17.07.2019
Dešifrovanie kódu ASCII. ASCII kódovanie
Materiál na samostatné štúdium na tému Prednášky 2
Tabuľka kódov ASCII (ASCII - Americká norma pre výmenu informácií).
Celkovo možno pomocou kódovacej tabuľky ASCII (obrázok 1) kódovať 256 rôznych znakov. Táto tabuľka je rozdelená na dve časti: hlavná (s kódmi od OOh do 7Fh) a doplnková (od 80h do FFh, kde písmeno h označuje, že kód patrí do systému hexadecimálnych čísel).
Obrázok 1
Na kódovanie jedného znaku z tabuľky sa pridelí 8 bitov (1 bajt). Pri spracovaní textové informácie jeden bajt môže obsahovať kód nejakého znaku - písmená, čísla, interpunkčné znamienka, akčné značky atď. Každá postava má svoj vlastný kód vo forme celého čísla. V tomto prípade sa všetky kódy zhromažďujú v špeciálnych tabuľkách nazývaných kódovanie. Pomocou nich sa kódový symbol prevedie na viditeľné zobrazenie na obrazovke monitora. Výsledkom je, že akýkoľvek text v počítačovej pamäti je reprezentovaný ako postupnosť bajtov so znakovými kódmi.
Napríklad slovo ahoj! budú kódované nasledovne (tabuľka 1).
Tabuľka 1
Obrázok 1 zobrazuje znaky zahrnuté v štandardnom (anglickom) a pokročilom (ruskom) ASCII kódovaní.
Prvá polovica tabuľky ASCII je štandardizovaná. Obsahuje kontrolné kódy (od 00h do 20h a 77h). Tieto kódy sa z tabuľky odstránia, pretože sa nevzťahujú na textové prvky. Uvádzajú sa tu aj interpunkčné znamienka a matematické znaky: 2lh - !, 26h - &, 28h - (, 2Bh - +, ..., veľké a malé písmená v latinke: 41h - A, 61h - a.
Druhá polovica tabuľky obsahuje národné písma, pseudografické symboly, z ktorých je možné zostavovať tabuľky, špeciálne matematické znaky. Spodnú časť tabuľky kódovania je možné nahradiť pomocou príslušných ovládačov - pomocných programov riadenia. Táto technika vám umožňuje používať niekoľko písiem a ich náhlavných súprav.
Displej pre každý symbolický symbol by mal zobrazovať obraz symbolu - nielen digitálny kód, ale zodpovedajúci obrázok, pretože každý symbol má svoj vlastný tvar. Opis tvaru každého symbolu je uložený v špeciálnom generátore pamäte displeja - znakov. Symbol sa zobrazuje na obrazovke displeja IBM PC napríklad pomocou bodiek tvoriacich maticu symbolov. Každý pixel v takejto matici je obrazovým prvkom a môže byť jasný alebo tmavý. Tmavá bodka je kódovaná číslom 0, svetlá (svetlá) - 1. Ak zobrazujete tmavé pixely ako bodku v poli matice znaku a svetlé pixely s hviezdičkou, môžete graficky znázorniť tvar znaku.
Ľudia v rôznych krajinách používajú znaky na písanie slov svojho rodného jazyka. V súčasnosti je väčšina aplikácií vrátane e-mailových systémov a webových prehliadačov čisto 8-bitová, to znamená, že podľa normy ISO-8859-1 dokážu iba zobrazovať a správne prijímať 8-bitové znaky.
Na svete je viac ako 256 znakov (berúc do úvahy azbuku, arabčinu, čínštinu, japončinu, kórejčinu a thajčinu) a objavuje sa tiež stále viac nových znakov. A to vytvára pre mnoho používateľov tieto priestory:
V tom istom dokumente nie je možné použiť znaky z rôznych znakových sád. Pretože každý textový dokument používa svoju vlastnú sadu kódovaní, s automatickým rozpoznaním textu sú veľké problémy.
Objavujú sa nové znaky (napríklad Euro), výsledkom čoho ISO vyvíja novú normu ISO-8859-15, ktorá je veľmi podobná norme ISO-8859-1. Rozdiel je nasledujúci: z kódovacej tabuľky starého štandardu ISO-8859-1 sa odstránia symboly označenia starých mien, ktoré sa v súčasnosti nepoužívajú, aby sa vytvoril priestor pre novo objavené symboly (napríklad eurá). Vďaka tomu môžu mať používatelia rovnaké dokumenty na diskoch, ale v rôznych kódovaniach. Riešením týchto problémov je prijatie jednotného medzinárodného súboru kódovania s názvom univerzálne kódovanie alebo unicode.
Počas tvorby ASCII boli kontrolné znaky, ktoré sú vlastné teletypom a písacím strojom, zahrnuté na začiatku kódovania a postupom času tam tesne zahynuli, hoci sa v 21. storočí prakticky nepoužívajú.
Poskytujem podrobné informácie o kódovaní ASCII:
ASCII (Angl. merican standard code pre janformácie janterchange, [ˈæs.ki]) - názov tabuľky (kódovanie, množina), v ktorej sú číselné kódy spojené s niektorými bežnými tlačenými a netlačenými znakmi. Tabuľka bola vyvinutá a štandardizovaná v USA v roku 1963. Názov „ASCII“ v ruštine sa často vyslovuje ako [ požiadať (-ia) a].
Tabuľka ASCII definuje kódy pre znaky:
- desatinné miesta;
- latinská abeceda;
- národná abeceda;
- interpunkčné znamienka;
- kontrolné znaky.
Príbeh
Spočiatku (1963) bol ASCII vyvinutý na kódovanie znakov, ktorých kódy boli umiestnené v 7 bitoch (128 znakov; 27 \u003d 128), zatiaľ čo najvýznamnejší siedmy bit (číslovanie od nuly) sa použil na kontrolu chýb, ku ktorým došlo počas prenosu údajov.
Postupom času sa kódovanie rozšírilo na 256 znakov (28 \u003d 256); kódy prvých 128 znakov sa nezmenili. ASCII sa začal vnímať ako polovica 8-bitového kódovania a „rozšírený ASCII“ sa nazýval ASCII so zapojeným 8. bitom (napríklad KOI-8).
Prekrytie znakov
Pomocou znaku Backspace (BS) (vracia jeden znak) môžete vytlačiť jeden znak na vrch tlačiarne. V ASCII môžete k písmenám pridávať diakritiku napríklad:
- a BS ‘→ á
- bS `→ à
- bS ^ → â
- o BS / → ø
- c BS, → ç
- n BS ~ → ñ
poznámka: u starých písiem bol apostrof „» “nakreslený so sklonom doľava (porovnaj„ `“ a „´“) a vlnovka „~“ bola posunutá nahor (porovnaj „~“ a „˜“), takže sa zmestili iba do role znaky sú „´“ a „tilda hore“.
Ak rovnaký znak vytlačíte dvakrát na rovnakom mieste, získate tučný znak. Ak tlačíte znak na jednu pozíciu a potom podčiarknete „_“, získa sa podčiarknutý znak.
- a BS a →
- bS _ → a
Táto technika sa stále používa napríklad v systéme pomoci pre ľudí.
Národné možnosti ASCII
Norma ISO 646 (ECMA-6) umožňuje umiestňovanie národných znakov do ASCII. Z tohto dôvodu sa navrhuje nahradiť znaky „@“, „[“, „\\“, „]“, „^“, „` “,„ (“,„ Vertikálna lišta “,„) “,„ ~ “. Symbol libry „£“ môžete tiež umiestniť namiesto znaku libry „#“ a namiesto symbolu dolára „$“ môžete umiestniť znak meny „¤“. Takýto systém je vhodný pre európske jazyky, pretože používajú latinské znaky a len niekoľko ďalších znakov. Variant ASCII, ktorý neobsahuje národné znaky, sa nazýva „US-ASCII“ alebo „medzinárodná referenčná verzia“.
Pre niektoré jazyky s ne latinskými skriptami (ruština, gréčtina, arabčina, hebrejčina) došlo k radikálnejším úpravám ASCII. V jednej z týchto úprav boli namiesto malých latinských písmen umiestnené národné symboly (pre ruštinu a gréčtinu - veľké písmená). Ďalšou úpravou bolo prepínanie medzi US-ASCII a národnou verziou; prepínanie bolo vykonávané „za behu“ - pomocou znakov SO (angl. shift out) a SI (anglicky) shift jan); v tomto prípade bolo možné v národnej verzii latinské písmená úplne nahradiť národnými symbolmi. Pozri tiež: KOI-7.
Následne sa ukázalo byť vhodnejšie použiť 8-bitové kódovanie (kódové stránky), v ktorom je spodná polovica tabuľky s kódmi (0 - 127) obsadená znakmi US-ASCII a horná polovica (128 - 255) je obsadená ďalšími znakmi vrátane sady národných znakov.
Horná polovica tabuľky ASCII pred rozšíreným prijatím Unicode sa teda aktívne používala na reprezentáciu lokalizovaných znakov, písmen miestneho jazyka.
Absencia jediného štandardu na umiestnenie cyrilických znakov v tabuľke ASCII spôsobila veľa problémov s kódovaním (KOI-8, Windows-1251 atď.). Iné jazyky s ne latinskými skriptami tiež trpeli kvôli prítomnosti niekoľkých rôznych kódovaní.
Prvých 128 znakov štandardu Unicode sa zhoduje so zodpovedajúcimi znakmi US-ASCII.
Tabuľka ASCII
.0 .1 .2 .3 .4 .5 .6 .7 .8 .9 .A .B .C .D .E F. 0. NUL SOH STX ETX EOT ENQ ACK BEL BS HT LF VT FF CR SO SI 1. PODĽA DC1 DC2 DC3 DC4 NAK SYN ETB CAN EM SUB ESC FS GS RS US 2. ! « # $ % & ‘ ( ) * + , - . / 3. 0 1 2 3 4 5 6 7 8 9 : ; < = > ? 4. @ B C D E F G H ja J K L M N O 5. P Q R S T U V W X Y Z [ \ ] ^ _ 6. ` b c d e f g hod ja j k l m n o 7. p q r s t u proti w x y z { | } ~ DEL V prvej verzii normy ASCII (1963) boli symboly „šípka nahor“ a „šípka doľava“ umiestnené na pozíciách 0x5e (94) a 0x5f (95). Norma ECMA-6 (1965) ich nahradila znakom vloženia (ktorý sa tiež používa ako symbol „^“) a podčiarkovník „_“.
Kontrolné znaky
Tabuľka ASCII bola vytvorená na výmenu informácií o typoch telefónov. Sada obsahovala netlačiteľné znaky používané ako príkazy na ovládanie zariadenia typu teletyp. Podobné príkazy sa použili v iných nástrojoch na zasielanie správ pred počítačom (Morseov kód, abeceda semafor), pričom sa zohľadnili špecifiká zariadenia.
- NUL, 00 - , empty. Nulový znak bol vždy ignorovaný. Na dierovaných páskach bolo číslo „1“ označené dierou a číslo „0“ chýbajúcou dierou. Úseky dierovanej pásky, kde neboli zaznamenané informácie, neobsahovali diery, to znamená, že obsahovali nulové znaky; takéto stránky boli umiestnené na začiatku a na konci pásky. Nulový znak sa stále používa v mnohých programovacích jazykoch ako znak konca riadku a označuje sa „\\ 0“. (Pojem „reťazec“ sa vzťahuje na postupnosť znakov.) V niektorých operačných systémoch je null posledný znak ľubovoľného textového súboru.
Správy prenášané cez komunikačný kanál boli rozdelené do dvoch častí:
- "Hlavička";
- "Text".
„Záhlavie“ obsahovalo adresy odosielateľa a príjemcu, kontrolný súčet atď., Bolo možné umiestniť pred „text“ alebo po ňom. Pojem „text“ bol súčasťou správy určenej na tlač.
- SOH, 01 - storta of hodeading, začiatok „hlavičky“.
- STX, 02 - skoláč te xt, začiatok „textu“. Symbol sa použil ako príkaz na zapnutie tlačiarne typu teletyp. Text na tlač bol umiestnený medzi znakmi STX a ETX.
- ETX, 03 - end z te xt, koniec „textu“. Tento symbol sa použil na vypnutie tlačového zariadenia typu teletyp. V súčasnosti sa kód 03 používa na odoslanie signálu SIGINT do procesu. signal interrupt) a dá sa odoslať stlačením kombinácie klávesov Ctrl + C. Po prijatí takéhoto signálu by mal proces dokončiť prácu.
- EOT, 04 - end of tvýplata, koniec prevodu. Symbol používajú terminálové emulátory s významom „koniec súboru“ (EOF, angl. end of file) a dá sa odoslať stlačením kombinácie klávesov Ctrl + D. Po prijatí takéhoto znaku emulátor terminálu určí proces, ktorý v súčasnosti pracuje s terminálom, a nastaví príznak „end of file“ (EOF) pre štandardný vstupný tok (stdin, eng. standar d vdať prúd) tohto procesu. Výsledkom je, že proces prestane čítať stdin a začne spracúvať načítané údaje.
- ENQ, 05 - eNQuire. "Žiadam o potvrdenie."
- ACK, 06 - acknowledgement. "Potvrdzujem." Symbol NAK znamená opak - „Nepotvrdzujem.“
- BEL, 07 - bell, volám, pípne. Symbol sa často označuje ako „\\ a“ a používa sa na spustenie poplachu. V modernom počítači reprodukuje zvuk zabudovaný reproduktor. Zvuky môžu prehrávať napríklad nasledujúce príkazy: echo -e “\\ a” alebo echo -e “\\ 007 ″ (bash); echo ^ G (cmd.exe; pre vstup do ^ G stlačte Ctrl + G), printf ("\\ a"); (kód v programovacom jazyku C).
- BS, 08 - back stempo, návrat jedného znaku. Kláves ← Backspace vymaže predchádzajúci znak.
- TAB, 09 - tab, vodorovná záložka. Je označený ako "\\ t". HT sa niekedy nazýva angličtina. hodoRIZONTÁLNE tabulation.
- LF, 0A - line feed, line feed. Príkaz na spustenie tlačového vozíka o jeden riadok nadol. Znak sa používa na označenie konca riadku textového súboru v systéme UNIX. Znaková sekvencia CR LF označuje koniec riadku textového súboru v systéme Windows. Symbol v mnohých programovacích jazykoch je označený ako "\\ n". Stlačením klávesu ↵ Enter pri výstupe textu sa dostanete na riadok.
- VT, 0B - protiertical tab, vertikálna zarážka.
- FF, 0C - foRM feED, spustenie stránky, nová stránka. Príkaz pre tlačiareň: pokračujte v tlači od začiatku nasledujúceho hárku.
- CR, 0D - carriaga return, návrat vozíka. Príkaz pre tlačiareň: pokračujte v tlači od začiatku aktuálneho riadku (nie od nového riadku). V mnohých programovacích jazykoch je symbol CR označený ako "\\ r". V systéme Mac OS označuje znak CR koniec riadku v textovom súbore. Z klávesnice je možné zadať symbol CR stlačením kombinácie klávesov Ctrl + M.
- SO, 0E - shift out, prepnite na inú pásku. Ďalšia páska bola zvyčajne natretá na červeno. Následne sa tento symbol použil na prepnutie na národné kódovanie.
- SI, 0F - shift jan. Príkaz na vykonanie opaku akcie SO: prepnite na zdrojovú pásku alebo prepnite na zdrojové kódovanie.
- PODĽA, 10 - data latrament estúpanie, uvoľnenie dátového kanála. Akékoľvek znaky nasledujúce po DLE by sa mali interpretovať ako údaje, a nie ako kontrolné znaky.
- DC1, 11 - devica controly 1 , 1. znak ovládania zariadenia. Príkaz: Zapnite čítačku pásky.
- DC2, 12 - devica controly 2 , 2. znak pre ovládanie zariadenia. Príkaz: zapnite úder.
- DC3, 13 - devica controly 3 , 3. znak ovládania zariadenia. Príkaz: vypnite čítačku pásky.
- DC4, 14 - devica controly 4 , 4. znak ovládania zariadenia. Príkaz: vypnite dierovač.
- NAK, 15 - negative c kteraz, nepotvrdzujte. Návrat na stránku ACK.
- SYN, 16 - synchronization. Tento symbol sa preniesol, keď bolo potrebné preniesť niečo na synchronizáciu.
- ETB, 17 - end z text bzámok, koniec textového bloku. Z technických dôvodov bol niekedy text rozdelený do blokov.
- CAN, 18 - plechovkacel, zrušenie (z toho, čo bolo predtým odoslané).
- EM, 19 - end z medium, koniec nosiča (dôjdu papierové pásky, papier atď.)
- SUB, 1A - náhradníknáhradník. Symbol sa nahrádza symbolom, ktorého hodnota sa počas prenosu stratila alebo poškodila. Alebo znak sa umiestni pred znak, ktorého interpretáciu musíte prepnúť na ďalšiu skupinu znakov. Alebo znak je umiestnený pred znak, ktorý je potrebné vytlačiť inou farbou. V súčasnosti sa znak vkladá stlačením kombinácie klávesov Ctrl + Z a používa sa na označenie konca súboru v systémoch DOS a Windows.
- ESC, 1B - esclidoop. Znak nasledujúci po znaku ESC má iný význam ako ten, ktorý je definovaný v ASCII. Únikové sekvencie sa zvyčajne riadia znakom ESC. V systéme DOS sú implementované ovládačom ANSI.SYS
Podporovalo sa oddelenie údajov do 4 úrovní:
- správa by sa mohla skladať zo súborov;
- súbory môžu pozostávať zo skupín;
- skupiny by mohli pozostávať zo záznamov;
- záznamy by mohli pozostávať z jednotiek.
- FS, 1C - file separator, oddeľovač súborov.
- GS, 1D - gmrľa soddeľovač, oddeľovač skupín.
- RS, 1E - record separator, separátor záznamov.
- US, 1F - uhníd soddeľovač, oddeľovač jednotiek.
- DEL, 7F - delete, vymaž posledný znak. So symbolom DEL, ktorý pozostáva zo všetkých jednotiek v binárnom kóde, môže byť akýkoľvek znak „zatĺkaný“. Zariadenia a programy ignorovali DEL rovnako ako NUL. Kód tohto symbolu pochádza od prvých textových procesorov s pamäťou na dierovanej páske: v nich bol symbol vymazaný „upchatím“ jeho kódu dierami (označujúcimi logické jednotky).
Tabuľka Štrukturálne vlastnosti
- Znakové kódy číslic "0" - "9" v systéme binárnych čísel začínajú číslom 00112 a končia binárnymi číslami. Napríklad 01012 je číslo 5 a 0011 01012 je znak "5". S týmto vedomím môžete previesť binárne desatinné čísla (BCD) na reťazec ASCII jednoduchým pridaním 00112 do každej binárnej desatinnej tabuľky naľavo.
- Písmená „A“ - „Z“ veľkých a malých písmen sa v ich znázornení líšia iba jedným bitom, čo zjednodušuje prevod registra a kontrolu, či kód patrí do rozsahu hodnôt. Písmená sú reprezentované ich sériovými číslami v abecede, napísanými piatimi číslicami v binárnom systéme, za ktorými nasleduje 0102 (pre veľké písmená) alebo 0112 (pre malé písmená).
Počítačová prezentácia ASCII
Na prevažnej väčšine moderných počítačov je minimálna adresovateľná jednotka pamäte 8-bitový bajt. Preto používa skôr 8-bitové ako 7-bitové znaky. Zvyčajne sa znak ASCII rozšíri na 8 bitov, pričom jednoducho pridá jeden nulový bit ako vysoký bit.
Kódy ASCII sa používajú pri programovaní ako medziskladové kódy stlačených klávesov (na rozdiel od skenovacích kódov IBM PC a iných interných kódov).
V prípade rozloženia klávesnice QWERTY vyzerá tabuľka kódov tak, ako to zobrazuje nasledujúca tabuľka:
uniknúť F1 F2 F3 F4 F5 F6 F7 F8 F9 F10 F11 F12 Obrazovka tlače Posunutie zámku prestávka `g 1 2 3 4 5 6 7 8 9 0 - =+ Zadný priestor insert domov Page up Num lock / add. * pridať. + pridať. pútko Q W E R T Y U ja O P [ ] delete koniec Page down 7 pridať. 8 pridať. 9 pridať. Caps lock S D F G H J K L ; w , e vstúpiť 4 pridať. 5 pridať. 6 pridať. Zadajte add. smena Z X C V B N M ,< .> / smena \| hore 1 pridať. 2 pridať. 3 pridať. ctrl výhra alt Medzerník alt výhra zoznam ctrl Left nadol doprava Ins / 0 Del /. 46/110
Na tomto rozložení klávesnice nie sú žiadne ruské písmená a vyskytujú sa aj určité nepresnosti, ale odzrkadľujú sa hlavné funkcie.
Vyzývam všetkých, aby sa vyjadrili
KÓDOVANIE TEXTOVÝCH INFORMÁCIÍ. KÓDOVANIE ASCII. ZÁKLADNÉ POUŽITÉ CYRILLSKÉ KÓDY
Akýkoľvek text je postupnosť znakov určitej abecedy. Ak je každý znak použitej abecedy kódovaný číslom, text sa zobrazí ako postupnosť čísiel. Pri spracovaní textu pomocou počítača sa používa binárna reprezentácia čísel.
Pre správnu interpretáciu kódovaného textu musíte vedieť, kde končí binárny kód jedného znaku pôvodnej abecedy a začína binárny kód iného znaku. Každý znak môžete kódovať v postupnosti 8 bitov - jeden bajt.
Do ôsmich číslic môžete napísať 28 \u003d 256 rôznych binárnych celých čísel - od 000000002 do 111111112. To je dostatočné na to, aby každé veľké a malé písmeno anglickej a ruskej abecedy, všetky arabské číslice, interpunkčné znamienka, niektoré ďalšie potrebné znaky, ako aj servisné kódy na prenos údajov zodpovedali jedinečnému (neopakujúcemu sa) osembitovému označeniu.
Pre uľahčenie digitálneho kódovania a následného dekódovania sa zostavujú tabuľky kódov. Rôzne typy počítačov s rôznymi operačnými systémami používajú rôzne tabuľky kódov. Jedným zo štandardov na kódovanie znakov počítačovej klávesnice s 8-bitovými číslami je tabuľka kódov ASCII (American Standard Code for Information Interchange). Jeho prvá polovica (kódy 0-127), ktorá obsahuje interpunkčné znamienka, arabské číslice a znaky anglickej abecedy, sa na celom svete všeobecne prijíma dohodou. Kódy 128 - 255 tabuľky ASCII (rozšírené kódy ASCII) sa používajú najmä pre národné abecedy.
Tabuľku kódov môžete prehrať zadaním požadovaného čísla od 0 do 255 na malej numerickej klávesnici a súčasným podržaním klávesu Alt. Obrázok 1 zobrazuje takto získanú tabuľku kódov.
♫ ☼ ◄ ↕ | ||||||||||
← ∟ ↔ |
||||||||||
M N O P R S T U V | ||||||||||
C HW D F Y S E |
||||||||||
Obrázok 1 - Tabuľka kódov
Kód je vytvorený z čísla riadku a čísla stĺpca. Napríklad kód 50 zodpovedá číslu 2, kódu 134 - písmeno J. Kódy od 0 do 32 - služba.
Prítomnosť mnohých variantov kódových tabuliek zameraných na používanie abecedy rôznych národných jazykov je sama o sebe veľkou nepríjemnosťou. Na usporiadanie tabuliek začali prideľovať špeciálne názvy a čísla (napríklad
KOI-8), to však nevyriešilo problém vytvorenia jednotného systému kódov kombinujúceho rôzne národné abecedy.
Odstránenie týchto nepríjemností a obmedzení bolo možné vďaka novému medzinárodnému štandardu Unicode, ktorý je podporovaný najnovšími verziami operačného systému Microsoft Windows. V súčasnosti tento štandard kódovania znakov prideľuje na jeden znak dva bajty. Toto kódovanie umožňuje v binárnej abecede reprezentovať 216 \u003d 65 536 rôznych znakov. Kódy prvých 128 znakov sú rovnaké ako ASCII.
INFORMAČNÝ OBJEM SPRÁV
ÚLOHY S ROZHODNUTIAMI
Úloha. Predpokladajme, že každý znak je kódovaný 1 bajtom (KOI-8). Odhadnite objem informácií v správe
Aj n n a w c A a n il x n s e d v o a HN s x h a f l.
Správa obsahuje 39 znakov, preto na jej kódovanie vyžaduje 1 bajt / znak * 39 znakov \u003d 39 bajtov,
alebo 8 bitov / bajtov * 39 bajtov \u003d 312 bitov.
1. V správe z predchádzajúceho príkladu bolo slovo „binárne“ nahradené slovom „desatinné miesto“. Ako sa zmenil objem informácií správy v bitoch a bajtoch?
Odpoveď: informačný objem správy sa zvýšil o 2 bajty, o 16 bitov.
2. Predpokladajme, že každý znak je kódovaný 1 bajtom (KOI-8). Odhadnite objem informácií v správe
Dokážem s vami komunikovať a komunikovať.
Odpoveď: informačný objem správy je 48 bajtov.
3. Predpokladajme, že každý znak je kódovaný v 2 bajtoch (Unicode). Odhadnite objem informácií v správe
Som si vedomý skutočnosti, že KO I - 8.
Odpoveď: informačný objem správy je 68 bajtov.
4. Predpokladajme, že každý znak je kódovaný v 2 bajtoch (Unicode). Odhadnite objem informácií v správe
ALGORITMMOZNO S P R S
Odpoveď: objem informácií v správe je 92 bajtov.
5. Informačná správa v ruštine, pôvodne zaznamenaná v 16-bitovom kóde Unicode, bola transkódovaná do 8-bitového kódovania KOI-8. Informačná správa sa zároveň znížila o 480 bitov. Aká je dĺžka správy v znakoch?
Odpoveď: Správa má 60 znakov.
6. Informačná správa v ruštine, pôvodne zaznamenaná v 8-bitovom kóde KOI-8, bola transkódovaná do 16-bitového kódovania Unicode. Objem informačnej správy sa zvýšil o 568 bitov. Aká je dĺžka správy v znakoch?
Odpoveď: Dĺžka správy je 71 znakov.
7. Informačná správa v ruštine, pôvodne zaznamenaná v 8-bitovom kóde KOI-8, bola transkódovaná do 16-bitového kódovania Unicode. Ako sa zmenil objem informačnej správy?
Odpoveď: objem informačnej správy sa zdvojnásobil.
8. Koľko znakov obsahuje správa v Unicode za 200 bitov?
Odpoveď: správa obsahuje 25 znakov.
9. Koľko znakov obsahuje správa, ktorej objem informácií v kódovaní KOI-8 je 240 bitov?
Odpoveď: správa obsahuje 30 znakov.
INFORMAČNÉ KÓDOVANIE A DEKOROVANIE
ÚLOHY S ROZHODNUTIAMI
1. Na kódovanie písmen A, B, C, D pomocou štvormiestneho čísla binárne kódy od 1 000 do 1011, v danom poradí. Pre postupnosť znakov B, D, B, A napíšte binárny kód a výsledok kódovania uveďte v osmičkovom kóde.
Kódy znakov sú uvedené v tabuľke 1: tabuľka 1
Zodpovedajúci binárny kód obsahuje 16 bitov: 1001101110101000, je vhodnejšie zapísať toto číslo na prevod na osmičkový kód s rozdelením na triády: 1 001 101 110 101 000. Je zrejmé, že príslušné osmičkové číslo má nasledujúcu formu: 115650.
Na prevod čísla predstavovaného v binárnom kóde na hexadecimálny je vhodné rozdeliť binárny záznam na tetrady (skupiny 4 číslic), počnúc sprava.
2. Pre 5 písmen ruskej abecedy sú stanovené ich binárne kódy, ktoré môžu obsahovať 2 alebo 3 číslice. Kódy sú zaznamenané v tabuľke 3:
1) 110100000100110111
2) 101010000010010011
3) 110100001001100111
4) 110110000100110010.
Každú zo štyroch správ postupne dekódujeme a rozdelíme do skupín bitov podľa tabuľky 3:
1) 11 01 000 001 001 10 111 Posledná skupina číslic nemôže zodpovedať znaku
podľa tabuľky 3. Správa obsahuje chybu.
2) 10 10 10 000 01 001 001 1 Správa obsahuje chybu.
3) 11 01 000 01 001 10 01 11
Správa môže byť dekódovaná. 4) 11 01 10 000 10 01 10 010 Správa obsahuje chybu.
Odpoveď: 3) 110100001001100111
ÚLOHY NEZÁVISLÉHO RIEŠENIA
1. Na kódovanie písmen M, N, P, Q sa používajú štvorciferné binárne kódy od 1 000 do 1011. Pre postupnosť znakov N, Q, P, M napíšte binárny kód a výsledok kódovania uveďte v osmičkovom kóde.
Odpoveď: binárny kód 1 001 101 110 101 000, osmičkový kód 115650.
2. Na kódovanie písmen A, B, C, D sa používajú štvormiestne binárne kódy od 1 000 do 1011. Pre postupnosť znakov B, D, C, A napíšte binárny kód a výsledok kódovania uveďte v hexadecimálnom kóde.
Odpoveď: binárny kód 1001 1011 1010 1000, hexadecimálny kód 9BA9.
3. Na kódovanie písmen M, N, O, P použite trojciferné binárne kódy od 000 do 111. Pre postupnosť znakov O, N, M, P napíšte binárny kód a výsledok kódovania uveďte v osmičkovom kóde.
Odpoveď: binárny kód 110 101 100 111, osmičkový kód 6547.
4. Na kódovanie písmen M, N, O, P sa používajú trojciferné binárne kódy od 100 do 111. Pre postupnosť znakov O, N, M, P napíšte binárny kód a výsledok kódovania uveďte v hexadecimálnom kóde.
Odpoveď: binárny kód 1101 0110 0111, hexadecimálny kód B67.
∙ druhá číslica nemôže byť 3.
6. Na zostavenie štvorciferných čísiel sa používajú čísla 1, 2, 3, 4, 5 a vyžadujú sa tieto pravidlá:
∙ na prvom mieste môže byť jedno z čísiel 1, 3, 4;
∙ v číselnom zázname sa striedajú párne a nepárne čísla;
∙ tretia číslica nemôže byť 4.
Zaznamenajte všetky možné čísla zostavené podľa týchto pravidiel.
7. Na zostavenie štvorciferných čísel sa používajú čísla 1, 2, 3, 4, 5 a vyžadujú sa nasledujúce pravidlá:
∙ na prvom mieste môže byť jedno z čísiel 2, 4, 5;
∙ v číselnom zázname sa striedajú párne a nepárne čísla;
∙ druhá a posledná číslica nemôžu byť rovnaké. Zaznamenajte všetky možné čísla zostavené podľa týchto pravidiel.
8. Pre 5 písmen ruskej abecedy sú stanovené ich binárne kódy, ktoré môžu obsahovať 2 alebo 3 číslice. Kódy sú uvedené v tabuľke:
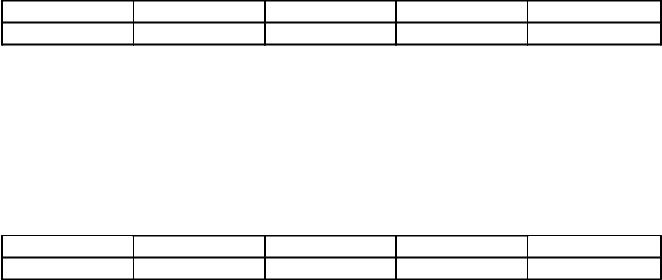
Zo štyroch správ v tomto kódovaní iba jedna prešla bez chýb, iba ju možno správne dekódovať. Nájdite túto správu zo zoznamu:
1) 110100000100110011
2) 111010000010010011
3) 110100001001100111
4) 110110000100110010. Odpoveď: 110100001001100111
9. Pre 5 písmen ruskej abecedy sú stanovené ich binárne kódy, ktoré môžu obsahovať 2 alebo 3 číslice. Kódy sú uvedené v tabuľke:
Zakódujte postupnosť FIGHT, urobte takú chybu v kóde, ktorá vám nedovolí správne dekódovať správu.
VÝCVIKOVÁ SKÚŠKA
2 Predpokladajme, že každý znak je kódovaný 1 1) 384 bitových bajtov (Koi-8). Ohodnoťte informácie 2) 192 bitov
24-znakový objem slov | ||||||
kódovanie. | ||||||
3 vyrobené | prekódovanie | |||||
informačná správa | ||||||
jazyk pôvodne zaznamenaný v 8- | ||||||
bitový kód KOI-8 v 16-bitovom kódovaní | ||||||
Unicode. Objem informácií | ||||||
správy sa zvýšili o 336 bitov. Čo je to? | ||||||
dĺžka správy v znakoch? | ||||||
4 Koľko znakov obsahuje | ||||||
správa, | informácie | |||||
ktorý v kódujúcom KOI-8 je 240 | ||||||
5 Koľko znakov obsahuje | ||||||
správa, | informácie | |||||
ktorého kódovanie Unicode je | ||||||
6 Pre kódovanie písmen A, B, C, D | ||||||
používať trojciferné binárne kódy | ||||||
doprava | ||||||

