाती है, तदनुसार की आवश्यकता होती है तीन पर (अष्ट) और चार पर (हेक्स) बाइनरी की तुलना में कम बिट्स (आखिरकार, संख्या 8 और 16, क्रमशः, संख्या 2 की तीसरी और चौथी डिग्री हैं)।
बाइनरी नंबर सिस्टम
कंप्यूटर विज्ञान में बाइनरी नंबर सिस्टम का विशेष महत्व इस तथ्य से निर्धारित होता है कि कंप्यूटर में किसी भी जानकारी का आंतरिक प्रतिनिधित्व द्विआधारी है, अर्थात। केवल दो वर्णों (0 और 1) के सेट द्वारा वर्णित है।
द्विआधारी रूपांतरण के लिए दशमलव
पूरे और भिन्नात्मक भागों का अलग-अलग अनुवाद किया जाता है। किसी संख्या के पूर्णांक भाग का अनुवाद करने के लिए, इसे संख्या प्रणाली 2 से विभाजित करना आवश्यक है और जब तक भागफल 0. के बराबर नहीं हो जाता है, तब तक भाग से भाग को विभाजित करना जारी रखता है। परिणामी अवशेषों का मान, रिवर्स ऑर्डर में लिया गया, वांछित बाइनरी नंबर बनाते हैं।
उदाहरण के लिए
25 (10) = 11001 (2)
आंशिक भाग का अनुवाद करने के लिए, इसे 2 से गुणा करें। काम का पूरा हिस्सा द्विआधारी प्रणाली में संख्या का पहला अंक होगा। फिर, परिणाम के भिन्नात्मक भाग को त्यागते हुए, हम फिर से 2 से गुणा करते हैं, आदि। इस मामले में अंतिम दशमलव अंश अच्छी तरह से एक अनंत (आवधिक) द्विआधारी बन सकता है।
उदाहरण के लिए
0.73 * 2 \u003d 1.46 (पूर्णांक भाग 1)
0.46 * 2 \u003d 0.92 (पूर्णांक भाग 0)
0.92 * 2 \u003d 1.84 (पूर्णांक भाग 1)
0.84 * 2 \u003d 1.68 (पूर्णांक भाग 1), आदि। 0.73 (10) \u003d 0.1011 ... (2)
बाइनरी नंबर के साथ अंकगणितीय संचालन
पर बाइनरी जोड़ 1 + 1 उच्च अंक में 1 का स्थानांतरण है, जैसा कि दशमलव अंकगणित में है। उदाहरण के लिए
पर बाइनरी घटाव यह याद रखना चाहिए कि निकटतम डिस्चार्ज 1 में कब्जा कर लिया गया है, कम से कम महत्वपूर्ण निर्वहन की दो इकाइयाँ देता है। यदि शून्य अगले उच्च अंकों में हैं, तो 1 कई अंकों में शामिल है। उसी समय, निकटतम महत्वपूर्ण उच्च क्रम में व्याप्त इकाई निचले क्रम की दो इकाइयाँ और सभी शून्य अंकों में इकाइयाँ, निचले और उच्चतम स्तर के बीच खड़ी होती है, जहाँ से इकाई ली गई थी।
197 से 174 घटाएं

बाइनरी डिवीजन गुणन और घटाव के द्विआधारी तालिकाओं का उपयोग करके होता है। 430 को 10 से भाग दें

ऑक्टल और हेक्साडेसिमल संकेतन
दशमलव से अष्टक में संख्याएँ परिवर्तित करना यह उसी तरह से उत्पन्न होता है जैसे बाइनरी में गुणन और विभाजन की सहायता से, लेकिन 2 से नहीं, बल्कि 8 से।
उदाहरण के लिए, 58.32 (10)
58: 8 \u003d 7 (2 बाएं)
7: 8 \u003d 0 (शेष में 7)
0,48 * 8 = 3,84, …
58,32 (10) = 72,243… (8)
दशमलव प्रणाली से हेक्साडेसिमल तक संख्याओं का रूपांतरण उसी तरह से किया जाता है। 567 (10) 0 \u003d 237 (16)
विभिन्न संख्या प्रणालियों में मिलान संख्या
|
दशमलव |
हेक्साडेसिमल |
अष्टभुजाकार |
बाइनरी |
एक पूर्णांक बाइनरी को ऑक्टल में बदलना इसे 3 अंकों के समूहों में बाएं से दाएं से बाएं में विभाजित करना आवश्यक है (सबसे बाएं समूह में तीन से कम द्विआधारी अंक हो सकते हैं), और फिर प्रत्येक समूह को अपने ऑक्टल समकक्ष को सौंपा जाना चाहिए। ऐसे समूह कहलाते हैं बाइनरी ट्रायड.
उदाहरण के लिए
11011001 = 11 011 001 = 331 (8)
बाइनरी पूर्णांक को हेक्साडेसिमल में बदलें इस संख्या को 4 अंकों के समूहों में तोड़कर बनाया गया है - बाइनरी व्यायाम किताबें.
1100011011001 \u003d 1 1000 1101 1001 \u003d 18D9 (16)
बाइनरी नंबरों के भिन्नात्मक भागों को एक अष्टा या हेक्साडेसिमल प्रणाली में अनुवाद करने के लिए, त्रैमासिक या टेट्रैड्स में एक समान विभाजन अल्पविराम से दाईं ओर (शून्य अंकों के साथ अंतिम अंकों में जोड़ा गया) किया जाता है।
0,1100011101 (2) = 0,110 001 110 100 = 0,6164 (8)
0.1100011101 (2) \u003d 0.1100 0111 0100 \u003d C74 (16)
बाइनरी में ऑक्टल (हेक्साडेसिमल) संख्याओं का रूपांतरण विपरीत तरीके से किया जाता है - प्रत्येक चरित्र को संबंधित ट्रिपल (चार) बाइनरी अंकों की संख्या के साथ मिलान करके।
A1F (16) \u003d 1010 0001 1111 (2)
127 (8) = 001 010 111 (2)
ऐसे परिवर्तनों की सादगी इस तथ्य के कारण है कि संख्या 8 और 16 संख्या 2 की पूर्णांक शक्तियां हैं। यह सादगी अष्टांगिक और हेक्साडेसिमल संख्या प्रणालियों की लोकप्रियता की व्याख्या करती है।
शिक्षकों के लिए वेबसाइटों की सूची (2)
दस्तावेज़पाम्स आर्काइव व्याख्यान के खगोल विज्ञान में ... कोडिंग, कोडिंग डेटा बाइनरी कोड, कोडिंग टेक्स्ट डेटा, प्रणाली एन्कोडिंग, कोडिंग ग्राफिक डेटा, कोडिंग ध्वनि की जानकारी। यूनिवर्सल सिस्टम एन्कोडिंग टेक्स्ट डेटा ...
विशेषता (तैयारी के क्षेत्र में) चलती वस्तुओं (विषय का नाम) के साथ संचार प्रणाली के विषय पर व्याख्यान नोट्स
व्याख्यान नोट... कोडिंग व्याख्यान 11. बचाव और सुधार के आधार कोड संक्षिप्त सारांश व्याख्यान: ... सूचना बिट्स k की संख्या, और के लिए बाइनरी कोड:। ऊपरी बाध्य ... ट्रांसमिशन विधि लागू एन्कोडिंग डेटाऑर्थोगोनल कहा जाता है ...
"इलेक्ट्रॉनिक औद्योगिक उपकरण" विषय पर व्याख्यान की सामग्री
दस्तावेज़... . कोडिंग जानकारी। मुख्य प्रकार कोड ................................................................. 19 व्याख्यान 6. ... इसकी रसीद डेटा उपभोक्ता; प्रासंगिकता ... बाइनरी कोड और इसका संशोधन सममित है बाइनरी कोड. बाइनरी कोड ...
डेटा एन्कोडिंग
बाइनरी डेटा एन्कोडिंग
विभिन्न प्रकारों से संबंधित डेटा के साथ काम को स्वचालित करने के लिए, उनकी प्रस्तुति फ़ॉर्म को एकजुट करना बहुत महत्वपूर्ण है - इसके लिए, आमतौर पर एक चाल का उपयोग किया जाता है एन्कोडिंग , वह है, एक प्रकार के डेटा की अभिव्यक्ति दूसरे प्रकार के डेटा के माध्यम से। प्राकृतिक मानव भाषाएं भाषण के माध्यम से विचारों को व्यक्त करने के लिए अवधारणाओं को संहिताबद्ध करने से ज्यादा कुछ नहीं हैं। भाषा एबीसी के निकट हैं (ग्राफिक प्रतीकों का उपयोग करते हुए भाषा घटकों के लिए कोडिंग सिस्टम)। इतिहास दिलचस्प जानता है, यद्यपि असफल, "सार्वभौमिक" भाषा और वर्णमाला बनाने का प्रयास करता है। जाहिरा तौर पर, उन्हें पेश करने के प्रयासों की विफलता इस तथ्य के कारण है कि राष्ट्रीय और सामाजिक संस्थाएं स्वाभाविक रूप से समझती हैं कि सार्वजनिक डेटा की कोडिंग प्रणाली में बदलाव से अनिवार्य रूप से सामाजिक तरीकों (यानी, कानूनी और नैतिक मानकों) में बदलाव होगा, और यह सामाजिक उथल-पुथल के कारण हो सकता है। ।
एक सार्वभौमिक कोडिंग टूल की एक ही समस्या प्रौद्योगिकी, विज्ञान और संस्कृति की व्यक्तिगत शाखाओं में काफी सफलतापूर्वक लागू होती है। उदाहरणों में गणितीय अभिव्यक्तियों की रिकॉर्डिंग के लिए एक प्रणाली, एक टेलीग्राफ वर्णमाला, एक समुद्री ध्वज वर्णमाला, अंधे के लिए एक ब्रेल प्रणाली और बहुत कुछ शामिल है,
एक कंप्यूटर प्रणाली भी मौजूद है - इसे बाइनरी कोडिंग कहा जाता है और यह केवल दो वर्णों के अनुक्रम द्वारा डेटा की प्रस्तुति पर आधारित है: 0 और 1. इन वर्णों को द्विआधारी अंक कहा जाता है, अंग्रेजी में - बिनै अंक या संक्षिप्त बिट (बिट)।
दो अवधारणाओं को एक बिट के साथ व्यक्त किया जा सकता है: 0 या 1 (हां या नहीं, काला या सफेद, सच्चा या गलत, आदि)। यदि बिट्स की संख्या दो तक बढ़ जाती है, तो चार अलग-अलग अवधारणाएं पहले ही व्यक्त की जा सकती हैं:
तीन बिट्स आठ विभिन्न अवधारणाओं को सांकेतिक कर सकते हैं:
000 001 010 011 100 101 110 111
यही है, बाइनरी कोडिंग सिस्टम में बिट्स की संख्या को एक से बढ़ाना, हम उन मूल्यों की संख्या को दोगुना करते हैं जो इस प्रणाली में व्यक्त किए जा सकते हैं। सामान्य सूत्र:
जहां एन स्वतंत्र एन्कोडेड मूल्यों की संख्या है;
m - इस प्रणाली में अपनाई गई कोडिंग।
प्रतिनिधित्व की एक बड़ी इकाई और साथ ही डेटा माप बाइट्स है।
8 बिट्स - 1 बाइट
1024 बाइट्स - 1 किलोबाइट (KB)
1,024 किलोबाइट - 1 मेगाबाइट (एमबी)
1024 मेगाबाइट - 1 गीगाबाइट (GB)
कंप्यूटर द्वारा संसाधित मुख्य प्रकार के डेटा:
पूर्णांक और वास्तविक संख्या।
पाठ डेटा।
ग्राफिक डेटा।
ध्वनि डेटा।
पूर्णांक और वास्तविक संख्या का कोडिंग
इंटिजर्स बाइनरी कोड के साथ काफी सरल रूप से एन्कोडेड हैं - बस एक पूर्णांक लें और इसे आधे में विभाजित करें जब तक कि भागफल एक के बराबर न हो। प्रत्येक भाग के अवशेषों का समूह, अंतिम भागफल के साथ दाईं से बाईं ओर लिखा गया, दशमलव संख्या का एक द्विआधारी एनालॉग बनाता है:
इस प्रकार, 19 10 \u003d 100112।
पूर्णांक को 0 से 255 तक एनकोड करने के लिए, बाइनरी कोड के 8 बिट्स (8 बिट्स) होना पर्याप्त है। सोलह बिट्स आपको पूर्णांक को ० से ६५,५३५ तक, और २४ बिट्स - १६.५ मिलियन से अधिक विभिन्न मूल्यों को एनकोड करने की अनुमति देते हैं।
80-बिट कोडिंग का उपयोग वास्तविक संख्याओं को एनकोड करने के लिए किया जाता है। इस स्थिति में, संख्या को सामान्य रूप में परिवर्तित कर दिया जाता है:
3,1415926=0,31415926*10 1
300 000 = 0,3*10 6
123 456 789 = 0,123456789*10 10
संख्या के पहले भाग को कहा जाता है अपूर्णांश और दूसरा - सुविधा । 80 बिट्स में से अधिकांश मंटिसा (संकेत के साथ) के भंडारण के लिए आरक्षित हैं और कुछ निश्चित संख्या में बिट्स विशेषताओं को संग्रहीत करने के लिए आवंटित किए गए हैं (संकेत के साथ भी)।
पाठ डेटा एन्कोडिंग
यदि वर्णमाला का प्रत्येक वर्ण एक विशिष्ट पूर्णांक (उदाहरण के लिए, एक सीरियल नंबर) के साथ जुड़ा हुआ है, तो बाइनरी कोड का उपयोग करके आप पाठ संबंधी जानकारी को भी एन्कोड कर सकते हैं। आठ बिट्स 256 विभिन्न वर्णों को एनकोड करने के लिए पर्याप्त हैं। यह आठ बिट्स के विभिन्न संयोजनों के साथ अंग्रेजी और रूसी भाषाओं के सभी वर्णों को व्यक्त करने के लिए पर्याप्त है, दोनों लोअरकेस और अपरकेस, साथ ही विराम चिह्न, बुनियादी अंकगणितीय संचालन के प्रतीक और कुछ आम तौर पर स्वीकृत विशेष वर्ण, उदाहरण के लिए "with"।
तकनीकी रूप से, यह बहुत सरल दिखता है, लेकिन संगठनात्मक कठिनाइयों में हमेशा काफी सुधार हुआ है। कंप्यूटर प्रौद्योगिकी के विकास के शुरुआती वर्षों में, वे आवश्यक मानकों की कमी से जुड़े थे, लेकिन आजकल वे इसके विपरीत, एक साथ संचालन और परस्पर विरोधी मानकों की प्रचुरता के कारण होते हैं। पूरी दुनिया के लिए एक ही तरह से पाठ डेटा को एनकोड करने के लिए, समान कोडिंग टेबल की आवश्यकता होती है, और यह अभी तक राष्ट्रीय वर्णमाला के पात्रों के बीच विरोधाभास के साथ-साथ एक कॉर्पोरेट प्रकृति के विरोधाभासों के कारण संभव नहीं है।
अंग्रेजी भाषा के लिए, जिसने संचार के अंतरराष्ट्रीय माध्यम के वास्तविक तथ्य पर कब्जा कर लिया है, विरोधाभासों को पहले ही हटा दिया गया है। अमेरिकन नेशनल स्टैंडर्ड इंस्टीट्यूट (ANSI) ने ASCII (अमेरिकन स्टैंडर्ड कोड फॉर इंफॉर्मेशन इंटरचेंज) कोडिंग सिस्टम की शुरुआत की। ASCII प्रणाली में, दो कोडिंग टेबल तय की जाती हैं - मूल और उन्नत। बेस टेबल 0 से 127 तक के कोड के मूल्यों को ठीक करता है, और विस्तारित संख्या 128 से 255 तक की संख्या वाले वर्णों को संदर्भित करता है।
आधार तालिका के पहले 32 कोड, जो शून्य से शुरू होते हैं, हार्डवेयर निर्माताओं (मुख्य रूप से कंप्यूटर और प्रिंटिंग डिवाइस के निर्माता) को दिए जाते हैं। इस क्षेत्र में, तथाकथित नियंत्रण कोड रखे जाते हैं, जो किसी भी भाषा वर्ण के अनुरूप नहीं होते हैं, और तदनुसार, ये कोड स्क्रीन पर या प्रिंटिंग डिवाइस पर प्रदर्शित नहीं होते हैं, लेकिन वे यह नियंत्रित कर सकते हैं कि अन्य डेटा आउटपुट कैसे है।
कोड 32 से शुरू होकर कोड 127 तक, अंग्रेजी वर्णमाला वर्ण, विराम चिह्न, संख्या, अंकगणितीय संचालन और कुछ सहायक वर्णों के कोड रखे गए हैं। बुनियादी ASCII एन्कोडिंग तालिका 1.1 में दिखाया गया है:
|
तालिका 1.1। |
बेस एन्कोडिंग तालिकाASCIIASCII |
||||||||||
|
32 दल |
|||||||||||
|
44 , |
|||||||||||
|
दस्तावेज़ व्याख्यान संख्या 4। कोडिंग डेटा बाइनरी कोड के साथ काम को स्वचालित करने के लिए डेटाविभिन्न प्रकार से संबंधित बहुत महत्वपूर्ण है ... आमतौर पर तकनीक का उपयोग करें एन्कोडिंग, यानी। अभिव्यक्ति डेटा एक प्रकार के माध्यम से डेटा एक अन्य प्रकार। उदाहरण ... यह निर्माण (निर्देश / निर्देश) लगातार अपडेट और संपादित किया जाएगा। आप अपनी इच्छाओं, सिफारिशों, विवरणों, टिप्पणियों को मंच पर छोड़ सकते हैं या मुझसे संपर्क फ़ॉर्म के माध्यम से संपर्क कर सकते हैं।निर्देश मैनुअलअधिकांश लोगों की सुनवाई। विधि कहा जाता है कोडिंग धारणा। उसी समय ... आपको एक, बाद में प्राप्त करने की आवश्यकता है एन्कोडिंग. मेनू आइटम पॉपअप विंडो का कारण बनता है ... - फिर यह एक पुनर्प्राप्ति योजना है डेटा से कोडित जिस तरह से वे प्रेषित कर रहे हैं ... इस अध्ययन गाइड में उच्च शिक्षा प्रणाली में विशेषज्ञों के प्रशिक्षण के लिए आवश्यक कंप्यूटर विज्ञान का पूरा पाठ्यक्रम है। विषयगत संरचनाअमूर्तआवश्यक जानकारी। 1.3। प्रस्तुत करना ( कोडिंग) डेटा 1.3.1। नंबर सिस्टम विभिन्न हैं ... जानकारी 6 1.1.4। सूचना प्रक्रिया 9 1.3। प्रस्तुत करना ( कोडिंग) डेटा १० १.३.१ संख्या प्रणाली 10 1.3.2। प्रस्तुत ... शारीरिक कोडिंगदस्तावेज़... कोडिंग और तार्किक कोडिंग एक प्रणाली बनाएं एन्कोडिंग निम्नतम स्तर। प्रणाली एन्कोडिंग प्रणाली एन्कोडिंग डेटा ... सबसे अधिक इस्तेमाल किया सिस्टम एन्कोडिंग: एनआरजेड (गैर ... 1. कोडिंग जानकारी की अवधारणा। जानकारी की असतत (डिजिटल) प्रस्तुति की सार्वभौमिकता। स्थिति और गैर-स्थितिगत संख्या प्रणाली। एल्गोरिदमदस्तावेज़महत्व के कारण इस का यह एक विशेष नाम है प्रक्रिया - कोडिंग जानकारी। कोडिंग जानकारी असाधारण है ... असतत तरीकों के कुछ उदाहरण दें एन्कोडिंग डेटा: ग्रंथ, ग्राफिक्स, ध्वनि। बचाने के लिए ... | |||||||||||
डेटा के साथ काम को स्वचालित करने के लिए कंप्यूटिंग नामक विशेष प्रकार के उपकरणों का उपयोग करें
पीसी एक सार्वभौमिक तकनीकी प्रणाली है, इसके विन्यास को आवश्यकतानुसार लचीले ढंग से बदला जा सकता है
7. पीसी परिधीय
इस समस्या का समाधान ओसी मॉडल (ओपन सिस्टम इंटरकनेक्शन) पर आधारित है
इंटरनेट एक इंटरकनेक्ट है जो समर्थन (maagistral) नेटवर्क के इंटरकनेक्शन का प्रतिनिधित्व करता है
हाइपरटेक्स्ट सूचना विनिमय प्रोटोकॉल
12 एल्गोरिथ्म की अवधारणा
13. ऑब्जेक्ट ओरिएंटेड प्रोग्रामिंग। 13 वस्तु उन्मुख दृष्टिकोण
§ 2 डेटा और सूचना एन्कोडिंग
डेटा सूचना का द्वंद्वात्मक घटक है। वे पंजीकृत संकेत हैं।
इस मामले में, किसी के द्वारा एम / बी रिकॉर्ड करने की भौतिक विधि (भौतिक निकायों या सतह के मापदंडों को स्थानांतरित करना, विद्युत, चुंबकीय या ऑप्टिकल विशेषताओं, रासायनिक संरचना, आदि को बदलना)
पंजीकरण विधि के अनुसार, डेटा को विभिन्न प्रकार के मीडिया पर संग्रहीत और परिवहन किया जा सकता है।
यह ध्यान में रखा जाना चाहिए कि जानकारी के गुण इसके वाहक के गुणों से निकटता से संबंधित हैं।
औसत उपभोक्ता के लिए, पुस्तक में जानकारी की उपलब्धता सीडी पर समान जानकारी की तुलना में अधिक है, क्योंकि सभी के पास ये उपकरण नहीं हैं।
डेटा संचालन
सूचना प्रक्रिया के दौरान, डेटा को एक तरीके से दूसरे तरीके में परिवर्तित किया जाता है।
डेटा प्रोसेसिंग में कई अलग-अलग ऑपरेशन शामिल हैं, जिनमें से निम्नलिखित को प्रतिष्ठित किया जा सकता है:
डेटा संग्रह - निर्णय लेने के लिए पर्याप्त सुनिश्चित करने के लिए जानकारी का संचय
डेटा का औपचारिककरण विभिन्न स्रोतों से एक ही रूप में आने वाले डेटा की कमी है ताकि उन्हें एक दूसरे के साथ तुलनीय बनाया जा सके, अर्थात, उनकी पहुंच के स्तर को बढ़ाया जा सके।
डेटा फ़िल्टरिंग - अनावश्यक डेटा को फ़िल्टर करना जो निर्णय लेने के लिए आवश्यक नहीं है; यह शोर के स्तर को कम करना चाहिए, और डेटा की विश्वसनीयता और पर्याप्तता बढ़नी चाहिए।
डेटा सॉर्ट करना - उपयोग में आसानी के उद्देश्य के लिए दिए गए विशेषता के अनुसार डेटा ऑर्डर करना, जो जानकारी की विश्वसनीयता को बढ़ाता है
डेटा संग्रह - एक सुविधाजनक और सुलभ रूप में डेटा भंडारण का आयोजन, डेटा भंडारण की आर्थिक लागत को कम करने का कार्य करता है और सूचना प्रक्रिया की समग्र विश्वसनीयता को बढ़ाता है।
डेटा सुरक्षा - डेटा की हानि, प्रजनन और संशोधन प्रदान करने के उद्देश्य से उपायों का एक सेट
डेटा परिवहन - सूचना प्रक्रिया के दूरस्थ प्रतिभागियों के बीच डेटा प्राप्त करना और संचारित करना; डेटा स्रोत को आमतौर पर सर्वर कहा जाता है, और उपभोक्ता को क्लाइंट कहा जाता है
डेटा रूपांतरण - डेटा को एक रूप से दूसरे में या एक संरचना से दूसरे में स्थानांतरित करना
बाइनरी डेटा एन्कोडिंग
………………………………………………………………………………
विभिन्न प्रकारों से संबंधित, उनकी प्रस्तुति फ़ॉर्म को एकजुट करना बहुत महत्वपूर्ण है।
इसके लिए, आमतौर पर एन्कोडिंग तकनीक का उपयोग किया जाता है, अर्थात, एक प्रकार के डेटा की अभिव्यक्ति दूसरे प्रकार के डेटा के माध्यम से। उदाहरण गणितीय अभिव्यक्तियों की रिकॉर्डिंग के लिए एक प्रणाली, एक टेलीग्राफिक वर्णमाला, अंधे के लिए एक ब्रेल प्रणाली, एक समुद्री ध्वज वर्णमाला, आदि शामिल हैं।
एक कंप्यूटर प्रणाली भी मौजूद है - इसे बाइनरी कोडिंग कहा जाता है और यह केवल दो वर्णों 0 और 1 के अनुक्रम द्वारा डेटा की प्रस्तुति पर आधारित है।
इन वर्णों को बाइनरी अंक (अंग्रेजी बाइनरी अंक में) या संक्षिप्त 1 बिट कहा जाता है।
एक बिट एम / बी दो अवधारणाओं को व्यक्त करता है: 0 या 1, हां या नहीं, काला या सफेद, सच्चा या गलत और। घ।
यदि बिट्स की संख्या 2 तक बढ़ जाती है, तो चार अलग-अलग अवधारणाएं पहले से ही व्यक्त की जा सकती हैं।
आठ अलग-अलग मूल्यों को तीन बिट्स के साथ एन्कोड किया जा सकता है: 000 001 010 011 100 101 110 111
बाइनरी कोडिंग सिस्टम में बिट्स की संख्या को एक से बढ़ाकर, इस सिस्टम में 2 गुना बढ़े हुए मानों की संख्या बढ़ जाती है, सामान्य फॉर्मूला होता है:
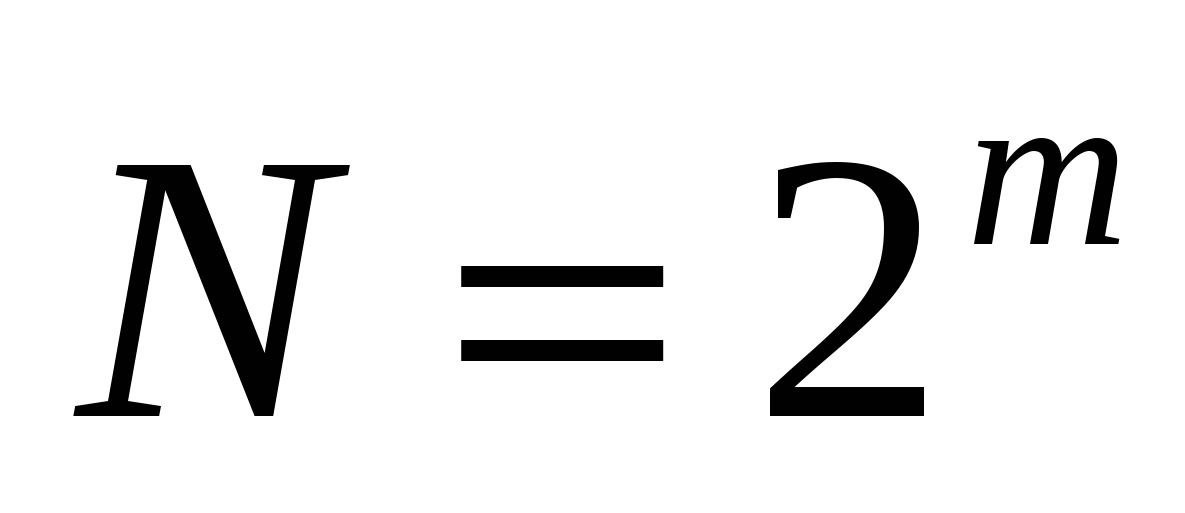
जहां N स्वतंत्र एन्कोडेड मूल्यों की संख्या है
एम - बिट कोडिंग को इस प्रणाली में अपनाया गया
पूर्णांक और वास्तविक संख्या का कोडिंग
पूर्णांक बाइनरी में एन्कोड किए गए हैं, निम्नानुसार: एक पूर्णांक लिया जाता है और तब तक आधा किया जाता है जब तक कि शेष में शून्य या एक का गठन नहीं किया जाता है।
अंतिम शेष के साथ दाईं से बाईं ओर लिखे प्रत्येक विभाजन के अवशेषों का सेट दशमलव संख्या का एक द्विआधारी एनालॉग बनाता है
यानी 19 10 \u003d 10011 2
पूर्णांक को 0 से 255 तक एनकोड करने के लिए, बाइनरी कोड के 8 बिट्स (8 बिट्स) होना पर्याप्त है
16 बिट्स आपको पूर्णांक को 0 से 65535 तक एनकोड करने की अनुमति देते हैं
24 बिट्स - 16.5 मिलियन से अधिक विभिन्न मूल्य।
80-बिट कोडिंग का उपयोग वास्तविक संख्याओं को एनकोड करने के लिए किया जाता है।
इस स्थिति में, संख्या पूर्व निर्धारित रूप से सामान्यीकृत रूप में परिवर्तित हो जाती है:
3,1415926 = 0,31415926 * 10 1
300000 = 0,3 * 10 6
123456789 = 0,123456789 * 10 10
संख्या का पहला भाग कहा जाता है ,,,, - विशेषता। Issa० बिट्स में से अधिकांश में एक संकेत के साथ एक जगह में मंटिसा को संचय करने के लिए आरक्षित किया जाता है, और कुछ पात्रों की विशेषताओं को संग्रहीत करने के लिए बिट्स की कुछ ऊन संख्या आरक्षित होती है।
पाठ डेटा एन्कोडिंग
यदि वर्णमाला का प्रत्येक प्रतीक एक विशिष्ट पूर्णांक (सीरियल नंबर) से जुड़ा है, तो बाइनरी कोड का उपयोग करके आप पाठ जानकारी को एन्कोड कर सकते हैं। आठ द्विआधारी अक्षर 256 विभिन्न वर्णों को एनकोड करने के लिए। अंग्रेजी के लिए, यूनाइटेड स्टेट्स इंस्टीट्यूट फॉर स्टैंडर्डाइजेशन (ANSI) ने अमेरिकन स्टैंडर्ड कोड फॉर इंफॉर्मेशन इंटरचेंज (ASCII), यूनाइटेड स्टेट्स स्टैंडर्ड इंफॉर्मेशन एक्सचेंज कोड की शुरुआत की।
ASCII प्रणाली में दो ........ एन्कोडिंग - मूल और उन्नत। बेस टेबल 0 से 127 तक के कोड के मान को ठीक करता है, और विस्तारित संख्या 128 से 255 तक की संख्या वाले वर्णों को संदर्भित करता है।
बेस टेबल के पहले 32 कोड हार्डवेयर निर्माताओं को दिए गए हैं। इस क्षेत्र में स्थित हैं d। एक। नियंत्रण कोड जो किसी भी भाषा वर्णों से मेल नहीं खाते हैं।
ये कोड प्रदर्शित नहीं होते हैं, या तो स्क्रीन पर या प्रिंट डिवाइस पर प्रदर्शित नहीं होते हैं, लेकिन ये नियंत्रित करते हैं कि अन्य डेटा आउटपुट कैसे हैं।
ASCII के अलावा, ऐसे एन्कोडिंग हैं जैसे कि Kona - 8 (सूचना विनिमय कोड, 8-अंक), विंडोज एन्कोडिंग, आईएसओ एनकोडिंग, UNICODE, GOST - वैकल्पिक एन्कोडिंग।
ग्राफिक्स एनकोडिंग
यदि आप किसी समाचार पत्र या पुस्तक में छपी बी / डब्ल्यू ग्राफिक छवियों को बढ़ाते हैं, तो आप देख सकते हैं कि इसमें छोटे डॉट्स होते हैं, जो एक रेखापुंज नामक एक विशेषता पैटर्न बनाते हैं।
चूंकि प्रत्येक बिंदु के रैखिक निर्देशांक और रंग को पूर्णांक का उपयोग करके व्यक्त किया जा सकता है, इसलिए यह कहा जा सकता है कि रेखांकन कोडिंग ग्राफिक डेटा को दर्शाने के लिए बाइनरी कोड का उपयोग करता है।
रंगीन चित्रों को एनकोड करने के लिए, मुख्य घटकों में मनमाने रंग के अपघटन के सिद्धांत को लागू किया जाता है।
इस तरह के घटक 3 प्राथमिक रंगों का उपयोग करते हैं:
लाल (लाल, आर)
हरा (हरा, जी)
नीला (नीला, बी)
इस तरह के कोडिंग सिस्टम को रंग नामों के पहले अक्षरों द्वारा एक RGB सिस्टम कहा जाता है।
16-बिट बाइनरी संख्या वाले रंग ग्राफिक्स को एन्कोडिंग करना उच्च रंग मोड कहा जाता है। और 24 बाइनरी अंकों का उपयोग करके रंगीन ग्राफिक्स का प्रतिनिधित्व करने वाले मोड को पूर्ण-रंग (.............) कहा जाता है।

