07.09.2019
Typer av kodning. Kodning för alkoholism - behandling och konsekvenser. Effektiva kodningsmetoder för alkoholberoende. Konsekvenserna av kodning från alkoholism
Sökmodulen är inte installerad.
Internetkodning och typsnitt
Vladimir Molochkov
När du arbetar med Internet eller e-post har många av er troligtvis stött på mer än en gång problemet med att välja en kodning för bokstäverna i det ryska alfabetet. Men vad ligger bakom namn som koi-8r eller UTF-8? Har du någonsin undrat hur man representerar 33 bokstäver i det ryska alfabetet från 26 bokstäver på engelska?
Processen för celldelning är ett enormt mirakel. Detta är inte bara en huvudlös separering, så det kommer bara att skapa massa, som om bröddegen hade stigit; eller låt oss titta på tumörens form. Denna separation är utan ett högre syfte. I början av ett nytt liv delar cellerna uppenbarligen ingenting som styr denna separering, och ändå vet varje cell vilken del av kroppen den ska skapa, vilken form den ska ha och om cellen är muskel, ben, blod eller för att bli ett glasartat öga . Kameror vet vilken riktning de ska dela och när de ska sluta dela.
NY TERM
Kodningen är en karaktärstabell, där varje bokstav i alfabetet (samt siffror och specialtecken) tilldelas sitt eget unika nummer - teckenkoden.
För att presentera text på datorns skärm måste du tilldela ett visst nummer till varje tecken - dess kod. Alla moderna kodningstabeller kommer från American Standard Code for Information Interchange (ASCII) 7-bitars tabell som dök upp på 60-talet, som innehåller 33 koder med kommandon eller kontrolltecken, de flesta används inte idag, och 95 koder för olika tecken, tillräckligt för att arbeta med engelska texter. I 7-bitars kodning mappas varje tecken till 7 bitar, det vill säga ett nummer i området från 0 till 127.
Det är inte uppenbart att alla tillgränsande delar av kroppen exakt sammanfaller i hela tillväxtprocessen. Således anpassar sig acetabulum alltid till formen på benet som rör sig i det. Det händer inte att acetabulum ökar på ett eller annat sätt i en oregelbunden form, att benet kommer att falla ut. Varje individuellt sammankopplat ben i kroppen ökar med avseende på angränsande ben under hela utvecklingen. Detta gäller också ögonen, hjärtat, hjärnan och andra organ. Naturligtvis ser vi detta mästerverk av perfektion i hela skapelsen.
Detta skulle inte vara möjligt för "slumpmässiga" processer med variation, såsom evolutionister har bestämt. Hjärtat slår ungefär en miljard gånger under en persons liv. Utan att stanna, utan den minsta pausen. Slaghastigheten anpassar sig till spänningen. Hjärtat har perfekta kamrar och ventiler, och alla vener är korrekt anslutna. Hjärtats aktivitet är helt oberoende av vårt medvetande, det är helt automatiskt. Om en person medvetet fokuserar på varje hjärtslag, skulle detta vara slutet på livet på jorden under lång tid.
Den snabba utvecklingen under de senaste åren av hypertekstmetoder för att presentera information om WWW har förvärrat problemet med att presentera och arbeta med kyrillisk information i elektronisk form, som har funnits i mer än ett decennium. Detta beror först på allt på bristen på en standard för utökad ASCII-kod - en tabell som inkluderar kodningen av kyrilliska karaktärer och av de olika lösningar som erbjuds av olika kommersiella företag.
Så allt detta, mina vänner, är statistiskt omöjligt, att detta hände av en slump, och, naturligtvis, inte vid första försöket. Vi försöker bara ta reda på hur skickligt han skapade Herren. Detta är Guds mysterium själv, och vi kan ödmjukt tillbe honom. Evolution kan inte svara på frågan om vad som kom först, ett ägg eller en kyckling. Detta är naturligtvis problemet med alla varelser som kläcks från ägg, det vill säga ormar, fåglar, sköldpaddor och andra. Detta evolutionsproblem verkar vara mycket mer betydelsefullt och utbrett. Har du någonsin undrat hur det första däggdjuret blev?
Endast hälften av ASCII-tabellen är standardiserad, nämligen de första 128 tecknen, som innehåller bokstäverna i det latinska alfabetet. Och det finns aldrig ett problem med dem. Den andra halvan av tabellen (med totalt 256 tecken - med antalet stater som kan ta en byte) anges för nationella tecken, och i varje land är denna del annorlunda. Till exempel i Ryssland finns det cirka 10 olika kodningar. Det vill säga, en annan digital kod motsvarar samma symbol, och om vi felaktigt fastställer kodningen för texten, kommer vi att se helt oläslig text. Och även om det här problemet verkligen existerar, räcker det faktiskt inte för att bestämma typen av textkodning i praktiken, och många program, till exempel Stirlitz (fig. 1), gör detta i automatiskt läge.
Var utvecklades han, under trädet? Eller någonstans i en pöl på golvet? I mammas kropp, dök det första lejonet upp? I slutändan var han den första och vid den tiden fanns det ingen mamma! Kvinnor som överlever en högriskgraviditet kan berätta hur bräcklig den här saken är. Att tänka på utvecklingen av fostret utanför moderns kropp är åtminstone utopi. Vi vet att många varelser behöver en mamma för sin utveckling, så detta problem är mycket vanligt. Här ser vi mycket väl att huvudmotorerna för evolution, mutation och naturligt urval får stora sprickor.
Fig. 1. Huvudfönstret i kodningsigenkänningsprogrammet "Stirlitz"
Den internationella standarden ISO / IEC 8859-1 är numera en ersättning för ASCII. I den motsvarar de första 32 koderna, numren 128-159, nästan oanvända kontrolltecken som är gemensamma för alla ISO-kodningstabeller. Även om 8859-1 kan användas för texter på nästan alla västeuropeiska språk, täcker den inte helt behoven hos franska och finska. Denna brist, liksom bristen på ett tecken för den nya paneuropeiska valutan, ledde 1999 till uppkomsten av kodning 8859-15, i vilken en ny version av värdena för koder 8859-1 användes.
En annan myt, som vi omedelbart kommer att motbevisa, är att utvecklingen av levande varelser har nått en sådan utvecklingsnivå på miljoner och miljoner år. Låt oss försöka föreställa oss hur den första, lite mer utvecklade personen utvecklades. På grund av mutationen dök mannen upp efter flera försök. Men detta kopplade inte artären korrekt och överlevde inte. I ett annat försök misslyckades många, hans mun växte samman och han hade inga hål i näsan, så han kvävs. I en annan mutation dök upp en man som hade allt i ordning, men ögongulorna var inte gjorda av transparent material, så han såg ingenting och dog av svält eftersom han inte kunde hitta någon mat.
Vad gäller det kyrilliska alfabetet finns det idag fem grundläggande tabeller för kodning av ryska bokstäver:
För användning med DOS-operativsystem utvecklades en kodtabell CP-866 (IBM / Microsoft). Kodningen CP866 är baserad på den alternativa kodningen GOST och skapades specifikt för MS-DOS OS, som använder pseudo-grafiska tecken. Idag är denna kodning lika populär än MS DOS.
Låt oss säga att nästa föddes perfekt, men evolutionen glömde att låta mamma utveckla bröstkörtlarna, så den fattiga kollegan dog av hunger. Nästa glömde att starta hjärtat. I ett annat fall passade inte benen ihop, och det var bara ett gäng kött och ben. Den andra saknade hela levern. I kroppen skulle det finnas flera saker som inte fungerar på en gång och inte bara en. Det finns bara ojämnheter i det fysiska tillståndet eller under andra omständigheter, och personen överlever inte.
Allt kan vara helt perfekt, men om bara en liten sak är fel, kommer inget av detta att vara. Vi vet att forskare försökte korsa olika arter, men till ingen nytta. Förklara för mig hur reproduktionsorgan kan utvecklas om den minsta oregelbundenheten automatiskt leder till utrotning av denna art, eftersom nästa generation av avkommor inte skulle ha fött. Samtidigt bör hela kroppen fungera 100%. Eller hur utvecklar en fisk i vatten gradvis källor? Om de inte fungerar perfekt kommer fisken för första gången att kvävas, och evolutionen slutar.
För användning i Windows-operativmiljön används kodtabellen CP-1251 (Microsoft). Kod Sida 1251 för Microsoft Windows har blivit populärt på grund av Microsofts enorma inflytande på marknaden för datorteknologi. Dessutom saknar det stöd för pseudografiska symboler i grafiska miljöer och är mycket mer komplett än i andra kodningar; symboler som c, R, olika typer av citattecken, bindestreck etc. presenteras. Denna kodtabell är den viktigaste i Ryssland idag.
Detsamma gäller för utvecklingen av hjärtat och i allmänhet för ett stort antal vitala organ. Så det är inte miljarder år, bara en generation eller snarare ögonblicket då Gud skapade allt genom sitt ord. Har du någonsin förstått det här? I detta ljus kollapsar evolutionsteorin till damm. Det är trevligt att se en levande varelse som Gud skapade, men vi ser att dessa metoder inte kan generaliseras till den globala livsprincipen.
Om ögonen, i stället för ljuskänsliga gula fläckar, smaklökarna i stället för trumhinnan i örat var ögatlinsen, skulle njurarna vara helt frånvarande och istället för urinblåsan. Hur vet blind evolution hur man kan hjälpa? Som vi redan har visat, borde alla organ ha varit korrekt samordnade samtidigt. Här är tydliga bevis på att bakom allt detta finns en rationell Skapare - Gud. Vad är sannolikheten för att blind evolution kan skapa en så perfekt organisme genom slumpmässiga prövningar och fel?
Codepage 10007 - Används på Macintosh-datorer och nästan identiskt i teckenuppsättning till CP1251.
I en UNIX-miljö är den vanligaste KOI8-R-kodtabellen. Detta är en av standardkodningarna för det ryska språket, som antogs i Sovjetunionen i början av datateknologins utveckling. KOI står för "informationskod." Siffran 8 indikerar att den här koden är 8-bitar (till skillnad från KOI-7, som användes allmänt på sovjetiska datorer). För närvarande är koi8-r en av de viktigaste ryskspråkiga kodningarna i Linux-operativsystem. Detta är den näst populäraste kodningen efter CP-1251 (win). Kodningen stöder pseudografiska tecken och upptar ungefär hälften av alla koder. 1993 standardiserades koi8-r-tabellen på Internet (fig. 2).
Detta är ouppnåeligt för fallet. Ett annat bevis på den så kallade evolutionisten är det välkända Miller-Urey-experimentet när elektriska laddningar under vissa förhållanden skapade olika aminosyror från vatten, metan, ammoniak och väte. Emellertid genererades inte nukleinsyror. Det visade sig dock att i de tidiga stadierna av jorden hade en helt annan atmosfärsammansättning, och detta experiment gav helt andra resultat med denna sammansättning. Naturligtvis kommer en sådan atmosfär att döda alla levande varelser.
Naturligtvis finns det inga skapelser utan Skaparen. Det finns också de som säger att livet på jorden är utomjordiskt. Naturligtvis är detta inte en lösning, problemet flyttas helt enkelt till en annan plats. Vi vet att många försöker hitta utomjordiskt liv i universum. Denna ansträngning är också förankrad i den matematiska sannolikheten att det i ett så stort antal stjärnor finns statistiskt förhållanden någonstans någonstans. Nu ser vi att detta inte handlar om lämpliga villkor, utan om skaparens beslut. Det är också känt att detta skulle vara ett slöseri med rymden om vi var de enda i hela universum.
Den internationella ISO-standarden definierar kodtabellen ISO 8859-5 för Ryssland. Pseudografik saknas. Just nu används denna kodning praktiskt taget inte. Men dess stöd finns i alla webbläsare.

Fig. 2. En uppsättning tecken för att representera det ryska språket i kodningen KOI8-R
Hur mycket kommer att försvinna från det oändliga rymden om vi separerar det mesta, som vårt universum? Oändlighet förblir oändlig. Gud är inte begränsad till vår rymdtid, och det som verkar gigantiskt för oss är ett tecken på Gud. Känner du till ordspråket: "Ett blad kan inte röra sig utan vind"? Vet du att detta i princip är en grundläggande vetenskaplig lag - kausalitetsprincipen, som avgör att varje fenomen måste ha en orsak? Vetenskap baserad på denna lag måste därför ta itu med svaret på frågan om vad som var huvudorsaken.
Vad orsakade Big Bang, eller vilken vetenskap anser att universum föddes? Enligt denna lag var detta fenomen tänkt att orsaka något. Det verkar som att den onda cirkeln och vetenskapen hjälplöst fick av med detta problem genom att sätta det i filosofi. Bibeln ger också ett svar på denna fråga i det första kapitlet i Johannesevangeliet och i början av 1 Mosebok. I början var Ordet, och Ordet var hos Gud, och Gud var Ordet. Det var samma från början med Gud. Allt görs ett och samma, och utan det görs ingenting, vad görs.
NOTERA
För kodning av det kyrilliska alfabetet kan ytterligare fem tabeller användas, som nu är arkaiska och har ingen internationell status: Huvudkodningen är GOST (USSR State Standard) från 1987. Dess huvudsakliga nackdel är att de pseudo-grafiska symbolerna finns annorlunda än de på IBM PC. Alternativ GOST-kodning (skiljer sig från CP866 i positionerna 242-251). Bulgarisk kodning (erhålls genom att mekaniskt ange ett block med 64 bokstäver i det ryska alfabetet i positionerna 128-191 CP437). KOI-8 (på IBM PC är inte utbredd på grund av det icke-alfabetiska arrangemanget av bokstäverna i det kyrilliska alfabetet).
Det var liv i honom, och livet är människors ljus. Den första termodynamiska lagen säger att energi i ett slutet system är konstant. Detta innebär att energi inte kan genereras eller förstöras. Detta talar om fysisk lag. Så var är all energi i universum? Vissa säger att det kom efter Big Bang. Men lagen säger att energi inte kan genereras! Så, vad exploderade och var kom så mycket energi ifrån? Det är också ett vetenskapligt bevis på Guds existens. Endast den allsmäktige Gud, som inte har någon början eller slut, kan producera något sådant.
För att koda tecken på vissa språk, som kinesiska eller japanska, räcker det inte med 8-bitarsnummer. Dessutom blev skapandet av 8-bitars kodningstabeller vid någon tidpunkt nästan okontrollerbart: varje nytt datorteckensnitt introducerade sitt eget bord. Det är därför Unicode-konsortiet skapades: Målet var att utveckla ett enhetligt kodningssystem för alla möjliga tecken, vilket gjorde det möjligt för oss att tilldela koder till datorteckensnittstecken i ett specifikt mönster.
Hans ord räcker, och allt händer. Kärnan i vetenskapen är att undersöka och fastställa lagarna i de fenomen och processer som omger oss som kan bevisas och beräknas. Det vore orimligt att säga att det vi inte kan bevisa experimentellt inte finns. Och det här är en snublen för människor. För att vi bara öppnar och börjar långsamt inse, för Gud trodde verkligen och gjorde allt. Vetenskapen kommer att stanna om vi inte inser att Gud verkligen finns och att han är skaparen av allt.
Det verkar ovetenskapligt och svagt om vetenskapen inser att Gud står bakom allt detta, men detta är det enda sättet. En person håller ibland sin stolthet för befälhavaren i hela skapelsen och för visdomens topp. Vi uppfinner många konstiga teorier och hävdar att de är sanna, och vi vet hur sårbara vi är för falska. Teorier om universum, partiklar av atomnivå och många andra lovande teorier, som i slutändan uteslutits, är mycket tydliga. Mannen, intelligensens och skapelsens topp. Låt oss bara se vilken typ av person som uppfann och tänkte att han skulle vara perfekt och effektiv.
Unicode-kodningen är baserad på UCS (Universal Character Set) -katalogen enligt ISO 10646-standarder och kan innehålla upp till 231 \u003d 2147483648 olika tecken, samt fylla på. UCS-2-koder är tvåbyte, det vill säga siffror från 0 till 65535, och UCS-4 är fyra-byte, det vill säga siffror från 0 till 2147483647. Två och fyra byte Unicode-koder kan representeras på två sätt: byte är ordnade från vänster till höger från äldsta till lägsta ( Big Endian, BE) eller från junior till senior (Little Endian, LE). Den andra metoden finns i de allra flesta fall. För mer kompakt kodning används dessutom UTF-8 (Unicode Transfer Format) 1-6-byte och UTF-16 - två- eller fyra-byte. Det senare finns också i två former (Little and Big Endian) och tillåter kodning av högst 220 + 216 \u003d 1114112 tecken.
Mästerverk av mänskligt geni, och ändå är de misslyckade försök som inte kan flyga och kopierades av naturen. Var inte rädd att erkänna att det finns någon som är större än oss. Detta är inte ett tecken på svaghet, utan mognad. Varje person bör kunna inse vad som är resultatet av en chans och skaparens arbete. Hela universumet, och därför allt vi ser bara på jorden, är skaparen, men i icke-levande materier agerar endast fysiska lagar, därför är detta inte så märkbart och betraktas som slumpmässigt. Förresten, alla lagar, fysiska konstanter, är väl anpassade, och till och med Einstein trodde själv att det borde finnas en skapare bakom honom.
Bland de nämnda kodningarna är den mest använda kodningen UTF-8, som låter dig kringgå 8 bitar för kodning av ASCII-tecken och 16 bitar för kodningstecken i de flesta alfabetiska skript, inklusive ryska. Texter i ASCII, särskilt på engelska, är samtidigt texter i UTF-8. UTF-8-koden, en sekvens av byte, erhålls från UCS-katalogkoden enligt ett specifikt schema. Till exempel är ett Unicode-tecken med kod 169 \u003d a916 \u003d 1010 1001 (tecken c) kodat i UTF-8 som 11000010 10101001 \u003d c216 a916.
Evolutionsteorin har lurat oss så mycket att det till synes tydliga beslutet inte längre är så tydligt tack vare de upprepade recensionerna från evolutionister som vi hör från alla sidor. 100-faldiga upprepade lögner blir sanna. Ta människan och många andra varelser som har en symmetrisk kropp. Och vi vet att detta inte är strikt symmetri, eftersom det inre organet inte är symmetriskt. Vad är sannolikheten för att tillfällighet kan skapa en sådan symmetri? Dessutom är mannen och kvinnan attraktiva och vackra för varandra.
Och detta gäller hela skapelsen. Kvinnliga feromoner är mycket attraktiva för manliga arter. Hjorten lockas inte sexuellt av ett vildsvin, utan av en attraktiv kvinna, och han besöker honom när tiden är rätt. Och denna parning fungerar av all natur. Många har till och med en smartphone. Detta är en komplex enhet med en processor, minne, batteri för laddning, en kamera med flera megapixlar, en mikrofon, högtalare etc. Den kan utföra beräkningar, lagra foton och videor och kommunicera. Kort sagt en mycket komplex enhet.
Unicode stöds fullt ut av moderna program - webbläsare, kontorssviter etc. Linux använder UTF-8 och Microsoft Windows använder också UCS-2. Hittills är UCS-stöd på Linux något svagare än på Windows 2000 / Me / XP. De viktigaste problemen när du använder Unicode är bristen på lämplig fullständig uppsättning teckensnitt och komplexiteten hos inmatningen.
(Här skulle jag vilja ställa den uppmärksamma läsaren frågan: "I vilken kodning kom EURO-symbolen först?")
Om harmonin i webbläsare och webbplats typsnitt
Det finns flera problem med att använda teckensnitt på webbsidor. Den första av dem är harmonin i kodningar på webbplatser och webbläsare. Webbplatser med webbläsare för olika användare bör kommunicera i samma kodning, dvs. Webbläsaren måste "förstå" vad webbplatsen skickar till den. För att göra detta måste du installera ett system på webbplatsen som kan skicka ett meddelande om vilken kodning på sidan kommer att skickas till användaren. Hans webbläsare måste acceptera detta meddelande och ställa in för att visa webbplatsen korrekt. I det här fallet kan du ange kodningen för webbplatssidan direkt i HTML-koden. För att göra detta använder du en speciell version av META-taggen med parametern charset som anger önskat språk. Till exempel, för en sida skriven i Win1251-kodning, skulle motsvarande kod se ut så här:
En metod är emellertid mycket utbredd i Ryssland, där webbservern automatiskt avgör i vilken kodning förfrågan kommer från klienten, och ger sidan till webbläsaren som redan har kodats. Denna META-tagg kan spela ett dåligt skämt här. Faktum är att instruktionerna på sidan har företräde framför de kommandon som skickas av webbservern, och har korrekt kodat sidan kan servern dock inte ändra innehållet i META-taggen. Det finns ett missförhållande mellan den faktiska kodningen i vilken kodningen kom och instruktionerna i META-taggen. En sådan sida kan normalt inte ses och omkodas med webbläsaren. Att välja kodningen manuellt i detta fall hjälper inte, för META-taggen har företräde framför webbläsarinställningarna. Det enda sättet att göra detta är att spara sidan på disken och sedan ta bort taggen.
I detta avseende rekommenderas det inte i RUNET att använda den här taggen alls. I detta fall kommer visningen att utföras i den kodning som webbläsaren är konfigurerad för, om servern inte skickar ett meddelande om kodning av dokumentet. I händelse av felanpassning kan det växlas ganska enkelt. Om standardkodningen dessutom är Win-1251, kommer sidan för de flesta användare omedelbart att visas korrekt.
Ett mått på läsbarheten är ett bredd på ett dokument. Med tillkomsten av bildskärmar som stöder stora skärmupplösningar har det blivit möjligt att "stapla" upp till flera hundra tecken på en rad, men raden "idealbredd" borde passa cirka 50-70 tecken. Med fler av dem saknar läshastigheten, och trötthet sker mycket snabbare.
Det andra kodningsfrågan kan vara kaskadstilark (CSS). Det är känt att den exakta teckensnittsstorleken och dess andra attribut kan ställas in med kaskaderande stilark (de kommer att diskuteras i kapitel 8). När vi använder CSS kan vi använda absolut valfri typsnitt. Men problemet är att teckensnitten är tagna från den uppsättning som är installerad på användarens dator och inte på webbplatsen. Det vill säga teckensnittet på webbplatsen och användarens teckensnitt stämmer kanske inte.
När du visar webbplatser använder du standardteckensnittet som är installerat i webbläsaren. För att ändra standardteckensnittet i Internet Explorer (dvs. Times New Roman) till ett annat, till exempel till Arial, kör kommandot Service4 Internet Options 4 Fonts.
Det tredje möjliga problemet är när teckensnittet på webbplatsen och på användarens dator är identiskt, men i ett fall är det kyrilliskt, och i det andra är det latin (icke-ryska versionen av teckensnittet). I det här fallet kommer texten att visas med några specialtecken och att läsa dessa tecken kommer att vara problematisk.
För att undvika sådana problem när du använder teckensnitt i webbdesign måste du följa ett antal regler:
Det är bättre att bara använda standardteckensnitt som levereras med Windows och garanteras att vara på klientens maskin. Det finns tre sådana teckensnitt: "Arial", "Times New Roman", "Courier".
Det är nödvändigt att korrekt beskriva teckensnitten i formatmallen (CSS) med en lista i listan med andra teckensnitt som ersätter det huvudsakliga (teckensnitt för utbyte). I slutet av listan bör en obligatorisk indikering av den allmänna typsnittfamiljen (med serifs, sans serifs, monospaced, etc.).
Till exempel:
Som ett alternativ för att komma ur situationen, presentera teckensnittet med grafik, till exempel i GIF-format. Både webbläsaren och operativsystemet bryr sig inte om vad som dras - att visa teckensnittet som en grafisk fil på alla användares skärmar kommer att vara identiska (men ett annat problem uppstår här - grafiken är stor).
Av det föregående följer att Internet-teknologier sätter specifika begränsningar för användningen av teckensnitt vid utformningen av webbdokument, och att icke-standardteckensnitt i webbdesign bör hanteras noggrant. Tyvärr finns det för närvarande inga tillräckligt utvecklade och pålitliga medel för att specificera ett visst headset när man presenterar information i form av text på en webbsida.
|
För att bilalarmet du köpte ska bli tillförlitligt skydd måste du välja det korrekt. En av huvudparametrarna som påverkar larmets prestanda är en signalkodningsmetod. I den här artikeln kommer vi att försöka förklara på ett tillgängligt sätt vad dynamisk kodning av signaler betyder och vad dialogkod betyder i bilalarm, vilken typ av kodning som är bättre, som var och en har sina positiva och negativa sidor.
Dynamisk kodning i bilalarm
Konfrontationen mellan utvecklarna av larm och biltjuvar började sedan skapandet av de första bilarna. Med tillkomsten av nya, mer avancerade säkerhetssystem förbättrades hackningsmedel. De allra första larmen hade en statisk kod, som lätt knäcktes av urvalsmetoden. Utvecklarnas svar var att blockera möjligheten att välja kod. Nästa steg i knäckarna var att skapa gripare - enheter som skannade signalen från tangentbordet och reproducerade den. På det sättet duplicerade de kommandona från ägarens nyckelfod och avlägsnade bilen från skydd vid rätt tidpunkt. För att skydda bilalarm från att bryta av en gripare började de använda dynamisk signalkodning.
Principen för dynamisk kodning
 Den dynamiska koden i bilalarm är ett datapaket som ständigt förändras som överförs från tangentbordet till larmenheten via radiokanalen. Med varje nytt kommando skickas en kod från nyckel fob som inte tidigare använts. Denna kod beräknas enligt en specifik algoritm som fastställts av tillverkaren. Den vanligaste och pålitliga algoritmen är Keelog.
Den dynamiska koden i bilalarm är ett datapaket som ständigt förändras som överförs från tangentbordet till larmenheten via radiokanalen. Med varje nytt kommando skickas en kod från nyckel fob som inte tidigare använts. Denna kod beräknas enligt en specifik algoritm som fastställts av tillverkaren. Den vanligaste och pålitliga algoritmen är Keelog.
Larmet fungerar enligt följande princip. När ägaren till bilen trycker på tangenten fob-knappen genereras en signal. Den innehåller information om antalet klick (detta värde är nödvändigt för att synkronisera funktionen för tangentbordet och styrenheten), enhetens serienummer och den hemliga koden. Innan du skickar är dessa data förkrypterade. Själva krypteringsalgoritmen är fritt tillgänglig, men för att dekryptera data måste du känna till den hemliga koden som är lagrad i nyckelfod och kontrollenhet från fabriken.
Det finns också originalalgoritmer utvecklade av larmtillverkare. Sådan kodning eliminerade praktiskt taget möjligheten att välja en kommandokod, men med tiden kringgick angriparna detta skydd.
Vad du behöver veta om hacking av dynamisk kod
 Som svar på införandet av dynamisk kodning i bilalarm skapades en dynamisk gripare. Principen för dess funktion är att störa och fånga signalen. När bilägaren lämnar bilen och trycker på knappen fobknapp skapas en stark radiostörning. Signalen med koden når inte larmstyrenheten, men den fångas upp och kopieras av griparen. Den förvånade föraren trycker på knappen igen, men processen upprepas och den andra koden fångas också upp. Andra gången bilen sätts på defensiven, men kommandot kommer från tjuvens enhet. När ägaren till bilen lugnt lämnar sin verksamhet skickar kaparen en andra, tidigare avlyssnad kod och tar bort bilen från skydd.
Som svar på införandet av dynamisk kodning i bilalarm skapades en dynamisk gripare. Principen för dess funktion är att störa och fånga signalen. När bilägaren lämnar bilen och trycker på knappen fobknapp skapas en stark radiostörning. Signalen med koden når inte larmstyrenheten, men den fångas upp och kopieras av griparen. Den förvånade föraren trycker på knappen igen, men processen upprepas och den andra koden fångas också upp. Andra gången bilen sätts på defensiven, men kommandot kommer från tjuvens enhet. När ägaren till bilen lugnt lämnar sin verksamhet skickar kaparen en andra, tidigare avlyssnad kod och tar bort bilen från skydd.
Vilket skydd används för dynamisk kod
 Tillverkare av bilalarm har löst problemet med hacking helt enkelt. De började installera två knappar på prydnadssnitten, varav den ena satte bilen på skyddet, och den andra - inaktiverade skyddet. Följaktligen skickades olika koder för att ställa in och ta bort skyddet. Därför, oavsett hur stor störning tjuven gör när han ställer in maskinen för skydd, kommer han aldrig att få den kod som krävs för att inaktivera larmet.
Tillverkare av bilalarm har löst problemet med hacking helt enkelt. De började installera två knappar på prydnadssnitten, varav den ena satte bilen på skyddet, och den andra - inaktiverade skyddet. Följaktligen skickades olika koder för att ställa in och ta bort skyddet. Därför, oavsett hur stor störning tjuven gör när han ställer in maskinen för skydd, kommer han aldrig att få den kod som krävs för att inaktivera larmet.
Om du klickade på knappen "inställt för att skydda" och bilen inte svarade, kan du ha blivit kaprarens mål. I det här fallet behöver du inte tankelöst trycka på alla knapparna på tangentbordet för att försöka rätta till situationen på något sätt. Det räcker att trycka på skyddsknappen igen. Om du av misstag klickar på knappen "ta bort från skyddet" får tjuven den kod han behöver, som han snart kommer att använda och stjäla din bil.
Larm med dynamisk kodning är redan något föråldrade, de ger inte hundra procent skydd av bilen från stöld. De ersattes av enheter med interaktiv kodning. Om du är ägare till en billig bil, behöver du inte oroa dig, eftersom det är mycket osannolikt att en tjuv utrustad med den modernaste utrustningen kommer att komma in på din fastighet. Använd skydd på flera nivåer för att skydda din egendom. Installera valfritt. Det ger skydd för bilen i händelse av bilalarm.
Dialogkodning i astrosignaler
 Efter tillkomsten av dynamiska gripare blev bilalarm med dynamisk kod mycket sårbara för angripare. Dessutom har ett stort antal kodningsalgoritmer hackats. För att skydda fordonet mot hackning av sådana enheter började larmutvecklare använda dialogsignalkodning.
Efter tillkomsten av dynamiska gripare blev bilalarm med dynamisk kod mycket sårbara för angripare. Dessutom har ett stort antal kodningsalgoritmer hackats. För att skydda fordonet mot hackning av sådana enheter började larmutvecklare använda dialogsignalkodning.
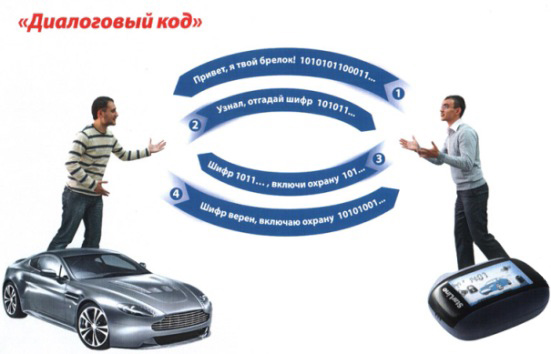
Principen för dialogkodning
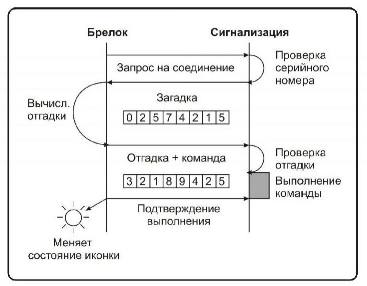 Som namnet antyder utförs den här typen av kryptering i ett dialogläge mellan nyckelfoten och bilalarmstyrenheten som finns i bilen. När du trycker på knappen skickas en begäran från tangenten fob för att köra kommandot. För att kontrollenheten ska se till att kommandot kom från ägarens key fob, skickar det en slumpmässig signal till key fob. Detta nummer behandlas enligt en specifik algoritm och skickas tillbaka till styrenheten. För närvarande bearbetar styrenheten samma nummer och jämför sitt resultat med resultatet som skickats av nyckelfoten. Om värdena överensstämmer kör kontrollenheten kommandot.
Som namnet antyder utförs den här typen av kryptering i ett dialogläge mellan nyckelfoten och bilalarmstyrenheten som finns i bilen. När du trycker på knappen skickas en begäran från tangenten fob för att köra kommandot. För att kontrollenheten ska se till att kommandot kom från ägarens key fob, skickar det en slumpmässig signal till key fob. Detta nummer behandlas enligt en specifik algoritm och skickas tillbaka till styrenheten. För närvarande bearbetar styrenheten samma nummer och jämför sitt resultat med resultatet som skickats av nyckelfoten. Om värdena överensstämmer kör kontrollenheten kommandot.
Den algoritm med vilken beräkningarna utförs på nyckelfoten och styrenheten är individuell för varje bilalarm och fastställs i det på en annan fabrik. Låt oss förstå den enklaste algoritmen:
X ∙ T 3 - X ∙ S 2 + X ∙ U - H \u003d Y
T, S, U och H är nummer som är inbäddade i larmet på fabriken.
X är ett slumpmässigt nummer som skickas från kontrollenheten till nyckelfod för verifiering.
Y är det antal som beräknas av styrenheten och nyckelfoten enligt en given algoritm.
Låt oss titta på situationen när ägaren till larmet tryckte på en knapp och en begäran skickades från nyckelfoten till kontrollenheten att avväxla bilen. Som svar genererade kontrollenheten ett slumpmässigt nummer (ta till exempel numret 846) och skickade det till nyckelringen. Därefter utför kontrollenheten och nyckelring beräkningen av siffran 846 enligt algoritmen (vi beräknar till exempel enligt den enklaste algoritmen som anges ovan).
För beräkningar tar vi:
T \u003d 29, S \u003d 43, U \u003d 91, H \u003d 38.
Vi kommer att lyckas:
846∙24389 - 846∙1849 + 846∙91- 38 = 19145788
Knappsatsen sänder numret (19145788) till styrenheten. Samtidigt utför styrenheten samma beräkning. Siffrorna kommer att matcha, kontrollenheten kommer att bekräfta tangentbordet och maskinen kommer att avaktiveras.
 Även för att dekryptera den elementära algoritmen som beskrivs ovan kommer det att vara nödvändigt att fånga datapaket fyra gånger (i vårt fall fyra okända i ekvationen).
Även för att dekryptera den elementära algoritmen som beskrivs ovan kommer det att vara nödvändigt att fånga datapaket fyra gånger (i vårt fall fyra okända i ekvationen).
Det är nästan omöjligt att fånga upp och dekryptera ett datapaket med dialogbilalarm. För kodning av en signal används de så kallade hashfunktionerna - algoritmer som konverterar strängar av godtycklig längd. Resultatet av denna kryptering kan innehålla upp till 32 bokstäver och siffror.
Nedan visas resultaten av krypteringsnummer med den mest populära MD5-krypteringsalgoritmen. Till exempel togs numret 846 och dess modifieringar.
MD5 (846) \u003d;
MD5 (841) \u003d;
MD5 (146) \u003d.
Som ni ser är resultaten från kodningsnummer som bara skiljer sig på en siffra helt annorlunda.
Liknande algoritmer används i moderna interaktiva bilalarm. Det bevisas att för omvänd avkodning och erhållande av en algoritm kommer moderna datorer att behöva mer än ett sekel. Och utan denna algoritm kommer det att vara omöjligt att generera verifieringskoder för att bekräfta kommandot. Därför är det nu och inom en nära framtid omöjlig att hacking av dialogkod.
Larm som arbetar med dialogkoden är säkrare, de är inte tillgängliga för elektronisk hacking, men det betyder inte att din bil kommer att vara helt säker. Du kan av misstag förlora nyckelringen eller så kommer den att bli stulen från dig. För att öka skyddsnivån är det nödvändigt att använda ytterligare medel, såsom och.

