17.07.2019
Decriptarea codului ascii. Codificare ASCII
Material pentru studiu independent pe tema Prelegerile 2
Tabel de cod ASCII (ASCII - Codul standard american pentru schimbul de informații).
În total, folosind tabelul de codare ASCII (Figura 1), pot fi codificate 256 de caractere diferite. Acest tabel este împărțit în două părți: principalul (cu coduri de la OOh la 7Fh) și suplimentar (de la 80h la FFh, unde litera h indică codul aparține sistemului de numere hexadecimale).
Figura 1
Pentru a codifica un caracter din tabel, sunt alocați 8 biți (1 octet). La procesare informații textuale un octet poate conține codul unor caractere - litere, numere, semne de punctuație, semne de acțiune etc. Fiecare personaj are propriul său cod sub forma unui număr întreg. În acest caz, toate codurile sunt colectate în tabele speciale numite codificare. Cu ajutorul lor, codul simbolului este convertit în reprezentarea sa vizibilă pe ecranul monitorului. Ca urmare, orice text din memoria computerului este reprezentat ca o secvență de octeți cu coduri de caractere.
De exemplu, cuvântul salut! va fi codat după cum urmează (tabelul 1).
Tabelul 1
Figura 1 prezintă caracterele incluse în codificarea ASCII standard (engleză) și avansată (rusă).
Prima jumătate a tabelului ASCII este standardizată. Conține coduri de control (între 00h și 20h și 77h). Aceste coduri sunt eliminate din tabel deoarece nu se aplică elementelor de text. Punctuația și semnele matematice sunt de asemenea plasate aici: 2lh -!, 26h - &, 28h - (, 2Bh - +, ..., litere mari și minuscule: litere latine: 41h - A, 61h - a.
A doua jumătate a tabelului conține fonturi naționale, simboluri pseudografice, din care pot fi construite tabele, caractere matematice speciale. Partea inferioară a tabelului de codificare poate fi înlocuită folosind driverele corespunzătoare - programe auxiliare de control. Această tehnică vă permite să utilizați mai multe fonturi și căști.
Afișajul pentru fiecare cod simbol ar trebui să afișeze imaginea simbolului - nu doar un cod digital, ci imaginea corespunzătoare, deoarece fiecare simbol are propria sa formă. Descrierea formei fiecărui simbol este stocată într-o memorie de afișare specială - generator de caractere. Un simbol este afișat pe un ecran de afișare a computerului IBM, de exemplu, prin intermediul unor puncte care formează o matrice de simboluri. Fiecare pixel dintr-o astfel de matrice este un element de imagine și poate fi luminos sau întunecat. Punctul întunecat este codat cu numărul 0, luminos (luminos) - 1. Dacă afișați pixelii întunecați ca un punct în câmpul matricial al personajului și pixelii de lumină cu un asterisc, puteți descrie grafic forma.
Oamenii din diferite țări folosesc caractere pentru a scrie cuvintele din limbile lor native. În zilele noastre, majoritatea aplicațiilor, inclusiv sistemele de e-mail și browserele web, sunt pur pe 8 biți, adică pot afișa și accepta doar caractere pe 8 biți, conform standardului ISO-8859-1.
Există mai mult de 256 de caractere în lume (luând în considerare limbile chirilice, arabe, chineze, japoneze, coreene și thailandeze) și, de asemenea, apar tot mai multe caractere noi. Și acest lucru creează următoarele spații pentru mulți utilizatori:
Nu este posibil să folosiți caractere din seturi de caractere diferite în același document. Deoarece fiecare document text folosește propriul set de codificări, există mari dificultăți în ceea ce privește recunoașterea automată a textului.
Apar noi caractere (de exemplu: Euro), în urma cărora ISO dezvoltă un nou standard ISO-8859-15, care este foarte similar cu standardul ISO-8859-1. Diferența este următoarea: din tabelul de codare al vechiului standard ISO-8859-1, simbolurile desemnării monedelor vechi care nu sunt utilizate în prezent au fost eliminate pentru a face loc simbolurilor nou apărute (precum Euro). Drept urmare, utilizatorii pot avea aceleași documente pe discuri, dar în codificări diferite. Soluția acestor probleme este adoptarea unui singur set internațional de codificări numit codare universală sau unicod.
În timpul formării ASCII, caracterele de control inerente teletipurilor și mașinilor de scris au fost incluse la începutul codificării, iar în timp au murit strâns acolo, deși practic nu sunt folosite în secolul XXI.
Ofer informații detaliate despre codificarea ASCII:
ASCII (Eng. American standard code pentru eunformații eunterchange, [ˈæs.ki]) - numele tabelului (codare, set) în care codurile numerice sunt asociate cu unele caractere comune tipărite și neimprimate. Tabelul a fost dezvoltat și standardizat în SUA în 1963. Numele "ASCII" în rusă este adesea pronunțat ca [ întrebați (i) și].
Tabelul ASCII definește codurile pentru caractere:
- cifre zecimale;
- alfabet latin;
- alfabetul național;
- semne de punctuație;
- personaje de control.
Povestea
Inițial (1963), ASCII a fost dezvoltat pentru a codifica caractere ale căror coduri au fost plasate în 7 biți (128 caractere; 27 \u003d 128), în timp ce cel mai semnificativ 7 bit (numerotare de la zero) a fost utilizat pentru a controla erorile apărute în timpul transferului de date.
În timp, codificarea a fost extinsă la 256 de caractere (28 \u003d 256); codurile primelor 128 de caractere nu s-au schimbat. ASCII a început să fie perceput ca jumătate din codificarea pe 8 biți, iar „ASCII extins” a fost numit ASCII cu 8 bit implicat (de exemplu, KOI-8).
Suprapunerea personajelor
Folosind caracterul Backspace (BS) (returnând un caracter), puteți imprima un personaj în partea de sus a imprimantei. În ASCII, puteți adăuga diacritice literelor în același mod, de exemplu:
- a BS '→ á
- a BS `→ à
- a BS ^ → â
- o BS / → ø
- c BS, → ç
- n BS ~ → ñ
remarcă: în fonturile vechi, apostroful „» ”a fost desenat cu o pantă spre stânga (comparați„ `” și „´”), iar tilde „~” au fost mutate în sus (comparați „~” și „˜”), astfel încât acestea se potrivesc doar rolului personajele sunt „´” și „tilde pe partea de sus”.
Dacă imprimați același personaj de două ori în aceeași poziție, obțineți un personaj îndrăzneț. Dacă imprimați un caracter într-o poziție și subliniați „_”, va fi obținut un caracter subliniat.
- a BS a → o
- a BS _ → a
Această tehnică este încă folosită, de exemplu, în sistemul de ajutor la om.
Opțiuni naționale ASCII
Standardul ISO 646 (ECMA-6) permite plasarea caracterelor naționale în ASCII. Pentru aceasta, se propune înlocuirea caracterelor "@", "[", "\\", "]", "^", "` "," ("," Bara verticală ",") "," ~ ". De asemenea, simbolul lirei „£” poate fi plasat în locul semnului lirei „#”, iar semnul monedei „¤” poate fi plasat în locul simbolului dolar „$”. Un astfel de sistem este potrivit pentru limbile europene, deoarece folosesc caractere latine și doar câteva caractere suplimentare. O variantă ASCII care nu conține caractere naționale se numește „US-ASCII” sau „versiune de referință internațională”.
Pentru unele limbi cu scripturi non-latine (rusă, greacă, arabă, ebraică) au existat modificări mai radicale ale ASCII. În una dintre aceste modificări, în locul literelor latine minuscule, au fost plasate simboluri naționale (pentru litere majuscule rusești și grecești). O altă modificare a inclus trecerea între US-ASCII și versiunea națională; comutarea a fost efectuată "pe mână" - folosind caracterele SO (ing. shift out) și SI (engleză shift eun); în acest caz, în versiunea națională, a fost posibilă înlocuirea completă a literelor latine cu simboluri naționale. Vezi și: KOI-7.
Ulterior s-a dovedit a fi mai convenabil să folosească codificări pe 8 biți (pagini de cod), în care jumătatea inferioară a tabelului de coduri (0‑127) este ocupată de caractere US-ASCII, iar jumătatea superioară (128‑255) este ocupată de caractere suplimentare, inclusiv un set de caractere naționale.
Astfel, jumătatea superioară a tabelului ASCII înainte de adoptarea pe scară largă a Unicode a fost utilizată activ pentru a reprezenta caractere localizate, litere ale limbii locale.
Lipsa unui singur standard pentru plasarea caracterelor chirilice în tabelul ASCII a cauzat o mulțime de probleme de codificare (KOI-8, Windows-1251 etc.). Alte limbi cu scripturi non-latine au suferit, de asemenea, din cauza prezenței mai multor codificări diferite.
Primele 128 de caractere ale standardului Unicode se potrivesc cu caracterele US-ASCII corespunzătoare.
Tabelul ASCII
.0 .1 .2 .3 .4 .5 .6 .7 .8 .9 .A .B .C .D .E .F 0. NUL SOH STX ETX EOT ENQ ACK BEL BS HT LF VT FF CR SO SI 1. DLE DC1 DC2 DC3 DC4 NAK SYN ETB CAN EM SUB ESC FS GS RS SUA 2. ! « # $ % & ‘ ( ) * + , - . / 3. 0 1 2 3 4 5 6 7 8 9 : ; < = > ? 4. @ A B C D E F G H eu J K L M N O 5. P Q R S T U V W X Y Z [ \ ] ^ _ 6. ` o b c d e f g h eu j k l m n o 7. p q r s t u v w x y z { | } ~ DEL În prima versiune a standardului ASCII (1963), simbolurile „săgeată sus” și „săgeată stângă” au fost localizate la pozițiile 0x5e (94) și respectiv 0x5f (95). Standardul ECMA-6 (1965) le-a înlocuit cu un caracter de inserare (care este folosit și ca simbol circumflex „^”) și, respectiv, simbolul de subliniere „_”.
Caracterele de control
Tabelul ASCII a fost creat pentru a schimba informații despre tipuri. Setul includea caractere neimprimabile folosite ca comenzi pentru controlul dispozitivului de tip teletip. Comenzi similare au fost utilizate în alte instrumente de mesagerie pre-computer (cod Morse, alfabet semafor), ținând cont de specificul dispozitivului.
- NUL, 00 - nul, gol. Caracterul nul a fost mereu ignorat. Pe benzi perforate, numărul „1” a fost indicat de o gaură, iar numărul „0” prin lipsa unei găuri. Secțiunile de bandă perforată în care informațiile nu au fost înregistrate nu conțineau găuri, adică conțineau caractere nule; astfel de site-uri au fost localizate la începutul și la sfârșitul benzii. Caracterul nul este încă utilizat în multe limbaje de programare, ca semn al sfârșitului liniei și este notat cu „\\ 0”. (Termenul „șir” se referă la o secvență de caractere.) Pe unele sisteme de operare, null este ultimul caracter al oricărui fișier text.
Mesajele transmise pe canalul de comunicare au fost împărțite în două părți:
- "Header";
- "Text".
„Antetul” conținea adresele expeditorului și ale destinatarului, suma de control etc., puteau fi plasate înainte de „text” sau după. Termenul „text” a fost partea din mesajul destinat tipăririi.
- SOH, 01 - startă of heading, începutul „antetului”.
- STX, 02 - starta de te xt, începutul „textului”. Simbolul a fost folosit ca o comandă pentru a porni imprimanta cu teletip. Textul pentru tipărire a fost localizat între caracterele STX și ETX.
- ETX, 03 - end te xt, sfârșitul „textului”. Simbolul a fost folosit pentru a opri dispozitivul de tipărire prin teletip. În prezent, codul 03 este utilizat pentru a trimite un semnal SIGINT la un proces. signal interrupt) și poate fi trimis apăsând combinația de taste Ctrl + C. După ce a primit un astfel de semnal, procesul ar trebui să finalizeze lucrarea.
- EOT, 04 - end of ttransmisie, sfârșitul transferului. Simbolul este folosit de emulatoarele terminale cu semnificația „sfârșitul fișierului” (EOF, eng. end of flle) și poate fi trimis apăsând combinația de taste Ctrl + D. După ce a primit un astfel de simbol, emulatorul terminalului va determina procesul care lucrează în prezent cu terminalul și va seta indicatorul „sfârșitul fișierului” (EOF) pentru fluxul de intrare standard (stdin, eng. standar d înpune flux) a acestui proces. Ca urmare, procesul va opri citirea stdin și va începe procesarea datelor citite.
- ENQ, 05 - eNQuire. "Cer confirmare."
- ACK, 06 - acknowledgement. „Confirm.” Simbolul NAK înseamnă opusul - „Nu confirm”.
- BEL, 07 - belsun, sună. Simbolul este adesea denumit „\\ a” și este folosit pentru a suna o alarmă. Într-un computer modern, sunetul este reprodus de difuzorul încorporat. De exemplu, următoarele comenzi pot reda sunet: ecou -e „\\ a” sau ecou -e „\\ 007 ″ (bash); echo ^ G (cmd.exe; pentru a intra ^ G apăsați Ctrl + G), printf ("\\ a"); (cod în limbajul de programare C).
- BS, 08 - back sritm, întoarcere cu un personaj Tasta ← Backspace șterge caracterul anterior.
- TAB, 09 - tab, fila orizontală. Este desemnat „\\ t”. Uneori numit HT din engleză. horizontal tabulation.
- LF, 0A - liNE feed, feed line. Comandați să coborâți carul de tipărire cu o linie în jos. Caracterul este folosit pentru a marca sfârșitul unei linii a unui fișier text pe UNIX. Secvența de caractere CR LF indică sfârșitul unei linii a unui fișier text în Windows. Simbolul în multe limbaje de programare este indicat ca "\\ n". Apăsarea tastei ↵ Enter în timp ce ieșirea textului duce la o alimentare de linie.
- VT, 0B - vertical tab, fila verticală.
- FF, 0C - foRM feed, pagina rulată, pagina nouă. Comandă pentru imprimantă: continuați imprimarea de la începutul foii următoare.
- CR, 0D - carriage return, retur car. Comandă pentru imprimantă: continuați imprimarea de la începutul liniei curente (nu de la o linie nouă). În multe limbaje de programare, simbolul CR este denumit „r”. Pe Mac OS, caracterul CR indică sfârșitul unei linii dintr-un fișier text. De la tastatură, simbolul CR poate fi introdus apăsând combinația de taste Ctrl + M.
- SO, 0E - shift out, treceți la o altă bandă. O altă bandă era de obicei vopsită în roșu. Ulterior, simbolul a fost folosit pentru a comuta la codarea națională.
- SI, 0F - shift eun. Comanda pentru a efectua opusul acțiunii SO: treceți la banda sursă sau treceți la codarea sursei.
- DLE, 10 - data lcerneală escape, eliberarea canalului de date. Orice caractere care urmează un DLE trebuie interpretate ca date, și nu ca caractere de control.
- DC1, 11 - device control 1 , Primul caracter al controlului dispozitivului. Comandă: porniți cititorul cu bandă.
- DC2, 12 - device control 2 , Al 2-lea caracter pentru controlul dispozitivului. Comandă: porniți pumnul.
- DC3, 13 - device control 3 , Al 3-lea caracter al controlului dispozitivului. Comandă: opriți cititorul cu bandă.
- DC4, 14 - device control 4 , Al 4-lea caracter al controlului dispozitivului. Comandă: opriți pumnul.
- NAK, 15 - negative oc kconfirmare, nu confirmați. Înapoi la ACK.
- SYN, 16 - sincronizarea. Acest simbol a fost transmis atunci când a fost necesar să se transmită ceva pentru sincronizare.
- ETB, 17 - end text bblocare, sfârșitul blocului de text. Uneori, din motive tehnice, textul era împărțit în blocuri.
- CAN, 18 - puteacel, anulare (a celor transmise mai devreme).
- EM, 19 - end medium, capătul purtătorului (rămâne fără bandă de hârtie, hârtie etc.)
- SUB, 1A - subînlocuitor, înlocuitor. Un simbol este pus în locul unui simbol a cărui valoare a fost pierdută sau deteriorată în timpul transmisiei. Sau un personaj este plasat înaintea unui personaj, pentru interpretarea căruia trebuie să treceți la un set suplimentar de caractere. Sau un personaj este plasat înaintea unui personaj care trebuie tipărit într-o altă culoare. În prezent, un caracter este inserat prin apăsarea combinației de taste Ctrl + Z și este utilizat pentru a marca sfârșitul unui fișier în DOS și Windows.
- ESC, 1B - escmaimuță. Caracterul care urmează caracterul ESC are o semnificație diferită de cea definită în ASCII. De obicei, secvențele de evacuare urmează un caracter ESC. În DOS, acestea sunt implementate de driverul ANSI.SYS
Separarea datelor în 4 niveluri a fost acceptată:
- mesajul ar putea consta din fișiere;
- fișierele pot consta din grupuri;
- grupurile ar putea consta din înregistrări;
- înregistrările ar putea consta din unități.
- FS, 1C - flle sseparator, separator de fișiere.
- GS, 1D - grupul sseparator, separator de grup.
- RS, 1E - reCORD separator, separator de înregistrare.
- SUA, 1F - ulindină separator, delimitator de unitate.
- DEL, 7F - delete, ștergeți ultimul personaj. Cu simbolul DEL, format din toate unitățile în cod binar, orice personaj ar putea fi „ciocanit”. Dispozitivele și programele au ignorat DEL, la fel ca NUL. Codul acestui simbol provine de la primele procesoare de text cu memorie pe o bandă perforată: în ele, simbolul a fost șters prin „înfundarea” codului său cu găuri (denotând unități logice).
Tabel Proprietăți structurale
- Codurile de caractere ale cifrelor „0” - „9” din sistemul de numere binare încep cu 00112 și se termină cu numere binare. De exemplu, 01012 este numărul 5, iar 0011 01012 este caracterul "5". Știind acest lucru, puteți converti numere binare zecimale (BCD) într-un șir ASCII, adăugând pur și simplu 00112 la fiecare butuc zecimal binar din stânga.
- Literele „A” - „Z” cu majuscule și minuscule se disting în reprezentarea lor printr-un singur bit, ceea ce simplifică conversia registrului și verifică dacă codul aparține gamei de valori. Literele sunt reprezentate de numerele lor de serie din alfabet, scrise în cinci cifre în sistemul binar, urmate de 0102 (pentru litere mari cu majuscule) sau 0112 (pentru litere mici).
Prezentare computer ASCII
Pe marea majoritate a computerelor moderne, unitatea minimă de memorie adresabilă este un octet de 8 biți. Prin urmare, folosește caractere pe 8 biți și nu pe 7 biți. De obicei, un caracter ASCII este extins la 8 biți, adăugând pur și simplu un bit zero ca bit mare.
Codurile ASCII sunt utilizate în programare ca coduri de platformă intermediară ale tastelor apăsate (spre deosebire de codurile de scanare IBM PC și alte coduri interne).
Pentru aspectul tastaturii QWERTY, tabelul de cod arată cum arată tabelul următor:
evadare F1 F2 F3 F4 F5 F6 F7 F8 F9 F10 F11 F12 Ecran de imprimare Derulare blocare pauză `g 1 2 3 4 5 6 7 8 9 0 - =+ Spatiul din spate Inserare acasă Pagină sus Blocare num / adăugați. * adăugați. + adăugați. Tab Q W E R T Y U eu O P [ ] Șterge capăt Pagină în jos 7 adaugă. 8 adaugă. 9 adaugă. Capacele se blochează A S D F G H J K L ; w „e introduce 4 adăugați. 5 adauga. 6 adaugă. Introduceți adăugarea. schimbare Z X C V B N M ,< .> / schimbare \| în sus 1 adaug. 2 adaugă. 3 adaug. Ctrl victorie Alt Bară spațială Alt victorie listă Ctrl stânga jos dreapta Ins / 0 Del /. 46/110
Nu există litere ruse pe acest aspect al tastaturii și există, de asemenea, unele inexactități, dar principalele caracteristici sunt reflectate.
Îi invit pe toți să vorbească
CODAREA INFORMAȚIILOR TEXT. CODIFICARE ASCII CODURI CIRILIANE DE BAZĂ UTILIZATE
Orice text este o secvență de caractere ale unui anumit alfabet. Dacă fiecare caracter al alfabetului utilizat este codat cu un număr, textul va fi prezentat ca o secvență de numere. La procesarea textului de către un computer, se utilizează o reprezentare binară a numerelor.
Pentru interpretarea corectă a textului codat, trebuie să știți unde se termină codul binar al unui caracter al alfabetului inițial și începe codul binar al altuia. Puteți codifica fiecare caracter într-o secvență de 8 biți - un octet.
În opt cifre, puteți scrie 28 \u003d 256 întregi binare diferite - de la 000000002 la 111111112. Acest lucru este suficient pentru a vă asigura că fiecare litere majuscule și minuscule din alfabetele engleză și rusă, toate cifrele arabe, semnele de punctuație, alte câteva caractere necesare, precum și codurile de servicii pentru transferul de date, corespund unei desemnări unice (care nu se repetă) pe opt biți.
Pentru comoditatea codării digitale și decodării ulterioare, sunt compilate tabele de cod. Diferite tipuri de calculatoare cu sisteme de operare diferite utilizează diferite tabele de coduri. Unul dintre standardele pentru codificarea caracterelor tastaturii computerului cu numere de 8 biți este tabelul de cod american Standard for Interchange Information (ASCII). Prima jumătate a acesteia (codurile 0-127), care conține semne de punctuație, cifre arabe și caractere ale alfabetului englez, este acceptată în general în întreaga lume. Codurile 128 - 255 din tabelul ASCII (coduri ASCII extinse) sunt utilizate în principal pentru alfabetele naționale.
Puteți reda tabelul de coduri tastând numărul dorit de la 0 la 255 pe tastatura numerică mică, ținând apăsată tasta Alt. Figura 1 arată tabelul de cod obținut în acest mod.
♫ ☼ ◄ ↕ | ||||||||||
← ∟ ↔ |
||||||||||
M N O P R S T U V | ||||||||||
C H W D F Y S E |
||||||||||
Figura 1 - Tabel de cod
Codul este format din numărul de rând și numărul coloanei. De exemplu, codul 50 corespunde numărului 2, codului 134 - litera J. Coduri de la 0 la 32 - serviciu.
Prezența a numeroase variante de tabele de coduri orientate spre utilizarea alfabetelor din diferite limbi naționale este în sine un mare inconvenient. Pentru organizarea tabelelor, au început să atribuie nume și numere speciale (de exemplu,
KOI-8), dar acest lucru nu a rezolvat problema creării unui sistem unificat de coduri care să combine diverse alfabete naționale.
Eliminarea acestor inconveniente și limitări a fost posibilă datorită noului standard internațional Unicode, susținut de cele mai recente versiuni ale sistemului de operare Microsoft Windows. În prezent, acest standard de codare a caracterelor alocă doi octeți pe caracter. Această codare vă permite să reprezentați 216 \u003d 65 536 de caractere diferite în alfabetul binar. Codurile primelor 128 de caractere sunt identice cu ASCII.
VOLUMUL INFORMAȚIONAL AL \u200b\u200bMESAJELOR
Sarcini cu decizii
Sarcină. Să presupunem că fiecare caracter este codat cu 1 octet (KOI-8). Estimați volumul de informații al mesajului
I n n și w c o și n il x n s e d in o si h n i x h și f l.
Mesajul conține 39 de caractere, prin urmare, necesită 1 octet / caracter * 39 caractere \u003d 39 octeți pentru a-l codifica,
sau 8 biți / octeți * 39 octeți \u003d 312 biți.
1. În mesajul din exemplul precedent, cuvântul „binar” a fost înlocuit cu cuvântul „zecimal”. Cum s-a modificat volumul de informații al mesajului în biți și octeți?
Răspuns: volumul informațional al mesajului a crescut cu 2 octeți, cu 16 biți.
2. Să presupunem că fiecare caracter este codat cu 1 octet (KOI-8). Estimați volumul de informații al mesajului
Sunt capabil să comunic și să trimit un mesaj.
Răspuns: volumul informațional al mesajului este de 48 de octeți.
3. Să presupunem că fiecare caracter este codat în 2 octeți (Unicode). Estimați volumul de informații al mesajului
Sunt conștient de faptul că KO I - 8.
Răspuns: volumul informațional al mesajului este de 68 de octeți.
4. Să presupunem că fiecare caracter este codat în 2 octeți (Unicode). Estimați volumul de informații al mesajului
ALGORITMMOZNO S P R S
Răspuns: volumul de informații al mesajului este de 92 de octeți.
5. Mesajul de informare în rusă, înregistrat inițial în cod Unicode pe 16 biți, a fost transcodat în codificarea KOI-8 pe 8 biți. În același timp, mesajul informațional a scăzut cu 480 de biți. Care este lungimea mesajului în caractere?
Răspuns: Mesajul are 60 de caractere.
6. Mesajul de informare în rusă, înregistrat inițial în codul KOI-8 pe 8 biți, a fost transcodat în codificarea Unicode pe 16 biți. Volumul mesajului informațional a crescut cu 568 de biți. Care este lungimea mesajului în caractere?
Răspuns: Lungimea mesajului este de 71 de caractere.
7. Mesajul de informare în rusă, înregistrat inițial în codul KOI-8 pe 8 biți, a fost transcodat în codificarea Unicode pe 16 biți. Cum s-a schimbat volumul mesajului informațional?
Răspuns: volumul unui mesaj informațional s-a dublat.
8. Câte caractere conține un mesaj în Unicode pentru 200 de biți?
Răspuns: mesajul conține 25 de caractere.
9. Câte caractere conține un mesaj, al cărui volum de informații în codificarea KOI-8 este de 240 de biți?
Răspuns: mesajul conține 30 de caractere.
CODARE ȘI DECODARE INFORMAȚIONALĂ
Sarcini cu decizii
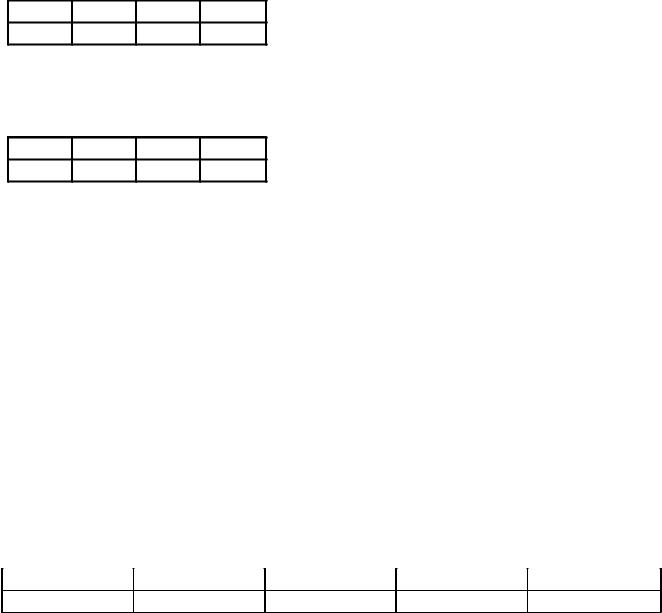
1. Pentru codificarea literelor A, B, C, D folosind patru cifre coduri binare de la 1000 la 1011, respectiv. Pentru o secvență de caractere B, D, B, A scrieți un cod binar, prezentați rezultatul codării în cod octal.
Codurile de caractere sunt prezentate în tabelul 1: tabelul 1
Codul binar corespunzător conține 16 biți: 1001101110101000, este mai convenabil să scrieți acest număr pentru conversia în cod octal cu o defalcare în triade: 1 001 101 110 101 000. Este clar că numărul octal corespunzător are următoarea formă: 115650.
Pentru a converti un număr reprezentat în cod binar în hexadecimal, este convenabil să împărțiți înregistrarea binară în tetraduri (grupuri de 4 cifre), începând de la dreapta.
2. Pentru 5 litere din alfabetul rus, sunt setate codurile binare, care pot conține 2 sau 3 cifre. Codurile sunt înregistrate în tabelul 3:
1) 110100000100110111
2) 101010000010010011
3) 110100001001100111
4) 110110000100110010.
Vom decodifica secvențial fiecare dintre cele patru mesaje, împărțindu-ne în grupuri de biți în conformitate cu tabelul 3:
1) 11 01 000 001 001 10 111 Ultimul grup de cifre nu poate fi asociat cu un caracter
conform tabelului 3. Mesajul conține o eroare.
2) 10 10 10 000 01 001 001 1 Mesajul conține o eroare.
3) 11 01 000 01 001 10 01 11
Mesajul poate fi decodat. 4) 11 01 10 000 10 01 10 010 Mesajul conține o eroare.
Răspuns: 3) 110100001001100111
SARCINI PENTRU SOLUȚIA INDEPENDENTĂ
1. Pentru a codifica literele M, N, P, Q, sunt utilizate coduri binare cu patru cifre de la 1000 la 1011, respectiv. Pentru o secvență de caractere N, Q, P, M scrieți un cod binar, prezentați rezultatul codării în cod octal.
Răspuns: cod binar 1 001 101 110 101 000, cod octal 115650.
2. Pentru codificarea literelor A, B, C, D, sunt utilizate coduri binare de patru cifre de la 1000 la 1011, respectiv. Pentru o secvență de caractere B, D, C, A scrieți un cod binar, prezentați rezultatul codării cu cod hexadecimal.
Răspuns: cod binar 1001 1011 1010 1000, cod hexadecimal 9BA9.
3. Pentru a codifica literele M, N, O, P, utilizați coduri binare din trei cifre de la 000 la 111, respectiv. Pentru o secvență de caractere O, N, M, P scrieți un cod binar, prezentați rezultatul codării în cod octal.
Răspuns: cod binar 110 101 100 111, cod octal 6547.
4. Pentru codificarea literelor M, N, O, P, sunt utilizate coduri binare cu trei cifre de la 100 la 111, respectiv. Pentru o secvență de caractere O, N, M, P scrieți un cod binar, prezentați rezultatul codării cu cod hexadecimal.
Răspuns: cod binar 1101 0110 0111, cod hexadecimal B67.
∙ a doua cifră nu poate fi 3.
6. Pentru a compune numere de patru cifre, sunt utilizate numerele 1, 2, 3, 4, 5 și sunt necesare următoarele reguli:
∙ în primul rând poate fi unul dintre numerele 1, 3, 4;
∙ în înregistrarea numerelor, numerele impare și impare alternează;
∙ a treia cifră nu poate fi 4.
Înregistrați toate numerele posibile compilate în conformitate cu aceste reguli.
7. Pentru a compune numere de patru cifre, sunt utilizate numerele 1, 2, 3, 4, 5 și sunt necesare următoarele reguli:
∙ în primul rând poate fi unul dintre numerele 2, 4, 5;
∙ în înregistrarea numerelor, numerele impare și impare alternează;
∙ a doua și ultima cifră nu pot fi aceleași. Înregistrați toate numerele posibile compilate în conformitate cu aceste reguli.
8. Pentru 5 litere din alfabetul rus, sunt setate codurile binare, care pot conține 2 sau 3 cifre. Codurile sunt scrise în tabel:
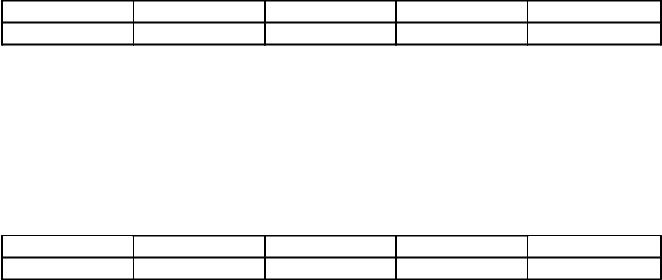
Dintre cele patru mesaje din această codificare, doar unul a trecut fără erori, numai acesta poate fi decodificat corect. Găsiți acest mesaj din listă:
1) 110100000100110011
2) 111010000010010011
3) 110100001001100111
4) 110110000100110010. Răspuns: 110100001001100111
9. Pentru 5 litere din alfabetul rus, sunt setate codurile binare, care pot conține 2 sau 3 cifre. Codurile sunt scrise în tabel:
Codificați secvența FIGHT, faceți o astfel de eroare în cod care nu vă va permite să decodificați corect mesajul.
TEST DE FORMARE
2 Presupunem că fiecare caracter este codificat 1 1) 384 biți octeți (Koi-8). Evaluarea informațională 2) 192 biți
volumul cuvintelor de 24 de caractere în acest | ||||||
codificare. | ||||||
3 produse | recodare | |||||
mesaj informativ | ||||||
limba înregistrată inițial în 8- | ||||||
cod de biți KOI-8, în codificare pe 16 biți | ||||||
Unicode. Volumul informațiilor | ||||||
mesajele au crescut cu 336 biți. Ce este | ||||||
lungimea mesajului în caractere? | ||||||
4 Câte caractere conține | ||||||
mesaj, | informații | |||||
care în codificarea KOI-8 este de 240 | ||||||
5 Câte caractere conține | ||||||
mesaj, | informații | |||||
al cărui cod Unicode este codat | ||||||
6 Pentru codificarea literelor A, B, C, D | ||||||
utilizați coduri binare din trei cifre | ||||||
dreapta | ||||||

