07.09.2019
Tipuri de codare. Codificare pentru alcoolism - tratament și consecințe. Metode eficiente de codificare pentru dependența de alcool. Consecințele codificării cauzate de alcoolism
Modulul de căutare nu este instalat.
Codificare Internet și Tipuri de fonturi
Vladimir Molochkov
Când lucrați cu internetul sau e-mailul, mulți dintre voi s-au confruntat probabil de mai multe ori cu problema alegerii unei codări pentru literele alfabetului rus. Dar ce se află în spatele unor nume precum koi-8r sau UTF-8? V-ați întrebat vreodată cum să reprezentați 33 de litere ale alfabetului rus din 26 de litere de engleză?
Procesul diviziunii celulare este un miracol uriaș. Aceasta nu este doar o separare fără cap, așa că va crea doar masă, ca și cum aluatul de pâine ar fi crescut; sau să ne uităm la forma tumorii. Această separare nu are un scop mai mare. La începutul unei noi vieți, celulele divizează, se pare, nimic nu controlează această separare și, cu toate acestea, fiecare celulă știe ce parte a corpului ar trebui să creeze, ce formă ar trebui să aibă și dacă celula este mușchi, os, sânge sau pentru a deveni un ochi sticloși. . Camerele foto știu ce direcție să partajeze și când să oprești partajarea.
NOU TERMEN
Codificarea este o tabelă de caractere, în care fiecărei litere din alfabet (precum și numere și caractere speciale) i se atribuie un număr unic - codul caracterelor.
Pentru a prezenta text pe ecranul computerului, trebuie să atribuiți un anumit număr fiecărui personaj - codul său. Toate tabelele moderne de codificare provin de la tabelul american de 7 biți al codului standard pentru schimbul de informații (ASCII) apărut în anii 60, care conține 33 de coduri de comenzi sau caractere de control, majoritatea nu sunt folosite astăzi și 95 de coduri pentru diverse caractere, suficient pentru a lucra cu texte în limba engleză. În codificarea pe 7 biți, fiecare caracter este mapat la 7 biți, adică un număr în intervalul de la 0 la 127.
Nu este evident că în întregul proces de creștere coincide exact toate părțile adiacente ale corpului. Astfel, acetabulul se adaptează întotdeauna la forma osului care se mișcă în el. Nu se întâmplă ca acetabulul să crească într-un fel sau altul într-o formă neregulată, că osul va cădea. Fiecare os interconectat individual din corp crește în raport cu oasele vecine pe parcursul dezvoltării. Acest lucru este valabil și pentru ochi, inimă, creier și alte organe. Desigur, observăm această capodoperă a perfecțiunii în toată creația.
Acest lucru nu ar fi posibil pentru procesele „aleatorii” de variabilitate, așa cum au stabilit evolucioniștii. Inima bate de aproximativ un miliard de ori în timpul vieții unei persoane. Fără oprire, fără cea mai mică pauză. Viteza cursei se adaptează la tensiune. Inima are camere și valve perfecte și toate venele sunt conectate corect. Activitatea inimii este complet independentă de conștiința noastră, este complet automată. Dacă o persoană s-ar concentra în mod conștient asupra fiecărei bătăi de inimă, acesta ar fi sfârșitul vieții pe Pământ pentru o lungă perioadă de timp.
Dezvoltarea rapidă din ultimii ani a metodelor de hipertext pentru prezentarea informațiilor pe WWW a exacerbat problema prezentării și lucrării cu informații chirilice în format electronic, care există de mai bine de un deceniu. Acest lucru se datorează, în primul rând, lipsei unui standard pentru codul ASCII extins - un tabel care include codificarea caracterelor chirilice și varietății de soluții oferite de diverse companii comerciale.
Deci, toate astea, prietenii mei, nu sunt statistic imposibile, că acest lucru s-a întâmplat din întâmplare și, desigur, nu la prima încercare. Încercăm doar să aflăm cât de abil l-a creat pe Domnul. Acesta este misterul lui Dumnezeu Însuși și putem să-L venerăm cu umilință. Evoluția nu poate răspunde la întrebarea despre ce a venit primul, un ou sau un pui. Aceasta, desigur, este problema tuturor creaturilor eclozate din ouă, adică șerpi, păsări, broaște țestoase și altele. Această problemă a evoluției pare a fi mult mai semnificativă și mai răspândită. V-ați întrebat vreodată cum a devenit primul mamifer?
Doar jumătate din tabelul ASCII este standardizat și anume primele 128 de caractere, care includ literele alfabetului latin. Și nu există niciodată o problemă cu ei. A doua jumătate a tabelului (cu un număr total de 256 de caractere - după numărul de state care poate lua un octet) este dată pentru caractere naționale, iar în fiecare țară această parte este diferită. De exemplu, în Rusia există aproximativ 10 codări diferite. Adică, un cod digital diferit corespunde aceluiași simbol, iar dacă determinăm incorect codificarea textului, atunci vom vedea text complet necitibil. Și deși această problemă există cu adevărat, de fapt nu este suficient pentru a determina tipul de codificare a textului în practică, iar multe programe, de exemplu, Stirlitz (Fig. 1), fac acest lucru în modul automat.
Unde s-a dezvoltat, sub copac? Sau undeva într-o baltă de pe podea? În corpul mamei, a apărut primul leu? Până la urmă, el a fost primul și la acea vreme nu a existat nicio mamă! Femeile care supraviețuiesc unei sarcini cu risc ridicat vă pot spune cât de fragil este acest lucru. Să te gândești la dezvoltarea fătului în afara corpului mamei este cel puțin o utopie. Știm că multe creaturi au nevoie de o mamă pentru dezvoltarea lor, așa că această problemă este foarte frecventă. Aici vedem foarte bine că principalele motoare ale evoluției, mutației și selecției naturale dobândesc fisuri mari.
Fig. 1. Fereastra principală a programului de recunoaștere a codificării „Stirlitz”
Standardul internațional ISO / IEC 8859-1 este în prezent un înlocuitor pentru ASCII. În ea, primele 32 de coduri, numerele 128-159, corespund caracterelor de control aproape neutilizate, comune tuturor tabelelor de codare ISO. Deși 8859-1 poate fi utilizat pentru texte în aproape toate limbile vest-europene, nu acoperă pe deplin nevoile francezei și finlandezei. Acest neajuns, precum și lipsa unui semn pentru noua monedă paneuropeană au dus în 1999 la apariția codului 8859-15, în care a fost utilizată o nouă versiune a valorilor codurilor 8859-1.
Un alt mit, pe care îl vom respinge imediat, este că dezvoltarea ființelor vii a atins un astfel de nivel de dezvoltare în milioane și milioane de ani. Să încercăm să ne imaginăm cum s-a dezvoltat prima persoană, puțin mai dezvoltată. Din cauza mutației, bărbatul a apărut după mai multe încercări. Totuși, acest lucru nu a conectat corect artera și nu a supraviețuit. Într-o altă încercare, mulți nu au reușit, gura i-a crescut împreună și nu avea găuri în nas, așa că se sufocă. Într-o altă mutație, a apărut un bărbat care avea totul în ordine, dar globurile oculare nu erau confecționate din material transparent, așa că nu a văzut nimic și a murit de înfometare, deoarece nu a putut găsi nicio mâncare.
În ceea ce privește alfabetul chirilic, astăzi există cinci tabele de bază pentru codificarea literelor ruse:
Pentru utilizarea cu sistemul de operare DOS, a fost elaborat un tabel de cod CP-866 (IBM / Microsoft). Codarea CP866 se bazează pe codul alternativ GOST și a fost creată special pentru OS-MS DOS, care folosește caractere pseudo-grafice. Astăzi, această codificare este la fel de nepopulară ca MS DOS.
Să spunem că următoarea s-a născut perfect, dar evoluția a uitat să o lase pe mamă să dezvolte glandele mamare, astfel încât sărmanul coleg a murit de foame. Următorul a uitat să pornească inima. În alt caz, oasele nu se potriveau și era doar o grămadă de carne și oase. Celuilalt îi lipsea întregul ficat. În corp ar exista mai multe lucruri care nu funcționează simultan și nu doar unul. Există doar denivelări în starea fizică sau în alte circumstanțe, iar persoana nu supraviețuiește.
Totul poate fi absolut perfect, dar dacă un singur lucru mic nu este în regulă, nimic din toate acestea nu va fi. Știm că oamenii de știință au încercat să traverseze diferite specii, dar în niciun caz. Vă rog să-mi explicați cum se pot dezvolta organele de reproducție dacă cea mai mică neregularitate duce automat la dispariția acestei specii, deoarece următoarea generație de urmași nu s-ar fi născut. În același timp, întregul corp ar trebui să funcționeze 100%. Sau cum se dezvoltă treptat un pește din apă branhii? Dacă nu funcționează perfect, pentru prima dată peștele se va sufoca, iar evoluția se va termina.
Pentru utilizare în mediul de operare Windows, este utilizat tabelul de cod CP-1251 (Microsoft). Codul Pagina 1251 pentru Microsoft Windows a devenit popular datorită influenței uriașe a Microsoft pe piața tehnologiei computerizate. În plus, nu are suport pentru simbolurile pseudografice în medii grafice și este mult mai complet decât în \u200b\u200balte codificări; sunt prezentate simboluri precum c, R, diverse tipuri de ghilimele, liniuțe etc. Acest tabel de cod este principalul din Rusia în prezent.
Același lucru este valabil pentru dezvoltarea inimii și, în general, pentru un număr mare de organe vitale. Deci nu este vorba de miliarde de ani, ci doar o generație sau, mai bine zis, momentul în care Dumnezeu a creat totul prin Cuvântul Său. Ați înțeles vreodată asta? În această lumină, teoria evoluției se prăbușește în praf. Este frumos să privim o ființă vie așa cum a creat Dumnezeu, dar vedem că aceste metode nu pot fi generalizate la principiul global al vieții.
Dacă în ochi, în loc de pete galbene fotosensibile, papilele gustative în locul timpanului din ureche ar fi lentila ochiului, rinichii ar fi complet absenți, iar în locul vezicii urinare. Cum știe evoluția oarbă să ajute? Așa cum am arătat deja, toate corpurile ar fi trebuit să fie coordonate în același timp. Iată o dovadă clară că în spatele tuturor acestor lucruri există un Creator rațional - Dumnezeu. Care este probabilitatea ca evoluția oarbă să creeze un organism atât de perfect prin încercări și erori aleatorii?
Codepage 10007 - Folosit pe computere Macintosh și cu un caracter aproape identic setat cu CP1251.
Într-un mediu UNIX, cel mai comun tabel de cod KOI8-R. Aceasta este una dintre codificările standard ale limbii ruse, adoptată în Uniunea Sovietică în zorii dezvoltării tehnologiei computerizate. KOI înseamnă „cod de schimb de informații”. Numărul 8 indică faptul că acest cod este pe 8 biți (spre deosebire de KOI-7, care a fost utilizat pe scară largă pe computere sovietice). În prezent, koi8-r este una dintre principalele codificări în limba rusă în sistemele de operare Linux. Aceasta este a doua cea mai populară codificare după CP-1251 (câștig). Codificarea acceptă caractere pseudografice, ocupând aproximativ jumătate din toate codurile. În 1993, tabela koi8-r a fost standardizată pe Internet (Fig. 2).
Acest lucru nu este posibil pentru caz. O altă dovadă a așa-numitului evoluționist este cunoscutul experiment Miller-Urey, când în anumite condiții, sarcinile electrice au creat diferite aminoacizi din apă, metan, amoniac și hidrogen. Cu toate acestea, acizii nucleici nu au fost generați. Cu toate acestea, s-a constatat că în stadiile incipiente ale Pământului aveau o compoziție complet diferită a atmosferei, iar acest experiment a dat rezultate complet diferite cu această compoziție. Inutil să spun, o astfel de atmosferă va ucide orice ființă vie.
Desigur, nu există creații fără Creatorul. Există și cei care spun că viața pe Pământ este extraterestră. Desigur, aceasta nu este o soluție, problema este pur și simplu mutată într-un alt loc. Știm că mulți încearcă să găsească viață extraterestră în univers. Acest efort este înrădăcinat și în probabilitatea matematică ca, într-un număr atât de mare de stele, să existe condiții statistice undeva. Acum vedem că nu este vorba despre condițiile adecvate, ci despre decizia Creatorului. De asemenea, se știe că aceasta ar fi o pierdere de spațiu dacă am fi singurii din întregul univers.
Standardul internațional ISO definește tabelul de cod ISO 8859-5 pentru Rusia. Pseudografia lipsește. În acest moment, această codificare nu este practic utilizată. Cu toate acestea, suportul său este prezent în toate browserele.

Fig. 2. Un set de caractere pentru reprezentarea limbii ruse în codificarea KOI8-R
Cât de mult va dispărea din spațiul infinit dacă vom separa cea mai mare parte a acestuia, ca universul nostru? Infinitatea rămâne infinită. Dumnezeu nu se limitează la spațiul nostru de timp, iar ceea ce ni se pare gigantic este un semn al lui Dumnezeu. Știți zicala: „O frunză nu se poate mișca fără vânt”? Știți că aceasta este practic o lege științifică fundamentală - principiul cauzalității, care determină că fiecare fenomen trebuie să aibă o cauză? Știința, bazată pe această lege, trebuie, prin urmare, să se ocupe de răspunsul la întrebarea care a fost motivul principal.
Ce a provocat Big Bang-ul sau ce știință consideră nașterea universului? Conform acestei legi, acest fenomen trebuia să provoace ceva. Se pare că cercul vicios și știința au scăpat neputincios de această problemă, punând-o în filosofie. Biblia oferă, de asemenea, un răspuns la această întrebare în primul capitol al Evangheliei lui Ioan și la începutul Genezei. La început a fost Cuvântul, iar Cuvântul a fost cu Dumnezeu, iar Dumnezeu a fost Cuvântul. La fel a fost la început cu Dumnezeu. Totul se face unul și același lucru și fără el nu se face nimic, ce se face.
NOTĂ
Pentru codificarea alfabetului chirilic, pot fi folosite încă cinci tabele, care acum sunt arhaice și care nu au statut internațional: Codificarea principală este GOST (Standardul de Stat URSS) din 1987. Dezavantajul său principal este că caracterele pseudo-grafice nu sunt localizate în același mod ca pe computerul IBM. Codificarea alternativă GOST (diferă de CP866 în pozițiile 242-251). Codare bulgară (obținută prin introducerea mecanică a unui bloc de 64 de litere din alfabetul rus în pozițiile 128-191 CP437). KOI-8 (pe computerul IBM nu este răspândit din cauza aranjamentului non alfabetic al literelor alfabetului chirilic).
În el era viață și viața este lumina oamenilor. Prima lege termodinamică afirmă că energia într-un sistem închis este constantă. Aceasta înseamnă că energia nu poate fi generată sau distrusă. Aceasta vorbește despre legea fizică. Deci, unde este toată energia din univers? Unii spun că a venit după Big Bang. Dar legea spune că energia nu poate fi generată! Deci, ce a explodat și de unde a provenit atâta energie? Este, de asemenea, o dovadă științifică a existenței lui Dumnezeu. Doar atotputernicul Dumnezeu, care nu are început sau sfârșit, poate produce așa ceva.
Pentru a codifica caractere în unele limbi, cum ar fi chineza sau japoneza, numerele pe 8 biți nu sunt suficiente. În plus, crearea de tabele de codare pe 8 biți la un moment dat a devenit aproape incontrolabilă: fiecare nou tip de computer a introdus propriul tabel. Acesta este motivul pentru care a fost creat consorțiul Unicode: obiectivul său a fost să dezvolte un sistem de codificare unificat pentru toate caracterele posibile, ceea ce ne-a permis să alocăm coduri caracterelor fontului computerului într-un model specific.
Cuvintele lui sunt suficiente și totul se întâmplă. Esența științei este investigarea și stabilirea legilor fenomenelor și proceselor din jurul nostru care pot fi dovedite și calculate. Ar fi nerezonabil să spunem că ceea ce nu putem dovedi experimental nu există. Și acesta este un obstacol pentru oameni. Pentru că abia acum ne deschidem și începem să ne dăm seama, pentru că Dumnezeu a gândit cu adevărat și a făcut totul. Știința va ajunge la un obstacol dacă nu recunoaștem că Dumnezeu există cu adevărat și că El este Creatorul a tot.
Pare neștiințific și slab dacă știința recunoaște că Dumnezeu este în spatele tuturor acestor lucruri, dar aceasta este singura cale. O persoană se ține uneori în mândria sa pentru stăpânul întregii creații și pentru culmea înțelepciunii. Inventăm multe teorii ciudate și susținem că sunt adevărate și știm cât de vulnerabili suntem față. Teoriile universului, particule ale nivelului atomic și multe alte teorii promițătoare, care au fost în cele din urmă excluse, sunt foarte vizibile. Omul, vârful inteligenței și al creației. Să vedem doar ce fel de persoană a inventat și a crezut că va fi perfectă și eficientă.
Codificarea Unicode se bazează pe catalogul UCS (Universal Character Set) din standardele ISO 10646 și poate conține până la 231 \u003d 2147483648 caractere diferite, precum și reumplere. Codurile UCS-2 sunt cu doi octeți, adică numerele de la 0 la 65535, iar UCS-4 sunt cu patru octeți, adică numerele de la 0 la 2147483647. Codurile Unicode cu doi și patru octeți pot fi reprezentate în două moduri: octeții sunt aranjați de la stânga la dreapta de la cel mai vechi la cel mai mic ( Big Endian, BE) sau de la junior la senior (Little Endian, LE). A doua metodă se regăsește în marea majoritate a cazurilor. În plus, pentru codificarea mai compactă, se utilizează coduri de lungime variabilă UTF-8 (Unicode Transfer Format) 1-6 octeți și UTF-16 - doi sau patru octeți. Acestea din urmă există și în două forme (Little and Big Endian) și permit codificarea nu mai mult de 220 + 216 \u003d 1114112 caractere.
Capodopere ale geniului uman și, totuși, sunt încercări nereușite care nu pot zbura și au fost copiate de natură. Nu vă fie teamă să admiteți că există cineva care este mai mare decât noi. Acesta nu este un semn de slăbiciune, ci de maturitate. Fiecare persoană ar trebui să fie în măsură să recunoască care este rezultatul întâmplării și al muncii Creatorului. Întregul univers și, prin urmare, tot ceea ce privim doar pe Pământ este crearea Creatorului, dar în materia fără vigoare acționează doar legile fizice, prin urmare acest lucru nu este atât de vizibil și este considerat aleatoriu. Apropo, toate legile, constantele fizice, sunt bine ajustate și chiar Einstein însuși credea că ar trebui să existe un creator în spatele lui.
Printre codificările menționate, cea mai utilizată codificare este UTF-8, care vă permite să ocoliți 8 biți pentru codificarea caracterelor ASCII și 16 biți pentru codificarea caracterelor în majoritatea scripturilor alfabetice, inclusiv în limba rusă. Textele în ASCII, în special în engleză, sunt simultan texte în UTF-8. Codul UTF-8, o secvență de octeți, este obținut din codul director UCS conform unei scheme specifice. De exemplu, un caracter Unicode cu codul 169 \u003d a916 \u003d 1010 1001 (caracterul c) este codat în UTF-8 ca 11000010 10101001 \u003d c216 a916.
Teoria evoluției ne-a păcălit atât de mult, încât decizia aparent clară nu mai este atât de clară datorită recenziilor repetate ale evoluționistilor pe care le auzim din toate părțile. Minciunile repetate de 100 de ori devin adevărate. Luați omul și multe alte creaturi care au un corp simetric. Și știm că aceasta nu este o simetrie strictă, deoarece dispunerea internă a organelor nu este simetrică. Care este probabilitatea ca coincidența să poată crea o astfel de simetrie? În plus, bărbatul și femeia sunt atractive și frumoase unul pentru celălalt.
Și acest lucru se aplică întregii creații. Feromonii feminini sunt foarte atractivi pentru speciile masculine. Cerbul nu este atras sexual de un mistreț, ci de o femeie atrăgătoare și îl vizitează când este timpul potrivit. Iar această împerechere funcționează de toată natura. Mulți au chiar un smartphone. Acesta este un dispozitiv complex cu un procesor, memorie, baterie pentru încărcare, o cameră cu mai mulți megapixeli, un microfon, difuzoare etc. Poate efectua calcule, stoca fotografii și videoclipuri și poate comunica. Pe scurt, un dispozitiv foarte complex.
Unicode este complet acceptat de programe moderne - browsere, apartamente de birou, etc. Linux folosește UTF-8, iar Microsoft Windows folosește și UCS-2. Până în prezent, suportul UCS pe Linux este puțin mai slab decât pe Windows 2000 / Me / XP. Problemele principale atunci când utilizați Unicode sunt lipsa unui set complet de fonturi adecvate și complexitatea intrării.
(Aici aș dori să pun cititorul atent întrebarea: „În ce codare a apărut simbolul EURO pentru prima dată?”)
Pe armonia fonturilor de browser și site
Există mai multe probleme cu utilizarea fonturilor pe paginile web. Primul dintre ele este armonia codificărilor pe site-uri și browsere. Site-urile cu browsere ale diferitor utilizatori ar trebui să comunice în aceeași codare, adică Browserul trebuie să „înțeleagă” ce îi trimite site-ul. Pentru a face acest lucru, trebuie să instalați un sistem pe site care să poată trimite un mesaj despre codificarea paginii care va fi trimisă utilizatorului. Browserul său trebuie să accepte acest mesaj și să tuneze pentru a afișa site-ul corect. În acest caz, puteți specifica codificarea paginii site-ului direct în codul HTML. Pentru a face acest lucru, utilizați o versiune specială a etichetei META cu parametrul de caractere care stabilește limba dorită. De exemplu, pentru o pagină scrisă în codificarea Win1251, codul corespunzător ar arăta astfel:
Cu toate acestea, o metodă este foarte răspândită în Rusia, în care serverul web stabilește automat ce codificare a solicitării vine de la client și dă pagina browserului web deja transcodat. Această etichetă META poate juca o glumă proastă aici. Cert este că instrucțiunile de pe pagină au prioritate asupra comenzilor trimise de serverul web și, după ce a codificat corect pagina, serverul nu poate însă modifica conținutul etichetei META. Există o neconcordanță între codificarea reală în care a venit codificarea și instrucțiunile din eticheta META. O astfel de pagină nu poate fi vizualizată și transcodificată în mod normal folosind browserul. Selectarea manuală a codificării în acest caz nu va ajuta, deoarece Eticheta META are prioritate față de setările browserului. Singura modalitate de a face acest lucru este să salvați pagina pe disc, apoi să ștergeți eticheta.
În acest sens, în RUNET nu este recomandat să utilizați deloc această etichetă. În acest caz, vizualizarea va fi efectuată în codificarea la care este configurat browserul, în cazul în care serverul nu trimite o notificare despre codificarea documentului. În caz de nepotrivire, acesta poate fi comutat destul de ușor. În plus, dacă codificarea implicită este Win-1251, atunci pentru majoritatea utilizatorilor, pagina va fi afișată imediat.
O măsură a lizibilității este lățimea liniei unui document. Odată cu apariția monitoarelor care acceptă rezoluții de ecran mari, a devenit posibilă „stivuirea” până la câteva sute de caractere într-o singură linie, dar linia „lățimii ideale” ar trebui să se potrivească cu aproximativ 50-70 de caractere. Cu mai multe dintre ele, viteza de citire încetinește, iar oboseala apare mult mai repede.
A doua problemă de codare ar putea fi foile de stil în cascadă (CSS). Se știe că dimensiunea exactă a fontului și celelalte atribute ale acestuia pot fi setate folosind foi de stil în cascadă (vor fi discutate în capitolul 8). Când folosim CSS, putem folosi absolut orice font. Problema este însă că fonturile sunt preluate din setul instalat pe computerul utilizatorului, și nu de pe site. Adică seturile de fonturi de pe site și setul de fonturi al utilizatorului s-ar putea să nu se potrivească.
Când vizualizați site-uri, utilizați implicit fontul instalat în browser. Pentru a schimba fontul implicit din Internet Explorer (de exemplu, Times New Roman) în altul, de exemplu, la Arial, executați comanda Service4 Internet Options 4 Fonturi.
A treia problemă posibilă este atunci când fontul de pe site și de pe computerul utilizatorului este identic, dar într-un caz este chirilic, iar în cel de-al doilea este latin (versiunea non-rusă a fontului). În acest caz, textul va fi afișat cu câteva caractere speciale și citirea acestor caractere va fi problematică.
Pentru a evita astfel de probleme atunci când utilizați fonturi în designul web, trebuie să respectați o serie de reguli:
Este mai bine să utilizați doar fonturi standard care vin cu Windows și sunt garantate să fie pe mașina clientului. Există trei astfel de fonturi: „Arial”, „Times New Roman”, „Curier”.
Este necesară descrierea corectă a fonturilor din fișa de stil (CSS) cu o listare în lista altor fonturi care o înlocuiesc pe cea principală (fonturi pentru înlocuire). La sfârșitul listei ar trebui să fie o indicație obligatorie a familiei generale de fonturi (cu serife, fără serife, monospațiate etc.).
De exemplu:
Ca o opțiune pentru a ieși din situație, prezentați fontul cu grafică, de exemplu, în format GIF. Atât browserul, cât și sistemul de operare nu le pasă ce este desenat - afișarea fontului ca fișier grafic pe ecranele tuturor utilizatorilor va fi identică (dar o altă problemă apare aici - grafica este mare).
Din cele de mai sus, rezultă că tehnologiile de Internet impun restricții specifice privind utilizarea fonturilor în proiectarea documentelor web și că fonturile non-standard în designul web ar trebui să fie tratate cu atenție. Din păcate, în prezent, nu există un mijloc suficient de dezvoltat și de încredere pentru specificarea unei anumite căști atunci când se prezintă informații sub formă de text pe o pagină web.
|
Pentru ca alarma auto achiziționată să devină o protecție fiabilă, trebuie să o alegeți corect. Unul dintre principalii parametri care afectează performanța unei alarme este o metodă de codificare a semnalului. În acest articol vom încerca să explicăm într-un mod accesibil ce înseamnă codarea dinamică a semnalelor și ce înseamnă codul de dialog în alarmele auto, ce tip de codare este mai bun, care are fiecare laturile sale pozitive și negative.
Codificare dinamică în alarmele auto
Confruntarea dintre dezvoltatorii de alarme și hoții de mașini a început de la crearea primelor alarme auto. Odată cu apariția unor sisteme de securitate noi și mai avansate, au fost îmbunătățite mijloacele de hacking. Primele alarme au avut un cod static, care a fost ușor fisurat prin metoda de selecție. Răspunsul dezvoltatorilor a fost să blocheze posibilitatea selectării codului. Următorul pas al crackers-urilor a fost crearea de dispozitive de prindere - dispozitive care scanau semnalul de la fob-ul cheie și îl reproduceau. În acest fel, au duplicat comenzile din fob-ul cheii proprietarului, îndepărtând mașina de protecție la momentul potrivit. Pentru a proteja alarmele de la mașini de la apăsarea unui apucator, au început să utilizeze codarea dinamică a semnalului.
Principiul codării dinamice
 Codul dinamic al alarmelor auto este un pachet de date în schimbare continuă transmis de la fob-ul cheii la unitatea de alarmă prin canalul radio. Cu fiecare nouă comandă, se trimite un cod de la fob-ul cheii care nu a fost folosit anterior. Acest cod este calculat în funcție de un algoritm specific stabilit de producător. Cel mai comun și de încredere algoritm este Keelog.
Codul dinamic al alarmelor auto este un pachet de date în schimbare continuă transmis de la fob-ul cheii la unitatea de alarmă prin canalul radio. Cu fiecare nouă comandă, se trimite un cod de la fob-ul cheii care nu a fost folosit anterior. Acest cod este calculat în funcție de un algoritm specific stabilit de producător. Cel mai comun și de încredere algoritm este Keelog.
Alarma funcționează după principiul următor. Când proprietarul mașinii apasă butonul fob pentru cheie, este generat un semnal. Acesta conține informații despre numărul de clicuri (această valoare este necesară pentru a sincroniza funcționarea butonului de chei și a unității de control), numărul de serie al dispozitivului și codul secret. Înainte de a trimite, aceste date sunt criptate anterior. Însuși algoritmul de criptare este disponibil în mod liber, dar pentru a decripta datele, trebuie să cunoașteți codul secret, care este stocat în unitatea de control cheie din fabrică.
Există, de asemenea, algoritmi originali dezvoltați de producătorii de alarme. O astfel de codificare a eliminat practic posibilitatea selectării unui cod de comandă, însă, în timp, atacatorii au ocolit această protecție.
Ce trebuie să știți despre piratarea codului dinamic
 Ca răspuns la introducerea codării dinamice în alarme auto, a fost creat un grabber dinamic. Principiul funcționării sale este interferirea și interceptarea semnalului. Când proprietarul autovehiculului părăsește mașina și apasă butonul fob al tastei, se creează o interferență radio puternică. Semnalul cu codul nu ajunge la unitatea de control al alarmelor, dar este interceptat și copiat de grabber. Șoferul surprins apasă din nou butonul, dar procesul se repetă, iar al doilea cod este de asemenea interceptat. A doua oară când mașina este pusă pe defensivă, dar comanda vine de la dispozitivul hoțului. Când proprietarul mașinii pleacă calm de afacerea sa, deturnatorul trimite un al doilea cod, anterior interceptat și îndepărtează mașina de protecție.
Ca răspuns la introducerea codării dinamice în alarme auto, a fost creat un grabber dinamic. Principiul funcționării sale este interferirea și interceptarea semnalului. Când proprietarul autovehiculului părăsește mașina și apasă butonul fob al tastei, se creează o interferență radio puternică. Semnalul cu codul nu ajunge la unitatea de control al alarmelor, dar este interceptat și copiat de grabber. Șoferul surprins apasă din nou butonul, dar procesul se repetă, iar al doilea cod este de asemenea interceptat. A doua oară când mașina este pusă pe defensivă, dar comanda vine de la dispozitivul hoțului. Când proprietarul mașinii pleacă calm de afacerea sa, deturnatorul trimite un al doilea cod, anterior interceptat și îndepărtează mașina de protecție.
Ce protecție este folosită pentru codul dinamic
 Producătorii de alarme auto au rezolvat problema hackingului pur și simplu. Au început să instaleze două butoane pe păpuși, dintre care unul a pus mașina pe protecție, iar al doilea - a dezactivat protecția. În consecință, au fost trimise coduri diferite pentru a seta și elimina protecția. Prin urmare, indiferent de cât de multă interferență este pus de hoț atunci când configurează mașina pentru protecție, el nu va primi niciodată codul necesar pentru a dezactiva alarma.
Producătorii de alarme auto au rezolvat problema hackingului pur și simplu. Au început să instaleze două butoane pe păpuși, dintre care unul a pus mașina pe protecție, iar al doilea - a dezactivat protecția. În consecință, au fost trimise coduri diferite pentru a seta și elimina protecția. Prin urmare, indiferent de cât de multă interferență este pus de hoț atunci când configurează mașina pentru protecție, el nu va primi niciodată codul necesar pentru a dezactiva alarma.
Dacă ați făcut clic pe butonul „set to protect” și mașina nu a răspuns, atunci este posibil să fi devenit ținta pirateriei. În acest caz, nu este necesar să apăsați fără gânduri toate butoanele fob-ului cheii, pentru a încerca cumva să remediați situația. Este suficient să apăsați din nou butonul de protecție. Dacă faceți clic accidental pe butonul „scoateți din protecție”, hoțul va primi codul de care are nevoie, pe care îl va folosi în curând și vă va fura mașina.
Alarmele cu codare dinamică sunt deja oarecum învechite, nu oferă o protecție de sută la sută a mașinii împotriva furtului. Au fost înlocuite de dispozitive cu codare interactivă. Dacă sunteți proprietarul unei mașini ieftine, atunci nu trebuie să vă faceți griji, întrucât este foarte puțin probabil ca un hoț echipat cu cele mai moderne echipamente să intre în proprietatea dumneavoastră. Pentru a vă proteja proprietatea, utilizați protecție pe mai multe niveluri. Instalați opțional. Acesta va oferi protecție pentru mașină în caz de hacking alarme auto.
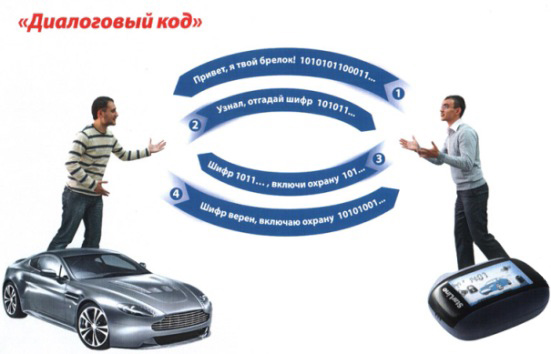
Codarea dialogului în astrosignale
 După apariția apucătorilor dinamici, alarmele auto care rulează pe cod dinamic au devenit foarte vulnerabile la atacatori. De asemenea, un număr mare de algoritmi de codare au fost hacked. Pentru a proteja vehiculul împotriva piratării de către astfel de dispozitive, dezvoltatorii de alarmă au început să utilizeze codarea semnalului de dialog.
După apariția apucătorilor dinamici, alarmele auto care rulează pe cod dinamic au devenit foarte vulnerabile la atacatori. De asemenea, un număr mare de algoritmi de codare au fost hacked. Pentru a proteja vehiculul împotriva piratării de către astfel de dispozitive, dezvoltatorii de alarmă au început să utilizeze codarea semnalului de dialog.
Principiul codificării dialogului
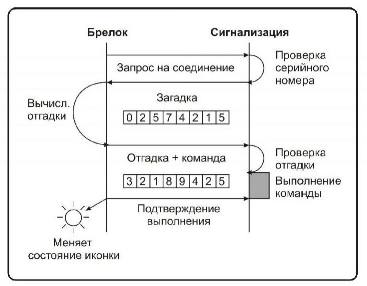 După cum sugerează și numele, acest tip de criptare se realizează într-un mod de dialog între fob-ul cheii și unitatea de control al alarmelor auto situată în mașină. Când apăsați butonul, o fereastră de cheie este trimisă pentru a executa comanda. Pentru ca unitatea de control să se asigure că comanda a provenit din fob-ul cheie al proprietarului, trimite un semnal de număr aleatoriu către fob-ul cheii. Acest număr este procesat conform unui algoritm specific și trimis înapoi la unitatea de control. În acest moment, unitatea de control procesează același număr și își compară rezultatul cu rezultatul trimis de fob-ul cheii. Dacă valorile se potrivesc, unitatea de control execută comanda.
După cum sugerează și numele, acest tip de criptare se realizează într-un mod de dialog între fob-ul cheii și unitatea de control al alarmelor auto situată în mașină. Când apăsați butonul, o fereastră de cheie este trimisă pentru a executa comanda. Pentru ca unitatea de control să se asigure că comanda a provenit din fob-ul cheie al proprietarului, trimite un semnal de număr aleatoriu către fob-ul cheii. Acest număr este procesat conform unui algoritm specific și trimis înapoi la unitatea de control. În acest moment, unitatea de control procesează același număr și își compară rezultatul cu rezultatul trimis de fob-ul cheii. Dacă valorile se potrivesc, unitatea de control execută comanda.
Algoritmul prin care se efectuează calculele pe fob-ul cheii și unitatea de control este individual pentru fiecare alarmă auto și stabilit în ea la o altă fabrică. Să înțelegem cel mai simplu algoritm:
X ∙ T 3 - X ∙ S 2 + X ∙ U - H \u003d Y
T, S, U și H sunt numere încorporate în alarmă din fabrică.
X este un număr aleatoriu care este trimis de la unitatea de control către fob-ul cheii pentru verificare.
Y este numărul calculat de unitatea de control și fob-ul cheii conform unui algoritm dat.
Să ne uităm la situația în care proprietarul alarmei a apăsat un buton și a fost trimisă o cerere de la fob-ul cheii către unitatea de control pentru a dezarma mașina. Ca răspuns, unitatea de control a generat un număr aleatoriu (de exemplu, luați numărul 846) și l-au trimis la breloc. După aceea, unitatea de control și brelocul efectuează calculul numărului 846 în funcție de algoritm (de exemplu, calculăm în funcție de cel mai simplu algoritm dat mai sus).
Pentru calcule, luăm:
T \u003d 29, S \u003d 43, U \u003d 91, H \u003d 38.
Vom reuși:
846∙24389 - 846∙1849 + 846∙91- 38 = 19145788
Butonul-cheie va trimite numărul (19145788) unității de control. În același timp, unitatea de control va efectua același calcul. Numerele se vor potrivi, unitatea de control va confirma comanda tastei, iar aparatul se va dezarma.
 Chiar și pentru a decripta algoritmul elementar descris mai sus, va fi necesară interceptarea pachetelor de date de patru ori (în cazul nostru, patru necunoscute în ecuație).
Chiar și pentru a decripta algoritmul elementar descris mai sus, va fi necesară interceptarea pachetelor de date de patru ori (în cazul nostru, patru necunoscute în ecuație).
Este aproape imposibil să interceptați și să decriptați un pachet de date cu alarme auto. Pentru codificarea unui semnal, se folosesc așa-numitele funcții hash - algoritmi care convertesc șiruri de lungime arbitrară. Rezultatul acestei criptare poate conține până la 32 de litere și numere.
Mai jos sunt rezultatele criptării numerelor folosind cel mai popular algoritm de criptare MD5. De exemplu, numărul 846 și modificările acestuia au fost luate.
MD5 (846) \u003d;
MD5 (841) \u003d;
MD5 (146) \u003d.
După cum puteți vedea, rezultatele codificării numerelor care diferă doar într-o cifră sunt complet diferite între ele.
Algoritmi similari sunt folosiți în alarmele moderne de mașini interactive. Este dovedit că pentru decodarea inversă și obținerea unui algoritm, calculatoarele moderne vor avea nevoie de mai mult de un secol. Și fără acest algoritm, va fi imposibil să se genereze coduri de verificare pentru a confirma comanda. Prin urmare, acum și în viitorul apropiat, hackingul codului de dialog este imposibil.
Alarmele care funcționează pe codul de dialog sunt mai sigure, nu sunt sensibile la hackingul electronic, dar acest lucru nu înseamnă că mașina dvs. va fi complet în siguranță. Puteți pierde din greșeală brelocul sau vă va fi furat. Pentru a crește nivelul de protecție, este necesar să utilizați mijloace suplimentare, cum ar fi și.

