29.06.2019
Hangi ses formatı en iyisidir. “Kayıpsız” nedir veya Kayıpsız müzik sıkıştırması hakkında
İyi günler.
Bugün kayıpsız veri sıkıştırma konusuna değinmek istiyorum. Hub üzerinde belirli algoritmalara ayrılmış makaleler olmasına rağmen, bu konuda biraz daha ayrıntılı olarak konuşmak istedim.
Her zamanki gibi hem matematiksel bir açıklama hem de bir açıklama vermeye çalışacağım, böylece herkes kendileri için ilginç bir şeyler bulabilir.
Bu makalede temel sıkıştırma anlarına ve ana algoritma türlerine değineceğim.
Sıkıştırma. Bugünlerde gerekli mi?
Evet, elbette. Tabii ki hepimiz artık hem büyük hacimli depolama ortamlarına hem de yüksek hızlı veri iletim kanallarına erişebildiğimizi anlıyoruz. Ancak, aynı zamanda, iletilen bilgi hacimleri de artmaktadır. Birkaç yıl önce bir diske uyan 700 megabaytlık filmler izleseydik, bugün HD kalitesinde filmler onlarca gigabayt kaplayabilir.
Tabii ki, her şeyi ve her şeyi sıkıştırmanın faydaları çok fazla değil. Ancak, gerekirse, sıkıştırmanın son derece yararlı olduğu durumlar vardır.
- Belgeleri e-postayla gönderme (özellikle mobil cihazları kullanan çok sayıda belge)
- Web sitelerinde doküman yayınlarken trafikten tasarruf etme ihtiyacı
- Depolama alanı değiştirirken veya eklerken disk alanından tasarruf etmek zordur. Örneğin, bu, sermaye harcamaları için bir bütçe almanın kolay olmadığı ve yeterli disk alanı olmadığı durumlarda olur.
Tabii ki, sıkıştırmanın yararlı olacağı daha birçok farklı durum ortaya çıkarabilirsiniz, ancak bu birkaç örnek bizim için yeterlidir.
Tüm sıkıştırma yöntemleri iki büyük gruba ayrılabilir: kayıplı sıkıştırma ve kayıpsız sıkıştırma. Kayıpsız sıkıştırma, bilginin bitlere göre doğru bir şekilde geri yüklenmesi gerektiği durumlarda kullanılır. Bu yaklaşım, örneğin metin verileri sıkıştırılırken mümkün olan tek yaklaşımdır.
Bununla birlikte, bazı durumlarda, doğru bilgi kurtarma gerekli değildir ve kayıpsız sıkıştırmanın aksine, genellikle kaybı daha kolay olan ve daha yüksek bir arşivleme sağlayan kayıplı sıkıştırma uygulayan algoritmaların kullanılmasına izin verilir.
Şimdi kayıpsız sıkıştırma algoritmalarına geçelim.
Evrensel kayıpsız sıkıştırma yöntemleri
Genel durumda, sıkıştırma algoritmalarının oluşturulduğu üç temel seçenek vardır.İlk grup akış dönüşüm yöntemleri. Bu, halihazırda işlenmiş olan yeni gelen sıkıştırılmamış verilerin bir açıklamasını ifade eder. Bu durumda, hiçbir olasılık hesaplanmaz, karakter kodlaması, yalnızca LZ yöntemlerinde (Abraham Lempel ve Jacob Ziva'dan sonra adlandırılır) olduğu gibi, zaten işlenmiş olan veriler temelinde gerçekleştirilir. Bu durumda, kodlayıcı tarafından zaten bilinen bir alt dizenin ikinci ve diğer oluşumları, ilk oluşumuna referanslarla değiştirilir.
İkinci grup yöntemler istatistiksel sıkıştırma yöntemleridir. Buna karşılık, bu yöntemler uyarlanabilir (veya akış) ve bloğa ayrılır.
İlk (uyarlanabilir) versiyonda, yeni veriler için olasılıkların hesaplanması kodlama sırasında zaten işlenmiş olan verilere dayanmaktadır. Bu yöntemler arasında Huffman ve Shannon-Fano algoritmalarının uyarlanabilir versiyonları bulunmaktadır.
İkinci (blok) durumda, her veri bloğunun istatistikleri ayrı olarak hesaplanır ve en sıkıştırılmış bloğa eklenir. Bunlar arasında Huffman, Shannon-Fano ve aritmetik kodlama yöntemlerinin statik sürümleri bulunur.
Üçüncü grup yöntemler, blok dönüştürme yöntemleridir. Gelen veriler daha sonra bir bütün olarak dönüştürülen bloklara bölünür. Bununla birlikte, özellikle blokların permütasyonuna dayanan bazı yöntemler, veri miktarında önemli (hatta herhangi bir) azalmaya yol açmayabilir. Bununla birlikte, bu tür bir işlemden sonra, veri yapısı önemli ölçüde iyileşir ve daha sonra diğer algoritmalarla sıkıştırma daha başarılı ve daha hızlıdır.
Veri sıkıştırmanın dayandığı genel ilkeler
Tüm veri sıkıştırma yöntemleri basit bir mantık ilkesine dayanmaktadır. En sık oluşan öğelerin daha kısa kodlarla kodlandığını ve daha az yaygın olanların daha uzun kodlarla kodlandığını hayal edersek, tüm verilerin depolanması, tüm öğelerin aynı uzunlukta kodlarla temsil edilenden daha az alana ihtiyacı olacaktır.
Eleman oluşum sıklıkları ve optimum kod uzunlukları arasındaki kesin ilişki, kayıpsız maksimum sıkıştırma sınırını ve Shannon'ın entropisini tanımlayan Shannon'un kaynak kodlama teoreminde açıklanmaktadır.
Biraz matematik
Bir elemanın (s i) ortaya çıkma olasılığı p (s i) 'ye eşitse, bu elemanı temsil etmek en avantajlı olacaktır - log 2 p (s i) bitleri. Kodlama sırasında tüm elemanların uzunluğunun log 2 p (s i) bite indirgenmesini sağlamak mümkünse, tüm kodlanmış sekansın uzunluğu olası tüm kodlama yöntemleri için minimum olacaktır. Ayrıca, tüm F \u003d (p (s i)) elemanlarının olasılık dağılımı değişmezse ve elemanların olasılıkları birbirinden bağımsızsa, kodların ortalama uzunluğu şu şekilde hesaplanabilir:Bu değere, olasılık dağılımının F entropisi veya belirli bir zamanda kaynağın entropisi denir.
Bununla birlikte, genellikle bir elemanın ortaya çıkma olasılığı bağımsız olamaz, aksine, bazı faktörlere bağlıdır. Bu durumda, her yeni kodlanmış eleman s i için, olasılık dağılımı F bir miktar F k alacak, yani her eleman için F \u003d F k ve H \u003d H k alacaktır.
Başka bir deyişle, kaynağın k durumunda olduğunu söyleyebiliriz; bu, tüm elemanlar s i için belirli bir olasılık kümesine p k (s i) karşılık gelir.
Bu nedenle, bu düzeltme göz önüne alındığında, kodların ortalama uzunluğunu şu şekilde ifade edebiliriz:
Burada P k, kaynak k durumunda kaynağı bulma olasılığıdır.
Bu nedenle, bu aşamada, sıkıştırmanın sık görülen öğeleri kısa kodlarla değiştirmeye dayalı olduğunu biliyoruz ve bunun tersi de geçerli ve kodların ortalama uzunluğunu nasıl belirleyeceğimizi biliyoruz. Ancak kod, kodlama nedir ve nasıl olur?
Hafızasız Kodlama
Belleği olmayan kodlar, verilerin sıkıştırılabileceği en basit kodlardır. Hafızasız kodda, kodlanmış veri vektöründeki her karakterin yerine ikili diziler veya kelimeler önek kümesindeki bir kod sözcüğü gelir.Bence en açık tanım değil. Bu konuyu daha ayrıntılı olarak ele alın.
Biraz alfabe verilmesine izin ver ![]() bazı (sonlu) harflerden oluşur. Bu alfabedeki her bir sonlu karakter dizisini çağırıyoruz (A \u003d a 1, a 2, ..., a n) tek kelimeyleve n sayısı bu kelimenin uzunluğudur.
bazı (sonlu) harflerden oluşur. Bu alfabedeki her bir sonlu karakter dizisini çağırıyoruz (A \u003d a 1, a 2, ..., a n) tek kelimeyleve n sayısı bu kelimenin uzunluğudur.
Başka bir alfabe de verilsin ![]() . Benzer şekilde, bu alfabedeki kelimeyi B olarak belirtin.
. Benzer şekilde, bu alfabedeki kelimeyi B olarak belirtin.
Alfabedeki tüm boş olmayan kelimelerin kümesi için iki gösterim daha sunuyoruz. - ilk alfabedeki boş olmayan kelimelerin sayısı ve ikincideki -.
Ayrıca, ilk alfabedeki her A kelimesi ile ikinci kelimeden B \u003d F (A) kelimesi ile ilişkilendirilen bir haritalama F verilsin. Sonra B kelimesi çağrılır kod A kelimeleri ve orijinal kelimeden koduna geçiş denir kodlama.
Kelime aynı zamanda bir harften oluşabileceğinden, ilk alfabenin harflerinin ve ikincisinden karşılık gelen kelimelerin yazışmalarını belirleyebiliriz:
a 1<-> B 1
a 2<-> B 2
…
a n<-> B n
Bu maçın adı düzenve ∑ ile gösterilir.
Bu durumda, B 1, B 2, ..., B n kelimeleri temel kodlarve yardımlarıyla kodlama türü - alfabetik kodlama. Elbette, yukarıda tarif ettiğim her şeyi bilmesek bile, çoğumuz bu tür kodlama ile karşılaştık.
Bu yüzden kavramlara karar verdik alfabe, kelime, kod, ve kodlama. Şimdi kavramı tanıtıyoruz önek.
B kelimesinin B \u003d B "B" "biçimini almasına izin verin. Sonra B" başlangıcı olarak adlandırılır veya önek B ve B "" kelimeleri - sonu. Bu oldukça basit bir tanımdır, ancak herhangi bir B kelimesi için hem belirli bir boş word (“boşluk”) hem de B kelimesinin kendisinin hem başlangıç \u200b\u200bhem de bitiş olarak kabul edilebileceği belirtilmelidir.
Bu nedenle, belleksiz kodların tanımını anlamaya yaklaşıyoruz. Anlamamız gereken son tanım önek kümesidir. Herhangi bir 1≤i, j≤r, i ≠ j için, B i kelimesi B j kelimesinin bir öneki değilse, şema ix bir önek özelliğine sahiptir.
Basitçe söylemek gerekirse, bir önek kümesi, hiçbir öğenin başka bir öğenin öneki (veya başlangıcı) olmadığı sonlu bir kümedir. Böyle bir kümenin basit bir örneği, örneğin, normal alfabe.
Böylece temel tanımları anladık. Öyleyse kendini kodlayan hafızasızlık nasıl olur?
Üç aşamada gerçekleşir.
- Orijinal mesajın karakterlerinin bir alfabesi Ψ derlenir ve alfabenin karakterleri mesajda meydana gelme olasılıklarının azalan sırasına göre sıralanır.
- Alphabet alfabesinden her i sembolü, Ω önek kümesindeki belirli bir B i kelimesi ile ilişkilidir.
- Her karakter kodlanır, ardından kodlar sıkıştırmanın sonucu olacak tek bir veri akışında birleştirilir.
Bu yöntemi gösteren kanonik algoritmalardan biri Huffman algoritmasıdır.
Huffman Algoritması
Huffman algoritması, giriş veri bloğunda aynı baytların görülme sıklığını kullanır ve daha kısa uzunluktaki bir bit zincirinin sık bloklarını eşleştirir ve tersi de geçerlidir. Bu kod asgari düzeyde gereksizdir. Giriş akışından bağımsız olarak, çıkış akışının alfabesinin yalnızca 2 karakterden (sıfır ve bir) oluştuğu durumu düşünün.Her şeyden önce, Huffman algoritması ile kodlama yaparken, ∑ devresini oluşturmamız gerekir. Bu aşağıdaki gibi yapılır:
- Giriş alfabesinin tüm harfleri azalan olasılık sırasına göre sıralanmıştır. Çıkış akışının alfabesinden (yani kodlayacağımız) tüm kelimeler başlangıçta boş kabul edilir (çıkış akışının alfabesinin sadece karakterlerden (0,1) oluştuğunu hatırlıyorum).
- En az ortaya çıkma olasılığı olan iki j-1 ve giriş akışının j karakteri, olasılıkla birlikte bir "sözde-sembol" halinde birleştirilir. p Kurucu karakterlerinin olasılıklarının toplamına eşittir. Sonra B j-1 kelimesinin başına 0 ve B j kelimesinin başına 1 ekleriz, bu karakter sırasıyla j-1 ve j karakter kodları olacaktır.
- Bu karakterleri orijinal mesajın alfabesinden kaldırıyoruz, ancak oluşturulan sözde sembolü bu alfabeye ekliyoruz (doğal olarak, olasılığı dikkate alınarak doğru yere alfabeye eklenmelidir).
Daha iyi bir örnek için küçük bir örnek düşünün.
Sadece dört karakterden oluşan bir alfabemiz olduğunu varsayın ((1, 2, 3, 4). Ayrıca, bu simgelerin ortaya çıkma olasılıklarının sırasıyla p 1 \u003d 0.5; p2 \u003d 0.24; p3 \u003d 0.15; p 4 \u003d 0.11 (tüm olasılıkların toplamı bire eşittir).
Böylece, bu alfabe için şema oluşturacağız.
- En az olasılıkla (0.11 ve 0.15) iki karakteri p "sözde karakterine" birleştirin.
- İki karakteri en az olasılıkla (0.24 ve 0.26) p sözde karakterine birleştiriyoruz.
- Birleştirilmiş karakterleri kaldırırız ve ortaya çıkan sahte karakteri alfabeye ekleriz.
- Son olarak, kalan iki karakteri birleştirin ve ağacın tepesini alın.
Bu işlemi gösterirseniz, aşağıdaki gibi bir şey elde edersiniz:
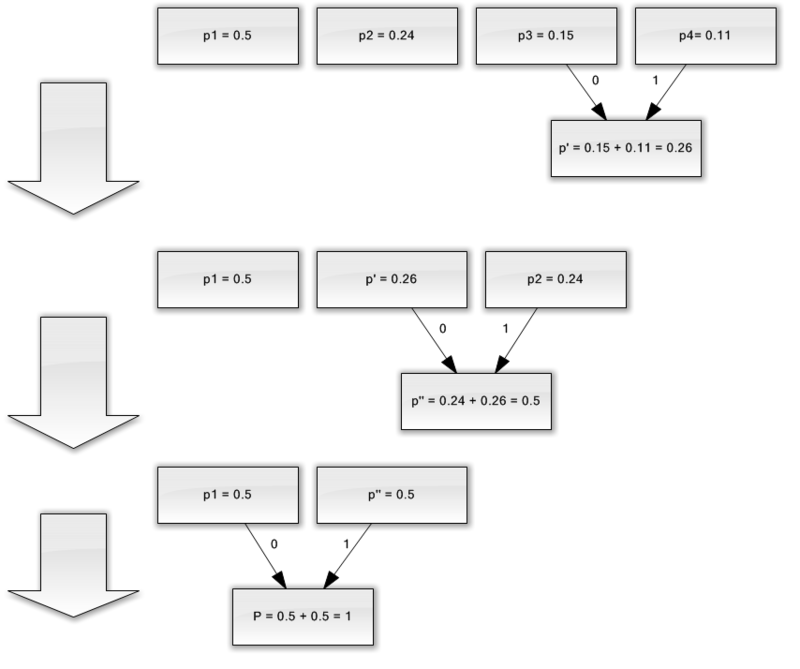
Gördüğünüz gibi, her birleştirme ile birleştirilecek karakterlere 0 ve 1 karakterlerini atarız.
Böylece, ağaç inşa edildiğinde, her karakter için kodu kolayca alabiliriz. Bizim durumumuzda, kodlar aşağıdaki gibi görünecektir:
A 1 \u003d 0
a 2 \u003d 11
a 3 \u003d 100
a 4 \u003d 101
Bu kodların hiçbiri diğerinin öneki olmadığından (yani kötü şöhretli önek setini aldık), çıkış akışındaki her kodu benzersiz bir şekilde tanımlayabiliriz.
Böylece, en sık kullanılan karakterin en kısa kodla kodlandığını ve tam tersini sağladık.
Başlangıçta, her karakteri saklamak için bir bayt kullanıldığını varsayarsak, verileri ne kadar azaltabileceğimizi hesaplayabiliriz.
Girişte 1000 karakterlik bir dize olduğunu varsayalım ki burada 1 karakteri 500 kez, 2 240, 3350 ve 4 110 kez meydana geldi.
Başlangıçta, bu dize 8000 bit işgal etti. Kodlamadan sonra ∑p i l i \u003d 500 * 1 + 240 * 2 + 150 * 3 + 110 * 3 \u003d 1760 bit uzunluğunda bir dize alırız. Böylece, verileri her bir akım sembolünün kodlamasına ortalama 1.76 bit harcayarak 4.54 kez sıkıştırabildik.
Shannon'a göre, kodların ortalama uzunluğunun olduğunu hatırlatmama izin verin. Olasılık değerlerimizi bu denkleme koyarsak, elde ettiğimiz sonuca çok, çok yakın olan 1.75496602732291'e eşit ortalama kod uzunluğunu elde ederiz.
Bununla birlikte, verilerin kendisine ek olarak, kodlanan verinin son boyutunu hafifçe artıracak olan kodlama tablosunu saklamamız gerektiğine dikkat edilmelidir. Açıkçası, farklı durumlarda algoritmanın farklı varyasyonları kullanılabilir - örneğin, önceden tanımlanmış bir olasılık tablosu kullanmak bazen daha etkilidir ve bazen sıkıştırılabilir verilerden geçerek dinamik olarak derlenmesi gerekir.
Sonuç
Bu makalede, hakkında konuşmaya çalıştım genel ilkeler, kayıpsız sıkıştırma meydana gelir ve aynı zamanda kanonik algoritmalardan biri olarak kabul edilir - Huffman kodlama.Makale habro topluluğunun tadı içinse, kayıpsız sıkıştırma ile ilgili daha ilginç şeyler olduğu için bir netice yazmaktan mutluluk duyacağım; bunlar hem klasik algoritmalar hem de ön veri dönüşümleridir (örneğin, Burroughs-Wheeler dönüşümü) ve tabii ki ses, video ve görüntüleri sıkıştırmak için özel algoritmalardır (bence en ilginç konu).
edebiyat
- Vatolin D., Ratushnyak A., Smirnov M. Yukin V.Veri sıkıştırma yöntemleri. Cihaz arşivleme, görüntü ve video sıkıştırma; ISBN 5-86404-170-X; 2003 yıl
- D. Salomon. Veri, görüntü ve sesin sıkıştırılması; ISBN 5-94836-027-X; 2004.
Ders sayısı 4. Bilgi sıkıştırma
Bilgi sıkıştırma ilkeleri
Veri sıkıştırmanın amacı, daha ekonomik depolama ve iletişim kanalları üzerinden iletilmesi için kaynak tarafından üretilen verilerin kompakt bir sunumunu sağlamaktır.
1 (bir) megabayt boyutunda bir dosyamız olduğunu varsayalım. Ondan daha küçük bir dosya almamız gerekiyor. Karmaşık bir şey yok - arşivleyiciyi, örneğin WinZip'i başlatıyoruz ve sonuç olarak, örneğin 600 kilobayt boyutunda bir dosya alıyoruz. Kalan 424 kilobayt nereye gitti?
Bilgileri sıkıştırmak onu kodlamanın bir yoludur. Genel olarak, kodlar üç büyük gruba ayrılır - sıkıştırma kodları (etkili kodlar), gürültüye dayanıklı kodlar ve kriptografik kodlar. Bilgileri sıkıştırmak için tasarlanmış kodlar, kayıpsız kodlara ve kayıplı kodlara bölünür. Kayıpsız kodlama, kod çözme işleminden sonra kesinlikle doğru veri kurtarma anlamına gelir ve herhangi bir bilgiyi sıkıştırmak için kullanılabilir. Kayıplı kodlama genellikle kayıpsız kodlamadan çok daha yüksek bir sıkıştırma oranına sahiptir, ancak kodu çözülen verilerin orijinalden bazı sapmalarına izin verir.
Sıkıştırma türleri
Tüm bilgi sıkıştırma yöntemleri iki büyük ayrık sınıfa ayrılabilir: kayıp bilgi ve sıkıştırma kayıpsız bilgileri.
Bilgi kaybı olmadan sıkıştırma.
Bu sıkıştırma yöntemleri her şeyden önce bizim için önemlidir, çünkü metin belgelerini ve programlarını aktarırken, tamamlanmış bir işi müşteriye verirken veya bilgisayarda depolanan bilgilerin yedek kopyalarını oluştururken tam olarak kullanılırlar.
Bu sınıfın sıkıştırma yöntemleri bilgi kaybına izin veremez, bu nedenle sadece artıklığını ortadan kaldırmaya dayanırlar ve bilgi neredeyse her zaman fazlalığa sahiptir (ancak daha önce hiç yoğunlaştırmamış olsa da). Artıklık olmasaydı sıkıştırılacak hiçbir şey olmazdı.
İşte basit bir örnek. Rus dilinde 33 harf, on basamak ve yaklaşık bir düzine noktalama işareti ve diğer özel karakterler var. Kaydedilen metin için sadece büyük Rus harfleriyle (telgraflarda ve radyogramlarda olduğu gibi) altmış farklı anlam yeterli olurdu. Ancak, her karakter genellikle 8 bit içeren ve 256 farklı kod ifade edebilen bir baytta kodlanır. Artıklık için ilk temel budur. “Telgraf” metnimiz için karakter başına altı bit yeterli olacaktır.
İşte başka bir örnek. Uluslararası karakter kodlamasında ASCII herhangi bir karakteri kodlamak için aynı sayıda bit ayrılır (8), herkes uzun zamandır en yaygın karakterlerin daha az karakterle kodlamanın mantıklı olduğunu biliyordu. Yani, örneğin, "Mors alfabesi" nde, sıklıkla bulunan "E" ve "T" harfleri bir karakterle kodlanır (sırasıyla, bu bir nokta ve bir tire işaretidir). Ve "Yu" (- -) ve "Ts" (- -) gibi nadir harfler dört karakterle kodlanır. Yetersiz kodlama yedekliliğin ikinci nedenidir. Veri sıkıştırması yapan programlar kendi kodlamalarını (farklı dosyalar için farklı) girebilir ve sıkıştırılmış dosyaya belirli bir tablo (sözlük) atayabilir; bu paketten çıkarma programı, belirli sembollerin veya gruplarının bu dosyada nasıl kodlandığını öğrenir. Bilginin kod dönüştürülmesine dayanan algoritmalar denir huffman algoritmaları.
Yinelenen parçaların varlığı, yedekliliğin üçüncü nedenidir. Bu metinlerde nadirdir, ancak tablolarda ve grafiklerde kodların tekrarı sık rastlanan bir durumdur. Örneğin, 0 sayısı arka arkaya yirmi kez tekrarlanırsa, yirmi sıfır bayt koymak mantıklı değildir. Bunun yerine, bir sıfır ve 20 katsayısı koydular. Tekrarların saptanmasına dayanan bu algoritmalara çağrılır yöntemleriRLE (koşmak uzunluk Kodlama).
Özdeş baytların büyük tekrarlayan dizileri özellikle grafik resimlerle ayırt edilir, ancak fotoğrafik olanlar (parametrelerde çok fazla gürültü ve komşu noktalar vardır), ancak sanatçıların animasyon filmlerinde olduğu gibi "pürüzsüz" bir renkte boyananlar.
Kayıplı sıkıştırma.
Bilgi kaybıyla sıkıştırma, sıkıştırılmış arşivi açtıktan sonra, en başında olandan biraz farklı bir belge alacağımız anlamına gelir. Sıkıştırma derecesi ne kadar büyük olursa, kaybın büyüklüğü de o kadar büyük olur.
Elbette, bu algoritmalar metin belgeleri, veritabanı tabloları ve özellikle programlar için geçerli değildir. Bir şekilde düz, biçimlendirilmemiş metinde küçük bozulmalardan kurtulabilirsiniz, ancak bir programda en az bir biti deforme etmek tamamen çalışmaz hale getirecektir.
Aynı zamanda, onlarca kez sıkıştırma elde etmek için bilginin yüzde birkaçını feda etmeye değer malzemeler vardır. Bunlar fotoğrafik illüstrasyonları, videoları ve müzik bestelerini içerir. Sıkıştırma ve daha sonra bu tür malzemelerde ambalajın açılması sırasında bilgi kaybı, bir miktar ek “gürültünün” ortaya çıkması olarak algılanır. Ancak bu materyalleri oluştururken hala belirli bir “gürültü” olduğu için, hafif artışı her zaman kritik görünmüyor ve dosya boyutundaki kazanç çok büyük (müzik için 10-15 kez, fotoğraf ve video için 20-30 kez).
Bilgi kaybı olan sıkıştırma algoritmaları, JPEG ve MPEG gibi iyi bilinen algoritmaları içerir. JPEG algoritması resimler sıkıştırılırken kullanılır. Bu yöntemle sıkıştırılan görüntü dosyalarının jpg uzantısı vardır. Video ve müzik sıkıştırılırken MPEG algoritmaları kullanılır. Bu dosyalar, belirli bir programa bağlı olarak çeşitli uzantılara sahip olabilir, ancak en ünlüleri video için .MPG ve müzik için .MPG'dir.
Bilgi kaybı sıkıştırma algoritmaları yalnızca tüketici görevleri için kullanılır. Bu, örneğin, bir fotoğraf görüntüleme için ve oynatma için müzik aktarılırsa, bu tür algoritmaların uygulanabileceği anlamına gelir. Daha fazla işlem için, örneğin düzenleme için aktarılırlarsa, kaynak malzemede bilgi kaybına izin verilmez.
Sıkıştırmada izin verilen kaybın büyüklüğü genellikle kontrol edilebilir. Bu, optimum boyut / kalite oranını denemenizi ve elde etmenizi sağlar. Ekranda gösterilmesi amaçlanan fotoğraf resimlerinde,% 5'lik bilgi kaybı genellikle kritik değildir ve bazı durumlarda% 20-25 tolere edilebilir.
Kayıpsız sıkıştırma algoritmaları
Shannon Feno Kodu
Daha fazla tartışma için, kaynak dosyamızı çıktısında birer birer görünen bir karakter kaynağı olarak metinle sunmak uygun olacaktır. Sırada hangi karakterin olacağını bilmiyoruz, ancak p1 olasılığı ile “a” harfinin görüneceğini, p2 olasılığı ile “b” harfinin vb. Görüneceğini biliyoruz.
En basit durumda, metnin tüm karakterlerinin birbirinden bağımsız olduğunu düşüneceğiz, yani. bir sonraki karakterin ortaya çıkma olasılığı bir önceki karakterin değerine bağlı değildir. Tabii ki, bu anlamlı bir metin için böyle değil, ama şimdi çok basitleştirilmiş bir durum düşünüyoruz. Bu durumda, "sembol daha fazla bilgi taşır, ortaya çıkma olasılığı o kadar az olur."
Alfabesi sadece 16 harften oluşan bir metin düşünelim: A, B, C, D, D, E, F, Z, I, K, L, M, H, O, P, P Bu karakterlerin her biri sadece 4 bit ile kodlayın: 0000'dan 1111'e. Şimdi bu karakterlerin ortaya çıkma olasılığının aşağıdaki gibi dağıtıldığını hayal edin:
Bu olasılıkların toplamı elbette birdir. Bu sembolleri iki gruba ayırırız, böylece her bir grubun sembollerinin toplam olasılığı ~ 0.5 olur (Şek.). Örneğimizde, bunlar gruplar olacak aB karakterleri ve GR. Şekildeki karakter gruplarını gösteren halkalara köşe veya düğüm denir ve bu düğümlerin yapısına ikili ağaç (B-ağacı) denir. Bir düğümü 0 numarayla ve diğerini 1 numarayla atayarak her düğüme kendi kodunu atayın.
Yine, birinci grubu (AB) toplam olasılıkları birbirine olabildiğince yakın olacak şekilde iki alt gruba ayırıyoruz. İlk alt grubun koduna 0 ve ikincinin koduna 1 sayısını ekleyin. 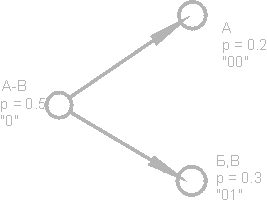
Bu işlemi, "ağacımızın" her köşesinde bir sembol kalana kadar tekrar edeceğiz. Alfabemiz için eksiksiz bir ağacın 31 düğümü olacaktır.
Karakter kodları (ağacın en sağ düğümleri) eşit olmayan uzunlukta kodlara sahiptir. Dolayısıyla, hayali metnimiz için p \u003d 0.2 olasılığı olan A harfi sadece iki bitle kodlanır ve p \u003d 0.013 olasılığı olan P harfi (şekilde gösterilmemiştir) altı bitlik bir kombinasyonla kodlanır.
Bu nedenle, ilke açıktır - sık sık oluşan karakterler daha az bitle kodlanır, nadiren oluşan karakterler daha fazla kodlanır. Sonuç olarak, karakter başına ortalama bit sayısı eşit olacaktır
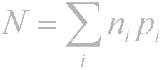
burada ni, i-th karakterini kodlayan bitlerin sayısıdır, pi, i-th karakterinin ortaya çıkma olasılığıdır.
Huffman Kodu.
Huffman algoritması, önek kümelerini kullanarak genel istatistiksel kodlama fikrini zarif bir şekilde uygular ve aşağıdaki gibi çalışır:
1. Alfabedeki tüm karakterleri, metinde ortaya çıkma olasılıklarının artan veya azalan düzeninde bir satırda yazarız.
2. İki simgeyi en az meydana gelme olasılığı olan yeni bir kompozit simgeye sürekli olarak birleştirin; gerçekleşme olasılığı, bileşen sembollerinin olasılıklarının toplamına eşit kabul edilir. Sonunda, her bir düğümü altındaki tüm düğümlerin toplam olasılığı olan bir ağaç inşa edeceğiz.
3. Ağacın her yaprağına giden yolu, her bir düğüme yönünü işaretleyerek izleriz (örneğin, sağa - 1, sola - 0). Ortaya çıkan dizi, her karaktere karşılık gelen bir kod sözcüğü verir (Şek.).
Aşağıdaki alfabe ile bir mesaj için kod ağacı oluşturun:
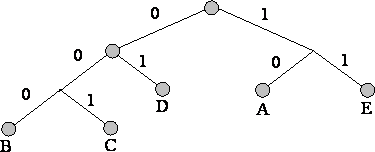
Yöntemlerin dezavantajları
Kodlarla ilgili en büyük zorluk, bir önceki tartışmada olduğu gibi, her sıkıştırılabilir veri türü için olasılık tablolarına ihtiyaç duyulmasıdır. İngilizce veya Rusça metnin sıkıştırıldığı biliniyorsa bu bir sorun değildir; kodlayıcı ve kod çözücüye İngilizce veya Rusça metin için uygun bir kod ağacı sağlarız. Genel durumda, giriş verisi için karakter olasılığı bilinmiyorsa, Huffman'ın statik kodları verimsiz çalışır.
Bu sorunun çözümü, verilerden ilk geçiş sırasında gerçekleştirilen kodlanmış verilerin istatistiksel bir analizidir ve buna dayanarak bir kod ağacının derlenmesidir. Aslında, kodlama ikinci geçiş tarafından gerçekleştirilir.
Kodların bir başka dezavantajı, onlar için minimum kod sözcüğü uzunluğunun birden az olamazken, mesaj entropisi 0.1 ve 0.01 bit / harf olabilir. Bu durumda, kod önemli ölçüde gereksiz hale gelir. Sorun, algoritmayı karakter bloklarına uygulayarak çözülür, ancak daha sonra kodlama / kod çözme prosedürü karmaşıktır ve kod ağacı önemli ölçüde genişletilir ve sonuçta kodla birlikte kaydedilmelidir.
Bu kodlar, hemen hemen her metinde bulunan karakterler arasındaki ilişkiyi dikkate almaz. Örneğin, q harfini İngilizce bir metinde görürsek, u harfinin onu takip edeceğini güvenle söyleyebiliriz.
Grup kodlaması - Çalışma Uzunluğu Kodlaması (RLE) - en eski ve en kolay arşivleme algoritmalarından biridir. RLE'deki sıkıştırma, özdeş bayt dizelerini sayaç, değer çiftleriyle değiştirerek gerçekleşir. ("Kırmızı, kırmızı, ..., kırmızı" "N kırmızı" olarak yazılır).
Algoritmanın uygulamalarından biri şöyledir: en az karşılaşılan baytı ararlar, bir önek olarak adlandırırlar ve aynı karakter dizelerini üçlü "önek, sayaç, değer" ile değiştirirler. Bu bayt, kaynak dosyada arka arkaya bir veya iki kez bulunursa, bir çift "önek, 1" veya "önek, 2" ile değiştirilir. Paketlenmiş verinin sonunun işareti olarak kullanılabilen kullanılmayan bir çift "0" öneki kalır.
Exe dosyalarını kodlarken, genellikle kaynaklarda (Unicode kodlamasında dizeler) bulunan AxAyAzAwAt ... formunun dizilerini arayabilir ve paketleyebilirsiniz.
Algoritmanın olumlu yönleri, çalışırken ek bellek gerektirmediğini ve hızlı bir şekilde yürütüldüğünü içerir. Algoritma PCX, TIFF, BMP formatlarında kullanılır. PCX'te grup kodlamasının ilginç bir özelliği, bazı görüntüler için arşivleme derecesinin, sadece görüntü paletindeki renklerin sırasını değiştirerek önemli ölçüde artırılabilmesidir.
LZW kodu (Lempel-Ziv & Welch), en yaygın kayıpsız sıkıştırma kodlarından biridir. LZW kodunun yardımıyla sıkıştırma, TIFF ve GIF gibi grafik formatlarında gerçekleştirilir, LZW modifikasyonlarının yardımıyla çok sayıda evrensel arşivleyici işlevlerini yerine getirir. Algoritma, giriş dosyasında 8 ila 12 bit uzunluğunda kombinasyonlar halinde kodlanan tekrarlanan karakter dizilerini aramaya dayanır. Bu nedenle, bu algoritma büyük tek renkli bölümlerin veya tekrarlanan piksel dizilerinin bulunduğu metin dosyalarında ve grafik dosyalarında en yüksek verimliliğe sahiptir.
LZW kodlaması sırasında bilgi kaybının olmaması, TIFF formatının yaygın olarak kullanılmasına yol açtı. Bu biçim, görüntünün boyutu ve renk derinliği üzerinde herhangi bir kısıtlama getirmez ve örneğin yazdırmada yaygındır. Başka bir LZW tabanlı format - GIF - daha ilkeldir - görüntüleri 8 bit / pikselden fazla olmayan renk derinliğine sahip saklamanızı sağlar. GIF dosyasının başında bir palet - renk dizini arasındaki yazışmayı ayarlayan bir tablo - 0 ile 255 arasında bir sayı ve gerçek, 24 bit renk değeri.
Bilgi kaybı sıkıştırma algoritmaları
JPEG algoritması, Birleşik Fotoğraf Uzmanları Grubu olarak adlandırılan bir grup şirket tarafından geliştirilmiştir. Projenin amacı, hem siyah beyaz hem de renkli görüntüler için yüksek verimli bir sıkıştırma standardı oluşturmaktı ve bu hedefe geliştiriciler tarafından ulaşıldı. Şu anda, JPEG, örneğin İnternet'te yüksek derecede sıkıştırma gerektiğinde yaygın olarak kullanılmaktadır.
LZW algoritmasının aksine, JPEG kodlaması kayıplı kodlamadır. Kodlama algoritmasının kendisi çok karmaşık matematiğe dayanmaktadır, ancak genel olarak şu şekilde açıklanabilir: görüntü 8 * 8 piksel karelere bölünür ve daha sonra her kare 64 piksel sıralı bir zincire dönüştürülür. Ayrıca, bu tür her bir zincir, ayrık Fourier dönüşümünün çeşitlerinden biri olan DCT dönüşümüne tabi tutulur. Piksellerin giriş dizisinin, çoklu frekanslı (harmonikler denilen) sinüzoidal ve kosinüs bileşenlerinin toplamı olarak temsil edilebileceği gerçeğinde yatmaktadır. Bu durumda, giriş sırasını yeterli bir doğrulukla geri yüklemek için sadece bu bileşenlerin genliklerini bilmemiz gerekir. Bildiğimiz daha fazla harmonik bileşen, orijinal ve sıkıştırılmış görüntü arasında daha az tutarsızlık olacaktır. Çoğu JPEG kodlayıcı sıkıştırma oranını ayarlamanıza izin verir. Bu çok basit bir şekilde elde edilir: sıkıştırma oranı ne kadar yüksek ayarlanırsa, her 64 piksel bloğundaki harmonikler o kadar az temsil edilir.
Tabii ki, bu tip kodlamanın gücü orijinal renk derinliğini korurken büyük bir sıkıştırma oranıdır. Sınırlı miktarda depolanması gereken multimedya ansiklopedilerinde dosya boyutunun küçültülmesinin çok önemli olduğu internette yaygın olarak kullanılmasına neden olan bu özelliktir.
Bu biçimin negatif bir özelliği hiçbir şekilde kurtarılamaz, bu da görüntü kalitesindeki doğal bozulmadır. Kalitenin çok önemli olduğu baskıda kullanılmasına izin vermeyen bu üzücü gerçektir.
Bununla birlikte, JPEG formatı, son dosyanın boyutunu küçültme arzusundaki mükemmellik sınırı değildir. Son zamanlarda, dalgacık dönüşümü (veya patlama dönüşümü) adı verilen alanda yoğun araştırmalar yapılmaktadır. En karmaşık matematiksel prensiplere dayanarak, dalgacık kodlayıcıları JPEG'den daha fazla sıkıştırma elde etmenizi sağlar, daha az bilgi kaybıyla. Dalgacık dönüşümünün matematiğinin karmaşıklığına rağmen, yazılım uygulamasında JPEG'den daha basittir. Dalgacık sıkıştırma algoritmaları hala emekleme döneminde olsalar da, büyük bir gelecekleri var.
Fraktal sıkıştırma
Fraktal görüntü sıkıştırma, görüntülere yinelenebilir fonksiyon sistemlerinin (genellikle afin dönüşümler olan IFS) uygulanmasına dayanan kayıplı bir görüntü sıkıştırma algoritmasıdır. Bu algoritma, bazı durumlarda, prensip olarak diğer görüntü sıkıştırma algoritmaları için mevcut olmayan, doğal nesnelerin gerçek fotoğrafları için çok yüksek sıkıştırma oranlarının elde edilmesine izin verdiği (en iyi örneklerin kabul edilebilir görsel kalite ile 1000 kata kadar) olmasıdır. Patentlemedeki zor durumdan dolayı algoritma yaygın olarak kullanılmadı.
Fraktal arşivleme, yinelenebilir fonksiyonlardan oluşan bir sistemin katsayılarını kullanarak görüntünün daha kompakt bir biçimde sunulmasına dayanır. Arşivleme sürecine bakmadan önce, IFS'in nasıl bir görüntü oluşturduğuna bakalım.
Kesin olarak ifade etmek gerekirse, IFS, bir görüntüyü diğerine çeviren üç boyutlu bir afin dönüşüm kümesidir. Üç boyutlu uzayda noktalar dönüştürülür (x koordinatı, y koordinatı, parlaklık).
Fraktal kodlama yönteminin temeli görüntüdeki kendine benzer bölümlerin tespit edilmesidir. Yinelenebilir fonksiyon sistemleri (IFS) teorisini görüntü sıkıştırma problemine uygulama olasılığı ilk olarak Michael Barnsley ve Alan Sloan tarafından araştırılmıştır. Fikirlerini 1990 ve 1991'de patentlediler. Jacquin, etki alanını ve aralık alt görüntü bloklarını, tüm görüntüyü kaplayan kare şekilli blokları kullanan bir fraktal kodlama yöntemini tanıttı. Bu yaklaşım, günümüzde kullanılan fraktal kodlama yöntemlerinin çoğunun temelini oluşturmuştur. Yuval Fisher ve diğer birçok araştırmacı tarafından geliştirilmiştir.
Bu yönteme uygun olarak, görüntü birçok örtüşmeyen rütbe alt görüntüsüne (aralık alt görüntüleri) bölünür ve birçok örtüşen etki alanı alt görüntüsü (etki alanı alt görüntüleri) belirlenir. Her bir sıra bloğu için kodlama algoritması, en uygun etki alanı bloğunu ve bu etki alanı bloğunu belirli bir sıra bloğuna dönüştüren afin dönüşümünü bulur. Görüntü yapısı bir sıra blokları, alan blokları ve dönüşümler sistemine eşlenir.
Fikir şudur: orijinal görüntünün bir tür sıkıştırıcı haritalamanın sabit bir noktası olduğunu varsayalım. Daha sonra, görüntünün kendisi yerine, bu ekranı bir şekilde hatırlamak mümkündür ve geri yükleme için bu ekranı herhangi bir başlangıç \u200b\u200bgörüntüsüne tekrar tekrar uygulamak yeterlidir.
Banach teoremine göre, bu tür yinelemeler her zaman sabit bir noktaya, yani orijinal görüntüye yol açar. Uygulamada, tüm zorluk, görüntüden en uygun sıkıştırıcı ekranı bulmak ve kompakt depolamada yatmaktadır. Kural olarak, eşleme arama algoritmaları (yani sıkıştırma algoritmaları) büyük ölçüde kaba kuvvettir ve büyük hesaplama maliyetleri gerektirir. Aynı zamanda, kurtarma algoritmaları oldukça verimli ve hızlıdır.
Kısaca Barnsley tarafından önerilen yöntem aşağıdaki gibi tarif edilebilir. Görüntü birkaç basit dönüşümle kodlanır (bizim durumumuzda afin), yani, bu dönüşümlerin katsayıları ile belirlenir (bizim durumumuzda A, B, C, D, E, F).
Örneğin, Koch eğrisinin görüntüsü dört afin dönüşüm ile kodlanabilir, sadece 24 katsayı kullanarak benzersiz bir şekilde belirleyeceğiz.
Sonuç olarak, nokta mutlaka orijinal görüntüdeki siyah alanın içinde bir yere gider. Bu işlemi birçok kez yaptıktan sonra, tüm siyah alanı dolduracağız, böylece resmi geri yükleyeceğiz.

En ünlüsü IFS kullanılarak elde edilen iki görüntüdür: Sierpinski üçgeni ve Barnsley eğrelti. Birincisi üç, ikincisi beş afin dönüşüm (veya terminolojimizde lensler) ile tanımlanır. Her dönüşüm kelimenin tam anlamıyla okunan baytlarla belirtilirken, yardımlarıyla oluşturulan bir görüntü birkaç megabayt alabilir.
Arşivleyicinin nasıl çalıştığı ve neden bu kadar zaman aldığı açıktır. Aslında, fraktal sıkıştırma görüntüdeki kendine benzer alanların araştırılması ve onlar için afin dönüşüm parametrelerinin belirlenmesidir.
En kötü durumda, optimizasyon algoritması kullanılmazsa, farklı boyutlardaki tüm olası görüntü parçalarının numaralandırılmasını ve karşılaştırılmasını gerektirir. Ayrıklığı göz önünde bulundurulan küçük görüntüler için bile, aranacak astronomik sayıda seçenek elde ederiz. Dönüşüm sınıflarının keskin bir şekilde daralması bile, örneğin, yalnızca belirli sayıda ölçekleme nedeniyle, kabul edilebilir bir zaman elde edilmesine izin vermeyecektir. Ayrıca, görüntü kalitesi de kaybolur. Fraktal kompresyon alanındaki çalışmaların büyük çoğunluğu şimdi yüksek kaliteli bir görüntü elde etmek için gereken arşivleme süresini azaltmayı amaçlamaktadır.
Bir fraktal sıkıştırma algoritması ve diğer kayıplı sıkıştırma algoritmaları için, sıkıştırma oranını ve kayıp derecesini kontrol etmenin mümkün olacağı mekanizmalar çok önemlidir. Bugüne kadar, yeterince büyük bir dizi yöntem geliştirilmiştir. İlk olarak, bilerek en azından sabit bir değere sahip bir sıkıştırma oranı sağlayarak dönüşümlerin sayısını sınırlamak mümkündür. İkinci olarak, işlenen parça ile en iyi yaklaşımı arasındaki farkın belirli bir eşik değerinden daha yüksek olduğu bir durumda, bu parçanın mutlaka ezilmesi gerekir (bunun için birkaç lens sarılmalıdır). Üçüncüsü, diyelim ki dört noktadan daha küçük parçaların parçalanmasını yasaklamak mümkündür. Eşik değerlerini ve bu koşulların önceliğini değiştirerek, görüntünün sıkıştırma oranını çok esnek bir şekilde kontrol edebilirsiniz: bitsel eşlemeden herhangi bir sıkıştırma oranına.
JPEG ile karşılaştırma
Bugün, en yaygın grafik arşivleme algoritması JPEG'dir. Fraktal sıkıştırma ile karşılaştırın.
İlk olarak, hem birinin hem de diğerinin 8 bit (gri tonlamalı) ve 24 bit tam renkli görüntülerle çalıştığını unutmayın. Her ikisi de kayıplı sıkıştırma algoritmalarıdır ve yakın arşivleme oranları sağlar. Hem fraktal algoritma hem de JPEG, kayıpları artırarak sıkıştırma oranını artırma fırsatına sahiptir. Ayrıca, her iki algoritma da çok iyi paralelleştirilmiştir.
Farklılıklar, algoritmaların arşivlenmesi / sıkıştırılması için geçen süreyi dikkate alırsak başlar. Böylece, fraktal algoritma JPEG'den yüzlerce hatta binlerce kat daha uzun sıkıştırır. Görüntünün ambalajının açılması, aksine, 5-10 kat daha hızlı gerçekleşir. Bu nedenle, görüntü yalnızca bir kez sıkıştırılır ve ağ üzerinden iletilir ve birçok kez paketten çıkarılırsa, fraktal algoritmayı kullanmak daha karlı olur.
JPEG görüntünün kosinüs fonksiyonlarına ayrışmasını kullanır, bu nedenle içindeki kayıp (belirtilen minimum kayıpta bile) keskin renk geçişlerinin sınırındaki dalgalar ve halelerde görünür. Bu efekt için, yüksek kaliteli baskı için hazırlanan görüntüleri sıkıştırırken kullanmayı sevmezler: orada bu etki çok belirgin hale gelebilir.
Fraktal algoritmada bu dezavantaj yoktur. Ayrıca, bir görüntü yazdırırken, yazdırma aygıtının raster (veya çizgisi) görüntü rasteriyle çakışmadığından, her seferinde bir ölçeklendirme işlemi gerçekleştirmeniz gerekir. Dönüştürme sırasında, görüntüyü programlı olarak ölçekleyerek (geleneksel lazer ve mürekkep püskürtmeli yazıcılar gibi düşük maliyetli yazdırma aygıtları için) veya yazdırma aygıtını kendi işlemcisi, sabit sürücüsü ve bir dizi görüntü işleme programı (pahalı fototipler için) ile donatarak kombine edilebilen birkaç hoş olmayan etki de ortaya çıkabilir. Tahmin edebileceğiniz gibi, fraktal algoritmayı kullanırken, bu tür problemler pratik olarak ortaya çıkmaz.
JPEG'in yaygın kullanımda fraktal algoritması tarafından kaldırılması yakında gerçekleşmeyecek (en azından ikincisini arşivlemenin düşük hızı nedeniyle), ancak multimedya uygulamaları alanında, bilgisayar oyunlarında kullanımı haklı.
İlk bölümde, ses formatlarına bakacağız. FLAC, WavPack, TAK, Maymunun Sesi, OptimFROG, ALAC, WMA, Kısalt, LA, TTA, LPAC, MPEG-4 ALS, MPEG-4 SLS, Gerçek Kayıpsız nedir? Kaç ses türü biliyor musunuz? Şimdiye kadar, kayıpsız ses sıkıştırma formatları ile uğraşıyoruz ve makalenin sonundaki ses uzantılarının sayısı hakkındaki sorunun cevabına bakıyoruz.
İlk olarak, terimleri tanımlarız:
« algoritması “Bu, değişken kaynak verilerinden istenen sonuca giden hesaplama sürecini tanımlayan kesin bir reçetedir.”
« Codec (eng. codec, kodlayıcı / kod çözücü - kodlayıcı / kod çözücü - kodlayıcı / kod çözücü veya kompresör / sıkıştırıcıdan) - veri veya sinyal dönüşümü gerçekleştirebilen bir aygıt veya program. Codec bileşenleri bir akışı / sinyali (genellikle iletim, depolama veya şifreleme için) kodlayabilir veya bu işlemler için daha uygun bir biçimde görüntülemek veya değiştirmek için kodunu çözebilir. Codec bileşenleri genellikle video ve sesin dijital işlenmesinde kullanılır.
Ses ve görsel veriler için çoğu codec bileşeni, bitmiş (sıkıştırılmış) dosyanın kabul edilebilir bir boyutunu elde etmek için kayıplı sıkıştırma kullanır. Kayıpsız sıkıştırma kodekleri de var. ”
« Kayıpsız sıkıştırma (Türkçe Kayıpsız veri sıkıştırma), kodlanmış bilgilerin bitlere doğru olarak geri yüklenebileceği bir bilgi sıkıştırma yöntemidir. Bu durumda, orijinal veriler sıkıştırılmış durumdan tamamen geri yüklenir. Her dijital bilgi türü için, kural olarak, kendi kayıpsız sıkıştırma algoritmaları vardır. "
Kayıpsız veri sıkıştırma, sıkıştırılmış verinin orijinaline kimliği önemli olduğunda kullanılır. Yaygın bir örnek, yürütülebilir dosyalar, belgeler ve kaynak kodudur. Kayıpsız sıkıştırma formatlarını kullanan programlara arşiv adı verilir, herkes ZIP veya RAR, Unix yardımcı programı Gzip vb. Popüler dosya formatlarını bilir. Tüm bu programlar, uygulanan algoritmalarda (bir veya birkaç) ve dolayısıyla farklı dosyaların farklı sıkıştırma özelliklerinde farklılık gösterir.
Bölüm I. - TEORİ:
Sıkıştırma yöntemleri veya kayıpsız sıkıştırma algoritmaları, oluşturuldukları veri türüne göre dağıtılabilir. Üç ana veri türü vardır: metin, resimler ve ses.
Prensip olarak, herhangi bir kayıpsız çok amaçlı veri sıkıştırma algoritması (çok amaçlı, herhangi bir ikili veri türünü işleyebileceği anlamına gelir) her tür veri için kullanılabilir, ancak bunların çoğu her ana tür için verimsizdir. Örneğin ses verileri, bir metin sıkıştırma algoritması tarafından iyi sıkıştırılamaz ve bunun tersi de geçerlidir.
Sıkıştırma yöntemleri arasında aşağıdakiler not edilebilir - entropi sıkıştırması, sözlük yöntemleri, istatistiksel yöntemler. Her yöntem belirli bir veri türü için iyidir ve bir dizi algoritma içerir.
Entropi Sıkıştırma: Huffman Algoritması · Huffman Uyarlamalı Algoritma · Aritmetik Kodlama (Shannon - Fano Algoritması · Aralık) · Golomb Kodları · Delta · Evrensel Kod (Elias · Fibonacci)
Kelime yöntemleri: RLE Deflate LZ (LZ77 / LZ78 LZSS LZW LZWL LZO LZMA LZX LZRW LZJB LZT)
Metin (veya yürütülebilir dosyalar gibi ikili metin verileri) için istatistiksel model algoritmaları şunları içerir: Burroughs-Wheeler dönüşümü (sıkıştırmayı daha verimli hale getiren blok sıralama ön işleme) · LZ77 ve LZ78 (DEFLATE kullanarak) · LZW.
Diğer: RLE · CTW · BWT · MTF · PPM · DMC
Genellikle, sadece iyi geliştirilmiş algoritmalar bir isim alırken, son gelişmeler sadece (genel kullanım, standardizasyon vb.) Anlamına gelir veya hiç belirtilmemiştir.
Ama konuya geri dönelim. Ses verilerini kodlamak için uygun algoritmalar:
Huffman algoritması (ayrıca DEFLATE kullanılır), aritmetik kodlama
Apple kayıpsız — ALAC (Apple Kayıpsız Ses Kod Çözücü)
Ses Kayıpsız Kodlama — mPEG-4 ALS olarak da bilinir
Ücretsiz Kayıpsız Ses Codec Bileşeni — FLAC
Meridyen Kayıpsız Ambalaj — MLP
Maymunun Sesi — APE
OptimFROG
RealPlayer — RealAudio Kayıpsız
kısaltın — SHN
TAK — (T) om "s verlustfreier (A) udio (K) ompressor (Almanca)
TTA — Gerçek ses kayıpsız
WavPack — Wavpack kayıpsız
WMA Kayıpsız — Windows Media Kayıpsız
DTS — DTS Surround Ses
Lempel-Ziv Algoritma Ailesi, RLE (Çalışma uzunluğu kodlaması)
FLAC (Ücretsiz Kayıpsız Ses Codec Bileşeni)
Maymunun Sesi (APE)
TTA (Gerçek Ses)
TTE
Los Angeles(LosslessAudio)
RealAudio Kayıpsız
WavPack ve diğerleri
Fark ettiğiniz gibi, kayıpsız sıkıştırma için çoğu codec bileşeni iki (bazen daha fazla) farklı algoritma türü kullanır: biri giriş verileri için istatistiksel bir model oluşturur, diğeri giriş verilerini bir bit gösteriminde görüntüler, “olasılıklı” elde etmek için modeli kullanır (yani, sık karşılaşılan) "inanılmaz" dan daha sık kullanılan veriler. Fayda - boyutu küçültme, hesaplaşma - kodlama / kod çözme için daha fazla işlemci süresi gerekir.
Küçük bir teori bulduğumuzda, çok sayıda kişi tarafından yazılan ses verilerini sıkıştırmak için kodeklerimize gideceğiz: Ücretsiz Kayıpsız Ses Codec'i, WavPack, TAK, Monkey's Audio (.ape, apl), OptimFROG (.ofr), Apple Lossless Audio Codec, WMA, Kısalt (.SHN), Kayıpsız Ses, Gerçek Ses, Kayıpsız Tahmini Ses Kodlayıcı (.LPAC), MPEG-4 ALS, MPEG-4 SLS (.mp4), Gerçek Kayıpsız veya RealAudio Kayıpsız, Windows Media Ses Kayıpsız, DTS .. Ve bu her şeyden uzak, profesyonel kayıt cihazları üreten birçok şirket kendi formatlarını icat etti ve icat etmeye devam ediyor.
Bu kadar çok sayıda ses verisi sıkıştırma biçimi, platformların teknik kusurlarından (listelenen kodeklerin çoğu 90'ların sonlarında yazılmıştır), pazarlamadan (ALAC durumunda) ve matematiksel ve üniversite izleyicilerinin veri sıkıştırma algoritmalarıyla çok ilgilendiklerinden kaynaklanmaktadır.
Yukarıdakilere ek olarak, ses arşivleyicileri ve ses kodekleri unutulmuş ya da hak edilmemiş çok sayıda unutulmuş (var). Bazılarının teknik özellikleri tabloda bulunabilir:
tıklanabilir:
Sadece yaygın kullanımda olan ve yazma sırasında internette bulunabilenleri daha ayrıntılı olarak ele alacağız. Onlardan sadece bir düzine var.
Bölüm II - UYGULAMA:
Soldan sağa: 1. mavi bölge SSDS (Sony Dinamik Dijital Ses), 2. gri bölge Dolby Digital (delme arasında), 3. Analog Ses (kayıtta olduğu gibi) ve 4. zaman kodu DTS (mavi).
İşte yukarıdakilerin dokuzunun 2009 yılı için yeni bir karşılaştırması:
Bölüm III. - TEST:
Karşılaştırma platformda gerçekleştirildi:
İşlemci: DualCore Intel Core i3 530, 2933 MHz (x86, x86-64, MMX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2)
Anakart. tahta: Asus P7H55-V
Rastgele erişimli hafıza: 2x2Gb DDR3-1333
HDD: Seagate SATA 160GB 8 MB önbellek (Sistem), Hitachi SATA-II 500GB 16 MB önbellek (Kaynak), Hitachi SATA-II 1000GB 32 MB önbellek (Hedef)
1. Kayıpsız Ses (LA) - Bu çok eski kodek (2004) sıkıştırmada tartışmasız kazanan oldu. Aynı zamanda, kodlama hızının (aynı OptimFROG veya WavPack ile karşılaştırıldığında) oldukça kabul edilebilir olduğu kadar, yeterli bir kod çözme hızı da not edilmelidir. LA dosyası foo_benchmark eklentisi kullanılarak çözülmemiş olsa da, tökezlemeden veya kaydırma gecikmeleri olmadan mükemmel bir şekilde oynatıldı.
Sadece yazarın neden kaynak kodu açmadan böyle güzel bir codec'i terk ettiğini merak edebiliriz.
2. OptimFROG - LA'nın çok gerisinde değil. Ancak hızı çok hızlı olarak adlandırılamaz. Ayrıca, bir dosyada gezinirken yüksek bir gecikme tatsız bir andır - bazen çok can sıkıcıdır.
3. Maymunun Sesi - Popüler ancak kaynak yoğun bir codec bileşeni. Gerçekten yüksek sıkıştırma sağlar, ancak yine kaydırma sorunları vardır. (Testin yazarı dosyayı hala veri kaybı ile dolu olan "Deli" seçeneğiyle sıkıştırmış görünüyor).
4. TAK - Bu aktif olarak geliştirilen codec bileşeni memnun etmiyor. Üç parametrenin tümünü (sıkıştırma, kodlama, kod çözme) dikkate alırsanız, TAK en çekici görünür. Yüksek çalışma hızı, işlemci optimizasyonlarının (SSSE3 dahil) aktif kullanımı ile açıklanmaktadır. Ve iki çekirdeğin kullanılması, kodlama hızında neredeyse iki kat artış sağlar! Bu nedenle, TAK durumunda, modern işlemcileri kullanmanın avantajı en belirgindir.
5. WavPack - dürüst olmak gerekirse, bu codec bileşeninin neden popülerlik kazandığını bilmiyorum. Orta sıkıştırma kodlaması, FLAC ile karşılaştırılabilir sonuçlar verir ve yüksek sıkıştırma modlarının kullanılması, hızda haksız bir düşüşe yol açar. Bu codec bileşeninin ana avantajı geniş desteği ve işlevselliği (çok kanallı ses desteği, karma mod dahil) olmasına rağmen, size bu testte sorunun bu tarafını dikkate almadığımızı hatırlatırım.
6. Gerçek Ses (TTA) - burada çok yüksek bir kodlama hızı ve kabul edilebilir bir sıkıştırma oranı (FLAC'dan biraz daha yüksek) dışında belirtilmelidir. Ayrıca, kod çözme hızı çok yüksek olarak adlandırılamaz.
7. FLAC- sıkıştırma oranı ortalama, ancak kod çözme hızı memnun. Doğru, bu kodekin halk arasında liderliğinin ana nedeni açık kaynak ve sonuç olarak en geniş donanım / yazılım desteğidir.
8. Elma Kayıpsız (ALAC) - Dikkat çekici olmayan ancak aktif olarak geliştiriciler tarafından implante edilmeye devam eden bu kodeklerden biri (bu durumda, Apple). Düşük sıkıştırma ve kod çözme hızı. Sıkıştırma hızı ortalamadır. İPod kullanıcıları dışında, başka seçenekleri yok.
9. WMA Kayıpsız - ALAC'a benzer bir durum, ancak burada Microsoft dev şirketi ile uğraşıyoruz. Daha az sıkıştırma, ortalama sıkıştırma oranı. Kod çözme hızı nispeten yüksektir. Bu kayıpsız codec bileşenini kullanmanın gerekli olacağı bir durumu hayal etmek zordur.
Bölüm IV - GENEL SONUÇLAR:
Seçim basittir ve iki noktadan oluşur:
Disk alanı önemliyse, Monkey's Audio'yu kullanırız (ARE, 1 TB diskte yaklaşık 100 GB veya yaklaşık 300 standart CD albümü olacak FLAC'den% 8-12 daha iyi sıkıştırır) Aynı şey İnternet'te dağıtım için de geçerlidir. Koleksiyonumu saklıyorum Ekstra Yüksek sıkıştırma seçeneğiyle Monkey’in Ses biçimindedir. Çeşitli LA'ları ve diğerlerini kullanmıyorum, çünkü Maymunun Sesi ile karşılaştırıldığında kullanımlarından elde edilen kazanç küçük.
Linux altında çalışan çeşitli oyuncular ve medya demir parçaları ile uyumluluk önemliyse ve sadece FLAC kullanmayın. Oyuncular için IMHO olmasına rağmen kendisi ve MP3 için oldukça uygundur, çünkü asıl şey ses değil, MÜZİK!
Gelecekte, TTA'nın gelişimine bakacağız, ancak öznel düşüncem TTA'nın "evsiz mesafe" ye buharlı lokomotif için zaten geç kaldığıdır.
"Haşhaş sürücüler" ve "Ai-Fonts" için - şimdiye kadar bildiğim kadarıyla bir seçim - bir tef ve ALAC formatında farklı kod dönüştürücüler etrafında dans ediyor.
Ve unutmayın, dosyaları her zaman bir codec bileşeninden diğerine aktarabilirsiniz ve kalite kaybı olmadan, kayıpsız sıkıştırma codec bileşenlerinin aksine kayıpsız sıkıştırma codec bileşenlerinin iyi olduğu budur.
Kazı "lirik" sayısı BİR KEZ.
"Udifilov" için. Ses formatlarındaki farklılıklar - HAYIR! “Yüksekliğin doğal rengi değil”, “zımbanın okunaksızlığı”, “sahnenin lekelenmesiyle ortadaki peçe” gibi - bu SİSTEMİNİZdedir. Codec bileşenleri oynatılmıyor, kod çözülüyor, hiçbir şey eklenmiyor ve hiçbir şey silinmiyor.
Digression "lirik" sayı İKİ.
Bu makale, müzik severler ve müzik koleksiyoncuları için yazılmıştır - yeni başlayanlar ve orta köylüler, aynı müzik aşığı ve koleksiyoncu.
Gurams, Kvods, Sensei ve Audio World'den Militant Udifils'in diğer Büyük Dümençileri burada ilgilenmeyecek. Makalenizi "blackjack ve kodeklerle" yazın.
İlginç bilgiler:
Şu anda, 1154 dosya uzantıları ses verileri ile bir şekilde veya başka bir şekilde kayıtlı!
kaynaklar:
wiki.hydrogenaudio.org/
ru.wikipedia.org/
resmi program sitelerinin yanı sıra.
İyi günler.
Bugün kayıpsız veri sıkıştırma konusuna değinmek istiyorum. Hub üzerinde belirli algoritmalara ayrılmış makaleler olmasına rağmen, bu konuda biraz daha ayrıntılı olarak konuşmak istedim.
Her zamanki gibi hem matematiksel bir açıklama hem de bir açıklama vermeye çalışacağım, böylece herkes kendileri için ilginç bir şeyler bulabilir.
Bu makalede temel sıkıştırma anlarına ve ana algoritma türlerine değineceğim.
Sıkıştırma. Bugünlerde gerekli mi?
Evet, elbette. Tabii ki hepimiz artık hem büyük hacimli depolama ortamlarına hem de yüksek hızlı veri iletim kanallarına erişebildiğimizi anlıyoruz. Ancak, aynı zamanda, iletilen bilgi hacimleri de artmaktadır. Birkaç yıl önce bir diske uyan 700 megabaytlık filmler izleseydik, bugün HD kalitesinde filmler onlarca gigabayt kaplayabilir.
Tabii ki, her şeyi ve her şeyi sıkıştırmanın faydaları çok fazla değil. Ancak, gerekirse, sıkıştırmanın son derece yararlı olduğu durumlar vardır.
- Belgeleri e-postayla gönderme (özellikle mobil cihazları kullanan çok sayıda belge)
- Web sitelerinde doküman yayınlarken trafikten tasarruf etme ihtiyacı
- Depolama alanı değiştirirken veya eklerken disk alanından tasarruf etmek zordur. Örneğin, bu, sermaye harcamaları için bir bütçe almanın kolay olmadığı ve yeterli disk alanı olmadığı durumlarda olur.
Tabii ki, sıkıştırmanın yararlı olacağı daha birçok farklı durum ortaya çıkarabilirsiniz, ancak bu birkaç örnek bizim için yeterlidir.
Tüm sıkıştırma yöntemleri iki büyük gruba ayrılabilir: kayıplı sıkıştırma ve kayıpsız sıkıştırma. Kayıpsız sıkıştırma, bilginin bitlere göre doğru bir şekilde geri yüklenmesi gerektiği durumlarda kullanılır. Bu yaklaşım, örneğin metin verileri sıkıştırılırken mümkün olan tek yaklaşımdır.
Bununla birlikte, bazı durumlarda, doğru bilgi kurtarma gerekli değildir ve kayıpsız sıkıştırmanın aksine, genellikle kaybı daha kolay olan ve daha yüksek bir arşivleme sağlayan kayıplı sıkıştırmayı uygulayan algoritmalar kullanılmasına izin verilir.
Şimdi kayıpsız sıkıştırma algoritmalarına geçelim.
Evrensel kayıpsız sıkıştırma yöntemleri
Genel durumda, sıkıştırma algoritmalarının oluşturulduğu üç temel seçenek vardır.
İlk grup akış dönüşüm yöntemleri. Bu, halihazırda işlenmiş olan yeni gelen sıkıştırılmamış verilerin bir açıklamasını ifade eder. Bu durumda, hiçbir olasılık hesaplanmaz, karakter kodlaması, yalnızca LZ yöntemlerinde (Abraham Lempel ve Jacob Ziva'dan sonra adlandırılır) olduğu gibi, zaten işlenmiş olan veriler temelinde gerçekleştirilir. Bu durumda, kodlayıcı tarafından zaten bilinen bir alt dizenin ikinci ve diğer oluşumları, ilk oluşumuna referanslarla değiştirilir.
İkinci grup yöntemler istatistiksel sıkıştırma yöntemleridir. Buna karşılık, bu yöntemler uyarlanabilir (veya akış) ve bloğa ayrılır.
İlk (uyarlanabilir) versiyonda, yeni veriler için olasılıkların hesaplanması kodlama sırasında zaten işlenmiş olan verilere dayanmaktadır. Bu yöntemler arasında Huffman ve Shannon-Fano algoritmalarının uyarlanabilir versiyonları bulunmaktadır.
İkinci (blok) durumda, her veri bloğunun istatistikleri ayrı olarak hesaplanır ve en sıkıştırılmış bloğa eklenir. Bunlar arasında Huffman, Shannon-Fano ve aritmetik kodlama yöntemlerinin statik sürümleri bulunur.
Üçüncü grup yöntemler, blok dönüştürme yöntemleridir. Gelen veriler daha sonra bir bütün olarak dönüştürülen bloklara bölünür. Bununla birlikte, özellikle blokların permütasyonuna dayanan bazı yöntemler, veri miktarında önemli (hatta herhangi bir) azalmaya yol açmayabilir. Bununla birlikte, bu tür bir işlemden sonra, veri yapısı önemli ölçüde iyileşir ve daha sonra diğer algoritmalarla sıkıştırma daha başarılı ve daha hızlıdır.
Veri sıkıştırmanın dayandığı genel ilkeler
Tüm veri sıkıştırma yöntemleri basit bir mantık ilkesine dayanmaktadır. En sık oluşan öğelerin daha kısa kodlarla kodlandığını ve daha az yaygın olanların daha uzun kodlarla kodlandığını hayal edersek, tüm verilerin depolanması, tüm öğelerin aynı uzunlukta kodlarla temsil edilenden daha az alana ihtiyacı olacaktır.
Eleman oluşum sıklıkları ve optimum kod uzunlukları arasındaki kesin ilişki, kayıpsız maksimum sıkıştırma sınırını ve Shannon'ın entropisini tanımlayan Shannon'un kaynak kodlama teoreminde açıklanmaktadır.
Biraz matematik
Bir elemanın (s i) ortaya çıkma olasılığı p (s i) 'ye eşitse, bu elemanı temsil etmek en avantajlı olacaktır - log 2 p (s i) bitleri. Kodlama sırasında tüm elemanların uzunluğunun log 2 p (s i) bite indirgenmesini sağlamak mümkünse, tüm kodlanmış sekansın uzunluğu olası tüm kodlama yöntemleri için minimum olacaktır. Ayrıca, tüm F \u003d (p (s i)) elemanlarının olasılık dağılımı değişmezse ve elemanların olasılıkları birbirinden bağımsızsa, kodların ortalama uzunluğu şu şekilde hesaplanabilir:
Bu değere, olasılık dağılımının F entropisi veya belirli bir zamanda kaynağın entropisi denir.
Bununla birlikte, genellikle bir elemanın ortaya çıkma olasılığı bağımsız olamaz, aksine, bazı faktörlere bağlıdır. Bu durumda, her yeni kodlanmış eleman s i için, olasılık dağılımı F bir miktar F k alacak, yani her eleman için F \u003d F k ve H \u003d H k alacaktır.
Başka bir deyişle, kaynağın k durumunda olduğunu söyleyebiliriz; bu, tüm elemanlar s i için belirli bir olasılık kümesine p k (s i) karşılık gelir.
Bu nedenle, bu düzeltme göz önüne alındığında, kodların ortalama uzunluğunu şu şekilde ifade edebiliriz:
Burada P k, kaynak k durumunda kaynağı bulma olasılığıdır.
Bu nedenle, bu aşamada, sıkıştırmanın sık görülen öğeleri kısa kodlarla değiştirmeye dayalı olduğunu biliyoruz ve bunun tersi de geçerli ve kodların ortalama uzunluğunu nasıl belirleyeceğimizi biliyoruz. Ancak kod, kodlama nedir ve nasıl olur?
Hafızasız Kodlama
Belleği olmayan kodlar, verilerin sıkıştırılabileceği en basit kodlardır. Hafızasız kodda, kodlanmış veri vektöründeki her karakterin yerine ikili diziler veya kelimeler önek kümesindeki bir kod sözcüğü gelir.
Bence en açık tanım değil. Bu konuyu daha ayrıntılı olarak ele alın.
Biraz alfabe verilmesine izin ver ![]() bazı (sonlu) harflerden oluşur. Bu alfabedeki her bir sonlu karakter dizisini çağırıyoruz (A \u003d a 1, a 2, ..., a n) tek kelimeyleve n sayısı bu kelimenin uzunluğudur.
bazı (sonlu) harflerden oluşur. Bu alfabedeki her bir sonlu karakter dizisini çağırıyoruz (A \u003d a 1, a 2, ..., a n) tek kelimeyleve n sayısı bu kelimenin uzunluğudur.
Başka bir alfabe de verilsin ![]() . Benzer şekilde, bu alfabedeki kelimeyi B olarak belirtin.
. Benzer şekilde, bu alfabedeki kelimeyi B olarak belirtin.
Alfabedeki tüm boş olmayan kelimelerin kümesi için iki gösterim daha sunuyoruz. - ilk alfabedeki boş olmayan kelimelerin sayısı ve ikincideki -.
Ayrıca, ilk alfabedeki her A kelimesi ile ikinci kelimeden B \u003d F (A) kelimesi ile ilişkilendirilen bir haritalama F verilsin. Sonra B kelimesi çağrılır kod A kelimeleri ve orijinal kelimeden koduna geçiş denir kodlama.
Kelime aynı zamanda bir harften oluşabileceğinden, ilk alfabenin harflerinin ve ikincisinden karşılık gelen kelimelerin yazışmalarını belirleyebiliriz:
a 1<-> B 1
a 2<-> B 2
…
a n<-> B n
Bu maçın adı düzenve ∑ ile gösterilir.
Bu durumda, B 1, B 2, ..., B n kelimeleri temel kodlarve yardımlarıyla kodlama türü - alfabetik kodlama. Elbette, yukarıda tarif ettiğim her şeyi bilmesek bile, çoğumuz bu tür kodlama ile karşılaştık.
Bu yüzden kavramlara karar verdik alfabe, kelime, kod, ve kodlama. Şimdi kavramı tanıtıyoruz önek.
B kelimesinin B \u003d B "B" "biçimini almasına izin verin. Sonra B" başlangıcı olarak adlandırılır veya önek B ve B "" kelimeleri - sonu. Bu oldukça basit bir tanımdır, ancak herhangi bir B kelimesi için hem belirli bir boş word (“boşluk”) hem de B kelimesinin kendisinin hem başlangıç \u200b\u200bhem de bitiş olarak kabul edilebileceği belirtilmelidir.
Bu nedenle, belleksiz kodların tanımını anlamaya yaklaşıyoruz. Anlamamız gereken son tanım önek kümesidir. Herhangi bir 1≤i, j≤r, i ≠ j için, B i kelimesi B j kelimesinin bir öneki değilse, şema ix bir önek özelliğine sahiptir.
Basitçe söylemek gerekirse, bir önek kümesi, hiçbir öğenin başka bir öğenin öneki (veya başlangıcı) olmadığı sonlu bir kümedir. Böyle bir kümenin basit bir örneği, örneğin, normal alfabe.
Böylece temel tanımları anladık. Öyleyse kendini kodlayan hafızasızlık nasıl olur?
Üç aşamada gerçekleşir.
- Orijinal mesajın karakterlerinin bir alfabesi Ψ derlenir ve alfabenin karakterleri mesajda meydana gelme olasılıklarının azalan sırasına göre sıralanır.
- Alphabet alfabesinden her i sembolü, Ω önek kümesindeki belirli bir B i kelimesi ile ilişkilidir.
- Her karakter kodlanır, ardından kodlar sıkıştırmanın sonucu olacak tek bir veri akışında birleştirilir.
Bu yöntemi gösteren kanonik algoritmalardan biri Huffman algoritmasıdır.
Huffman Algoritması
Huffman algoritması, giriş veri bloğunda aynı baytların görülme sıklığını kullanır ve daha kısa uzunluktaki bir bit zincirinin sık bloklarını eşleştirir ve tersi de geçerlidir. Bu kod asgari düzeyde gereksizdir. Giriş akışından bağımsız olarak, çıkış akışının alfabesinin yalnızca 2 karakterden (sıfır ve bir) oluştuğu durumu düşünün.
Her şeyden önce, Huffman algoritması ile kodlama yaparken, ∑ devresini oluşturmamız gerekir. Bu aşağıdaki gibi yapılır:
- Giriş alfabesinin tüm harfleri azalan olasılık sırasına göre sıralanmıştır. Çıkış akışının alfabesinden (yani kodlayacağımız) tüm kelimeler başlangıçta boş kabul edilir (çıkış akışının alfabesinin sadece karakterlerden (0,1) oluştuğunu hatırlıyorum).
- En az ortaya çıkma olasılığı olan iki j-1 ve giriş akışının j karakteri, olasılıkla birlikte bir "sözde-sembol" halinde birleştirilir. p Kurucu karakterlerinin olasılıklarının toplamına eşittir. Sonra B j-1 kelimesinin başına 0 ve B j kelimesinin başına 1 ekleriz, bu karakter sırasıyla j-1 ve j karakter kodları olacaktır.
- Bu karakterleri orijinal mesajın alfabesinden kaldırıyoruz, ancak oluşturulan sözde sembolü bu alfabeye ekliyoruz (doğal olarak, olasılığı dikkate alınarak doğru yere alfabeye eklenmelidir).
Adım 2 ve 3, alfabede, alfabenin tüm orijinal karakterlerini içeren 1 sahte karakter kalana kadar tekrarlanır. Ayrıca, her adımda ve her karakter için, karşılık gelen Bi kelimesi değiştiğinden (bir veya sıfır ekleyerek), bu prosedür tamamlandıktan sonra, belirli bir B i kodu, i i alfabesinin her bir ilk karakterine karşılık gelir.
Daha iyi bir örnek için küçük bir örnek düşünün.
Sadece dört karakterden oluşan bir alfabemiz olduğunu varsayın ((1, 2, 3, 4). Ayrıca, bu simgelerin ortaya çıkma olasılıklarının sırasıyla p 1 \u003d 0.5; p2 \u003d 0.24; p3 \u003d 0.15; p 4 \u003d 0.11 (tüm olasılıkların toplamı bire eşittir).
Böylece, bu alfabe için şema oluşturacağız.
- En az olasılıkla (0.11 ve 0.15) iki karakteri p "sözde karakterine" birleştirin.
- İki karakteri en az olasılıkla (0.24 ve 0.26) p sözde karakterine birleştiriyoruz.
- Birleştirilmiş karakterleri kaldırırız ve ortaya çıkan sahte karakteri alfabeye ekleriz.
- Son olarak, kalan iki karakteri birleştirin ve ağacın tepesini alın.
Bu işlemi gösterirseniz, aşağıdaki gibi bir şey elde edersiniz:
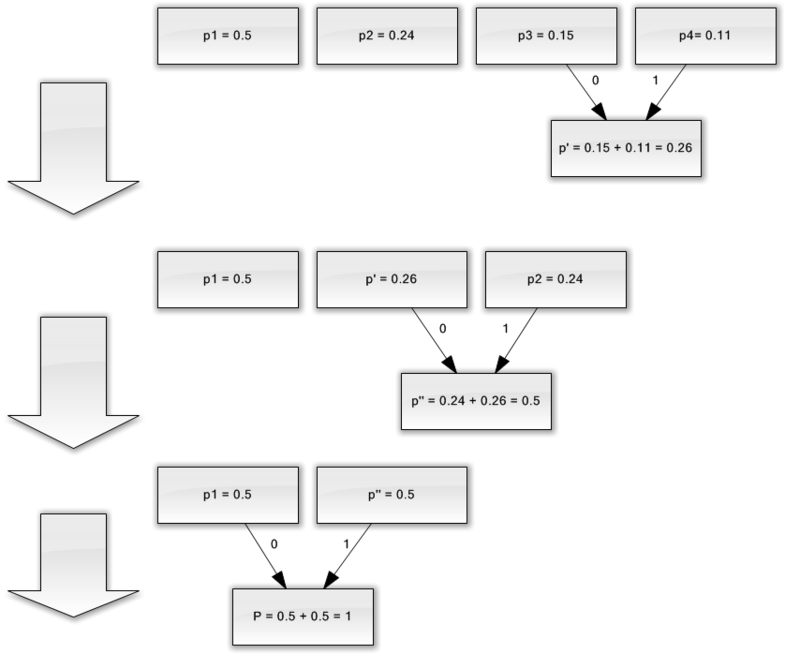
Gördüğünüz gibi, her birleştirme ile birleştirilecek karakterlere 0 ve 1 karakterlerini atarız.
Böylece, ağaç inşa edildiğinde, her karakter için kodu kolayca alabiliriz. Bizim durumumuzda, kodlar aşağıdaki gibi görünecektir:
a 1 \u003d 0
a 2 \u003d 11
a 3 \u003d 100
a 4 \u003d 101
Bu kodların hiçbiri diğerinin öneki olmadığından (yani kötü şöhretli önek setini aldık), çıkış akışındaki her kodu benzersiz bir şekilde tanımlayabiliriz.
Böylece, en sık kullanılan karakterin en kısa kodla kodlandığını ve tam tersini sağladık.
Her karakteri saklamak için başlangıçta bir bayt kullanıldığını varsayarsak, verileri ne kadar azaltabileceğimizi hesaplayabiliriz.
Girişte 1000 karakterlik bir dize olduğunu varsayalım ki burada 1 karakteri 500 kez, 2 240, 3350 ve 4 110 kez meydana geldi.
Başlangıçta, bu dize 8000 bit işgal etti. Kodlamadan sonra ∑p i l i \u003d 500 * 1 + 240 * 2 + 150 * 3 + 110 * 3 \u003d 1760 bit uzunluğunda bir dize alırız. Böylece, verileri her bir akım sembolünün kodlamasına ortalama 1.76 bit harcayarak 4.54 kez sıkıştırabildik.
Shannon'a göre, ortalama kod uzunluğunun ![]() . Olasılık değerlerimizi bu denkleme koyarsak, elde ettiğimiz sonuca çok, çok yakın olan 1.75496602732291'e eşit ortalama kod uzunluğunu elde ederiz.
. Olasılık değerlerimizi bu denkleme koyarsak, elde ettiğimiz sonuca çok, çok yakın olan 1.75496602732291'e eşit ortalama kod uzunluğunu elde ederiz.
Bununla birlikte, verilerin kendisine ek olarak, kodlanan verinin son boyutunu hafifçe artıracak olan kodlama tablosunu saklamamız gerektiğine dikkat edilmelidir. Açıkçası, farklı durumlarda algoritmanın farklı varyasyonları kullanılabilir - örneğin, önceden tanımlanmış bir olasılık tablosu kullanmak bazen daha etkilidir ve bazen sıkıştırılabilir verilerden geçerek dinamik olarak derlenmesi gerekir.
Sonuç
Bu nedenle, bu makalede kayıpsız sıkıştırmanın meydana geldiği genel prensipler hakkında konuşmaya çalıştım ve ayrıca kanonik algoritmalardan birini inceledim - Huffman kodlaması.
Makale habro topluluğunun tadı içinse, kayıpsız sıkıştırma ile ilgili daha ilginç şeyler olduğu için bir netice yazmaktan mutluluk duyacağım; bunlar hem klasik algoritmalar hem de ön veri dönüşümleridir (örneğin, Burroughs-Wheeler dönüşümü) ve tabii ki ses, video ve görüntüleri sıkıştırmak için özel algoritmalardır (bence en ilginç konu).
edebiyat
- Vatolin D., Ratushnyak A., Smirnov M. Yukin V.Veri sıkıştırma yöntemleri. Cihaz arşivleme, görüntü ve video sıkıştırma; ISBN 5-86404-170-X; 2003 yıl
- D. Salomon. Veri, görüntü ve sesin sıkıştırılması; ISBN 5-94836-027-X; 2004.
Sesi kayıpsız sıkıştıran kodekler, taşınabilir MP3 çalarlar dünyasında nispeten popüler hale geldi. Gerçek şu ki, bu kodekler sesi kalite kaybı ile sıkıştıran kodeklerin övünebilecek kadar büyük sıkıştırma oranlarını karşılayamazlar. MP3 çaların kullanıcılarına yalnızca son üç veya dört yıl içinde büyük miktarda bellek yaygınlaştı - ve MP3 çalarda büyük hacimli hafızaların ortaya çıkmasıyla kayıpsız müzik sıkıştırma popüler hale geldi. Tabii ki, kalite kaybı olmadan müzik dinlemek isteyenler bunu her zaman yapmıştır (örneğin, Ses CD çalarlarını kullanarak) ve günümüzde herkes (doğal olarak, oyuncularının karşılık gelen codec'lerinin desteği ile) Kayıpsız codec'leri eylemde deneyebilir .
Ses verilerini, kayıpla sıkıştırılan codec bileşenlerinden kalite kaybı olmadan sıkıştıran codec bileşenleri arasındaki temel fark, kalite kaybı olmayan codec bileşenlerinin, kayıpla sıkıştırıldığında gereksiz olarak değerlendirilebilecek bilgileri ses akışından kaldırmamasıdır. Kayıpsız codec bileşeninin ana görevi, orijinal ses bilgilerini tek bir bilgi bile kaybetmeden olabildiğince sıkıştırmaktır.
Kayıpsız kodekleri destekleyen durum şu anda en yaygın desteğin doğrudan Apple ve oyuncuları ile ilişkili olan ALAC kodek olduğu şekildedir. Diğer codec bileşenleri hala birkaç oyuncu tarafından desteklenir, bazen oyuncunun codec bileşenini desteklemesi için, oyuncunun yanıp sönmesini gerektirir ve belki de Kayıpsız codec bileşenlerini destekleyen oyuncular için en ünlü bellenim, RockBox resmi değil, alternatif bir bellenimdir.
Kayıpsız codec bileşenleri ile çalışırken, Cue dosyaları veya dosya dizin kartları görebilirsiniz. İpucu dosyaları, örneğin, tüm albümün depolandığı bir büyük (yaklaşık 300 MB) dosya olan MP3 ve WAV dosyalarıyla daha az sıklıkla FLAC veya APE dosyalarıyla birlikte dağıtılır. İşaret dosyası - büyük bir dosyayı parçalara bölme ve bu parçaların adları hakkında bilgi içerir. Tek tek dosyalarla çalışmak daha uygundur, ancak CUE dosyasında yer alan bilgilere dayanarak, CUE dosyasına sahip büyük bir FLAC dosyası elinize geçseniz bile, kaynak dosya ayrı parçalara bölünebilir - yazılımı bu sorunu çözebilir.
Popüler FLAC formatıyla kayıpsız veri sıkıştırma formatlarının açıklamasına başlayalım.
FLAC
FLAC (Free Lossless Audio Codec), Xiph tarafından geliştirilen kayıpsız bir ses sıkıştırma formatıdır. Org Vakfı. Bu herkesin kullanabileceği tamamen ücretsiz bir biçimdir.
Kayıpsız ses verilerini depolayan FLAC ve diğer kodeklerin çalışması, geleneksel arşivleyicilerinkine benzer. Bununla birlikte, özel algoritmalar nedeniyle, bu tür kodeklerin ses bilgilerinin sıkıştırılmasındaki etkinliği geleneksel arşivleyicilerinkinden çok daha yüksektir.
FLAC biçimi bir akış biçimi olarak geliştirildi - FLAC dosyasındaki bilgiler, her biri diğer çerçevelerden ayrı olarak çözülebilen çerçevelere (çerçevelere) bölünür.
Genellikle, FLAC kaynak dosyayı, örneğin Ses CD'si kalitesini% 40-50 oranında sıkıştırabilir. Sonuç olarak, elde edilen kaydın bit hızı yaklaşık 800 Kbit / s'ye eşittir.
FLAC formatında, CD'leri gerektiğinde orijinal diski tamamen yeniden oluşturabileceğiniz şekilde kaydetmek mümkündür - bu, sonraki kurtarma olasılığı ile CD'lerinin dijital kopyalarını oluşturmak isteyenler için çok uygundur.
FLAC dosyalarının kodlama ve kod çözme hızı aynı değildir. Kodlama hızı sıkıştırma seviyesine ve sistemin hızına bağlıdır - yüksek sıkıştırma seviyelerinde oldukça yavaş olabilir. Bununla birlikte, kod çözme çok hızlıdır - modern MP3 çalarlar onunla kolayca başa çıkabilir.
Ücretsiz ücretsiz kullanım olasılığı nedeniyle, neredeyse tüm modern işletim sistemleri temelinde FLAC ile çalışabilirsiniz, giderek daha fazla MP3 çalar bu formatı desteklemektedir.
FLAC formatına kodlama
FLAC dosyalarını kodlamak için yardımcı programı adresinden indirebilirsiniz. Bu kod çözücünün kendisini ve kod çözücü için bir yazılım kabuğu olan Frontend denir. Dağıtımın boyutu yaklaşık 2.5 MB alır. Codec ile çalışmak basittir: ilgilenilen dosyaları program penceresine eklersiniz (Şekil 4.1.) Dosyaları Ekle düğmesini kullanarak kodlama seçeneklerini yapılandırın ve Kodla düğmesini tıklatın - program bir FLAC dosyası oluşturur.
Şek. 4.1.
En önemli kodek ayarlarına bakalım. İlk olarak, Kodlama Seçenekleri parametre grubunda duralım.
Level parametresi veri sıkıştırma seviyesinden sorumludur. 0 ila 8 arasında değişebilir. Sıkıştırma seviyesi ne kadar yüksek olursa, bitmiş dosya o kadar küçük olur, ancak dosyaları kodlamak için gereken süre de o kadar uzun olur. Hızlı bilgisayarlarda, örneğin 30 megabaytlık bir WAV dosyasını kodlarken Seviye 0 ile Seviye 8 arasındaki fark birkaç saniye olabilir. Boyut, orijinal dosya boyutundan yaklaşık% 10 farklıdır. PC'nizde bu seçeneği denemelisiniz - belki de birkaç yüz dosyayı kodlarsanız, daha yüksek bir çalışma hızına göre daha düşük bir sıkıştırma düzeyi tercih edersiniz.
Verify parametresi kodlayıcıya çıktı dosyalarını kontrol etmesini bildirir.
Etiket ekle parametresi, bitmiş dosyaya etiketler ekler (örneğin, şarkının adını, yazarını vb. İçerebilir) - Etiket Conf düğmesine tıklayarak bunları yapılandırabilirsiniz. (Etiket özelleştirme).
Replaygain parametresi, dosyalara dosyanın ses düzeyini belirten bir parametre ekler. “Giriş dosyalarını bir albüm olarak gir” parametresi ayarlanmışsa, albümdeki tüm girişler aynı ses seviyesinde çalar.
Genel Seçenekler parametre grubu iki parametre içerir. Belki de OGG-Flac parametresi burada belirtilmelidir. Bu parametre sıfırlanırsa, FLAC verileri standart bir FLAC kabına paketlenir. Yalnızca alınan FLAC dosyalarını dinlemeyi planlıyorsanız, bu parametreyi ayarlayamazsınız ve bu dosyalar için planlarınız daha kapsamlıysa - örneğin, bunları düzenlemeyi planlıyorsanız, filmlere eklemek için kullanın, Ogg-FLAC parametresini etkinleştirmek en iyisidir.
Çıktı Dizini parametresi, çıktı dosyalarının yer alacağı dizinin yolunu içerir.
Kod çözme seçenekleri parametre grubunda bir Dec. parametresi vardır. Hatalar aracılığıyla - Kod çözme sırasında hatalar olsa bile bir dosyanın kodunu çözmek istiyorsanız ayarlayın. Kod çözme kodlamanın tersidir - yani FLAC dosyalarını WAV dosyalarına dönüştürerek kodunu çözebilirsiniz. Kod çözme için, elbette, program penceresine FLAC dosyaları eklemeniz gerekecektir.
Her şey yapılandırıldıktan sonra FLAC dosyaları oluşturmak için Kodla düğmesine tıklayın veya mevcut FLAC dosyalarının kodunu çözmek istiyorsanız, Kod Çöz düğmesine tıklayın.
Yukarıdakilere ek olarak, diğer programlar FLAC'yi kodlayabilir. Örneğin, bu zaten ImTOO Audio Encoder tarafından bilinir - FLAC formatına kodlamak için, sadece format listesinden seçin (Şek. 4.2.), Bundan sonra Kes düğmesine hemen tıklayabilir veya biraz sonra, dosya adlarını ayarladıktan sonra yapabilirsiniz.

