29.06.2019
Ktorý zvukový formát je najlepší. Čo je „bezstratová“ alebo O bezstratovej kompresii hudby
Dobrý deň.
Dnes sa chcem dotknúť témy bezstratovej kompresie údajov. Napriek tomu, že už boli články o náboji venované určitým algoritmom, chcel som o tom hovoriť trochu podrobnejšie.
Pokúsim sa matematický popis aj popis uviesť obvyklým spôsobom, aby si každý mohol nájsť niečo zaujímavé pre seba.
V tomto článku sa dotknem základných momentov kompresie a hlavných typov algoritmov.
Kompresia. Je to potrebné dnes?
Áno, samozrejme. Všetci samozrejme chápeme, že teraz máme prístup k veľkoobjemovým úložným médiám aj k kanálom vysokorýchlostného prenosu údajov. Zároveň však narastá objem prenášaných informácií. Ak sme pred niekoľkými rokmi sledovali filmy s veľkosťou 700 megabajtov, ktoré sa zmestia na jeden disk, dnes filmy v kvalite HD môžu obsadzovať desiatky gigabajtov.
Výhody komprimácie všetkého a všetkého samozrejme nie sú toľko. Stále však existujú situácie, keď je kompresia mimoriadne užitočná, ak nie nevyhnutná.
- Posielanie dokumentov e-mailom (najmä veľké objemy dokumentov pomocou mobilných zariadení)
- Pri publikovaní dokumentov na webových stránkach je potrebné šetriť prevádzku
- Pri zmene alebo pridaní úložného priestoru ušetrite miesto na disku. Napríklad k tomu dôjde v prípadoch, keď nie je ľahké získať rozpočet na kapitálové výdavky a na disku nie je dostatok miesta.
Samozrejme, môžete prísť na oveľa viac rôznych situácií, v ktorých bude kompresia užitočná, ale týchto pár príkladov je pre nás dosť.
Všetky metódy kompresie je možné rozdeliť do dvoch veľkých skupín: stratová kompresia a bezstratová kompresia. Bezstratová kompresia sa používa v prípadoch, keď je potrebné obnoviť informácie presne podľa bitov. Tento prístup je jediný možný pri kompresii napríklad textových údajov.
V niektorých prípadoch však nie je potrebné presné obnovenie informácií a je dovolené používať algoritmy, ktoré implementujú stratovú kompresiu, ktorá sa na rozdiel od bezstratovej kompresie zvyčajne ľahšie implementuje a poskytuje vyšší stupeň archivácie.
Prejdime teda k bezstratovým kompresným algoritmom.
Univerzálne metódy bezstratovej kompresie
Vo všeobecnosti existujú tri základné možnosti, na ktorých sú postavené kompresné algoritmy.Prvá skupina metódy - prúdová konverzia. Znamená to opis nových prichádzajúcich nekomprimovaných údajov prostredníctvom už spracovaných údajov. V tomto prípade nie sú vypočítané žiadne pravdepodobnosti, kódovanie znakov sa vykonáva iba na základe údajov, ktoré už boli spracované, napríklad v metódach LZ (pomenovaných po Abraham Lempel a Jacob Ziva). V tomto prípade sa druhý a ďalší výskyt podreťazca, ktorý je už známy kodéru, nahradí odkazmi na jeho prvý výskyt.
Druhá skupina metódy sú štatistické metódy kompresie. Tieto metódy sa ďalej delia na adaptívne (alebo tokové) a blokové.
V prvej (adaptívnej) verzii je výpočet pravdepodobnosti nových údajov založený na údajoch už spracovaných počas kódovania. Tieto metódy zahŕňajú adaptívne verzie algoritmov Huffman a Shannon-Fano.
V druhom prípade (blok) sa štatistika každého dátového bloku počíta osobitne a pridá sa k najkomprimovanejšiemu bloku. Patria medzi ne statické verzie Huffmanovej, Shannon-Fanoovej metódy a aritmetické kódovanie.
Tretia skupina metódy sú takzvané metódy blokovej konverzie. Prichádzajúce údaje sú rozdelené do blokov, ktoré sa potom transformujú ako celok. Niektoré metódy, najmä založené na permutácii blokov, však nemusia viesť k významnému (alebo dokonca akémukoľvek) zníženiu množstva údajov. Po takomto spracovaní sa však dátová štruktúra výrazne zlepšuje a následná kompresia inými algoritmami je úspešnejšia a rýchlejšia.
Všeobecné zásady, na ktorých je založená kompresia údajov
Všetky metódy kompresie údajov sú založené na jednoduchom logickom princípe. Ak si predstavíme, že najčastejšie sa vyskytujúce prvky sú kódované kratšími kódmi a menej často sa vyskytujúce sú kódované dlhšími, potom na uloženie všetkých údajov je potrebných menej miesta, ako keby boli všetky prvky reprezentované kódmi rovnakej dĺžky.
Presný vzťah medzi frekvenciami výskytu prvkov a optimálnymi dĺžkami kódu je opísaný v takzvanej Shannonovej zdrojovej kódovacej vete, ktorá definuje bezstratový maximálny kompresný limit a Shannonovu entropiu.
Trochu matematiky
Ak je pravdepodobnosť výskytu prvku s i rovná p (s i), potom bude najvýhodnejšie predstavovať tento prvok - log 2 p (s i) bitov. Ak je počas kódovania možné zabezpečiť, aby sa dĺžka všetkých prvkov znížila na log 2 p (s i) bitov, potom dĺžka celej kódovanej sekvencie bude minimálna pre všetky možné spôsoby kódovania. Okrem toho, ak je rozdelenie pravdepodobnosti všetkých prvkov F \u003d (p (s i)) nezmenené a pravdepodobnosti prvkov sú vzájomne nezávislé, potom je možné priemernú dĺžku kódov vypočítať akoTáto hodnota sa nazýva entropia rozdelenia pravdepodobnosti F alebo entropia zdroja v danom časovom okamihu.
Pravdepodobnosť výskytu prvku však obyčajne nemôže byť nezávislá, naopak, záleží na niektorých faktoroch. V tomto prípade pre každý nový kódovaný prvok si bude mať pravdepodobnostné rozdelenie F nejakú hodnotu Fk, to znamená pre každý prvok F \u003d Fk a H \u003d Hk.
Inými slovami, môžeme povedať, že zdroj je v stave k, čo zodpovedá určitej skupine pravdepodobností p k (s i) pre všetky prvky s i.
Preto, vzhľadom na túto opravu, môžeme vyjadriť priemernú dĺžku kódov ako
Kde P k je pravdepodobnosť nájdenia zdroja v stave k.
V tejto fáze vieme, že kompresia je založená na nahradení často sa vyskytujúcich prvkov krátkymi kódmi a naopak, a vieme tiež určiť priemernú dĺžku kódov. Čo je to kód, kódovanie a ako k tomu dôjde?
Kódovanie bez pamäte
Kódy bez pamäte sú najjednoduchšie kódy, na základe ktorých je možné údaje komprimovať. V bezchybnom kóde je každý znak v kódovanom dátovom vektore nahradený kódovým slovom z predpony sady binárnych sekvencií alebo slov.Podľa môjho názoru to nie je najjasnejšia definícia. Zvážte túto tému podrobnejšie.
Nechajte nejakú abecedu ![]() pozostáva z určitého (konečného) počtu písmen. Nazývame každú konečnú postupnosť znakov z tejto abecedy (A \u003d a 1, a 2, ..., a n) jedným slovoma číslo n je dĺžka tohto slova.
pozostáva z určitého (konečného) počtu písmen. Nazývame každú konečnú postupnosť znakov z tejto abecedy (A \u003d a 1, a 2, ..., a n) jedným slovoma číslo n je dĺžka tohto slova.
Nech je uvedená aj iná abeceda ![]() , Podobne označte slovo v tejto abecede ako B.
, Podobne označte slovo v tejto abecede ako B.
Predstavujeme ďalšie dve notácie pre súbor všetkých neprázdnych slov v abecede. Dovoliť - počet neprázdnych slov v prvej abecede a - v druhom.
Dovolí sa aj mapovanie F, ktoré spojí s každým slovom A z prvej abecedy slovo B \u003d F (A) z druhého písmena. Potom sa zavolá slovo B. kód budú sa volať slová A a bude sa hovoriť z pôvodného slova do jeho kódu kódovanie.
Keďže slovo môže pozostávať aj z jedného písmena, môžeme identifikovať korešpondenciu písmen prvej abecedy a zodpovedajúcich slov od druhého:
a 1<-> B 1
a 2<-> B 2
…
a n<-> B n
Tento zápas sa volá systéma označujú ∑.
V tomto prípade sa volajú slová B1, B2, ..., Bn základné kódya typ kódovania s pomocou - abecedné kódovanie, Väčšina z nás sa samozrejme stretla s takýmto kódovaním, aj keď nevieme všetko, čo som opísal vyššie.
Takže sme sa rozhodli pre koncepty abeceda, slovo, kód, a kódovanie, Teraz predstavíme tento koncept prefix.
Nech má slovo B tvar B \u003d B "B" "Potom sa B" nazýva začiatok, alebo prefix slová B a B "" - jej koniec. Toto je pomerne jednoduchá definícia, ale treba poznamenať, že pre každé slovo B možno určité prázdne slovo ʌ („medzera“) aj samotné slovo B považovať za začiatočné aj cieľové slovo.
Priblížime sa teda k pochopeniu definície kódov bez pamäte. Poslednú definíciu, ktorú musíme pochopiť, je predpona. Schéma ∑ má vlastnosť predpony, ak pre akékoľvek 1≤i, j≤r, i ≠ j slovo Bi nie je predponou slova Bj.
Jednoducho povedané, predpona je konečná množina, v ktorej žiadny prvok nie je predponou (alebo začiatkom) žiadneho iného prvku. Jednoduchým príkladom takejto množiny je napríklad regulárna abeceda.
Takže sme prišli na základné definície. Ako teda prebieha samotné pamäťové kódovanie?
Vyskytuje sa v troch fázach.
- Zostaví sa abeceda Ψ znakov pôvodnej správy a znaky abecedy sa zoradia zostupne podľa pravdepodobnosti výskytu v správe.
- Každý symbol ai z abecedy Ψ je spojený s určitým slovom B i z množiny predpony Ω.
- Každý znak je kódovaný, po ktorom nasleduje kombinácia kódov do jedného dátového toku, ktorý bude výsledkom kompresie.
Jedným z kanonických algoritmov, ktoré ilustrujú túto metódu, je Huffmanov algoritmus.
Huffmanov algoritmus
Huffmanov algoritmus používa frekvenciu výskytu rovnakých bajtov vo vstupnom dátovom bloku a porovnáva časté bloky reťazca bitov kratších dĺžok a naopak. Tento kód je minimálne zbytočný. Zvážte prípad, keď abeceda výstupného toku, bez ohľadu na vstupný tok, pozostáva iba z 2 znakov - nula a jeden.Predovšetkým pri kódovaní pomocou Huffmanovho algoritmu musíme skonštruovať obvod ∑. Toto sa vykonáva takto:
- Všetky písmená vstupnej abecedy sú usporiadané v zostupnom poradí pravdepodobnosti. Všetky slová z abecedy výstupného toku (to, čo kódujeme) sa spočiatku považujú za prázdne (spomínam si, že abeceda výstupného toku pozostáva iba zo znakov (0,1)).
- Dva znaky a-1 a j vstupného toku, ktoré majú najmenšiu pravdepodobnosť výskytu, sa spoja do jedného „pseudo-symbolu“ s pravdepodobnosťou p rovná súčtu pravdepodobností ich základných znakov. Potom pripojíme 0 na začiatok slova Bj-1 a 1 na začiatok slova Bj, ktoré budú následne znakovými kódmi a-1 a j.
- Tieto znaky odstránime z abecedy pôvodnej správy, ale do tejto abecedy pridáme vygenerovaný pseudo-symbol (prirodzene by sa mal vložiť do abecedy na správnom mieste, berúc do úvahy jej pravdepodobnosť).
Pre lepšiu ilustráciu uvážte malý príklad.
Predpokladajme, že máme abecedu skladajúcu sa iba zo štyroch znakov - (a 1, a 2, a 3, a 4). Predpokladajme tiež, že pravdepodobnosť výskytu týchto symbolov je rovnaká, p1 \u003d 0,5; p2 \u003d 0,24; p3 \u003d 0,15; p 4 \u003d 0,11 (súčet všetkých pravdepodobností je zjavne rovný jednej).
Zostavíme schému pre túto abecedu.
- Skombinujte tieto dva znaky s najmenšou pravdepodobnosťou (0,11 a 0,15) do p "pseudo-znaku".
- Kombinujeme tieto dva znaky s najmenšou pravdepodobnosťou (0,24 a 0,26) do p pseudo-znaku.
- Odstránime kombinované znaky a výsledný pseudo-znak vložíme do abecedy.
- Nakoniec skombinujte zostávajúce dva znaky a získajte vrchol stromu.
Ak tento proces ilustrujete, dostanete niečo ako toto:
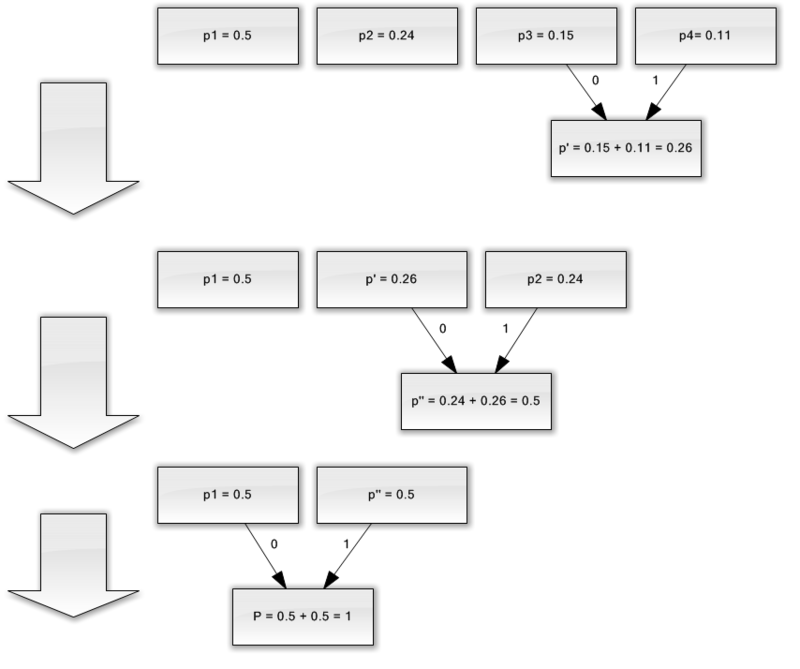
Ako vidíte, pri každom zlúčení priradíme znakom 0, ktoré sa majú zlúčiť.
Keď sa teda vytvorí strom, môžeme ľahko získať kód pre každý znak. V našom prípade budú kódy vyzerať takto:
A 1 \u003d 0
a 2 \u003d 11
a 3 \u003d 100
a 4 \u003d 101
Pretože žiadny z týchto kódov nie je predponou žiadneho iného (to znamená, že máme notoricky známe predpony), môžeme jedinečne identifikovať každý kód vo výstupnom toku.
Dosiahli sme teda, že najčastejší znak je kódovaný najkratším kódom a naopak.
Ak predpokladáme, že spočiatku sa na uloženie každého znaku použil jeden bajt, potom môžeme vypočítať, koľko sme boli schopní redukovať údaje.
Predpokladajme, že na vstupe sme mali reťazec 1 000 znakov, v ktorom sa znak 1 vyskytol 500-krát, 2 240, 3 150 a 4 110-krát.
Tento reťazec spočiatku zaberal 8 000 bitov. Po kódovaní dostaneme reťazec s dĺžkou ip i l i \u003d 500 * 1 + 240 * 2 + 150 * 3 + 110 * 3 \u003d 1760 bitov. Takže sme boli schopní komprimovať dáta 4,54 krát, pričom na kódovanie každého symbolu toku sme strávili priemerne 1,76 bitov.
Dovoľte mi pripomenúť, že podľa Shannona je priemerná dĺžka kódov. Nahradením našich pravdepodobnostných hodnôt do tejto rovnice dostaneme priemernú dĺžku kódu rovnú 1.75496602732291, čo je veľmi, veľmi blízko k dosiahnutému výsledku.
Malo by sa však pamätať na to, že okrem samotných údajov musíme uložiť aj kódovaciu tabuľku, ktorá mierne zvýši konečnú veľkosť kódovaných údajov. Je zrejmé, že v rôznych prípadoch je možné použiť rôzne variácie algoritmu - napríklad je niekedy efektívnejšie použiť preddefinovanú pravdepodobnostnú tabuľku a niekedy je potrebné ju dynamicky kompilovať pomocou komprimovateľných údajov.
záver
Takže v tomto článku som sa pokúsil hovoriť všeobecné zásady, čím dôjde k bezstratovej kompresii a tiež sa považuje za jeden z kanonických algoritmov - Huffmanovo kódovanie.Ak je tento článok podľa chuti habro komunity, rád napíšem pokračovanie, pretože v súvislosti so bezstratovou kompresiou je veľa zaujímavejších vecí; sú to klasické algoritmy, ako aj predbežné transformácie údajov (napríklad Burroughs-Wheelerova transformácia), a samozrejme špecifické algoritmy na kompresiu zvuku, videa a obrázkov (podľa môjho názoru najzaujímavejšia téma).
literatúra
- Vatolin D., Ratushnyak A., Smirnov M. Yukin V. Metódy kompresie údajov. Archivátory zariadenia, kompresia obrázkov a videa; ISBN 5-86404-170-X; 2003 rok
- D. Salomon. Kompresia dát, obrazu a zvuku; ISBN 5-94836-027-X; 2004.
Prednáška číslo 4. Kompresia informácií
Zásady kompresie informácií
Účelom kompresie údajov je poskytnúť kompaktné zobrazenie údajov generovaných zdrojom, pre ich úspornejšie uloženie a prenos prostredníctvom komunikačných kanálov.
Predpokladajme, že máme súbor s veľkosťou 1 (jeden) megabajtov. Potrebujeme z neho získať menší súbor. Nič zložité - spustíme archivátor, napríklad WinZip, a získame napríklad súbor s veľkosťou 600 kilobajtov. Kam šlo zvyšných 424 kilobajtov?
Kompresia informácií je jedným zo spôsobov, ako ich kódovať. Vo všeobecnosti sú kódy rozdelené do troch veľkých skupín - kompresné kódy (efektívne kódy), kódy odolné voči šumu a kryptografické kódy. Kódy určené na kompresiu informácií sa ďalej delia na bezstratové kódy a stratové kódy. Bezstratové kódovanie znamená absolútne presné obnovenie údajov po dekódovaní a môže sa použiť na kompresiu akýchkoľvek informácií. Stratové kódovanie má zvyčajne oveľa vyššiu kompresnú rýchlosť ako bezstratové kódovanie, ale umožňuje určité odchýlky dekódovaných údajov od pôvodného.
Druhy kompresie
Všetky metódy kompresie informácií možno rozdeliť do dvoch veľkých disjunktívnych tried: kompresia s strata informácie a kompresia bez straty informácie.
Kompresia bez straty informácií.
Tieto metódy kompresie sú pre nás v prvom rade zaujímavé, pretože sa používajú presne pri prenose textových dokumentov a programov, pri vydávaní dokončených prác zákazníkovi alebo pri vytváraní záložných kópií informácií uložených v počítači.
Metódy kompresie tejto triedy nemôžu dovoliť stratu informácií, preto sú založené iba na odstránení jej redundancie a informácie majú redundanciu takmer vždy (aj keď ju niekto predtým nezúžil). Keby nedošlo k žiadnej redundancii, nemalo by sa nič komprimovať.
Tu je jednoduchý príklad. Ruský jazyk má 33 písmen, desať číslic a asi tucet ďalších interpunkčných znamienok a ďalších špeciálnych znakov. Pre zaznamenaný text iba veľkými písmenami v ruštine (ako v telegramoch a rádiogramoch) by stačilo šesťdesiat rôznych významov. Každý znak je však obvykle kódovaný v bajte, ktorý obsahuje 8 bitov a môže vyjadrovať 256 rôznych kódov. Toto je prvý základ pre prepúšťanie. Pre náš „telegrafický“ text by stačilo šesť bitov na znak.
Tu je ďalší príklad. V medzinárodnom kódovaní znakov ASCII rovnaký počet bitov je pridelený na kódovanie ľubovoľného znaku (8), zatiaľ čo každý si už dlho uvedomuje, že najbežnejšie znaky majú zmysel kódovať menej znakov. Napríklad v „Morseovom kóde“ sa často nachádzajú písmená „E“ a „T“ jedným znakom (v tomto poradí ide o bodku a pomlčku). A také vzácne písmená ako „Yu“ (- -) a „Ts“ (- -) sú kódované štyrmi znakmi. Neefektívne kódovanie je druhým dôvodom redundancie. Programy, ktoré vykonávajú kompresiu informácií, môžu zadať svoje vlastné kódovanie (rôzne pre rôzne súbory) a ku komprimovanému súboru priradiť určitú tabuľku (slovník), z ktorej program rozbalenia zistí, ako sú v tomto súbore kódované určité symboly alebo ich skupiny. Nazývajú sa algoritmy založené na transkódovaní informácií huffmanov algoritmy.
Tretím dôvodom pre nadbytočnosť je prítomnosť duplicitných fragmentov. V textoch je to zriedkavé, ale v tabuľkách a grafoch je opakovanie kódov bežným javom. Napríklad, ak sa číslo 0 opakuje dvadsaťkrát za sebou, potom nemá zmysel umiestniť dvadsať nulových bajtov. Namiesto toho dali jednu nulu a koeficient 20. Takéto algoritmy založené na detekcii opakovaní sa nazývajú metódyRLE (beh dĺžka kódovanie).
Veľké opakujúce sa sekvencie rovnakých bajtov sa vyznačujú najmä grafickými ilustráciami, ale nie fotografické (existuje veľa šumu a susedné body sa výrazne líšia v parametroch), ale tie, ktoré umelci maľujú „hladkou“ farbou, ako v prípade animovaných filmov.
Stratová kompresia.
Kompresia so stratou informácií znamená, že po vybalení komprimovaného archívu dostaneme dokument, ktorý sa mierne líši od dokumentu, ktorý bol na začiatku. Je zrejmé, že čím väčší je stupeň kompresie, tým väčšia je veľkosť straty a naopak.
Takéto algoritmy samozrejme nie sú použiteľné pre textové dokumenty, databázové tabuľky a najmä pre programy. Akýmkoľvek spôsobom môžete prežiť menšie skreslenia obyčajného, \u200b\u200bneformátovaného textu, ale skreslenie aspoň jedného bitu v programe spôsobí, že bude úplne nefunkčný.
Zároveň existujú materiály, v ktorých je potrebné obetovať niekoľko percent informácií, aby sa získali desaťnásobné kompresie. Patria sem fotografické ilustrácie, videá a hudobné kompozície. Strata informácií pri kompresii a následnom vybalení v takýchto materiáloch sa vníma ako výskyt nejakého dodatočného „hluku“. Keďže však pri vytváraní týchto materiálov stále existuje určitý „hluk“, jeho mierny nárast nie vždy vyzerá kriticky a nárast veľkosti súboru je obrovský (10 - 15-krát v prípade hudby, 20 - 30-krát v prípade fotografií a videa).
Kompresné algoritmy so stratou informácií zahŕňajú také známe algoritmy ako JPEG a MPEG. Pri kompresii obrázkov sa používa algoritmus JPEG. Obrazové súbory komprimované touto metódou majú príponu jpg. Algoritmy MPEG sa používajú pri kompresii videa a hudby. Tieto súbory môžu mať rôzne prípony v závislosti od konkrétneho programu, ale najznámejšie sú súbory .MPG pre video a MP3 pre hudbu.
Algoritmy kompresie straty informácií sa používajú iba na spotrebiteľské úlohy. To napríklad znamená, že ak sa fotografia prenáša na prezeranie a hudba na prehrávanie, môžu sa takéto algoritmy použiť. Ak sa prenášajú na ďalšie spracovanie, napríklad na úpravu, potom nie je prípustná žiadna strata informácií v zdrojovom materiáli.
Rozsah prípustnej straty kompresie sa zvyčajne dá regulovať. To vám umožní experimentovať a dosiahnuť optimálny pomer veľkosti a kvality. Na fotografických ilustráciách, ktoré sa majú zobraziť na obrazovke, je strata 5% informácií zvyčajne nekritická a v niektorých prípadoch je možné tolerovať 20 až 25%.
Bezstratové kompresné algoritmy
Shannon Fenoov kód
Pre ďalšiu diskusiu bude vhodné predstaviť náš zdrojový súbor s textom ako zdrojom znakov, ktoré sa objavia jeden po druhom na jeho výstupe. Nevieme vopred, ktorý znak bude nasledovať, ale vieme, že s pravdepodobnosťou p1 sa objaví písmeno „a“, s pravdepodobnosťou p2 sa objaví písmeno „b“ atď.
V najjednoduchšom prípade budeme považovať všetky znaky textu za navzájom nezávislé, t.j. pravdepodobnosť výskytu nasledujúceho znaku nezávisí od hodnoty predchádzajúceho znaku. Nejde samozrejme o zmysluplný text, ale teraz uvažujeme o veľmi zjednodušenej situácii. V tomto prípade vyhlásenie „symbol nesie viac informácií, tým menšia je pravdepodobnosť jeho výskytu“.
Predstavme si text, ktorého abeceda pozostáva iba zo 16 písmen: A, B, C, D, D, E, F, Z, I, K, L, M, H, O, P, P. Každý z týchto znakov môže kódujte iba 4 bitmi: od 0000 do 1111. Teraz si predstavte, že pravdepodobnosť výskytu týchto znakov je rozdelená nasledovne:
Súčet týchto pravdepodobností je, samozrejme, jeden. Tieto symboly rozdelíme do dvoch skupín tak, aby celková pravdepodobnosť symbolov každej skupiny bola ~ 0,5 (obr.). V našom príklade to budú skupiny znaky AB a GR. Kruhy na obrázku, označujúce skupiny znakov, sa nazývajú vrcholy alebo uzly a štruktúra týchto uzlov sa nazýva binárny strom (B-strom). Každému uzlu priraďte vlastný kód a jeden uzol označte číslom 0 a druhý uzlom číslo 1.
Opäť rozdelíme prvú skupinu (AB) do dvoch podskupín tak, aby ich celkové pravdepodobnosti boli čo najbližšie k sebe. Pridajte číslo 0 do kódu prvej podskupiny a číslo 1 do kódu druhej podskupiny. 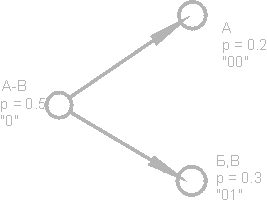
Túto operáciu zopakujeme, kým v každom vrchole nášho „stromu“ nezostane jeden symbol. Celý strom našej abecedy bude mať 31 uzlov.
Znakové kódy (krajne pravé uzly stromu) majú kódy nerovnakej dĺžky. Písmeno A, ktoré má pravdepodobnosť p \u003d 0,2 pre náš imaginárny text, je kódované iba dvoma bitmi a písmeno P (neznázornené na obrázku), ktoré má pravdepodobnosť p \u003d 0,013, je kódované šesťbitovou kombináciou.
Princíp je teda zrejmý - často sa vyskytujúce znaky sú kódované menším počtom bitov, zriedka sa vyskytujúce znaky sú kódované viac. Výsledkom bude, že priemerný počet bitov na znak sa bude rovnať
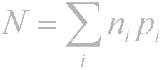
kde ni je počet bitov kódujúcich i-tý znak, pi je pravdepodobnosť výskytu i-teho znaku.
Huffmanov kód.
Algoritmus spoločnosti Huffman elegantne implementuje všeobecnú myšlienku štatistického kódovania pomocou súborov predpon a pracuje takto:
1. Píšeme do riadku všetky znaky abecedy vzostupne alebo zostupne podľa pravdepodobnosti ich výskytu v texte.
2. Dôsledne kombinujte dva symboly s najmenšou pravdepodobnosťou výskytu do nového zloženého symbolu, ktorého pravdepodobnosť výskytu sa rovná súčtu pravdepodobností jeho základných symbolov. Nakoniec postavíme strom, ktorého každý uzol má celkovú pravdepodobnosť všetkých uzlov pod ním.
3. Sledujeme cestu ku každému listu stromu a označujeme smer do každého uzla (napríklad doprava - 1, doľava - 0). Výsledná sekvencia poskytuje kódové slovo zodpovedajúce každému znaku (obr.).
Zostavte strom kódov pre správu s nasledujúcou abecedou:
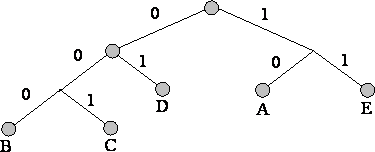
Nevýhody metód
Najväčší problém s kódmi, ako vyplýva z predchádzajúcej diskusie, je potreba mať tabuľky pravdepodobnosti pre každý typ komprimovateľných údajov. Toto nie je problém, ak je známe, že je komprimovaný anglický alebo ruský text; jednoducho poskytneme kódovač a dekodér s kódovým stromom vhodným pre anglický alebo ruský text. Všeobecne platí, že keď nie je známa pravdepodobnosť znakov pre vstupné údaje, Huffmanovy statické kódy fungujú neúčinne.
Riešením tohto problému je štatistická analýza kódovaných údajov, uskutočnená počas prvého prechodu dát, a na základe toho zostavenie kódového stromu. V skutočnosti sa kódovanie vykonáva druhým priechodom.
Ďalšou nevýhodou kódov je to, že minimálna dĺžka kódového slova pre nich nemôže byť menšia ako jeden, zatiaľ čo entropia správy môže byť 0,1 a 0,01 bitov / písmeno. V tomto prípade sa kód stáva nadbytočným. Problém je vyriešený použitím algoritmu na bloky znakov, ale potom je procedúra kódovania / dekódovania komplikovaná a kódový strom sa výrazne rozširuje, ktorý sa musí spolu s kódom nakoniec uložiť.
Tieto kódy nezohľadňujú vzťah medzi znakmi, ktoré sú prítomné takmer v akomkoľvek texte. Napríklad, ak vidíme písmeno q v anglickom texte, môžeme s istotou povedať, že písmeno u ho bude nasledovať.
Skupinové kódovanie - Run Length Encoding (RLE) - jeden z najstarších a najjednoduchších archivačných algoritmov. Kompresia v RLE sa uskutoční nahradením reťazcov identických bajtov pármi čítačov a hodnôt. („Červená, červená, ..., červená“ sa píše ako „N červená“).
Jedna z implementácií algoritmu je nasledovná: hľadajú najmenej často sa vyskytujúci bajt, nazývajú ho predponou a nahrádzajú reťazce identických znakov tromi výrazmi „predpona, počítadlo, hodnota“. Ak sa tento bajt nájde v zdrojovom súbore raz alebo dvakrát za sebou, nahradí sa dvojicou „predpona 1“ alebo „predpona 2“. Zostáva jeden nepoužitý pár „predpona 0“, ktorý sa môže použiť ako znak konca zabalených údajov.
Pri kódovaní súborov exe môžete vyhľadávať a baliť sekvencie vo formáte AxAyAzAwAt ..., ktoré sa často nachádzajú v zdrojoch (reťazce v kódovaní Unicode)
Medzi pozitívne aspekty algoritmu patrí skutočnosť, že pri práci nevyžaduje dodatočnú pamäť a je rýchlo vykonaný. Algoritmus sa používa vo formátoch PCX, TIFF, BMP. Zaujímavou črtou skupinového kódovania v PCX je to, že stupeň archivácie niektorých snímok sa môže výrazne zvýšiť len zmenou poradia farieb v obrazovej palete.
Kód LZW (Lempel-Ziv & Welch) je zďaleka jedným z najbežnejších bezstratových kompresných kódov. S pomocou kódu LZW sa kompresia vykonáva v takých grafických formátoch, ako sú TIFF a GIF, s pomocou úprav LZW, mnoho univerzálnych archivátorov vykonáva svoje funkcie. Algoritmus je založený na vyhľadávaní opakovaných sekvencií znakov vo vstupnom súbore, ktoré sú kódované v kombináciách s dĺžkou 8 až 12 bitov. Tento algoritmus má teda najvyššiu účinnosť pri textových súboroch a grafických súboroch, v ktorých sú veľké jednofarebné sekcie alebo opakujúce sa sekvencie pixelov.
Neprítomnosť straty informácií počas kódovania LZW viedla k rozsiahlemu použitiu formátu TIFF na jeho základe. Tento formát neukladá žiadne obmedzenia týkajúce sa veľkosti a farebnej hĺbky obrázka a je rozšírený napríklad pri tlači. Iný formát založený na LZW - GIF - je primitívnejší - umožňuje vám ukladať obrázky s farebnou hĺbkou najviac 8 bitov / pixel. Na začiatku súboru GIF je paleta - tabuľka, ktorá nastavuje zhodu medzi indexom farieb - číslom v rozsahu od 0 do 255 a skutočnou 24-bitovou hodnotou farby.
Algoritmy kompresie straty informácií
Algoritmus JPEG bol vyvinutý skupinou spoločností s názvom Joint Photographic Experts Group. Cieľom projektu bolo vytvoriť vysoko efektívny kompresný štandard pre čiernobiely aj farebný obraz a tento cieľ dosiahli vývojári. V súčasnosti sa JPEG často používa tam, kde sa vyžaduje vysoký stupeň kompresie - napríklad na internete.
Na rozdiel od algoritmu LZW je kódovanie JPEG stratové. Samotný kódovací algoritmus je založený na veľmi zložitej matematike, ale vo všeobecnosti sa dá opísať takto: obraz je rozdelený na štvorce s veľkosťou 8 x 8 pixelov, a potom je každý štvorec prevedený na sekvenčný reťazec 64 pixlov. Ďalej je každý takýto reťazec podrobený tzv. DCT transformácii, ktorá je jednou z odrôd diskrétnej Fourierovej transformácie. Spočíva v tom, že vstupnú sekvenciu pixelov je možné predstavovať ako súčet sínusoidálnych a kosínových zložiek s viacerými frekvenciami (tzv. Harmonické). V tomto prípade potrebujeme poznať iba amplitúdy týchto komponentov, aby sme obnovili vstupnú postupnosť s dostatočnou mierou presnosti. Čím viac harmonických komponentov poznáme, tým menšie bude rozdiely medzi originálnym a komprimovaným obrázkom. Väčšina kodérov JPEG vám umožňuje upraviť pomer kompresie. Toto sa dosiahne veľmi jednoduchým spôsobom: čím vyšší je kompresný pomer, tým menej harmonických bude predstavovať každý 64-pixlový blok.
Sila tohto typu kódovania je samozrejme vysoký kompresný pomer pri zachovaní pôvodnej farebnej hĺbky. Je to vlastnosť, ktorá spôsobila jeho rozsiahle použitie na internete, kde je zníženie veľkosti súboru prvoradé, v multimediálnych encyklopédiách, kde je potrebné uložiť čo najviac grafiky v obmedzenom množstve.
Negatívna vlastnosť tohto formátu je neodstrániteľná akýmkoľvek spôsobom, jeho prirodzené zhoršenie kvality obrazu. Je to smutná skutočnosť, ktorá neumožňuje jej použitie v tlači, kde je kvalita prvoradá.
Formát JPEG však nie je limitom dokonalosti v snahe zmenšiť veľkosť konečného súboru. V súčasnosti sa vykonáva intenzívny výskum v oblasti tzv. Vlnkovej transformácie (burst transform). Na základe najkomplikovanejších matematických princípov vám vlnkové enkodéry umožňujú získať väčšiu kompresiu ako JPEG s menšou stratou informácií. Napriek zložitosti matematiky vlnkovej transformácie je v implementácii softvéru jednoduchšia ako JPEG. Hoci algoritmy kompresie vlniek sú ešte stále v plienkach, majú veľkú budúcnosť.
Fraktálna kompresia
Fraktálna kompresia obrazu je algoritmus kompresie stratovej snímky založený na aplikácii iterovateľných funkčných systémov (IFS, ktoré sú zvyčajne afinitné transformácie) na obrazy. Tento algoritmus je známy tým, že v niektorých prípadoch umožňuje získať veľmi vysoké kompresné pomery (najlepšie príklady sú až 1000-krát s prijateľnou vizuálnou kvalitou) pre skutočné fotografie prírodných objektov, čo v zásade nie je k dispozícii pre iné algoritmy kompresie obrazu. Z dôvodu zložitej situácie s patentovaním sa algoritmus často nepoužíval.
Fraktálna archivácia je založená na skutočnosti, že pomocou koeficientov systému iterovateľných funkcií je obraz prezentovaný v kompaktnejšej podobe. Predtým, ako sa pozrieme na proces archivácie, pozrime sa, ako IFS vytvára obraz.
Presne povedané, IFS je súbor trojrozmerných afinných transformácií, ktoré prekladajú jeden obraz do druhého. Body v trojrozmernom priestore sa transformujú (súradnice x, súradnice y, jas).
Základom metódy fraktálneho kódovania je detekcia self-like sekcií v obraze. Možnosti aplikácie teórie iterovateľných funkčných systémov (IFS) na problém kompresie obrazu najprv preskúmali Michael Barnsley a Alan Sloan. Patentovali svoj nápad v rokoch 1990 a 1991. Jacquin predstavil metódu fraktálneho kódovania, ktorá využíva bloky subimágových domén a rozsahov, štvorcové bloky pokrývajúce celý obraz. Tento prístup sa stal základom pre väčšinu dnes používaných metód fraktálneho kódovania. Bol vyvinutý Yuvalom Fisherom a mnohými ďalšími výskumníkmi.
V súlade s touto metódou je obraz rozdelený do mnohých neprekrývajúcich sa čiastkových obrazových radov (rozsahové obrazy) a určuje sa veľa prekrývajúcich sa doménových obrazov (doménové obrazy). Pre každý blok pozície, algoritmus kódovania nájde najvhodnejší blok domény a afinnú transformáciu, ktorá prekladá tento blok domény do daného bloku klasifikácie. Štruktúra obrazu je mapovaná do systému hodnotiacich blokov, doménových blokov a transformácií.
Ide o toto: predpokladajme, že pôvodný obrázok je pevným bodom nejakého kompresného mapovania. Potom je možné namiesto tohto obrazu nejakým spôsobom zapamätať toto zobrazenie a na obnovenie stačí toto zobrazenie opakovane použiť na akýkoľvek počiatočný obrázok.
Banachovou vetou také iterácie vedú vždy k pevnému bodu, to znamená k pôvodnému obrazu. V praxi spočíva celý problém v nájdení najvhodnejšieho kompresného displeja z obrázka av kompaktnom úložisku. Algoritmy mapovania vyhľadávania (t.j. kompresné algoritmy) sú spravidla veľmi hrubou silou a vyžadujú veľké výpočtové náklady. Algoritmy obnovy sú zároveň pomerne efektívne a rýchle.
Stručne, spôsob navrhnutý Barnsleyom môže byť opísaný nasledovne. Obrázok je kódovaný niekoľkými jednoduchými transformáciami (v našom prípade afinitou), to znamená, že je určený koeficientmi týchto transformácií (v našom prípade A, B, C, D, E, F).
Napríklad obraz Kochovej krivky môže byť kódovaný štyrmi afinnými transformáciami, jedinečne ho určíme pomocou iba 24 koeficientov.
V dôsledku toho bude bod nevyhnutne ísť niekde vnútri čiernej oblasti v pôvodnom obrázku. Keď ste túto operáciu vykonali mnohokrát, vyplníme všetok čierny priestor, čím obnovíme obraz.

Najznámejšie sú dva obrázky získané pomocou IFS: Sierpinského trojuholník a Barnsleyova papraď. Prvá je definovaná tromi a druhá piatimi afinitnými transformáciami (alebo v našej terminológii šošovky). Každá konverzia je určená doslovne prečítanými bajtmi, zatiaľ čo obrázok skonštruovaný pomocou ich pomoci môže trvať niekoľko megabajtov.
Je zrejmé, ako funguje archivátor a prečo to trvá tak dlho. V skutočnosti je fraktálna kompresia hľadaním sebapodobných oblastí v obraze a určovaním parametrov afinných transformácií pre ne.
V najhoršom prípade, ak sa nepoužije optimalizačný algoritmus, bude to vyžadovať výpočet a porovnanie všetkých možných fragmentov obrazu rôznych veľkostí. Aj pri malých obrázkoch, ktoré sa berú do úvahy diskrétnosť, máme k dispozícii astronomické množstvo možností. Napríklad ostré zúženie tried transformácie, napríklad kvôli škálovaniu iba v určitom počte, neumožní dosiahnutie prijateľného času. Okrem toho sa stráca kvalita obrazu. Veľká väčšina štúdií v oblasti kompresie fraktálov je teraz zameraná na skrátenie času archivácie potrebného na získanie vysokokvalitných obrázkov.
Pre algoritmus fraktálnej kompresie, ako aj pre ďalšie algoritmy stratovej kompresie, sú veľmi dôležité mechanizmy, pomocou ktorých bude možné regulovať kompresný pomer a stupeň straty. Doteraz sa vyvinul dostatočne veľký súbor takýchto metód. Po prvé, je možné obmedziť počet transformácií a samozrejme poskytnúť kompresný pomer nie nižší ako pevná hodnota. Po druhé, môžete požadovať, aby v situácii, keď rozdiel medzi spracovaným fragmentom a jeho najlepším priblížením, bol vyšší ako určitá prahová hodnota, je tento fragment nevyhnutne rozdrvený (musí sa naň navinúť niekoľko šošoviek). Po tretie, je možné zakázať fragmentáciu fragmentov menších ako, povedzme, štyroch bodov. Zmenou prahových hodnôt a prioritou týchto podmienok môžete veľmi flexibilne kontrolovať kompresný pomer obrázka: od bitovej zhody po akýkoľvek kompresný pomer.
Porovnanie s JPEG
Najbežnejším algoritmom archivácie grafiky je dnes JPEG. Porovnať s fraktálne kompresie.
Najprv si všimneme, že jeden aj druhý pracujú s 8-bitovými (v odtieňoch šedej) a 24-bitovými farebnými obrázkami. Obaja sú algoritmy stratovej kompresie a poskytujú úzke archivačné pomery. Fraktálny algoritmus aj JPEG majú možnosť zvýšiť kompresný pomer zvýšením strát. Okrem toho sú oba algoritmy veľmi dobre paralelné.
Rozdiely začínajú, ak vezmeme do úvahy čas potrebný na archiváciu / rozbalenie algoritmov. Fraktálový algoritmus teda komprimuje stovky a dokonca tisícky krát dlhšie ako JPEG. Rozbalenie obrázka sa naopak uskutoční 5-10 krát rýchlejšie. Preto, ak bude obraz komprimovaný iba raz a bude prenášaný po sieti a mnohokrát rozbalený, je výhodnejšie použiť fraktálny algoritmus.
JPEG používa rozklad obrazu na kosínusové funkcie, preto sa straty v ňom (aj pri minimálnych stratách) objavujú vo vlnách a haloch na hranici ostrých farebných prechodov. Z tohto dôvodu sa im nepáči používať pri kompresii obrázkov, ktoré sú pripravené na vysoko kvalitnú tlač: tam sa tento efekt môže stať veľmi viditeľným.
Fraktálový algoritmus nemá túto nevýhodu. Okrem toho pri tlači obrázka musíte zakaždým vykonať mierku, pretože raster (alebo línia tlače) tlačového zariadenia sa nezhoduje s rastrom obrazu. Pri konverzii sa môže vyskytnúť aj niekoľko nepríjemných účinkov, proti ktorým sa dá bojovať buď programovým prispôsobením mierky obrázka (pre nízkonákladové tlačiarenské zariadenia, ako sú bežné laserové a atramentové tlačiarne), alebo vybavením tlačového zariadenia jeho vlastným procesorom, pevným diskom a sadou programov na spracovanie snímok (pre drahé fotografické sadzače). Ako asi viete, pri použití fraktálneho algoritmu takéto problémy prakticky nevznikajú.
Vytláčanie JPEG pomocou fraktálneho algoritmu pri rozšírenom používaní sa čoskoro nestane (prinajmenšom z dôvodu nízkej rýchlosti jeho archivácie), avšak v oblasti multimediálnych aplikácií v počítačových hrách je jeho použitie opodstatnené.
V prvej časti sa pozrieme na zvukové formáty. Čo je to FLAC, WavPack, TAK, Monkey's Audio, OptimFROG, ALAC, WMA, skrátiť, LA, TTA, LPAC, MPEG-4 ALS, MPEG-4 SLS, Real Lossless? Viete, koľko typov zvuku Súbory sa doteraz zaoberajú bezstratovými formátmi kompresie zvuku a hľadáme odpoveď na otázku o počte zvukových prípon na úplnom konci článku.
Najprv definujeme pojmy:
« algoritmus „Toto je presný predpis, ktorý definuje výpočtový proces, ktorý prechádza z premenných zdrojových údajov k požadovanému výsledku.“
« kodek (Anglický kodek, od kódovača / dekodéra - kódovača / dekodéra - kódovača / dekodéra alebo kompresora / dekompresora) - zariadenie alebo program schopný konvertovať dáta alebo signál. Kodeky môžu buď kódovať tok / signál (často na prenos, ukladanie alebo šifrovanie), alebo ho dekódovať, aby sa zobrazil alebo zmenil vo formáte, ktorý je pre tieto operácie vhodnejší. Kodeky sa často používajú pri digitálnom spracovaní videa a zvuku.
Väčšina kodekov pre zvukové a obrazové údaje využíva stratovú kompresiu na získanie prijateľnej veľkosti hotového (komprimovaného) súboru. Existujú tiež bezstratové kompresné kodeky. “
« Bezstratová kompresia (Anglická bezstratová kompresia údajov) je metóda kompresie informácií, pomocou ktorej sa môžu kódované informácie obnoviť s presnosťou na bity. V tomto prípade sa pôvodné údaje úplne obnovia z komprimovaného stavu. Pre každý typ digitálnej informácie existujú spravidla vlastné bezstratové kompresné algoritmy. ““
Bezstratová kompresia údajov sa používa, keď je dôležitá identita komprimovaných údajov s originálom. Bežným príkladom sú spustiteľné súbory, dokumenty a zdrojový kód. Programy využívajúce bezstratové kompresné formáty sa nazývajú archivátory, každý pozná populárne formáty súborov ZIP alebo RAR, unixový nástroj Gzip atď. Všetky tieto programy sa líšia v použitých algoritmoch (jeden alebo viac), a preto v rôznych komprimačných vlastnostiach rôznych súborov.
Časť I. - TEÓRIA:
Metódy kompresie alebo bezstratové kompresné algoritmy môžu byť distribuované podľa typu údajov, pre ktoré boli vytvorené. Existujú tri hlavné typy údajov: text, obrázky a zvuk.
V zásade sa akýkoľvek bezstratový viacúčelový algoritmus kompresie údajov (viacúčelový znamená, že dokáže spracovať ľubovoľný typ binárnych údajov) môže použiť pre akýkoľvek typ údajov, ale väčšina z nich je neefektívna pre každý hlavný typ. Napríklad zvukové údaje nie je možné dobre komprimovať pomocou algoritmu kompresie textu a naopak.
Medzi metódami kompresie možno uviesť: - entropickú kompresiu, slovníkové metódy, štatistické metódy. Každá metóda je vhodná pre určitý typ údajov a obsahuje množstvo algoritmov.
Entropická kompresia: Huffmanov algoritmus · Huffmanov adaptačný algoritmus · aritmetické kódovanie (Shannon - Fanoov algoritmus · interval) · Golombove kódy · Delta · univerzálny kód (Elias · Fibonacci)
Metódy slovník: RLE · Deflate · LZ (LZ77 / LZ78 · LZSS · LZW · LZWL · LZO · LZMA · LZX · LZRW · LZJB · LZT)
Medzi algoritmy štatistického modelu pre text (alebo binárne textové údaje, ako sú spustiteľné súbory) patria: Barrows-Wheelerova transformácia (predbežné spracovanie podľa triedenia blokov, ktoré robí kompresiu efektívnejšou) · LZ77 a LZ78 (pomocou DEFLATE) · LZW.
Iné: RLE · CTW · BWT · MTF · PPM · DMC
Názov sa často získava iba u dobre vyvinutých algoritmov, zatiaľ čo nedávny vývoj naznačuje (všeobecné použitie, štandardizácia atď.) Alebo nie je špecifikovaný vôbec.
Ale späť k našej téme. Pre kódovanie zvukových údajov vhodné algoritmy:
Huffmanov algoritmus (tiež používaný DEFLATE), aritmetické kódovanie
Apple bezstratové — ALAC (Apple Lossless Audio Codec)
Bezstratové kódovanie zvuku — tiež známy ako MPEG-4 ALS
Bezstratový zvukový kodek — FLAC
Meridian bezstratové balenie — MLP
Monkey's Audio — APE
OptimFROG
RealPlayer — RealAudio Lossless
Shorten — SHN
TAK — (T) om 's verlustfreier (A) udio (K) ompressor (German)
TTA — Skutočný zvuk bezstratový
WavPack — Wavpack bezstratový
Wma bezstratové — Windows Media Lossless
DTS — Priestorový zvuk DTS
Rodinná skupina algoritmov Lempel-Ziv, RLE (kódovanie run-length)
FLAC (Bezstratový zvukový kodek)
Monkey's Audio (APE)
TTA (True Audio)
TTE
Los Angeles(LosslessAudio)
RealAudio Lossless
WavPack a ďalšie
Ako ste si všimli, väčšina kodekov na bezstratovú kompresiu používa dva (niekedy aj viac) rôzne typy algoritmov: jeden generuje štatistický model pre vstupné údaje, druhý zobrazuje vstupné údaje v bitovej reprezentácii a pomocou tohto modelu získa „pravdepodobnostné“ (tj často sa vyskytujúce) údaje, ktoré sa používajú častejšie ako „neuveriteľné“. Prínos - zníženie veľkosti, zúčtovanie - viac času procesora potrebného na kódovanie / dekódovanie.
Keď sme prišli na malú teóriu, prejdeme k našim kodekom na kompresiu zvukových údajov, ktoré boli napísané mnohými: bezplatný bezstratový zvukový kodek, WavPack, TAK, opičí zvuk (.ape, apl), OptimFROG (.ofr), Apple bezstratový zvukový kodek, WMA, skrátiť (.SHN), bezstratový zvuk, skutočný zvuk, bezstratový predikčný zvukový kodér (.LPAC), MPEG-4 ALS, MPEG-4 SLS (.mp4), skutočne bezstratový alebo bezstratový RealAudio, bezstratový zvuk Windows Media, DTS .. A to zďaleka nie je všetko, veľa spoločností, ktoré vyrábajú profesionálne záznamové zariadenie, vynašlo a vyvíja svoje vlastné formáty.
Takéto veľké množstvo formátov kompresie zvukových údajov je spôsobených technickými nedokonalosťami platforiem (väčšina uvedených kodekov bola napísaná na konci 90. rokov), marketingu (v prípade ALAC) a matematické a vysokoškolské publikum sa veľmi zaujíma o algoritmy kompresie údajov.
Okrem vyššie uvedeného existuje (existovalo) veľké množstvo zabudnutých alebo nezaslúžene zvukových archivátorov a zvukových kodekov. Technické vlastnosti niektorých sú uvedené v tabuľke:
clickable:
Podrobnejšie sa budeme zaoberať iba tými, ktoré sa bežne používajú a ktoré sa v čase písania nachádzajú na internete. Je ich iba tucet.
Časť II - PRAX:
Zľava doprava: 1. modrá zóna SSDS (Sony Dynamic Digital Sound), 2. sivá zóna Dolby Digital (medzi dierovaním), 3. analógový zvuk (podľa záznamu) a 4. časový kód DTS (modrý).
A tu je nové porovnanie deviatich z vyššie uvedených údajov za rok 2009:
Časť III. - TESTOVANIE:
Porovnanie sa uskutočnilo na platforme:
CPU: DualCore Intel Core i3 530, 2933 MHz (x86, x86-64, MMX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2)
Základná doska. doska: Asus P7H55-V
RAM: 2x2Gb DDR3-1333
HDD: Seagate SATA 160 GB 8 MB vyrovnávacia pamäť (systém), Hitachi SATA-II 500 GB 16 MB vyrovnávacia pamäť (zdroj), Hitachi SATA-II 1 000 GB 32 MB vyrovnávacia pamäť (cieľ)
1. Bezstratový zvuk (LA) - Tento veľmi starý kodek (2004) sa stal nesporným víťazom kompresie. Zároveň treba poznamenať, že rýchlosť kódovania je celkom prijateľná (v porovnaní s rovnakým OptimFROG alebo WavPack), ako aj dostatočná rýchlosť dekódovania. Aj keď súbor LA nebol dekódovaný pomocou doplnku foo_benchmark, hral dokonale, bez toho, aby došlo k otrasom alebo posúvaniu.
Dá sa len čudovať, prečo autor opustil taký krásny kodek bez otvorenia zdrojového kódu.
2. OptimFROG - Nie príliš ďaleko za LA. Jeho rýchlosť sa však dá len ťažko nazvať rýchlou. Okrem toho je veľkým oneskorením pri listovaní v súbore nepríjemný okamih - niekedy je to veľmi nepríjemné.
3. Monkey's Audio - Populárny kodek, ktorý je náročný na zdroje. Poskytuje skutočne vysokú kompresiu, ale opäť má problémy s posúvaním. (Zdá sa, že autor testu uchytil súbor pomocou možnosti „Insane“, ktorá je stále plná straty údajov).
4. TAK - Tento aktívne vyvinutý kodek neprestáva uspokojovať. Ak vezmete do úvahy všetky tri parametre (kompresia, kódovanie, dekódovanie), vyzerá TAK najatraktívnejšie. Vysoká rýchlosť prevádzky sa vysvetľuje aktívnym využívaním optimalizácie procesorov (vrátane SSSE3). A použitie dvoch jadier umožňuje takmer dvojnásobné zvýšenie rýchlosti kódovania! V prípade TAK je teda najnápadnejšia výhoda využívania moderných procesorov.
5. WavPack - aby som bol úprimný, neviem, prečo si tento kodek získal popularitu. Výsledkom kódovania so strednou kompresiou sú výsledky porovnateľné s programom FLAC a použitie režimov vysokej kompresie vedie k neodôvodnenému zníženiu rýchlosti. Hoci hlavnou výhodou tohto kodeku je jeho široká podpora a funkčnosť (vrátane podpory viackanálového zvuku, hybridného režimu), pripomínam vám však, že túto stránku problému v tomto teste nezohľadňujeme.
6. Skutočný zvuk (TTA) - tu by sa malo poznamenať, s výnimkou veľmi vysokej rýchlosti kódovania a prijateľného kompresného pomeru (mierne vyšší ako u FLAC). Okrem toho nemožno dekódovaciu rýchlosť označovať ako veľmi vysokú.
7. FLAC- kompresný pomer je priemerný, ale rýchlosť dekódovania je potešujúca. Je pravda, že hlavným dôvodom vedúceho tohto kodeku medzi verejnosťou je otvorený zdroj a v dôsledku toho najširšia podpora hardvéru a softvéru.
8. Apple Lossless (ALAC) - Jeden z tých kodekov, ktoré nie sú pozoruhodné, ale vývojári ich naďalej implantovali (v tomto prípade Apple). Nízka rýchlosť kompresie a dekódovania. Rýchlosť kompresie je priemerná. Okrem používateľov prehrávača iPod nemajú na výber.
9. Wma bezstratové - Prípad podobný ALAC, ale tu ide o obrovskú spoločnosť Microsoft. Ešte nižšia kompresia, priemerná kompresná rýchlosť. Dekódovacia rýchlosť je pomerne vysoká. Je ťažké si predstaviť prípad, v ktorom by bolo potrebné použiť tento konkrétny bezstratový kodek.
Časť IV - VŠEOBECNÉ ZÁVERY:
Výber je jednoduchý a pozostáva z dvoch bodov:
Ak je miesto na disku dôležité, použijeme zvuk Monkey's Audio (ARE komprimuje o 8-12% lepšie ako FLAC, ktorý na 1 TB disku bude mať asi 100 GB alebo asi 300 štandardných albumov CD). To isté platí pre distribúciu na internete. je v audio formáte Monkey s možnosťou extra vysokej kompresie. Nepoužívam rôzne LA a iné, pretože zisk z ich použitia v porovnaní s Monkey's Audio je malý.
Ak je kompatibilita s rôznymi prehrávačmi a multimediálnymi kúskami železa, ktoré pracujú pod Linuxom, dôležitá a nielen používa FLAC. Aj keď IMHO pre hráčov je celkom vhodný pre seba a pre MP3, pretože hlavná vec nie je zvuk, ale MUSIC!
V budúcnosti sa pozrieme na vývoj TTA, ale podľa môjho subjektívneho názoru je TTA už neskoro v prípade parnej lokomotívy do „vzdialenosti bezdomovcov“.
Pre "ovládače maku" a "Ai-Fonts" - pokiaľ je mi známe, je voľba jedna - tamburína a tance okolo rôznych transkodérov vo formáte ALAC.
Pamätajte, že súbory môžete vždy prenášať z jedného kodeku do druhého a bez straty kvality sú to bezstratové kompresné kodeky na rozdiel od stratových kompresných kodekov.
„Lyrické“ číslo degresie JEDNO.
Pre "Udifilov". Rozdiely vo zvukových formátoch - NIE! „Nie prirodzená farba vysokej“, „ľahká nečitateľnosť úderu“, napríklad „závoj stredu so rozmazaním scény“ - toto je vo vašom SYSTÉME. Kodeky sa neprehrávajú, dekódujú, nepridávajú nič a nič neodstraňujú.
Digresia je „lyrické“ číslo DVA.
Tento článok je určený pre milovníkov hudby a hudobných zberateľov - začiatočníkov a stredných roľníkov, toho istého milovníka hudby a zberateľa.
Gurams, Kvods, Sensei a ďalší veľkí kormidelníci zo sveta zvuku, ako aj militantné Udifily, sa tu nebudú zaujímať. Napíšte svoj článok „s blackjackom a kodekmi“.
Zaujímavé informácie:
V súčasnosti je registrovaných 1154 prípon súborov takým spôsobom, ktorý súvisí so zvukovými údajmi!
zdroj:
wiki.hydrogenaudio.org/
ru.wikipedia.org/
ako aj oficiálne stránky programu.
Dobrý deň.
Dnes sa chcem dotknúť témy bezstratovej kompresie údajov. Napriek tomu, že už boli články o náboji venované určitým algoritmom, chcel som o tom hovoriť trochu podrobnejšie.
Pokúsim sa matematický popis aj popis uviesť obvyklým spôsobom, aby si každý mohol nájsť niečo zaujímavé pre seba.
V tomto článku sa dotknem základných momentov kompresie a hlavných typov algoritmov.
Kompresia. Je to potrebné dnes?
Áno, samozrejme. Všetci samozrejme chápeme, že teraz máme prístup k veľkoobjemovým úložným médiám aj k kanálom vysokorýchlostného prenosu údajov. Zároveň však narastá objem prenášaných informácií. Ak sme pred niekoľkými rokmi sledovali filmy s veľkosťou 700 megabajtov, ktoré sa zmestia na jeden disk, dnes filmy v kvalite HD môžu obsadzovať desiatky gigabajtov.
Výhody komprimácie všetkého a všetkého samozrejme nie sú toľko. Stále však existujú situácie, keď je kompresia mimoriadne užitočná, ak nie nevyhnutná.
- Posielanie dokumentov e-mailom (najmä veľké objemy dokumentov pomocou mobilných zariadení)
- Pri publikovaní dokumentov na webových stránkach je potrebné šetriť prevádzku
- Pri zmene alebo pridaní úložného priestoru ušetrite miesto na disku. Napríklad k tomu dôjde v prípadoch, keď nie je ľahké získať rozpočet na kapitálové výdavky a na disku nie je dostatok miesta.
Samozrejme, môžete prísť na oveľa viac rôznych situácií, v ktorých bude kompresia užitočná, ale týchto pár príkladov je pre nás dosť.
Všetky metódy kompresie je možné rozdeliť do dvoch veľkých skupín: stratová kompresia a bezstratová kompresia. Bezstratová kompresia sa používa v prípadoch, keď je potrebné obnoviť informácie presne podľa bitov. Tento prístup je jediný možný pri kompresii napríklad textových údajov.
V niektorých prípadoch však nie je potrebné presné obnovenie informácií a je dovolené používať algoritmy, ktoré implementujú stratovú kompresiu, ktorá sa na rozdiel od bezstratovej kompresie zvyčajne ľahšie implementuje a poskytuje vyšší stupeň archivácie.
Prejdime teda k bezstratovým kompresným algoritmom.
Univerzálne metódy bezstratovej kompresie
Vo všeobecnosti existujú tri základné možnosti, na ktorých sú postavené kompresné algoritmy.
Prvá skupina metódy - prúdová konverzia. Znamená to opis nových prichádzajúcich nekomprimovaných údajov prostredníctvom už spracovaných údajov. V tomto prípade nie sú vypočítané žiadne pravdepodobnosti, kódovanie znakov sa vykonáva iba na základe údajov, ktoré už boli spracované, napríklad v metódach LZ (pomenovaných po Abraham Lempel a Jacob Ziva). V tomto prípade sa druhý a ďalší výskyt podreťazca, ktorý je už známy kodéru, nahradí odkazmi na jeho prvý výskyt.
Druhá skupina metódy sú štatistické metódy kompresie. Tieto metódy sa ďalej delia na adaptívne (alebo tokové) a blokové.
V prvej (adaptívnej) verzii je výpočet pravdepodobnosti nových údajov založený na údajoch už spracovaných počas kódovania. Tieto metódy zahŕňajú adaptívne verzie algoritmov Huffman a Shannon-Fano.
V druhom prípade (blok) sa štatistika každého dátového bloku počíta osobitne a pridá sa k najkomprimovanejšiemu bloku. Patria medzi ne statické verzie Huffmanovej, Shannon-Fanoovej metódy a aritmetické kódovanie.
Tretia skupina metódy sú takzvané metódy blokovej konverzie. Prichádzajúce údaje sú rozdelené do blokov, ktoré sa potom transformujú ako celok. Niektoré metódy, najmä založené na permutácii blokov, však nemusia viesť k významnému (alebo dokonca akémukoľvek) zníženiu množstva údajov. Po takomto spracovaní sa však dátová štruktúra výrazne zlepšuje a následná kompresia inými algoritmami je úspešnejšia a rýchlejšia.
Všeobecné zásady, na ktorých je založená kompresia údajov
Všetky metódy kompresie údajov sú založené na jednoduchom logickom princípe. Ak si predstavíme, že najčastejšie sa vyskytujúce prvky sú kódované kratšími kódmi a menej často sa vyskytujúce sú kódované dlhšími, potom na uloženie všetkých údajov je potrebných menej miesta, ako keby boli všetky prvky reprezentované kódmi rovnakej dĺžky.
Presný vzťah medzi frekvenciami výskytu prvkov a optimálnymi dĺžkami kódu je opísaný v takzvanej Shannonovej zdrojovej kódovacej vete, ktorá definuje bezstratový maximálny kompresný limit a Shannonovu entropiu.
Trochu matematiky
Ak je pravdepodobnosť výskytu prvku s i rovná p (s i), potom bude najvýhodnejšie predstavovať tento prvok - log 2 p (s i) bitov. Ak je počas kódovania možné zabezpečiť, aby sa dĺžka všetkých prvkov znížila na log 2 p (s i) bitov, potom dĺžka celej kódovanej sekvencie bude minimálna pre všetky možné spôsoby kódovania. Okrem toho, ak je rozdelenie pravdepodobnosti všetkých prvkov F \u003d (p (s i)) nezmenené a pravdepodobnosti prvkov sú vzájomne nezávislé, potom je možné priemernú dĺžku kódov vypočítať ako
Táto hodnota sa nazýva entropia rozdelenia pravdepodobnosti F alebo entropia zdroja v danom časovom okamihu.
Pravdepodobnosť výskytu prvku však obyčajne nemôže byť nezávislá, naopak, záleží na niektorých faktoroch. V tomto prípade pre každý nový kódovaný prvok si bude mať pravdepodobnostné rozdelenie F nejakú hodnotu Fk, to znamená pre každý prvok F \u003d Fk a H \u003d Hk.
Inými slovami, môžeme povedať, že zdroj je v stave k, čo zodpovedá určitej skupine pravdepodobností p k (s i) pre všetky prvky s i.
Preto, vzhľadom na túto opravu, môžeme vyjadriť priemernú dĺžku kódov ako
Kde P k je pravdepodobnosť nájdenia zdroja v stave k.
V tejto fáze vieme, že kompresia je založená na nahradení často sa vyskytujúcich prvkov krátkymi kódmi a naopak, a vieme tiež určiť priemernú dĺžku kódov. Čo je to kód, kódovanie a ako k tomu dôjde?
Kódovanie bez pamäte
Kódy bez pamäte sú najjednoduchšie kódy, na základe ktorých je možné údaje komprimovať. V bezchybnom kóde je každý znak v kódovanom dátovom vektore nahradený kódovým slovom z predpony sady binárnych sekvencií alebo slov.
Podľa môjho názoru to nie je najjasnejšia definícia. Zvážte túto tému podrobnejšie.
Nechajte nejakú abecedu ![]() pozostáva z určitého (konečného) počtu písmen. Nazývame každú konečnú postupnosť znakov z tejto abecedy (A \u003d a 1, a 2, ..., a n) jedným slovoma číslo n je dĺžka tohto slova.
pozostáva z určitého (konečného) počtu písmen. Nazývame každú konečnú postupnosť znakov z tejto abecedy (A \u003d a 1, a 2, ..., a n) jedným slovoma číslo n je dĺžka tohto slova.
Nech je uvedená aj iná abeceda ![]() , Podobne označte slovo v tejto abecede ako B.
, Podobne označte slovo v tejto abecede ako B.
Predstavujeme ďalšie dve notácie pre súbor všetkých neprázdnych slov v abecede. Dovoliť - počet neprázdnych slov v prvej abecede a - v druhom.
Dovolí sa aj mapovanie F, ktoré spojí s každým slovom A z prvej abecedy slovo B \u003d F (A) z druhého písmena. Potom sa zavolá slovo B. kód budú sa volať slová A a bude sa hovoriť z pôvodného slova do jeho kódu kódovanie.
Keďže slovo môže pozostávať aj z jedného písmena, môžeme identifikovať korešpondenciu písmen prvej abecedy a zodpovedajúcich slov od druhého:
a 1<-> B 1
a 2<-> B 2
…
a n<-> B n
Tento zápas sa volá systéma označujú ∑.
V tomto prípade sa volajú slová B1, B2, ..., Bn základné kódya typ kódovania s pomocou - abecedné kódovanie, Väčšina z nás sa samozrejme stretla s takýmto kódovaním, aj keď nevieme všetko, čo som opísal vyššie.
Takže sme sa rozhodli pre koncepty abeceda, slovo, kód, a kódovanie, Teraz predstavíme tento koncept prefix.
Nech má slovo B tvar B \u003d B "B" "Potom sa B" nazýva začiatok, alebo prefix slová B a B "" - jej koniec. Toto je pomerne jednoduchá definícia, ale treba poznamenať, že pre každé slovo B možno určité prázdne slovo ʌ („medzera“) aj samotné slovo B považovať za začiatočné aj cieľové slovo.
Priblížime sa teda k pochopeniu definície kódov bez pamäte. Poslednú definíciu, ktorú musíme pochopiť, je predpona. Schéma ∑ má vlastnosť predpony, ak pre akékoľvek 1≤i, j≤r, i ≠ j slovo Bi nie je predponou slova Bj.
Jednoducho povedané, predpona je konečná množina, v ktorej žiadny prvok nie je predponou (alebo začiatkom) žiadneho iného prvku. Jednoduchým príkladom takejto množiny je napríklad regulárna abeceda.
Takže sme prišli na základné definície. Ako teda prebieha samotné pamäťové kódovanie?
Vyskytuje sa v troch fázach.
- Zostaví sa abeceda Ψ znakov pôvodnej správy a znaky abecedy sa zoradia zostupne podľa pravdepodobnosti výskytu v správe.
- Každý symbol ai z abecedy Ψ je spojený s určitým slovom B i z množiny predpony Ω.
- Každý znak je kódovaný, po ktorom nasleduje kombinácia kódov do jedného dátového toku, ktorý bude výsledkom kompresie.
Jedným z kanonických algoritmov, ktoré ilustrujú túto metódu, je Huffmanov algoritmus.
Huffmanov algoritmus
Huffmanov algoritmus používa frekvenciu výskytu rovnakých bajtov vo vstupnom dátovom bloku a porovnáva časté bloky reťazca bitov kratších dĺžok a naopak. Tento kód je minimálne zbytočný. Zvážte prípad, keď abeceda výstupného toku, bez ohľadu na vstupný tok, pozostáva iba z 2 znakov - nula a jeden.
Predovšetkým pri kódovaní pomocou Huffmanovho algoritmu musíme skonštruovať obvod ∑. Toto sa vykonáva takto:
- Všetky písmená vstupnej abecedy sú usporiadané v zostupnom poradí pravdepodobnosti. Všetky slová z abecedy výstupného toku (to, čo kódujeme) sa spočiatku považujú za prázdne (spomínam si, že abeceda výstupného toku pozostáva iba zo znakov (0,1)).
- Dva znaky a-1 a j vstupného toku, ktoré majú najmenšiu pravdepodobnosť výskytu, sa spoja do jedného „pseudo-symbolu“ s pravdepodobnosťou p rovná súčtu pravdepodobností ich základných znakov. Potom pripojíme 0 na začiatok slova Bj-1 a 1 na začiatok slova Bj, ktoré budú následne znakovými kódmi a-1 a j.
- Tieto znaky odstránime z abecedy pôvodnej správy, ale do tejto abecedy pridáme vygenerovaný pseudo-symbol (prirodzene by sa mal vložiť do abecedy na správnom mieste, berúc do úvahy jej pravdepodobnosť).
Kroky 2 a 3 sa opakujú, až kým v abecede zostane iba 1 pseudo-znak obsahujúci všetky pôvodné znaky abecedy. Navyše, pretože v každom kroku a pre každý znak sa zodpovedajúce slovo Bi zmení (pridaním jedného alebo nuly), po dokončení tohto postupu bude určitý kód Bi zodpovedať každému počiatočnému znaku abecedy ai.
Pre lepšiu ilustráciu uvážte malý príklad.
Predpokladajme, že máme abecedu skladajúcu sa iba zo štyroch znakov - (a 1, a 2, a 3, a 4). Predpokladajme tiež, že pravdepodobnosť výskytu týchto symbolov je rovnaká, p1 \u003d 0,5; p2 \u003d 0,24; p3 \u003d 0,15; p 4 \u003d 0,11 (súčet všetkých pravdepodobností je zjavne rovný jednej).
Zostavíme schému pre túto abecedu.
- Skombinujte tieto dva znaky s najmenšou pravdepodobnosťou (0,11 a 0,15) do p "pseudo-znaku".
- Kombinujeme tieto dva znaky s najmenšou pravdepodobnosťou (0,24 a 0,26) do p pseudo-znaku.
- Odstránime kombinované znaky a výsledný pseudo-znak vložíme do abecedy.
- Nakoniec skombinujte zostávajúce dva znaky a získajte vrchol stromu.
Ak tento proces ilustrujete, dostanete niečo ako toto:
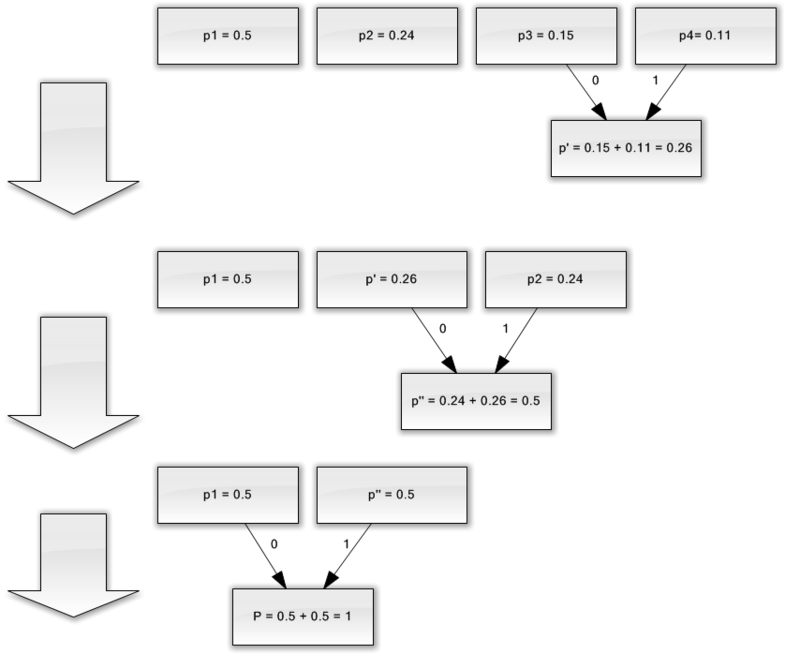
Ako vidíte, pri každom zlúčení priradíme znakom 0, ktoré sa majú zlúčiť.
Keď sa teda vytvorí strom, môžeme ľahko získať kód pre každý znak. V našom prípade budú kódy vyzerať takto:
a 1 \u003d 0
a 2 \u003d 11
a 3 \u003d 100
a 4 \u003d 101
Pretože žiadny z týchto kódov nie je predponou žiadneho iného (to znamená, že máme notoricky známe predpony), môžeme jedinečne identifikovať každý kód vo výstupnom toku.
Dosiahli sme teda, že najčastejší znak je kódovaný najkratším kódom a naopak.
Ak predpokladáme, že spočiatku sa na uloženie každého znaku použil jeden bajt, potom môžeme vypočítať, koľko sme boli schopní redukovať údaje.
Predpokladajme, že na vstupe sme mali reťazec 1 000 znakov, v ktorom sa znak 1 vyskytol 500-krát, 2 240, 3 150 a 4 110-krát.
Tento reťazec spočiatku zaberal 8 000 bitov. Po kódovaní dostaneme reťazec s dĺžkou ip i l i \u003d 500 * 1 + 240 * 2 + 150 * 3 + 110 * 3 \u003d 1760 bitov. Takže sme boli schopní komprimovať dáta 4,54 krát, pričom na kódovanie každého symbolu toku sme strávili priemerne 1,76 bitov.
Dovoľte mi pripomenúť, že podľa Shannona je priemerná dĺžka kódov ![]() , Nahradením našich pravdepodobnostných hodnôt do tejto rovnice dostaneme priemernú dĺžku kódu rovnú 1.75496602732291, čo je veľmi, veľmi blízko k dosiahnutému výsledku.
, Nahradením našich pravdepodobnostných hodnôt do tejto rovnice dostaneme priemernú dĺžku kódu rovnú 1.75496602732291, čo je veľmi, veľmi blízko k dosiahnutému výsledku.
Malo by sa však pamätať na to, že okrem samotných údajov musíme uložiť aj kódovaciu tabuľku, ktorá mierne zvýši konečnú veľkosť kódovaných údajov. Je zrejmé, že v rôznych prípadoch je možné použiť rôzne variácie algoritmu - napríklad je niekedy efektívnejšie použiť preddefinovanú pravdepodobnostnú tabuľku a niekedy je potrebné ju dynamicky kompilovať pomocou komprimovateľných údajov.
záver
V tomto článku som sa pokúsil hovoriť o všeobecných zásadách, podľa ktorých dochádza ku bezstratovej kompresii, a tiež som skúmal jeden z kanonických algoritmov - Huffmanovo kódovanie.
Ak je tento článok podľa chuti habro komunity, rád napíšem pokračovanie, pretože v súvislosti so bezstratovou kompresiou je veľa zaujímavejších vecí; sú to klasické algoritmy, ako aj predbežné transformácie údajov (napríklad Burroughs-Wheelerova transformácia), a samozrejme špecifické algoritmy na kompresiu zvuku, videa a obrázkov (podľa môjho názoru najzaujímavejšia téma).
literatúra
- Vatolin D., Ratushnyak A., Smirnov M. Yukin V. Metódy kompresie údajov. Archivátory zariadenia, kompresia obrázkov a videa; ISBN 5-86404-170-X; 2003 rok
- D. Salomon. Kompresia dát, obrazu a zvuku; ISBN 5-94836-027-X; 2004.
Kodeky, ktoré komprimujú zvuk bez straty, sa stali vo svete prenosných MP3 prehrávačov relatívne populárne. Faktom je, že tieto kodeky si nemôžu dovoliť také veľké kompresné pomery, ktoré sa môžu pochváliť kodekmi, ktoré komprimujú zvuk so stratou kvality. Veľké množstvo pamäte sa stalo široko dostupnou pre užívateľov MP3 prehrávačov iba za posledné tri alebo štyri roky - a s príchodom veľkých objemov pamäte v MP3 prehrávačoch sa stala bezstratovou kompresiou hudby populárna. Tí, ktorí chceli počúvať hudbu bez straty kvality, to samozrejme vždy robili (napríklad pomocou prehrávačov zvukových diskov CD) a v súčasnosti si každý (prirodzene, vzhľadom na podporu príslušných kodekov ich hráčmi) môže vyskúšať bezstratové kodeky v akcii ,
Hlavný rozdiel medzi kodekmi, ktoré komprimujú zvukové údaje bez straty kvality, z kodekov, ktoré sa komprimujú so stratou, spočíva v tom, že kodeky bez straty kvality neodstránia informácie zo zvukového toku, ktoré môžu byť považované za nadbytočné, keď sú komprimované so stratou. Hlavnou úlohou kodeku Lossless je čo najviac skomprimovať pôvodné zvukové informácie bez toho, aby sa stratila jediná bitová informácia.
Situácia s podporou bezstratových kodekov je v súčasnosti taká, že najrozšírenejšou podporou je kodek ALAC, ktorý priamo súvisí s Apple a jeho hráčmi. Zvyšok kodekov stále podporuje niekoľko hráčov. Niekedy, aby hráč podporoval kodek, vyžaduje prehrávač blikanie prehrávača a pravdepodobne najslávnejší firmvér pre hráčov, ktorí podporujú bezstratové kodeky, RockBox je alternatívny a nie oficiálny firmvér.
Pri práci s bezstratovými kodekmi sa môžu zobraziť tzv. Súbory Cue alebo indexové karty súborov. Cue-súbory sú distribuované napríklad spolu so súbormi FLAC alebo APE, menej často - so súbormi MP3 a WAV, čo je jeden veľký súbor (asi 300 MB), v ktorom je uložený celý album. Cue - file - obsahuje informácie o rozdelení veľkého súboru na stopy a názvy týchto stôp. Je pohodlnejšie pracovať s jednotlivými súbormi, aj keď sa dostanete do rúk, povedzme, veľký súbor FLAC so súborom CUE, na základe informácií obsiahnutých v súbore CUE, zdrojový súbor možno rozdeliť do samostatných stôp - zvážime softvér, ktorý môže tento problém vyriešiť.
Začnime s popisom formátov bezstratovej kompresie údajov s populárnym formátom FLAC.
FLAC
FLAC (Free Lossless Audio Codec) je bezstratový formát kompresie zvuku vyvinutý spoločnosťou Xiph. Org Foundation. Toto je úplne zadarmo formát, ktorý môže použiť každý.
Prevádzka systému FLAC a ďalších kodekov, ktoré ukladajú bezstratové zvukové údaje, sa podobá činnosti konvenčných archivátorov. V dôsledku špeciálnych algoritmov je však účinnosť takýchto kodekov pri kompresii zvukových informácií oveľa vyššia ako pri bežných archivátoroch.
Formát FLAC bol vyvinutý ako formát toku - informácie v súbore FLAC sú rozdelené do rámcov (rámcov), z ktorých každý môže byť dekódovaný oddelene od ostatných rámcov.
FLAC je zvyčajne schopný komprimovať zdrojový súbor, napríklad kvalitu audio CD, o 40-50%. Výsledkom je, že dátový tok výsledného záznamu sa rovná asi 800 Kbit / s.
Vo formáte FLAC je možné uložiť CD tak, aby ste v prípade potreby mohli pôvodný disk úplne znovu vytvoriť - to je veľmi výhodné pre tých, ktorí chcú vytvárať digitálne kópie svojich CD s možnosťou následného obnovenia.
Rýchlosť kódovania a dekódovania súborov FLAC nie je rovnaká. Rýchlosť kódovania závisí od úrovne kompresie a od rýchlosti systému - pri vysokých úrovniach kompresie môže byť pomerne pomalá. Dekódovanie je však veľmi rýchle - moderné prehrávače MP3 s ním ľahko zvládnu.
Vďaka možnosti bezplatného použitia môžete pracovať s programom FLAC na základe takmer akéhokoľvek moderného operačného systému, čím viac formátu MP3 prehrávače podporuje tento formát.
Kódovanie do formátu FLAC
Pomôcku na kódovanie súborov FLAC si môžete stiahnuť na stránke. Zahŕňa samotný kodek a tzv. Frontend - softvérový shell pre kodek. Veľkosť distribúcie trvá asi 2,5 MB. Práca s kodekom je jednoduchá: do okna programu pridáte zaujímavé súbory (obr. 4.1.). Pomocou tlačidla Pridať súbory nakonfigurujte možnosti kódovania a kliknite na tlačidlo Kódovať - \u200b\u200bprogram vytvorí súbor FLAC.
Obr. 4.1.
Pozrime sa na najdôležitejšie nastavenia kodeku. Najprv sa pozrime na skupinu parametrov kódovania Možnosti.
Parameter Level je zodpovedný za úroveň kompresie údajov. Môže sa meniť od 0 do 8. Čím vyššia je úroveň kompresie, tým je menší hotový súbor, ale čím dlhší je čas potrebný na zakódovanie súborov. Na rýchlych počítačoch môže byť rozdiel medzi úrovňou 0 a úrovňou 8 pri kódovaní napríklad 30-megabajtový súbor WAV niekoľko sekúnd. Veľkosť sa líši asi o 10% od pôvodnej veľkosti súboru. Mali by ste experimentovať s touto voľbou na vašom počítači - možno, ak kódujete niekoľko stoviek súborov, mali by ste radšej nižšiu úroveň kompresie než vyššiu rýchlosť práce.
Parameter Verify inštruuje kodér na kontrolu výstupných súborov.
Parameter Pridať značky pridá značky do hotového súboru (napríklad môžu obsahovať názov skladby, autora atď.) - môžete ich nakonfigurovať kliknutím na tlačidlo Tag Conf. (Prispôsobenie značiek).
Parameter Replaygain pridá do súborov parameter, ktorý označuje úroveň hlasitosti súboru. Ak je nastavený parameter „Vstupné vstupné súbory ako jeden album“, všetky položky v albume budú znieť na rovnakej hlasitosti.
Skupina parametrov Všeobecné voľby obsahuje dva parametre. Možno by sa tu mal uviesť parameter OGG-Flac. Ak sa tento parameter vynuluje, dáta FLAC sa zabalia do štandardného kontajnera FLAC. Ak plánujete počúvať iba prijaté súbory FLAC, tento parameter nemôžete nastaviť a ak sú vaše plány pre tieto súbory rozsiahlejšie - napríklad ich plánujete upravovať, používať na vkladanie do filmov, je najlepšie povoliť parameter Ogg-FLAC.
Parameter Output Directory obsahuje cestu k adresáru, kde budú obsiahnuté výstupné súbory.
Skupina parametrov dekódovania má parameter december. Prostredníctvom chýb - Nastavte ho, ak chcete dekódovať súbor, aj keď sa vyskytnú chyby počas dekódovania. Dekódovanie je opak kódovania - to znamená, že môžete dekódovať súbory FLAC tak, že ich zmeníte na súbory WAV. Na dekódovanie budete samozrejme musieť do okna programu pridať súbory FLAC.
Po nakonfigurovaní všetkého stačí kliknúť na tlačidlo Kódovať a vytvoriť súbory FLAC, alebo ak chcete dekódovať existujúce súbory FLAC, kliknite na tlačidlo Dekódovať.
Okrem vyššie uvedeného môžu FLAC kódovať aj ďalšie programy. Napríklad, už vám to vieme ImTOO Audio Encoder - na kódovanie do formátu FLAC stačí vybrať zo zoznamu formátov (obr. 4.2.), Potom môžete okamžite kliknúť na tlačidlo Vystrihnúť alebo to urobiť o niečo neskôr, po nastavení názvov súborov.

