24.07.2019
Codificarea informațiilor text. De ce este codul binar universal? Metode de programare
Hai să vedem cum toate la fel digitalizarea textelor? Apropo, pe site-ul nostru puteți traduce orice text în zecimal, hexadecimal, cod binar Utilizarea calculatorului de cod online.
Codare text.
Conform teoriei computerului, orice text este format din caractere individuale. Aceste caractere includ: litere, numere, punctuație cu minuscule, caractere speciale ("", nr, () etc.), includ și spații între cuvinte.
Cunoașterea necesară. Setul de caractere cu care scriu textul se numește ALFAVIT.
Numărul de caractere luate în alfabet reprezintă puterea acestuia.
Cantitatea de informații poate fi determinată de formula: N \u003d 2b
- N este aceeași putere (multe caractere),
- b - Bit (greutatea personajului preluat).
Alfabetul în care vor fi 256 poate găzdui aproape toate caracterele necesare. Astfel de alfabete sunt numite SUFICIENT.
Dacă luăm alfabetul cu o capacitate de 256, și rețineți că 256 \u003d 28
- 8 biți sunt întotdeauna numiți un octet:
- 1 octet \u003d 8 biți.
Dacă traduceți fiecare caracter în cod binar, atunci acest cod de text al computerului va ocupa 1 octet.
Cum pot arăta informațiile text în memoria computerului?
Orice text este tastat pe tastatură, pe tastele tastaturii, vedem semne care ne sunt familiare (numere, litere etc.). Acestea introduc RAM-ul computerului numai ca cod binar. Codul binar al fiecărui personaj arată ca un număr format din opt cifre, de exemplu 00111111.
Deoarece octețul este cea mai mică particulă adresabilă a memoriei, iar memoria este adresată fiecărui caracter separat, comoditatea unei astfel de codări este evidentă. Cu toate acestea, 256 de caractere reprezintă o sumă foarte convenabilă pentru orice informații despre caracter.
Desigur, a apărut întrebarea: Care anume cod de opt biți aparține fiecărui personaj? Și cum se traduce textul în cod digital?
Acest proces este condiționat și avem dreptul să venim cu diverse metode de codare a caracterelor. Fiecare simbol al alfabetului are un număr de la 0 la 255. Și fiecărui număr i se atribuie un cod de la 00000000 la 11111111.
Tabelul pentru codificare este o „foaie de înșelăciune”, care indică caracterele alfabetului în conformitate cu numărul de serie. Pentru diferite tipuri de calculatoare, utilizați tabele diferite pentru codificare.
ASCII (sau Asuka) a devenit standardul internațional pentru calculatoarele personale. Masa are două părți.
Prima jumătate pentru tabelul ASCII. (A fost prima jumătate care a devenit standardul.)
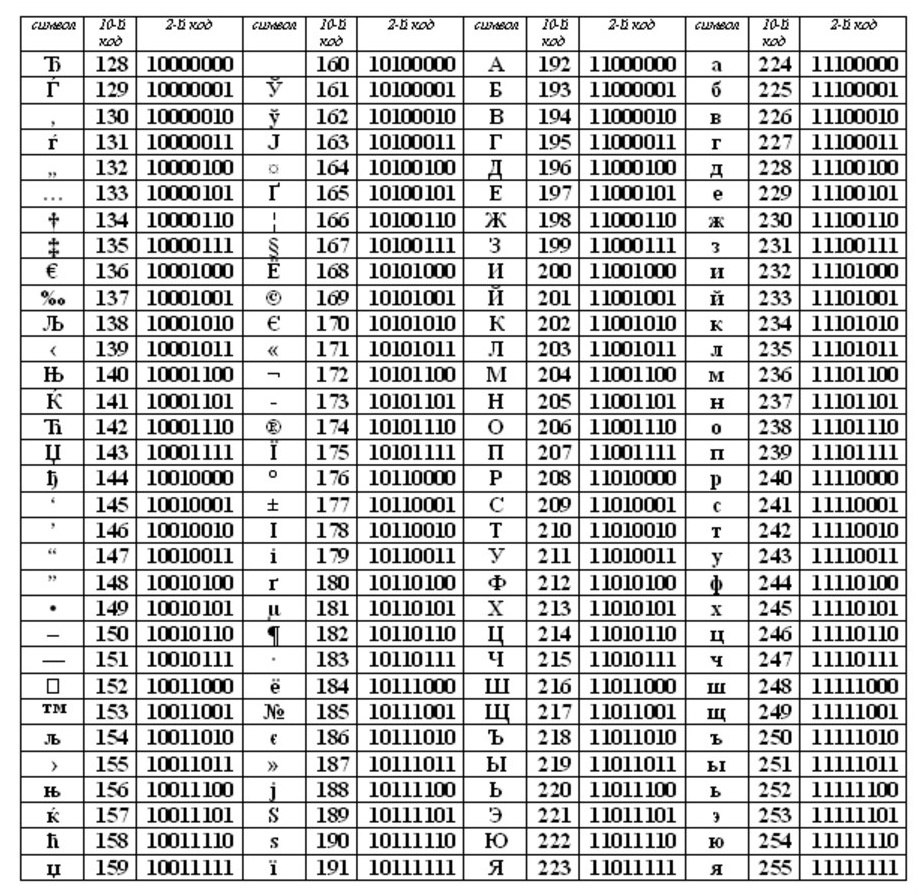
Respectarea ordinii lexicografice, adică literele din tabel (minuscule și majuscule) sunt indicate în ordine alfabetică strictă, iar numerele în ordine crescătoare se numesc principiul codării secvențiale a alfabetului.
Pentru alfabetul rus, de asemenea, respectați-vă principiu de codificare secvențială.
Acum, în ziua de azi folosesc întregi cinci sisteme de codificare Alfabet rus (KOI8-P, Windows. MS-DOS, Macintosh și ISO). Datorită numărului de sisteme de codificare și lipsei unui standard, foarte des apar neînțelegeri cu transferul textului rusesc în forma computerului.
Una dintre primele standarde pentru codificarea alfabetului rusiar pe calculatoarele personale se consideră KOI8 („Cod de schimb de informații, pe 8 biți”) Această codificare a fost utilizată la mijlocul anilor șaptezeci pe o serie de computere CE, iar de la mijlocul anilor optzeci, a început să fie utilizată în primele sisteme de operare UNIX traduse în rusă.
De la începutul anilor 90, așa-numita perioadă în care a dominat sistemul de operare MS DOS, apare sistemul de codare CP866 („CP” înseamnă „Pagina de cod”, „pagina de cod”).
Gigantul computerului APPLE, cu sistemul său inovator sub controlul lor (Mac OS), începe să folosească propriul sistem pentru a codifica alfabetul MAC.
Organizația internațională de standarde (ISO) stabilește un alt standard pentru limba rusă sistem de codare alfabetnumit ISO 8859-5.
Și cel mai obișnuit, astăzi, un sistem de codificare a alfabetului, inventat în Microsoft Windows și se numește CP1251.
Începând cu a doua jumătate a anilor 90, problema standardului pentru traducerea textului în cod digital pentru limba rusă și nu numai prin introducerea în standard a unui sistem numit Unicode. Este reprezentată prin codificare pe șaisprezece biți, ceea ce înseamnă că sunt alocați exact doi octeți de RAM pentru fiecare caracter. Desigur, cu această codificare, costurile de memorie sunt dublate. Cu toate acestea, un astfel de sistem de cod permite traducerea a până la 65536 de caractere în cod electronic.
Specificul sistemului Unicode standard este includerea absolut a oricărui alfabet, fie el existent, dispărut, alcătuit. În cele din urmă, absolut orice alfabet, pe lângă acesta, sistemul Unicode, include o mulțime de simboluri matematice, chimice, muzicale și comune.
Să folosim tabelul ASCII pentru a vedea cum poate arăta un cuvânt în memoria computerului.
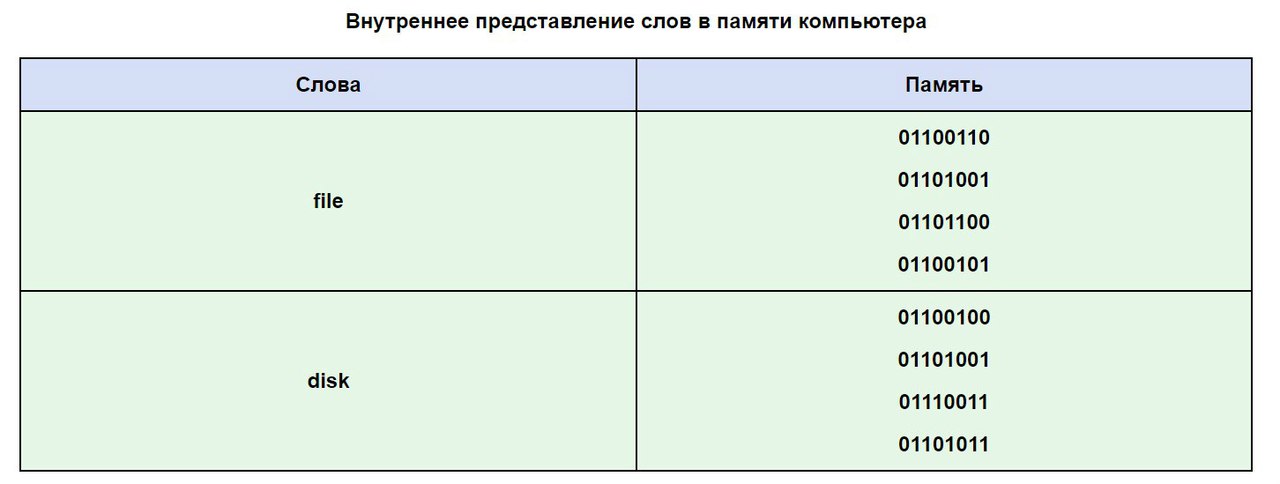
Se întâmplă adesea ca textul tău, care este scris cu litere din alfabetul rus, să nu poată fi citit, acest lucru se datorează diferenței dintre sistemele de codare ale alfabetului pe computere. Aceasta este o problemă foarte frecventă care este adesea detectată.
Unitățile minime de informații sunt biți și octeți.
unul bit vă permite să codificați 2 valori (0 sau 1).
utilizând două biții pot fi codați 4 Valori: 00, 01, 10, 11.
trei biții sunt codați 8 valori diferite: 000, 001, 010, 011, 100, 101, 110, 111.
Din exemplele de mai sus se poate observa că adăugarea unui bit dublează numărul de valori care pot fi codificate:
1 bit codează -\u003e 2 valori diferite (2 1 \u003d 2),
2 biți codifică -\u003e 4 valori diferite (2 2 \u003d 4),
3 biți codifică -\u003e 8 valori diferite (2 3 \u003d 8),
4 biți codifică -\u003e 16 valori diferite (2 4 \u003d 16),
5 biți codifică -\u003e 32 valori diferite (2 5 \u003d 32),
6 biți codifică -\u003e 64 valori diferite (2 6 \u003d 64),
7 biți codifică -\u003e 128 valori diferite (2 7 \u003d 128),
8 biți codifică -\u003e 256 valori diferite (2 8 \u003d 256),
9 biți codifică -\u003e 512 valori diferite (2 9 \u003d 512),
10 biți codifică -\u003e 1024 valori diferite (2 10 \u003d 1024).
Ne amintim că într-un octet, nu 9 și nu 10 biți, ci doar 8. Prin urmare, folosind un octet, puteți codifica 256 de caractere diferite. Crezi că este mult sau puțin? Să ne uităm la un exemplu de codificare informații textuale.
Există 33 de litere în rusă și, prin urmare, sunt necesare 33 de octeți pentru codificarea lor. Calculatorul distinge între litere mari (majuscule) și mici (minuscule) doar dacă sunt codificate cu coduri diferite. Deci, pentru a codifica litere mari și mici ale alfabetului rus, sunt necesare 66 de octeți.
Pentru majuscule și litere mici din alfabetul englez, sunt necesare alte 52 de octeți. Rezultatul este 66 + 52 \u003d 118 octeți. Aici trebuie să adăugați și numere (de la 0 la 9), un caracter spațial, toate semnele de punctuație: punct, virgulă, liniuță, exclamare și semne de întrebare, paranteze: rotunde, cretate și pătrate, precum și semne ale operațiilor matematice: +, -, \u003d, / (aceasta este diviziune), * (aceasta este înmulțirea). Adăugăm, de asemenea, caractere speciale:%, $, &, @, #, nr, etc. Toate acestea luate împreună reprezintă aproximativ 256 de caractere diferite.
Și atunci problema a fost lăsată celor mici. Este necesar să vă asigurați că toți oamenii de pe Pământ sunt de acord între ei cu privire la care anumite coduri (de la 0 la 255, adică un total de 256) să fie atribuite simbolurilor. Să presupunem că toți oamenii sunt de acord că codul 33 înseamnă un punct de exclamare (!), Iar codul 63 înseamnă un semn de întrebare (?). Și, de asemenea, pentru toate caracterele aplicabile. Atunci aceasta va însemna că textul scris de o persoană pe computerul său poate fi întotdeauna citit și tipărit de o altă persoană pe un alt computer.
Tabelul ASCII
Un astfel de acord universal privind utilizarea egală a ceva este denumit standard. În cazul nostru, standardul ar trebui să fie un tabel în care corespund codurile (de la 0 la 255) și caractere. Se numește un tabel similar tabel de codificare.
Dar nu atât de simplu. La urma urmei, personajele care sunt bune, de exemplu, pentru Grecia, nu vor funcționa pentru Turcia, deoarece alte litere sunt folosite acolo. În mod similar, ceea ce este bun pentru Statele Unite nu este potrivit pentru Rusia, iar ceea ce este bun pentru Rusia nu este potrivit pentru Germania.
Prin urmare, au decis să împartă tabelul de coduri la jumătate.
Primele 128 de coduri (de la 0 la 127) trebuie să fie standard și obligatoriu pentru toate țările și pentru toate computerele, acesta este - internaționalstandardul.
Și cu a doua jumătate a tabelului de coduri (de la 128 la 255), fiecare țară poate face orice și poate crea propriul său standard în această jumătate - național.
Se numește prima jumătate (internațională) a tabelului de coduri o masăASCII, care a fost creat în SUA și acceptat în toată lumea. Standardul ASCII nu este responsabil pentru a doua jumătate a tabelului de coduri. Diferite țări își creează aici propriile tabele de coduri naționale. Poate fi, de asemenea, că într-o țară există standarde diferite pentru sisteme de calcul diferite, dar numai în a doua jumătate a tabelului de cod.
Coduri din tabelul internațional ASCII
0-31 - caractere speciale care nu sunt tipărite pe ecran sau pe imprimantă, dar sunt utilizate pentru a efectua acțiuni speciale (de exemplu, pentru „transferul carului” - pentru a muta textul pe o nouă linie sau pentru „fila” - pentru a seta cursorul pe poziții speciale dintr-o linie text etc.).
32 - spațiu (separatorul între cuvinte este, de asemenea, un caracter care trebuie codat, deși este afișat ca un „spațiu gol” între cuvinte și caractere),
33-47 - caractere speciale (paranteze etc.) și semne de punctuație (perioadă, virgulă etc.),
48-57 - numere de la 0 la 9,
58-64 - simboluri matematice (plus (+), minus (-), înmulțiți (*), împărțiți (/) etc.) și semne de punctuație (punct, punct și virgulă etc.),
65-90 - litere mari cu majuscule
91-96 - caractere speciale (paranteze pătrate etc.),
97-122 - scrisori în engleză mici (minuscule),
123-127 - personaje speciale (bretele cret etc.).
În afara tabelului ASCII, începând cu numerele 128 - 159, există litere majuscule (majuscule) litere ruse, iar de la 160 la 170 și de la 224 la 239 litere sunt mici (minuscule) litere ruse.
Codificare a cuvântului pace
Folosind codificarea arătată, putem să ne imaginăm cum un computer codifică și apoi reproduce, de exemplu, cuvântul MIR (cu majuscule). Acest cuvânt este reprezentat de trei coduri: litera M corespunde codului 140 (conform sistemului național rus de codificare), și - acesta este codul 136 și P - acesta este 144.
Dar după cum am menționat anterior, computerul percepe informații doar în formă binară, adică. ca o secvență de zerouri și altele. Fiecare octet corespunzător fiecărei litere a cuvântului MIR conține o secvență de opt zerouri și unul. Folosind regulile pentru convertirea informațiilor zecimale în binar, puteți înlocui valorile zecimale ale codurilor de litere cu omologii lor binari.
Cifra zecimală 140 corespunde numărului binar 10001100. Aceasta poate fi verificată dacă se fac următoarele calcule: 2 7 + 2 3 +2 2 \u003d 140. Gradul în care se ridică fiecare „două” este numărul de poziție al numărului binar 10001100, în care există „1 », Iar pozițiile sunt numerotate de la dreapta la stânga, începând de la numărul poziției zero: 0, 1, 2 etc.
Puteți afla mai multe despre transferul de numere de la un sistem de numere la altul, de exemplu, din manualele de informatică sau prin Internet.
În mod similar, puteți verifica dacă cifra 136 corespunde numărului binar 10001000 (verificați: 2 7 + 2 3 \u003d 136). Și numărul 144 corespunde numărului binar 10010000 (verificați: 2 7 + 2 4 \u003d 144).
Astfel, în computer, cuvântul MIR va fi memorat sub forma următoarei secvențe de zerouri și altele (biți): 10001100 10001000 10010000.
Desigur, toate transformările de date prezentate mai sus sunt efectuate folosind programe de calculator și nu sunt vizibile pentru utilizatori. Aceștia observă doar rezultatele acestor programe, atât când introduceți informații cu ajutorul tastaturii, cât și când sunt afișate pe ecranul monitorului sau pe o imprimantă.
Trebuie menționat că, la nivelul studierii alfabetizării, utilizatorii de calculatoare nu trebuie să cunoască sistemul de numere binare. Este suficient să aveți o idee despre codurile de caractere zecimale. Doar programatorii de sistem, în practică, folosesc sisteme binare, hexadecimale, octale și alte numere. Acest lucru este deosebit de important pentru ei atunci când computerele afișează mesaje de eroare în software care indică valori eronate fără conversie în zecimale.
Exerciții de alfabetizare pe calculatorcare vă permit să vedeți și să simțiți în mod independent sistemele de codificare descrise sunt prezentate în articol
P.S. Articolul s-a terminat, dar puteți citi în continuare:
P.P.S.că abonați-vă pentru a primi articole noicare nu sunt încă pe blog:
1) Introduceți adresa dvs. de e-mail în acest formular.
Codarea textului binar
Începând de la sfârșitul anilor 60, calculatoarele au început să fie folosite din ce în ce mai mult pentru procesarea informațiilor text, iar acum majoritatea computerelor personale din lume (și de cele mai multe ori) sunt ocupate cu procesarea informațiilor text.
În mod tradițional, pentru codificarea unui singur caracter, se utilizează o cantitate de informații egală cu 1 octet, adică I \u003d 1 octet \u003d 8 biți.
Pentru a codifica un caracter, este necesar un octet de informație.
Dacă considerăm simbolurile ca evenimente posibile, atunci conform formulei (2.1), putem calcula câte simboluri diferite pot fi codificate:
N \u003d 2 I \u003d 2 8 \u003d 256.
Un astfel de număr de caractere este suficient pentru a reprezenta informații textuale, inclusiv litere mari și minuscule ale alfabetelor ruse și latine, numere, semne, simboluri grafice etc.
Codarea constă în faptul că fiecărui personaj i se atribuie un cod zecimal unic de la 0 la 255 sau codul său binar corespunzător de la 00000000 la 11111111. Astfel, o persoană distinge caracterele după stilurile lor, iar computerul - după codurile sale.
Când informațiile text sunt introduse într-un computer, acestea sunt codate binar, imaginea personajului este convertită în codul său binar. Utilizatorul apasă o tastă cu un simbol pe tastatură și o anumită secvență de opt impulsuri electrice (cod simbol binar) intră în computer. Codul de caractere este stocat în memoria RAM a computerului, unde ocupă un octet.
În procesul de afișare a unui simbol pe ecranul computerului, se efectuează procesul invers - decodare, adică conversia codului simbolului în imaginea sa.
Este important să atribuiți un cod specific unui simbol este o problemă de acord, care este fixată în tabelul de coduri. Primele 33 de coduri (de la 0 la 32) corespund nu cu caractere, ci cu operațiuni (feed line, introducere spațiu și așa mai departe).
Codurile 33 până la 127 sunt internaționale și corespund caracterelor alfabetului latin, numere, semne ale operațiilor aritmetice și semne de punctuație.
Codurile 128 - 255 sunt naționale, adică în codificări naționale, simboluri diferite corespund aceluiași cod. Din păcate, în prezent, există cinci tabele de cod diferite pentru litere rusești (KOI8, CP1251, CP866, Mac, ISO - Tabelul 1.3), astfel încât textele create într-o codificare nu vor fi afișate corect în alta.
În prezent, noul standard internațional Unicode este larg răspândit, care alocă nu un octet, ci două pentru fiecare caracter, deci cu ajutorul său puteți codifica nu 256 de caractere, dar N \u003d 216 \u003d \u003d 65536 caractere diferite. Această codificare este acceptată de cele mai recente versiuni ale platformei Microsoft Windows & Office (din 1997).
Fiecare codificare este setată de propria sa tabelă de coduri. După cum se poate observa din tabel. 1.3, simboluri diferite sunt atribuite aceluiași cod binar în codificări diferite.
De exemplu, o secvență de coduri numerice 221, 194, 204 în codificarea CP1251 formează cuvântul "computer", în timp ce în alte codări va fi un set de caractere fără sens.
Din fericire, în majoritatea cazurilor, utilizatorul nu trebuie să se preocupe de transcodarea documentelor text, deoarece acest lucru este realizat prin programe speciale de convertor încorporate în aplicații.
Definiția unui cod de caractere numerice
1. Lansați editorul de text MS Word 2002. Introduceți comanda [Insert-Symbol ...]. Pe ecran va apărea o casetă de dialog. simbol. Centrul casetei de dialog este tabelul de caractere pentru un anumit font (de exemplu, Times New Roman).
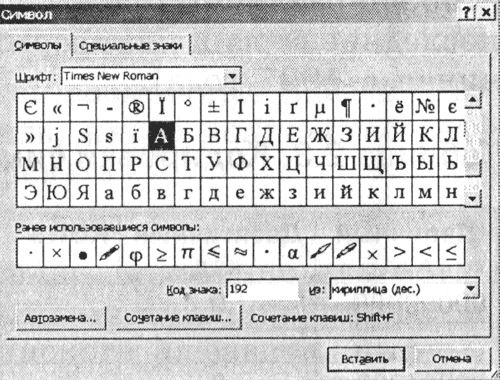 |
Simbolurile sunt aranjate secvențial de la stânga la dreapta și linie cu linie, începând cu simbolul decalaj în colțul din stânga sus și se termină cu litera „I” în colțul din dreapta jos al tabelului.
Selectați un personaj și din lista derulantă de la: tipul de codificare. În caseta de text Codul semnului: va apărea codul său numeric.
Introducerea caracterelor prin cod numeric
1. Rulați programul standard caiet. Folosind tastatura numerică opțională, țineți apăsată tasta (Alt), introduceți numărul 0224, eliberați tasta (Alt). Un document apare în document. Repetați procedura pentru codurile numerice de la 0225 la 0233. Documentul va afișa o secvență de 12 caractere pentru „securitate la domiciliu” în codarea Windows (CP1251).
2. Folosind tastatura numerică opțională în timp ce apăsați tasta (Alt), introduceți numărul 224, simbolul „p” va apărea în document. Repetați procedura pentru codurile numerice de la 225 la 233, documentul va afișa o secvență de 12 caractere „rstuhtschshshsh” în codificarea MS-DOS (CP866).
 |
Exerciții practice
1,29. Folosind un tabel de caractere (MS Word), notează o secvență de coduri numerice zecimale în codarea Windows (CP1251) pentru cuvântul „computer”.
1.30. Utilizând Notepad, determinați ce cuvânt din codificarea Windows (CP1251) este dat de o succesiune de coduri numerice: 225, 224, 233.242.
1.31. Ce secvență de litere vor corespunde codarea KOI8 și ISO cu cuvântul „computer” înregistrat în codificarea CP1251?
Calculatorul procesează o cantitate mare de informații. Fișiere audio, imagini, texte - toate acestea trebuie reproduse sau afișate. De ce codarea binară este o metodă universală de programare a informațiilor pentru orice echipament tehnic?
Care este diferența dintre criptare și criptare?
Adesea, oamenii identifică conceptele de „codificare” și „criptare” atunci când de fapt au semnificații diferite. Deci, criptarea este procesul de conversie a informațiilor pentru a le ascunde. Persoana care a schimbat textul, sau persoane special instruite, poate descifra adesea. Codificarea este utilizată pentru a prelucra informațiile și a simplifica colaborarea cu aceasta. De obicei, se folosește o tabelă de codificare comună, care este familiară tuturor. Este încorporat în computer.
Principiul codării binare
Codare binară bazat pe utilizarea a doar două caractere - 0 și 1 - pentru a procesa informațiile utilizate de diferite dispozitive. Aceste semne au fost numite cifre binare, în engleză - cifră binară sau bit. Fiecare personaj ocupă 1 bit de memorie computer. De ce codarea binară este o metodă universală de procesare a informațiilor? Cert este că pentru computer este mai ușor să proceseze mai puține caractere. Productivitatea PC-ului depinde în mod direct de aceasta: cu cât sarcinile mai puțin funcționale trebuie să îndeplinească dispozitivul, cu atât este mai mare viteza și calitatea muncii. 
Principiul codificării binare nu se găsește numai în programare. Prin alternarea batailor de tambur surd și sonor, locuitorii Polinezi și-au transmis informații reciproc. Un principiu similar se aplică atunci când sunetele lungi și scurte sunt utilizate pentru a transmite un mesaj. „Alfabetul telegrafic” este folosit astăzi.
Unde se utilizează codarea binară?
Binarul în computer este folosit peste tot. Fiecare fișier, fie el muzică sau text, trebuie să fie programat, astfel încât ulterior să poată fi procesat și citit cu ușurință. Sistemul de codare binar este util pentru lucrul cu simboluri și numere, fișiere audio, grafică.
Codarea numerelor binare
Acum, în calculatoare, numerele sunt prezentate în formă codificată, de neînțeles pentru persoana obișnuită. Utilizarea cifrelor arabe, așa cum ne imaginăm că este irațional pentru tehnologie. Motivul pentru aceasta este nevoia de a atribui un caracter unic fiecărui număr, care este uneori imposibil de făcut.

Există două sisteme numerice: pozițională și non-pozițională. Sistemul non-pozițional se bazează pe utilizarea literelor latine și ne este familiar în formă. Această metodă de înregistrare este destul de dificil de înțeles, așa că au abandonat-o.
Sistemul numeric pozițional este folosit astăzi. Aceasta include codarea binară, zecimală, octală și chiar hexadecimală a informațiilor.
Folosim sistemul de codare zecimal în viața de zi cu zi. Acestea ne sunt familiare, care sunt inteligibile pentru fiecare persoană. Codarea binară a numerelor diferă folosind doar zero și unul.
Numerele întregi sunt transformate într-un sistem de codare binar, împărțindu-le la 2. Coeficienții rezultați sunt de asemenea etapizați cu 2 până la obținerea unui număr de 0 sau 1. De exemplu, numărul 123 10 dintr-un sistem binar poate fi reprezentat ca 1111011 2. Și numărul 20 10 va arăta ca 10100 2.
Indicii 10 și 2 sunt desemnați, respectiv, sistem de codare a numerelor zecimale și binare. Simbolul de codare binară este utilizat pentru a simplifica lucrul cu valori reprezentate în sisteme numerice diferite.
Metodele de programare zecimale se bazează pe un punct flotant. Pentru a traduce corect valoarea de la zecimal la sistemul de codare binar, folosiți formula N \u003d M x qp. M este mantisa (o expresie a unui număr fără nicio ordine), p este ordinea valorii lui N, iar q este baza sistemului de codare (în cazul nostru 2).
Nu toate numerele sunt pozitive. Pentru a distinge numerele pozitive și cele negative, computerul lasă un spațiu de 1 bit pentru codificarea caracterelor. Aici, zero reprezintă semnul plus, iar unul reprezintă semnul minus.
Utilizarea unui astfel de sistem de numere face ușor pentru un computer să lucreze cu numere. Acesta este motivul pentru care codificarea binară este universală în procesele de calcul.

Codarea textului binar
Fiecare caracter al alfabetului este codat de propriul set de zerouri și de unii. Textul este format din caractere diferite: litere (minuscule și minuscule), caractere aritmetice și alte semnificații diverse. Codificarea informațiilor textuale necesită utilizarea a 8 valori binare consecutive de la 00000000 la 11111111. În acest fel, 256 de caractere diferite pot fi convertite.
Pentru a evita confuzia în codarea textului, se utilizează tabele de valori speciale pentru fiecare caracter. Au alfabetul latin, semne aritmetice și semne speciale (de exemplu, €, ¥ și altele). Caracterele Gap 128-255 codifică alfabetul național al țării.
Pentru a codifica 1 caracter, sunt necesare 8 biți de memorie. Pentru a simplifica subconturile, 8 biți sunt egali cu 1 octet, astfel încât spațiul total pe disc pentru informațiile textului este măsurat în octeți.

Majoritatea computerelor personale au un tabel standard. codificări ASCII (Codul standard american pentru schimbul de informații). De asemenea, sunt utilizate alte tabele în care sistemul de codificare a textului este diferit. De exemplu, prima codificare de caractere cunoscută se numește KOI-8 (un cod de schimb de informații pe 8 biți) și funcționează pe computere care rulează UNIX. Tabelul de cod CP1251, care a fost creat pentru sistemul de operare Windows, este de asemenea găsit pe scară largă.
Codare sonoră binară
Un alt motiv pentru care codarea binară este o metodă universală de programare a informațiilor este simplitatea ei atunci când lucrați cu fișiere audio. Orice muzică este undă sonoră cu amplitudine și frecvență diferită. Volumul sunetului și tonul acestuia depind de acești parametri.
Pentru a programa o undă sonoră, computerul o împarte condiționat în mai multe părți sau „mostre”. Numărul de astfel de eșantioane poate fi mare, deci există 65.536 de combinații diferite de zerouri și altele. În consecință, calculatoarele moderne sunt echipate cu plăci de sunet pe 16 biți, ceea ce înseamnă utilizarea 16 cifre binare pentru a codifica un eșantion al undei sonore.
Pentru a reda un fișier audio, computerul procesează secvențele de coduri binare programate și le combină într-o undă continuă. 
Codificare grafică
Informațiile grafice pot fi prezentate sub formă de desene, diagrame, imagini sau diapozitive în PowerPoint. Orice imagine constă din puncte mici - pixeli, care pot fi pictate în culori diferite. Culoarea fiecărui pixel este codată și salvată și, în consecință, obținem o imagine deplină.
Dacă imaginea este alb-negru, codul pentru fiecare pixel poate fi unul sau zero. Dacă se folosesc 4 culori, codul fiecăreia dintre ele este format din două cifre: 00, 01, 10 sau 11. Prin acest principiu se distinge calitatea procesării oricărei imagini. Creșterea sau micșorarea luminozității afectează și numărul de culori utilizate. În cel mai bun caz, computerul distinge aproximativ 16.777.216 nuanțe.

concluzie
Există diferite metode de programare a informațiilor, dintre care cea mai eficientă este codarea binară. Cu doar două caractere - 1 și 0 - computerul citește cu ușurință majoritatea fișierelor. În același timp, viteza de procesare este mult mai mare decât, de exemplu, ar fi utilizat un sistem de programare zecimal. Simplitatea acestei metode o face indispensabilă pentru orice tehnică. Acesta este motivul pentru care codificarea binară este universală printre colegii săi.
Toată lumea știe că calculatoarele pot efectua calcule cu grupuri mari de date cu viteză extraordinară. Dar nu toată lumea știe că aceste acțiuni depind doar de două condiții: dacă există sau nu curent și ce tensiune.
Cum reușește un computer să proceseze informații atât de diverse?
Secretul constă în sistemul binar. Toate datele intră în computer, prezentate sub formă de unități și zerouri, fiecare corespunzând unei stări a cablului electric: unități - tensiune înaltă, zerouri - scăzute sau unități - prezența tensiunii, zerourilor - absența acesteia. Convertirea datelor în zeruri și altele se numește conversie binară, iar denumirea finală se numește cod binar.
Într-o notație zecimală bazată pe sistemul zecimal de calcul care este utilizat în viața de zi cu zi, valoarea numerică este reprezentată de zece cifre de la 0 la 9, iar fiecare loc din număr are o valoare de zece ori mai mare decât locul din dreapta acestuia. Pentru a reprezenta un număr mai mare de nouă în sistemul zecimal, zero este pus la locul său și unul este plasat pe următorul, mai valoros în stânga. În mod similar, în sistemul binar, unde sunt utilizate doar două cifre - 0 și 1, fiecare loc este de două ori mai valoros decât locul din dreapta acestuia. Astfel, în codul binar, doar zero și unul pot fi reprezentate ca numere unice, iar orice număr mai mare decât unul necesită două locuri. După zero și unu, următoarele trei numere binare sunt 10 (citiți unu-zero) și 11 (citiți unu-unu) și 100 (citiți unu-zero-zero). 100 de sisteme binare sunt echivalente cu 4 zecimale. Tabelul superior din dreapta prezintă alte echivalente binare zecimale.
Orice număr poate fi exprimat în mod binar, ocupă doar mai mult spațiu decât în \u200b\u200bnotație zecimală. În sistemul binar, puteți scrie și alfabetul, dacă fiecărei litere i se atribuie un număr binar specific.
Două cifre pentru patru locuri
16 combinații pot fi realizate folosind bile întunecate și luminoase, combinându-le în seturi de patru. Dacă luați bile întunecate ca zero și luminoase ca unități, atunci 16 seturi se vor dovedi a fi un cod binar de 16 unități, a căror valoare numerică este de la zero la cinci ( vezi tabelul de sus la pagina 27). Chiar și cu două tipuri de bile în sistemul binar, puteți construi un număr infinit de combinații prin simpla creștere a numărului de bile din fiecare grup - sau a numărului de locuri în numere.
Bits și octeți
Cea mai mică unitate în procesarea computerului, un bit este o unitate de date care poate avea una dintre cele două condiții posibile. De exemplu, fiecare dintre cele și zerourile (din dreapta) înseamnă 1 bit. Bitul poate fi reprezentat în alte moduri: prezența sau absența unui curent electric, o gaură și absența acestuia, direcția de magnetizare spre dreapta sau spre stânga. Opt biți alcătuiesc un octet. 256 octeți posibile pot reprezenta 256 de caractere și caractere. Multe computere procesează octeți de date în același timp.
Conversie binară Un cod binar format din patru cifre poate reprezenta numere zecimale de la 0 la 15.
Tabele de cod
Când un cod binar este utilizat pentru a indica literele alfabetului sau semnele de punctuație, sunt necesare tabele de cod care indică care cod se potrivește cu caracterul respectiv. Mai multe astfel de coduri au fost compilate. Majoritatea computerelor sunt adaptate pentru un cod de șapte cifre numit ASCII sau codul standard american pentru schimbul de informații. Tabelul din dreapta arată coduri ASCII pentru alfabetul englez. Alte coduri sunt destinate mii de caractere și alfabeturi din alte limbi ale lumii.

Parte a tabelului de cod ASCII

