29.06.2019
Кой аудио формат е най-добрият. Какво е „загуба“ или за компресиране на музика без загуби
Добър ден.
Днес искам да засегна темата за компресиране на данни без загуби. Въпреки факта, че вече има статии за хъба, посветени на определени алгоритми, исках да говоря за това малко по-подробно.
Ще се опитам да дам както математическо описание, така и описание по обичайния начин, така че всеки да намери нещо интересно за себе си.
В тази статия ще засегна основните моменти на компресия и основните видове алгоритми.
Компресия. Необходимо ли е в днешно време?
Да, разбира се. Разбира се, всички ние разбираме, че сега можем да имаме достъп както до големи обеми за съхранение, така и до високоскоростни канали за предаване на данни. Същевременно обаче нараства обемът на предаваната информация. Ако преди няколко години гледахме 700-мегабайтови филми, които се побират на един диск, днес HD-качествените филми могат да заемат десетки гигабайти.
Разбира се, ползите от компресирането на всичко и всичко не са толкова много. Но все още има ситуации, в които компресията е изключително полезна, ако не е необходима.
- Изпращане на имейли на документи (особено големи обеми документи, използващи мобилни устройства)
- При публикуване на документи на уебсайтове, необходимостта да се спести трафик
- Спестете място на диска при смяна или добавяне на място за съхранение е трудно. Например това се случва в случаите, когато не е лесно да получите бюджет за капиталови разходи и няма достатъчно дисково пространство.
Разбира се, можете да измислите още много различни ситуации, в които компресията ще бъде полезна, но тези няколко примера са ни достатъчни.
Всички методи за компресия могат да бъдат разделени на две големи групи: компресия на загуба и компресия без загуби. Компресирането без загуби се използва в случаите, когато информацията трябва да бъде възстановена точна до битове. Този подход е единственият възможен при компресиране например на текстови данни.
В някои случаи обаче не се изисква точно възстановяване на информация и е позволено да се използват алгоритми, които осъществяват компресия на загуби, която, за разлика от компресирането без загуби, обикновено е по-лесна за изпълнение и осигурява по-висока степен на архивиране.
Така че, да преминем към алгоритмите за компресия без загуби.
Универсални методи за компресия без загуби
В общия случай има три основни опции, върху които са изградени алгоритми за компресия.Първа група методи - преобразуване на потоци. Това предполага описание на новите входящи некомпресирани данни през вече обработените. В този случай не се изчисляват вероятности, кодирането на символи се извършва само въз основа на данните, които вече са обработени, като например в методите на LZ (кръстени на Авраам Лемпел и Яков Жива). В този случай вторият и следващите събития на подреда, която вече е известна на енкодера, се заменят с препратки към първото му възникване.
Втора група методите са методи за статистическа компресия. От своя страна тези методи са разделени на адаптивни (или поточни) и блокови.
В първата (адаптивна) версия изчисляването на вероятностите за новите данни се основава на данните, които вече са обработени по време на кодирането. Тези методи включват адаптивни версии на алгоритмите на Huffman и Shannon-Fano.
Във втория (блок) случай статистиката на всеки блок данни се изчислява отделно и се добавя към най-компресирания блок. Те включват статични версии на методите на Huffman, Shannon-Fano и аритметично кодиране.
Трета група методите са така наречените методи за преобразуване на блокове. Входящите данни са разделени на блокове, които след това се трансформират като цяло. Въпреки това, някои методи, особено базирани на пермутация на блокове, може да не доведат до значително (или дори каквото и да е) намаляване на количеството данни. След такава обработка обаче структурата на данните се подобрява значително и последващото компресиране от други алгоритми е по-успешно и по-бързо.
Общи принципи, на които се основава компресирането на данни
Всички методи за компресиране на данни се основават на прост логически принцип. Ако си представим, че най-често срещаните елементи са кодирани с по-къси кодове, а по-рядко срещаните се кодират с по-дълги, тогава всички данни ще се нуждаят от по-малко място за съхранение, отколкото ако всички елементи бяха представени с кодове с еднаква дължина.
Точната връзка между честотите на възникване на елементи и оптималните дължини на кода е описана в така наречената теорема за кодиране на източника на Шенън, която определя максималната граница на компресия без загуба и ентропията на Шанън.
Малко математика
Ако вероятността за възникване на елемент s i е равна на p (s i), тогава ще бъде най-изгодно да се представи този елемент - log 2 p (s i) бита. Ако по време на кодирането е възможно да се гарантира, че дължината на всички елементи е намалена до log 2 p (s i) бита, тогава дължината на цялата кодирана последователност ще бъде минимална за всички възможни методи на кодиране. Освен това, ако вероятностното разпределение на всички елементи F \u003d (p (s i)) е непроменено и вероятностите на елементите са взаимно независими, тогава средната дължина на кодовете може да бъде изчислена катоТази стойност се нарича ентропия на разпределението на вероятността F или ентропия на източника в даден момент от време.
Обаче обикновено вероятността от появата на даден елемент не може да бъде независима, напротив, зависи от някои фактори. В този случай за всеки нов кодиран елемент s i разпределението на вероятността F ще приеме някаква стойност F k, тоест за всеки елемент F \u003d F k и H \u003d H k.
С други думи, можем да кажем, че източникът е в състояние k, което съответства на определен набор от вероятности p k (s i) за всички елементи s i.
Следователно, като се има предвид тази корекция, можем да изразим средната дължина на кодовете като
Където P k е вероятността за намиране на източника в състояние k.
И така, на този етап знаем, че компресията се основава на заместване на често срещащи се елементи с кратки кодове и обратно, а също така знаем как да определим средната дължина на кодовете. Но какво е код, кодиране и как се случва?
Кодиране без памет
Кодовете без памет са най-простите кодове, въз основа на които могат да се компресират данни. В незапомнен код всеки символ в кодирания вектор на данни се заменя с кодираща дума от набор от префикси на двоични последователности или думи.Според мен не е най-ясното определение. Разгледайте тази тема по-подробно.
Нека се даде някаква азбука ![]() състоящ се от някакъв (краен) брой букви. Ние наричаме всяка крайна последователност от знаци от тази азбука (A \u003d a 1, 2, ..., a n) с една дума, а числото n е дължината на тази дума.
състоящ се от някакъв (краен) брой букви. Ние наричаме всяка крайна последователност от знаци от тази азбука (A \u003d a 1, 2, ..., a n) с една дума, а числото n е дължината на тази дума.
Нека бъде дадена и друга азбука ![]() , По същия начин, обозначавайте думата в тази азбука като B.
, По същия начин, обозначавайте думата в тази азбука като B.
Въвеждаме още две нотация за набора от всички непусти думи в азбуката. Нека - броят на празните думи в първата азбука, и - във втората.
Нека се даде и картографиране F, което свързва с всяка дума A от първата азбука дума B \u003d F (A) от втората. Тогава ще бъде наречена думата Б код думи A и преходът от оригиналната дума към нейния код ще бъде извикан кодиране.
Тъй като думата може да се състои и от една буква, можем да идентифицираме съответствието на буквите от първата азбука и съответните думи от втората:
a 1<-> Б 1
a 2<-> B 2
…
a n<-> B n
Този мач се нарича схема, и обозначаваме ∑.
В този случай думите B 1, B 2, ..., B n се наричат елементарни кодовеи вида на кодирането с тяхна помощ - азбучно кодиране, Разбира се, повечето от нас са се сблъскали с този вид кодиране, дори да не знаем всичко, което описах по-горе.
И така, решихме концепциите азбука, дума, код, и кодиране, Сега въвеждаме концепцията префикс.
Нека думата B има формата B \u003d B "B" ". Тогава B" се нарича началото, или префикс думите B и B "" - неговият край. Това е доста проста дефиниция, но трябва да се отбележи, че за всяка дума B може да се счита както начална, така и крайна дума както празна дума ʌ („интервал“), така и самата дума Б.
И така, ние се приближаваме до разбирането на дефиницията на кодовете без памет. Последната дефиниция, която трябва да разберем, е набор от префикси. Схема ∑ има свойството на префикс, ако за всеки 1≤i, j≤r, i ≠ j, думата B i не е префикс на думата B j.
Просто казано, набор от префикси е краен набор, в който никой елемент не е префиксът (или началото) на който и да е друг елемент. Прост пример за такъв набор е например обикновената азбука.
И така, измислихме основните дефиниции. И така, как се случва самото безконтактно кодиране?
Проявява се на три етапа.
- Съставя се азбука the от знаците на оригиналното съобщение и символите на азбуката се сортират в низходящ ред по вероятността им да се появят в съобщението.
- Всеки символ a i от азбуката Ψ се свързва с определена дума B i от префикса набора Ω.
- Всеки символ е кодиран, последвано от комбиниране на кодовете в един поток от данни, което ще бъде резултат от компресиране.
Един от каноничните алгоритми, които илюстрират този метод, е алгоритъмът на Хафман.
Алгоритъм на Хафман
Алгоритъмът на Huffman използва честотата на възникване на едни и същи байтове във входния блок данни и съвпада с честите блокове от верига битове с по-къси дължини и обратно. Този код е минимално излишен. Помислете за случая, когато независимо от входния поток азбуката на изходния поток се състои само от 2 знака - нула и един.На първо място, когато кодираме с алгоритъма на Huffman, трябва да конструираме веригата ∑. Това се прави, както следва:
- Всички букви от входната азбука са подредени в низходящ ред на вероятност. Всички думи от азбуката на изходния поток (тоест това, което ще кодираме) първоначално се считат за празни (припомням, че азбуката на изходния поток се състои само от знаци (0,1)).
- Два знака j-1 и j на входящия поток, които имат най-малка вероятност за поява, се комбинират в един „псевдосимвол“ с вероятност р равна на сумата от вероятностите на съставните й знаци. След това добавяме 0 към началото на думата B j-1 и 1 към началото на думата B j, която впоследствие ще бъде кодовете на символите съответно j-1 и j.
- Премахваме тези знаци от азбуката на оригиналното съобщение, но добавяме генерирания псевдо-символ към тази азбука (естествено, тя трябва да бъде вмъкната в азбуката на правилното място, като се вземе предвид вероятността й).
За по-добра илюстрация, помислете за малък пример.
Да предположим, че имаме азбука, състояща се само от четири знака - (a 1, 2, 3, 4). Да приемем също, че вероятностите за възникване на тези символи са равни, съответно, p 1 \u003d 0,5; р 2 \u003d 0,24; р 3 \u003d 0,15; p 4 \u003d 0,11 (сумата от всички вероятности очевидно е равна на единица).
Така че ние ще изградим схемата за тази азбука.
- Комбинирайте двата знака с най-малко вероятности (0,11 и 0,15) в p „псевдо-символ“.
- Ние комбинираме двата знака с най-малка вероятност (0,24 и 0,26) в p псевдо символа.
- Премахваме комбинираните знаци и вмъкваме получения псевдо символ в азбуката.
- Накрая комбинирайте останалите два знака и вземете върха на дървото.
Ако илюстрирате този процес, получавате нещо като следното:
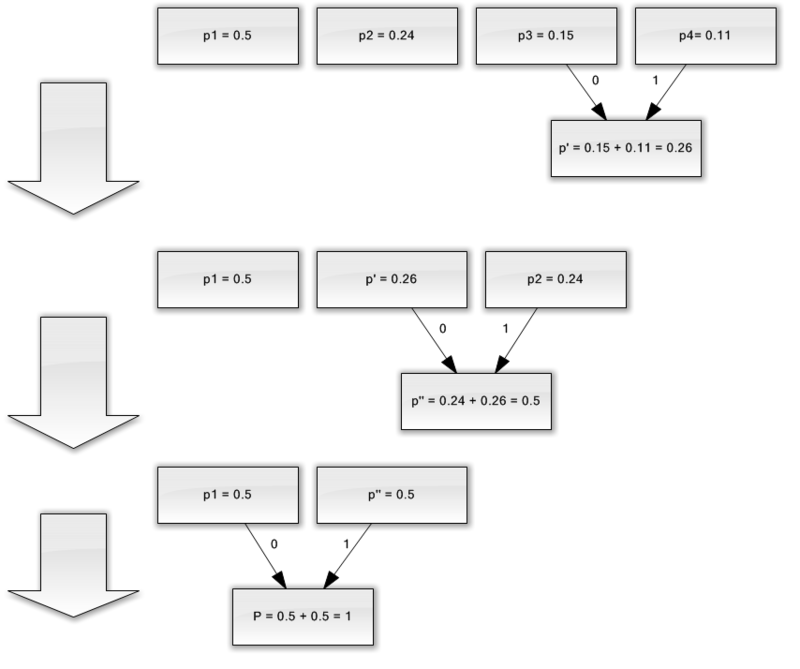
Както можете да видите, с всяко сливане ние присвояваме знаците 0 и 1 на героите, които трябва да бъдат обединени.
По този начин, когато дървото е изградено, лесно можем да получим кода за всеки символ. В нашия случай кодовете ще изглеждат така:
A 1 \u003d 0
a 2 \u003d 11
a 3 \u003d 100
a 4 \u003d 101
Тъй като никой от тези кодове не е префикс на който и да е друг (тоест получихме прословутия набор от префикси), можем еднозначно да идентифицираме всеки код в изходния поток.
И така, ние постигнахме, че най-честият символ се кодира от най-краткия код и обратно.
Ако приемем, че първоначално един байт е бил използван за съхранение на всеки символ, тогава можем да изчислим колко успяхме да намалим данните.
Да предположим, че имахме низ от 1000 знака на входа, в който символът a 1 е възникнал 500 пъти, 2 240, 3 150 и 4 110 пъти.
Първоначално този низ е заемал 8000 бита. След кодирането получаваме низ с дължина ∑p i l i \u003d 500 * 1 + 240 * 2 + 150 * 3 + 110 * 3 \u003d 1760 бита. Така че успяхме да компресираме данните 4,54 пъти, изразходвайки средно 1,76 бита за кодирането на всеки символ на потока.
Нека ви напомня, че според Шанън средната дължина на кодовете е. Замествайки стойностите на вероятността в това уравнение, получаваме средната дължина на кода равна на 1.75496602732291, което е много, много близко до получения резултат.
Независимо от това, трябва да се има предвид, че в допълнение към самите данни трябва да съхраняваме таблицата за кодиране, което леко ще увеличи крайния размер на кодираните данни. Очевидно е, че в различни случаи могат да се използват различни вариации на алгоритъма - например понякога е по-ефективно да се използва предварително определена таблица на вероятностите, а понякога е необходимо да се компилира динамично, като се преминат през компресивни данни.
заключение
И така, в тази статия се опитах да говоря общи принципи, чрез която се получава компресиране без загуби, а също така се счита за един от каноничните алгоритми - кодирането на Huffman.Ако статията е по вкуса на хабро-общността, тогава ще се радвам да напиша продължение, тъй като има много повече интересни неща относно компресията без загуби; това са както класически алгоритми, така и предварителни трансформации на данни (например трансформацията на Burroughs-Wheeler), и, разбира се, специфични алгоритми за компресиране на звук, видео и изображения (най-интересната тема според мен).
литература
- Ватолин Д., Ратушняк А., Смирнов М. Юкин В. Методи за компресиране на данни. Архиватори на устройства, компресия на изображения и видео; ISBN 5-86404-170-X; 2003 година
- Д. Саломон. Компресиране на данни, изображения и звук; ISBN 5-94836-027-X; 2004 година.
Лекция номер 4 Компресиране на информация
Принципи за компресиране на информация
Целта на компресирането на данни е да се осигури компактно представяне на данните, генерирани от източника, за по-икономичното им съхранение и предаване по комуникационни канали.
Да предположим, че имаме файл с размер 1 (един) мегабайта. Трябва да вземем по-малък файл от него. Нищо сложно - стартираме архиватора например WinZip и в резултат получаваме например файл с размер 600 килобайта. Къде отидоха останалите 424 килобайта?
Компресирането на информация е един от начините за нейното кодиране. Като цяло кодовете са разделени на три големи групи - кодове за компресия (ефективни кодове), шумоустойчиви кодове и криптографски кодове. Кодовете, предназначени да компресират информация, се разделят от своя страна на кодове без загуби и кодове на загуби. Кодирането без загуба предполага абсолютно точно възстановяване на данни след декодиране и може да се използва за компресиране на всяка информация. Кодирането на загуби обикновено има много по-висока степен на компресия от кодирането без загуби, но позволява някои отклонения на декодираните данни от оригинала.
Видове компресия
Всички методи за компресиране на информация могат да бъдат разделени на два големи разграничаващи се класа: компресия с загуба информация и компресия без загуба информация.
Компресиране без загуба на информация.
Тези методи за компресиране са от интерес за нас преди всичко, тъй като те се използват точно при прехвърляне на текстови документи и програми, при издаване на завършена работа на клиент или при създаване на резервни копия на информация, съхранявана на компютър.
Методите за компресиране от този клас не могат да позволят загуба на информация, следователно те се основават само на елиминиране на излишъка й и информацията има излишък почти винаги (макар че някой не я е кондензирал преди). Ако нямаше съкращения, нямаше какво да се компресира.
Ето един прост пример. Руският език има 33 букви, десет цифри и още десетина препинателни знаци и други специални знаци. За записан текст само с главни руски букви (както в телеграмите и радиограмите) шестдесет различни значения биха били достатъчни. Всеки символ обаче обикновено е кодиран в байт, който съдържа 8 бита и може да изрази 256 различни кода. Това е първата основа за съкращаване. За нашия „телеграфен“ текст шест бита на знак биха били достатъчни.
Ето още един пример. При международно кодиране на символи ASCII същият брой битове се разпределя за кодиране на всеки символ (8), докато всички отдавна са добре наясно, че най-често срещаните символи имат смисъл да кодират с по-малко знаци. Така например в "кода на Морз" буквите "Е" и "Т", които често се срещат, са кодирани с един знак (съответно това е точка и тире). И такива редки букви като "Yu" (- -) и "Ts" (- -) са кодирани с четири знака. Неефективното кодиране е втората причина за съкращаването. Програмите, които извършват компресиране на информация, могат да въведат собствено кодиране (различно за различните файлове) и да присвоят определена таблица (речник) на компресирания файл, от която програмата за разопаковане ще разбере как определени символи или техните групи са кодирани в този файл. Назовават се алгоритми, основани на кодирането на информация алгоритми на Хафман.
Наличието на дублирани фрагменти е третата причина за съкращаване. Това е рядкост в текстове, но в таблици и графики повторението на кодовете е често срещано явление. Така например, ако числото 0 се повтори двадесет пъти подред, тогава няма смисъл да поставяте двадесет нула байта. Вместо това те поставят една нула и коефициент 20. Подобни алгоритми, основаващи се на откриване на повторения, се наричат методиУПИ (тичам дължина Encoding).
Големите повтарящи се поредици от еднакви байтове се отличават особено с графични илюстрации, но не фотографски (има много шум и съседните точки варират значително по параметри), а такива, които художниците рисуват в "гладък" цвят, както в анимационните филми.
Компресия на загуба.
Компресирането със загуба на информация означава, че след разопаковането на компресирания архив ще получим документ, който е малко по-различен от този, който беше в самото начало. Ясно е, че колкото по-голяма е степента на компресия, толкова по-голяма е степента на загубата и обратно.
Разбира се, такива алгоритми не са приложими за текстови документи, таблици на база данни и особено за програми. Можете по някакъв начин да преживеете незначителни изкривявания в обикновен, неформатиран текст, но изкривяването на поне един бит в дадена програма ще я направи напълно неработеща.
В същото време има материали, в които си струва да жертвате няколко процента информация, за да получите компресия десетки пъти. Те включват фотографски илюстрации, видеоклипове и музикални композиции. Загубата на информация по време на компресиране и последващо разопаковане в такива материали се възприема като появата на някакъв допълнителен „шум“. Но тъй като все още има известен „шум“ при създаването на тези материали, неговото леко увеличение не винаги изглежда критично и печалбата в размера на файла е огромна (10-15 пъти за музика, 20-30 пъти за снимки и видео).
Алгоритмите за компресия със загуба на информация включват такива добре известни алгоритми като JPEG и MPEG. JPEG алгоритъмът се използва при компресиране на снимки. Файловете с изображения, компресирани с този метод, имат разширението jpg. MPEG алгоритмите се използват при компресиране на видео и музика. Тези файлове могат да имат различни разширения, в зависимост от конкретната програма, но най-известните са .MPG за видео и. MP3 за музика.
Алгоритмите за компресиране на загуби на информация се използват само за задачи на потребителите. Това означава например, че ако една снимка се предава за гледане, а музика за възпроизвеждане, тогава могат да се прилагат такива алгоритми. Ако те се прехвърлят за по-нататъшна обработка, например за редактиране, не се допуска загуба на информация в изходния материал.
Размерът на допустимата загуба при компресия обикновено може да се контролира. Това ви позволява да експериментирате и да постигнете оптималното съотношение размер / качество. При фотографските илюстрации, предназначени да се показват на екран, загубата на 5% от информацията обикновено е некритична, а в някои случаи 20-25% може да се толерира.
Алгоритми за компресия без загуби
Код на Шенън Фено
За допълнителна дискусия ще бъде удобно да представим нашия изходен файл с текст като източник на символи, които се появяват един по един при изхода му. Не знаем предварително кой знак ще бъде следващият, но знаем, че с вероятност p1 ще се появи буквата „a“, с вероятност p2 ще се появи буквата „b“ и т.н.
В най-простия случай ще считаме всички знаци на текста за независими един от друг, т.е. вероятността за появата на следващия символ не зависи от стойността на предишния символ. Разбира се, това не е така за смислен текст, но сега обмисляме много опростена ситуация. В този случай изявлението "символът носи повече информация, толкова по-малка е вероятността за неговото появяване."
Нека си представим текст, чиято азбука се състои само от 16 букви: A, B, C, D, D, E, F, Z, I, K, L, M, H, O, P, P. Всеки от тези знаци може да бъде кодирайте само с 4 бита: от 0000 до 1111. Сега си представете, че вероятността за поява на тези знаци се разпределя, както следва:
Сумата от тези вероятности е, разбира се, една. Разделяме тези символи на две групи, така че общата вероятност на символите на всяка група е ~ 0,5 (фиг.). В нашия пример това ще са групи символи AB и GR. Кръговете на фигурата, обозначаващи групи от знаци, се наричат \u200b\u200bвърхове или възли, а структурата на тези възли се нарича бинарно дърво (B-дърво). Задайте на всеки възел свой собствен код, обозначавайки единия възел с числото 0, а другия с числото 1.
Отново разделяме първата група (AB) на две подгрупи, така че общите им вероятности да са максимално близки една до друга. Добавете числото 0 към кода на първата подгрупа, а числото 1 към кода на втората. 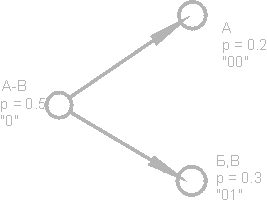
Ще повтаряме тази операция, докато не остане по един символ върху всяка върха на нашето „дърво“. Пълно дърво за нашата азбука ще има 31 възли.
Символните кодове (крайните десни възли на дървото) имат кодове с неравна дължина. И така, буквата A, която има вероятност p \u003d 0,2 за нашия въображаем текст, е кодирана само с два бита, а буквата P (не е показана на фигурата), която има вероятност p \u003d 0,013, е кодирана с шест битова комбинация.
И така, принципът е очевиден - често срещащите се символи са кодирани с по-малко битове, рядко срещащите се символи се кодират повече. В резултат на това средният брой битове на знак ще бъде равен на
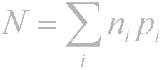
където ni е броят на битовете, кодиращи i-тия символ, pi е вероятността за поява на i-тия символ.
Код на Хафман.
Алгоритъмът на Huffman изящно реализира общата идея за статистическо кодиране, използвайки набор от префикси и работи, както следва:
1. Пишем подред всички знаци от азбуката във възходящ или низходящ ред на вероятността за тяхното появяване в текста.
2. Последователно комбинирайте двата символа с най-малко вероятности за възникване в нов съставен символ, вероятността от възникване на който се приема, че е равна на сумата от вероятностите на неговите съставни символи. В крайна сметка ще изградим дърво, чийто възел има обща вероятност за всички възли под него.
3. Проследяваме пътя към всяко листо на дървото, като маркираме посоката към всеки възел (например вдясно - 1, вляво - 0). Получената последователност дава кодова дума, съответстваща на всеки символ (фиг.).
Създайте кодово дърво за съобщение със следната азбука:
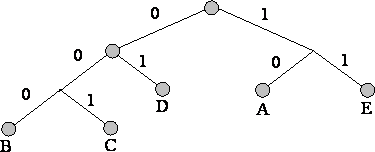
Недостатъци на методите
Най-голямата трудност с кодовете, както следва от предишното обсъждане, е необходимостта да има таблици на вероятностите за всеки тип сгъваеми данни. Това не е проблем, ако се знае, че текстът на английски или руски език се компресира; ние просто предоставяме на енкодера и декодера с кодово дърво, подходящо за английски или руски текст. В общия случай, когато вероятността на символите за входните данни е неизвестна, статичните кодове на Huffman работят неефективно.
Решението на този проблем е статистически анализ на кодираните данни, извършен по време на първото преминаване през данните и съставяне на кодово дърво въз основа на него. Всъщност кодирането се извършва от втория пропуск.
Друг недостатък на кодовете е, че минималната дължина на кодовата дума за тях не може да бъде по-малка от една, докато ентропията на съобщението може да бъде 0,1 и 0,01 бита / буква. В този случай кодът става значително излишен. Проблемът се решава чрез прилагане на алгоритъма към блокове от знаци, но след това процедурата на кодиране / декодиране е сложна и кодовото дърво е значително разширено, което в крайна сметка трябва да бъде запазено заедно с кода.
Тези кодове не вземат предвид връзката между героите, които присъстват в почти всеки текст. Например, ако видим буквата q в английски текст, можем уверено да кажем, че буквата u ще я последва.
Групово кодиране - Кодиране на дължина на изпълнение (RLE) - един от най-старите и лесни алгоритми за архивиране. Компресирането в RLE се извършва чрез замяна на низове от идентични байтове с двойки броячи и стойности. ("Червено, червено, ..., червено" се изписва като "N червено").
Една от реализациите на алгоритъма е следната: те търсят най-рядко срещания байт, наричат \u200b\u200bго префикс и заменят низовете от идентични символи с тризначни "префикс, брояч, стойност". Ако този байт се намери в изходния файл веднъж или два пъти подред, тогава той се заменя с двойка "префикс, 1" или "префикс, 2". Остава един неизползван чифт "префикс, 0", който може да се използва като знак за края на пакетираните данни.
Когато кодирате EXE файлове, можете да търсите и пакетирате последователности от формата AxAyAzAwAt ..., които често се намират в ресурси (низове в Unicode кодиране)
Положителните страни на алгоритъма включват факта, че той не изисква допълнителна памет при работа и бързо се изпълнява. Алгоритъмът се използва във формати PCX, TIFF, BMP. Интересна особеност на груповото кодиране в PCX е, че степента на архивиране на някои изображения може да се увеличи значително само чрез промяна на реда на цветовете в палитрата на изображения.
Кодът LZW (Lempel-Ziv & Welch) е един от най-разпространените кодове за компресия без загуби. Именно с помощта на кода LZW компресията се извършва в такива графични формати като TIFF и GIF, с помощта на модификации на LZW много много универсални архиватори изпълняват своите функции. Алгоритъмът се основава на търсене във входния файл за повторени последователности от символи, които са кодирани в комбинации с дължина от 8 до 12 бита. По този начин този алгоритъм има най-голяма ефективност за текстови файлове и за графични файлове, в които има големи едноцветни секции или повтарящи се последователности от пиксели.
Липсата на загуба на информация по време на кодирането на LZW доведе до широкото използване на TIFF формат, базиран на него. Този формат не налага никакви ограничения върху размера и дълбочината на цвета на изображението и е широко разпространен, например при печат. Друг формат, базиран на LZW - GIF - е по-примитивен - той ви позволява да съхранявате изображения с дълбочина на цвета не повече от 8 бита / пиксела. В началото на GIF файла е палитра - таблица, която задава съответствието между цветовия индекс - число в диапазона от 0 до 255 и истинска, 24-битова цветова стойност.
Алгоритми за компресиране на загуба на информация
JPEG алгоритъмът е разработен от група компании, наречена Joint Photographic Experts Group. Целта на проекта беше да създаде високоефективен стандарт за компресия както за черно-бели, така и за цветни изображения, като тази цел беше постигната от разработчиците. В момента JPEG се използва широко там, където се изисква висока степен на компресия - например в Интернет.
За разлика от LZW алгоритъма, JPEG кодирането е кодиране с загуба. Самият алгоритъм за кодиране се основава на много сложна математика, но в общи линии може да се опише по следния начин: изображението се разделя на квадрати от 8 * 8 пиксела и след това всеки квадрат се преобразува в последователна верига от 64 пиксела. Освен това всяка такава верига се подлага на така наречената DCT трансформация, която е една от разновидностите на дискретната трансформация на Фурие. Той се състои във факта, че входната последователност на пиксели може да бъде представена като сбор от синусоидални и косинусни компоненти с множество честоти (така наречените хармоници). В този случай трябва да знаем само амплитудите на тези компоненти, за да възстановим входната последователност с достатъчна степен на точност. Колкото повече хармонични компоненти знаем, толкова по-малко ще има разминаване между оригинала и компресираното изображение. Повечето JPEG енкодери ви позволяват да регулирате съотношението на компресия. Това се постига по много прост начин: колкото по-високо е зададено съотношението на компресия, толкова по-малко хармоници ще бъдат представени всеки 64-пикселен блок.
Разбира се, силата на този тип кодиране е голям коефициент на компресия при запазване на оригиналната дълбочина на цвета. Именно това свойство е причинило широкото му използване в Интернет, където намаляването на размера на файловете е от първостепенно значение, в мултимедийните енциклопедии, където се изисква възможно най-много графика, за да се съхранява в ограничено количество.
Отрицателното свойство на този формат е невъзстановимо по никакъв начин, присъщото му присъщо влошаване на качеството на изображението. Именно този тъжен факт не позволява използването му в печата, където качеството е от първостепенно значение.
JPEG форматът обаче не е границата на съвършенството в желанието да се намали размера на крайния файл. Напоследък се провеждат интензивни изследвания в областта на така наречената вълнообразна трансформация (или спукната трансформация). Въз основа на най-сложните математически принципи, вълновите енкодери ви позволяват да получите повече компресия от JPEG, с по-малко загуба на информация. Въпреки сложността на математиката на вълновата трансформация, тя е по-проста в реализацията на софтуера в сравнение с JPEG. Въпреки че алгоритмите за компресиране на вълни все още са в начален стадий, те имат голямо бъдеще.
Фрактална компресия
Компресирането на фрактално изображение е алгоритъм за компресиране на загуба на изображения, базиран на прилагането на итерабелни функционални системи (IFS, които обикновено са афинитни трансформации) към изображенията. Този алгоритъм е известен с факта, че в някои случаи той позволява да се получат много високи коефициенти на компресия (най-добрите примери са до 1000 пъти с приемливо визуално качество) за реални снимки на природни обекти, което по принцип не е достъпно за други алгоритми за компресиране на изображения. Поради трудната ситуация с патентоването алгоритъмът не се използва широко.
Фракталното архивиране се основава на факта, че използвайки коефициентите на система от итерабелни функции, изображението се представя в по-компактен вид. Преди да разгледаме процеса на архивиране, нека разгледаме как IFS изгражда изображение.
Строго погледнато, IFS е набор от триизмерни афинитни трансформации, които превеждат едно изображение в друго. Точките в триизмерното пространство се трансформират (x координата, y координата, яркост).
Основата на метода на фрактално кодиране е откриване на самоподобни секции в изображението. Възможността за прилагане на теорията на повтарящите се функционални системи (IFS) към проблема за компресиране на изображението беше първо изследвана от Майкъл Барнсли и Алън Слоун. Те патентовали идеята си през 1990 и 1991 година. Jacquin представи метод на фрактално кодиране, който използва блокове за домейни и диапазони за подразделение, блокове с квадратна форма, покриващи цялото изображение. Този подход се превърна в основа за повечето методи за фрактално кодиране, използвани днес. Той е разработен от Ювал Фишер и редица други изследователи.
В съответствие с този метод, изображението се разделя на много подразличия на ранг поддиапазони (поддиапазони на диапазона) и се определят много припокриващи се домейни на домейни (домейни). За всеки ранг блок алгоритъмът за кодиране намира най-подходящия блок от домейни и аффинната трансформация, която превежда този домейн блок в даден ранг блок. Структурата на изображението е картографирана в система от ранг блокове, блокове на домейни и трансформи.
Идеята е следната: да предположим, че оригиналното изображение е фиксирана точка на някакво компресивно картографиране. Тогава вместо самото изображение е възможно да се запомни този дисплей по някакъв начин и за възстановяване е достатъчно многократно да се прилага този дисплей към всяко начално изображение.
По теорема на Банах подобни итерации винаги водят до фиксирана точка, тоест до първоначалното изображение. На практика цялата трудност се състои в намирането на най-подходящия компресивен дисплей от изображението и в компактно съхранение. Като правило, картографирането на алгоритмите за търсене (т.е. алгоритмите за компресия) са силно груба сила и изискват големи изчислителни разходи. В същото време алгоритмите за възстановяване са доста ефективни и бързи.
Накратко, предлаганият от Barnsley метод може да бъде описан по следния начин. Изображението е кодирано от няколко прости трансформации (в нашия случай аффини), тоест се определя от коефициентите на тези трансформации (в нашия случай A, B, C, D, E, F).
Например изображението на кривата на Кох може да бъде кодирано с четири аффинни трансформации, ние ще го определим еднозначно, използвайки само 24 коефициента.
В резултат точката задължително ще отиде някъде вътре в черната зона в оригиналното изображение. Правейки тази операция много пъти, ще запълним цялото черно пространство, като по този начин възстановим картината.

Най-известните са две изображения, получени с помощта на IFS: триъгълникът Sierpinski и папрат на Barnsley. Първата се дефинира от три, а втората с пет аффинни трансформации (или, в нашата терминология, лещи). Всяко преобразуване се определя от буквално прочетени байтове, докато изображението, конструирано с тяхна помощ, може да отнеме няколко мегабайта.
Става ясно как работи архиваторът и защо отнема толкова много време. Всъщност фракталната компресия е търсене на самоподобни области в изображението и определяне на параметрите на аффинните трансформации за тях.
В най-лошия случай, ако оптимизиращият алгоритъм не се използва, той ще изисква изброяване и сравнение на всички възможни фрагменти на изображения с различни размери. Дори за малки изображения с дискретност, взети под внимание, получаваме астрономически брой опции, които да се търсят. Дори рязкото стесняване на класовете на трансформация, например поради мащабиране само определен брой пъти, няма да позволи постигането на приемливо време. Освен това се губи качеството на изображението. По-голямата част от проучванията в областта на фракталната компресия сега са насочени към намаляване на времето за архивиране, необходимо за получаване на висококачествени изображения.
За алгоритъма на фрактална компресия, както и за други алгоритми на компресиране на загуби, много важни са механизмите, с които ще бъде възможно да се контролира съотношението на компресия и степента на загуба. Към днешна дата е разработен достатъчно голям набор от такива методи. Първо, възможно е да се ограничи броят на трансформациите, очевидно осигурявайки коефициент на компресия не по-нисък от фиксирана стойност. Второ, можете да изискате, че в ситуация, когато разликата между обработения фрагмент и неговото най-добро приближение е по-висока от определена прагова стойност, този фрагмент задължително се разделя (за него трябва да бъдат навити няколко обектива). Трето, възможно е да се забрани фрагментирането на фрагменти, по-малки от, да речем, четири точки. Променяйки праговите стойности и приоритета на тези условия, можете много гъвкаво да контролирате степента на компресия на изображението: от битово съвпадение до коефициент на компресия.
Сравнение с JPEG
Днес най-често срещаният алгоритъм за архивиране на графични изображения е JPEG. Сравнете го с фрактална компресия.
Първо, отбелязваме, че и единият, и другият работят с 8-битови (в сиви скали) и 24-битови пълноцветни изображения. И двете са алгоритми за компресия на загуби и осигуряват близки съотношения за архивиране. Както фракталният алгоритъм, така и JPEG имат възможност да увеличат коефициента на компресия чрез увеличаване на загубите. В допълнение, и двата алгоритма са много паралелни.
Разликите започват, ако вземем предвид времето, необходимо за алгоритмите за архивиране / разархивиране. И така, фракталният алгоритъм компресира стотици и дори хиляди пъти по-дълъг от JPEG. Разопаковането на изображението, напротив, ще се случи 5-10 пъти по-бързо. Следователно, ако изображението ще бъде компресирано само веднъж и прехвърлено по мрежата и разопаковано много пъти, е по-изгодно да използвате фракталния алгоритъм.
JPEG използва разлагането на изображението в косинусни функции, така че загубата в него (дори при определената минимална загуба) се появява във вълните и ореолите на границата на остри цветни преходи. Именно за този ефект те не обичат да го използват при компресиране на изображения, подготвени за висококачествен печат: там този ефект може да стане много забележим.
Фракталният алгоритъм е свободен от този недостатък. Освен това, когато отпечатвате изображение, всеки път трябва да извършвате операция за мащабиране, тъй като растерът (или линията) на печатащото устройство не съвпада с растерния образ. При конвертиране могат да се появят и няколко неприятни ефекта, които могат да се преборят или чрез мащабиране на изображението програмно (за печатни устройства с ниска цена като конвенционални лазерни и мастиленоструйни принтери), или чрез оборудване на печатащото устройство със собствен процесор, твърд диск и набор от програми за обработка на изображения (за скъпи фотографски наборници). Както може би се досещате, когато използвате фракталния алгоритъм, подобни проблеми практически не възникват.
Изпускането на JPEG от фракталния алгоритъм при широко използване няма да се случи скоро (поне поради ниската скорост на архивиране на последното), но в областта на мултимедийните приложения, в компютърните игри, използването му е оправдано.
В първата част ще разгледаме аудио форматите. Какво е FLAC, WavPack, TAK, Monkey's Audio, OptimFROG, ALAC, WMA, Shorten, LA, TTA, LPAC, MPEG-4 ALS, MPEG-4 SLS, Real Lossless? Знаете ли колко вида аудио Засега се занимаваме с формати за компресиране на аудио без загуби и разглеждаме отговора на въпроса за броя на аудио разширенията в самия край на статията.
И така, първо дефинираме термините:
« алгоритъм „Това е точно предписание, което определя изчислителния процес, който преминава от данни с променлив източник до желания резултат.“
« кодек (англ. кодек, от кодер / декодер - енкодер / декодер - енкодер / декодер или компресор / декомпресор) - устройство или програма, които могат да извършват преобразуване на данни или сигнал. Кодеци могат или да кодират поток / сигнал (често за предаване, съхранение или криптиране), или да го декодират, за да го видят или променят във формат, който е по-подходящ за тези операции. Кодеците често се използват при дигитална обработка на видео и звук.
Повечето кодеци за аудио и визуални данни използват компресия на загуба, за да получат приемлив размер на готовия (компресиран) файл. Съществуват и кодеци за компресия без загуби. "
« Компресия без загуба (Английско компресиране на данни без загуби) е метод за компресиране на информация, с помощта на който кодираната информация може да бъде възстановена точно до битове. В този случай първоначалните данни се възстановяват напълно от компресирано състояние. За всеки тип цифрова информация по правило има свои собствени алгоритми за компресия без загуби. "
Компресирането на загуба на данни се използва, когато е важна идентичността на компресираните данни с оригинала. Често срещан пример са изпълними файлове, документи и изходен код. Програмите, използващи формати за компресия без загуби, се наричат \u200b\u200bархиватори, всеки знае популярните файлови формати ZIP, или RAR, Unix-полезност Gzip и т.н. Всички тези програми се различават в приложените алгоритми (един или няколко) и следователно различни свойства на компресия на различни файлове.
Част I. - ТЕОРИЯ:
Методите за компресиране или алгоритмите за компресия без загуби могат да бъдат разпределени според типа данни, за които са създадени. Има три основни типа данни: текст, изображения и звук.
По принцип всеки алгоритъм за компресиране на многофункционални данни без загуби (многофункционален означава, че може да обработва всеки тип двоични данни) може да се използва за всеки тип данни, но повечето от тях са неефективни за всеки основен тип. Звуковите данни, например, не могат да бъдат добре компресирани чрез алгоритъм за компресиране на текст и обратно.
Сред методите на компресиране може да се отбележи следното - ентропийна компресия, речни методи, статистически методи. Всеки метод е добър за определен тип данни и включва редица алгоритми.
Компресия на ентропия: Алгоритъм на Хафман · Адаптивен алгоритъм на Хафман · Аритметично кодиране (Алгоритъм на Шанън - Фано · Интервал) · Кодове на Голамб · Делта · Универсален код (Елиас · Фибоначи)
Методи на речника: RLE · Дефлиране · LZ (LZ77 / LZ78 · LZSS · LZW · LZWL · LZO · LZMA · LZX · LZRW · LZJB · LZT)
Алгоритмите на статистическия модел за текст (или двоични текстови данни, като изпълними файлове) включват: Преобразуване на Barrow-Wheeler (предварителна обработка на блокове за сортиране, която прави компресията по-ефективна) · LZ77 и LZ78 (използвайки DEFLATE) · LZW.
Други: RLE · CTW · BWT · MTF · PPM · DMC
Често се извикват само добре разработени алгоритми, докато последните разработки само предполагат (общо използване, стандартизация и т.н.) или изобщо не са посочени.
Но да се върнем към нашата тема. За кодиране на аудио данни подходящи алгоритми:
Алгоритъм на Хафман (използван също DEFLATE), аритметично кодиране
Apple без загуби — ALAC (Аудио кодек без загуба на Apple)
Кодиране без загуба на аудио — известен също като MPEG-4 ALS
Безплатен аудио кодек без загуба — FLAC
Опаковка без загуба на меридиан — MLP
Аудиото на маймуната — APE
OptimFROG
RealPlayer — RealAudio Без загуба
скъси — SHN
ТАК — (T) om "s verlustfreier (A) udio (K) ompressor (немски)
TTA — Истинско аудио без загуби
WavPack — Wavpack без загуби
Wma загуба — Windows Media Lossless
DTS — DTS съраунд звук
Семейство алгоритми на Lempel-Ziv, RLE (кодиране по дължина)
FLAC (Безплатен аудио кодек без загуба)
Аудиото на маймуната (APE)
TTA (Истинско аудио)
TTE
LA(LosslessAudio)
RealAudio Без загуба
WavPack и други
Както забелязахте, повечето кодеци за компресия без загуби използват два (понякога повече) различни типа алгоритми: единият генерира статистически модел за входните данни, другият показва входните данни в малко представяне, използвайки модела за получаване на „вероятностни“ (тоест често срещани) данни, които се използват по-често, отколкото „невероятни“. Полза - намаляване на размера, изчисляване - повече време на процесора, необходимо за кодиране / декодиране.
Когато измислим малко теория, ще преминем към нашите кодеци за компресиране на аудио данни, които са написани от много хора: Безплатен аудио кодек без загуба, WavPack, TAK, Monkey's Audio (.ape, apl), OptimFROG (.ofr), Apple Lossless Audio Codec, WMA, Shorten (.SHN), LosslessAudio, True Audio, предсказуем аудио кодър (.LPAC), MPEG-4 ALS, MPEG-4 SLS (.mp4), Real Lossless или RealAudio Lossless, Windows Media Audio Lossless, DTS .. И това далеч не е всичко, много компании, произвеждащи професионална звукозаписна техника, изобретени и продължават да измислят свои собствени формати.
Толкова много формати за компресиране на аудио данни са причинени от технически несъвършенства на платформите (повечето от изброените кодеци са написани в края на 90-те), маркетинга (в случая на ALAC) и математическата и университетската аудитория са силно заинтересовани от алгоритмите за компресиране на данни.
В допълнение към горното, има (съществуват) много много забравени заслужено или не заслужено аудио архиватори и аудио кодеци. Техническите характеристики на някои от тях могат да бъдат намерени в таблицата:
може да се кликва:
Ще разгледаме по-подробно само онези, които са широко използвани и които към момента на писането могат да бъдат намерени в Интернет. Има само десетина от тях.
Част II - ПРАКТИКА:
Отляво надясно: 1. синя зона SSDS (Sony Dynamic Digital Sound), 2. сива зона Dolby Digital (между перфорирането), 3. аналогов аудио (както е записан) и 4. времеви код DTS (син).
И ето едно ново сравнение за 2009 г. на девет от горните:
Част III. - ИЗПИТВАНЕ:
Сравнението беше извършено на платформата:
Процесор: DualCore Intel Core i3 530, 2933 MHz (x86, x86-64, MMX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2)
Дънна платка. дъска: Asus P7H55-V
RAM: 2x2Gb DDR3-1333
HDD: Seagate SATA 160GB 8 MB кеш (система), Hitachi SATA-II 500GB 16 MB кеш (източник), Hitachi SATA-II 1000GB 32 MB кеш (дестинация)
1. Аудио без загуби (LA) - Този много стар кодек (2004) стана безспорен победител в компресията. В същото време трябва да се отбележи, че скоростта на кодиране е доста приемлива (в сравнение със същия OptimFROG или WavPack), както и достатъчна скорост на декодиране. Въпреки че LA файлът не е декодиран с помощта на плъгин foo_benchmark, той играеше перфектно, без спънки или забавяне на превъртане.
Човек може само да се чуди защо авторът се е отказал от такъв красив кодек, без дори да отвори изходния код.
2. OptimFROG - Не много далеч зад Ел Ей. Но скоростта му трудно може да се нарече бърза. В допълнение, голямото закъснение при превъртане през файл е неприятен момент - понякога е много досадно.
3. Аудиото на маймуната - Популярен, но ресурсно интензивен кодек. Той дава наистина висока компресия, но отново има проблеми с превъртането. (Изглежда авторът на теста е захванал файла с опцията „Insane“, която все още е изпълнена със загуба на данни).
4. ТАК - Този активно разработен кодек не престава да угажда. Ако вземете предвид и трите параметъра (компресия, кодиране, декодиране), TAK изглежда най-привлекателен. Високата скорост на работа се обяснява с активното използване на процесорни оптимизации (включително SSSE3). А използването на две ядра дава почти двукратно увеличение на скоростта на кодиране! По този начин, в случая с TAK, предимството на използването на съвременни процесори е най-забележимо.
5. WavPack - за да бъда честен, не знам защо този кодек придоби популярност. Кодирането със средна компресия дава резултати, сравними с FLAC, а използването на режими на висока компресия води до неоправдано намаляване на скоростта. Въпреки че основното предимство на този кодек е неговата широка поддръжка и функционалност (включително поддръжка за многоканално аудио, хибриден режим), но ви напомням, че не разглеждаме тази страна на проблема в този тест.
6. Истинско аудио (TTA) - тук трябва да се отбележи, освен че много висока скорост на кодиране и приемлив коефициент на компресия (малко по-висок от този на FLAC). Освен това скоростта на декодиране не може да се нарече много висока.
7. FLAC- съотношението на компресия е средно, но скоростта на декодиране е доволна. Вярно е, че основната причина за лидерството на този кодек сред обществеността е отворен код и в резултат на това най-широката хардуерна / софтуерна поддръжка.
8. Apple Lossless (ALAC) - Един от онези кодеци, които не са забележителни, но продължават да се имплантират активно от разработчиците (в случая Apple). Ниска скорост на компресия и декодиране. Скоростта на компресия е средна. С изключение на потребителите на iPod, те просто нямат избор.
9. Wma загуба - Случай, подобен на ALAC, но тук имаме работа с гигантската корпорация Microsoft. Още по-малко компресия, средна степен на компресия. Скоростта на декодиране е сравнително висока. Трудно е да си представим случай, в който би било необходимо да се използва този кодек без загуби.
Част IV - ОБЩИ ЗАКЛЮЧЕНИЯ:
Изборът е прост и се състои от две точки:
Ако дисковото пространство е важно, използваме аудиото на Monkey's (ARE компресира 8-12% по-добре от FLAC, което на 1TB диск ще бъде около 100 GB или около 300 стандартни CD албума). Същото се отнася и за разпространение в Интернет. Съхранявам колекцията си той е в аудио формат на Маймуна с опция за изключително високо компресиране. Не използвам различни LA и други, защото печалбата от използването им в сравнение с Audio Monkey е малка.
Ако е важна съвместимостта с различни плейъри и медии, които работят под Linux и не използвайте само FLAC. Въпреки че IMHO за плейърите е доста подходящ за себе си и MP3, защото основното не е звук, а МУЗИКА!
В бъдеще ще разгледаме развитието на TTA, но моето субективно мнение е, че TTA вече закъсня за парния локомотив до „разстоянието без дом“.
За „макови шофьори“ и „Ай-шрифтове“ - изборът, доколкото знам досега, е един - тамбур и танци около различни транскодери във формат ALAC.
И не забравяйте, че винаги можете да прехвърляте файлове от един кодек в друг и без загуба на качество това е, което кодеците за компресия без загуби са добри за разлика от кодеците със загуба на компресия.
Отклонение "лирически" номер ПОСЛЕД.
За „Удифилов“. Разлики в звуковите формати - НЕ! „Не естественият цвят на високото“, „лесна нечетливост на удара“, като „булото на средата с размазването на сцената“ - това е във вашата СИСТЕМА. Кодеци не играят, те декодират, не добавят нищо и не изтриват нищо.
Дигресията е "лиричен" номер ДВА.
Тази статия е написана за любителите на музиката и колекционерите на музика - начинаещи и средни селяни, същия любител на музиката и колекционер.
Gurams, Kvods, Sensei и други велики кормчии от света на аудиото, както и войнствените Udifils, няма да се интересуват тук. Напишете статията си "с блекджек и кодеци."
Интересна информация:
В момента 1154 разширения на файлове са регистрирани по един или друг начин, свързани с аудио данни!
източници:
wiki.hydrogenaudio.org/
ru.wikipedia.org/
както и официални сайтове за програми.
Добър ден.
Днес искам да засегна темата за компресиране на данни без загуби. Въпреки факта, че вече има статии за хъба, посветени на определени алгоритми, исках да говоря за това малко по-подробно.
Ще се опитам да дам както математическо описание, така и описание по обичайния начин, така че всеки да намери нещо интересно за себе си.
В тази статия ще засегна основните моменти на компресия и основните видове алгоритми.
Компресия. Необходимо ли е в днешно време?
Да, разбира се. Разбира се, всички ние разбираме, че сега можем да имаме достъп както до големи обеми за съхранение, така и до високоскоростни канали за предаване на данни. Същевременно обаче нараства обемът на предаваната информация. Ако преди няколко години гледахме 700-мегабайтови филми, които се побират на един диск, днес HD-качествените филми могат да заемат десетки гигабайти.
Разбира се, ползите от компресирането на всичко и всичко не са толкова много. Но все още има ситуации, в които компресията е изключително полезна, ако не е необходима.
- Изпращане на имейли на документи (особено големи обеми документи, използващи мобилни устройства)
- При публикуване на документи на уебсайтове, необходимостта да се спести трафик
- Спестете място на диска при смяна или добавяне на място за съхранение е трудно. Например това се случва в случаите, когато не е лесно да получите бюджет за капиталови разходи и няма достатъчно дисково пространство.
Разбира се, можете да измислите още много различни ситуации, в които компресията ще бъде полезна, но тези няколко примера са ни достатъчни.
Всички методи за компресия могат да бъдат разделени на две големи групи: компресия на загуба и компресия без загуби. Компресирането без загуби се използва в случаите, когато информацията трябва да бъде възстановена точна до битове. Този подход е единственият възможен при компресиране например на текстови данни.
В някои случаи обаче не се изисква точно възстановяване на информация и е позволено да се използват алгоритми, които осъществяват компресия на загуби, която, за разлика от компресирането без загуби, обикновено е по-лесна за изпълнение и осигурява по-висока степен на архивиране.
Така че, да преминем към алгоритмите за компресия без загуби.
Универсални методи за компресия без загуби
В общия случай има три основни опции, върху които са изградени алгоритми за компресия.
Първа група методи - преобразуване на потоци. Това предполага описание на новите входящи некомпресирани данни през вече обработените. В този случай не се изчисляват вероятности, кодирането на символи се извършва само въз основа на данните, които вече са обработени, като например в методите на LZ (кръстени на Авраам Лемпел и Яков Жива). В този случай вторият и следващите събития на подреда, която вече е известна на енкодера, се заменят с препратки към първото му възникване.
Втора група методите са методи за статистическа компресия. От своя страна тези методи са разделени на адаптивни (или поточни) и блокови.
В първата (адаптивна) версия изчисляването на вероятностите за новите данни се основава на данните, които вече са обработени по време на кодирането. Тези методи включват адаптивни версии на алгоритмите на Huffman и Shannon-Fano.
Във втория (блок) случай статистиката на всеки блок данни се изчислява отделно и се добавя към най-компресирания блок. Те включват статични версии на методите на Huffman, Shannon-Fano и аритметично кодиране.
Трета група методите са така наречените методи за преобразуване на блокове. Входящите данни са разделени на блокове, които след това се трансформират като цяло. Въпреки това, някои методи, особено базирани на пермутация на блокове, може да не доведат до значително (или дори каквото и да е) намаляване на количеството данни. След такава обработка обаче структурата на данните се подобрява значително и последващото компресиране от други алгоритми е по-успешно и по-бързо.
Общи принципи, на които се основава компресирането на данни
Всички методи за компресиране на данни се основават на прост логически принцип. Ако си представим, че най-често срещаните елементи са кодирани с по-къси кодове, а по-рядко срещаните се кодират с по-дълги, тогава всички данни ще се нуждаят от по-малко място за съхранение, отколкото ако всички елементи бяха представени с кодове с еднаква дължина.
Точната връзка между честотите на възникване на елементи и оптималните дължини на кода е описана в така наречената теорема за кодиране на източника на Шенън, която определя максималната граница на компресия без загуба и ентропията на Шанън.
Малко математика
Ако вероятността за възникване на елемент s i е равна на p (s i), тогава ще бъде най-изгодно да се представи този елемент - log 2 p (s i) бита. Ако по време на кодирането е възможно да се гарантира, че дължината на всички елементи е намалена до log 2 p (s i) бита, тогава дължината на цялата кодирана последователност ще бъде минимална за всички възможни методи на кодиране. Освен това, ако вероятностното разпределение на всички елементи F \u003d (p (s i)) е непроменено и вероятностите на елементите са взаимно независими, тогава средната дължина на кодовете може да бъде изчислена като
Тази стойност се нарича ентропия на разпределението на вероятността F или ентропия на източника в даден момент от време.
Обаче обикновено вероятността от появата на даден елемент не може да бъде независима, напротив, зависи от някои фактори. В този случай за всеки нов кодиран елемент s i разпределението на вероятността F ще приеме някаква стойност F k, тоест за всеки елемент F \u003d F k и H \u003d H k.
С други думи, можем да кажем, че източникът е в състояние k, което съответства на определен набор от вероятности p k (s i) за всички елементи s i.
Следователно, като се има предвид тази корекция, можем да изразим средната дължина на кодовете като
Където P k е вероятността за намиране на източника в състояние k.
И така, на този етап знаем, че компресията се основава на заместване на често срещащи се елементи с кратки кодове и обратно, а също така знаем как да определим средната дължина на кодовете. Но какво е код, кодиране и как се случва?
Кодиране без памет
Кодовете без памет са най-простите кодове, въз основа на които могат да се компресират данни. В незапомнен код всеки символ в кодирания вектор на данни се заменя с кодираща дума от набор от префикси на двоични последователности или думи.
Според мен не е най-ясното определение. Разгледайте тази тема по-подробно.
Нека се даде някаква азбука ![]() състоящ се от някакъв (краен) брой букви. Ние наричаме всяка крайна последователност от знаци от тази азбука (A \u003d a 1, 2, ..., a n) с една дума, а числото n е дължината на тази дума.
състоящ се от някакъв (краен) брой букви. Ние наричаме всяка крайна последователност от знаци от тази азбука (A \u003d a 1, 2, ..., a n) с една дума, а числото n е дължината на тази дума.
Нека бъде дадена и друга азбука ![]() , По същия начин, обозначавайте думата в тази азбука като B.
, По същия начин, обозначавайте думата в тази азбука като B.
Въвеждаме още две нотация за набора от всички непусти думи в азбуката. Нека - броят на празните думи в първата азбука, и - във втората.
Нека се даде и картографиране F, което свързва с всяка дума A от първата азбука дума B \u003d F (A) от втората. Тогава ще бъде наречена думата Б код думи A и преходът от оригиналната дума към нейния код ще бъде извикан кодиране.
Тъй като думата може да се състои и от една буква, можем да идентифицираме съответствието на буквите от първата азбука и съответните думи от втората:
a 1<-> Б 1
a 2<-> B 2
…
a n<-> B n
Този мач се нарича схема, и обозначаваме ∑.
В този случай думите B 1, B 2, ..., B n се наричат елементарни кодовеи вида на кодирането с тяхна помощ - азбучно кодиране, Разбира се, повечето от нас са се сблъскали с този вид кодиране, дори да не знаем всичко, което описах по-горе.
И така, решихме концепциите азбука, дума, код, и кодиране, Сега въвеждаме концепцията префикс.
Нека думата B има формата B \u003d B "B" ". Тогава B" се нарича началото, или префикс думите B и B "" - неговият край. Това е доста проста дефиниция, но трябва да се отбележи, че за всяка дума B може да се счита както начална, така и крайна дума както празна дума ʌ („интервал“), така и самата дума Б.
И така, ние се приближаваме до разбирането на дефиницията на кодовете без памет. Последната дефиниция, която трябва да разберем, е набор от префикси. Схема ∑ има свойството на префикс, ако за всеки 1≤i, j≤r, i ≠ j, думата B i не е префикс на думата B j.
Просто казано, набор от префикси е краен набор, в който никой елемент не е префиксът (или началото) на който и да е друг елемент. Прост пример за такъв набор е например обикновената азбука.
И така, измислихме основните дефиниции. И така, как се случва самото безконтактно кодиране?
Проявява се на три етапа.
- Съставя се азбука the от знаците на оригиналното съобщение и символите на азбуката се сортират в низходящ ред по вероятността им да се появят в съобщението.
- Всеки символ a i от азбуката Ψ се свързва с определена дума B i от префикса набора Ω.
- Всеки символ е кодиран, последвано от комбиниране на кодовете в един поток от данни, което ще бъде резултат от компресиране.
Един от каноничните алгоритми, които илюстрират този метод, е алгоритъмът на Хафман.
Алгоритъм на Хафман
Алгоритъмът на Huffman използва честотата на възникване на едни и същи байтове във входния блок данни и съвпада с честите блокове от верига битове с по-къси дължини и обратно. Този код е минимално излишен. Помислете за случая, когато независимо от входния поток азбуката на изходния поток се състои само от 2 знака - нула и един.
На първо място, когато кодираме с алгоритъма на Huffman, трябва да конструираме веригата ∑. Това се прави, както следва:
- Всички букви от входната азбука са подредени в низходящ ред на вероятност. Всички думи от азбуката на изходния поток (тоест това, което ще кодираме) първоначално се считат за празни (припомням, че азбуката на изходния поток се състои само от знаци (0,1)).
- Два знака j-1 и j на входящия поток, които имат най-малка вероятност за поява, се комбинират в един „псевдосимвол“ с вероятност р равна на сумата от вероятностите на съставните й знаци. След това добавяме 0 към началото на думата B j-1 и 1 към началото на думата B j, която впоследствие ще бъде кодовете на символите съответно j-1 и j.
- Премахваме тези знаци от азбуката на оригиналното съобщение, но добавяме генерирания псевдо-символ към тази азбука (естествено, тя трябва да бъде вмъкната в азбуката на правилното място, като се вземе предвид вероятността й).
Стъпки 2 и 3 се повтарят, докато в азбуката не остане само 1 псевдо символ, съдържащ всички оригинални знаци от азбуката. Освен това, тъй като на всяка стъпка и за всеки знак съответната дума B i се променя (чрез добавяне на едно или нула), след като приключи тази процедура, определен код B i ще съответства на всеки начален символ на азбуката a i.
За по-добра илюстрация, помислете за малък пример.
Да предположим, че имаме азбука, състояща се само от четири знака - (a 1, 2, 3, 4). Да приемем също, че вероятностите за възникване на тези символи са равни, съответно, p 1 \u003d 0,5; р 2 \u003d 0,24; р 3 \u003d 0,15; p 4 \u003d 0,11 (сумата от всички вероятности очевидно е равна на единица).
Така че ние ще изградим схемата за тази азбука.
- Комбинирайте двата знака с най-малко вероятности (0,11 и 0,15) в p „псевдо-символ“.
- Ние комбинираме двата знака с най-малка вероятност (0,24 и 0,26) в p псевдо символа.
- Премахваме комбинираните знаци и вмъкваме получения псевдо символ в азбуката.
- Накрая комбинирайте останалите два знака и вземете върха на дървото.
Ако илюстрирате този процес, получавате нещо като следното:
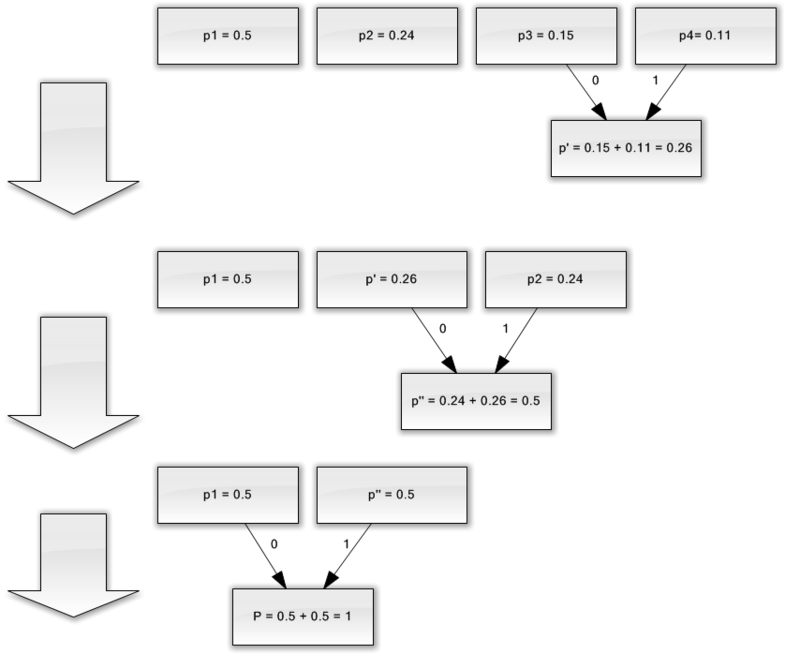
Както можете да видите, с всяко сливане ние присвояваме знаците 0 и 1 на героите, които трябва да бъдат обединени.
По този начин, когато дървото е изградено, лесно можем да получим кода за всеки символ. В нашия случай кодовете ще изглеждат така:
a 1 \u003d 0
a 2 \u003d 11
a 3 \u003d 100
a 4 \u003d 101
Тъй като никой от тези кодове не е префикс на който и да е друг (тоест получихме прословутия набор от префикси), можем еднозначно да идентифицираме всеки код в изходния поток.
И така, ние постигнахме, че най-честият символ се кодира от най-краткия код и обратно.
Ако приемем, че първоначално един байт е бил използван за съхранение на всеки символ, тогава можем да изчислим колко успяхме да намалим данните.
Да предположим, че имахме низ от 1000 знака на входа, в който символът a 1 е възникнал 500 пъти, 2 240, 3 150 и 4 110 пъти.
Първоначално този низ е заемал 8000 бита. След кодирането получаваме низ с дължина ∑p i l i \u003d 500 * 1 + 240 * 2 + 150 * 3 + 110 * 3 \u003d 1760 бита. Така че успяхме да компресираме данните 4,54 пъти, изразходвайки средно 1,76 бита за кодирането на всеки символ на потока.
Нека ви напомня, че според Шанън средната дължина на кодовете е ![]() , Замествайки стойностите на вероятността в това уравнение, получаваме средната дължина на кода равна на 1.75496602732291, което е много, много близко до получения резултат.
, Замествайки стойностите на вероятността в това уравнение, получаваме средната дължина на кода равна на 1.75496602732291, което е много, много близко до получения резултат.
Независимо от това, трябва да се има предвид, че в допълнение към самите данни трябва да съхраняваме таблицата за кодиране, което леко ще увеличи крайния размер на кодираните данни. Очевидно е, че в различни случаи могат да се използват различни вариации на алгоритъма - например понякога е по-ефективно да се използва предварително определена таблица на вероятностите, а понякога е необходимо да се компилира динамично, като се преминат през компресивни данни.
заключение
И така, в тази статия се опитах да говоря за общите принципи, чрез които се получава компресиране без загуби, и разгледах един от каноничните алгоритми - кодирането на Huffman
Ако статията е по вкуса на хабро-общността, тогава ще се радвам да напиша продължение, тъй като има много повече интересни неща относно компресията без загуби; това са както класически алгоритми, така и предварителни трансформации на данни (например трансформацията на Burroughs-Wheeler), и, разбира се, специфични алгоритми за компресиране на звук, видео и изображения (най-интересната тема според мен).
литература
- Ватолин Д., Ратушняк А., Смирнов М. Юкин В. Методи за компресиране на данни. Архиватори на устройства, компресия на изображения и видео; ISBN 5-86404-170-X; 2003 година
- Д. Саломон. Компресиране на данни, изображения и звук; ISBN 5-94836-027-X; 2004 година.
Кодеци, които компресират звук без загуба, станаха сравнително популярни в света на преносими MP3 плейъри. Факт е, че тези кодеци не могат да си позволят толкова големи съотношения на компресия, с които кодеци, които компресират звук със загуба на качество, могат да се похвалят. Големите количества памет станаха широко достъпни за потребителите на MP3 плейъри само през последните три или четири години - и с появата на големи количества памет в MP3 плейърите, компресирането на музика без загуби стана популярно. Разбира се, тези, които искаха да слушат музика без загуба на качество, винаги правеха това (например, използвайки аудио CD плейъри) и в днешно време всички (естествено, с подкрепата на съответните кодеци от своите плейъри) могат да изпробват кодеци без загуба в действие ,
Основната разлика между кодеци, които компресират аудио данни без загуба на качество от кодеци, които се компресират със загуба е, че кодеците без загуба на качество не премахват информация от аудио потока, която може да се счита за излишна, когато се компресира със загуба. Основната задача на кодека Lossless е да компресира максимално оригиналната звукова информация, без да губи нито един бит информация.
Понастоящем ситуацията с поддръжката на кодеци без загуби е най-разпространената поддръжка на кодека ALAC, който е пряко свързан с Apple и неговите играчи. Останалите кодеци все още се поддържат от малко играчи, понякога за да може плейърът да поддържа кодека, плейърът изисква да мига плейъра и може би най-известният фърмуер за играчи, който поддържа кодеци без загуби, RockBox е алтернативен, а не официален фърмуер.
Когато работите с кодеци без загуба, може да видите така наречените Cue файлове или картотеки с индекс на файлове. Cue-файловете се разпространяват например, заедно с FLAC или APE-файлове, по-рядко - с MP3 и WAV-файлове, които са един голям (около 300 MB) файл, в който се съхранява целият албум. Cue - файл - съдържа информация за разделянето на голям файл на песни и имената на тези песни. По-удобно е да работите с отделни файлове, но дори и да получите в ръцете си, да речем, голям FLAC файл с CUE файл, въз основа на информацията, съдържаща се в CUE файла, изходният файл може да бъде разделен на отделни песни - ще разгледаме софтуер, който може да реши този проблем.
Нека започнем описанието на формати за компресиране на данни без загуби с популярния FLAC формат.
FLAC
FLAC (Free Lossless Audio Codec) е формат за компресиране на аудио без загуби, разработен от Xiph. Фондация за орги Това е абсолютно безплатен формат, който всеки може да използва.
Работата на FLAC и други кодеци, които съхраняват аудио данни без загуби, прилича на тази на конвенционалните архиватори. Поради специални алгоритми, ефективността на такива кодеци при компресиране на аудио информация е много по-висока от тази на конвенционалните архиватори.
Форматът FLAC е разработен като формат на потока - информацията във файла FLAC е разделена на рамки (кадри), всеки от които може да бъде декодиран отделно от други кадри.
Обикновено FLAC е в състояние да компресира изходния файл, например, качеството на аудио CD с 40-50%. В резултат на това битрейтът на получения запис е равен на около 800 Kbit / s.
Във формат FLAC е възможно да запишете компактдискове по такъв начин, че да можете да пресъздадете напълно оригиналния диск, ако е необходимо - това е много удобно за тези, които искат да създадат цифрови копия на своите компактдискове с възможност за последващо възстановяване.
Скоростта на кодиране и декодиране на FLAC файлове не е една и съща. Скоростта на кодиране зависи от нивото на компресия и от скоростта на системата - при високи нива на компресия тя може да бъде доста бавна. Декодирането обаче е много бързо - съвременните MP3 плейъри могат лесно да се справят с него.
Поради възможността за безплатна безплатна употреба, можете да работите с FLAC въз основа на почти всяка съвременна ОС, все повече MP3 плейъри поддържат този формат.
Кодиране във FLAC формат
Можете да изтеглите помощната програма за кодиране на FLAC файлове на адрес. Той включва самия кодек и така наречения Frontend - софтуерна обвивка за кодека. Размерът на дистрибуцията отнема около 2,5 MB. Работата с кодека е проста: добавяте желаните от вас файлове в прозореца на програмата (фиг. 4.1.) Използвайки бутона Добавяне на файлове, конфигурирайте опциите за кодиране и щракнете върху бутона Кодиране - програмата създава FLAC файл.
Фиг. 4.1.
Нека разгледаме най-важните настройки на кодека. Първо, нека спрем на групата от параметри на опциите за кодиране.
Параметърът Level е отговорен за нивото на компресия на данни. Тя може да варира от 0 до 8. Колкото по-високо е степента на компресия, съответно, толкова по-малък е готовият файл, но по-дълго време, необходимо за кодиране на файловете. На бързите компютри разликата между ниво 0 и ниво 8 при кодиране, да речем, 30-мегабайт WAV файл може да бъде няколко секунди. Размерът се различава с около 10% от оригиналния размер на файла. Трябва да експериментирате с тази опция на вашия компютър - може би ако кодирате няколкостотин файла, бихте предпочели по-ниско ниво на компресия при по-висока скорост на работа.
Параметърът Verify инструктира енкодера да провери изходните файлове.
Параметърът Добавяне на тагове добавя тагове към готовия файл (например, те могат да съдържат името на песента, автор и т.н.) - можете да ги конфигурирате, като кликнете върху бутона Tag Conf. (Персонализиране на маркери).
Параметърът Replaygain добавя параметър към файловете, който показва нивото на силата на звука на файла. Ако е зададен параметърът „Въвеждане на входни файлове като един албум“, всички записи в албума ще звучат с еднаква сила.
Групата с параметри за общи опции съдържа два параметъра. Може би тук трябва да се отбележи параметърът OGG-Flac. Ако този параметър се нулира, FLAC данните се пакетират в стандартен FLAC контейнер. Ако планирате да слушате само получените FLAC файлове, не можете да зададете този параметър и ако вашите планове за тези файлове са по-обширни - например планирате да ги редактирате, да ги използвате за вмъкване във филми, най-добре е да активирате параметъра Ogg-FLAC.
Параметърът Output Directory съдържа пътя към директорията, в която ще се съдържат изходните файлове.
Групата параметри на опциите за декодиране има параметър декември. Чрез грешки - задайте го, ако искате да декодирате файл, дори ако има грешки по време на декодиране. Декодирането е обратната страна на кодирането - тоест можете да декодирате FLAC файлове, като ги превърнете във WAV файлове. За декодиране, разбира се, ще трябва да добавите FLAC файлове в прозореца на програмата.
След като всичко е конфигурирано, просто щракнете върху бутона Encode, за да създадете FLAC файлове, или ако искате да декодирате съществуващи FLAC файлове, щракнете върху бутона Decode.
В допълнение към горното, други програми могат да кодират FLAC. Например, това вече ви е известно на ImTOO Audio Encoder - за кодиране до FLAC формат, просто го изберете от списъка с формати (фиг. 4.2.), След което можете веднага да кликнете върху бутона Cut или да го направите малко по-късно, след като настроите имената на файловете.

