24.07.2019
पाठ जानकारी एन्कोडिंग। बाइनरी कोडिंग यूनिवर्सल क्यों है? प्रोग्रामिंग के तरीके
आइए देखें कि सभी समान कैसे हैं ग्रंथों को डिजिटाइज़ करें? वैसे, हमारी साइट पर आप किसी भी पाठ को दशमलव, हेक्साडेसिमल में अनुवाद कर सकते हैं, बाइनरी कोड ऑनलाइन कोड कैलकुलेटर का उपयोग करना।
पाठ एन्कोडिंग।
कंप्यूटर सिद्धांत के अनुसार, किसी भी पाठ में अलग-अलग वर्ण होते हैं। इन वर्णों में शामिल हैं: अक्षर, संख्या, लोअरकेस विराम चिह्न, विशेष वर्ण ("", नहीं, (), आदि), वे शब्दों के बीच रिक्त स्थान भी शामिल करते हैं।
आवश्यक ज्ञान। जिन वर्णों के साथ मैं पाठ लिखता हूँ, उन्हें ALFAVIT कहा जाता है।
वर्णमाला में लिए गए वर्णों की संख्या इसकी शक्ति को दर्शाती है।
जानकारी की मात्रा सूत्र द्वारा निर्धारित की जा सकती है: एन \u003d 2 बी
- एन एक ही शक्ति (कई अक्षर) है,
- बी - बिट (लिया चरित्र का वजन)।
वर्णमाला जिसमें 256 होंगे, लगभग सभी आवश्यक वर्णों को समायोजित कर सकते हैं। इस तरह के अक्षर को SUFFICIENT कहा जाता है।
यदि हम वर्णमाला को 256 की क्षमता के साथ लेते हैं, और ध्यान रखें कि 256 \u003d 28
- 8 बिट्स को हमेशा 1 बाइट कहा जाता है:
- 1 बाइट \u003d 8 बिट्स।
यदि आप प्रत्येक वर्ण को बाइनरी कोड में अनुवाद करते हैं, तो कंप्यूटर टेक्स्ट का यह कोड 1 बाइट पर कब्जा कर लेगा।
कंप्यूटर मेमोरी में टेक्स्ट की जानकारी कैसे दिख सकती है?
किसी भी टेक्स्ट को कीबोर्ड पर टाइप किया जाता है, कीबोर्ड कीज़ पर, हम हमें (संख्या, अक्षर आदि) से परिचित संकेत देखते हैं। वे केवल बाइनरी कोड के रूप में कंप्यूटर की रैम में प्रवेश करते हैं। प्रत्येक वर्ण का बाइनरी कोड आठ अंकों की संख्या जैसा दिखता है, उदाहरण के लिए 00111111।
चूंकि बाइट मेमोरी का सबसे छोटा पता योग्य कण है, और मेमोरी को प्रत्येक वर्ण को अलग से संबोधित किया जाता है, ऐसे एन्कोडिंग की सुविधा स्पष्ट है। हालांकि, किसी भी वर्ण की जानकारी के लिए 256 वर्ण बहुत सुविधाजनक राशि है।
स्वाभाविक रूप से, सवाल उठता है: जो विशेष रूप से आठ बिट कोड हर पात्र का है? और टेक्स्ट को डिजिटल कोड में कैसे ट्रांसलेट करें?
यह प्रक्रिया सशर्त है, और हमें विभिन्न के साथ आने का अधिकार है चरित्र एन्कोडिंग के लिए तरीके। वर्णमाला के प्रत्येक प्रतीक में 0 से 255 तक की संख्या होती है। और प्रत्येक संख्या को 00000000 से 11111111 तक का कोड दिया जाता है।
एन्कोडिंग के लिए तालिका एक "धोखा शीट" है, जो सीरियल नंबर के अनुसार वर्णमाला के पात्रों को इंगित करता है। विभिन्न प्रकार के कंप्यूटर के लिए एन्कोडिंग के लिए विभिन्न तालिकाओं का उपयोग करें।
ASCII (या असुका) व्यक्तिगत कंप्यूटरों के लिए अंतर्राष्ट्रीय मानक बन गया है। तालिका के दो भाग हैं।
ASCII तालिका के लिए पहली छमाही। (यह पहली छमाही थी जो मानक बन गई।)
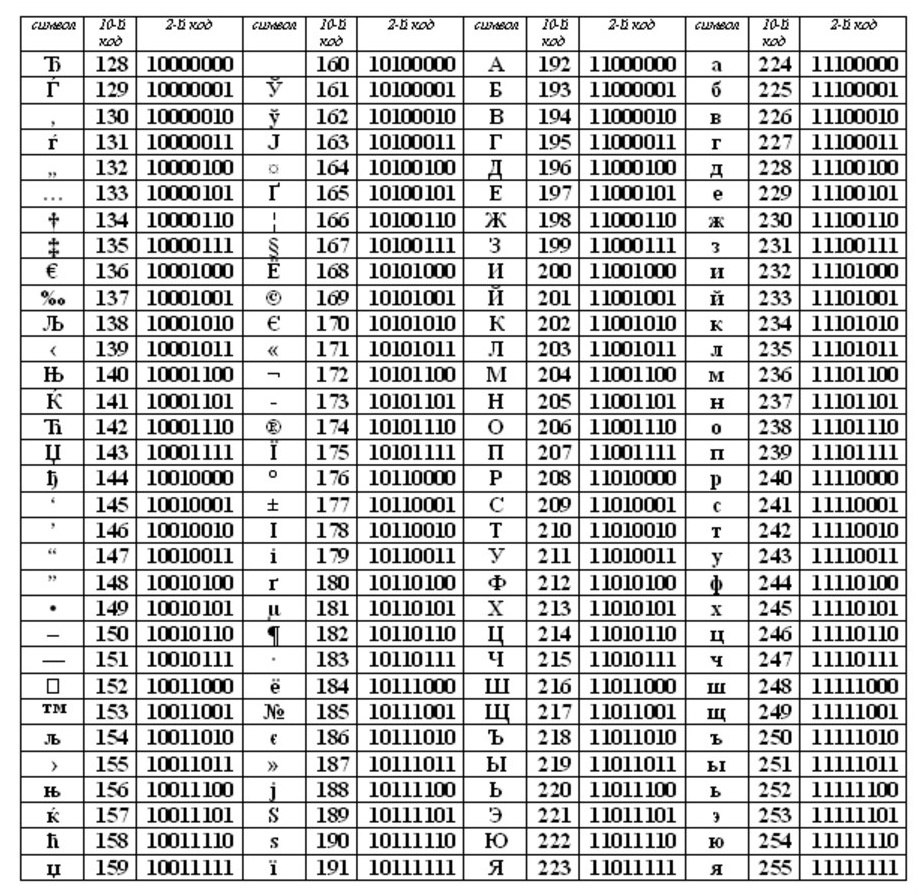
लेक्सिकोग्राफिक ऑर्डर का अनुपालन, अर्थात, तालिका में अक्षर (लोअरकेस और अपरकेस) को सख्त वर्णमाला क्रम में दर्शाया गया है, और आरोही क्रम में संख्याओं को वर्णमाला के अनुक्रमिक कोडिंग के सिद्धांत कहा जाता है।
रूसी वर्णमाला के लिए भी अनुपालन करें अनुक्रमिक कोडिंग सिद्धांत.
अब, आजकल वे पूरे उपयोग करते हैं पाँच एन्कोडिंग सिस्टम रूसी वर्णमाला (KOI8-P, Windows। MS-DOS, Macintosh और ISO)। एन्कोडिंग सिस्टम की संख्या और एक मानक की कमी के कारण, बहुत बार गलतफहमी रूसी टेक्स्ट को उसके कंप्यूटर रूप में स्थानांतरित करने के साथ उत्पन्न होती है।
पहले में से एक रूसी वर्णमाला कोडिंग के लिए मानकऔर व्यक्तिगत कंप्यूटर पर KOI8 ("सूचना विनिमय कोड, 8-बिट") पर विचार करें। इस एन्कोडिंग का उपयोग सत्तर के दशक में ईसी कंप्यूटरों की एक श्रृंखला पर किया जाता था, और अस्सी के दशक के मध्य से, इसका उपयोग रूसी में अनुवादित पहले UNIX ऑपरेटिंग सिस्टम में किया जाने लगा।
नब्बे के दशक की शुरुआत के बाद से, तथाकथित समय जब एमएस डॉस ऑपरेटिंग सिस्टम का बोलबाला था, CP866 कोडिंग सिस्टम प्रकट होता है ("सीपी" का अर्थ "कोड पेज", "कोड पृष्ठ") है।
अपने नियंत्रण (मैक ओएस) के तहत अभिनव प्रणाली के साथ, कंप्यूटर विशाल APPLE, MAC वर्णमाला को एनकोड करने के लिए अपनी प्रणाली का उपयोग करना शुरू कर रहा है।
अंतर्राष्ट्रीय मानक संगठन (आईएसओ) रूसी भाषा के लिए एक और मानक निर्धारित करता है वर्णमाला कोडिंग प्रणालीआईएसओ 8859-5 कहा जाता है।
और सबसे आम, आज, माइक्रोसॉफ्ट विंडोज में आविष्कार किए गए वर्णमाला को कोड करने के लिए एक प्रणाली है, और इसे सीपी 1251 कहा जाता है।
नब्बे के दशक के उत्तरार्ध के बाद से, रूसी भाषा के लिए डिजिटल कोड में पाठ का अनुवाद करने के लिए मानक की समस्या और न केवल यूनिकोड नामक एक प्रणाली को मानक में पेश करने से हल किया गया था। यह सोलह-बिट एन्कोडिंग द्वारा दर्शाया गया है, जिसका अर्थ है कि वास्तव में प्रत्येक वर्ण के लिए दो बाइट्स रैम आवंटित किए जाते हैं। बेशक, इस एन्कोडिंग के साथ, मेमोरी की लागत दोगुनी हो जाती है। हालांकि, इस तरह की एक कोड प्रणाली 65536 वर्णों को इलेक्ट्रॉनिक कोड में बदलने की अनुमति देती है।
मानक यूनिकोड प्रणाली की बारीकियों को किसी भी वर्णमाला में शामिल किया जाना मौजूदा, विलुप्त, बना-बनाया होना है। अंत में, बिल्कुल किसी भी वर्णमाला, इसके अलावा, यूनिकोड प्रणाली में बहुत सारे गणितीय, रासायनिक, संगीत और सामान्य प्रतीक शामिल हैं।
आइए ASCII तालिका का उपयोग करके देखें कि आपके कंप्यूटर की मेमोरी में कोई शब्द कैसा दिख सकता है।
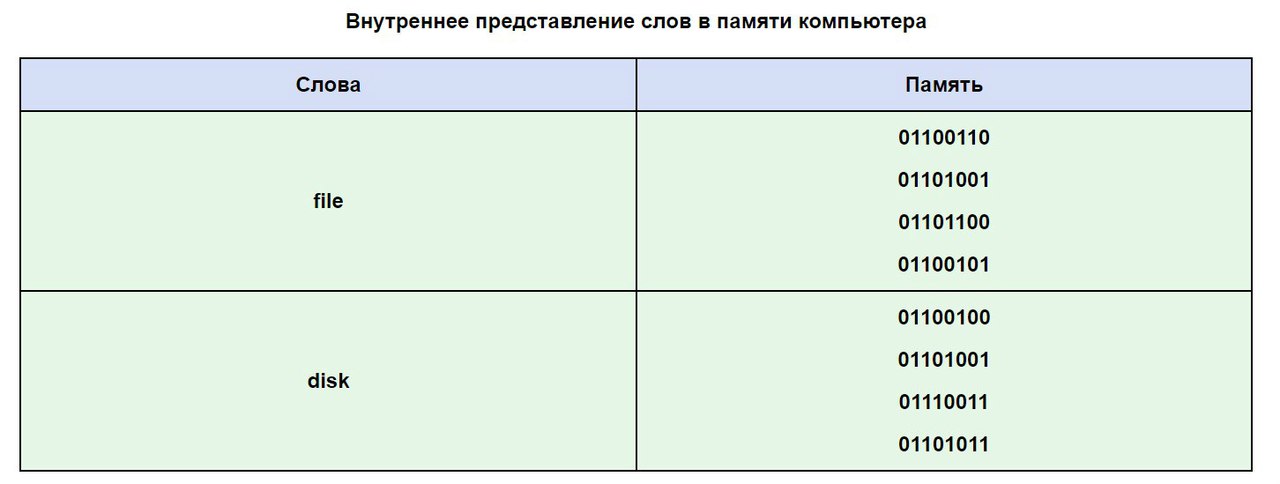
अक्सर ऐसा होता है कि आपका पाठ, जो रूसी वर्णमाला के अक्षरों में लिखा गया है, पठनीय नहीं है, यह कंप्यूटर पर वर्णमाला के कोडिंग सिस्टम में अंतर के कारण है। यह एक बहुत ही आम समस्या है जिसका अक्सर पता लगाया जाता है।
सूचना की न्यूनतम इकाइयाँ बिट्स और बाइट्स हैं।
एक बिट आपको सांकेतिक शब्दों में बदलना करने की अनुमति देता है 2 मान (0 या 1)।
का उपयोग करते हुए दो बिट्स एन्कोड किया जा सकता है 4 मान: 00, 01, 10, 11।
तीन बिट्स एन्कोडेड हैं 8 विभिन्न मूल्य: 000, 001, 010, 011, 100, 101, 110, 111।
यह उपरोक्त उदाहरणों से देखा जा सकता है कि एक बिट जोड़ने से उन मानों की संख्या दोगुनी हो सकती है जिन्हें एन्कोड किया जा सकता है:
1 बिट एन्कोड -\u003e 2 अलग-अलग मान (2 1 \u003d 2),
2 बिट्स एनकोड -\u003e 4 अलग-अलग मान (2 2 \u003d 4),
3 बिट्स एनकोड -\u003e 8 अलग-अलग मान (2 3 \u003d 8),
4 बिट्स एनकोड -\u003e 16 अलग-अलग मान (2 4 \u003d 16),
5 बिट्स एनकोड -\u003e 32 विभिन्न मूल्य (2 5 \u003d 32),
6 बिट्स सांकेतिक शब्दों में बदलना -\u003e 64 विभिन्न मूल्य (2 6 \u003d 64),
7 बिट्स एनकोड -\u003e 128 विभिन्न मूल्य (2 7 \u003d 128),
8 बिट्स एनकोड -\u003e 256 विभिन्न मान (2 8 \u003d 256),
9 बिट्स एनकोड -\u003e 512 विभिन्न मूल्य (2 9 \u003d 512),
10 बिट एन्कोड -\u003e 1024 अलग-अलग मान (2 10 \u003d 1024)।
हमें याद है कि एक बाइट में, 9 या 10 बिट नहीं, बल्कि केवल 8. इसलिए, एक बाइट का उपयोग करके, आप 256 विभिन्न वर्णों को एन्कोड कर सकते हैं। क्या आपको लगता है कि यह बहुत कम है या थोड़ा है? आइए कोडिंग का एक उदाहरण देखें पाठ संबंधी जानकारी.
रूसी में 33 पत्र हैं और इसलिए, उनके एन्कोडिंग के लिए 33 बाइट्स की आवश्यकता होती है। कंप्यूटर बड़े (अपरकेस) और छोटे (लोअरकेस) अक्षरों के बीच अंतर करता है, केवल अगर वे विभिन्न कोड के साथ एन्कोड किए गए हों। तो, रूसी वर्णमाला के बड़े और छोटे अक्षरों को एन्कोड करने के लिए, 66 बाइट्स की आवश्यकता होती है।
अंग्रेजी वर्णमाला के पूंजी और छोटे अक्षरों के लिए, अन्य 52 बाइट्स की आवश्यकता होती है। परिणाम 66 + 52 \u003d 118 बाइट्स है। यहां आपको संख्याओं (0 से 9 तक), एक अंतरिक्ष वर्ण, सभी विराम चिह्न: डॉट, अल्पविराम, डैश, विस्मयादिबोधक और प्रश्न चिह्न, कोष्ठक: गोल, घुंघराले और वर्गाकार, और साथ ही गणितीय संक्रियाओं के संकेत भी जोड़ने होंगे: + +, -, -, \u003d, / (यह विभाजन है), * (यह गुणा है)। हम विशेष वर्ण भी जोड़ते हैं:%, $, &, @, #, नहीं, आदि। यह सब एक साथ लिया गया है लगभग 256 विभिन्न वर्ण हैं।
और फिर मामला छोटे पर छोड़ दिया गया। यह सुनिश्चित करना आवश्यक है कि पृथ्वी पर सभी लोग आपस में सहमत हैं कि कौन से विशेष कोड (0 से 255 तक, यानी, कुल 256) प्रतीकों को निर्दिष्ट करने के लिए। मान लीजिए कि सभी लोग इस बात से सहमत हैं कि कोड 33 का अर्थ है विस्मयादिबोधक बिंदु (!), और कोड 63 का अर्थ है प्रश्न चिह्न (?)। और सभी लागू वर्णों के लिए भी। तब इसका मतलब यह होगा कि एक व्यक्ति द्वारा अपने कंप्यूटर पर टाइप किया गया पाठ हमेशा दूसरे व्यक्ति द्वारा दूसरे कंप्यूटर पर पढ़ा और मुद्रित किया जा सकता है।
ASCII तालिका
किसी चीज़ के समान उपयोग पर इस तरह के एक सार्वभौमिक समझौते को कहा जाता है मानक। हमारे मामले में, मानक एक तालिका होनी चाहिए जिसमें कोड का पत्राचार (0 से 255 तक) और वर्ण तय हो। एक समान तालिका कहा जाता है एन्कोडिंग तालिका।
लेकिन इतना सरल नहीं है। आखिरकार, जो अक्षर अच्छे हैं, उदाहरण के लिए, ग्रीस के लिए, तुर्की के लिए काम नहीं करेगा क्योंकि अन्य अक्षर वहां उपयोग किए जाते हैं। इसी तरह, संयुक्त राज्य अमेरिका के लिए जो अच्छा है वह रूस के लिए उपयुक्त नहीं है, और जो रूस के लिए अच्छा है वह जर्मनी के लिए उपयुक्त नहीं है।
इसलिए, उन्होंने कोड तालिका को आधे में विभाजित करने का फैसला किया।
पहले 128 कोड (0 से 127 तक) सभी देशों के लिए और सभी कंप्यूटरों के लिए मानक और अनिवार्य होने चाहिए, यह है - अंतरराष्ट्रीयमानक।
और कोड तालिका (128 से 255 तक) की दूसरी छमाही के साथ, प्रत्येक देश कुछ भी कर सकता है, और इस आधे में अपना मानक बना सकता है - राष्ट्रीय.
कोड तालिका का पहला (अंतरराष्ट्रीय) आधा भाग कहा जाता है एक मेजASCII, जो संयुक्त राज्य अमेरिका में बनाया गया था और पूरी दुनिया में स्वीकार किया गया था। कोड तालिका के दूसरे भाग के लिए ASCII मानक जिम्मेदार नहीं है। विभिन्न देश यहां अपनी राष्ट्रीय कोड टेबल बनाते हैं। यह भी हो सकता है कि एक देश के भीतर अलग-अलग कंप्यूटर प्रणालियों के लिए अलग-अलग मानक हों, लेकिन केवल कोड तालिका के दूसरे भाग के भीतर।
अंतर्राष्ट्रीय ASCII तालिका से कोड
0-31 - विशेष वर्ण जो स्क्रीन पर या प्रिंटर पर मुद्रित नहीं होते हैं, लेकिन विशेष कार्यों को करने के लिए उपयोग किए जाते हैं (उदाहरण के लिए, "कैरिज ट्रांसफर" - पाठ को एक नई पंक्ति में ले जाने के लिए, या "टैब" के लिए - कर्सर को एक लाइन में विशेष पदों पर सेट करने के लिए। पाठ, आदि)।
32 - स्थान (शब्दों के बीच विभाजक भी एन्कोड किया जाने वाला एक वर्ण है, हालाँकि इसे शब्दों और वर्णों के बीच "रिक्त स्थान" के रूप में प्रदर्शित किया जाता है),
33-47 - विशेष वर्ण (कोष्ठक, आदि) और विराम चिह्न (अवधि, अल्पविराम, आदि)।
48-57 - संख्या 0 से 9 तक,
58-64 - गणितीय प्रतीक (प्लस (+), माइनस (-), गुणा (*), डिवाइड (/), आदि) और विराम चिह्न (कोलन, सेमीकोलन, आदि), आदि।
65-90 - अपरकेस (लोअरकेस) अंग्रेजी अक्षर,
91-96 - विशेष वर्ण (वर्ग कोष्ठक, आदि),
97-122 - छोटे (निचले) अंग्रेजी अक्षर,
123-127 - विशेष वर्ण (घुंघराले ब्रेसिज़, आदि)।
ASCII तालिका के बाहर, 128 से 159 की संख्या के साथ शुरू, रूसी अक्षरों में बड़े अक्षर हैं, और 160 से 170 और 224 से 239 तक, छोटे (लोअरकेस) रूसी पत्र हैं।
शांति शब्द एन्कोडिंग
दिखाए गए एन्कोडिंग का उपयोग करके, हम कल्पना कर सकते हैं कि कंप्यूटर कैसे एनकोड करता है और फिर पुन: पेश करता है, उदाहरण के लिए, MIR शब्द (बड़े अक्षरों में)। यह शब्द तीन संहिताओं द्वारा दर्शाया गया है: एम अक्षर कोड 140 (राष्ट्रीय रूसी कोडिंग प्रणाली के अनुसार) से मेल खाता है, और - यह कोड 136 है और पी - यह 144 है।
लेकिन जैसा कि पहले उल्लेख किया गया है, कंप्यूटर केवल द्विआधारी रूप में जानकारी मानता है, अर्थात। शून्य और लोगों के अनुक्रम के रूप में। MIR शब्द के प्रत्येक अक्षर के अनुरूप प्रत्येक बाइट में आठ शून्य और एक क्रम होता है। दशमलव जानकारी को बाइनरी में परिवर्तित करने के नियमों का उपयोग करते हुए, आप उनके बाइनरी समकक्षों के साथ पत्र कोड के दशमलव मूल्यों को बदल सकते हैं।
दशमलव अंक 140 द्विआधारी संख्या 10001100 से मेल खाता है। यह जाँच की जा सकती है यदि निम्न गणनाएँ की जाती हैं: 2 7 + 2 3 +2 2 \u003d 140। प्रत्येक "दो" को जिस सीमा तक उठाया जाता है वह बाइनरी संख्या 100100100 की स्थिति संख्या है, जिसमें "1" है। », और स्थिति को दायें से बायें, शून्य स्थिति संख्या से शुरू किया जाता है: 0, 1, 2, आदि।
आप एक संख्या प्रणाली से दूसरे नंबर पर स्थानांतरण के बारे में अधिक जान सकते हैं, उदाहरण के लिए, कंप्यूटर विज्ञान की पाठ्यपुस्तकों से या इंटरनेट के माध्यम से।
इसी तरह, आप यह सत्यापित कर सकते हैं कि अंक 136 द्विआधारी संख्या 10001000 (चेक: 2 7 + 2 3 \u003d 136) से मेल खाती है। और संख्या 144 द्विआधारी संख्या 10010000 (जांच: 2 7 + 2 4 \u003d 144) से मेल खाती है।
इस प्रकार, कंप्यूटर में, MIR शब्द को शून्य और वालों (बिट्स) के निम्नलिखित अनुक्रम के रूप में संग्रहीत किया जाएगा: 10001100 10001000 10010000।
बेशक, ऊपर दिखाए गए सभी डेटा रूपांतरण कंप्यूटर प्रोग्राम का उपयोग करके किए जाते हैं, और वे उपयोगकर्ताओं को दिखाई नहीं देते हैं। वे केवल कीबोर्ड का उपयोग करके जानकारी दर्ज करते समय, और जब यह मॉनिटर स्क्रीन या प्रिंटर पर प्रदर्शित होता है, तो वे इन कार्यक्रमों के परिणामों का निरीक्षण करते हैं।
यह ध्यान दिया जाना चाहिए कि कंप्यूटर साक्षरता का अध्ययन करने के स्तर पर, कंप्यूटर उपयोगकर्ताओं को बाइनरी नंबर सिस्टम को जानने की आवश्यकता नहीं है। दशमलव वर्ण कोड का विचार होना पर्याप्त है। व्यवहार में केवल सिस्टम प्रोग्रामर बाइनरी, हेक्साडेसिमल, ऑक्टल और अन्य नंबर सिस्टम का उपयोग करते हैं। यह उनके लिए विशेष रूप से महत्वपूर्ण है जब कंप्यूटर सॉफ़्टवेयर में त्रुटि संदेश प्रदर्शित करते हैं जो दशमलव में रूपांतरण के बिना गलत मान दर्शाते हैं।
कंप्यूटर साक्षरता अभ्यासयह आपको स्वतंत्र रूप से वर्णित एन्कोडिंग सिस्टम को देखने और महसूस करने की अनुमति देता है जो लेख में दिए गए हैं
अनुलेख लेख खत्म हो गया है, लेकिन आप अभी भी पढ़ सकते हैं:
P.P.S.कि नए लेख प्राप्त करने के लिए सदस्यता लेंजो अभी ब्लॉग पर नहीं हैं:
1) इस रूप में अपना ई-मेल पता दर्ज करें।
बाइनरी टेक्स्ट एन्कोडिंग
60 के दशक के अंत से शुरू होकर, टेक्स्ट जानकारी को संसाधित करने के लिए कंप्यूटर का अधिक से अधिक उपयोग किया जाने लगा, और अब दुनिया के अधिकांश पर्सनल कंप्यूटर (और अधिकांश समय) टेक्स्ट सूचना के प्रसंस्करण के साथ व्याप्त हैं।
परंपरागत रूप से, किसी एकल वर्ण को कोड करने के लिए, 1 बाइट के बराबर जानकारी का उपयोग किया जाता है, अर्थात, I \u003d 1 बाइट \u003d 6 बिट्स।
एक चरित्र को एनकोड करने के लिए, सूचना की 1 बाइट की आवश्यकता होती है।
यदि हम प्रतीकों को संभावित घटनाओं के रूप में मानते हैं, तो सूत्र (2.1) के अनुसार, हम गणना कर सकते हैं कि कितने अलग-अलग प्रतीकों को एन्कोड किया जा सकता है:
एन \u003d 2 आई \u003d 2 8 \u003d 256।
इस तरह के कई अक्षर पाठ संबंधी जानकारी का प्रतिनिधित्व करने के लिए पर्याप्त हैं, जिनमें रूसी और लैटिन वर्णमाला के अपरकेस और लोअरकेस अक्षर, संख्याएं, संकेत, ग्राफिक प्रतीक आदि शामिल हैं।
कोडिंग में यह तथ्य शामिल है कि प्रत्येक वर्ण को 0 से 255 तक एक अद्वितीय दशमलव कोड दिया गया है या 00000000 से 11111111 तक संबंधित द्विआधारी कोड है। इस प्रकार, एक व्यक्ति अपनी शैलियों द्वारा वर्णों को अलग करता है, और कंप्यूटर अपने कोड द्वारा।
जब पाठ की जानकारी कंप्यूटर में दर्ज की जाती है, तो यह द्विआधारी एनकोडेड होता है, चरित्र की छवि इसके बाइनरी कोड में बदल जाती है। उपयोगकर्ता कीबोर्ड पर प्रतीक के साथ एक कुंजी दबाता है, और आठ विद्युत आवेगों (बाइनरी प्रतीक कोड) का एक निश्चित अनुक्रम कंप्यूटर में प्रवेश करता है। चरित्र कोड कंप्यूटर की रैम में संग्रहीत होता है, जहां यह एक बाइट पर कब्जा कर लेता है।
कंप्यूटर स्क्रीन पर एक प्रतीक प्रदर्शित करने की प्रक्रिया में, रिवर्स प्रक्रिया की जाती है - डिकोडिंग, अर्थात्, प्रतीक कोड का अपनी छवि में रूपांतरण।
यह महत्वपूर्ण है कि प्रतीक को एक विशिष्ट कोड असाइन करना समझौते का विषय है, जो कोड तालिका में तय किया गया है। पहले 33 कोड (0 से 32 तक) वर्णों के अनुरूप नहीं हैं, लेकिन संचालन (लाइन फीड, स्पेस इनपुट, और इसी तरह) के अनुरूप हैं।
127 के माध्यम से कोड 33 अंतरराष्ट्रीय हैं और लैटिन वर्णमाला, संख्या, अंकगणितीय संचालन के संकेत और विराम चिह्नों के अनुरूप हैं।
१२ से २५५ तक के कोड राष्ट्रीय हैं, यानी राष्ट्रीय एन्कोडिंग में, विभिन्न प्रतीक समान कोड के अनुरूप हैं। दुर्भाग्य से, वर्तमान में रूसी अक्षरों (KOI8, CP1251, CP866, Mac, ISO - तालिका 1.3) के लिए पांच अलग-अलग कोड टेबल हैं, इसलिए एक एन्कोडिंग में बनाए गए ग्रंथों को दूसरे में सही ढंग से प्रदर्शित नहीं किया जाएगा।
वर्तमान में, नया अंतर्राष्ट्रीय यूनिकोड मानक व्यापक है, जो प्रत्येक वर्ण के लिए एक बाइट नहीं, बल्कि दो को आवंटित करता है, इसलिए इसकी सहायता से 256 वर्णों को नहीं, बल्कि N \u003d 216 \u003d \u003d 65536 विभिन्न वर्णों को एनकोड करना संभव है। यह एन्कोडिंग Microsoft Windows और Office प्लेटफ़ॉर्म (1997 से) के नवीनतम संस्करणों द्वारा समर्थित है।
प्रत्येक एन्कोडिंग अपने स्वयं के कोड तालिका द्वारा निर्धारित की जाती है। जैसा कि टेबल से देखा जा सकता है। 1.3, अलग-अलग प्रतीकों में अलग-अलग प्रतीकों को एक ही बाइनरी कोड को सौंपा गया है।
उदाहरण के लिए, CP1251 एन्कोडिंग में संख्यात्मक कोड 221, 194, 204 का एक क्रम "कंप्यूटर" शब्द बनाता है, जबकि अन्य एन्कोडिंग में यह वर्णों का एक अर्थहीन सेट होगा।
सौभाग्य से, ज्यादातर मामलों में, उपयोगकर्ता को टेक्स्ट दस्तावेजों को ट्रांसकोडिंग के बारे में चिंता करने की ज़रूरत नहीं है, क्योंकि यह अनुप्रयोगों में निर्मित विशेष कनवर्टर कार्यक्रमों द्वारा किया जाता है।
एक संख्यात्मक चरित्र कोड की परिभाषा
1. टेक्स्ट एडिटर MS Word 2002 लॉन्च करें। कमांड डालें [Insert-Symbol ...]। स्क्रीन पर एक डायलॉग बॉक्स दिखाई देगा। प्रतीक। संवाद बॉक्स का केंद्र किसी विशेष फ़ॉन्ट के लिए वर्ण तालिका है (उदाहरण के लिए, टाइम्स न्यू रोमन)।
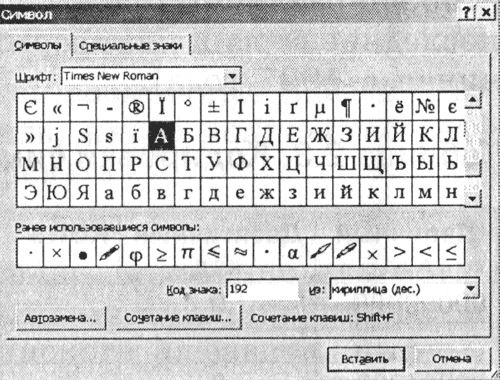 |
प्रतीकों को प्रतीक से शुरू करके, बाएं से दाएं और रेखा से क्रमिक रूप से व्यवस्थित किया जाता है अन्तर ऊपरी बाएं कोने में और तालिका के निचले दाएं कोने में "I" अक्षर के साथ समाप्त होता है।
एक चरित्र का चयन करें और ड्रॉप-डाउन सूची से से: एन्कोडिंग का प्रकार। पाठ बॉक्स में साइन कोड: इसका संख्यात्मक कोड दिखाई देगा।
संख्यात्मक कोड द्वारा वर्ण दर्ज करना
1. मानक कार्यक्रम चलाएँ नोटबुक। वैकल्पिक संख्यात्मक कीपैड का उपयोग करके, (Alt) कुंजी दबाए रखें, नंबर 0224 दर्ज करें, (Alt) कुंजी जारी करें। दस्तावेज़ में एक प्रतीक दिखाई देता है। 0225 से 0233 तक संख्यात्मक कोड के लिए प्रक्रिया को दोहराएं। दस्तावेज़ एन्कोडिंग विंडोज (CP1251) में "घर की सुरक्षा" के लिए 12 वर्णों का एक अनुक्रम प्रदर्शित करेगा।
2. (Alt) कुंजी दबाते समय वैकल्पिक संख्यात्मक कीपैड का उपयोग करते हुए, 224 नंबर दर्ज करें, दस्तावेज़ में प्रतीक "पी" दिखाई देगा। 225 से 233 तक संख्यात्मक कोड के लिए प्रक्रिया दोहराएं, दस्तावेज़ एन्कोडिंग MS-DOS (CP866) में 12 वर्ण "rstuhtschshshsh" का एक क्रम प्रदर्शित करेगा।
 |
व्यावहारिक अभ्यास
1.29। एक वर्ण तालिका (MS Word) का उपयोग करते हुए, "कंप्यूटर" शब्द के लिए विंडोज एन्कोडिंग (CP1251) में दशमलव संख्यात्मक कोड का एक क्रम लिखें।
1.30। नोटपैड का उपयोग करते हुए, निर्धारित करें कि एन्कोडिंग विंडोज (सीपी 1251) में कौन सा शब्द संख्यात्मक कोड के अनुक्रम द्वारा दिया गया है: 225, 224, 233,242।
1.31। कोडिंग CP121 कोडिंग में दर्ज "कंप्यूटर" शब्द के कोडिंग कोड KOI8 और ISO किस क्रम के होंगे?
कंप्यूटर बड़ी मात्रा में जानकारी संसाधित करता है। ऑडियो फ़ाइलें, चित्र, पाठ - यह सब पुन: प्रस्तुत या प्रदर्शित किया जाना चाहिए। बाइनरी कोडिंग किसी भी तकनीकी उपकरण की प्रोग्रामिंग जानकारी की एक सार्वभौमिक विधि क्यों है?
एन्क्रिप्शन और एन्क्रिप्शन के बीच अंतर क्या है?
अक्सर लोग "कोडिंग" और "एन्क्रिप्शन" की अवधारणाओं की पहचान करते हैं जब वास्तव में उनके अलग-अलग अर्थ होते हैं। इसलिए, एन्क्रिप्शन इसे छुपाने के लिए सूचना को परिवर्तित करने की प्रक्रिया है। वह व्यक्ति जिसने पाठ को बदल दिया है, या विशेष रूप से प्रशिक्षित लोग, अक्सर डिक्रिप्ट कर सकते हैं। कोडिंग का उपयोग सूचना को संसाधित करने और इसके साथ काम करने को सरल बनाने के लिए किया जाता है। आमतौर पर एक सामान्य एन्कोडिंग तालिका का उपयोग किया जाता है जो सभी के लिए परिचित है। यह कंप्यूटर में बनाया गया है।
बाइनरी कोडिंग सिद्धांत
बाइनरी कोडिंग विभिन्न उपकरणों द्वारा उपयोग की जाने वाली जानकारी को संसाधित करने के लिए केवल दो वर्णों - 0 और 1 के उपयोग के आधार पर। इन संकेतों को बाइनरी अंक कहा जाता था, अंग्रेजी में - बाइनरी अंक, या बिट। प्रत्येक वर्ण कंप्यूटर मेमोरी की 1 बिट लेता है। बाइनरी कोडिंग प्रसंस्करण की जानकारी का एक सार्वभौमिक तरीका क्यों है? तथ्य यह है कि कंप्यूटर के लिए कम वर्णों को संसाधित करना आसान है। पीसी उत्पादकता भी सीधे इस पर निर्भर करती है: काम करने के लिए कम कार्यात्मक कार्यों की आवश्यकता होती है, काम की गति और गुणवत्ता जितनी अधिक होती है। 
बाइनरी कोडिंग का सिद्धांत केवल प्रोग्रामिंग में नहीं पाया जाता है। बहरे और सोनोरस ड्रम बीट्स को बारी-बारी से, पोलिनेशिया के निवासियों ने एक-दूसरे को जानकारी दी। एक समान सिद्धांत लागू होता है जहां संदेश प्रसारित करने के लिए लंबी और छोटी ध्वनियों का उपयोग किया जाता है। "टेलीग्राफ वर्णमाला" का उपयोग आज किया जाता है।
बाइनरी कोडिंग का उपयोग कहां किया जाता है?
कंप्यूटर में बाइनरी का उपयोग हर जगह किया जाता है। प्रत्येक फ़ाइल, यह संगीत या पाठ हो, प्रोग्राम किया जाना चाहिए ताकि बाद में इसे आसानी से संसाधित और पढ़ा जा सके। बाइनरी कोडिंग सिस्टम प्रतीकों और संख्याओं, ऑडियो फाइलों, ग्राफिक्स के साथ काम करने के लिए उपयोगी है।
बाइनरी नंबर कोडिंग
अब कंप्यूटर में, संख्याओं को एन्कोडेड रूप में प्रस्तुत किया जाता है, औसत व्यक्ति के लिए समझ से बाहर। जैसा कि हम कल्पना करते हैं कि अरबी अंकों का उपयोग प्रौद्योगिकी के लिए तर्कहीन है। इसका कारण प्रत्येक नंबर के लिए एक अद्वितीय चरित्र निर्दिष्ट करने की आवश्यकता है, जो कभी-कभी असंभव है।

दो नंबर सिस्टम हैं: स्थिति और गैर-स्थिति। गैर-स्थिति प्रणाली लैटिन अक्षरों के उपयोग पर आधारित है और हमें रूप में परिचित है। यह रिकॉर्डिंग विधि समझने में काफी कठिन है, इसलिए उन्होंने इसे छोड़ दिया।
आज पोजिशनल नंबर सिस्टम का उपयोग किया जाता है। इसमें बाइनरी, दशमलव, ऑक्टल और यहां तक \u200b\u200bकि जानकारी के हेक्साडेसिमल एन्कोडिंग शामिल हैं।
हम रोजमर्रा की जिंदगी में दशमलव कोडिंग प्रणाली का उपयोग करते हैं। ये हमारे परिचित हैं जो हर व्यक्ति के लिए समझ में आते हैं। संख्याओं का बाइनरी कोडिंग केवल शून्य और एक का उपयोग करके भिन्न होता है।
Integers को बाइनरी कोडिंग सिस्टम में 2 से विभाजित करके परिवर्तित किया जाता है। परिणामी उद्धरणों को भी 2 से चरणबद्ध किया जाता है, जब तक कि कुल 0 या 1 प्राप्त नहीं हो जाता। उदाहरण के लिए, बाइनरी सिस्टम में 123 10 नंबर को 1111011 2 के रूप में दर्शाया जा सकता है। और २० १० की संख्या १०१०० २ जैसी दिखेगी।
सूचक 10 और 2 क्रमशः, दशमलव और बाइनरी नंबर कोडिंग प्रणाली में निर्दिष्ट हैं। बाइनरी कोडिंग प्रतीक का उपयोग विभिन्न संख्या प्रणालियों में प्रदर्शित मूल्यों के साथ काम को सरल बनाने के लिए किया जाता है।
दशमलव प्रोग्रामिंग विधियाँ एक अस्थायी बिंदु पर आधारित होती हैं। दशमलव से बाइनरी कोडिंग सिस्टम में मूल्य का सही अनुवाद करने के लिए, सूत्र N \u003d M x qp का उपयोग करें। M, मंटिसा (बिना किसी क्रम के एक संख्या की अभिव्यक्ति), P, N के मूल्य का क्रम है, और q कोडिंग सिस्टम का आधार है (हमारे मामले में 2)।
सभी संख्याएँ सकारात्मक नहीं हैं। सकारात्मक और नकारात्मक संख्याओं के बीच अंतर करने के लिए, कंप्यूटर चरित्र एन्कोडिंग के लिए 1 बिट का स्थान छोड़ देता है। यहां, शून्य प्लस चिह्न का प्रतिनिधित्व करता है, और एक ऋण चिह्न का प्रतिनिधित्व करता है।
ऐसी संख्या प्रणाली का उपयोग करना कंप्यूटर के लिए संख्याओं के साथ काम करना आसान बनाता है। यही कारण है कि बाइनरी कोडिंग कम्प्यूटेशनल प्रक्रियाओं में सार्वभौमिक है।

बाइनरी टेक्स्ट एन्कोडिंग
वर्णमाला के प्रत्येक चरित्र को शून्य और अपने स्वयं के सेट द्वारा एन्कोड किया गया है। पाठ में विभिन्न वर्ण होते हैं: अक्षर (अपरकेस और लोअरकेस), अंकगणित वर्ण और अन्य विभिन्न अर्थ। पाठ्य जानकारी को एन्कोडिंग करने के लिए 00000000 से 11111111 तक लगातार 8 बाइनरी मान के उपयोग की आवश्यकता होती है। इस तरह से 256 विभिन्न वर्णों को परिवर्तित किया जा सकता है।
पाठ एन्कोडिंग में भ्रम से बचने के लिए, प्रत्येक वर्ण के लिए विशेष मूल्य तालिकाओं का उपयोग किया जाता है। उनके पास लैटिन वर्णमाला, अंकगणितीय संकेत और विशेष संकेत हैं (उदाहरण के लिए, €, Latin, और अन्य)। गैप वर्ण 128-255 देश की राष्ट्रीय वर्णमाला को कूटबद्ध करता है।
1 वर्ण को एनकोड करने के लिए, 8 बिट मेमोरी की आवश्यकता होती है। उप-खातों को सरल बनाने के लिए, 8 बिट्स 1 बाइट के बराबर हैं, इसलिए पाठ जानकारी के लिए कुल डिस्क स्थान बाइट्स में मापा जाता है।

अधिकांश व्यक्तिगत कंप्यूटर में एक मानक तालिका होती है। aSCII एनकोडिंग (सूचना मानक के लिए अमेरिकी मानक कोड)। अन्य तालिकाओं का भी उपयोग किया जाता है जिसमें पाठ एन्कोडिंग प्रणाली अलग होती है। उदाहरण के लिए, पहले ज्ञात वर्ण एन्कोडिंग कोओआई -8 (एक 8-बिट सूचना विनिमय कोड) कहा जाता है, और यह कंप्यूटर पर एलएक्स के साथ काम करता है। CP1251 कोड टेबल, जिसे विंडोज ऑपरेटिंग सिस्टम के लिए बनाया गया था, वह भी व्यापक रूप से पाया जाता है।
बाइनरी साउंड एन्कोडिंग
ऑडियो फ़ाइलों के साथ काम करते समय बाइनरी कोडिंग प्रोग्रामिंग जानकारी का एक सार्वभौमिक तरीका इसकी सरलता है। कोई भी संगीत विभिन्न आयाम और दोलन की आवृत्ति की ध्वनि तरंगें हैं। ध्वनि की मात्रा और इसकी पिच इन मापदंडों पर निर्भर करती है।
ध्वनि तरंग को प्रोग्राम करने के लिए, कंप्यूटर इसे सशर्त रूप से कई भागों में विभाजित करता है, या "नमूने"। ऐसे नमूनों की संख्या बड़ी हो सकती है, इसलिए शून्य और लोगों के 65,536 अलग-अलग संयोजन हैं। तदनुसार, आधुनिक कंप्यूटर 16-बिट साउंड कार्ड से लैस हैं, जिसका अर्थ है कि ध्वनि तरंग के एक नमूने को एनकोड करने के लिए 16 बाइनरी अंकों का उपयोग करना।
एक ऑडियो फ़ाइल चलाने के लिए, कंप्यूटर प्रोग्राम बाइनरी कोड अनुक्रमों को संसाधित करता है और उन्हें एक निरंतर तरंग में जोड़ता है। 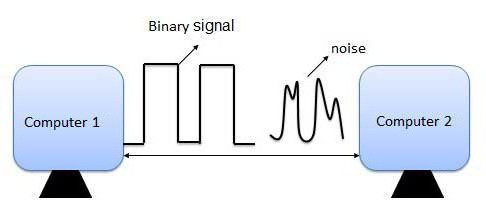
ग्राफिक्स कोडिंग
PowerPoint में चित्र, आरेख, चित्र या स्लाइड के रूप में ग्राफिक जानकारी प्रस्तुत की जा सकती है। किसी भी चित्र में छोटे डॉट्स - पिक्सेल होते हैं, जिन्हें विभिन्न रंगों में चित्रित किया जा सकता है। प्रत्येक पिक्सेल का रंग एन्कोड और सहेजा जाता है, और परिणामस्वरूप हमें एक पूर्ण छवि मिलती है।
यदि चित्र काला और सफेद है, तो प्रत्येक पिक्सेल का कोड एक या शून्य हो सकता है। यदि 4 रंगों का उपयोग किया जाता है, तो उनमें से प्रत्येक के कोड में दो अंक होते हैं: 00, 01, 10 या 11. इस सिद्धांत से, किसी भी छवि के प्रसंस्करण की गुणवत्ता प्रतिष्ठित है। चमक बढ़ने या घटने से उपयोग किए जाने वाले रंगों की संख्या पर भी असर पड़ता है। सबसे अच्छे मामले में, कंप्यूटर लगभग 16,777,216 रंगों को अलग करता है।

निष्कर्ष
प्रोग्रामिंग जानकारी के विभिन्न तरीके हैं, जिनमें से बाइनरी कोडिंग सबसे कुशल है। केवल दो वर्णों - 1 और 0 के साथ - कंप्यूटर अधिकांश फ़ाइलों को आसानी से पढ़ता है। इसके अलावा, प्रसंस्करण की गति की तुलना में बहुत अधिक है, उदाहरण के लिए, एक दशमलव प्रोग्रामिंग प्रणाली का उपयोग किया जाएगा। इस पद्धति की सादगी इसे किसी भी तकनीक के लिए अपरिहार्य बनाती है। यही कारण है कि बाइनरी कोडिंग अपने साथियों के बीच सार्वभौमिक है।
हर कोई जानता है कि कंप्यूटर जबरदस्त गति से डेटा के बड़े समूहों के साथ गणना कर सकते हैं। लेकिन हर कोई नहीं जानता है कि ये क्रियाएं केवल दो स्थितियों पर निर्भर करती हैं: क्या वर्तमान और क्या वोल्टेज है या नहीं।
ऐसी विविध जानकारी को संसाधित करने के लिए एक कंप्यूटर कैसे प्रबंधित करता है?
रहस्य बाइनरी सिस्टम में निहित है। सभी डेटा कंप्यूटर में प्रवेश करते हैं, इकाइयों और शून्य के रूप में प्रस्तुत किए जाते हैं, जिनमें से प्रत्येक बिजली के तार के एक राज्य से मेल खाती है: इकाइयां - उच्च वोल्टेज, शून्य - निम्न, या इकाइयां - वोल्टेज की उपस्थिति, शून्य - इसकी अनुपस्थिति। डेटा को शून्य और लोगों में परिवर्तित करने को द्विआधारी रूपांतरण कहा जाता है, और इसके अंतिम पदनाम को द्विआधारी कोड कहा जाता है।
रोज़मर्रा के जीवन में उपयोग किए जाने वाले कैलकुलस के दशमलव प्रणाली के आधार पर एक दशमलव संकेतन में, संख्यात्मक मान को 0 से 9 तक दस अंकों से दर्शाया जाता है, और संख्या में प्रत्येक स्थान के दाईं ओर के स्थान की तुलना में दस गुना अधिक मूल्य होता है। दशमलव प्रणाली में नौ से अधिक संख्या का प्रतिनिधित्व करने के लिए, शून्य को इसके स्थान पर रखा जाता है, और एक को बाईं ओर अगले, अधिक मूल्यवान स्थान पर रखा जाता है। इसी प्रकार, द्विआधारी प्रणाली में, जहां केवल दो अंकों का उपयोग किया जाता है - 0 और 1, प्रत्येक स्थान इसके दाईं ओर के स्थान से दोगुना मूल्यवान है। इस प्रकार, बाइनरी कोड में, केवल शून्य और एक को एकल संख्याओं के रूप में दर्शाया जा सकता है, और एक से अधिक संख्या में दो स्थानों की आवश्यकता होती है। शून्य और एक के बाद, निम्नलिखित तीन बाइनरी संख्याएं 10 (एक-शून्य पढ़ें) और 11 (एक-एक पढ़ें) और 100 (एक-शून्य-शून्य पढ़ें) हैं। 100 बाइनरी सिस्टम 4 दशमलव के बराबर हैं। दाईं ओर ऊपरी तालिका अन्य बाइनरी दशमलव समकक्षों को दिखाती है।
किसी भी संख्या को बाइनरी में व्यक्त किया जा सकता है, यह दशमलव संकेतन की तुलना में अधिक स्थान लेता है। बाइनरी सिस्टम में, आप वर्णमाला भी लिख सकते हैं, यदि प्रत्येक अक्षर को एक विशिष्ट बाइनरी नंबर सौंपा गया है।
चार स्थानों के लिए दो अंक
16 संयोजनों को अंधेरे और हल्की गेंदों का उपयोग करके बनाया जा सकता है, उन्हें चार के सेट में मिलाकर बनाया जाता है। यदि आप इकाइयों के रूप में शून्य और प्रकाश वाले के रूप में अंधेरे गेंदों को लेते हैं, तो 16 सेट एक 16-इकाई बाइनरी कोड के रूप में निकलेंगे, जिनमें से संख्यात्मक मूल्य शून्य से पांच तक है ( पृष्ठ 27 पर शीर्ष तालिका देखें)। बाइनरी सिस्टम में दो प्रकार की गेंदों के साथ भी, आप प्रत्येक समूह में गेंदों की संख्या बढ़ाकर - या संख्या में स्थानों की संख्या को बढ़ाकर अनंत संख्या में संयोजन बना सकते हैं।
बिट्स और बाइट्स
कंप्यूटर प्रसंस्करण में सबसे छोटी इकाई, बिट डेटा की एक इकाई है जिसमें दो संभावित स्थितियों में से एक हो सकती है। उदाहरण के लिए, प्रत्येक और शून्य (दाईं ओर) का अर्थ है 1 बिट। एक बिट को अन्य तरीकों से दर्शाया जा सकता है: एक विद्युत प्रवाह की उपस्थिति या अनुपस्थिति से, एक छेद और इसकी अनुपस्थिति से, दाएं या बाएं चुंबकत्व की दिशा से। आठ बिट्स एक बाइट बनाते हैं। 256 संभावित बाइट्स 256 वर्णों और वर्णों का प्रतिनिधित्व कर सकते हैं। कई कंप्यूटर एक ही समय में डेटा के बाइट्स की प्रक्रिया करते हैं।
बाइनरी रूपांतरण एक चार-अंकीय बाइनरी कोड 0 से 15 तक दशमलव संख्याओं का प्रतिनिधित्व कर सकता है।
कोड टेबल
जब वर्णमाला या विराम चिह्नों के अक्षरों को इंगित करने के लिए एक द्विआधारी कोड का उपयोग किया जाता है, तो कोड तालिकाओं की आवश्यकता होती है जो इंगित करते हैं कि कौन सा कोड किस वर्ण से मेल खाता है। ऐसे कई कोड संकलित किए गए हैं। अधिकांश पीसी को सात अंकों के कोड के लिए अनुकूलित किया जाता है, जिसे ASCII कहा जाता है, या सूचना विनिमय के लिए अमेरिकी मानक कोड। सही शो पर तालिका aSCII कोड अंग्रेजी वर्णमाला के लिए। अन्य कोड दुनिया के अन्य भाषाओं के हजारों वर्णों और वर्णमाला के लिए अभिप्रेत हैं।

ASCII कोड टेबल का हिस्सा

