07.09.2019
Видове кодиране. Кодиране за алкохолизъм - лечение и последствия. Ефективни методи за кодиране на алкохолна зависимост. Последиците от кодирането от алкохолизъм
Модулът за търсене не е инсталиран.
Интернет кодиране и видове шрифтове
Владимир Молочков
Когато работите с интернет или електронна поща, много от вас вероятно вече не веднъж са срещали проблема с избора на кодиране за буквите на руската азбука. Но какво стои зад имена като koi-8r или UTF-8? Замисляли ли сте се как да представите 33 букви от руската азбука от 26 букви на английски?
Процесът на делене на клетките е огромно чудо. Това не е просто раздяла без глава, така че ще създаде само маса, сякаш тестото за хляб се е вдигнало; или нека да разгледаме формата на тумора. Това разделяне е без по-висша цел. В началото на нов живот клетките се делят, очевидно нищо не контролира това разделяне и въпреки това всяка клетка знае каква част от тялото трябва да създаде, каква форма трябва да има и дали клетката е мускулна, костна, кръвна или да се превърне в стъклено око , Камерите знаят в коя посока да споделят и кога да спрат споделянето.
НОВ СРОК
Кодирането е таблица с символи, където на всяка буква от азбуката (както и цифри и специални знаци) е присвоен собствен уникален номер - кодът на знаците.
За да представите текст на екрана на вашия компютър, трябва да зададете определен номер на всеки символ - неговия код. Всички съвременни кодиращи таблици идват от 7-битната таблица на американския стандартен код за обмен на информация (ASCII), появила се през 60-те, която съдържа 33 кода от команди или контролни знаци, повечето от които не се използват днес, и 95 кода за различни символи, достатъчно за работа с английски текстове. При 7-битово кодиране всеки символ е картографиран на 7 бита, тоест число в диапазона от 0 до 127.
Не е очевидно, че в целия процес на растеж всички съседни части на тялото точно съвпадат. Така ацетабулът винаги се адаптира към формата на костта, която се движи в него. Не се случва ацетабулът да се увеличи по един или друг начин с неправилна форма, че костта да изпадне. Всяка отделна взаимосвързана кост в тялото се увеличава по отношение на съседните кости през цялото развитие. Това важи и за очите, сърцето, мозъка и други органи. Разбира се, наблюдаваме този шедьовър на съвършенството в цялото творение.
Това не би било възможно за „случайни“ процеси на променливост, както еволюционистите определят. Сърцето бие около милиард пъти по време на живота на човек. Без спиране, без най-малката пауза. Скоростта на хода се адаптира към напрежението. Сърцето има перфектни камери и клапани и всички вени са правилно свързани. Активността на сърцето е напълно независима от нашето съзнание, тя е напълно автоматична. Ако човек съзнателно се съсредоточи върху всяко сърцебиене, това би бил краят на живота на Земята за дълго време.
Бързото развитие в последните години на хипертекстовите методи за представяне на информация на WWW изостря проблема с представянето и работата с информация на кирилица в електронен вид, която съществува от десетилетие. Това се дължи на първо място на липсата на стандарт за разширен ASCII код - таблица, която включва кодирането на букви на кирилица, както и на разнообразието от решения, предлагани от различни търговски компании.
Така че всичко това, приятели мои, е статистически невъзможно, че това се случи случайно и, разбира се, не при първия опит. Ние само се опитваме да разберем колко умело той е създал Господа. Това е тайната на самия Бог и можем смирено да Му се покланяме. Еволюцията не може да отговори на въпроса какво е първо, яйце или пиле. Това, разбира се, е проблемът на всички същества, излюпени от яйца, тоест змии, птици, костенурки и други. Този проблем на еволюцията изглежда много по-съществен и широко разпространен. Замисляли ли сте се как стана първият бозайник?
Само половината от таблицата на ASCII е стандартизирана, а именно първите 128 знака, които включват буквите на латинската азбука. И никога няма проблем с тях. Втората половина на таблицата (с общо 256 знака - според броя на състоянията, които могат да вземат един байт) е дадена за национални знаци, като във всяка страна тази част е различна. Например в Русия има около 10 различни кодировки. Тоест различен цифров код съответства на един и същ символ и ако неправилно определим кодирането на текста, тогава ще видим напълно нечетлив текст. И въпреки че този проблем наистина съществува, всъщност не е достатъчно да се определи вида на кодирането на текст на практика и много програми, например Stirlitz (фиг. 1), правят това в автоматичен режим.
Къде се разви под дървото? Или някъде в локва на пода? В тялото на майката се появи ли първият лъв? В крайна сметка той беше първият и по това време нямаше майка! Жените, които преживяват бременност с висок риск, могат да ви кажат колко крехко е това нещо. Да се \u200b\u200bмисли за развитието на плода извън тялото на майката е поне утопия. Знаем, че много същества се нуждаят от майка за своето развитие, така че този проблем е много често срещан. Тук виждаме много добре, че основните двигатели на еволюцията, мутацията и естествения подбор придобиват големи пукнатини.
Фиг. 1. Основният прозорец на програмата за разпознаване на кодиране "Stirlitz"
Международният стандарт ISO / IEC 8859-1 понастоящем е заместител на ASCII. В него първите 32 кода с номера 128-159 съответстват на почти неизползвани контролни символи, общи за всички ISO кодиращи таблици. Въпреки че 8859-1 може да се използва за текстове на почти всички западноевропейски езици, той не покрива напълно нуждите на френски и фински. Този недостатък, както и липсата на знак за новата общоевропейска валута, доведоха през 1999 г. до появата на кодиране 8859-15, при което беше използвана нова версия на стойностите на кодовете 8859-1.
Друг мит, който веднага ще опровергаем, е, че развитието на живите същества е достигнало такова ниво на развитие за милиони и милиони години. Нека се опитаме да си представим как се е развил първият, малко по-развит човек. Поради мутацията мъжът се появил след няколко опита. Това обаче не свързва правилно артерията и не оцелява. При друг опит мнозина се провалиха, устата му се срасна и той нямаше дупки в носа, така че се задушава. При друга мутация се появи мъж, който имаше всичко в ред, но очните ябълки не бяха направени от прозрачен материал, така че той не видя нищо и умря от глад, защото не можа да намери храна.
Що се отнася до кирилицата, днес има пет основни таблици за кодиране на руски букви:
За използване с операционната система DOS е разработена кодова таблица CP-866 (IBM / Microsoft). Кодирането CP866 се базира на алтернативното кодиране GOST и е създадено специално за MS-DOS OS, която използва псевдо-графични символи. Днес това кодиране е толкова непопулярно, колкото и MS DOS.
Да кажем, че следващият се роди перфектно, но еволюцията забрави да позволи на мама да развие млечните жлези, така че бедният умря от глад. Следващият забрави да запали сърцето. В друг случай костите не се сближаваха и бяха просто куп плът и кост. В другата липсваше целият черен дроб. В тялото би имало няколко не функциониращи неща наведнъж, а не само едно. Има само неравномерност във физическото състояние или при други обстоятелства и човекът не оцелява.
Всичко може да бъде абсолютно перфектно, но ако само едно малко нещо не е наред, нищо от това няма да бъде. Знаем, че учените се опитаха да кръстосват различни видове, но безрезултатно. Моля, обяснете ми как могат да се развият репродуктивните органи, ако най-малката нередност автоматично доведе до изчезване на този вид, тъй като следващото поколение потомство не би се родило. В същото време цялото тяло трябва да работи на 100%. Или как риба във вода постепенно развива хриле? Ако не работят перфектно, за първи път рибата ще се задуши и еволюцията ще приключи.
За използване в операционната среда на Windows се използва таблицата с кодове CP-1251 (Microsoft). Code Page 1251 за Microsoft Windows стана популярен поради огромното влияние на Microsoft върху пазара на компютърни технологии. Освен това му липсва поддръжка на псевдографски символи в графична среда и е много по-пълна, отколкото в други кодировки; представени са символи като c, R, различни видове кавички, тирета и др. Тази таблица с кодове е основната в Русия днес.
Същото се отнася и за развитието на сърцето и като цяло за голям брой жизненоважни органи. Значи не са милиарди години, а само поколение или по-скоро моментът, в който Бог е създал всичко чрез Словото си. Разбирал ли си някога това? В тази светлина теорията за еволюцията се срива в прах. Хубаво е да наблюдаваме живо същество, както Бог е създал, но виждаме, че тези методи не могат да бъдат обобщени с глобалния житейски принцип.
Ако в очите, вместо фоточувствителни жълти петна, вкусовите рецептори вместо тъпанчето в ухото бяха лещата на окото, бъбреците щяха напълно да отсъстват и вместо пикочния мехур. Как сляпата еволюция знае как да помогне? Както вече показахме, всички органи трябваше да бъдат правилно координирани едновременно. Ето ясни доказателства, че зад всичко това стои един разумен Създател - Бог. Каква е вероятността сляпата еволюция да създаде такъв съвършен организъм чрез случайни изпитания и грешки?
Код страница 10007 - Използва се на компютри Macintosh и почти идентичен по знаци, зададен на CP1251
В UNIX среда най-често срещаната кодова таблица KOI8-R. Това е едно от стандартните кодировки на руския език, прието в Съветския съюз в зората на развитието на компютърните технологии. KOI означава "код за обмен на информация." Числото 8 показва, че този код е 8-битов (за разлика от KOI-7, който се използва широко на съветските компютри). В момента koi8-r е едно от основните кодировки на руски език в операционните системи Linux. Това е второто най-популярно кодиране след CP-1251 (win). Кодирането поддържа псевдографски знаци, заемащи около половината от всички кодове. През 1993 г. таблицата koi8-r беше стандартизирана в Интернет (фиг. 2).
Това е недостижимо за случая. Друго доказателство за т. Нар. Еволюционист е добре известният експеримент Милър-Урей, \u200b\u200bкогато при определени условия електрически заряди създават различни аминокиселини от вода, метан, амоняк и водород. Нуклеиновите киселини обаче не се генерират. Въпреки това беше установено, че в ранните етапи на Земята имаше съвсем различен състав на атмосферата и този експеримент даде напълно различни резултати с този състав. Излишно е да казвам, че такава атмосфера ще убие всяко живо същество.
Разбира се, без Твореца няма творения. Има и такива, които казват, че животът на Земята е извънземен. Разбира се, това не е решение, проблемът просто се премества на друго място. Знаем, че мнозина се опитват да намерят извънземен живот във Вселената. Това усилие се корени и в математическата вероятност, че в такъв голям брой звезди, статистически условия съществуват някъде някъде. Сега виждаме, че не става въпрос за подходящите условия, а за решението на Създателя. Известно е също, че това би било загуба на пространство, ако бяхме единствените в цялата Вселена.
Международният стандарт ISO определя кодовата таблица ISO 8859-5 за Русия. Псевдографията липсва. В момента това кодиране практически не се използва. Поддръжката му обаче присъства във всички браузъри.

Фиг. 2. Набор знаци за представяне на руския език в кодиращата KOI8-R
Колко ще изчезне от безкрайното пространство, ако отделим по-голямата част от него, като нашата вселена? Безкрайността остава безкрайна. Бог не се ограничава до нашето пространство-време и това, което ни се струва гигантско, е знак на Бог. Знаете ли поговорката: "Лист не може да се движи без вятър"? Знаете ли, че това е основно фундаментален научен закон - принципът на причинността, който определя, че всяко явление трябва да има причина? Следователно науката, основана на този закон, трябва да се справи с отговора на въпроса каква е била основната причина.
Какво предизвика Големия взрив или какво науката счита за раждането на Вселената? Според този закон това явление е трябвало да причини нещо. Изглежда, че порочният кръг и науката безпомощно са се отървали от този проблем, поставяйки го във философията. Библията също дава отговор на този въпрос в първата глава на Евангелието от Йоан и в началото на Битие. В началото беше Словото и Словото беше с Бога, и Бог беше Словото. В началото беше същото с Бога. Всичко се прави едно и също и без него не се прави нищо, какво се прави.
ЗАБЕЛЕЖКА
За кодиране на кирилицата могат да се използват още пет таблици, които понастоящем са архаични и нямат международен статус: Основното кодиране е GOST (Държавен стандарт на СССР) от 1987 г. Основният му недостатък е, че псевдо-графичните символи са разположени по различен начин от тези на IBM PC. Алтернативно кодиране на GOST (различава се от CP866 в позиции 242-251). Българско кодиране (получено чрез механично въвеждане на блок от 64 букви от руската азбука в позиции 128-191 CP437). KOI-8 (на IBM PC не е широко разпространен поради не-азбучното подреждане на буквите на кирилицата).
В него имаше живот и животът е светлината на хората. Първият термодинамичен закон гласи, че енергията в затворена система е постоянна. Това означава, че енергията не може да бъде генерирана или унищожена. Това говори за физическия закон. И така, къде е цялата енергия във Вселената? Някои казват, че е дошъл след Големия взрив. Но законът казва, че енергията не може да бъде генерирана! И така, какво избухна и откъде дойде толкова много енергия? Това е и научно доказателство за съществуването на Бог. Само всемогъщият Бог, който няма начало или край, може да произведе такова нещо.
За кодиране на знаци на някои езици, като китайски или японски, 8-битовите числа не са достатъчни. В допълнение, създаването на 8-битови таблици за кодиране в един момент стана почти неконтролируемо: всеки нов компютърен шрифт въвеждаше собствена таблица. Ето защо беше създаден консорциумът Unicode: неговата цел беше да разработи унифицирана система за кодиране за всички възможни символи, която ни позволи да присвояваме кодове на символите на компютърния шрифт по определен шаблон.
Думите му са достатъчни и всичко се случва. Същността на науката е да изследва и установява законите на явленията и процесите около нас, които могат да бъдат доказани и изчислени. Би било неразумно да се каже, че това, което не можем да докажем експериментално, не съществува. И това е спънка за хората. Защото ние само се отваряме и бавно започваме да осъзнаваме, защото Бог наистина мисли и направи всичко. Науката ще спре, ако не признаем, че Бог наистина съществува и че Той е Създателят на всичко.
Изглежда ненаучно и слабо, ако науката признае, че Бог стои зад всичко това, но това е единственият начин. Човек понякога държи в гордостта си за господаря на цялото творение и за върха на мъдростта. Измисляме много странни теории и твърдим, че те са верни и знаем колко сме уязвими към заблуда. Много ясно се виждат теориите на Вселената, частиците на атомното ниво и много други обещаващи теории, които в крайна сметка бяха изключени. Човек, пикът на интелигентността и сътворението. Нека просто да видим какъв човек е измислил и сметнали, че ще бъде перфектен и ефикасен.
Unicode кодирането се основава на UCS (Universal Character Set) каталог на стандартите ISO 10646 и може да съдържа до 231 \u003d 2147483648 различни знака, както и да се попълва. UCS-2 кодовете са двубайтови, тоест числа от 0 до 65535, а UCS-4 са четирибайтови, тоест числа от 0 до 2147483647. Дву и четири байтови кодове Unicode могат да бъдат представени по два начина: байтовете са подредени отляво надясно от най-старите до най-ниските ( Big Endian, BE) или от младши до старши (Little Endian, LE). Вторият метод се среща в огромното мнозинство от случаите. В допълнение, за по-компактно кодиране се използват кодове с променлива дължина UTF-8 (Unicode Transfer Format) 1-6-байт и UTF-16 - дву- или четирибайтови. Последните съществуват също в две форми (Little и Big Endian) и позволяват кодиране на не повече от 220 + 216 \u003d 1114112 символа.
Шедьоври на човешкия гений и въпреки това са неуспешни опити, които не могат да летят и са били копирани от природата. Не се страхувайте да признаете, че има някой, който е по-голям от нас. Това не е признак на слабост, а на зрялост. Всеки човек трябва да може да разпознае какво е резултат от случайността и работата на Създателя. Цялата вселена и следователно всичко, което гледаме само на Земята, е творението на Създателя, но в неживата материя действат само физическите закони, следователно това не е толкова забележимо и се счита за случайно. Между другото, всички закони, физическите константи, са добре настроени и дори самият Айнщайн вярваше, че зад него трябва да има творец.
Сред споменатите кодировки най-широко използваното кодиране е UTF-8, което ви позволява да заобиколите 8 бита за кодиране на ASCII символи и 16 бита за кодиране на знаци в повечето азбучни скриптове, включително руски. Текстовете в ASCII, по-специално на английски, са едновременно текстове в UTF-8. Кодът UTF-8, поредица от байтове, се получава от кода на UCS директория според специфична схема. Например, Unicode символ с код 169 \u003d a916 \u003d 1010 1001 (знак c) е кодиран в UTF-8 като 11000010 10101001 \u003d c216 a916.
Теорията на еволюцията ни заблуди толкова много, че привидно ясното решение вече не е толкова ясно благодарение на многократните прегледи на еволюционистите, които чуваме от всички страни. 100-кратните повтаряни лъжи стават истина. Вземете човек и много други същества, които имат симетрично тяло. И знаем, че това не е строга симетрия, защото вътрешното разположение на органите не е симетрично. Каква е вероятността случайността да създаде такава симетрия? Освен това мъжът и жената са привлекателни и красиви един за друг.
И това се отнася за цялото творение. Женските феромони са много привлекателни за мъжките видове. Еленът не е привлечен сексуално от глиган, а от привлекателна жена и той го посещава, когато е подходящото време. И това сдвояване работи от всякаква природа. Мнозина дори имат смартфон. Това е сложно устройство с процесор, памет, батерия за зареждане, камера с няколко мегапиксела, микрофон, високоговорители и т.н. Той може да извършва изчисления, да съхранява снимки и видеоклипове и да общува. Накратко, много сложно устройство.
Unicode се поддържа изцяло от съвременни програми - браузъри, офис пакети и др. Linux използва UTF-8, а Microsoft Windows също използва UCS-2. Засега поддръжката на UCS в Linux е малко по-слаба, отколкото в Windows 2000 / Me / XP. Основните проблеми при използване на Unicode са липсата на подходящ пълен набор от шрифтове и сложността на въвеждането.
(Тук бих искал да задам на внимателния читател въпроса: „В кое кодиране първо се появи символът EURO?“)
За хармонията на шрифтовете на браузъра и сайта
Има няколко проблема с използването на шрифтове на уеб страници. Първият от тях е хармонията на кодирането на сайтове и браузъри. Сайтовете с браузъри на различни потребители трябва да комуникират в едно и също кодиране, т.е. Браузърът трябва да "разбере" какво го изпраща сайтът. За да направите това, трябва да инсталирате система на сайта, която може да изпрати съобщение за това, в което кодиране на страницата ще бъде изпратена на потребителя. Неговият браузър трябва да приеме това съобщение и да се настрои, за да показва правилно сайта. В този случай можете да посочите кодирането на страницата на сайта директно в HTML кода. За целта използвайте специална версия на етикета META с параметъра charset, който задава желания език. Например за страница, написана в кодиране на Win1251, съответният код ще изглежда така:
Въпреки това методът е много разпространен в Русия, при който уеб сървърът автоматично определя в кодирането на заявката идва от клиента и дава страницата на вече прекодирания уеб браузър. Този META маркер може да изиграе лоша шега тук. Факт е, че инструкциите на страницата имат предимство пред командите, изпратени от уеб сървъра, и правилно кодирайки страницата, сървърът обаче не може да промени съдържанието на META маркера. Има несъответствие между действителното кодиране, в което е дошло кодирането, и инструкциите в META тага. Такава страница не може да бъде нормално преглеждана и кодирана чрез браузъра. Избирането на кодирането ръчно в този случай няма да помогне, защото Маркерът META има предимство пред настройките на браузъра. Единственият начин да направите това е да запазите страницата на диск и след това да изтриете маркера.
В тази връзка в RUNET изобщо не се препоръчва използването на този маркер. В този случай разглеждането ще се извърши в кодирането, на което е конфигуриран браузърът, ако сървърът не изпрати известие за кодирането на документа. В случай на несъответствие, може да се превключи доста лесно. Освен това, ако кодирането по подразбиране е Win-1251, тогава за повечето потребители страницата веднага ще се покаже правилно.
Една мярка за четимост е ширината на реда на документ. С появата на монитори, които поддържат големи разделителни способности на екрана, стана възможно да се "подреждат" до няколкостотин символа в един ред, но линията с "идеална ширина" трябва да се побира около 50-70 знака. С повече от тях скоростта на четене се забавя, а умората настъпва много по-бързо.
Вторият проблем с кодирането може да бъде каскаден лист от стилове (CSS). Известно е, че точният размер на шрифта и другите му атрибути могат да бъдат зададени с помощта на каскадни таблици със стилове (те ще бъдат разгледани в глава 8). Когато използваме CSS, можем да използваме абсолютно всеки шрифт. Но проблемът е, че шрифтовете се вземат от множеството, инсталирано на компютъра на потребителя, а не от сайта. Тоест, наборите на шрифтове в сайта и наборът от шрифтове на потребителя може да не съвпада.
Когато разглеждате сайтове, използвате шрифта, инсталиран в браузъра по подразбиране. За да промените шрифта по подразбиране в Internet Explorer (т.е. Times New Roman) в друг, например в Arial, изпълнете командата Service4 Internet Options 4 Fonts.
Третият възможен проблем е, когато шрифтът на сайта и на компютъра на потребителя е идентичен, но в единия случай е кирилица, а във втория - латиница (неруска версия на шрифта). В този случай текстът ще се показва с някои специални символи и четенето на тези знаци ще бъде проблематично.
За да избегнете подобни проблеми, когато използвате шрифтове в уеб дизайна, трябва да спазвате редица правила:
По-добре е да използвате само стандартни шрифтове, които се доставят с Windows и гарантирано са на машината на клиента. Има три такива шрифта: "Arial", "Times New Roman", "Courier".
Необходимо е правилно да се опишат шрифтовете в таблицата със стилове (CSS) с включване в списъка на други шрифтове, които заместват основния (шрифтове за замяна). В края на списъка трябва да има задължително обозначаване на общото семейство шрифтове (със серифи, серифи без sans, моноразширени и т.н.).
Например:
Като опция да излезете от ситуацията, представете шрифта с графика, например, във формат GIF. И на браузъра, и на операционната система не им пука какво е нарисувано - показването на шрифта като графичен файл на екраните на всички потребители ще бъде идентично (но тук възниква друг проблем - графиките са големи).
От гореизложеното следва, че интернет технологиите налагат специфични ограничения за използването на шрифтове при проектирането на уеб документи и че с нестандартните шрифтове в уеб дизайна трябва да се работи внимателно. За съжаление, в момента няма достатъчно разработени и надеждни средства за уточняване на определена слушалка при представяне на информация под формата на текст на уеб страница.
|
За да може автомобилната аларма, която сте закупили, да се превърне в надеждна защита, трябва да я изберете правилно. Един от основните параметри, влияещ върху работата на алармата, е методът на кодиране на сигнала. В тази статия ще се опитаме да обясним по достъпен начин какво означава динамично кодиране на сигнали и какво диалогов код означава при автомобилни аларми, какъв тип кодиране е по-добър, всеки от които има своите положителни и отрицателни страни.
Динамично кодиране в автомобилни аларми
Конфронтацията между разработчиците на аларми и крадци на автомобили започва от създаването на първите автомобилни аларми. С появата на нови, по-модерни системи за сигурност, средствата за хакване бяха подобрени. Първите аларми имаха статичен код, който лесно се пропукваше чрез метода за избор. Отговорът на разработчиците беше да блокират възможността за избор на код. Следващата стъпка на крекерите беше създаването на грайфери - устройства, които сканираха сигнала от ключодържателя и го възпроизвеждаха. По този начин те дублирали командите от ключалката на собственика, премахвайки колата от защита в подходящия момент. За да предпазят автомобилните аларми от счупване от грабеж, те започнаха да използват динамично кодиране на сигнала.
Принципът на динамичното кодиране
 Динамичният код в автомобилните аларми е непрекъснато променящ се пакет данни, предаван от ключодържателя към алармения блок чрез радиоканала. С всяка нова команда се изпраща код от ключа, който не е бил използван преди това. Този код се изчислява според специфичен алгоритъм, определен от производителя. Най-често срещаният и надежден алгоритъм е Keelog.
Динамичният код в автомобилните аларми е непрекъснато променящ се пакет данни, предаван от ключодържателя към алармения блок чрез радиоканала. С всяка нова команда се изпраща код от ключа, който не е бил използван преди това. Този код се изчислява според специфичен алгоритъм, определен от производителя. Най-често срещаният и надежден алгоритъм е Keelog.
Алармата работи по следния принцип. Когато собственикът на колата натисне бутона на клавиатурата, се генерира сигнал. Той носи информация за броя на кликванията (тази стойност е необходима за синхронизиране на работата на ключодържателя и контролния блок), серийния номер на устройството и секретния код. Преди изпращането тези данни са предварително кодирани. Самият алгоритъм за криптиране е свободно достъпен, но за да декриптирате данните, трябва да знаете секретния код, който се съхранява във фабричния ключ и контролния блок.
Съществуват и оригинални алгоритми, разработени от производителите на аларми. Подобно кодиране на практика елиминира възможността за избор на команден код, но с течение на времето атакуващите заобикалят тази защита.
Какво трябва да знаете за хакване на динамичен код
 В отговор на въвеждането на динамично кодиране в автомобилни аларми е създаден динамичен грайфер. Принципът на неговата работа е да пречи и да прехване сигнала. Когато собственикът на автомобила напусне колата и натисне бутона за клавиш, се създава силна радиосмушка. Сигналът с кода не достига до устройството за управление на алармата, но се прихваща и копира от грайфера. Изненаданият водач натиска отново бутона, но процесът се повтаря и вторият код също се прихваща. Вторият път колата е поставена в отбрана, но командата идва от устройството на крадеца. Когато собственикът на колата спокойно си тръгва за бизнеса си, похитителят изпраща втори, предварително прихванат код и сваля колата от защита.
В отговор на въвеждането на динамично кодиране в автомобилни аларми е създаден динамичен грайфер. Принципът на неговата работа е да пречи и да прехване сигнала. Когато собственикът на автомобила напусне колата и натисне бутона за клавиш, се създава силна радиосмушка. Сигналът с кода не достига до устройството за управление на алармата, но се прихваща и копира от грайфера. Изненаданият водач натиска отново бутона, но процесът се повтаря и вторият код също се прихваща. Вторият път колата е поставена в отбрана, но командата идва от устройството на крадеца. Когато собственикът на колата спокойно си тръгва за бизнеса си, похитителят изпраща втори, предварително прихванат код и сваля колата от защита.
Каква защита се използва за динамичен код
 Производителите на автомобилни аларми са решили проблема с хакване доста просто. Те започнаха да монтират два бутона на дрънкулките, единият от които постави колата на защитата, а вторият - деактивира защитата. Съответно бяха изпратени различни кодове за задаване и премахване на защита. Следователно, без значение колко намеса крадецът поставя, когато настройва машината за защита, той никога няма да получи кода, необходим за деактивиране на алармата.
Производителите на автомобилни аларми са решили проблема с хакване доста просто. Те започнаха да монтират два бутона на дрънкулките, единият от които постави колата на защитата, а вторият - деактивира защитата. Съответно бяха изпратени различни кодове за задаване и премахване на защита. Следователно, без значение колко намеса крадецът поставя, когато настройва машината за защита, той никога няма да получи кода, необходим за деактивиране на алармата.
Ако сте кликнали върху бутона „настроен за защита“ и колата не е отговорила, тогава може би сте станали мишена на похитителя. В този случай не е необходимо безмислено да натискате всички бутони на ключодържателя, в опит да поправите по някакъв начин ситуацията. Достатъчно е отново да натиснете бутона за защита. Ако случайно кликнете върху бутона „премахване от защита“, крадецът ще получи необходимия му код, който скоро ще използва и открадне колата ви.
Алармите с динамично кодиране вече са донякъде остарели, те не осигуряват сто процента защита на автомобила от кражба. Те бяха заменени от устройства с интерактивно кодиране. Ако сте собственик на евтин автомобил, тогава няма нужда да се притеснявате, тъй като е много малко вероятно крадец, оборудван с най-модерното оборудване, да посегне на вашия имот. За да защитите вашия имот, използвайте защита на много нива. Инсталирайте по избор. Той ще осигури защита на автомобила в случай на хакване на автомобилни аларми.
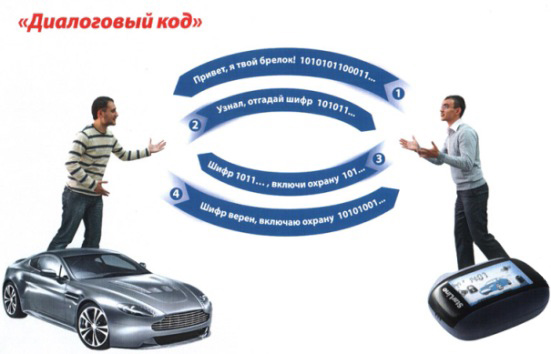
Диалогово кодиране в астросигнали
 След появата на динамични грайфери автомобилните аларми, работещи на динамичен код, стават много уязвими за нападателите. Освен това е бил хакнат голям брой алгоритми за кодиране. За да защитят автомобила от хакване от такива устройства, разработчиците на аларми започнаха да използват диалогово кодиране на сигнали.
След появата на динамични грайфери автомобилните аларми, работещи на динамичен код, стават много уязвими за нападателите. Освен това е бил хакнат голям брой алгоритми за кодиране. За да защитят автомобила от хакване от такива устройства, разработчиците на аларми започнаха да използват диалогово кодиране на сигнали.
Принципът на кодиране на диалога
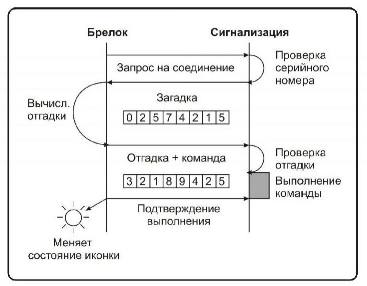 Както подсказва името, този тип криптиране се осъществява в диалогов режим между ключовете и контролния блок за аларма на автомобила, разположен в автомобила. Когато натиснете бутона, от ключалката се изпраща заявка за изпълнение на командата. За да може устройството за управление да се увери, че командата е дошла от ключовия панел на собственика, той изпраща сигнал на произволен номер към ключа. Този номер се обработва съгласно специфичен алгоритъм и се изпраща обратно към контролния блок. По това време управляващото устройство обработва същия номер и сравнява резултата си с резултата, изпратен от ключовата част. Ако стойностите съвпадат, контролното устройство изпълнява командата.
Както подсказва името, този тип криптиране се осъществява в диалогов режим между ключовете и контролния блок за аларма на автомобила, разположен в автомобила. Когато натиснете бутона, от ключалката се изпраща заявка за изпълнение на командата. За да може устройството за управление да се увери, че командата е дошла от ключовия панел на собственика, той изпраща сигнал на произволен номер към ключа. Този номер се обработва съгласно специфичен алгоритъм и се изпраща обратно към контролния блок. По това време управляващото устройство обработва същия номер и сравнява резултата си с резултата, изпратен от ключовата част. Ако стойностите съвпадат, контролното устройство изпълнява командата.
Алгоритъмът, чрез който се извършват изчисленията на ключодържателя и контролния блок, е индивидуален за всяка аларма на автомобила и е заложен в него в друга фабрика. Нека разберем най-простият алгоритъм:
X ∙ T 3 - X ∙ S 2 + X ∙ U - H \u003d Y
T, S, U и H са номера, които са вградени в алармата във фабриката.
X е произволно число, което се изпраща от управляващото устройство до ключовото устройство за проверка.
Y е числото, изчислено от управляващото устройство и ключодържателя според даден алгоритъм.
Нека да разгледаме ситуацията, когато собственикът на алармата натисна бутон и от ключодържателя беше изпратена заявка до контролния блок за разоръжаване на автомобила. В отговор контролното устройство генерира произволно число (например, вземете числото 846) и го изпрати на ключодържателя. След това контролното устройство и ключодържателят извършват изчислението на числото 846 според алгоритъма (например, изчисляваме според най-простия алгоритъм, даден по-горе).
За изчисления вземаме:
Т \u003d 29, S \u003d 43, U \u003d 91, Н \u003d 38.
Ще успеем:
846∙24389 - 846∙1849 + 846∙91- 38 = 19145788
Keyfob ще изпрати номера (19145788) на контролния блок. В същото време контролното устройство ще извърши същото изчисление. Числата ще съвпадат, контролното устройство ще потвърди командата keyfob и машината ще се дезактивира.
 Дори за да декриптирате описания по-горе елементарен алгоритъм, ще бъде необходимо да прехванете пакети данни четири пъти (в нашия случай четири неизвестни в уравнението).
Дори за да декриптирате описания по-горе елементарен алгоритъм, ще бъде необходимо да прехванете пакети данни четири пъти (в нашия случай четири неизвестни в уравнението).
Почти невъзможно е да се прихване и дешифрира пакет данни от диалогови аларми за автомобили. За кодиране на сигнал се използват така наречените хеш функции - алгоритми, които преобразуват низове с произволна дължина. Резултатът от това криптиране може да съдържа до 32 букви и цифри.
По-долу са резултатите от криптирането на числата с помощта на най-популярния алгоритъм за криптиране MD5. Например, числото 846 и неговите модификации са взети.
MD5 (846) \u003d;
MD5 (841) \u003d;
MD5 (146) \u003d.
Както можете да видите, резултатите от кодирането на числа, които се различават само в една цифра, са напълно различни един от друг.
Подобни алгоритми се използват в съвременните интерактивни автомобилни аларми. Доказано е, че за обратното декодиране и получаване на алгоритъм, съвременните компютри ще се нуждаят от повече от век. И без този алгоритъм ще бъде невъзможно да се генерират кодове за проверка, за да се потвърди командата. Следователно сега и в близко бъдеще хакването на диалогов код е невъзможно.
Алармите, работещи върху диалоговия код, са по-безопасни, не подлежат на електронно хакване, но това не означава, че колата ви ще бъде напълно безопасна. Може случайно да загубите ключодържателя или той ще бъде откраднат от вас. За да се увеличи нивото на защита, е необходимо да се използват допълнителни средства, като и.

