07.09.2019
Typy kódovania. Kódovanie pre alkoholizmus - liečba a dôsledky. Účinné metódy kódovania závislosti od alkoholu. Dôsledky kódovania z alkoholizmu
Vyhľadávací modul nie je nainštalovaný.
Internetové kódovanie a typy písma
Vladimír Molochkov
Pri práci s internetom alebo e-mailom mnohí z vás pravdepodobne narazili viac ako raz na problém s kódovaním písmen ruskej abecedy. Čo je však za názvami ako koi-8r alebo UTF-8? Premýšľali ste niekedy, ako reprezentovať 33 písmen ruskej abecedy z 26 anglických písmen?
Proces delenia buniek je obrovský zázrak. Nejde iba o separáciu bez hlavy, takže sa vytvorí iba hmota, akoby cesto chleba povstalo; alebo pozrime sa na tvar nádoru. Toto oddelenie je bez vyššieho účelu. Na začiatku nového života sa bunky delia, zdá sa, nič neriadi túto separáciu, a napriek tomu každá bunka vie, akú časť tela by mala vytvárať, aký tvar má mať a či je bunkou sval, kosť, krv alebo sa stane sklovitým okom. , Kamery vedia, ktorým smerom zdieľať a kedy zastaviť zdieľanie.
NOVÝ TERM
Kódovanie je tabuľka znakov, kde každému písmenu abecedy (ako aj číslam a špeciálnym znakom) je pridelené vlastné jedinečné číslo - znakový kód.
Ak chcete na obrazovke počítača zobraziť text, musíte každému znaku priradiť určité číslo - jeho kód. Všetky moderné kódovacie tabuľky pochádzajú zo 7-bitovej tabuľky ASCII (American Standard Code for Information Interchange), ktorá sa objavila v 60. rokoch a ktorá obsahuje 33 kódov príkazov alebo kontrolných znakov, z ktorých väčšina sa dnes nepoužíva, a 95 kódov pre rôzne znaky, dostatočné na prácu s anglickými textami. V 7-bitovom kódovaní je každý znak mapovaný na 7 bitov, čo je číslo v rozsahu od 0 do 127.
Nie je zrejmé, že v celom rastovom procese sa všetky susedné časti tela presne zhodujú. Acetabulum sa teda vždy prispôsobuje tvaru kosti, ktorá sa v ňom pohybuje. Nestáva sa, že sa acetabulum tak či onak zvyšuje v nepravidelnom tvare, takže kosť vypadne. Každá jednotlivá vzájomne prepojená kosť v tele sa v priebehu vývoja zvyšuje s ohľadom na susedné kosti. Platí to aj pre oči, srdce, mozog a ďalšie orgány. Samozrejme, pozorujeme toto majstrovské dielo dokonalosti vo všetkých stvoreniach.
To by nebolo možné pre „náhodné“ procesy variability, ako určili evolucionisti. Srdce bije počas života človeka asi miliónkrát. Bez zastavenia, bez najmenšej pauzy. Rýchlosť zdvihu sa prispôsobuje napätiu. Srdce má dokonalé komory a chlopne a všetky žily sú správne spojené. Činnosť srdca je úplne nezávislá od nášho vedomia, je úplne automatická. Keby sa niekto vedome sústredil na každý srdcový rytmus, bol by to koniec života na Zemi na dlhú dobu.
Rýchly vývoj hypertextových metód na prezentáciu informácií na WWW v posledných rokoch zhoršil problém prezentácie a práce s cyrilickými informáciami v elektronickej podobe, ktorý existuje už viac ako desať rokov. Dôvodom je predovšetkým nedostatok štandardu pre rozšírený kód ASCII - tabuľka, ktorá obsahuje kódovanie cyrilických znakov, a rozmanitosť riešení ponúkaných rôznymi komerčnými spoločnosťami.
To všetko, moji priatelia, je teda štatisticky nemožné, že sa to stalo náhodou a samozrejme, že sa to nestalo pri prvom pokuse. Snažíme sa len zistiť, ako šikovne stvoril Pána. Toto je tajomstvo samotného Boha a my ho môžeme pokorne uctievať. Evolúcia nemôže odpovedať na otázku, čo sa stalo skôr, vajce alebo kura. Toto je, samozrejme, problém všetkých zvierat vyliahnutých z vajec, to znamená hadí, vtákov, korytnačiek a ďalších. Zdá sa, že tento problém vývoja je oveľa závažnejší a rozšírenejší. Premýšľali ste niekedy, ako sa stal prvý cicavec?
Štandardizovaná je iba polovica tabuľky ASCII, a to prvých 128 znakov, ktoré obsahujú písmená latinskej abecedy. A nikdy s nimi nie je problém. Druhá polovica tabuľky (spolu 256 znakov - podľa počtu štátov, ktoré môžu mať jeden bajt) je uvedená pre národné znaky a táto časť je v každej krajine iná. Napríklad v Rusku existuje asi 10 rôznych kódovaní. To znamená, že iný digitálny kód zodpovedá rovnakému symbolu, a ak nesprávne určíme kódovanie textu, uvidíme úplne nečitateľný text. Aj keď tento problém skutočne existuje, v skutočnosti nestačí len určiť typ kódovania textu v praxi a mnoho programov, napríklad Stirlitz (obr. 1), to robí v automatickom režime.
Kde sa vyvinul pod stromom? Alebo niekde v louži na podlahe? Objavil sa v tele matky prvý lev? Nakoniec bol prvým a v tom čase neexistovala matka! Ženy, ktoré prežijú vysokorizikové tehotenstvo, vám môžu povedať, ako je táto vec krehká. Premýšľať o vývoji plodu mimo tela matky je prinajmenšom utópia. Vieme, že mnoho stvorení potrebuje matku na svoj rozvoj, takže tento problém je veľmi bežný. Tu vidíme veľmi dobre, že hlavné motory evolúcie, mutácie a prirodzeného výberu získavajú veľké trhliny.
Obr. 1. Hlavné okno programu na rozpoznávanie kódovania „Stirlitz“
Medzinárodná norma ISO / IEC 8859-1 je v súčasnosti náhradou za ASCII. V ňom prvých 32 kódov, čísla 128 až 159, zodpovedá takmer nepoužitým kontrolným znakom spoločným pre všetky tabuľky kódovania ISO. Hoci je 8859-1 použiteľný pre texty takmer vo všetkých západoeurópskych jazykoch, nepokrýva úplne potreby francúzštiny a fínčiny. Tento nedostatok, ako aj absencia znamenia pre novú celoeurópsku menu, viedli v roku 1999 k vzniku kódovania 8859-15, v ktorom sa použila nová verzia hodnôt kódov 8859-1.
Ďalším mýtom, ktorý okamžite vyvrátime, je, že vývoj živých bytostí dosiahol takú úroveň rozvoja za milióny a milióny rokov. Skúsme si predstaviť, ako sa vyvinul prvý, mierne rozvinutý človek. Vďaka mutácii sa muž objavil po niekoľkých pokusoch. To však správne nepripojilo artériu a neprežilo. Pri ďalšom pokuse mnohí zlyhali, jeho ústa rástli spolu a nemal v nose žiadne diery, takže sa udusil. V inej mutácii sa objavil muž, ktorý mal všetko v poriadku, ale očné bulky neboli vyrobené z priehľadného materiálu, takže nič nevidel a zomrel hladom, pretože nenašiel žiadne jedlo.
Pokiaľ ide o azbuku, v súčasnosti existuje päť základných tabuliek na kódovanie ruských písmen:
Pre použitie s operačným systémom DOS bola vyvinutá tabuľka kódov CP-866 (IBM / Microsoft). Kódovanie CP866 je založené na alternatívnom kódovaní GOST a bolo vytvorené špeciálne pre operačný systém MS-DOS, ktorý používa pseudografické znaky. Dnes je toto kódovanie rovnako nepopulárne ako MS DOS.
Povedzme, že ďalší sa narodil dokonale dobre, ale evolúcia zabudla nechať mamu vyvinúť prsné žľazy, takže chudobný zomrel na hlad. Ďalší zabudol začať srdce. V inom prípade sa kosti navzájom nezmestili a bola to iba partia mäsa a kostí. Druhá chýbala celá pečeň. V tele by bolo niekoľko nefunkčných vecí naraz, nielen jedna. Vo fyzickom stave alebo za iných okolností sú iba nerovnosti a táto osoba neprežije.
Všetko môže byť absolútne dokonalé, ale ak bude zlé iba jedna maličkosť, nič z toho nebude. Vieme, že vedci sa snažili krížiť rôzne druhy, ale bez úspechu. Vysvetlite mi, ako sa môžu vyvíjať reprodukčné orgány, ak najmenšia nepravidelnosť automaticky vedie k vyhynutiu tohto druhu, pretože by sa nenarodila ďalšia generácia potomkov. Zároveň by celé telo malo pracovať 100%. Alebo ako sa ryby vo vode postupne vyvíjajú? Ak nebudú fungovať dokonale, ryby sa prvýkrát udušia a vývoj sa skončí.
Na použitie v operačnom prostredí Windows sa používa tabuľka kódov CP-1251 (Microsoft). Kódová stránka 1251 pre systém Microsoft Windows sa stala populárnou v dôsledku obrovského vplyvu spoločnosti Microsoft na trh počítačových technológií. Okrem toho chýba podpora pre pseudografické symboly, ktoré sú zbytočné v grafickom prostredí a sú oveľa úplnejšie ako v iných kódovaniach, ako sú symboly c, R, rôzne typy úvodzoviek, pomlčky atď. Táto kódová tabuľka je dnes v Rusku hlavná.
To isté platí pre vývoj srdca a všeobecne pre veľký počet životne dôležitých orgánov. Takže to nie sú miliardy rokov, iba generácia, alebo skôr okamih, keď Boh stvoril všetko svojím Slovom. Už ste to niekedy pochopili? V tomto svetle sa teória evolúcie zrúti na prach. Je pekné pozerať sa na živé tvory, ako stvoril Boh, ale vidíme, že tieto metódy nemožno zovšeobecniť na globálny princíp života.
Keby v očiach namiesto fotocitlivých žltých škvŕn boli šošovkami oka chuťové poháriky namiesto ušného bubienka v uchu, obličky by úplne chýbali a namiesto močového mechúra. Ako vie slepá evolúcia, ako pomôcť? Ako sme už ukázali, všetky orgány by mali byť súčasne riadne koordinované. Tu je jasný dôkaz, že za tým všetkým je racionálny Stvoriteľ - Boh. Aká je pravdepodobnosť, že slepá evolúcia môže vytvoriť taký dokonalý organizmus náhodnými pokusmi a chybami?
Codepage 10007 - Používa sa v počítačoch Macintosh a takmer totožná znaková sada ako CP1251.
V prostredí UNIX, najbežnejšia tabuľka kódov KOI8-R. Je to jedno zo štandardných kódovaní ruského jazyka, ktoré sa prijalo v Sovietskom zväze na začiatku vývoja počítačovej technológie. KOI znamená „kód na výmenu informácií“. Číslo 8 naznačuje, že tento kód je 8-bitový (na rozdiel od KOI-7, ktorý sa bežne používal na sovietskych počítačoch). V súčasnej dobe je koi8-r jedným z hlavných kódovaní v ruskom jazyku v operačných systémoch Linux. Toto je druhé najpopulárnejšie kódovanie po CP-1251 (win). Kódovanie podporuje pseudografické znaky a zaberá asi polovicu všetkých kódov. V roku 1993 bola koi8-r tabuľka štandardizovaná na internete (obr. 2).
To je pre daný prípad nedosiahnuteľné. Ďalším dôkazom takzvaného evolucionistu je známy Miller-Ureyov experiment, keď elektrické náboje za určitých podmienok vytvorili rôzne aminokyseliny z vody, metánu, amoniaku a vodíka. Nukleové kyseliny však neboli generované. Zistilo sa však, že v počiatočných fázach Zeme malo úplne odlišné zloženie atmosféry a tento experiment dal s týmto zložením úplne odlišné výsledky. Netreba dodávať, že takáto atmosféra zabije každého živého tvora.
Bez Stvoriteľa samozrejme neexistujú žiadne výtvory. Sú aj tí, ktorí tvrdia, že život na Zemi je mimozemský. Toto samozrejme nie je riešenie, problém sa jednoducho presunie na iné miesto. Vieme, že mnohí sa snažia nájsť mimozemský život vo vesmíre. Toto úsilie má korene v matematickej pravdepodobnosti, že v takom veľkom počte hviezd niekde niekde existujú štatistické podmienky. Teraz vidíme, že nejde o vhodné podmienky, ale o rozhodnutie Stvoriteľa. Je tiež známe, že by to bola strata priestoru, keby sme boli jediní v celom vesmíre.
Medzinárodná norma ISO definuje tabuľku kódov ISO 8859-5 pre Rusko. Chýbajú pseudografické údaje. V súčasnosti sa toto kódovanie prakticky nepoužíva. Jeho podpora je však prítomná vo všetkých prehľadávačoch.

Obr. 2. Súbor znakov na znázornenie ruského jazyka v kódovaní KOI8-R
Koľko zmizne z nekonečného priestoru, ak ho väčšinu oddelíme, napríklad náš vesmír? Nekonečno zostáva nekonečné. Boh sa neobmedzuje iba na náš časopriestor a to, čo sa nám zdá gigantické, je Božie znamenie. Poznáte príslovie: „List sa nemôže pohybovať bez vetra“? Viete, že toto je v podstate základné vedecké právo - zásada kauzality, ktorá určuje, že každý jav musí mať príčinu? Veda, založená na tomto zákone, sa preto musí zaoberať odpoveďou na otázku, čo bolo hlavným dôvodom.
Čo spôsobilo Veľký tresk alebo čo veda zvažuje narodenie vesmíru? Podľa tohto zákona mal tento jav niečo spôsobiť. Zdá sa, že začarovaný kruh a veda sa bez problémov zbavili tohto problému a uviedli ho do filozofie. Biblia tiež poskytuje odpoveď na túto otázku v prvej kapitole Jánovho evanjelia a na začiatku Genesis. Na počiatku bolo Slovo a to Slovo bolo s Bohom a Boh bol Slovo. Na začiatku to bolo to isté s Bohom. Všetko sa robí jedno a to isté a bez toho sa nič neurobí, čo sa robí.
POZNÁMKA
Na kódovanie cyriliky je možné použiť ďalších päť tabuliek, ktoré sú teraz archaické a nemajú medzinárodný štatút: Hlavným kódovaním je GOST (SSSR State Standard) od roku 1987. Jeho hlavnou nevýhodou je, že pseudografické symboly sú umiestnené odlišne od tých, ktoré sú na počítači IBM PC. Alternatívne kódovanie GOST (líši sa od CP866 v pozíciách 242 - 251). Bulharské kódovanie (získané mechanickým vložením 64-písmenového bloku ruskej abecedy do pozícií 128-191 CP437). KOI-8 (na počítačoch IBM PC nie je rozšírený kvôli nea abecednému usporiadaniu písmen azbuky).
Bol v ňom život a život je svetlom ľudí. Prvý termodynamický zákon uvádza, že energia v uzavretom systéme je konštantná. To znamená, že energia sa nemôže vytvárať alebo ničiť. Toto hovorí o fyzikálnom práve. Kde je teda všetka energia vo vesmíre? Niektorí hovoria, že to prišlo po Veľkom tresku. Zákon však hovorí, že energia sa nemôže vyrábať! Čo teda vybuchlo a odkiaľ prišlo toľko energie? Je to tiež vedecký dôkaz o existencii Boha. Iba všemohúci Boh, ktorý nemá začiatok ani koniec, môže niečo také vyrobiť.
Na kódovanie znakov v niektorých jazykoch, napríklad v čínštine alebo japončine, nestačí 8-bitové číslo. Okrem toho sa vytvorenie 8-bitových kódovacích tabuliek v určitom okamihu stalo takmer nekontrolovateľnými: každé nové počítačové písmo predstavilo svoju vlastnú tabuľku. Z tohto dôvodu bolo vytvorené konzorcium Unicode: jeho cieľom bolo vyvinúť jednotný systém kódovania pre všetky možné znaky, ktorý by nám umožnil priradiť kódy počítačovým písmom v špecifickom vzore.
Jeho slová sú dosť a všetko sa deje. Podstatou vedy je skúmať a zavádzať zákony javov a procesov, ktoré nás obklopujú, ktoré je možné dokázať a vypočítať. Bolo by neprimerané tvrdiť, že to, čo nemôžeme experimentálne dokázať, neexistuje. A to je kameň úrazu pre ľudí. Pretože sa otvárame a pomaly si uvedomujeme, pretože Boh naozaj myslel a urobil všetko. Veda sa zastaví, ak neuznáme, že Boh skutočne existuje a že je Stvoriteľom všetkého.
Zdá sa, že to nie je vedecké a slabé, ak veda uznáva, že za tým všetkým stojí Boh, ale to je jediný spôsob. Človek si niekedy drží pýchu za pána všetkého stvorenia a za vrchol múdrosti. Vymýšľame mnoho podivných teórií a tvrdíme, že sú pravdivé, a vieme, ako sme zraniteľní voči klamom. Teórie vesmíru, častice atómovej úrovne a mnoho ďalších sľubných teórií, ktoré boli nakoniec vylúčené, sú veľmi jasne viditeľné. Človek, vrchol inteligencie a stvorenia. Pozrime sa, aký druh človeka vymyslel, a myslel som si, že bude dokonalý a efektívny.
Kódovanie Unicode je založené na katalógu UCS (Universal Character Set) štandardov ISO 10646 a môže obsahovať až 231 \u003d 2147483648 rôznych znakov, ako aj doplnenie. Kódy UCS-2 sú dvojbajtové, tj čísla od 0 do 65535 a UCS-4 sú štvorbajtové, tj čísla od 0 do 2147483647. Dva a štyri bajtové kódy Unicode môžu byť reprezentované dvoma spôsobmi: bajty sú usporiadané zľava doprava od najstarších po najnižšie ( Big Endian, BE) alebo od juniora po seniorku (Little Endian, LE). Druhá metóda sa nachádza vo veľkej väčšine prípadov. Okrem toho sa na kompaktnejšie kódovanie používajú kódy s premenlivou dĺžkou UTF-8 (formát prenosu Unicode) 1-6 bajtov a UTF-16 - dvoj- alebo štvorbajtové. Posledne menované existujú aj v dvoch formách (Little a Big Endian) a umožňujú kódovanie nie viac ako 220 + 216 \u003d 1114112 znakov.
Majstrovské diela ľudského génia, a napriek tomu sú to neúspešné pokusy, ktoré nemôžu letieť a boli skopírované prírodou. Neboj sa priznať, že existuje niekto, kto je väčší ako my. Toto nie je znak slabosti, ale zrelosť. Každá osoba by mala byť schopná rozpoznať, čo je výsledkom náhody a práce Stvoriteľa. Celý vesmír, a preto všetko, čo sa pozeráme iba na Zem, je stvoriteľ, ale v neživej veci konajú iba fyzikálne zákony, preto to nie je také viditeľné a považuje sa za náhodné. Mimochodom, všetky zákony, fyzické konštanty, sú dobre vyladené a dokonca aj Einstein veril, že za ním by mal byť tvorca.
Medzi spomenutými kódovaniami je najčastejšie používaným kódovaním UTF-8, ktorý vám umožňuje obísť 8 bitov na kódovanie znakov ASCII a 16 bitov na kódovanie znakov vo väčšine abecedných skriptov vrátane ruštiny. Texty v ASCII, najmä v angličtine, sú súčasne textami v UTF-8. Kód UTF-8, sekvencia bajtov, sa získa z kódu adresára UCS podľa špecifickej schémy. Napríklad znak Unicode s kódom 169 \u003d a916 \u003d 1010 1001 (znak c) je kódovaný v UTF-8 ako 11000010 10101001 \u003d c216 a916.
Teória evolúcie nás natoľko oklamala, že zdanlivo jasné rozhodnutie už nie je také jasné vďaka opakovaným recenziám evolucionistov, ktoré počujeme zo všetkých strán. Stane sa opakovaným lžami. Vezmite človeka a mnoho ďalších tvorov, ktorí majú symetrické telo. A vieme, že to nie je striktná symetria, pretože vnútorné usporiadanie orgánov nie je symetrické. Aká je pravdepodobnosť, že zhoda môže vytvoriť takúto symetriu? Okrem toho sú muž a žena navzájom atraktívni a krásni.
A to platí pre celé stvorenie. Ženské feromóny sú pre samcov veľmi atraktívne. Jelena nie je sexuálne priťahovaná diviakom, ale atraktívnou ženou a keď je správny čas, navštevuje ho. A toto párovanie funguje všetkej povahy. Mnohí dokonca majú smartphone. Jedná sa o komplexné zariadenie s procesorom, pamäťou, batériou na nabíjanie, kamerou s niekoľkými megapixelov, mikrofónom, reproduktormi atď. Dokáže vykonávať výpočty, ukladať fotografie a videá a komunikovať. Stručne povedané, veľmi zložité zariadenie.
Unicode je plne podporovaný modernými programami - prehliadačmi, kancelárskymi balíkmi atď. Linux používa UTF-8 a Microsoft Windows tiež používa UCS-2. Podpora UCS v systéme Linux je zatiaľ o niečo slabšia ako v operačných systémoch Windows 2000 / Me / XP. Hlavnými problémami pri používaní Unicode je nedostatok vhodnej úplnej sady písiem a zložitosť vstupu.
(Tu by som rád položil pozornému čitateľovi otázku: „V ktorom kódovaní sa prvýkrát objavil symbol EURO?“)
O harmónii fontov prehliadača a stránok
Existuje niekoľko problémov s používaním písiem na webových stránkach. Prvým z nich je harmónia kódovania na stránkach a prehliadačoch. Webové stránky s prehliadačmi rôznych používateľov by mali komunikovať v rovnakom kódovaní, t. Prehliadač musí „pochopiť“, čo naň web posiela. Ak to chcete urobiť, musíte na webe nainštalovať systém, ktorý môže odosielať správu o tom, v akom kódovaní sa stránka pošle používateľovi. Jeho prehliadač musí prijať túto správu a naladiť ju, aby mohol web správne zobraziť. V takom prípade môžete určiť kódovanie stránky webu priamo v kóde HTML. Na tento účel použite špeciálnu verziu značky META s parametrom charset, ktorý nastavuje požadovaný jazyk. Napríklad pre stránku napísanú v kódovaní Win1251 by zodpovedajúci kód vyzeral takto:
V Rusku je však veľmi rozšírená metóda, pri ktorej webový server automaticky určí, v ktorom kódovaní žiadosť pochádza od klienta, a stránku poskytne už prešifrovanému webovému prehliadaču. Táto značka META tu môže hrať zlý žart. Faktom je, že pokyny na stránke majú prednosť pred príkazmi odoslanými webovým serverom a po správnom zakódovaní stránky nemôže server zmeniť obsah značky META. Medzi skutočným kódovaním, v ktorom kódovanie prišlo, a pokynmi v značke META existuje nesúlad. Takúto stránku nie je možné normálne prehliadať a transkódovať pomocou prehliadača. Manuálne výber kódovania v tomto prípade nepomôže, pretože Značka META má prednosť pred nastaveniami prehliadača. Jediným spôsobom, ako to dosiahnuť, je uložiť stránku na disk a potom značku odstrániť.
V tejto súvislosti sa v službe RUNET neodporúča používať túto značku vôbec. V tomto prípade sa prehliadanie vykoná v kódovaní, v ktorom je prehliadač nakonfigurovaný, ak server neodošle upozornenie na kódovanie dokumentu. V prípade nezhody sa dá prepínať pomerne ľahko. Okrem toho, ak je predvolené kódovanie Win-1251, potom sa pre väčšinu používateľov stránka okamžite zobrazí správne.
Jednou mierou čitateľnosti je šírka riadku dokumentu. S príchodom monitorov, ktoré podporujú rozlíšenie veľkých obrazoviek, je možné „stohovať“ až niekoľko stoviek znakov na jeden riadok, ale riadok „ideálnej šírky“ by mal mať asi 50 - 70 znakov. Pri viacerých z nich sa rýchlosť čítania spomaľuje a únava sa objavuje oveľa rýchlejšie.
Druhým problémom s kódovaním môžu byť kaskádové štýly (CSS). Je známe, že presnú veľkosť písma a jeho ďalšie atribúty je možné nastaviť pomocou kaskádových šablón štýlov (o ktorých sa bude hovoriť v kapitole 8). Pri použití CSS môžeme použiť absolútne ľubovoľné písmo. Problém je však v tom, že písma sú prevzaté zo sady nainštalovanej v počítači používateľa a nie na webe. To znamená, že sady písiem na webe a sada písiem používateľa sa nemusia zhodovať.
Pri prezeraní webových stránok sa v predvolenom nastavení používa písmo nainštalované v prehliadači. Ak chcete zmeniť predvolené písmo v programe Internet Explorer (t. J. Times New Roman) na iné, napríklad na Arial, vykonajte príkaz Service4 Internet Options 4 Fonts.
Tretím možným problémom je situácia, keď je písmo na webe a v počítači používateľa identické, ale v jednom prípade je to azbuka, a v druhom prípade je to latinka (ne ruská verzia písma). V takom prípade sa text zobrazí s niektorými špeciálnymi znakmi a čítanie týchto znakov bude problematické.
Ak sa chcete vyhnúť takým problémom pri používaní písiem vo webdizajne, musíte dodržať niekoľko pravidiel:
Je lepšie používať iba štandardné písma, ktoré sa dodávajú so systémom Windows a je zaručené, že sa nachádzajú na počítači klienta. Existujú tri takéto písma: „Arial“, „Times New Roman“, „Courier“.
Je potrebné správne opísať písma v šablóne so štýlmi (CSS) so zoznamom v zozname ďalších typov písma, ktoré nahrádzajú hlavné (písma na nahradenie). Na konci zoznamu by mala byť povinná informácia o všeobecnej rodine fontov (s pätkami, bezpatkovými, monospaced atď.).
Napríklad:
Ako možnosť, ako sa dostať zo situácie, môžete písmo prezentovať pomocou grafiky, napríklad vo formáte GIF. Prehliadač aj operačný systém sa nestarajú o to, čo je nakreslené - zobrazenie písma ako grafického súboru na obrazovkách všetkých používateľov bude totožné (ale tu sa objaví ďalší problém - grafika je veľká).
Z vyššie uvedeného vyplýva, že internetové technológie ukladajú osobitné obmedzenia na používanie písiem pri navrhovaní webových dokumentov a že s neštandardnými typmi písiem by sa malo pri webovom dizajne zaobchádzať opatrne. Bohužiaľ v súčasnosti neexistujú dostatočne vyvinuté a spoľahlivé prostriedky na špecifikovanie určitých náhlavných súprav pri prezentácii informácií vo forme textu na webovej stránke.
|
Aby sa zakúpený autoalarm stal spoľahlivou ochranou, musíte si ho zvoliť správne. Jedným z hlavných parametrov ovplyvňujúcich výkon alarmu je metóda kódovania signálu. V tomto článku sa pokúsime prístupným spôsobom vysvetliť, čo znamená dynamické kódovanie signálov a aký dialógový kód znamená v autoalarmoch, aký typ kódovania je lepší, z ktorých každý má svoje pozitívne i negatívne stránky.
Dynamické kódovanie v autoalarmoch
Konfrontácia medzi vývojármi výstražných systémov a zlodejmi automobilov začala od vytvorenia prvých autoalarmov. S príchodom nových, vyspelejších bezpečnostných systémov sa vylepšili prostriedky na hackovanie. Úplne prvé poplachy mali statický kód, ktorý bol ľahko popraskaný metódou výberu. Reakciou vývojárov bolo zablokovať možnosť výberu kódu. Ďalším krokom sušienok bolo vytvorenie grabberov - zariadení, ktoré snímali signál z ovládača a reprodukovali ho. Týmto spôsobom duplikovali príkazy z kľúčenky majiteľa a v správnom čase odstránili vozidlo z ochrany. Aby ochránili autoalarmy pred rozbitím hmatadlom, začali používať dynamické kódovanie signálu.
Princíp dynamického kódovania
 Dynamický kód v autoalarmoch je neustále sa meniaci dátový paket prenášaný z ovládača do zabezpečovacej jednotky cez rádiový kanál. Pri každom novom príkaze sa odošle kód z ovládača, ktorý nebol predtým použitý. Tento kód sa počíta podľa osobitného algoritmu stanoveného výrobcom. Najbežnejším a najspoľahlivejším algoritmom je Keelog.
Dynamický kód v autoalarmoch je neustále sa meniaci dátový paket prenášaný z ovládača do zabezpečovacej jednotky cez rádiový kanál. Pri každom novom príkaze sa odošle kód z ovládača, ktorý nebol predtým použitý. Tento kód sa počíta podľa osobitného algoritmu stanoveného výrobcom. Najbežnejším a najspoľahlivejším algoritmom je Keelog.
Alarm funguje podľa nasledujúceho princípu. Keď majiteľ vozidla stlačí tlačidlo ovládača, generuje sa signál. Poskytuje informácie o počte kliknutí (táto hodnota je potrebná na synchronizáciu činnosti ovládača a ovládacej jednotky), sériové číslo zariadenia a tajný kód. Pred odoslaním sú tieto dáta vopred zašifrované. Samotný šifrovací algoritmus je voľne k dispozícii, ale na dešifrovanie údajov potrebujete poznať tajný kód, ktorý je uložený v ovládači a ovládacej jednotke v továrni.
Existujú tiež originálne algoritmy vyvinuté výrobcami alarmov. Takéto kódovanie prakticky vylúčilo možnosť výberu príkazového kódu, ale útočníci časom obchádzali túto ochranu.
Čo potrebujete vedieť o hackovaní dynamického kódu
 V reakcii na zavedenie dynamického kódovania do autoalarmov sa vytvoril dynamický grabber. Princíp jeho činnosti je rušiť a zachytávať signál. Keď majiteľ vozidla opustí vozidlo a stlačí tlačidlo ovládača, vytvorí sa silné rádiové rušenie. Signál s kódom nedosiahne riadiacu jednotku alarmu, ale zachytáva ju a skopíruje ho grabber. Prekvapený ovládač znovu stlačí tlačidlo, ale proces sa opakuje a zachytí sa aj druhý kód. Druhýkrát je vozidlo nasadené do defenzívy, ale príkaz pochádza už zo zlodejského zariadenia. Keď majiteľ vozidla pokojne odchádza o svojej firme, únosca pošle druhý kód, ktorý predtým zachytil, a vozidlo odstráni z ochrany.
V reakcii na zavedenie dynamického kódovania do autoalarmov sa vytvoril dynamický grabber. Princíp jeho činnosti je rušiť a zachytávať signál. Keď majiteľ vozidla opustí vozidlo a stlačí tlačidlo ovládača, vytvorí sa silné rádiové rušenie. Signál s kódom nedosiahne riadiacu jednotku alarmu, ale zachytáva ju a skopíruje ho grabber. Prekvapený ovládač znovu stlačí tlačidlo, ale proces sa opakuje a zachytí sa aj druhý kód. Druhýkrát je vozidlo nasadené do defenzívy, ale príkaz pochádza už zo zlodejského zariadenia. Keď majiteľ vozidla pokojne odchádza o svojej firme, únosca pošle druhý kód, ktorý predtým zachytil, a vozidlo odstráni z ochrany.
Aká ochrana sa používa pre dynamický kód
 Výrobcovia autoalarmov vyriešili problém hackovania celkom jednoducho. Začali inštalovať na gombíky dve gombíky, z ktorých jedno dalo auto na ochranu a druhé deaktivovalo ochranu. V súlade s tým boli zasielané rôzne kódy na nastavenie a odstránenie ochrany. Preto nezáleží na tom, do akej miery zlodej pri nastavovaní stroja chráni, nikdy nedostane kód potrebný na deaktiváciu alarmu.
Výrobcovia autoalarmov vyriešili problém hackovania celkom jednoducho. Začali inštalovať na gombíky dve gombíky, z ktorých jedno dalo auto na ochranu a druhé deaktivovalo ochranu. V súlade s tým boli zasielané rôzne kódy na nastavenie a odstránenie ochrany. Preto nezáleží na tom, do akej miery zlodej pri nastavovaní stroja chráni, nikdy nedostane kód potrebný na deaktiváciu alarmu.
Ak ste klikli na tlačidlo „nastaviť na ochranu“ a vozidlo neodpovedalo, možno ste sa stali cieľom únoscov. V tomto prípade nemusíte bezmyšlienne stláčať všetky tlačidlá ovládača, aby ste situáciu nejako napravili. Stačí znova stlačiť ochranné tlačidlo. Ak omylom kliknete na tlačidlo „Odstrániť z ochrany“, zlodej dostane kód, ktorý potrebuje, ktorý čoskoro použije a ukradne vaše auto.
Alarmy s dynamickým kódovaním sú už trochu zastarané, neposkytujú stopercentnú ochranu automobilu pred krádežou. Nahradili ich zariadenia s interaktívnym kódovaním. Ak ste vlastníkom lacného automobilu, nemusíte sa obávať, pretože je veľmi nepravdepodobné, že by zlodej vybavený najmodernejším vybavením zasahoval do vášho majetku. Na ochranu svojho majetku použite viacúrovňovú ochranu. Nainštalujte voliteľné. Poskytne ochranu automobilu v prípade, že dôjde k poplachu na počítač.
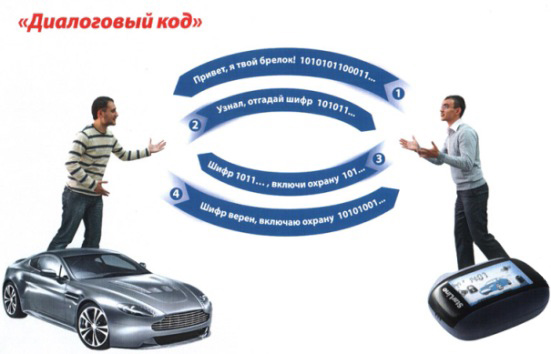
Dialogové kódovanie v astrosignále
 Po príchode dynamických grabberov sa automobilové alarmy bežiace na dynamickom kóde stali veľmi zraniteľné pre útočníkov. Napadol sa aj veľký počet kódovacích algoritmov. Na ochranu vozidla pred hackermi takýmito zariadeniami začali vývojári alarmov používať dialógové kódovanie signálov.
Po príchode dynamických grabberov sa automobilové alarmy bežiace na dynamickom kóde stali veľmi zraniteľné pre útočníkov. Napadol sa aj veľký počet kódovacích algoritmov. Na ochranu vozidla pred hackermi takýmito zariadeniami začali vývojári alarmov používať dialógové kódovanie signálov.
Princíp kódovania dialógu
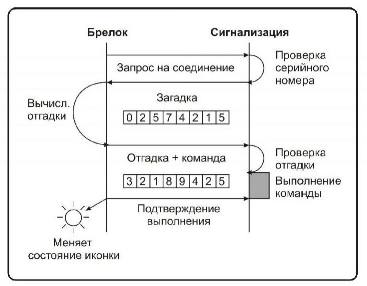 Ako už názov napovedá, tento typ šifrovania sa vykonáva v dialógovom režime medzi kľúčovým ovládačom a riadiacou jednotkou autoalarmu umiestnenou vo vozidle. Keď stlačíte tlačidlo, od ovládača sa odošle žiadosť o vykonanie príkazu. Aby sa riadiaca jednotka uistila, že príkaz vyšiel z ovládača ovládača, vyšle do ovládača ovládania náhodný číselný signál. Toto číslo je spracované podľa špecifického algoritmu a odoslané späť do riadiacej jednotky. V tomto okamihu riadiaca jednotka spracuje rovnaké číslo a porovná svoj výsledok s výsledkom zaslaným kľúčovým ovládačom. Ak sa hodnoty zhodujú, riadiaca jednotka vykoná príkaz.
Ako už názov napovedá, tento typ šifrovania sa vykonáva v dialógovom režime medzi kľúčovým ovládačom a riadiacou jednotkou autoalarmu umiestnenou vo vozidle. Keď stlačíte tlačidlo, od ovládača sa odošle žiadosť o vykonanie príkazu. Aby sa riadiaca jednotka uistila, že príkaz vyšiel z ovládača ovládača, vyšle do ovládača ovládania náhodný číselný signál. Toto číslo je spracované podľa špecifického algoritmu a odoslané späť do riadiacej jednotky. V tomto okamihu riadiaca jednotka spracuje rovnaké číslo a porovná svoj výsledok s výsledkom zaslaným kľúčovým ovládačom. Ak sa hodnoty zhodujú, riadiaca jednotka vykoná príkaz.
Algoritmus, ktorým sa výpočty vykonávajú na ovládači a ovládacej jednotke, je individuálny pre každý autoalarm a je v ňom stanovený v inej továrni. Poďme pochopiť najjednoduchší algoritmus:
X \u003d T3 - X \u003d S2 + X \u003d U - H \u003d Y
T, S, U a H sú čísla, ktoré sú zabudované do poplachu v továrni.
X je náhodné číslo, ktoré je zaslané z riadiacej jednotky do ovládača na overenie.
Y je číslo vypočítané riadiacou jednotkou a kľúčovým ovládačom podľa daného algoritmu.
Pozrime sa na situáciu, keď majiteľ alarmu stlačil tlačidlo a od ovládača sa poslala požiadavka na odzbrojenie vozidla. V reakcii na to riadiaca jednotka vygenerovala náhodné číslo (napríklad zobrala číslo 846) a poslala ho na kľúčenku. Potom riadiaca jednotka a kľúčenka vykonajú výpočet čísla 846 podľa algoritmu (napríklad vypočítame podľa najjednoduchšieho algoritmu uvedeného vyššie).
Pre výpočty berieme:
T \u003d 29, S \u003d 43, U \u003d 91, H \u003d 38.
Budeme úspešní:
846∙24389 - 846∙1849 + 846∙91- 38 = 19145788
Ovládač pošle číslo (19145788) do riadiacej jednotky. Zároveň riadiaca jednotka vykoná rovnaký výpočet. Čísla sa budú zhodovať, riadiaca jednotka potvrdí príkaz ovládača a zariadenie sa vypne.
 Dokonca aj na dešifrovanie vyššie opísaného elementárneho algoritmu bude potrebné zachytiť dátové pakety štyrikrát (v našom prípade štyri neznáme v rovnici).
Dokonca aj na dešifrovanie vyššie opísaného elementárneho algoritmu bude potrebné zachytiť dátové pakety štyrikrát (v našom prípade štyri neznáme v rovnici).
Je takmer nemožné zachytiť a dešifrovať dátový balík alarmov dialógových automobilov. Na kódovanie signálu sa používajú tzv. Hašovacie funkcie - algoritmy, ktoré prevádzajú reťazce ľubovoľnej dĺžky. Výsledok tohto šifrovania môže obsahovať až 32 písmen a číslic.
Nižšie sú uvedené výsledky šifrovania čísel pomocou najpopulárnejšieho šifrovacieho algoritmu MD5. Napríklad číslo 846 a jeho zmeny boli prijaté.
MD5 (846) \u003d;
MD5 (841) \u003d;
MD5 (146) \u003d.
Ako vidíte, výsledky čísel kódovania, ktoré sa líšia iba jednou číslicou, sa od seba úplne líšia.
Podobné algoritmy sa používajú v moderných interaktívnych autoalarmoch. Je dokázané, že na spätné dekódovanie a získanie algoritmu budú moderné počítače potrebovať viac ako storočie. Bez tohto algoritmu nebude možné vygenerovať verifikačné kódy na potvrdenie príkazu. Preto je teraz a v blízkej budúcnosti možné hackovanie dialógového kódu nemožné.
Alarmy pracujúce na kóde dialógu sú bezpečnejšie, nie sú prístupné elektronickému hackerstvu, to však neznamená, že vaše auto bude úplne bezpečné. Môžete omylom prísť o kľúčenku alebo vám bude ukradnutý. Na zvýšenie úrovne ochrany je potrebné použiť ďalšie prostriedky, ako napríklad.

