24.07.2019
Metin bilgilerini kodlama. İkili kodlama neden evrenseldir? Programlama yöntemleri
Bakalım hepsi aynı metinleri sayısallaştır? Bu arada, sitemizde herhangi bir metni ondalık, onaltılık, ikili kod Çevrimiçi Kod Hesaplayıcı'yı kullanma.
Metin kodlaması.
Bilgisayar teorisine göre, herhangi bir metin bireysel karakterlerden oluşur. Bu karakterler şunları içerir: harfler, sayılar, küçük noktalama işaretleri, özel karakterler ("", No., (), vb.), Ayrıca sözcükler arasında boşluklar içerir.
Gerekli bilgi. Metni yazdığım karakter kümesine ALFAVIT denir.
Alfabede alınan karakter sayısı gücünü temsil eder.
Bilgi miktarı aşağıdaki formül ile belirlenebilir: N \u003d 2b
- N aynı güçtür (birçok karakter),
- b - Bit (alınan karakterin ağırlığı).
256 olacağı alfabe neredeyse tüm gerekli karakterleri barındırabilir. Bu tür alfabelere YETERLİ denir.
Alfabeyi 256 kapasitesi ile alırsak ve 256 \u003d 28 olduğunu unutmayın.
- 8 bit her zaman 1 bayt olarak adlandırılır:
- 1 bayt \u003d 8 bit.
Her karakteri ikili koda çevirirseniz, bilgisayar metninin bu kodu 1 bayt kullanır.
Metin bilgileri bilgisayar belleğinde nasıl görünebilir?
Herhangi bir metin klavyede, klavye tuşlarında yazılır, bize tanıdık işaretler görürüz (sayılar, harfler vb.). Bilgisayarın RAM'ini yalnızca ikili kod olarak girerler. Her karakterin ikili kodu sekiz basamaklı bir sayıya benzer, örneğin 00111111.
Bayt, belleğin adreslenebilir en küçük parçacığı olduğundan ve bellek her karaktere ayrı ayrı adreslendiğinden, bu tür kodlamanın rahatlığı açıktır. Ancak, 256 karakter herhangi bir karakter bilgisi için çok uygun bir miktardır.
Doğal olarak, soru ortaya çıktı: sekiz bitlik kod her karaktere aittir? Metni dijital koda nasıl çevirebiliriz?
Bu süreç şartlı ve çeşitli biçimlerde ortaya çıkma hakkımız var karakter kodlama yöntemleri. Alfabenin her sembolünün 0 ila 255 arasında bir numarası vardır. Her sayıya 00000000 ila 11111111 arasında bir kod atanır.
Kodlama tablosu, seri numarasına göre alfabenin karakterlerini gösteren bir “kopya kağıdı” dır. Farklı bilgisayar türleri için kodlama için farklı tablolar kullanın.
ASCII (veya Asuka) kişisel bilgisayarlar için uluslararası standart haline gelmiştir. Masanın iki kısmı vardır.
ASCII tablosunun ilk yarısı. (Standart olan ilk yarı oldu.)
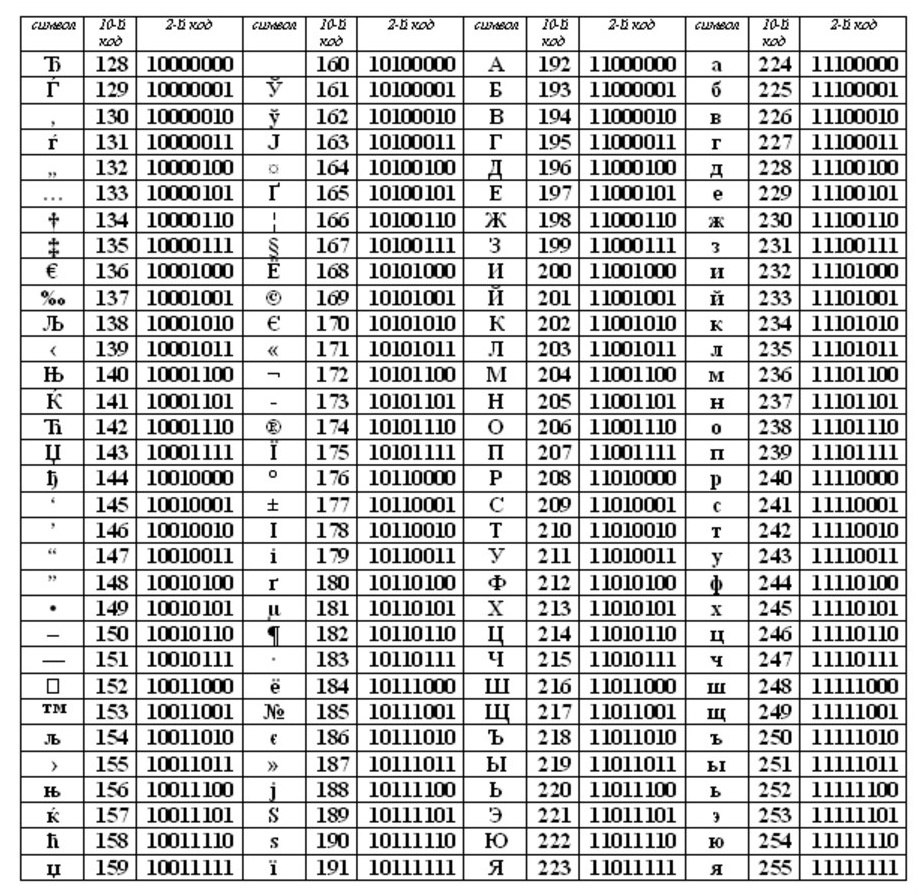
Sözcükbilimsel sıraya uygunluk, yani tabloda harfler (Küçük harf ve büyük harf) katı alfabetik sırada gösterilir ve artan sıradaki rakamlar alfabenin sonraki kodlaması prensibi olarak adlandırılır.
Rus alfabesi için de uyun ardışık kodlama ilkesi.
Şimdi, günümüzde bütün beş kodlama sistemi Rus alfabesi (KOI8-P, Windows. MS-DOS, Macintosh ve ISO). Kodlama sistemlerinin sayısı ve bir standardın olmaması nedeniyle, Rus metninin bilgisayar formuna aktarılması ile sıklıkla yanlış anlaşılmalar ortaya çıkar.
İlklerden biri Rus alfabesini kodlamak için standartlarve kişisel bilgisayarlarda KOI8'i ("Bilgi Değişim Kodu, 8 bit") düşünün. Bu kodlama bir dizi EC bilgisayarda yetmişli yılların ortalarında kullanıldı ve seksenlerin ortalarında Rusçaya çevrilen ilk UNIX işletim sistemlerinde kullanılmaya başlandı.
Doksanların başından beri, MS DOS işletim sisteminin hakim olduğu zaman adı verilen CP866 kodlama sistemi görünür ("CP", "Kod Sayfası", "kod sayfası" anlamına gelir).
Bilgisayar devi APPLE, kontrolü altındaki yenilikçi sistemi (Mac OS) ile MAC alfabesini kodlamak için kendi sistemini kullanmaya başlıyor.
Uluslararası Standartlar Örgütü (ISO) Rus dili için başka bir standart belirliyor alfabe kodlama sistemiISO 8859-5 olarak adlandırılır.
Ve en yaygın, bugün, Microsoft Windows'da icat edilen ve CP1251 olarak adlandırılan alfabeyi kodlamak için bir sistem.
Doksanların ikinci yarısından bu yana, metnin Rus dili için dijital koda çevrilmesi ve sadece Unicode adı verilen bir sistemin standarda getirilmesi sorunu çözüldü. On altı bit kodlama ile temsil edilir, yani her karakter için tam olarak iki bayt RAM tahsis edilir. Tabii ki, bu kodlama ile bellek maliyetleri iki katına çıkar. Bununla birlikte, böyle bir kod sistemi 65536 karaktere kadar elektronik koda tercüme edilmesini sağlar.
Standart Unicode sisteminin özellikleri, mevcut, soyu tükenmiş, uydurulmuş olsun, kesinlikle herhangi bir alfabenin dahil edilmesidir. Sonuç olarak, kesinlikle herhangi bir alfabe, buna ek olarak, Unicode sistemi, birçok matematiksel, kimyasal, müzikal ve ortak sembol içerir.
Bilgisayarınızın belleğinde bir kelimenin nasıl görünebileceğini görmek için ASCII tablosunu kullanalım.
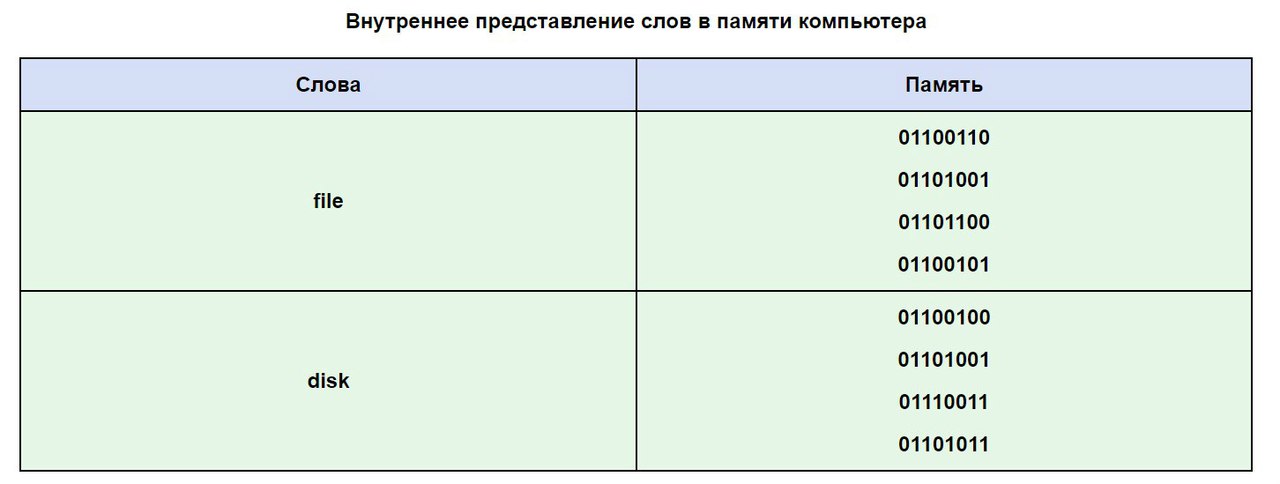
Rus alfabesinden harflerle yazılan metninizin okunamayacağı çoğu zaman, bu, alfabenin bilgisayarlardaki kodlama sistemlerindeki farktan kaynaklanmaktadır. Bu çok sık görülen bir sorundur.
Minimum bilgi birimleri bit ve bayttır.
bir bit kodlamanıza izin verir 2 değerleri (0 veya 1).
kullanma iki bitler kodlanabilir 4 Değerler: 00, 01, 10, 11.
üç bitler kodlanmıştır 8 farklı değerler: 000, 001, 010, 011, 100, 101, 110, 111.
Yukarıdaki örneklerden, bir bit eklemenin kodlanabilecek değer sayısını iki katına çıkardığı görülebilir:
1 bit kodlar -\u003e 2 farklı değer (2 1 \u003d 2),
2 bit kodlar -\u003e 4 farklı değer (2 2 \u003d 4),
3 bit kodlar -\u003e 8 farklı değer (2 3 \u003d 8),
4 bit kodlar -\u003e 16 farklı değer (2 4 \u003d 16),
5 bit kodlar -\u003e 32 farklı değer (2 5 \u003d 32),
6 bit kodlar -\u003e 64 farklı değer (2 6 \u003d 64),
7 bit kodlar -\u003e 128 farklı değer (27 \u003d 128),
8 bit kodlar -\u003e 256 farklı değer (2 8 \u003d 256),
9 bit kodlar -\u003e 512 farklı değer (2 9 \u003d 512),
10 bit kodlar -\u003e 1024 farklı değer (2 10 \u003d 1024).
Bir baytta, 9 değil, 10 bit değil, sadece 8 olduğunu hatırlıyoruz. Bu nedenle, bir bayt kullanarak 256 farklı karakteri kodlayabilirsiniz. Sence çok mu yoksa biraz mı? Bir kodlama örneğine bakalım metin bilgisi.
Rusça'da 33 harf vardır ve bu nedenle kodlamaları için 33 bayt gereklidir. Bilgisayar büyük (büyük harf) ve küçük (küçük harf) harfleri yalnızca farklı kodlarla kodlandıklarında ayırt eder. Bu nedenle, Rus alfabesinin büyük ve küçük harflerini kodlamak için 66 bayt gereklidir.
İngiliz alfabesinin büyük ve küçük harfleri için 52 bayt daha gereklidir. Sonuç 66 + 52 \u003d 118 bayttır. Burada ayrıca sayılar (0'dan 9'a kadar), bir boşluk karakteri, tüm noktalama işaretleri eklemeniz gerekir: nokta, virgül, tire, ünlem işareti ve soru işaretleri, köşeli ayraçlar: yuvarlak, kıvırcık ve kare ve ayrıca matematiksel işlem belirtileri: +, -, \u003d, / (bu bölüm), * (bu çarpma). Ayrıca özel karakterler de ekliyoruz:%, $, &, @, #, No., vb. Bunların hepsi birlikte alınan yaklaşık 256 farklı karakterdir.
Ve sonra mesele küçüklere bırakıldı. Dünyadaki tüm insanların, sembollere atanacak belirli kodların (0 ila 255, yani toplam 256) kendi aralarında anlaştıklarından emin olmak gerekir. Tüm insanların 33 kodunun bir ünlem (!) Anlamına geldiğini ve 63 kodunun bir soru işareti (?) Anlamına geldiğini varsayalım. Ve ayrıca tüm geçerli karakterler için. Bu, bilgisayarındaki bir kişinin yazdığı metnin başka bir bilgisayardaki başka bir kişi tarafından her zaman okunabileceği ve yazdırılabileceği anlamına gelir.
ASCII tablosu
Bir şeyin eşit kullanımı üzerine böyle evrensel bir anlaşmaya denir standart. Bizim durumumuzda standart, kodların (0'dan 255'e kadar) ve karakterlerin yazışmalarının sabit olduğu bir tablo olmalıdır. Benzer bir tablo denir kodlama tablosu.
Ama o kadar basit değil. Sonuçta, örneğin Yunanistan için iyi olan karakterler Türkiye için işe yaramayacak, çünkü orada başka harfler kullanılıyor. Benzer şekilde, ABD için iyi olan şey Rusya için uygun değildir ve Rusya için iyi olan Almanya için uygun değildir.
Bu nedenle, kod tablosunu ikiye bölmeye karar verdiler.
İlk 128 kod (0'dan 127'ye kadar) tüm ülkeler ve tüm bilgisayarlar için standart ve zorunlu olmalıdır, bu - uluslararasıstandardı.
Kod tablosunun ikinci yarısı (128'den 255'e kadar) ile, her ülke her şeyi yapabilir ve bu yarıda kendi standardını oluşturabilir - milli.
Kod tablosunun ilk (uluslararası) yarısı denir bir masaASCII, aBD'de yaratıldı ve tüm dünyada kabul edildi. ASCII standardı kod tablosunun ikinci yarısından sorumlu değildir. Farklı ülkeler burada kendi ulusal kod tablolarını oluştururlar. Bir ülkede farklı bilgisayar sistemleri için farklı standartlar olabilir, ancak kod tablosunun sadece ikinci yarısında olabilir.
Uluslararası ASCII tablosundan kodlar
0-31 - ekranda veya yazıcıda yazdırılmayan ancak özel eylemler gerçekleştirmek için kullanılan özel karakterler (örneğin, “taşıma aktarımı” için - metni yeni bir satıra taşımak veya “sekme” için - imleci bir satırdaki özel konumlara ayarlamak için) metin vb.).
32 - boşluk (kelimeler ve karakterler arasındaki ayırıcı aynı zamanda kodlanacak bir karakterdir, ancak kelimeler ve karakterler arasında "boş alan" olarak gösterilmesine rağmen),
33-47 - özel karakterler (parantez vb.) Ve noktalama işaretleri (nokta, virgül vb.),
48-57 - 0'dan 9'a kadar olan sayılar,
58-64 - matematiksel semboller (artı (+), eksi (-), çarpma (*), bölme (/) vb.) Ve noktalama işaretleri (iki nokta üst üste, noktalı virgül vb.),
65-90 - büyük harf (küçük harf) İngilizce harfler,
91-96 - özel karakterler (köşeli ayraçlar, vb.),
97-122 - küçük (küçük harf) İngilizce harfler,
123-127 - özel karakterler (kıvırcık parantez, vb.).
ASCII tablosunun dışında, 128 ila 159 sayıları ile başlayarak, büyük harfler (büyük harfler) Rus harfleri vardır ve 160 ila 170 ve 224 ila 239 harfler küçük (küçük harf) Rus harfleridir.
Barış kelimesi kodlaması
Gösterilen kodlamayı kullanarak, bir bilgisayarın MIR kelimesini (büyük harflerle) nasıl kodladığını ve daha sonra yeniden ürettiğini hayal edebiliriz. Bu kelime üç kodla temsil edilir: M harfi 140 koduna karşılık gelir (ulusal Rus kodlama sistemine göre), Ve - bu kod 136 ve P - bu 144'tür.
Ancak daha önce de belirtildiği gibi, bilgisayar bilgileri sadece ikili biçimde algılar, yani. sıfırlar ve birler dizisi olarak. MIR kelimesinin her harfine karşılık gelen her bayt, sekiz sıfır ve bir dizi içerir. Ondalık bilgileri ikiliye dönüştürme kurallarını kullanarak, harf kodlarının ondalık değerlerini ikili karşılıklarıyla değiştirebilirsiniz.
Ondalık basamak (140) 10001100 ikili numarasına karşılık gelir. Aşağıdaki hesaplamalar yapılırsa bu kontrol edilebilir: 2 7 + 2 3 +2 2 \u003d 140. Her bir “ikisinin” yükselme derecesi, 10001100 ikili sayısının pozisyon numarasıdır, “1” », Ve konumlar sıfır konum numarasından başlayarak sağdan sola numaralandırılır: 0, 1, 2, vb.
Sayıların bir sayı sisteminden diğerine, örneğin bilgisayar bilimi ders kitaplarından veya Internet üzerinden aktarılması hakkında daha fazla bilgi edinebilirsiniz.
Benzer şekilde, 136 rakamının 10001000 ikili numarasına karşılık geldiğini doğrulayabilirsiniz (kontrol: 2 7 + 2 3 \u003d 136). Ve 144 sayısı 10010000 ikili numarasına karşılık gelir (kontrol: 2 7 + 2 4 \u003d 144).
Böylece, bilgisayarda, MIR kelimesi aşağıdaki sıfırlar ve birler (bitler) dizisi biçiminde saklanacaktır: 10001100 10001000 10010000.
Elbette, yukarıda gösterilen tüm veri dönüşümleri bilgisayar programları kullanılarak gerçekleştirilir ve kullanıcılar tarafından görülemez. Bu programların sonuçlarını, hem klavyeyi kullanarak bilgi girerken hem de bir monitör ekranında veya bir yazıcıda görüntülendiğinde gözlemlerler.
Bilgisayar okuryazarlığı eğitimi düzeyinde, bilgisayar kullanıcılarının ikili sayı sistemini bilmesi gerekmediğine dikkat edilmelidir. Ondalık karakter kodları hakkında fikir sahibi olmak yeterlidir. Sadece pratikte sistem programcıları ikili, onaltılı, sekizli ve diğer sayı sistemlerini kullanır. Bilgisayarlar ondalık sayıya dönüştürülmeden hatalı değerleri gösteren hata mesajlarını görüntülerken bu özellikle onlar için önemlidir.
Bilgisayar okuryazarlığı çalışmalarımakalede açıklanan kodlama sistemlerini bağımsız olarak görmenizi ve hissetmenizi sağlayan
Not; Makale bitti, ancak yine de okuyabilirsiniz:
P.P.S.o yeni makaleler almak için abone olhenüz blogda olmayanlar:
1) Bu forma e-posta adresinizi girin.
İkili Metin Kodlaması
60'ların sonundan itibaren, bilgisayarlar metin bilgilerinin işlenmesi için gittikçe daha fazla kullanılmaya başlandı ve şimdi dünyadaki kişisel bilgisayarların çoğu (ve çoğu zaman) metin bilgilerinin işlenmesi ile meşgul.
Geleneksel olarak, tek bir karakteri kodlamak için 1 bayta eşit miktarda bir bilgi kullanılır, yani I \u003d 1 bayt \u003d 8 bit.
Bir karakteri kodlamak için 1 bayt bilgi gerekir.
Sembolleri olası olaylar olarak değerlendirirsek, formül (2.1) 'e göre, kaç farklı sembolün kodlanabileceğini hesaplayabiliriz:
N \u003d 2 I \u003d 28 \u003d 256.
Böyle bir dizi karakter, Rus ve Latin alfabelerinin büyük ve küçük harfleri, sayılar, işaretler, grafik sembolleri vb.Dahil olmak üzere metin bilgilerini temsil etmek için yeterlidir.
Kodlama, her karaktere 0 ila 255 arasında benzersiz bir ondalık kodu veya 00000000 ila 11111111 arasında karşılık gelen ikili kod atanmasıdır. Böylece, bir kişi karakterleri stillerine ve bilgisayarı kodlarına göre ayırır.
Bir bilgisayara metin bilgisi girildiğinde, ikili kodlanır, karakterin görüntüsü ikili koduna dönüştürülür. Kullanıcı klavyede sembolü olan bir tuşa basar ve bilgisayara sekiz elektrik impulsunun (ikili sembol kodu) belirli bir sırası girer. Karakter kodu bilgisayarın RAM'inde saklanır ve burada bir bayt yer kaplar.
Bilgisayar ekranında bir sembolün gösterilmesi sürecinde, ters işlem gerçekleştirilir - kod çözme, yani sembol kodunun görüntüsüne dönüştürülmesi.
Bir sembole belirli bir kod atamanın, kod tablosunda sabitlenmiş olan bir anlaşma meselesi olması önemlidir. İlk 33 kod (0'dan 32'ye kadar) karakterlere değil, işlemlere (satır besleme, boşluk girişi vb.) Karşılık gelir.
33 ile 127 arasındaki kodlar uluslararasıdır ve Latin alfabesinin karakterlerine, sayılara, aritmetik işlemlerin işaretlerine ve noktalama işaretlerine karşılık gelir.
128 ila 255 arasındaki kodlar ulusaldır, yani ulusal kodlamalarda farklı semboller aynı koda karşılık gelir. Ne yazık ki, şu anda Rus harfleri için beş farklı kod tablosu vardır (KOI8, CP1251, CP866, Mac, ISO - Tablo 1.3), bu nedenle bir kodlamada oluşturulan metinler başka bir kodda doğru şekilde görüntülenmeyecektir.
Şu anda, yeni uluslararası Unicode standardı yaygındır, bu da her karakter için bir bayt değil iki tane ayırır, bu nedenle yardımıyla 256 karakteri değil, N \u003d 216 \u003d \u003d 65536 farklı karakteri kodlamak mümkündür. Bu kodlama, Microsoft Windows ve Office platformunun en son sürümleri tarafından desteklenmektedir (1997'den beri).
Her kodlama kendi kod tablosu tarafından ayarlanır. Tablodan görüldüğü gibi. 1.3, farklı kodlamalarda aynı ikili koda farklı semboller atanır.
Örneğin CP1251 kodlamasındaki 221, 194, 204 nümerik kod dizisi "bilgisayar" kelimesini oluştururken, diğer kodlamalarda anlamsız bir karakter kümesi olacaktır.
Neyse ki, çoğu durumda, kullanıcının uygulamalara yerleştirilmiş özel dönüştürücü programları tarafından yapıldığından, metin belgelerinin kod çevrimi konusunda endişelenmesine gerek yoktur.
Sayısal karakter kodunun tanımı
1. MS Word 2002 metin düzenleyicisini başlatın. [Insert-Symbol ...] komutunu girin. Ekranda bir iletişim kutusu görünecektir. sembol. İletişim kutusunun orta kısmı, belirli bir yazı tipi için karakter tablosu (örneğin, Times New Roman) ile doldurulur.
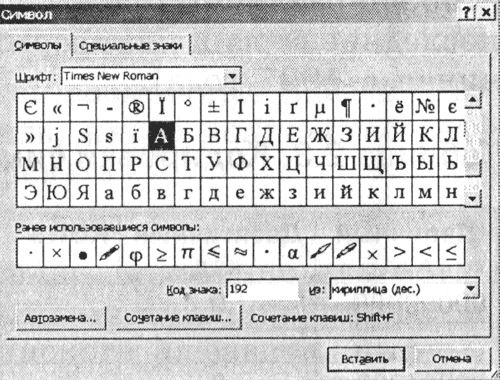 |
Semboller, sembolle başlayarak sırayla soldan sağa ve satır satır düzenlenir boşluk sol üst köşede ve tablonun sağ alt köşesinde "I" harfiyle bitiyor.
Bir karakter seçin ve açılır listeden dan: kodlama türü. Metin kutusunda İşaret Kodu: sayısal kodu görünecektir.
Sayısal koda göre karakter girme
1. Standart programı çalıştırın defter. İsteğe bağlı sayısal tuş takımını kullanarak (Alt) tuşunu basılı tutun, 0224 sayısını girin, (Alt) tuşunu serbest bırakın. Belgede bir sembol görünür. 0225 ile 0233 arasındaki sayısal kodlar için prosedürü tekrarlayın. Belge, kodlama Windows'ta (CP1251) "ev güvenliği" için 12 karakterlik bir sıra görüntüler.
2. (Alt) tuşuna basarken isteğe bağlı sayısal tuş takımını kullanarak 224 sayısını girin, belgede "p" sembolü görünecektir. 225 ile 233 arasındaki sayısal kodlar için prosedürü tekrarlayın, belge kodlama MS-DOS (CP866) 12 karakter "rstuhtschshshsh" bir sıra görüntüler.
 |
Pratik alıştırmalar
1.29. Bir karakter tablosu (MS Word) kullanarak, Windows bilgisayar kodlamasında (CP1251) "bilgisayar" kelimesi için bir ondalık sayı kod dizisi yazın.
1.30. Not Defteri'ni kullanarak, kodlama penceresindeki (CP1251) hangi kelimenin bir dizi sayısal kodla verildiğini belirleyin: 225, 224, 233,242.
1.31. Kodlama KOI8 ve ISO hangi harf dizisi CP1251 kodlamasında kaydedilen "bilgisayar" kelimesine karşılık gelir?
Bilgisayar büyük miktarda bilgiyi işler. Ses dosyaları, resimler, metinler - tüm bunlar çoğaltılmalı veya görüntülenmelidir. İkili kodlama neden herhangi bir teknik ekipmanın bilgilerini programlamak için evrensel bir yöntemdir?
Şifreleme ve şifreleme arasındaki fark nedir?
Çoğu zaman insanlar, aslında farklı anlamları olduğunda "kodlama" ve "şifreleme" kavramlarını tanımlarlar. Dolayısıyla şifreleme, bilgiyi gizlemek için bilgiyi dönüştürme işlemidir. Metni değiştiren kişi veya özel olarak eğitilmiş kişiler genellikle şifresini çözebilir. Kodlama, bilgileri işlemek ve onunla çalışmayı basitleştirmek için kullanılır. Genellikle herkese tanıdık gelen ortak bir kodlama tablosu kullanılır. Bilgisayarın içine yerleştirilmiştir.
İkili kodlama ilkesi
İkili kodlama çeşitli cihazlar tarafından kullanılan bilgileri işlemek için sadece iki karakter - 0 ve 1 - kullanımına dayanır. Bu işaretlere İngilizce - ikili basamak veya bit olarak ikili basamaklar denirdi. Her karakter 1 bit bilgisayar belleği kaplar. İkili kodlama neden evrensel bir bilgi işleme yöntemidir? Gerçek şu ki, bir bilgisayarın daha az karakteri işlemesi daha kolaydır. PC üretkenliği de doğrudan buna bağlıdır: cihazın ne kadar az fonksiyonel görevi yerine getirmesi gerekiyorsa, çalışma hızı ve kalitesi de o kadar yüksek olur. 
İkili kodlama prensibi sadece programlamada bulunmaz. Sağır ve sonorous davul vuruşlarını değiştirerek, Polinezya sakinleri birbirlerine bilgi aktardılar. Bir mesaj iletmek için uzun ve kısa seslerin kullanıldığı yerlerde de benzer bir ilke geçerlidir. "Telgraf alfabesi" bugün kullanılmaktadır.
İkili kodlama nerede kullanılır?
Bilgisayarda ikili her yerde kullanılır. Her dosya, ister müzik ister metin olsun, daha sonra kolayca işlenip okunabilecek şekilde programlanmalıdır. İkili kodlama sistemi, semboller ve sayılar, ses dosyaları, grafikler ile çalışmak için kullanışlıdır.
İkili sayı kodlaması
Şimdi bilgisayarlarda, sayılar ortalama bir kişi tarafından anlaşılamayan kodlanmış biçimde sunulmaktadır. Arap rakamlarının hayal ettiğimiz gibi kullanılması teknoloji için mantıksızdır. Bunun nedeni, her sayıya benzersiz bir karakter atama gereğidir, bu da bazen imkansızdır.

İki sayı sistemi vardır: konumsal ve konumsal olmayan. Konumsal olmayan sistem, Latin harflerinin kullanımına dayanır ve formda bize aşinadır.Bu kayıt yöntemini anlamak oldukça zordur, bu yüzden terk ettiler.
Bugün konumsal sayı sistemi kullanılmaktadır. Bu, bilginin ikili, ondalık, sekizli ve hatta onaltılık kodlamasını içerir.
Ondalık kodlama sistemini günlük hayatta kullanıyoruz. Bunlar, herkes tarafından anlaşılabilir olan bize tanıdık geliyor. Sayıların ikili kodlaması sadece sıfır ve bir kullanılarak değişir.
Tamsayılar, 2'ye bölünerek ikili bir kodlama sistemine çevrilir. Elde edilen bölümler, toplam 0 veya 1 elde edilene kadar 2'ye kadar aşamalandırılır, örneğin, bir ikili sistemdeki 123 10 sayısı, 1111011 2 olarak temsil edilebilir. Ve 20 10 sayısı 10100 2'ye benzeyecek.
Endeksler 10 ve 2, sırasıyla ondalık ve ikili sayı kodlama sistemi olarak adlandırılır. İkili kodlama sembolü, farklı sayı sistemlerinde temsil edilen değerlerle çalışmayı basitleştirmek için kullanılır.
Ondalık programlama yöntemleri bir kayan noktaya dayanır. Değeri ondalıktan ikili kodlama sistemine doğru şekilde çevirmek için N \u003d M x qp formülünü kullanın. M, mantistir (herhangi bir sıra olmadan bir sayının ifadesi), p, N değerinin sırasıdır ve q, kodlama sisteminin temelidir (bizim durumumuzda 2).
Tüm sayılar pozitif değildir. Pozitif ve negatif sayılar arasında ayrım yapmak için, bilgisayar karakter kodlaması için 1 bit boşluk bırakır. Burada sıfır artı işaretini, biri eksi işaretini temsil eder.
Böyle bir sayı sisteminin kullanılması bilgisayarın sayılarla çalışmasını kolaylaştırır. Bu nedenle ikili kodlama hesaplama süreçlerinde evrenseldir.

İkili Metin Kodlaması
Alfabenin her karakteri kendi sıfırları ve karakterleri ile kodlanır. Metin farklı karakterlerden oluşur: harfler (büyük harf ve küçük harf), aritmetik karakterler ve diğer çeşitli anlamlar. Metin bilgilerinin kodlanması, 00000000'den 11111111'e kadar 8 ardışık ikili değerin kullanılmasını gerektirir. Bu şekilde 256 farklı karakter dönüştürülebilir.
Metin kodlamasında karışıklığı önlemek için, her karakter için özel değer tabloları kullanılır. Latin alfabesi, aritmetik işaretleri ve özel işaretleri vardır (örneğin, €, ¥ ve diğerleri). Boşluk karakterleri 128-255 ülkenin ulusal alfabesini kodlar.
1 karakteri kodlamak için 8 bit bellek gerekir. Alt hesapları basitleştirmek için, 8 bit 1 bayta eşittir, bu nedenle metin bilgileri için toplam disk alanı bayt olarak ölçülür.

Çoğu kişisel bilgisayarın standart bir tablosu vardır. aSCII kodlamaları Bilgi Değişimi için Amerikan Standart Kodu. Metin kodlama sisteminin farklı olduğu diğer tablolar da kullanılır. Örneğin, bilinen ilk karakter kodlamasına KOI-8 (8 bit bilgi değişim kodu) denir ve UNIX çalıştıran bilgisayarlarda çalışır. Windows işletim sistemi için oluşturulan CP1251 kod tablosu da yaygın olarak bulunur.
İkili Ses Kodlaması
İkili kodlamanın, bilgi programlama için evrensel bir yöntem olmasının bir başka nedeni, ses dosyalarıyla çalışırken basit olmasıdır. Herhangi bir müzik, farklı genlik ve salınım frekansındaki ses dalgalarıdır. Ses seviyesi ve ses perdesi bu parametrelere bağlıdır.
Bir ses dalgası programlamak için, bilgisayar onu koşullu olarak birkaç parçaya veya “örneğe” ayırır. Bu tür örneklerin sayısı büyük olabilir, bu nedenle 65.536 farklı sıfır ve bir kombinasyonları vardır. Buna göre, modern bilgisayarlar 16-bit ses kartları ile donatılmıştır, yani bir ses dalgasının bir örneğini kodlamak için 16 ikili basamak kullanmak anlamına gelir.
Bir ses dosyasını oynatmak için, bilgisayar programlanan ikili kod dizilerini işler ve bunları bir sürekli dalga halinde birleştirir. 
Grafik kodlama
Grafik bilgileri PowerPoint'te çizimler, diyagramlar, resimler veya slaytlar şeklinde sunulabilir. Herhangi bir resim, farklı renklerde boyanabilen piksellerden oluşan küçük noktalardan oluşur. Her pikselin rengi kodlanır ve kaydedilir ve sonuç olarak tam teşekküllü bir görüntü elde ederiz.
Resim siyah beyazsa, her piksel için kod bir veya sıfır olabilir. 4 renk kullanılırsa, bunların her birinin kodu iki basamaktan oluşur: 00, 01, 10 veya 11. Bu prensipte, herhangi bir görüntünün işleme kalitesi ayırt edilir. Parlaklığı artırmak veya azaltmak, kullanılan renk sayısını da etkiler. En iyi durumda, bilgisayar yaklaşık 16.777.216 tonu ayırt eder.

Sonuç
İkili kodlamanın en verimli olduğu çeşitli programlama bilgisi yöntemleri vardır. Sadece iki karakterle (1 ve 0) bilgisayar çoğu dosyayı kolayca okur. Aynı zamanda, işlem hızı, örneğin, bir ondalık programlama sisteminden çok daha yüksektir. Bu yöntemin sadeliği, herhangi bir teknik için vazgeçilmezdir. Bu nedenle ikili kodlama akranları arasında evrenseldir.
Herkes bilgisayarların büyük veri gruplarıyla muazzam hızda hesaplamalar yapabileceğini bilir. Ancak herkes bu eylemlerin sadece iki koşula bağlı olduğunu bilmiyor: akım olup olmadığı ve hangi voltajın olduğu.
Bir bilgisayar bu kadar çeşitli bilgileri nasıl işleyebilir?
Sır, ikili sistemde yatar. Tüm veriler, her biri elektrik kablosunun bir durumuna karşılık gelen birimler ve sıfırlar şeklinde sunulan bilgisayara girer: birimler - yüksek voltaj, sıfırlar - düşük veya birimler - voltaj varlığı, sıfırlar - yokluğu. Verileri sıfırlara ve bunlara dönüştürme ikili dönüşüm olarak adlandırılır ve son ataması ikili kod olarak adlandırılır.
Günlük yaşamda kullanılan ondalık sayı sistemine dayanan ondalık bir göstergede, sayısal değer 0'dan 9'a kadar on basamakla temsil edilir ve sayıdaki her yer, sağındaki yerden on kat daha yüksek bir değere sahiptir. Ondalık sistemde dokuzdan büyük bir sayıyı temsil etmek için, yerine sıfır konur ve soldaki bir sonraki, daha değerli yer birdir. Benzer şekilde, sadece iki rakamın kullanıldığı ikili sistemde - 0 ve 1, her yer sağındaki yerin iki katıdır. Bu nedenle, ikili kodda, yalnızca sıfır ve bir, tek sayılar olarak temsil edilebilir ve birden büyük herhangi bir sayı iki yer gerektirir. Sıfır ve bir sonra, aşağıdaki üç ikili sayı 10 (bir-sıfır oku) ve 11 (bir-bir oku) ve 100 (bir-sıfır-sıfır oku) şeklindedir. 100 ikili sistem 4 ondalığa eşittir. Sağdaki üst tablo diğer ikili ondalık eşdeğerlerini göstermektedir.
Herhangi bir sayı ikili olarak ifade edilebilir, sadece ondalık gösterimden daha fazla yer kaplar. İkili sistemde, her harfe belirli bir ikili sayı atanmışsa alfabeyi de yazabilirsiniz.
Dört yer için iki basamak
Koyu ve açık renkli toplar kullanılarak 16 kombinasyon yapılabilir, bunları dörtlü setler halinde birleştirirsiniz. Koyu renkli topları sıfır olarak ve açık olanları birim olarak alırsanız, 16 set, sayısal değeri sıfırdan beşe kadar olan 16 birimlik bir ikili kod olacaktır ( bkz. üst tablo, sayfa 27). İkili sistemdeki iki tür topla bile, her bir gruptaki top sayısını veya sayılardaki yer sayısını artırarak sonsuz sayıda kombinasyon oluşturabilirsiniz.
Bitler ve baytlar
Bilgisayar işlemedeki en küçük birim, bit, iki olası durumdan birine sahip olabilen bir veri birimidir. Örneğin, her biri ve sıfırlar (sağda) 1 bit anlamına gelir. Bit başka şekillerde temsil edilebilir: bir elektrik akımının varlığı veya yokluğu, bir delik ve yokluğu, sağa veya sola mıknatıslanma yönü. Sekiz bit bir bayt oluşturur. 256 olası bayt 256 karakter ve karakteri temsil edebilir. Birçok bilgisayar aynı anda bayt veri işler.
İkili dönüşüm Dört basamaklı bir ikili kod, 0 ile 15 arasındaki ondalık sayıları temsil edebilir.
Kod tabloları
Alfabedeki harfleri veya noktalama işaretlerini göstermek için bir ikili kod kullanıldığında, hangi kodun hangi karakterle eşleştiğini gösteren kod tabloları gereklidir. Bu tür birkaç kod derlenmiştir. Çoğu bilgisayar ASCII adı verilen yedi haneli bir kod veya bilgi alışverişi için Amerikan standart kodu için uyarlanmıştır. Sağdaki tablo aSCII kodları İngiliz alfabesi için. Diğer kodlar, dünyanın diğer dillerindeki binlerce karakter ve alfabe için tasarlanmıştır.

ASCII Kod Tablosunun bir kısmı

