29.06.2019
Care format audio este cel mai bun. Ce este „fără pierderi” sau Despre comprimarea muzicii fără pierderi
Bună ziua.
Astăzi vreau să ating subiectul compresiei datelor fără pierderi. În ciuda faptului că deja existau articole pe hub dedicate anumitor algoritmi, am vrut să vorbesc despre asta într-un pic mai detaliat.
Voi încerca să dau atât o descriere matematică, cât și o descriere în mod obișnuit, astfel încât fiecare să găsească ceva interesant pentru ei înșiși.
În acest articol voi atinge momentele fundamentale ale compresiunii și principalele tipuri de algoritmi.
Compresie. Este nevoie în zilele noastre?
Da, desigur. Desigur, cu toții înțelegem că acum putem accesa atât suporturi de stocare de volum mare, cât și canale de transmisie de date de mare viteză. Totuși, în același timp, volumele de informații transmise cresc. Dacă acum câțiva ani am urmărit filme de 700 de megabyte care se potrivesc pe un disc, astăzi filmele de calitate HD pot ocupa zeci de gigabyte.
Desigur, avantajele comprimării a tot și a tuturor nu sunt atât. Dar mai există situații în care compresia este extrem de utilă, dacă nu este necesară.
- Documentare prin e-mail (în special volume mari de documente care utilizează dispozitive mobile)
- La publicarea documentelor pe site-uri, este necesară economisirea traficului
- Economisiți spațiu pe disc atunci când schimbați sau adăugați stocare este dificil. De exemplu, acest lucru se întâmplă în cazurile în care nu este ușor să obții un buget pentru cheltuieli de capital și nu există suficient spațiu pe disc.
Desigur, puteți veni cu multe alte situații diferite în care compresia va fi utilă, dar aceste câteva exemple sunt suficiente pentru noi.
Toate metodele de compresie pot fi împărțite în două grupuri mari: compresia fără pierderi și compresia fără pierderi. Compresia fără pierderi este utilizată în cazurile în care informația trebuie să fie restaurată exact la biți. Această abordare este singura posibilă atunci când comprimăm, de exemplu, date text.
În unele cazuri, însă, nu este necesară recuperarea corectă a informațiilor și este permisă utilizarea algoritmilor care implementează compresia cu pierderi, care, spre deosebire de compresia fără pierderi, este de obicei mai ușor de implementat și oferă un grad mai mare de arhivare.
Așadar, să trecem la algoritmi de compresie fără pierderi.
Metode de compresie universală fără pierderi
În cazul general, există trei opțiuni de bază pe care sunt construiți algoritmi de compresie.Primul grup metode - conversie în flux. Aceasta implică o descriere a noilor date necomprimate prin intermediul procesării deja procesate. În acest caz, nu sunt calculate probabilități, codificarea caracterelor se realizează numai pe baza datelor care au fost deja procesate, cum ar fi în metodele LZ (numite după Abraham Lempel și Jacob Ziva). În acest caz, a doua și alte apariții ale unei subtringuri deja cunoscute codificatorului sunt înlocuite de referințe la prima sa apariție.
Al doilea grup metodele sunt metode de compresie statistică. La rândul lor, aceste metode sunt împărțite în adaptive (sau flux) și bloc.
În prima versiune (adaptivă), calculul probabilităților pentru noile date se bazează pe datele deja procesate în timpul codificării. Aceste metode includ versiuni adaptive ale algoritmilor Huffman și Shannon-Fano.
În cel de-al doilea caz (bloc), statisticile fiecărui bloc de date sunt calculate separat și adăugate la cel mai comprimat bloc. Acestea includ versiunile statice ale Huffman, Shannon-Fano și metodele de codificare aritmetică.
Grupa a treia metodele sunt așa-numitele metode de conversie bloc. Datele primite sunt împărțite în blocuri, care sunt apoi transformate în ansamblu. Cu toate acestea, unele metode, în special bazate pe permutarea blocurilor, pot să nu conducă la o reducere semnificativă (sau chiar vreo) a cantității de date. Cu toate acestea, după o astfel de procesare, structura de date se îmbunătățește semnificativ, iar compresia ulterioară de către alți algoritmi este mai reușită și mai rapidă.
Principii generale pe care se bazează compresia datelor
Toate metodele de compresie a datelor se bazează pe un principiu logic simplu. Dacă ne imaginăm că elementele care apar cel mai des sunt codificate cu coduri mai scurte și cele mai puțin obișnuite sunt codificate cu altele mai lungi, atunci toate datele vor avea nevoie de mai puțin spațiu pentru a stoca decât dacă toate elementele ar fi reprezentate prin coduri de aceeași lungime.
Relația exactă între frecvențele aparițiilor elementelor și lungimile optime ale codului este descrisă în așa-numita teoremă de codare a sursei Shannon, care definește limita de compresie maximă fără pierderi și entropia lui Shannon.
Un pic de matematică
Dacă probabilitatea apariției unui element s i este egală cu p (s i), atunci va fi cel mai avantajos să reprezinți acest element - log 2 p (s i) biți. Dacă în timpul codificării este posibil să se asigure că lungimea tuturor elementelor este redusă la biți log 2 p (s), atunci lungimea întregii secvențe codate va fi minimă pentru toate metodele de codare posibile. Mai mult, dacă distribuția probabilității tuturor elementelor F \u003d (p (s i)) este neschimbată și probabilitățile elementelor sunt reciproc independente, atunci lungimea medie a codurilor poate fi calculată caAceastă valoare se numește entropia distribuției de probabilitate F sau entropia sursei la un moment dat în timp.
Totuși, de obicei, probabilitatea apariției unui element nu poate fi independentă, dimpotrivă, depinde de unii factori. În acest caz, pentru fiecare element nou codat s i, distribuția probabilității F va lua o anumită valoare F k, adică pentru fiecare element F \u003d F k și H \u003d H k.
Cu alte cuvinte, putem spune că sursa este în starea k, ceea ce corespunde unui anumit set de probabilități p k (s i) pentru toate elementele s i.
Prin urmare, având în vedere această corecție, putem exprima lungimea medie a codurilor ca
Unde P k este probabilitatea de a găsi sursa în starea k.
Deci, în această etapă, știm că compresia se bazează pe înlocuirea elementelor care apar frecvent cu coduri scurte și invers și știm, de asemenea, cum să determinăm lungimea medie a codurilor. Dar ce este codul, codarea și cum se întâmplă?
Codificare fără memorie
Codurile fără memorie sunt cele mai simple coduri pe baza cărora datele pot fi comprimate. În codul fără memorie, fiecare caracter din vectorul de date codat este înlocuit cu un cod cod dintr-un set prefix de secvențe sau cuvinte binare.În opinia mea, nu cea mai clară definiție. Luați în considerare acest subiect mai detaliat.
Să fie dat un anumit alfabet ![]() constând dintr-un număr (finit) de litere. Numim fiecare secvență finită de caractere din acest alfabet (A \u003d a 1, a 2, ..., a n) într-un cuvânt, iar numărul n este lungimea acestui cuvânt.
constând dintr-un număr (finit) de litere. Numim fiecare secvență finită de caractere din acest alfabet (A \u003d a 1, a 2, ..., a n) într-un cuvânt, iar numărul n este lungimea acestui cuvânt.
Să fie dat și un alt alfabet ![]() . În mod similar, notăm cuvântul din acest alfabet drept B.
. În mod similar, notăm cuvântul din acest alfabet drept B.
Mai introducem încă două notații pentru setul tuturor cuvintelor care nu sunt dezgustate în alfabet. Let - numărul de cuvinte care nu sunt goale în primul alfabet și - în al doilea.
Să se acorde și o mapare F care asociază cu fiecare cuvânt A din primul alfabet un cuvânt B \u003d F (A) din al doilea. Atunci se va numi cuvântul B cod cuvintele A și trecerea de la cuvântul inițial la codul său se va numi de codificare.
Deoarece cuvântul poate fi format dintr-o singură literă, putem identifica corespondența literelor primului alfabet și a cuvintelor corespunzătoare din a doua:
a 1<-> B 1
a 2<-> B 2
…
a n<-> B n
Acest meci se numește schemăși denotați ∑.
În acest caz, cuvintele B 1, B 2, ..., B n sunt numite coduri elementareși tipul de codificare cu ajutorul lor - codificare alfabetică. Desigur, cei mai mulți dintre noi am întâlnit acest tip de codificare, chiar dacă nu știm tot ce am descris mai sus.
Deci, am decis asupra conceptelor alfabet, cuvânt, cod, și de codificare. Acum introducem conceptul prefix.
Fie că cuvântul B are forma B \u003d B "B" ". Atunci B" se numește început, sau prefix cuvintele B, și B "" - sfârșitul ei. Aceasta este o definiție destul de simplă, dar trebuie menționat că pentru orice cuvânt B, atât un anumit cuvânt gol ʌ („spațiu”), cât și cuvântul B în sine pot fi considerate atât începuturi cât și sfârșite.
Așadar, ne apropiem de înțelegerea definiției codurilor fără memorie. Ultima definiție pe care trebuie să o înțelegem este setul de prefixe. O schemă ∑ are proprietatea unui prefix dacă, pentru oricare 1≤i, j≤r, i ≠ j, cuvântul B i nu este un prefix al cuvântului B j.
Mai simplu spus, un set de prefixuri este un set finit în care niciun element nu este prefixul (sau începutul) oricărui alt element. Un exemplu simplu de astfel de set este, de exemplu, alfabetul obișnuit.
Așadar, ne-am dat seama de definițiile de bază. Deci, cum se întâmplă codificarea fără memorie?
Apare în trei etape.
- Se compune un alfabet the al caracterelor mesajului inițial, iar caracterele alfabetului sunt sortate în ordine descrescătoare a probabilității lor de apariție în mesaj.
- Fiecare simbol a i din alfabet Ψ este asociat cu un anumit cuvânt B i din prefixul set Ω.
- Fiecare caracter este codat, urmat de combinarea codurilor într-un singur flux de date, ceea ce va fi rezultatul compresiei.
Unul dintre algoritmii canonici care ilustrează această metodă este algoritmul Huffman.
Algoritmul Huffman
Algoritmul Huffman folosește frecvența apariției acelorași octeți în blocul de date de intrare și se potrivește cu blocurile frecvente ale unui lanț de biți de lungimi mai scurte și invers. Acest cod este redundant minim. Luați în considerare cazul când, indiferent de fluxul de intrare, alfabetul fluxului de ieșire este format din doar 2 caractere - zero și unul.În primul rând, atunci când codificăm cu algoritmul Huffman, trebuie să construim circuitul ∑. Aceasta se face după cum urmează:
- Toate literele alfabetului de intrare sunt ordonate în ordine descrescătoare a probabilității. Toate cuvintele din alfabetul fluxului de ieșire (adică ceea ce vom codifica) sunt considerate inițial goale (reamintesc că alfabetul fluxului de ieșire este format doar din caractere (0,1)).
- Două caractere j-1 și j ale fluxului de intrare, care au cea mai mică probabilitate de apariție, sunt combinate într-un „pseudo-simbol” cu probabilitate p egală cu suma probabilităților caracterelor sale constitutive. Apoi adăugăm 0 la începutul cuvântului B j-1 și 1 la începutul cuvântului B j, care vor fi ulterior codurile de caractere a j-1 și respectiv j.
- Eliminăm aceste caractere din alfabetul mesajului inițial, dar adăugăm pseudo-simbol generat acestui alfabet (în mod natural, ar trebui să fie introdus în alfabet la locul potrivit, ținând cont de probabilitatea acestuia).
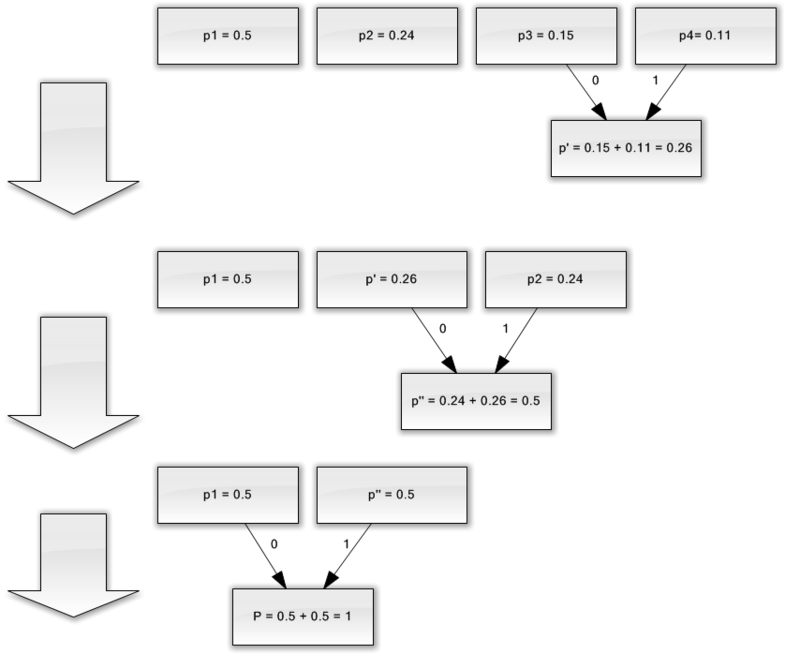
Pentru o ilustrare mai bună, luați în considerare un exemplu mic.
Să presupunem că avem un alfabet format din doar patru caractere - (un 1, un 2, un 3, un 4). De asemenea, presupunem că probabilitățile de apariție ale acestor simboluri sunt egale, respectiv, p 1 \u003d 0,5; p 2 \u003d 0,24; p 3 \u003d 0,15; p 4 \u003d 0.11 (suma tuturor probabilităților este, evident, egală cu una).
Deci, vom construi schema pentru acest alfabet.
- Combinați cele două caractere cu cele mai mici probabilități (0,11 și 0,15) în p "pseudo-caracterul".
- Combinăm cele două caractere cu cea mai mică probabilitate (0,24 și 0,26) în pseudo-caracterul p.
- Eliminăm caracterele combinate și introducem pseudo-caracterul rezultat în alfabet.
- În cele din urmă, combinați cele două personaje rămase și obțineți vârful arborelui.
Dacă ilustrați acest proces, primiți ceva de genul:
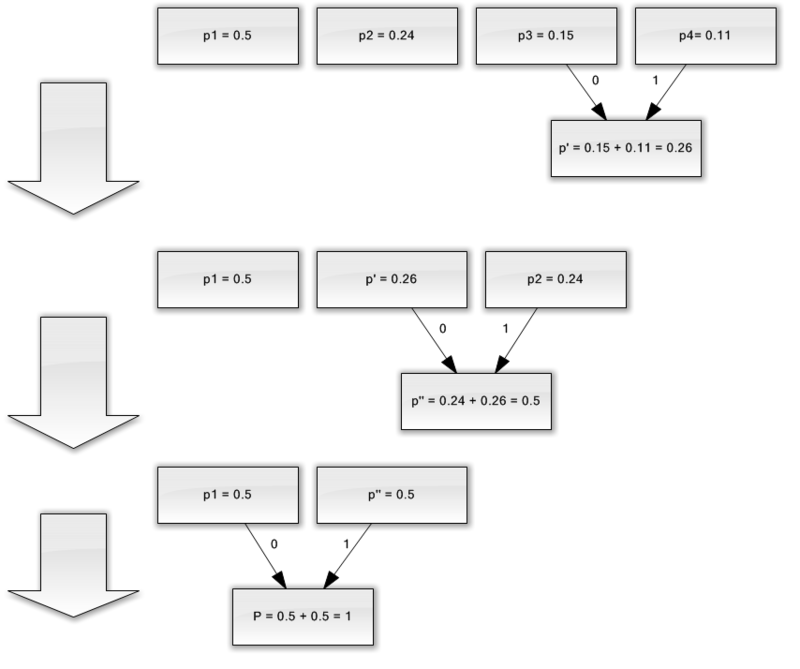
După cum puteți vedea, cu fiecare îmbinare, atribuim caracterele 0 și 1 caracterelor care urmează să fie îmbinate.
Astfel, când arborele este construit, putem obține cu ușurință codul pentru fiecare personaj. În cazul nostru, codurile vor arăta astfel:
A 1 \u003d 0
a 2 \u003d 11
a 3 \u003d 100
a 4 \u003d 101
Deoarece niciunul dintre aceste coduri nu este un prefix al oricărui altul (adică am primit prefixul notoriu set), putem identifica în mod unic fiecare cod din fluxul de ieșire.
Astfel, am obținut că cel mai frecvent personaj este codat de codul cel mai scurt, și invers.
Dacă presupunem că inițial, s-a folosit un octet pentru stocarea fiecărui caracter, atunci putem calcula cât am putut să reducem datele.
Să presupunem că am avut un șir de 1000 de caractere la intrare, în care personajul a 1 s-a produs de 500 de ori, un 2 240, un 3 150 și un 4 110 de ori.
Inițial, acest șir ocupa 8000 de biți. După codificare, obținem un șir cu lungimea de ∑p i l i \u003d 500 * 1 + 240 * 2 + 150 * 3 + 110 * 3 \u003d 1760 biți. Astfel, am putut comprima datele de 4,54 ori, cheltuind în medie 1,76 biți pentru codificarea fiecărui simbol stream.
Permiteți-mi să vă reamintesc că, în conformitate cu Shannon, lungimea medie a codurilor este. Substituind valorile noastre de probabilitate în această ecuație, obținem lungimea medie a codului egală cu 1.75496602732291, ceea ce este foarte, foarte aproape de rezultatul obținut.
Cu toate acestea, trebuie avut în vedere faptul că, pe lângă datele în sine, trebuie să păstrăm tabelul de codificare, care va crește ușor dimensiunea finală a datelor codate. Evident, în diferite cazuri se pot utiliza diferite variații ale algoritmului - de exemplu, uneori este mai eficient să se utilizeze un tabel de probabilitate predefinit, iar alteori este necesar să se compileze dinamic parcurgând date comprimabile.
concluzie
Așadar, în acest articol am încercat să vorbesc principii generale, prin care apare compresia fără pierderi și, de asemenea, considerat unul dintre algoritmii canonici - codarea Huffman.Dacă articolul este pe gustul comunității habro, atunci voi fi fericit să scriu o continuare, deoarece există multe alte lucruri interesante în ceea ce privește compresia fără pierderi; aceștia sunt atât algoritmi clasici, cât și transformări preliminare ale datelor (de exemplu, transformarea Burroughs-Wheeler) și, bineînțeles, algoritmi specifici pentru comprimarea sunetului, videoclipurilor și imaginilor (subiectul cel mai interesant, după părerea mea).
literatură
- Vatolin D., Ratushnyak A., Smirnov M. Yukin V. Metode de compresie a datelor. Arhivarea dispozitivului, compresia de imagini și video; ISBN 5-86404-170-X; Anul 2003
- D. Salomon. Compresia datelor, imaginii și sunetului; ISBN 5-94836-027-X; 2004.
Prelegerea numărul 4. Compresia informațională
Principii de compresiune informațională
Scopul compresiunii datelor este de a oferi o reprezentare compactă a datelor generate de sursă, pentru stocarea și transmiterea lor mai economică prin canale de comunicare.
Să presupunem că avem un fișier cu o dimensiune de 1 (unu) megabite. Trebuie să obținem un fișier mai mic din el. Nimic complicat - începem arhivatorul, de exemplu, WinZip și, prin urmare, obținem, de exemplu, un fișier cu dimensiunea de 600 kilobiți. Unde s-au dus restul de 424 de kilobiți?
Comprimarea informațiilor este o modalitate de a o codifica. În general, codurile sunt împărțite în trei mari grupuri - coduri de compresie (coduri eficiente), coduri rezistente la zgomot și coduri criptografice. Codurile proiectate pentru a comprima informațiile sunt împărțite, la rândul lor, în coduri fără pierderi și coduri cu pierderi. Codificarea fără pierderi implică recuperarea datelor exacte după decodare și poate fi utilizată pentru a comprima orice informație. Codificarea cu pierderi are, de obicei, o rată de compresie mult mai mare decât codificarea fără pierderi, dar permite unele abateri ale datelor decodate de la original.
Tipuri de compresie
Toate metodele de comprimare a informațiilor pot fi împărțite în două clase mari de disjuncție: compresia cu pierdere informații și comprimare fără pierderi informații.
Compresia fără pierderea informațiilor.
Aceste metode de compresie ne interesează în primul rând, deoarece sunt utilizate cu exactitate la transmiterea documentelor și programelor text, la emiterea lucrărilor finalizate către un client sau la crearea copiilor de rezervă ale informațiilor stocate pe un computer.
Metodele de compresie din această clasă nu pot permite pierderea informațiilor, de aceea se bazează doar pe eliminarea redundanței sale, iar informațiile au redundanță aproape întotdeauna (deși cineva nu a mai condensat-o înainte). Dacă nu ar fi redundanță, nu ar fi nimic de comprimat.
Iată un exemplu simplu. Limba rusă are 33 de litere, zece cifre și aproximativ o duzină de semne de punctuație și alte caractere speciale. Pentru textul care este înregistrat numai cu majuscule rusești (ca în telegrame și radiograme) șaizeci de semnificații diferite ar fi fost suficiente. Cu toate acestea, fiecare caracter este de obicei codat într-un octet care conține 8 biți și poate exprima 256 de coduri diferite. Aceasta este prima bază pentru concediere. Pentru textul nostru „telegrafic”, șase biți pentru fiecare personaj ar fi suficiente.
Iată un alt exemplu. În codificarea de caractere internaționale ASCII același număr de biți este alocat pentru codificarea oricărui caracter (8), în timp ce toată lumea știa de mult timp că cele mai comune caractere au sens să se codifice cu mai puține caractere. Deci, de exemplu, în „codul Morse” literele „E” și „T”, care se găsesc adesea, sunt codificate cu un singur caracter (respectiv, acesta este un punct și o liniuță). Și astfel de litere rare precum „Yu” (- -) și „Ts” (- -) sunt codificate cu patru caractere. Codificarea insuficientă este al doilea motiv pentru concediere. Programele care efectuează compresia informațiilor pot introduce propria codificare (diferită pentru diferite fișiere) și pot atribui un anumit tabel (dicționar) fișierului comprimat, din care programul de dezambalare va afla cum sunt codificate anumite simboluri sau grupurile lor în acest fișier. Algoritmele bazate pe transcodarea informațiilor sunt numite algoritmi Huffman.
Prezența fragmentelor duplicate este al treilea motiv pentru concediere. Acest lucru este rar în texte, dar în tabele și grafice, repetarea codurilor este o întâmplare frecventă. Deci, de exemplu, dacă numărul 0 este repetat de douăzeci de ori la rând, atunci nu are sens să punem douăzeci de octeți zero. În schimb, ele pun un zero și un coeficient de 20. Se numesc astfel de algoritmi bazate pe detectarea repetărilor metodeRLE (alerga lungime Codare).
Secvențe mari de repetare a octeților identici se deosebesc în special prin ilustrații grafice, dar nu fotografice (există o mulțime de zgomot, iar punctele învecinate variază semnificativ în parametri), dar cele pe care artiștii le pictează într-o culoare „netedă”, ca în filmele de animație.
Compresie pierdută.
Compresia cu pierderea informațiilor înseamnă că după despachetarea arhivei comprimate, vom primi un document care este ușor diferit de cel care a fost la început. Este clar că, cu cât gradul de compresie este mai mare, cu atât mai mare este pierderea și invers.
Desigur, astfel de algoritmi nu se aplică documentelor text, tabelelor bazei de date și mai ales programelor. Puteți supraviețui cumva la distorsiuni minore într-un text simplu, neformatat, dar denaturarea a cel puțin un bit într-un program îl va face complet nefuncțional.
În același timp, există materiale în care merită sacrificat câteva procente de informații pentru a obține compresia de zeci de ori. Acestea includ ilustrații fotografice, videoclipuri și compoziții muzicale. Pierderea informațiilor în timpul compresiei și a despachetării ulterioare în astfel de materiale este percepută ca apariția unor „zgomote” suplimentare. Dar, deoarece există încă un anumit „zgomot” la crearea acestor materiale, creșterea sa mică nu pare întotdeauna critică, iar câștigul în dimensiunile fișierelor dă unul uriaș (de 10-15 ori la muzică, de 20-30 de ori pe materiale foto și video).
Algoritmii de compresie cu pierderi de informații includ astfel de algoritmi cunoscuți precum JPEG și MPEG. Algoritmul JPEG este utilizat la comprimarea imaginilor. Fișierele de imagine comprimate cu această metodă au extensia jpg. Algoritmii MPEG sunt folosiți la comprimarea videoclipurilor și a muzicii. Aceste fișiere pot avea diferite extensii, în funcție de programul specific, dar cele mai cunoscute sunt .MPG pentru video și. MP3 pentru muzică.
Algoritmii de compresie a pierderilor de informații sunt folosiți numai pentru sarcinile consumatorilor. Acest lucru înseamnă, de exemplu, că dacă o fotografie este transmisă pentru vizualizare și muzică pentru redare, atunci astfel de algoritmi pot fi aplicați. Dacă sunt transferate pentru procesare ulterioară, de exemplu pentru editare, atunci nu este permisă pierderea informațiilor din materialul sursă.
Mărimea pierderii admisibile în compresiune poate fi de obicei controlată. Acest lucru vă permite să experimentați și să obțineți raportul calitate / mărime optim. În ilustrațiile fotografice destinate a fi afișate pe un ecran, pierderea de 5% din informații este de obicei necritică, iar în unele cazuri poate fi tolerată 20-25%.
Algoritmi de compresie fără pierderi
Codul Shannon Feno
Pentru discuții suplimentare, va fi convenabil să prezentăm fișierul sursă cu text ca o sursă de caractere care apar câte una la ieșire. Nu știm dinainte care personaj va fi următorul, dar știm că cu probabilitatea p1 va apărea litera „a”, cu probabilitatea p2 va apărea litera „b” etc.
În cel mai simplu caz, vom considera toate caracterele textului independente unele de altele, adică. probabilitatea apariției personajului următor nu depinde de valoarea personajului precedent. Desigur, nu este așa pentru un text semnificativ, dar acum avem în vedere o situație foarte simplificată. În acest caz, afirmația „simbolul poartă mai multe informații, cu atât este mai mică probabilitatea apariției acestuia”.
Să ne imaginăm un text al cărui alfabet constă din doar 16 litere: A, B, C, D, D, E, F, Z, I, K, L, M, H, O, P, P. Fiecare dintre aceste caractere poate codează cu doar 4 biți: de la 0000 la 1111. Acum imaginați-vă că probabilitatea apariției acestor caractere sunt distribuite după cum urmează:
Suma acestor probabilități este, desigur, una. Împărțim aceste simboluri în două grupuri, astfel încât probabilitatea totală a simbolurilor fiecărui grup este de ~ 0,5 (Fig.). În exemplul nostru, acestea vor fi grupuri personaje AB și GR. Cercurile din figură, care notează grupuri de caractere, sunt numite noduri sau noduri, iar structura acestor noduri se numește arbore binar (arbore B). Alocați fiecărui nod propriul său cod, desemnând un nod cu numărul 0, iar celălalt cu numărul 1.
Din nou, împărțim primul grup (AB) în două subgrupuri, astfel încât probabilitățile lor totale să fie cât mai aproape unele de altele. Adăugați numărul 0 la codul primului subgrup și numărul 1 la codul celui de-al doilea. 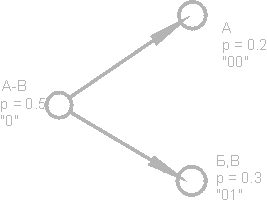
Vom repeta această operație până când un simbol rămâne pe fiecare vertex al „copacului” nostru. Un arbore complet pentru alfabetul nostru va avea 31 de noduri.
Codurile de caractere (nodurile din extremitatea dreaptă a arborelui) au coduri de lungime inegală. Deci, litera A, care are o probabilitate p \u003d 0,2 pentru textul nostru imaginar, este codificată cu doar doi biți, iar litera P (care nu este prezentată în figură), care are o probabilitate p \u003d 0,013, este codată cu o combinație de șase biți.
Prin urmare, principiul este evident - caracterele care apar frecvent sunt codificate cu mai puțini biți, rareori caracterele sunt codate mai mult. Ca urmare, numărul mediu de biți pe caracter va fi egal cu
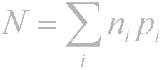
unde ni este numărul de biți care codifică caracterul i-a, pi este probabilitatea apariției caracterului i.
Cod Huffman.
Algoritmul Huffman implementează cu grație ideea generală a codificării statistice folosind seturi de prefixuri și funcționează astfel:
1. Scriem pe rând toate caracterele alfabetului în ordine crescătoare sau descendentă a probabilității apariției lor în text.
2. Combinați în mod constant cele două simboluri cu cele mai mici probabilități de apariție într-un nou simbol compozit, a cărui probabilitate de apariție se presupune a fi egală cu suma probabilităților simbolurilor sale constitutive. La final, vom construi un arbore, fiecare nod având o probabilitate totală a tuturor nodurilor de sub el.
3. Urmărim calea către fiecare frunză a copacului, marcând direcția către fiecare nod (de exemplu, spre dreapta - 1, spre stânga - 0). Secvența rezultată dă un cod de comandă corespunzător fiecărui caracter (Fig.).
Construiți un arbore de cod pentru un mesaj cu următorul alfabet:
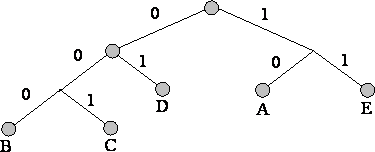
Dezavantaje ale metodelor
Cea mai mare dificultate a codurilor, după cum rezultă din discuția anterioară, este necesitatea de a avea tabele de probabilitate pentru fiecare tip de date comprimabile. Aceasta nu este o problemă dacă se știe că textul în engleză sau rusă este comprimat; pur și simplu furnizăm codificatorul și decodificatorul cu un arbore de cod adecvat textului în engleză sau rusă. În cazul general, când probabilitatea caracterelor pentru datele de intrare nu este cunoscută, codurile statice ale lui Huffman funcționează ineficient.
Soluția la această problemă este o analiză statistică a datelor codate, efectuată în timpul primei treceri prin date și compilarea unui arbore de coduri bazat pe acestea. De fapt, codificarea este efectuată de a doua trecere.
Un alt dezavantaj al codurilor este că lungimea minimă a codului de cod nu poate fi mai mică decât una, în timp ce entropia mesajului poate fi de 0,1 și 0,01 biți / literă. În acest caz, codul devine semnificativ redundant. Problema este rezolvată prin aplicarea algoritmului pe blocuri de caractere, dar apoi procedura de codare / decodare este complicată, iar arborele de cod este extins semnificativ, care în cele din urmă trebuie salvat împreună cu codul.
Aceste coduri nu țin cont de relația dintre personajele care sunt prezente în aproape orice text. De exemplu, dacă vedem litera q într-un text englezesc, putem spune cu încredere că litera u o va urma.
Codare de grup - Ruptura de lungime (RLE) - unul dintre cele mai vechi și mai simple algoritmi de arhivare. Compresia în RLE are loc prin înlocuirea șirurilor de octeți identici cu perechi de contor, de valori. („Roșu, roșu,…, roșu” este scris ca „N roșu”).
Una dintre implementările algoritmului este următoarea: ele caută un octet cel mai puțin întâlnit, îl numesc prefix și înlocuiesc șirurile caracterelor identice cu tripluri „prefix, contor, valoare”. Dacă acest octet se găsește în fișierul sursă o dată sau de două ori la rând, atunci este înlocuit cu o pereche de „prefix, 1” sau „prefix, 2”. Rămâne o pereche nefolosită „prefix, 0”, care poate fi folosită ca semn al finalului datelor ambalate.
Când codificați fișiere exe, puteți căuta și pacheta secvențe ale formularului AxAyAzAwAt ..., care se găsesc deseori în resurse (șiruri în codificarea Unicode)
Aspectele pozitive ale algoritmului includ faptul că nu necesită memorie suplimentară atunci când lucrați și este executat rapid. Algoritmul este utilizat în formatele PCX, TIFF, BMP. O caracteristică interesantă a codificării grupurilor în PCX este că gradul de arhivare pentru unele imagini poate fi crescut semnificativ doar modificând ordinea culorilor din paleta de imagini.
Codul LZW (Lempel-Ziv și Welch) este de departe unul dintre cele mai comune coduri de compresie fără pierderi. Cu ajutorul codului LZW, compresia este realizată în formate grafice precum TIFF și GIF, cu ajutorul modificărilor LZW foarte multe arhive universale își îndeplinesc funcțiile. Algoritmul se bazează pe căutarea în fișierul de intrare a secvențelor repetate de caractere care sunt codificate în combinații de 8 - 12 biți lungime. Astfel, acest algoritm are cea mai mare eficiență în fișierele text și pe fișierele grafice, în care există secțiuni mari de o singură culoare sau secvențe repetate de pixeli.
Lipsa pierderilor de informații în timpul codificării LZW a dus la utilizarea pe scară largă a formatului TIFF bazat pe acesta. Acest format nu impune nicio restricție asupra dimensiunii și adâncimii culorii imaginii și este răspândit, de exemplu, în tipărire. Un alt format bazat pe LZW - GIF - este mai primitiv - vă permite să stocați imagini cu o adâncime de culoare de cel mult 8 biți / pixel. La începutul fișierului GIF este o paletă - un tabel care stabilește corespondența între indicele de culoare - un număr în intervalul de la 0 la 255 și o valoare de culoare adevărată, pe 24 de biți.
Algoritmi de compresie a pierderilor de informații
Algoritmul JPEG a fost dezvoltat de un grup de companii numit Joint Photographic Experts Group. Scopul proiectului a fost de a crea un standard de compresie extrem de eficient atât pentru imagini alb-negru cât și pentru culori, iar acest obiectiv a fost realizat de dezvoltatori. În prezent, JPEG este utilizat pe scară largă acolo unde este necesar un grad ridicat de compresie - de exemplu, pe Internet.
Spre deosebire de algoritmul LZW, codarea JPEG este codarea cu pierderi. Algoritmul de codificare în sine se bazează pe o matematică foarte complexă, dar în termeni generali poate fi descris după cum urmează: imaginea este împărțită în pătrate de 8 * 8 pixeli și apoi fiecare pătrat este convertit într-un lanț secvențial de 64 de pixeli. Mai mult, fiecare astfel de lanț este supus așa-numitei transformări DCT, care este una dintre varietățile transformării discrete Fourier. Acesta constă în faptul că secvența de intrare a pixelilor poate fi reprezentată ca suma componentelor sinusoidale și cosiniene cu mai multe frecvențe (așa-numitele armonice). În acest caz, trebuie să cunoaștem doar amplitudinile acestor componente pentru a restabili secvența de intrare cu un grad suficient de precizie. Cu cât cunoaștem mai multe componente armonice, cu atât va exista o discrepanță între imaginea originală și cea comprimată. Majoritatea codificatorilor JPEG vă permit să reglați raportul de compresie. Acest lucru este obținut într-un mod foarte simplu: cu cât raportul de compresie este mai mare, cu atât mai puțin armonice fiecare bloc de 64 de pixeli va fi reprezentat.
Desigur, rezistența acestui tip de codare este un raport de compresie mare, menținând în același timp adâncimea originală a culorii. Această proprietate este cea care a determinat utilizarea pe scară largă pe internet, unde reducerea dimensiunii fișierelor are o importanță crucială, în enciclopedii multimedia, unde este necesar să se păstreze cât mai multe elemente grafice într-o cantitate limitată.
O proprietate negativă a acestui format nu poate fi recuperată prin orice mijloace, deteriorarea sa inerentă a calității imaginii. Acest fapt trist nu permite utilizarea sa în tipărire, unde calitatea este primordială.
Cu toate acestea, formatul JPEG nu este limita de perfecțiune din dorința de a reduce dimensiunea fișierului final. De curând, cercetările intense sunt efectuate în domeniul așa-numitei transformări de undă (sau transformare de rupere). Pe baza celor mai complicate principii matematice, codificatoarele wavelet vă permit să obțineți mai multă compresie decât JPEG, cu mai puține pierderi de informații. În ciuda complexității matematicii transformării de undă, este mai simplă în implementarea software decât JPEG. Deși algoritmii de compresie a undelor sunt încă la început, au un viitor deosebit.
Compresie fractală
Compresia imaginii fractale este un algoritm de compresie a imaginilor cu pierderi bazat pe aplicarea unor sisteme funcționale iterabile (IFS, care sunt de obicei transformări afine) la imagini. Acest algoritm este cunoscut pentru faptul că, în unele cazuri, permite obținerea unor raporturi de compresie foarte mari (cele mai bune exemple sunt de până la 1000 de ori cu o calitate vizuală acceptabilă) pentru fotografii reale ale obiectelor naturale, ceea ce nu este disponibil în principiu pentru alți algoritmi de compresie a imaginii. Datorită situației dificile cu brevetarea, algoritmul nu a fost utilizat pe scară largă.
Arhivarea fracturilor se bazează pe faptul că folosind coeficienții unui sistem de funcții iterabile, imaginea este prezentată într-o formă mai compactă. Înainte de a privi procesul de arhivare, să analizăm modul în care IFS construiește o imagine.
Strict vorbind, IFS este un set de transformări afine tridimensionale care traduc o imagine în alta. Punctele din spațiul tridimensional sunt transformate (coordonată x, coordonată y, luminozitate).
Baza metodei de codare fractală este detectarea secțiunilor auto-similare din imagine. Posibilitatea aplicării teoriei sistemelor funcționale iterabile (IFS) la problema compresiunii imaginii a fost investigată pentru prima dată de Michael Barnsley și Alan Sloan. Ei și-au brevetat ideea în 1990 și 1991. Jacquin a introdus o metodă de codare fractală care folosește blocuri de subimagini de domeniu și domeniu, blocuri în formă de pătrat care acoperă întreaga imagine. Această abordare a devenit baza pentru majoritatea metodelor de codare fractală utilizate astăzi. A fost dezvoltat de Yuval Fisher și o serie de alți cercetători.
În conformitate cu această metodă, imaginea este împărțită în mai multe subimaje de rang care nu se suprapun (subimagii de rang) și sunt determinate o mulțime de subimaje de domeniu suprapuse (subimagii de domeniu). Pentru fiecare bloc de rang, algoritmul de codificare găsește cel mai potrivit bloc de domeniu și transformarea afină care traduce acest bloc de domeniu într-un bloc de rang dat. Structura imaginii este mapată într-un sistem de blocuri de rang, blocuri de domenii și transformări.
Ideea este aceasta: să presupunem că imaginea originală este un punct fix al unui fel de mapare compresivă. Apoi, în loc de imaginea în sine, este posibil să vă amintiți într-un fel acest ecran, iar pentru restaurare este suficient să aplicați în mod repetat acest ecran pe orice imagine de pornire.
Prin teorema lui Banach, astfel de iterații duc întotdeauna la un punct fix, adică la imaginea inițială. În practică, întreaga dificultate constă în găsirea celui mai potrivit afișaj compresiv din imagine și în stocarea compactă. De regulă, algoritmii de căutare de mapare (adică algoritmi de compresie) au o forță brută puternic și necesită costuri de calcul mari. În același timp, algoritmii de recuperare sunt destul de eficienți și rapide.
Pe scurt, metoda propusă de Barnsley poate fi descrisă după cum urmează. Imaginea este codificată de mai multe transformări simple (în cazul nostru, afin), adică este determinată de coeficienții acestor transformări (în cazul nostru A, B, C, D, E, F).
De exemplu, imaginea curbei Koch poate fi codată cu patru transformări afine, o vom determina în mod unic folosind doar 24 de coeficienți.
Drept urmare, punctul va merge neapărat în interiorul zonei negre din imaginea originală. După ce am efectuat această operație de multe ori, vom umple tot spațiul negru, restabilind astfel imaginea.

Cele mai cunoscute sunt două imagini obținute folosind IFS: triunghiul Sierpinski și feriga Barnsley. Prima este definită de trei, iar a doua de cinci transformări afine (sau, în terminologia noastră, lentile). Fiecare conversie este specificată de bytes citite literal, în timp ce o imagine construită cu ajutorul lor poate lua mai mulți megabyți.
Devine clar cum funcționează arhivarul și de ce durează atât de mult timp. De fapt, compresia fractală este o căutare a unor zone similare din imagine și determinarea parametrilor transformărilor afine pentru acestea.
În cel mai rău caz, dacă algoritmul de optimizare nu este utilizat, acesta va necesita enumerarea și compararea tuturor fragmentelor de imagine posibile de diferite dimensiuni. Chiar și pentru imaginile mici cu discretitate luate în considerare, obținem un număr astronomic de opțiuni care trebuie căutate. Chiar și o restrângere bruscă a claselor de transformare, de exemplu, datorită reducerii doar a unui anumit număr de ori, nu va permite realizarea unui timp acceptabil. În plus, calitatea imaginii este pierdută. Marea majoritate a studiilor în domeniul compresiei fractale vizează acum reducerea timpului de arhivare necesar obținerii unei imagini de înaltă calitate.
Pentru un algoritm de compresie fractală, precum și pentru alți algoritmi de compresie cu pierderi, mecanismele cu care va fi posibil să se controleze raportul de compresie și gradul de pierdere sunt foarte importante. Până în prezent, a fost dezvoltat un set suficient de mare de astfel de metode. În primul rând, este posibil să se limiteze numărul de transformări, oferind în mod evident un raport de compresie nu mai mic decât o valoare fixă. În al doilea rând, puteți solicita ca într-o situație în care diferența dintre fragmentul procesat și cea mai bună aproximare a acestuia să fie mai mare decât o anumită valoare de prag, acest fragment să fie în mod necesar strivit (mai multe lentile trebuie înfășurate). În al treilea rând, este posibil să interzică fragmentarea fragmentelor mai mici decât, să spunem, patru puncte. Modificând valorile pragului și prioritatea acestor condiții, puteți controla foarte flexibil raportul de compresie al imaginii: de la potrivire bit în orice raport de compresie.
Comparație cu JPEG
Astăzi, cel mai frecvent algoritm de arhivare grafică este JPEG. Comparați-l cu compresia fractală.
În primul rând, remarcăm faptul că atât unul cât și celălalt funcționează cu imagini color pe 8 biți (în scară de gri) și 24 de biți color. Ambii sunt algoritmi de compresie cu pierderi și asigură raporturi de arhivare strânse. Atât algoritmul fractal, cât și JPEG au posibilitatea de a crește raportul de compresie prin creșterea pierderii. În plus, ambii algoritmi sunt foarte bine paralelați.
Diferențele încep dacă avem în vedere timpul necesar pentru arhivarea / dezarhivarea algoritmilor. Deci, algoritmul fractal comprimă sute și chiar de mii de ori mai mult decât JPEG. Desfacerea imaginii, dimpotrivă, se va întâmpla de 5-10 ori mai repede. Prin urmare, dacă imaginea va fi comprimată o singură dată și transmisă prin rețea și despachetată de mai multe ori, este mai profitabil să folosiți algoritmul fractal.
JPEG folosește descompunerea imaginii în funcții cosiniene, astfel încât pierderea în ea (chiar și la pierderea minimă specificată) apare în valuri și halos la marginea tranzițiilor de culoare ascuțite. Pentru acest efect, nu le place să-l folosească atunci când comprimă imagini care sunt pregătite pentru imprimare de înaltă calitate: acolo acest efect poate deveni foarte vizibil.
Algoritmul fractal este lipsit de acest dezavantaj. Mai mult, atunci când imprimați o imagine, trebuie să efectuați o operație de scalare de fiecare dată, deoarece rasterul (sau linia) a dispozitivului de imprimare nu coincide cu rasterul imaginii. La convertire, pot apărea, de asemenea, mai multe efecte neplăcute, care pot fi combătute fie prin scalarea imaginii programatic (pentru dispozitivele de tipărire cu costuri scăzute, cum ar fi imprimantele convenționale cu laser și cu jet de cerneală), fie echipând dispozitivul de imprimare cu propriul procesor, hard disk și un set de programe de procesare a imaginilor (pentru tipografiile fotografice scumpe). După cum puteți ghici, atunci când utilizați algoritmul fractal, astfel de probleme nu apar.
Eliminarea JPEG de către algoritmul fractal în utilizare pe scară largă nu se va întâmpla curând (cel puțin datorită vitezei mici de arhivare a acesteia din urmă), cu toate acestea, în domeniul aplicațiilor multimedia, în jocurile pe calculator, utilizarea acestuia este justificată.
În prima parte vom lua în considerare formate audio. Ce este FLAC, WavPack, TAK, Monkey's Audio, OptimFROG, ALAC, WMA, Shorten, LA, TTA, LPAC, MPEG-4 ALS, MPEG-4 SLS, Real Lossless? Știți câte tipuri de audio Până în prezent, avem de-a face cu formate de compresie audio fără pierderi și ne uităm la răspunsul la întrebarea despre numărul de extensii audio de la sfârșitul articolului.
Deci, mai întâi definim termenii:
« algoritmul „Aceasta este o prescripție exactă care definește procesul de calcul care trece de la datele sursei variabile la rezultatul dorit.”
« codecul (Codec englez, de la coder / decodificator - codificator / decodificator - codificator / decodificator sau compresor / decompresor) - dispozitiv sau program capabil să convertească date sau semnal. Codec-urile pot fie codifica un flux / semnal (adesea pentru transmisie, stocare sau criptare), sau îl pot decoda pentru a-l vizualiza sau modifica într-un format mai potrivit pentru aceste operațiuni. Codec-urile sunt adesea utilizate în procesarea digitală a sunetului video.
Majoritatea codecurilor pentru date audio și vizuale utilizează o compresie cu pierderi pentru a obține o dimensiune acceptabilă a fișierului terminat (comprimat). Există, de asemenea, codec-uri de compresie fără pierderi. "
« Compresie fără pierderi (Engleză Lossless data compression) este o metodă de comprimare a informațiilor, folosind care informațiile codate pot fi restaurate exact la biți. În acest caz, datele originale sunt complet restabilite din starea comprimată. Pentru fiecare tip de informație digitală, de regulă, există propriii algoritmi de compresie fără pierderi. "
Compresia de date fără pierderi este utilizată atunci când identitatea datelor comprimate față de original este importantă. Un exemplu obișnuit este fișierele, documentele și codul sursă executabile. Programele care folosesc formate de compresie fără pierderi se numesc arhive, toată lumea cunoaște formatele de fișiere populare ZIP, sau RAR, Unix-utilitate Gzip etc. Toate aceste programe diferă în algoritmii aplicați (unul sau mai multe) și, prin urmare, proprietăți de compresie diferite ale fișierelor diferite.
Partea I. - TEORIE:
Metodele de compresie sau algoritmii de compresie fără pierderi pot fi distribuite după tipul de date pentru care au fost create. Există trei tipuri principale de date: text, imagini și sunet.
În principiu, orice algoritm de compresie a datelor multifuncționale fără pierderi (multifuncțional înseamnă că poate prelucra orice tip de date binare) poate fi utilizat pentru orice tip de date, dar majoritatea sunt ineficiente pentru fiecare tip principal. Datele sonore, de exemplu, nu pot fi bine comprimate printr-un algoritm de compresiune a textului și invers.
Dintre metodele de compresie, pot fi notate următoarele: compresia entropiei, metodele de dicționar, metodele statistice. Fiecare metodă este bună pentru un anumit tip de date și include o serie de algoritmi.
Compresia entropiei: algoritmul Huffman · Algoritmul adaptativ Huffman · Codificare aritmetică (Shannon - Algoritmul Fano · Interval) · Coduri Golomb · Delta · Cod universal (Elias · Fibonacci)
Metode de vocabular: RLE Deflate LZ (LZ77 / LZ78 LZSS LZW LZWL LZO LZMA LZX LZRW LZJB LZT)
Algoritmii modelului statistic pentru text (sau date de text binar, cum ar fi fișierele executabile) includ: transformarea Barrows-Wheeler (pre-procesare de blocare care face compresia mai eficientă) · LZ77 și LZ78 (folosind DEFLATE) · LZW.
Altele: RLE · CTW · BWT · MTF · PPM · DMC
Adesea, doar algoritmi bine dezvoltați primesc un nume, în timp ce evoluțiile recente implică doar (utilizare generală, standardizare etc.) sau deloc specificate.
Dar înapoi la subiectul nostru. Pentru codificarea algoritmilor de date audio adecvate:
Algoritmul Huffman (folosit și DEFLATE), codificare aritmetică
Apple fără pierderi — ALAC (Apple Lossless Audio Codec)
Codare audio fără pierderi — cunoscut și sub denumirea de MPEG-4 ALS
Codec audio audio fără pierderi — FLAC
Ambalare fără pierderi Meridian — MLP
Audio Monkey — APE
OptimFROG
RealPlayer — RealAudio Lossless
Scurtarea — SHN
TAK — (T) om "s verlustfreier (A) udio (K) ompressor (germană)
TTA — Adevărat audio fără pierderi
WavPack — Wavpack fără pierderi
Wma fără pierderi — Windows Media Lossless
DTS — DTS Surround Sound
Familia Lempel-Ziv de algoritmi, RLE (codare pe lungime de rulare)
FLAC (Codec audio audio fără pierderi)
Audio al maimuței (APE)
TTA (True Audio)
TTE
LA(LosslessAudio)
RealAudio Lossless
WavPack și altele
După cum ați observat, majoritatea codec-urilor pentru compresia fără pierderi folosesc două (uneori mai multe) tipuri diferite de algoritmi: unul generează un model statistic pentru datele primite, celălalt afișează datele primite într-o reprezentare bit, folosind un model pentru a obține „probabilistic” (adică întâlnit frecvent) date care sunt utilizate mai des decât „incredibile”. Beneficiu - reducerea dimensiunii, calcularea - mai mult timp de procesor necesar pentru codificare / decodare.
Când ne-am dat seama de o mică teorie, vom trece la codec-urile noastre pentru comprimarea datelor audio, care au fost scrise de foarte mulți: Codec audio Lossless gratuit, WavPack, TAK, Monkey's Audio (.ape, apl), OptimFROG (.ofr), Apple Lossless Audio Codec, WMA, Scurtare (.SHN), LosslessAudio, True Audio, Lossless Predictive Audio Coder (.LPAC), MPEG-4 ALS, MPEG-4 SLS (.mp4), Real Lossless sau RealAudio Lossless, Windows Media Audio Lossless, DTS .. Și acest lucru este departe de toate, multe companii producătoare de echipamente profesionale de înregistrare au inventat și continuă să își inventeze propriile formate.
Un astfel de mare format de compresie de date audio sunt cauzate de imperfecțiunile tehnice ale platformelor (majoritatea codec-urilor enumerate au fost scrise la sfârșitul anilor 90), marketingul (în cazul ALAC) și publicul matematic și universitar sunt foarte interesați de algoritmii de compresie a datelor.
În plus față de cele de mai sus, există (a existat) o mulțime de mulți arhivatori audio și codec-uri audio uitate meritat sau nu. Caracteristicile tehnice ale unora pot fi găsite în tabel:
se poate face clic:
Vom lua în considerare mai detaliat doar cele care sunt utilizate pe scară largă și care, la momentul scrierii, pot fi găsite pe internet. Există doar o duzină dintre ei.
Partea a II-a - PRACTICA:
De la stânga la dreapta: 1. SSDS de zonă albastră (Sony Dynamic Digital Sound), 2. zona gri Dolby Digital (între perforare), 3. Audio analogic (ca în înregistrare) și 4. cod de timp DTS (albastru).
Iată o nouă comparație pentru anul 2009 din nouă dintre cele de mai sus:
Partea a III-a. - TESTARE:
Comparația a fost realizată pe platformă:
CPU: DualCore Intel Core i3 530, 2933 MHz (x86, x86-64, MMX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2)
Plăci de bază. placa: Asus P7H55-V
RAM: 2x2Gb DDR3-1333
HDD: Seagate SATA 160 GB 8 MB memorie cache (sistem), Hitachi SATA-II 500GB 16 MB memorie cache (Sursa), Hitachi SATA-II 1000 GB 32 MB memorie cache (destinație)
1. Lossless Audio (LA) - Acest codec foarte vechi (2004) a devenit câștigătorul incontestabil al compresiei. În același timp, trebuie menționat că viteza de codare este destul de acceptabilă (în comparație cu același OptimFROG sau WavPack), precum și o viteză de decodare suficientă. Deși fișierul LA nu a fost decodificat folosind pluginul foo_benchmark, acesta a jucat perfect, fără a întârzia sau a defila întârzieri.
Nu ne putem întreba decât de ce autorul a abandonat un codec atât de frumos, fără să deschidă măcar codul sursă.
2. OptimFROG - Nu prea departe de LA. Dar viteza sa cu greu poate fi numită rapidă. În plus, o întârziere mare la derularea unui fișier este un moment neplăcut - uneori este foarte enervant.
3. Audio Monkey - Un codec popular, dar intensiv în resurse. Oferă o compresie foarte mare, dar are din nou probleme de defilare. (Autorul testului pare să fi strâns fișierul cu opțiunea „Insane”, care este încă plină de pierderi de date).
4. TAK - Acest codec dezvoltat activ nu încetează. Dacă țineți cont de toți cei trei parametri (compresie, codare, decodare), TAK arată cel mai atractiv. Viteza mare de operare se explică prin utilizarea activă a optimizărilor procesorului (inclusiv SSSE3). Iar utilizarea a două nuclee oferă o creștere aproape dublă a vitezei de codare! Astfel, în cazul TAK, avantajul utilizării procesoarelor moderne este cel mai vizibil.
5. WavPack - să fiu sincer, nu știu de ce acest codec a câștigat popularitate. Codificarea prin compresie medie produce rezultate comparabile cu FLAC, iar utilizarea modurilor de compresie înaltă duce la o scădere nejustificată a vitezei. Deși, principalul avantaj al acestui codec este suportul larg și funcționalitatea acestuia (inclusiv suportul pentru audio multi-canal, modul hibrid), însă vă reamintesc că nu considerăm această latură a problemei în acest test.
6. Audio True (TTA) - aici trebuie menționat, cu excepția faptului că o viteză de codificare foarte mare și un raport de compresie acceptabil (puțin mai mare decât cel al FLAC). Mai mult, viteza de decodare nu poate fi numită foarte mare.
7. FLAC- raportul de compresie este mediu, dar viteza de decodare este mulțumită. Este adevărat, principalul motiv pentru conducerea acestui codec în rândul publicului este open source și, ca urmare, cel mai larg suport hardware / software.
8. Apple Lossless (ALAC) - Unul dintre acele codecuri care nu sunt marcabile, dar continuă să fie implantat în mod activ de dezvoltatori (în acest caz, Apple). Viteză scăzută de compresie și decodare. Viteza de compresie este medie. Cu excepția utilizatorilor de iPod, nu au de ales.
9. Wma fără pierderi - Un caz similar cu ALAC, dar aici avem de-a face cu societatea gigantă Microsoft. Și mai puțin compresia, rata medie de compresie. Viteza de decodare este relativ mare. Este dificil să ne imaginăm un caz în care ar fi necesar să utilizăm acest codec particular fără pierderi.
Partea a IV-a - CONCLUZII GENERALE:
Alegerea este simplă și constă în două puncte:
Dacă spațiul pe disc este important, atunci folosim Audio Monkey (ARE comprimă cu 8-12% mai bine decât FLAC, care pe un disc de 1 TB va avea aproximativ 100 GB sau aproximativ 300 de albume CD standard). Același lucru este valabil și pentru distribuția pe internet. este în format Audio Monkey cu opțiune de compresie Extra High. Nu folosesc diferite sisteme LA și altele, deoarece câștigul obținut din utilizarea lor în comparație cu Monkey's Audio este mic.
Dacă compatibilitatea cu diverși jucători și piese de fier care funcționează sub Linux este importantă și nu folosiți numai FLAC. Deși IMHO pentru jucători, este destul de potrivit pentru el și MP3, pentru că principalul lucru nu este sunetul, ci MUZICA!
În viitor, vom analiza dezvoltarea TTA, dar părerea mea subiectivă este că TTA a întârziat deja locomotiva cu aburi până la „distanța fără adăpost”.
Pentru „driverele de mac” și „Ai-fonturi” - alegerea din câte știu eu până acum este una - o tamburină și dansează în jurul diferitor transcodere în format ALAC.
Și amintiți-vă, puteți transfera fișierele întotdeauna de la un codec la altul și, fără pierderi de calitate, acesta este ceea ce codec-urile de compresie fără pierderi sunt bune, în contrast cu codec-urile cu compresie pierdută.
Numerarea "lirică" a Digresiunii ONCE.
Pentru „Udifilov”. Diferențe în formatele de sunet - NU! „Nu culoarea naturală a înălțimii”, „ilizibilitatea ușoară a pumnului”, cum ar fi „voalul din mijloc cu pătrunderea scenei” - acesta este în SISTEMUL tău. Codec-urile nu joacă, decodează, nu adaugă nimic și nu șterge nimic.
Digresiunea este numărul „liric” DOUĂ.
Acest articol este scris pentru iubitorii de muzică și colecționari de muzică - începători și țărani de mijloc, același iubitor de muzică și colecționar.
Gurami, Kvods, Sensei și alți Mari Helmsmen din Lumea Audio, precum și Udifils Militanți, nu vor fi interesați aici. Scrieți-vă articolul „cu blackjack și codecs”.
Informații interesante:
În prezent, 1154 de extensii de fișiere sunt înregistrate într-un fel sau altul conectate cu date audio!
surse:
wiki.hydrogenaudio.org/
ru.wikipedia.org/
precum și site-urile oficiale de programe.
Bună ziua.
Astăzi vreau să ating subiectul compresiei datelor fără pierderi. În ciuda faptului că deja existau articole pe hub dedicate anumitor algoritmi, am vrut să vorbesc despre asta într-un pic mai detaliat.
Voi încerca să dau atât o descriere matematică, cât și o descriere în mod obișnuit, astfel încât fiecare să găsească ceva interesant pentru ei înșiși.
În acest articol voi atinge momentele fundamentale ale compresiunii și principalele tipuri de algoritmi.
Compresie. Este nevoie în zilele noastre?
Da, desigur. Desigur, cu toții înțelegem că acum putem accesa atât suporturi de stocare de volum mare, cât și canale de transmisie de date de mare viteză. Totuși, în același timp, volumele de informații transmise cresc. Dacă acum câțiva ani am urmărit filme de 700 de megabyte care se potrivesc pe un disc, astăzi filmele de calitate HD pot ocupa zeci de gigabyte.
Desigur, avantajele comprimării a tot și a tuturor nu sunt atât. Dar mai există situații în care compresia este extrem de utilă, dacă nu este necesară.
- Documentare prin e-mail (în special volume mari de documente care utilizează dispozitive mobile)
- La publicarea documentelor pe site-uri, este necesară economisirea traficului
- Economisiți spațiu pe disc atunci când schimbați sau adăugați stocare este dificil. De exemplu, acest lucru se întâmplă în cazurile în care nu este ușor să obții un buget pentru cheltuieli de capital și nu există suficient spațiu pe disc.
Desigur, puteți veni cu multe alte situații diferite în care compresia va fi utilă, dar aceste câteva exemple sunt suficiente pentru noi.
Toate metodele de compresie pot fi împărțite în două grupuri mari: compresia fără pierderi și compresia fără pierderi. Compresia fără pierderi este utilizată în cazurile în care informația trebuie să fie restaurată exact la biți. Această abordare este singura posibilă atunci când comprimăm, de exemplu, date text.
În unele cazuri, însă, nu este necesară recuperarea corectă a informațiilor și este permisă utilizarea algoritmilor care implementează compresia cu pierderi, care, spre deosebire de compresia fără pierderi, este de obicei mai ușor de implementat și oferă un grad mai mare de arhivare.
Așadar, să trecem la algoritmi de compresie fără pierderi.
Metode de compresie universală fără pierderi
În cazul general, există trei opțiuni de bază pe care sunt construiți algoritmi de compresie.
Primul grup metode - conversie în flux. Aceasta implică o descriere a noilor date necomprimate prin intermediul procesării deja procesate. În acest caz, nu sunt calculate probabilități, codificarea caracterelor se realizează numai pe baza datelor care au fost deja procesate, cum ar fi în metodele LZ (numite după Abraham Lempel și Jacob Ziva). În acest caz, a doua și alte apariții ale unei subtringuri deja cunoscute codificatorului sunt înlocuite de referințe la prima sa apariție.
Al doilea grup metodele sunt metode de compresie statistică. La rândul lor, aceste metode sunt împărțite în adaptive (sau flux) și bloc.
În prima versiune (adaptivă), calculul probabilităților pentru noile date se bazează pe datele deja procesate în timpul codificării. Aceste metode includ versiuni adaptive ale algoritmilor Huffman și Shannon-Fano.
În cel de-al doilea caz (bloc), statisticile fiecărui bloc de date sunt calculate separat și adăugate la cel mai comprimat bloc. Acestea includ versiunile statice ale Huffman, Shannon-Fano și metodele de codificare aritmetică.
Grupa a treia metodele sunt așa-numitele metode de conversie bloc. Datele primite sunt împărțite în blocuri, care sunt apoi transformate în ansamblu. Cu toate acestea, unele metode, în special bazate pe permutarea blocurilor, pot să nu conducă la o reducere semnificativă (sau chiar vreo) a cantității de date. Cu toate acestea, după o astfel de procesare, structura de date se îmbunătățește semnificativ, iar compresia ulterioară de către alți algoritmi este mai reușită și mai rapidă.
Principii generale pe care se bazează compresia datelor
Toate metodele de compresie a datelor se bazează pe un principiu logic simplu. Dacă ne imaginăm că elementele care apar cel mai des sunt codificate cu coduri mai scurte și cele mai puțin obișnuite sunt codificate cu altele mai lungi, atunci toate datele vor avea nevoie de mai puțin spațiu pentru a stoca decât dacă toate elementele ar fi reprezentate prin coduri de aceeași lungime.
Relația exactă între frecvențele aparițiilor elementelor și lungimile optime ale codului este descrisă în așa-numita teoremă de codare a sursei Shannon, care definește limita de compresie maximă fără pierderi și entropia lui Shannon.
Un pic de matematică
Dacă probabilitatea apariției unui element s i este egală cu p (s i), atunci va fi cel mai avantajos să reprezinți acest element - log 2 p (s i) biți. Dacă în timpul codificării este posibil să se asigure că lungimea tuturor elementelor este redusă la 2 bi (s) biți log, atunci lungimea întregii secvențe codate va fi minimă pentru toate metodele de codare posibile. Mai mult, dacă distribuția probabilității tuturor elementelor F \u003d (p (s i)) este neschimbată și probabilitățile elementelor sunt independente reciproc, atunci lungimea medie a codurilor poate fi calculată ca
Această valoare se numește entropia distribuției de probabilitate F sau entropia sursei la un moment dat în timp.
Totuși, de obicei, probabilitatea apariției unui element nu poate fi independentă, dimpotrivă, depinde de unii factori. În acest caz, pentru fiecare element nou codat s i, distribuția probabilității F va lua o anumită valoare F k, adică pentru fiecare element F \u003d F k și H \u003d H k.
Cu alte cuvinte, putem spune că sursa este în starea k, ceea ce corespunde unui anumit set de probabilități p k (s i) pentru toate elementele s i.
Prin urmare, având în vedere această corecție, putem exprima lungimea medie a codurilor ca
Unde P k este probabilitatea de a găsi sursa în starea k.
Deci, în această etapă, știm că compresia se bazează pe înlocuirea elementelor care apar frecvent cu coduri scurte și invers și știm, de asemenea, cum să determinăm lungimea medie a codurilor. Dar ce este codul, codarea și cum se întâmplă?
Codificare fără memorie
Codurile fără memorie sunt cele mai simple coduri pe baza cărora datele pot fi comprimate. În codul fără memorie, fiecare caracter din vectorul de date codat este înlocuit cu un cod cod dintr-un set prefix de secvențe sau cuvinte binare.
În opinia mea, nu cea mai clară definiție. Luați în considerare acest subiect mai detaliat.
Să fie dat un anumit alfabet ![]() constând dintr-un număr (finit) de litere. Numim fiecare secvență finită de caractere din acest alfabet (A \u003d a 1, a 2, ..., a n) într-un cuvânt, iar numărul n este lungimea acestui cuvânt.
constând dintr-un număr (finit) de litere. Numim fiecare secvență finită de caractere din acest alfabet (A \u003d a 1, a 2, ..., a n) într-un cuvânt, iar numărul n este lungimea acestui cuvânt.
Să fie dat și un alt alfabet ![]() . În mod similar, notăm cuvântul din acest alfabet drept B.
. În mod similar, notăm cuvântul din acest alfabet drept B.
Mai introducem încă două notații pentru setul tuturor cuvintelor care nu sunt disprețuite în alfabet. Let - numărul de cuvinte care nu sunt goale în primul alfabet și - în al doilea.
Să se acorde și o mapare F care asociază cu fiecare cuvânt A din primul alfabet un cuvânt B \u003d F (A) din al doilea. Atunci se va numi cuvântul B cod cuvintele A și trecerea de la cuvântul inițial la codul său se va numi de codificare.
Deoarece cuvântul poate fi format dintr-o singură literă, putem identifica corespondența literelor primului alfabet și a cuvintelor corespunzătoare din a doua:
a 1<-> B 1
a 2<-> B 2
…
a n<-> B n
Acest meci se numește schemăși denotați ∑.
În acest caz, cuvintele B 1, B 2, ..., B n sunt numite coduri elementareși tipul de codificare cu ajutorul lor - codificare alfabetică. Desigur, cei mai mulți dintre noi am întâlnit acest tip de codificare, chiar dacă nu știm tot ce am descris mai sus.
Deci, am decis asupra conceptelor alfabet, cuvânt, cod, și de codificare. Acum introducem conceptul prefix.
Fie că cuvântul B are forma B \u003d B "B" ". Atunci B" se numește început, sau prefix cuvintele B, și B "" - sfârșitul ei. Aceasta este o definiție destul de simplă, dar trebuie menționat că pentru orice cuvânt B, atât un anumit cuvânt gol ʌ („spațiu”), cât și cuvântul B în sine pot fi considerate atât începuturi cât și sfârșite.
Așadar, ne apropiem de înțelegerea definiției codurilor fără memorie. Ultima definiție pe care trebuie să o înțelegem este setul de prefixe. O schemă ∑ are proprietatea unui prefix dacă, pentru oricare 1≤i, j≤r, i ≠ j, cuvântul B i nu este un prefix al cuvântului B j.
Mai simplu spus, un set de prefixuri este un set finit în care niciun element nu este prefixul (sau începutul) oricărui alt element. Un exemplu simplu de astfel de set este, de exemplu, alfabetul obișnuit.
Așadar, ne-am dat seama de definițiile de bază. Deci, cum se întâmplă codificarea fără memorie?
Apare în trei etape.
- Se compune un alfabet the al caracterelor mesajului inițial, iar caracterele alfabetului sunt sortate în ordine descrescătoare a probabilității lor de apariție în mesaj.
- Fiecare simbol a i din alfabet Ψ este asociat cu un anumit cuvânt B i din prefixul set Ω.
- Fiecare caracter este codat, urmat de combinarea codurilor într-un singur flux de date, ceea ce va fi rezultatul compresiei.
Unul dintre algoritmii canonici care ilustrează această metodă este algoritmul Huffman.
Algoritmul Huffman
Algoritmul Huffman folosește frecvența apariției acelorași octeți în blocul de date de intrare și se potrivește cu blocurile frecvente ale unui lanț de biți de lungimi mai scurte și invers. Acest cod este redundant minim. Luați în considerare cazul când, indiferent de fluxul de intrare, alfabetul fluxului de ieșire este format din doar 2 caractere - zero și unul.
În primul rând, atunci când codificăm cu algoritmul Huffman, trebuie să construim circuitul ∑. Aceasta se face după cum urmează:
- Toate literele alfabetului de intrare sunt ordonate în ordine descrescătoare a probabilității. Toate cuvintele din alfabetul fluxului de ieșire (adică ceea ce vom codifica) sunt considerate inițial goale (reamintesc că alfabetul fluxului de ieșire este format doar din caractere (0,1)).
- Două caractere j-1 și j ale fluxului de intrare, care au cea mai mică probabilitate de apariție, sunt combinate într-un „pseudo-simbol” cu probabilitate p egală cu suma probabilităților caracterelor sale constitutive. Apoi adăugăm 0 la începutul cuvântului B j-1 și 1 la începutul cuvântului B j, care vor fi ulterior codurile de caractere a j-1 și respectiv j.
- Eliminăm aceste caractere din alfabetul mesajului inițial, dar adăugăm pseudo-simbol generat acestui alfabet (în mod natural, ar trebui să fie introdus în alfabet la locul potrivit, ținând cont de probabilitatea acestuia).
Pașii 2 și 3 se repetă până când doar un pseudo-caracter rămâne în alfabet care conține toate caracterele originale ale alfabetului. Mai mult, întrucât la fiecare etapă și pentru fiecare caracter, cuvântul B i corespunzător se schimbă (adăugând unul sau zero), după finalizarea acestei proceduri, un anumit cod B i va corespunde fiecărui caracter inițial al alfabetului a i.
Pentru o ilustrare mai bună, luați în considerare un exemplu mic.
Să presupunem că avem un alfabet format din doar patru caractere - (un 1, un 2, un 3, un 4). De asemenea, presupunem că probabilitățile de apariție ale acestor simboluri sunt egale, respectiv, p 1 \u003d 0,5; p 2 \u003d 0,24; p 3 \u003d 0,15; p 4 \u003d 0.11 (suma tuturor probabilităților este, evident, egală cu una).
Deci, vom construi schema pentru acest alfabet.
- Combinați cele două caractere cu cele mai mici probabilități (0,11 și 0,15) în p "pseudo-caracterul".
- Combinăm cele două caractere cu cea mai mică probabilitate (0,24 și 0,26) în pseudo-caracterul p.
- Eliminăm caracterele combinate și introducem pseudo-caracterul rezultat în alfabet.
- În cele din urmă, combinați cele două personaje rămase și obțineți vârful arborelui.
Dacă ilustrați acest proces, primiți ceva de genul:
După cum puteți vedea, cu fiecare îmbinare, atribuim caracterele 0 și 1 caracterelor care urmează să fie îmbinate.
Astfel, când arborele este construit, putem obține cu ușurință codul pentru fiecare personaj. În cazul nostru, codurile vor arăta astfel:
a 1 \u003d 0
a 2 \u003d 11
a 3 \u003d 100
a 4 \u003d 101
Deoarece niciunul dintre aceste coduri nu este un prefix al oricărui altul (adică am primit prefixul notoriu set), putem identifica în mod unic fiecare cod din fluxul de ieșire.
Astfel, am obținut că cel mai frecvent personaj este codat de codul cel mai scurt, și invers.
Dacă presupunem că inițial, un octet a fost folosit pentru a stoca fiecare caracter, atunci putem calcula cât am putut să reducem datele.
Să presupunem că am avut un șir de 1000 de caractere la intrare, în care personajul a 1 s-a produs de 500 de ori, un 2 240, un 3 150 și un 4 110 de ori.
Inițial, acest șir ocupa 8000 de biți. După codificare, obținem un șir cu lungimea de ∑p i l i \u003d 500 * 1 + 240 * 2 + 150 * 3 + 110 * 3 \u003d 1760 biți. Astfel, am putut comprima datele de 4,54 ori, cheltuind în medie 1,76 biți pentru codificarea fiecărui simbol.
Permiteți-mi să vă reamintesc că, în conformitate cu Shannon, lungimea medie a codurilor este ![]() . Substituind valorile noastre de probabilitate în această ecuație, obținem lungimea medie a codului egală cu 1.75496602732291, ceea ce este foarte, foarte aproape de rezultatul obținut.
. Substituind valorile noastre de probabilitate în această ecuație, obținem lungimea medie a codului egală cu 1.75496602732291, ceea ce este foarte, foarte aproape de rezultatul obținut.
Cu toate acestea, trebuie avut în vedere faptul că, pe lângă datele în sine, trebuie să păstrăm tabelul de codificare, care va crește ușor dimensiunea finală a datelor codate. Evident, în diferite cazuri se pot utiliza diferite variații ale algoritmului - de exemplu, uneori este mai eficient să se utilizeze un tabel de probabilitate predefinit, iar alteori este necesar să se compileze dinamic parcurgând date comprimabile.
concluzie
Așadar, în acest articol am încercat să vorbesc despre principiile generale prin care apare compresia fără pierderi și am examinat și unul dintre algoritmii canonici - codarea Huffman.
Dacă articolul este pe gustul comunității habro, atunci voi fi fericit să scriu o continuare, deoarece există multe alte lucruri interesante în ceea ce privește compresia fără pierderi; aceștia sunt atât algoritmi clasici, cât și transformări preliminare ale datelor (de exemplu, transformarea Burroughs-Wheeler) și, bineînțeles, algoritmi specifici pentru comprimarea sunetului, videoclipurilor și imaginilor (subiectul cel mai interesant, după părerea mea).
literatură
- Vatolin D., Ratushnyak A., Smirnov M. Yukin V. Metode de compresie a datelor. Arhivarea dispozitivului, compresia de imagini și video; ISBN 5-86404-170-X; Anul 2003
- D. Salomon. Compresia datelor, imaginii și sunetului; ISBN 5-94836-027-X; 2004.
Codec-urile care comprimă sunetul fără pierderi au devenit relativ populare în lumea playerelor MP3 portabile. Cert este că aceste codec-uri nu își pot permite raporturi de compresie atât de mari de care se pot lăuda codec-urile care comprimă sunetul cu pierderea calității. Cantități mari de memorie au devenit pe larg disponibile utilizatorilor de playere MP3 doar în ultimii trei sau patru ani - și odată cu apariția unor volume mari de memorie în playere MP3, compresia muzică fără pierderi a devenit populară. Desigur, cei care doreau să asculte muzică fără pierderi de calitate au făcut întotdeauna acest lucru (de exemplu, folosind CD-playere audio), iar în prezent, toată lumea (în mod natural, cu sprijinul codec-urilor corespunzătoare de către playerele lor) poate încerca codec-uri Lossless în acțiune .
Principala diferență între codec-uri care comprimă datele audio fără pierderea calității din codec-uri care se comprimă cu pierdere este că codec-urile fără pierderea calității nu elimină informațiile din fluxul audio care poate fi considerat redundant atunci când este comprimat cu pierdere. Sarcina principală a codecului Lossless este de a comprima informațiile audio originale cât mai mult posibil, fără a pierde un singur bit de informații.
Situația cu suport pentru codecuri Lossless este în prezent astfel încât cel mai răspândit suport este codecul ALAC, care este direct legat de Apple și de jucătorii săi. Restul codec-urilor sunt în continuare susținute de puțini jucători, uneori pentru ca jucătorul să susțină codec-ul, jucătorul necesită blițul playerului și poate cel mai cunoscut firmware pentru jucătorii care acceptă codec-uri Lossless, RockBox este o firmware alternativă și nu oficială.
Când lucrați cu codecuri Lossless, puteți vedea așa-numitele fișiere Cue sau fișiere index index. Fișierele Cue sunt distribuite, de exemplu, împreună cu fișierele FLAC sau APE, mai rar cu fișierele MP3 și WAV, care sunt un fișier mare (aproximativ 300 MB) în care este stocat întregul album. Cue - fișier - conține informații despre împărțirea unui fișier mare în piese și numele acestor piese. Este mai convenabil să lucrați cu fișiere individuale, însă, chiar dacă intrați în mâinile dvs., să spunem, un fișier FLAC mare cu fișier CUE, pe baza informațiilor conținute în fișierul CUE, fișierul sursă poate fi împărțit în piese separate - vom considera software care poate rezolva această problemă.
Să începem descrierea formatelor de compresie a datelor fără pierderi cu formatul popular FLAC.
FLAC
FLAC (Free Lossless Audio Codec) este un format de compresie audio fără pierderi dezvoltat de Xiph. Fundația Org. Acesta este un format absolut gratuit pe care toată lumea îl poate folosi.
Funcționarea FLAC și a altor codecuri care stochează date audio fără pierderi seamănă cu cea a arhivelor convenționale. Cu toate acestea, datorită algoritmilor speciali, eficiența unor astfel de codecuri în comprimarea informațiilor audio este mult mai mare decât cea a arhivelor convenționale.
Formatul FLAC a fost dezvoltat sub forma unui flux - informațiile din fișierul FLAC sunt împărțite în cadre (cadre), fiecare putând fi decodat separat de alte cadre.
De obicei, FLAC este capabil să comprimeze fișierul sursă, de exemplu, calitatea CD audio cu 40-50%. Drept urmare, bitratul înregistrării rezultate este egal cu aproximativ 800 Kbit / s.
În formatul FLAC, este posibil să salvați CD-uri astfel încât să puteți recrea complet discul original dacă este necesar - acest lucru este foarte convenabil pentru cei care doresc să creeze copii digitale ale CD-urilor lor cu posibilitatea recuperării ulterioare.
Viteza de codare și decodare a fișierelor FLAC nu este aceeași. Viteza de codare depinde de nivelul de compresie și de viteza sistemului - la niveluri ridicate de compresie, poate fi destul de lent. Cu toate acestea, decodarea este foarte rapidă - playerele MP3 moderne pot face față cu ușurință.
Datorită posibilității de utilizare gratuită gratuit, puteți lucra cu FLAC pe baza oricărui sistem de operare modern, tot mai mulți playere MP3 acceptă acest format.
Codificare în format FLAC
Puteți descărca utilitarul pentru codificarea fișierelor FLAC la. Acesta include codec-ul în sine și așa-numitul Frontend - un shell software pentru codec. Dimensiunea distribuției durează aproximativ 2,5 MB. Lucrul cu codecul este simplu: adăugați fișierele care vă interesează în fereastra programului (Fig. 4.1.) Utilizând butonul Adăugați fișiere, configurați opțiunile de codare și faceți clic pe butonul Encode - programul creează un fișier FLAC.
Fig. 4.1.
Să ne uităm la cele mai semnificative setări de codec. În primul rând, să ne bazăm pe grupul de parametri Opțiuni de codificare.
Parametrul Nivel este responsabil pentru nivelul compresiei datelor. Poate varia de la 0 la 8. Cu cât nivelul de compresie este mai ridicat, corespunzător, cu atât este mai mic fișierul terminat, dar cu atât este mai lung timpul necesar pentru codificarea fișierelor. Pe computere rapide, diferența dintre nivelul 0 și nivelul 8 atunci când se codifică, să zicem, un fișier WAV de 30 de megabyte poate fi de câteva secunde. Mărimea diferă cu aproximativ 10% de dimensiunea fișierului original. Ar trebui să experimentați această opțiune pe computer - probabil dacă codificați câteva sute de fișiere, preferați un nivel de compresie mai mic decât o viteză mai mare de lucru.
Parametrul Verificare recomandă codificatorului să verifice fișierele de ieșire.
Parametrul Adăugare etichete adaugă etichete la fișierul finalizat (de exemplu, acestea pot conține numele melodiei, autorului etc.) - le puteți configura făcând clic pe butonul Tag Conf. (Personalizare tag).
Parametrul Replaygain adaugă un parametru la fișierele care indică nivelul de volum al fișierului. Dacă parametrul „Introducerea fișierelor de intrare ca un album” este setat, toate intrările din album vor suna la același volum.
Grupul de parametri Opțiuni generale conține doi parametri. Probabil, parametrul OGG-Flac ar trebui notat aici. Dacă acest parametru este resetat, atunci datele FLAC sunt ambalate într-un container FLAC standard. Dacă plănuiți doar să ascultați fișierele FLAC primite, nu puteți seta acest parametru și dacă planurile dvs. pentru aceste fișiere sunt mai extinse - de exemplu, intenționați să le editați, să le utilizați pentru a le introduce în filme, este mai bine să activați parametrul Ogg-FLAC.
Parametrul Directory Output conține calea către directorul în care vor fi conținute fișierele de ieșire.
Grupul de parametri Opțiuni de decodare are un parametru Dec. Prin erori - Setați-l dacă doriți să decodați un fișier, chiar dacă există erori în timpul decodării. Decodarea este inversul codificării - adică puteți decoda fișierele FLAC transformându-le în fișiere WAV. Pentru decodare, desigur, va trebui să adăugați fișiere FLAC în fereastra programului.
După ce totul este configurat, trebuie doar să faceți clic pe butonul Encode pentru a crea fișiere FLAC, sau dacă doriți să decodați fișierele FLAC existente, faceți clic pe butonul Decodare.
Pe lângă cele de mai sus, alte programe pot codifica FLAC. De exemplu, acest lucru este deja cunoscut pentru dvs. ImTOO Audio Encoder - pentru codificarea în formatul FLAC, selectați-l doar din lista de formate (Fig. 4.2.), După care puteți face imediat clic pe butonul Cut sau faceți-l un pic mai târziu, după configurarea numelor de fișiere.

