17.07.2019
ASCII kodunun şifresini çözme. ASCII kodlaması
Konuyla ilgili bağımsız çalışma için materyaller Dersler 2
ASCII Kod Tablosu (ASCII - Bilgi Alışverişi için Amerikan Standart Kodu).
Toplamda, ASCII kodlama tablosu (Şekil 1) kullanılarak 256 farklı karakter kodlanabilir. Bu tablo iki bölüme ayrılmıştır: ana (OOh ila 7Fh kodları ile) ve ek (80h ila FFh arasında, burada h harfi kodun onaltılık sayı sistemine ait olduğunu gösterir).
Resim 1
Tablodan bir karakteri kodlamak için 8 bit (1 bayt) ayrılır. İşlem yaparken metin bilgisi bir bayt bazı karakterlerin kodunu içerebilir - harfler, sayılar, noktalama işaretleri, eylem işaretleri vb. Her karakterin bir tamsayı şeklinde kendi kodu vardır. Bu durumda, tüm kodlar kodlama adı verilen özel tablolarda toplanır. Onların yardımı ile, sembol kodu monitör ekranındaki görünür gösterimine dönüştürülür. Sonuç olarak, bilgisayar belleğindeki herhangi bir metin, karakter kodlarına sahip bir bayt dizisi olarak temsil edilir.
Örneğin, merhaba kelimesi! aşağıdaki gibi kodlanacaktır (tablo 1).
Tablo 1
Şekil 1, standart (İngilizce) ve gelişmiş (Rusça) ASCII kodlamasına dahil edilen karakterleri göstermektedir.
ASCII tablosunun ilk yarısı standartlaştırılmıştır. Kontrol kodları içerir (00h - 20h ve 77h arası). Bu kodlar metin öğelerine uygulanmadığı için tablodan kaldırılır. Noktalama işaretleri ve matematiksel işaretler de buraya yerleştirilir: 2lh - !, 26h - &, 28h - (, 2Bh - +, ..., büyük ve küçük Latin harfleri: 41h - A, 61h - a.
Tablonun ikinci yarısı, ulusal yazı tiplerini, tabloların oluşturulabileceği sahte sembolleri, özel matematiksel karakterleri içerir. Kodlama tablosunun alt kısmı uygun sürücüler - kontrol yardımcı programları kullanılarak değiştirilebilir. Bu teknik, çeşitli yazı tiplerini ve kulaklıklarını kullanmanızı sağlar.
Her sembol kodunun ekranı, yalnızca dijital bir kod değil, aynı zamanda ilgili resmin de olduğu için sembolün görüntüsünü göstermelidir, çünkü her sembolün kendi şekli vardır. Her sembolün şeklinin açıklaması özel bir ekran belleği - karakter üretecinde saklanır. Bir sembol, bir IBM PC görüntü ekranında, örneğin bir sembol matrisi oluşturan noktalar aracılığıyla görüntülenir. Böyle bir matristeki her piksel bir görüntü öğesidir ve parlak veya karanlık olabilir. Koyu nokta 0 sayısı, açık (parlak) - ile kodlanır. 1. Koyu pikselleri karakterin matris alanında bir nokta olarak ve açık renkli yıldız işaretli bir nokta olarak görüntülerseniz, karakterin şeklini grafik olarak gösterebilirsiniz.
Farklı ülkelerdeki insanlar anadillerinin kelimelerini yazmak için karakterler kullanırlar. Günümüzde, e-posta sistemleri ve web tarayıcıları da dahil olmak üzere çoğu uygulama tamamen 8 bittir, yani ISO-8859-1 standardına göre sadece 8 bit karakterleri gösterebilir ve doğru bir şekilde kabul edebilirler.
Dünyada (Kiril, Arapça, Çince, Japonca, Korece ve Tay dili dillerinde) 256'dan fazla karakter var ve daha fazla yeni karakter ortaya çıkıyor. Bu da birçok kullanıcı için aşağıdaki alanları oluşturur:
Aynı belgedeki farklı karakter kümelerinden karakterler kullanmak mümkün değildir. Her metin belgesi kendi kodlama kümesini kullandığından, otomatik metin tanımada büyük zorluklar vardır.
Yeni karakterler ortaya çıkıyor (örneğin: Euro), bunun sonucunda ISO, ISO-8859-1 standardına çok benzeyen yeni bir ISO-8859-15 standardı geliştiriyor. Fark şu şekildedir: eski ISO-8859-1 standardının kodlama tablosundan, yeni kullanılmayan sembollere (Euro gibi) yer açmak için şu anda kullanılmayan eski para birimlerinin sembolleri kaldırıldı. Sonuç olarak, kullanıcılar disklerde aynı belgelere sahip olabilirler, ancak farklı kodlamalarda. Bu sorunların çözümü, tek bir uluslararası kodlama dizisinin benimsenmesidir. evrensel kodlama veya unicode.
ASCII'nin oluşumu sırasında, teletiplerde ve daktilolarda bulunan kontrol karakterleri kodlamanın başlangıcına dahil edildi ve 21. yüzyılda pratik olarak kullanılmasalar da zamanla orada sıkıca öldüler.
ASCII kodlaması hakkında ayrıntılı bilgi veririm:
ASCII (İng. birmerican standard ciçin bennformation bennterchange, [ˈæs.ki]) - sayısal kodların bazı yaygın basılı ve basılmamış karakterlerle ilişkilendirildiği tablonun adı (kodlama, küme). Tablo 1963'te ABD'de geliştirilmiş ve standartlaştırılmıştır. Rusçada "ASCII" adı genellikle [ sor ve].
ASCII tablosu karakterler için kodlar tanımlar:
- ondalık basamak;
- latin alfabesi;
- ulusal alfabe;
- noktalama işaretleri;
- kontrol karakterleri.
Hikaye
Başlangıçta (1963), kodları 7 bit (128 karakter; 27 \u003d 128) içine yerleştirilen karakterleri kodlamak için ASCII geliştirilirken, veri aktarımı sırasında meydana gelen hataları kontrol etmek için en önemli 7. bit (sıfırdan numaralandırma) kullanılmıştır.
Zamanla kodlama 256 karaktere genişletildi (28 \u003d 256); ilk 128 karakterin kodları değişmedi. ASCII, 8 bit kodlamanın yarısı olarak algılanmaya başladı ve “genişletilmiş ASCII”, 8. bitle birlikte ASCII olarak adlandırıldı (örneğin, KOI-8).
Karakter yer paylaşımı
Geri (BS) karakterini kullanarak (bir karakter döndürerek) yazıcının üstüne bir karakter yazdırabilirsiniz. ASCII'de harflere aynı şekilde aksan işaretleri ekleyebilirsiniz, örneğin:
- a BS ‘→ á
- a BS `→ à
- a BS ^ → â
- o BS / → ø
- c BS, → ç
- n BS ~ → ñ
düşünce: eski yazı tiplerinde, kesme işareti “» ”sola eğimli olarak çizildi (“ `” ve “´” ile karşılaştır) ve “~” işareti kaydırıldı (“~” ve “˜” ile karşılaştırıldı), böylece sadece role uyuyorlar karakterler “´” ve “üstte tilde” dir.
Aynı karakteri aynı konumda iki kez yazdırırsanız, kalın bir karakter alırsınız. Bir karakteri bir konuma yazdırır ve sonra “_” ın altını çizerseniz, altı çizili bir karakter elde edilir.
- a BS a → bir
- a BS _ → a
Bu teknik, örneğin insan yardım sisteminde hala kullanılmaktadır.
Ulusal ASCII Seçenekleri
ISO 646 standardı (ECMA-6), ulusal karakterlerin ASCII'ye yerleştirilmesine izin verir. Bunun için "@", "[", "\\", "]", "^", "` "," ("," Dikey çubuk ",") "," ~ "karakterlerinin değiştirilmesi önerilir. Ayrıca, pound sembolü “£”, “#” pound işareti yerine, “$” para birimi işareti de “$” dolar simgesi yerine yerleştirilebilir. Böyle bir sistem Latin dilleri ve sadece birkaç ek karakter kullandıkları için Avrupa dilleri için çok uygundur. Ulusal karakterler içermeyen bir ASCII varyantına "US-ASCII" veya "uluslararası referans sürümü" denir.
Latince olmayan komut dosyaları olan bazı dillerde (Rusça, Yunanca, Arapça, İbranice) ASCII'nin daha radikal modifikasyonları vardı. Bu değişikliklerden birinde, küçük Latin harfleri yerine ulusal semboller yerleştirildi (Rus ve Yunan büyük harfleri için). Bir başka değişiklik, US-ASCII ve ulusal versiyon arasında geçiş; anahtarlama "anında" - SO (Eng. shift out) ve SI (İngilizce shift benn); bu durumda, ulusal versiyonda, Latin harflerini tamamen ulusal sembollerle değiştirmek mümkün oldu. Ayrıca bakınız: KOI-7.
Daha sonra, kod tablosunun alt yarısının (0‑127) US-ASCII karakterleri tarafından işgal edildiği ve üst yarının (128‑255) bir dizi ulusal karakter de dahil olmak üzere ek karakterler tarafından işgal edildiği 8 bit kodlamaların (kod sayfaları) kullanılması daha uygun hale geldi.
Bu nedenle, Unicode'un yaygın olarak benimsenmesinden önce ASCII tablosunun üst yarısı, yerelleştirilmiş karakterleri, yerel dilin harflerini temsil etmek için aktif olarak kullanıldı.
Kiril karakterlerini ASCII tablosuna yerleştirmek için tek bir standardın bulunmaması birçok kodlama sorununa neden olmuştur (KOI-8, Windows-1251, vb.). Latince olmayan komut dosyalarına sahip diğer diller de birkaç farklı kodlamanın varlığı nedeniyle acı çekti.
Unicode standardının ilk 128 karakteri karşılık gelen US-ASCII karakterleriyle eşleşir.
ASCII tablosu
.0 .1 .2 .3 .4 .5 .6 .7 .8 .9 .A .B .C .D .E .F 0. NUL SOH STX ETX EOT ENQ ACK BEL BS HT LF VT FF CR SO SI 1. DLE DC1 DC2 DC3 DC4 NAK SYN ETB CAN EM ALT ESC FS GS RS Amerika 2. ! « # $ % & ‘ ( ) * + , - . / 3. 0 1 2 3 4 5 6 7 8 9 : ; < = > ? 4. @ bir B C D E F G, 'H ben J K L M N- Ey 5. P S R, S T U V W X Y Z [ \ ] ^ _ 6. ` bir b c d e f g h ben j k l m n o 7. p q r s t u v w x y z { | } ~ DEL ASCII standardının (1963) ilk versiyonunda, “yukarı ok” ve “sol ok” sembolleri sırasıyla 0x5e (94) ve 0x5f (95) konumlarına yerleştirildi. ECMA-6 standardı (1965), bunları sırasıyla bir ekleme karakteriyle (sirkumfleks sembolü “^” olarak da kullanılır) ve alt çizgi sembolü “_” ile değiştirdi.
Kontrol karakterleri
ASCII tablosu, teletype bilgisini alıp vermek için oluşturulmuştur. Set, teletype cihazını kontrol etmek için komut olarak kullanılan yazdırılamayan karakterler içeriyordu. Benzer komutlar, cihazın özelliklerini dikkate alarak diğer bilgisayar öncesi mesajlaşma araçlarında (Mors kodu, semafor alfabesi) kullanıldı.
- NUL, 00 - boş, boş. Boş karakter her zaman yoksayılır. Delikli bantlarda, “1” sayısı bir delik ile ve “0” sayısı da bir delik olmaması ile belirtilmiştir. Bilginin kaydedilmediği delikli bant bölümleri delik içermiyordu, yani boş karakterler içeriyordu; bu tür siteler kasetin başında ve sonunda yer alıyordu. Null karakteri hala birçok programlama dilinde satır sonunun işareti olarak kullanılır ve "\\ 0" ile gösterilir. ("String" terimi bir karakter dizisini ifade eder.) Bazı işletim sistemlerinde , herhangi bir metin dosyasının son karakteridir.
İletişim kanalı üzerinden iletilen mesajlar iki bölüme ayrıldı:
- "Üst";
- "Metin".
“Üstbilgi”, gönderenin ve alıcının adreslerini, sağlama toplamını vb. İçerdi, “metin” ten önce veya sonra yerleştirilebilir. "Metin" terimi, mesajın yazdırmaya yönelik kısmıdır.
- SOH, 01 - start of heading, "başlık" başlangıcı.
- STX, 02 - start te xt, "metnin" başlangıcı. Sembol, teletype yazıcıyı açmak için bir komut olarak kullanılmıştır. Yazdırma metni STX ve ETX karakterleri arasındaydı.
- ETX, 03 - end te xt, "metnin" sonu. Sembol, teletype yazdırma aygıtını kapatmak için kullanıldı. Günümüzde, kod 03 bir işleme SIGINT sinyali göndermek için kullanılır. signal intpatlarım) ve Ctrl + C tuş bileşimine basılarak gönderilebilir. Böyle bir sinyal aldıktan sonra, süreç işi tamamlamalıdır.
- EOT, 04 - end of taktarım, transfer sonu. Sembol, "dosya sonu" anlamına gelen terminal öykünücüler tarafından kullanılır (EOF, eng. end of file) ve Ctrl + D tuş bileşimine basılarak gönderilebilir. Böyle bir karakteri aldıktan sonra, terminal öykünücüsü şu anda terminalle çalışan işlemi belirleyecek ve standart giriş akışı (stdin, eng. standar d içindeyayın yapmak) ekleyin. Sonuç olarak, işlem stdin okumayı durduracak ve okunan verileri işlemeye başlayacaktır.
- ENQ, 05 - enquire. "Onay istiyorum."
- ACK, 06 - acknowledgement. “Onaylıyorum.” NAK sembolü bunun tersi anlamına gelir - "Onaylamıyorum".
- BEL, 07 - belarama, bip sesi. Sembol genellikle “\\ a” olarak adlandırılır ve alarm çalmak için kullanılır. Modern bir bilgisayarda, ses dahili hoparlör tarafından üretilir. Örneğin, aşağıdaki komutlar ses çalabilir: echo -e “\\ a” veya echo -e “\\ 007 ″ (bash); echo ^ G (cmd.exe; ^ G girmek için Ctrl + G tuşlarına basın, printf ("\\ a"); (programlama dilinde kod C).
- BS, 08 - back shız, bir karakter dönüş. ← Geri tuşu önceki karakteri siler.
- TAB, 09 - tab, yatay sekme. "\\ T" olarak belirtilir. Bazen İngilizce'den HT denir. horizontal tabulation.
- LF, 0A - line feed, satır besleme. Taşıyıcıyı bir satır aşağı indirme komutu. Karakter, UNIX'te bir metin dosyasının satırının sonunu işaretlemek için kullanılır. CR LF karakter dizisi, Windows'ta bir metin dosyasının satırının sonunu gösterir. Birçok programlama dilinde sembol "\\ n" olarak belirtilir. Metin çıktısı alırken ↵ Enter tuşuna basmak satır beslemeye yol açar.
- VT, 0B - vertical tab, dikey sekme.
- FF, 0C - form feed, sayfa çalıştırma, yeni sayfa. Yazıcı komutu: yazdırmaya sonraki sayfanın başından devam edin.
- CR, 0D - carriage return, satır başı. Yazıcı komutu: geçerli satırın başlangıcından itibaren yazdırmaya devam edin (yeni bir satırdan değil). Birçok programlama dilinde, CR sembolü "\\ r" olarak belirtilir. Mac OS'de, CR karakteri bir metin dosyasındaki satırın sonunu gösterir. Klavyeden CR sembolü Ctrl + M tuş bileşimine basılarak girilebilir.
- SO, 0E - shift out, başka bir kasete geçin. Başka bir bant genellikle kırmızıya boyandı. Daha sonra, sembol ulusal kodlamaya geçmek için kullanıldı.
- SI, 0F - shift benn. SO eyleminin tersini gerçekleştirme komutu: kaynak banda geçin veya kaynak kodlamaya geçin.
- DLE, 10 - data lmürekkep escape, veri kanalını serbest bırakıyor. DLE'yi izleyen karakterler kontrol karakterleri olarak değil veri olarak yorumlanmalıdır.
- DC1, 11 - dihaz control 1 , Cihaz kontrolünün 1. karakteri. Komut: Bant okuyucuyu açın.
- DC2, 12 - dihaz control 2 , Cihaz kontrolü için 2. karakter. Komut: delgiyi açın.
- DC3, 13 - dihaz control 3 , Cihaz kontrolünün 3. karakteri. Komut: teyp okuyucuyu kapatın.
- DC4, 14 - dihaz control 4 , Cihaz kontrolünün 4. karakteri. Komut: delgiyi kapatın.
- NAK, 15 - negative birc knowledgment, onaylamayın. ACK'ya dön.
- SYN, 16 - synchronization. Bu sembol, senkronizasyon için bir şey iletmek gerektiğinde iletildi.
- ETB, 17 - end text bkilit, metin bloğunun sonu. Bazen, teknik nedenlerle, metin bloklara ayrıldı.
- CAN, 18 - kutucel, iptal (daha önce iletilenlerin).
- EM, 19 - end medium, taşıyıcı sonu (kağıt bant bitmiş, kağıt vb.)
- ALT, 1A - altstitute, ikame. İletim sırasında değeri kaybolan veya hasar gören bir sembolün yerine bir sembol konur. Veya bir karakter, yorumlanması için ek bir karakter kümesine geçmeniz gereken bir karakterin önüne yerleştirilir. Ya da bir karakter farklı renkte basılması gereken bir karakterin önüne yerleştirilir. Şu anda, Ctrl + Z tuş bileşimine basılarak bir karakter ekleniyor ve DOS ve Windows'ta bir dosyanın sonunu işaretlemek için kullanılıyor.
- ESC, 1B - escmaymun. ESC karakterini takip eden karakter, ASCII'de tanımlanan karakterden farklı bir anlama sahiptir. Tipik olarak, kaçış dizileri bir ESC karakterini takip eder. DOS'ta, bunlar ANSI.SYS sürücüsü tarafından uygulanır
Verilerin 4 seviyeye ayrılması desteklenmiştir:
- mesaj dosyalardan oluşabilir;
- dosyalar gruplardan oluşabilir;
- gruplar kayıtlardan oluşabilir;
- kayıtlar birimlerden oluşabilir.
- FS, 1C - file separator, dosya ayırıcı.
- GS, 1D - gtavuk difterisi separator, grup ayırıcı.
- RS, 1E - rüzerindeki Record separator, kayıt ayırıcı.
- Amerika, 1F - usirke separator, birim sınırlayıcı.
- DEL, 7F - delete, son karakteri sil. İkili koddaki tüm birimlerden oluşan DEL sembolü ile herhangi bir karakter "dövülebilir". Cihazlar ve programlar DEL'i NUL gibi yok saydı. Bu sembolün kodu, delikli bir kasette belleğe sahip ilk sözcük işlemcilerinden gelir: içlerinde sembol, kodunu deliklerle tıkayarak (mantıksal birimleri belirterek) silindi.
Tablo Yapısal Özellikleri
- İkili sayı sistemindeki "0" - "9" rakamlarının karakter kodları 00112 ile başlar ve ikili rakamlarla biter. Örneğin, 01012, 5 sayısı ve 0011 01012, "5" karakteridir. Bunu bilerek, soldaki her ikili ondalık kemere 00112 ekleyerek ikili ondalık sayıları (BCD) ASCII dizesine dönüştürebilirsiniz.
- Büyük ve küçük harflerin “A” - “Z” harfleri, gösterimlerinde yalnızca bir bit ile ayırt edilir, bu da kaydın dönüştürülmesini kolaylaştırır ve kodun değer aralığına ait olup olmadığını kontrol eder. Harfler, ikili sistemde beş basamakla yazılan ve ardından 0102 (büyük harfler için) veya 0112 (küçük harfler için) alfabedeki seri numaraları ile temsil edilir.
Bilgisayar ASCII Sunumu
Modern bilgisayarların büyük çoğunluğunda, adreslenebilir minimum bellek birimi 8 bit bayttır. Bu nedenle, 7 bitlik karakterler yerine 8 bitlik karakterler kullanır. Tipik olarak, bir ASCII karakteri 8 bite genişletilir ve yüksek bit olarak bir sıfır bit eklenir.
ASCII kodları, basılı tuşların ara platformlar arası kodları olarak programlamada kullanılır (IBM PC tarama kodlarının ve diğer dahili kodların aksine).
QWERTY klavye düzeni için kod tablosu aşağıdaki tabloda gösterildiği gibidir:
kaçış F1 F2 F3 F4 F5 F6 F7 F8 F9 F10 F11 F12 Ekranı yazdır Kaydırma kilidi durma `g 1 2 3 4 5 6 7 8 9 0 - =+ Arka boşluk Ekle ev Sayfa yukarı Num lock / add. * ekleyin. + ekle. çıkıntı S W E R, T Y U ben Ey P [ ] Sil uç Sayfa aşağı 7 ekleyin. 8 ekleyin. 9 ekleyin. Caps lock bir S D F G, 'H J K L ; w 'e girmek 4 ekleyin. 5 ekleyin. 6 ekleyin. Ekle girin. vardiya Z X C V B N- M ,< .> / vardiya \| yukarı 1 ekleyin. 2 ekleyin. 3 ekleyin. Ctrl kazanmak Alt Boşluk çubuğu Alt kazanmak liste Ctrl Sol aşağı sağ Ins / 0 Del /. 46/110
Bu klavye düzeninde Rus harfleri yok ve bazı yanlışlıklar da var, ancak ana özellikler yansıtılıyor.
Herkesi konuşmaya davet ediyorum
METİN BİLGİLERİ KODLAMA. ASCII KODLAMA. TEMEL KULLANILAN CYRILLIAN KODLARI
Herhangi bir metin, belirli bir alfabenin karakter dizisidir. Kullanılan alfabenin her karakteri bir sayı ile kodlanmışsa, metin bir sayı dizisi olarak sunulur. Metin bilgisayar tarafından işlenirken, sayıların ikili gösterimi kullanılır.
Kodlanmış metnin doğru şekilde yorumlanması için, orijinal alfabenin bir karakterinin ikili kodunun nerede bittiğini ve diğerinin ikili kodunun nerede başladığını bilmeniz gerekir. Her karakteri 8 bitlik bir sırayla kodlayabilirsiniz - bir bayt.
Sekiz basamakta, 000000002 ile 111111112 arasında 28 \u003d 256 farklı ikili tamsayı yazabilirsiniz. Bu, İngilizce ve Rusça alfabelerin her büyük ve küçük harfinin, tüm Arap rakamlarının, noktalama işaretlerinin, diğer bazı gerekli karakterlerin ve veri aktarımı için servis kodlarının benzersiz (tekrar etmeyen) sekiz bitlik bir atamaya karşılık gelmesini sağlamak için yeterlidir.
Dijital kodlama ve müteakip kod çözme kolaylığı için kod tabloları derlenir. Farklı işletim sistemlerine sahip farklı bilgisayar türleri farklı kod tabloları kullanır. Bilgisayar klavye karakterlerini 8 bitlik sayılarla kodlamak için kullanılan standartlardan biri Amerikan Bilgi Değişimi Standart Kodu (ASCII) kod tablosudur. Noktalama işaretleri, Arap rakamları ve İngiliz alfabesinin karakterlerini içeren ilk yarısı (0-127 kodları), genel olarak dünya çapında kabul edilen anlaşma ile. ASCII tablosunun 128 - 255 kodları (genişletilmiş ASCII kodları) esas olarak ulusal alfabe için kullanılır.
Alt tuşunu basılı tutarken küçük sayısal tuş takımında 0 ile 255 arasında istediğiniz sayıyı yazarak kod tablosunu çalabilirsiniz, Şekil 1, bu şekilde elde edilen kod tablosunu gösterir.
♫ ☼ ◄ ↕ | ||||||||||
← ∟ ↔ |
||||||||||
M N O P R S T U V | ||||||||||
C H W D F Y S E |
||||||||||
Şekil 1 - Kod tablosu
Kod, satır numarası ve sütun numarasından oluşur. Örneğin, 50 kodu 2 numarasına karşılık gelir, 134 kodu - J harfi. 0'dan 32'ye kodlar - servis.
Çeşitli ulusal dillerin alfabe kullanımına yönelik kod tablolarının birçok varyantının varlığı kendi başına büyük bir rahatsızlıktır. Tabloları düzenlemek için özel adlar ve numaralar atamaya başladılar (örneğin,
KOI-8), ancak bu, çeşitli ulusal alfabeleri birleştiren birleşik kod sistemi oluşturma sorununu çözmedi.
Bu rahatsızlıkların ve sınırlamaların ortadan kaldırılması, Microsoft Windows işletim sisteminin en son sürümleri tarafından desteklenen yeni uluslararası Unicode standardı sayesinde mümkün olmuştur. Şu anda, bu karakter kodlama standardı karakter başına iki bayt ayırmaktadır. Bu kodlama ikili alfabede 216 \u003d 65 536 farklı karakteri temsil etmenizi sağlar. İlk 128 karakterin kodları ASCII ile aynıdır.
MESAJLARIN BİLGİ HACMİ
KARARLI GÖREVLER
Görev. Her karakterin 1 bayt (KOI-8) ile kodlandığını varsayın. İletinin bilgi hacmini tahmin etme
I, n, n ve a ve n il x n s e d O ve HN s x h, f l c w.
Mesaj 39 karakter içerir, bu nedenle kodlamak için 1 bayt / karakter * 39 karakter \u003d 39 bayt gerektirir,
veya 8 bit / bayt * 39 bayt \u003d 312 bit.
1. Önceki örneğin mesajında, “ikili” kelimesi “ondalık” kelimesi ile değiştirildi. İletinin bilgi hacmi bit ve bayt olarak nasıl değişti?
Cevap: Mesajın bilgi hacmi 2 bayt, 16 bit arttı.
2. Her karakterin 1 bayt (KOI-8) ile kodlandığını varsayın. İletinin bilgi hacmini tahmin etme
Sizinle iletişim kurabiliyorum ve iletişim kurabiliyorum.
Cevap: Mesajın bilgi hacmi 48 bayttır.
3. Her karakterin 2 bayt (Unicode) olarak kodlandığını varsayın. İletinin bilgi hacmini tahmin etme
KO I - 8'in olduğunun farkındayım.
Cevap: Mesajın bilgi hacmi 68 bayttır.
4. Her karakterin 2 bayt (Unicode) olarak kodlandığını varsayın. İletinin bilgi hacmini tahmin etme
ALGORITMMOZNO S P R S
Cevap: Mesajın bilgi hacmi 92 bayttır.
5. Başlangıçta 16 bit Unicode kodunda kaydedilen Rusça bilgi iletisi, 8 bit KOI-8 kodlamasına kodlanmıştır. Aynı zamanda bilgi mesajı 480 bit azaldı. Mesajın karakter cinsinden uzunluğu nedir?
Cevap: Mesaj 60 karakter uzunluğundadır.
6. Başlangıçta 8 bit KOI-8 kodunda kaydedilen Rusça bilgi mesajı, 16 bit Unicode kodlamasına kodlanmıştır. Bilgi mesajının hacmi 568 bit arttı. Mesajın karakter cinsinden uzunluğu nedir?
Cevap: Mesaj uzunluğu 71 karakterdir.
7. Başlangıçta 8 bit KOI-8 kodunda kaydedilen Rusça bilgi mesajı, 16 bit Unicode kodlamasına kodlanmıştır. Bilgi mesajının hacmi nasıl değişti?
Cevap: Bilgi mesajının hacmi iki katına çıktı.
8. Bir ileti 200 bit için Unicode'da kaç karakter içeriyor?
Cevap: Mesaj 25 karakter içeriyor.
9. KOI-8 kodlamasındaki bilgi hacmi 240 bit olan bir mesaj kaç karakter içerir?
Cevap: Mesaj 30 karakter içeriyor.
BİLGİ KODLAMA VE DECODING
KARARLI GÖREVLER
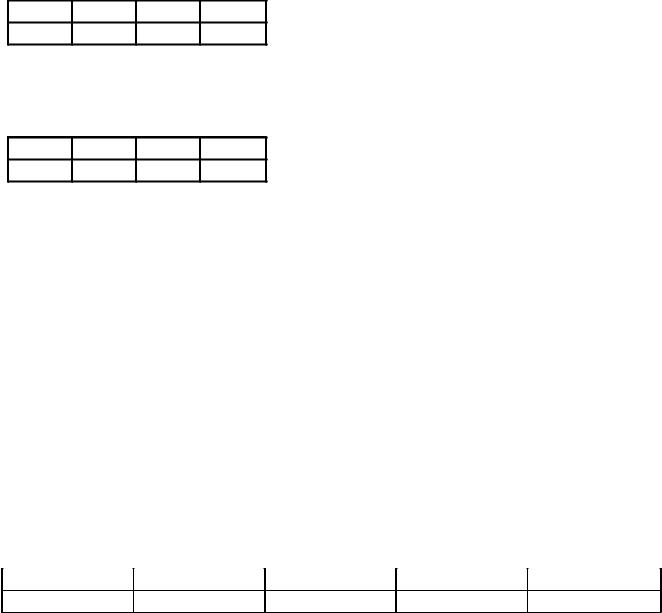
1. Dört basamaklı A, B, C, D harflerinin kodlanması için ikili kodlar sırasıyla 1000 ila 1011 arasındadır. Bir B, D, B, A karakter dizisi için bir ikili kod yazın, kodlama sonucunu sekizli kodda gösterin.
Karakter kodları tablo 1'de verilmiştir: tablo 1
Karşılık gelen ikili kod 16 bit içerir: 1001101110101000, triadlara bir dökümle sekizlik koda dönüştürmek için bu sayıyı yazmak daha uygundur: 1 001 101 110 101 000. İlgili sekizlik sayının aşağıdaki forma sahip olduğu açıktır: 115650.
İkili kodda temsil edilen bir sayıyı onaltılık biçime dönüştürmek için, ikili kaydı sağdan başlayarak dörtgenlere (4 basamaklı gruplar) bölmek uygundur.
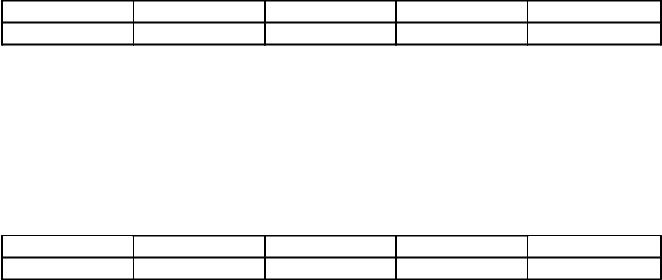
2. Rus alfabesinin 5 harfinde, 2 veya 3 basamak içerebilen ikili kodları ayarlanır. Kodlar tablo 3'e kaydedilir:
1) 110100000100110111
2) 101010000010010011
3) 110100001001100111
4) 110110000100110010.
Tablo 3'e uygun olarak dört mesajın her birini sırayla çözeceğiz:
1) 11 01 000 001 001 10 111 Son basamak grubu bir karakterle eşleştirilemez
tablo 3'e göre. Mesaj bir hata içeriyor.
2) 10 10 10 000 01 001 001 1 Mesaj bir hata içeriyor.
3) 11 01 000 01 001 10 01 11
Mesajın kodu çözülebilir. 4) 11 01 10 000 10 01 10 010 Mesaj bir hata içeriyor.
Yanıt: 3) 110100001001100111
BAĞIMSIZ ÇÖZÜM İÇİN GÖREVLER
1. M, N, P, Q harflerini kodlamak için, sırasıyla 1000 ila 1011 arasındaki dört basamaklı ikili kodlar kullanılır. Bir dizi N, Q, P, M karakterleri için bir ikili kod yazın, kodlama sonucunu sekizli kodda gösterin.
Cevap: ikili kod 1001101101010000, sekizlik kod 115650.
2. A, B, C, D harflerini kodlamak için, sırasıyla 1000 ila 1011 arasındaki dört basamaklı ikili kodlar kullanılır. Bir B, D, C, A karakter dizisi için bir ikili kod yazın, kodlama sonucunu onaltılık kodda gösterin.
Cevap: ikili kod 1001 1011 1010 1000, onaltılı kod 9BA9.
3. M, N, O, P harflerini kodlamak için, sırasıyla 000 ila 111 arasındaki üç basamaklı ikili kodları kullanın. Bir O, N, M, P karakter dizisi için bir ikili kod yazın, kodlama sonucunu sekizli kodda gösterin.
Cevap: ikili kod 110101100111, sekizli kod 6547.
4. M, N, O, P harflerini kodlamak için sırasıyla 100 ila 111 arasındaki üç basamaklı ikili kodlar kullanılır. Bir O, N, M, P karakter dizisi için bir ikili kod yazın, kodlama sonucunu onaltılık kodda gösterin.
Cevap: ikili kod 1101 0110 0111, onaltılı kod B67.
∙ ikinci basamak 3 olamaz.
6. Dört basamaklı sayılar oluşturmak için 1, 2, 3, 4, 5 sayıları kullanılır ve aşağıdaki kurallar gereklidir:
∙ ilk etapta 1, 3, 4 sayılarından biri olabilir;
∙ sayı kaydında, çift ve tek sayılar dönüşümlü olarak;
∙ üçüncü basamak 4 olamaz.
Bu kurallara göre derlenen tüm olası sayıları kaydedin.
7. Dört basamaklı sayılar oluşturmak için 1, 2, 3, 4, 5 sayıları kullanılır ve aşağıdaki kurallar gereklidir:
∙ ilk etapta 2, 4, 5 sayılarından biri olabilir;
∙ sayı kaydında, çift ve tek sayılar dönüşümlü olarak;
∙ ikinci ve son basamaklar aynı olamaz. Bu kurallara göre derlenen tüm olası sayıları kaydedin.
8. Rus alfabesinin 5 harfi için, 2 veya 3 basamak içerebilen ikili kodları ayarlanır. Kodlar tabloya yazılmıştır:
Bu kodlamadaki dört mesajdan sadece biri hatasız olarak geçti, sadece doğru bir şekilde kodu çözülebilir. Bu mesajı listeden bulun:
1) 110100000100110011
2) 111010000010010011
3) 110100001001100111
4) 110110000100110010. Yanıt: 110100001001100111
9. Rus alfabesinin 5 harfi için, 2 veya 3 basamak içerebilen ikili kodları ayarlanır. Kodlar tabloya yazılmıştır:
MÜCADELE dizisini kodlayın, kodda mesajı doğru şekilde çözmenize izin vermeyecek bir hata yapın.
EĞİTİM TESTİ
2 Her karakterin kodlanmış olduğunu varsayın 1 1) 384 bit bayt (Koi-8). Bilgilendirme oranı 2) 192 bit
24 karakterlik kelime hacmi | ||||||
kodlayan. | ||||||
3 üretilmiş | yeniden şifreleme | |||||
bilgilendirici mesaj | ||||||
başlangıçta 8- olarak kaydedilen dil | ||||||
bit kodu KOI-8, 16 bit kodlamada | ||||||
Unicode. Bilgi hacmi | ||||||
mesajlar 336 bit arttı. Nedir? | ||||||
mesaj uzunluğu? | ||||||
4 Kaç karakter içerir | ||||||
mesajı | bilgi | |||||
kOI-8 kodlamasında 240 olan | ||||||
5 Kaç karakter içerir | ||||||
mesajı | bilgi | |||||
unicode kodlanmış olan | ||||||
6 A, B, C, D harflerini kodlamak için | ||||||
üç basamaklı ikili kodlar kullanın | ||||||
sağ | ||||||

