29.06.2019
कौन सा ऑडियो प्रारूप सबसे अच्छा है। "दोषरहित" या दोषरहित संगीत संपीड़न के बारे में क्या है
शुभ दिन।
आज मैं दोषरहित डेटा संपीड़न के विषय पर स्पर्श करना चाहता हूं। इस तथ्य के बावजूद कि हब पर पहले से ही कुछ एल्गोरिदम के लिए समर्पित लेख थे, मैं इस बारे में थोड़ा और विस्तार से बात करना चाहता था।
मैं गणितीय विवरण और विवरण दोनों को सामान्य तरीके से देने की कोशिश करूंगा, ताकि हर कोई अपने लिए कुछ दिलचस्प पा सके।
इस लेख में मैं संपीड़न के मूल क्षणों और मुख्य प्रकार के एल्गोरिदम पर स्पर्श करूंगा।
संपीड़न। क्या आजकल इसकी जरूरत है?
हां, बिल्कुल। बेशक, हम सभी समझते हैं कि अब हम बड़ी मात्रा में स्टोरेज मीडिया और हाई-स्पीड डेटा ट्रांसमिशन चैनल दोनों का उपयोग कर सकते हैं। हालांकि, एक ही समय में, संचरित जानकारी के वॉल्यूम बढ़ रहे हैं। अगर कुछ साल पहले हम 700-मेगाबाइट फिल्में देखते थे जो एक डिस्क पर फिट होती हैं, तो आज एचडी-गुणवत्ता वाली फिल्में दसियों गीगाबाइट्स पर कब्जा कर सकती हैं।
बेशक, सब कुछ और सब कुछ को संपीड़ित करने के लाभ इतने अधिक नहीं हैं। लेकिन अभी भी ऐसी परिस्थितियां हैं जिनमें संपीड़न अत्यंत उपयोगी है, यदि आवश्यक नहीं है।
- ईमेल दस्तावेज़ (विशेषकर मोबाइल उपकरणों का उपयोग करने वाले दस्तावेज़ों की बड़ी मात्रा)
- वेबसाइटों पर दस्तावेज़ प्रकाशित करते समय, ट्रैफ़िक को बचाने की आवश्यकता है
- स्टोरेज को बदलते या जोड़ते समय डिस्क स्थान सहेजें। उदाहरण के लिए, यह उन मामलों में होता है जहां पूंजी व्यय के लिए बजट प्राप्त करना आसान नहीं होता है, और पर्याप्त डिस्क स्थान नहीं होता है।
बेशक, आप कई अलग-अलग स्थितियों के साथ आ सकते हैं जिनमें संपीड़न उपयोगी होगा, लेकिन ये कुछ उदाहरण हमारे लिए पर्याप्त हैं।
सभी संपीड़न विधियों को दो बड़े समूहों में विभाजित किया जा सकता है: हानिपूर्ण संपीड़न और दोषरहित संपीड़न। दोषरहित संपीड़न का उपयोग उन मामलों में किया जाता है जहां जानकारी को बिट्स के लिए सटीक रूप से बहाल करने की आवश्यकता होती है। संपीड़ित करते समय यह दृष्टिकोण केवल एक ही संभव है, उदाहरण के लिए, पाठ डेटा।
कुछ मामलों में, हालांकि, सटीक जानकारी पुनर्प्राप्ति की आवश्यकता नहीं होती है और इसे एल्गोरिदम का उपयोग करने की अनुमति होती है जो हानिरहित संपीड़न को लागू करते हैं, जो दोषरहित संपीड़न के विपरीत, आमतौर पर लागू करना आसान होता है और उच्च स्तर की संग्रह प्रदान करता है।
तो, चलो दोषरहित संपीड़न एल्गोरिदम पर चलते हैं।
सार्वभौमिक दोषरहित संपीड़न विधियाँ
सामान्य मामले में, तीन बुनियादी विकल्प हैं जिन पर संपीड़न एल्गोरिदम का निर्माण किया जाता है।पहला समूह तरीके - धारा रूपांतरण। यह पहले से ही संसाधित के माध्यम से नए आने वाले असम्पीडित डेटा का विवरण देता है। इस मामले में, किसी भी संभाव्यता की गणना नहीं की जाती है, चरित्र एन्कोडिंग केवल उस डेटा के आधार पर किया जाता है जिसे पहले से ही संसाधित किया गया है, जैसे कि एलजेड विधियों (अब्राहम लेम्पेल और जैकब जिवा के नाम पर)। इस मामले में, एनकोडर को पहले से ज्ञात एक सबस्ट्रिंग की दूसरी और आगे की घटनाओं को इसकी पहली घटना के संदर्भों से बदल दिया जाता है।
दूसरा समूह विधियाँ सांख्यिकीय संपीड़न विधियाँ हैं। बदले में, इन विधियों को अनुकूली (या प्रवाह), और ब्लॉक में विभाजित किया गया है।
पहले (अनुकूली) संस्करण में, नए डेटा के लिए संभावनाओं की गणना एन्कोडिंग के दौरान पहले से संसाधित किए गए डेटा पर आधारित है। इन विधियों में हफ़मैन और शैनन-फ़ानो एल्गोरिदम के अनुकूली संस्करण शामिल हैं।
दूसरे (ब्लॉक) मामले में, प्रत्येक डेटा ब्लॉक के आंकड़ों को अलग-अलग गणना की जाती है, और सबसे संकुचित ब्लॉक में जोड़ा जाता है। इनमें हफ़मैन, शैनन-फ़ानो, और अंकगणित कोडिंग विधियों के स्थिर संस्करण शामिल हैं।
तीसरा समूह विधियाँ तथाकथित ब्लॉक रूपांतरण विधियाँ हैं। आने वाले डेटा को ब्लॉक में विभाजित किया जाता है, जो तब संपूर्ण रूप में बदल जाते हैं। हालांकि, कुछ विधियां, विशेष रूप से ब्लॉकों के क्रमांकन के आधार पर, डेटा की मात्रा में महत्वपूर्ण (या कोई भी) कमी नहीं ला सकती है। हालांकि, इस तरह के प्रसंस्करण के बाद, डेटा संरचना में काफी सुधार होता है, और अन्य एल्गोरिदम द्वारा बाद में संपीड़न अधिक सफल और तेज होता है।
सामान्य सिद्धांत जिस पर डेटा संपीड़न आधारित है
सभी डेटा संपीड़न विधियाँ एक सरल तार्किक सिद्धांत पर आधारित हैं। यदि हम कल्पना करते हैं कि सबसे अधिक बार होने वाले तत्व कम कोड के साथ एन्कोड किए जाते हैं, और कम बार होने वाले लोग लंबे समय तक एन्कोडेड होते हैं, तो सभी डेटा को स्टोर करने के लिए, कम जगह की आवश्यकता होती है अगर सभी तत्वों को समान लंबाई के कोड द्वारा दर्शाया गया था।
तत्व घटनाओं की आवृत्ति और इष्टतम कोड लंबाई के बीच सटीक संबंध तथाकथित शैनन के स्रोत कोडिंग प्रमेय में वर्णित है, जो दोषरहित अधिकतम संपीड़न सीमा और शैनन की एन्ट्रापी को परिभाषित करता है।
थोड़ा सा गणित
यदि किसी तत्व के i की उत्पत्ति की संभावना p (s i) के बराबर है, तो इस तत्व का प्रतिनिधित्व करने के लिए सबसे अधिक फायदेमंद होगा - 2 p (s i) बिट्स लॉग करें। यदि एन्कोडिंग के दौरान यह सुनिश्चित करना संभव है कि सभी तत्वों की लंबाई 2 पी (एस आई) बिट्स लॉग करने के लिए कम हो जाती है, तो पूरे एन्कोडेड अनुक्रम की लंबाई सभी संभव एन्कोडिंग विधियों के लिए न्यूनतम होगी। इसके अलावा, यदि सभी तत्वों F \u003d (p (s i)) की संभाव्यता वितरण अपरिवर्तित है, और तत्वों की संभाव्यता परस्पर स्वतंत्र हैं, तो कोड की औसत लंबाई की गणना की जा सकती हैइस मान को प्रायिकता वितरण F की एन्ट्रापी या किसी निश्चित समय पर स्रोत की एन्ट्रॉपी कहा जाता है।
हालांकि, आमतौर पर एक तत्व की उपस्थिति की संभावना स्वतंत्र नहीं हो सकती है, इसके विपरीत, यह कुछ कारकों पर निर्भर करता है। इस मामले में, प्रत्येक नए एन्कोडेड एलिमेंट के लिए, प्रायिकता डिस्ट्रीब्यूशन F कुछ वैल्यू F k लेगा, यानी प्रत्येक एलिमेंट F \u003d F k और H \u003d H k के लिए।
दूसरे शब्दों में, हम कह सकते हैं कि स्रोत राज्य k में है, जो सभी तत्वों के लिए निश्चित संभावनाओं p k (s i) से मेल खाता है।
इसलिए, इस सुधार को देखते हुए, हम कोड की औसत लंबाई को व्यक्त कर सकते हैं
जहां पी के राज्य में स्रोत को खोजने की संभावना है।
इसलिए, इस स्तर पर, हम जानते हैं कि संपीड़न छोटे कोड के साथ अक्सर होने वाले तत्वों की जगह पर आधारित है, और इसके विपरीत, और हम यह भी जानते हैं कि कोड की औसत लंबाई कैसे निर्धारित करें। लेकिन कोड, कोडिंग क्या है और यह कैसे होता है?
मेमोरीलेस एनकोडिंग
मेमोरी के बिना कोड सबसे सरल कोड हैं जिनके आधार पर डेटा को संपीड़ित किया जा सकता है। मेमोरीलेस कोड में, एन्कोडेड डेटा वेक्टर में प्रत्येक वर्ण को बाइनरी दृश्यों या शब्दों के एक उपसर्ग सेट से कोडवर्ड के साथ बदल दिया जाता है।मेरी राय में, सबसे स्पष्ट परिभाषा नहीं। इस विषय पर अधिक विस्तार से विचार करें।
कुछ अक्षर बताए जाएं ![]() कुछ (परिमित) अक्षरों से मिलकर। हम इस वर्णमाला के वर्णों के प्रत्येक परिमित अनुक्रम को कहते हैं (A \u003d a 1, a 2, ..., a) एक शब्द में, और संख्या n इस शब्द की लंबाई है।
कुछ (परिमित) अक्षरों से मिलकर। हम इस वर्णमाला के वर्णों के प्रत्येक परिमित अनुक्रम को कहते हैं (A \u003d a 1, a 2, ..., a) एक शब्द में, और संख्या n इस शब्द की लंबाई है।
एक अन्य वर्णमाला भी बताइए ![]() । इसी तरह, इस वर्णमाला के शब्द को B के रूप में निरूपित करें।
। इसी तरह, इस वर्णमाला के शब्द को B के रूप में निरूपित करें।
हम वर्णमाला के सभी गैर-रिक्त शब्दों के सेट के लिए दो और संकेतन प्रस्तुत करते हैं। आज्ञा दें - पहले वर्णमाला में गैर-खाली शब्दों की संख्या और - दूसरे में।
आइए एक मैपिंग F भी दें जो कि प्रत्येक शब्द A के साथ पहले वर्णमाला के दूसरे शब्द B \u003d F (A) से जुड़ा हो। तब B शब्द कहा जाएगा कोड शब्द A, और मूल शब्द से उसके कोड में परिवर्तन को कहा जाएगा कोडिंग.
चूँकि शब्द में एक अक्षर भी हो सकता है, इसलिए हम पहले वर्णमाला के अक्षरों के पत्राचार और दूसरे से संबंधित शब्दों की पहचान कर सकते हैं:
एक १<-> बी १
एक २<-> बी २
…
a n<-> बी एन
इस मैच को कहा जाता है योजना, और निरूपित करें ∑।
इस स्थिति में, बी 1, बी 2, ..., बी एन शब्दों को कहा जाता है प्राथमिक कोड, और उनकी मदद से कोडिंग का प्रकार - वर्णमाला कोडिंग। बेशक, हम में से अधिकांश इस तरह के कोडिंग के साथ आए हैं, भले ही हम उन सभी को नहीं जानते हैं जो मैंने ऊपर वर्णित किया था।
इसलिए, हमने अवधारणाओं पर फैसला किया वर्णमाला, शब्द, कोड, और कोडिंग। अब हम अवधारणा पेश करते हैं उपसर्ग.
B शब्द को B \u003d B "B" का रूप दें। तब B को शुरुआत कहा जाता है, या उपसर्ग शब्द बी, और बी "" - इसका अंत। यह एक काफी सरल परिभाषा है, लेकिन यह ध्यान दिया जाना चाहिए कि किसी भी शब्द बी के लिए, एक निश्चित शब्द ʌ ("स्थान") और बी शब्द ही दोनों शुरुआत और अंत माना जा सकता है।
तो, हम मेमोरी के बिना कोड की परिभाषा को समझने के करीब आते हैं। अंतिम परिभाषा जिसे हमें समझने की जरूरत है वह उपसर्ग सेट है। एक योजना for में एक उपसर्ग की संपत्ति होती है यदि, किसी भी 1≤i, jr, i, j के लिए, B शब्द I, B शब्द का उपसर्ग नहीं है।
सीधे शब्दों में कहें, एक उपसर्ग सेट एक परिमित सेट है जिसमें कोई तत्व किसी अन्य तत्व का उपसर्ग (या शुरुआत) नहीं है। इस तरह के एक सेट का एक सरल उदाहरण है, उदाहरण के लिए, नियमित वर्णमाला।
इसलिए, हमने आधारभूत परिभाषाएं निकालीं। तो मेमोरीलेस कोडिंग कैसे होती है?
यह तीन चरणों में होता है।
- मूल संदेश के वर्णों का एक वर्णमाला Ψ संकलित किया जाता है, और वर्णमाला के पात्रों को संदेश में उनके होने की संभावना के अवरोही क्रम में क्रमबद्ध किया जाता है।
- प्रत्येक प्रतीक i, वर्णमाला से Ψ उपसर्ग सेट Ω से एक निश्चित शब्द B i से जुड़ा हुआ है।
- प्रत्येक वर्ण को कूटबद्ध किया जाता है, जिसके बाद कोडों को एक एकल डेटा स्ट्रीम में संयोजित किया जाता है, जो संपीड़न का परिणाम होगा।
इस विधि का वर्णन करने वाले विहित एल्गोरिदम में से एक हफ़मैन एल्गोरिथम है।
हफ़मैन एल्गोरिदम
हफमैन एल्गोरिथ्म इनपुट डेटा ब्लॉक में एक ही बाइट्स की घटना की आवृत्ति का उपयोग करता है, और छोटी लंबाई के बिट्स की एक श्रृंखला के लगातार ब्लॉक से मेल खाता है, और इसके विपरीत। यह कोड न्यूनतम बेमानी है। मामले पर विचार करें, जब इनपुट स्ट्रीम की परवाह किए बिना, आउटपुट स्ट्रीम की वर्णमाला में केवल 2 वर्ण होते हैं - शून्य और एक।सबसे पहले, हफ़मैन एल्गोरिथ्म के साथ कोडिंग करते समय, हमें सर्किट cod के निर्माण की आवश्यकता होती है। यह निम्नानुसार किया जाता है:
- इनपुट वर्णमाला के सभी अक्षरों को संभाव्यता के अवरोही क्रम में क्रमबद्ध किया जाता है। आउटपुट स्ट्रीम की वर्णमाला के सभी शब्द (जो हम एनकोड करेंगे) को शुरू में खाली माना जाता है (मुझे याद है कि आउटपुट स्ट्रीम की वर्णमाला में केवल वर्ण (0,1) होते हैं)।
- दो वर्णों में एक j-1 और एक इनपुट स्ट्रीम, जिसमें घटना होने की संभावना सबसे कम होती है, को संभाव्यता के साथ एक "छद्म-प्रतीक" में जोड़ा जाता है। पी इसके घटक पात्रों की संभावनाओं के योग के बराबर। फिर हम B शब्द के आरंभ में B j-1, और 1 से B शब्द की शुरुआत करते हैं, जो बाद में क्रमशः a-1 और j अक्षर का कोड होगा।
- हम इन पात्रों को मूल संदेश की वर्णमाला से हटा देते हैं, लेकिन इस वर्णमाला में उत्पन्न छद्म-चिह्न को जोड़ते हैं (स्वाभाविक रूप से, इसे सही जगह पर वर्णमाला में डाला जाना चाहिए, इसकी संभावना को ध्यान में रखते हुए)।
बेहतर चित्रण के लिए, एक छोटे से उदाहरण पर विचार करें।
मान लीजिए कि हमारे पास केवल चार वर्णों से युक्त एक वर्णमाला है - (1, 2, 3, 4)। यह भी मान लें कि इन प्रतीकों की घटना की संभावनाएं समान हैं, क्रमशः, पी 1 \u003d 0.5; पी 2 \u003d 0.24; पी 3 \u003d 0.15; पी 4 \u003d 0.11 (सभी संभावनाओं का योग स्पष्ट रूप से एक के बराबर है)।
इसलिए, हम इस वर्णमाला के लिए योजना का निर्माण करेंगे।
- दो अक्षरों को कम से कम संभावनाओं (0.11 और 0.15) के साथ p "छद्म चरित्र" में मिलाएं।
- हम दो वर्णों को कम से कम प्रायिकता (0.24 और 0.26) के साथ p छद्म वर्ण में संयोजित करते हैं।
- हम संयुक्त वर्णों को हटाते हैं, और परिणामस्वरूप छद्म वर्ण को वर्णमाला में सम्मिलित करते हैं।
- अंत में, शेष दो पात्रों को मिलाएं और पेड़ की चोटी प्राप्त करें।
यदि आप इस प्रक्रिया का वर्णन करते हैं, तो आपको निम्न जैसा कुछ मिलेगा:
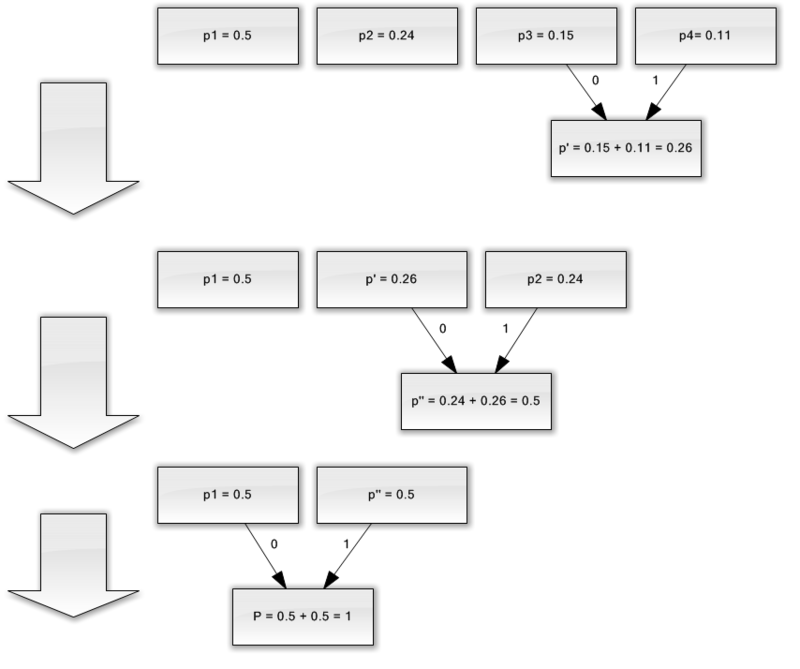
जैसा कि आप देख सकते हैं, प्रत्येक मर्ज के साथ, हम वर्णों को मर्ज किए जाने वाले वर्णों को 0 और 1 असाइन करते हैं।
इस प्रकार, जब पेड़ बनाया जाता है, तो हम आसानी से प्रत्येक वर्ण के लिए कोड प्राप्त कर सकते हैं। हमारे मामले में, कोड इस तरह दिखाई देंगे:
ए १ \u003d ०
एक 2 \u003d 11
एक 3 \u003d 100
एक 4 \u003d 101
चूंकि इनमें से कोई भी कोड किसी अन्य का उपसर्ग नहीं है (अर्थात, हमें कुख्यात उपसर्ग सेट मिला है), हम उत्पादन कोड में प्रत्येक कोड को विशिष्ट रूप से पहचान सकते हैं।
इसलिए, हमने पाया है कि सबसे अक्सर चरित्र सबसे छोटे कोड द्वारा एन्कोड किया गया है, और इसके विपरीत।
यदि हम मानते हैं कि शुरू में, प्रत्येक चरित्र को संग्रहीत करने के लिए एक बाइट का उपयोग किया गया था, तो हम गणना कर सकते हैं कि हम डेटा को कम करने में कितना सक्षम थे।
मान लीजिए कि हमारे पास इनपुट में 1000 वर्णों की एक स्ट्रिंग है, जिसमें चरित्र 1 1 बार 500 बार, एक 2 240, 3 150 और 4 110 बार हुआ।
प्रारंभ में, इस स्ट्रिंग ने 8000 बिट्स पर कब्जा कर लिया। कोडिंग के बाद, हमें withp i l i \u003d 500 * 1 + 240 * 2 + 150 * 3 + 110 * 3 \u003d 1760 बिट्स की लंबाई के साथ एक स्ट्रिंग मिलती है। इसलिए, हम प्रत्येक स्ट्रीम प्रतीक के एन्कोडिंग पर औसतन 1.76 बिट्स खर्च करते हुए, डेटा को 4.54 बार सेक करने में सक्षम थे।
आपको याद दिला दूं कि शैनन के अनुसार, कोड की औसत लंबाई है। इस समीकरण में हमारे संभाव्यता मानों को प्रतिस्थापित करते हुए, हम औसत कोड की लंबाई 1.75496602732291 के बराबर प्राप्त करते हैं, जो कि हमारे द्वारा प्राप्त किए गए परिणाम के बहुत करीब है।
फिर भी, यह ध्यान में रखा जाना चाहिए कि डेटा के अलावा, हमें एन्कोडिंग तालिका को संग्रहीत करने की आवश्यकता है, जो एन्कोडेड डेटा के अंतिम आकार को थोड़ा बढ़ा देगा। जाहिर है, अलग-अलग मामलों में एल्गोरिथ्म के विभिन्न रूपों का उपयोग किया जा सकता है - उदाहरण के लिए, पूर्वनिर्धारित संभाव्यता तालिका का उपयोग करने के लिए कभी-कभी यह अधिक कुशल होता है, और कभी-कभी इसे संकुचित डेटा के माध्यम से गतिशील रूप से संकलित करना आवश्यक होता है।
निष्कर्ष
इसलिए, इस लेख में मैंने बात करने की कोशिश की सामान्य सिद्धांत, जिसके द्वारा दोषरहित संपीड़न होता है, और इसे कैनोनिकल एल्गोरिदम में से एक माना जाता है - हफ़मैन कोडिंग।यदि लेख हाबोर-समुदाय के स्वाद के लिए है, तो मुझे अगली कड़ी लिखने में खुशी होगी, क्योंकि दोषरहित संपीड़न के बारे में कई और दिलचस्प बातें हैं; ये दोनों शास्त्रीय एल्गोरिदम और प्रारंभिक डेटा रूपांतरण हैं (उदाहरण के लिए, बरोज़-व्हीलर ट्रांसफ़ॉर्म), और, निश्चित रूप से, ध्वनि, वीडियो और छवियों को संपीड़ित करने के लिए विशिष्ट एल्गोरिदम (सबसे दिलचस्प विषय, मेरी राय में)।
साहित्य
- वैटोलिन डी।, रतुश्नायक ए।, स्मिरनोव एम। युकिन वी। डेटा संपीड़न के तरीके। डिवाइस अभिलेखागार, छवि और वीडियो संपीड़न; आईएसबीएन 5-86404-170-एक्स; 2003 वर्ष
- डी। सलोमन। डेटा, छवि और ध्वनि का संपीड़न; आईएसबीएन 5-94836-027-एक्स; 2004।
व्याख्यान संख्या 4। सूचना संपीड़न
सूचना संपीड़न सिद्धांत
डेटा संपीड़न का उद्देश्य संचार माध्यमों के माध्यम से उनके अधिक किफायती भंडारण और संचरण के लिए स्रोत द्वारा उत्पन्न डेटा का एक कॉम्पैक्ट प्रतिनिधित्व प्रदान करना है।
मान लीजिए कि हमारे पास 1 (एक) मेगाबाइट के आकार के साथ एक फ़ाइल है। हमें इससे एक छोटी फ़ाइल प्राप्त करने की आवश्यकता है। कुछ भी जटिल नहीं है - हम संग्रह शुरू करते हैं, उदाहरण के लिए, विनज़िप, और नतीजतन, हम कहते हैं, एक 600 किलोबाइट फ़ाइल। शेष 424 किलोबाइट कहां गए?
जानकारी को संप्रेषित करने का एक तरीका है। सामान्य तौर पर, कोड तीन बड़े समूहों में विभाजित होते हैं - संपीड़न कोड (प्रभावी कोड), शोर-प्रतिरोधी कोड और क्रिप्टोग्राफ़िक कोड। जानकारी को संपीड़ित करने के लिए डिज़ाइन किए गए कोड, बदले में, दोषरहित कोड और हानिपूर्ण कोड में विभाजित होते हैं। दोषरहित कोडिंग का मतलब डिकोडिंग के बाद पूरी तरह से सटीक डेटा रिकवरी है और इसका उपयोग किसी भी जानकारी को संपीड़ित करने के लिए किया जा सकता है। हानिपूर्ण कोडिंग में आमतौर पर दोषरहित कोडिंग की तुलना में बहुत अधिक संपीड़न दर होती है, लेकिन मूल से डिकोड किए गए डेटा के कुछ विचलन की अनुमति देता है।
संपीड़न के प्रकार
सूचना संपीड़न के सभी तरीकों को दो बड़े डिस्गॉइंट वर्गों में विभाजित किया जा सकता है: संपीड़न हानि सूचना और संपीड़न बिना नुकसान के जानकारी।
सूचना के नुकसान के बिना संपीड़न।
ये संपीड़न विधियाँ हमारे लिए सबसे पहले रुचि की हैं, क्योंकि इनका उपयोग तब किया जाता है, जब इनका उपयोग टेक्स्ट डॉक्यूमेंट्स और प्रोग्राम्स को ट्रांसमिट करते समय, किसी ग्राहक को पूरा काम जारी करते समय, या कंप्यूटर पर संग्रहीत जानकारी की बैकअप प्रतियाँ बनाते समय किया जाता है।
इस वर्ग के संपीड़न के तरीके जानकारी के नुकसान की अनुमति नहीं दे सकते हैं, इसलिए वे केवल इसके अतिरेक के उन्मूलन पर आधारित हैं, और जानकारी में अतिरेक लगभग हमेशा होता है (हालांकि अगर किसी ने पहले इसकी निंदा नहीं की थी)। यदि अतिरेक नहीं होता, तो संपीड़ित करने के लिए कुछ भी नहीं होता।
यहाँ एक सरल उदाहरण है। रूसी भाषा में 33 अक्षर, दस अंक और लगभग एक दर्जन से अधिक विराम चिह्न और अन्य विशेष वर्ण हैं। जो पाठ रिकॉर्ड किया गया है केवल राजधानी रूसी पत्रों में (टेलीग्राम और रेडियोग्राम की तरह) साठ अलग-अलग अर्थ पर्याप्त होते। हालांकि, प्रत्येक चरित्र आमतौर पर एक बाइट में एन्कोडेड होता है जिसमें 8 बिट होते हैं और 256 विभिन्न कोड व्यक्त कर सकते हैं। यह अतिरेक का पहला आधार है। हमारे "टेलीग्राफिक" पाठ के लिए, प्रति वर्ण छह बिट पर्याप्त होंगे।
यहाँ एक और उदाहरण है। अंतरराष्ट्रीय चरित्र एन्कोडिंग में ASCII किसी भी वर्ण (8) को एन्कोडिंग के लिए बिट्स की एक ही संख्या आवंटित की गई है, जबकि हर कोई लंबे समय से अच्छी तरह से जानता है कि सबसे आम चरित्र कम वर्णों के साथ सांकेतिक शब्दों में बदलना है। इसलिए, उदाहरण के लिए, "मोर्स कोड" में "ई" और "टी" अक्षर, जो अक्सर पाए जाते हैं, एक वर्ण के साथ एन्कोडेड होते हैं (क्रमशः, यह एक डॉट और एक डैश है)। और "यू" (- -) और "त्स" (- -) जैसे दुर्लभ अक्षरों को चार वर्णों के साथ एन्कोड किया गया है। अक्षम एन्कोडिंग अतिरेक का दूसरा कारण है। सूचना संपीड़न करने वाले कार्यक्रम अपने स्वयं के एन्कोडिंग (विभिन्न फ़ाइलों के लिए अलग-अलग) दर्ज कर सकते हैं और संपीड़ित फ़ाइल को एक निश्चित तालिका (शब्दकोश) असाइन कर सकते हैं, जिससे अनपैकिंग प्रोग्राम यह पता लगाएगा कि इस फ़ाइल में कुछ प्रतीक या उनके समूह कैसे एन्कोड किए गए हैं। सूचना के ट्रांसकोडिंग के आधार पर एल्गोरिदम को कहा जाता है हफमैन एल्गोरिदम।
डुप्लिकेट टुकड़ों की उपस्थिति अतिरेक का तीसरा कारण है। यह ग्रंथों में दुर्लभ है, लेकिन तालिकाओं और रेखांकन में कोड की पुनरावृत्ति एक सामान्य घटना है। इसलिए, उदाहरण के लिए, यदि संख्या 0 को एक पंक्ति में बीस बार दोहराया जाता है, तो बीस शून्य बाइट्स लगाने का कोई मतलब नहीं है। इसके बजाय, वे एक शून्य और 20 का गुणांक डालते हैं। पुनरावृत्तियों का पता लगाने के आधार पर ऐसे एल्गोरिदम को कहा जाता है तरीकोंRLE (रन लंबाई एन्कोडिंग).
समरूप बाइट्स के बड़े दोहराव वाले दृश्यों को विशेष रूप से ग्राफिक चित्रण द्वारा प्रतिष्ठित किया जाता है, लेकिन फोटोग्राफिक नहीं (मापदंडों में बहुत शोर और पड़ोसी बिंदु काफी भिन्न होते हैं), लेकिन जो कलाकार "चिकनी" रंग में रंगते हैं, जैसा कि एनिमेटेड फिल्मों में होता है।
हानिपूर्ण संपीड़न।
जानकारी के नुकसान के साथ संपीड़न का मतलब है कि संपीड़ित संग्रह को अनपैक करने के बाद, हम एक दस्तावेज प्राप्त करेंगे जो उस शुरुआत से थोड़ा अलग है जो शुरुआत में था। यह स्पष्ट है कि संपीड़न की डिग्री जितनी अधिक होगी, नुकसान की अधिकता और इसके विपरीत।
बेशक, इस तरह के एल्गोरिदम पाठ दस्तावेजों, डेटाबेस तालिकाओं और विशेष रूप से कार्यक्रमों के लिए लागू नहीं हैं। आप किसी भी तरह सादे, बिना किसी पाठ में मामूली विकृतियों से बच सकते हैं, लेकिन किसी कार्यक्रम में कम से कम एक बिट को विकृत करने से यह पूरी तरह से निष्क्रिय हो जाएगा।
इसी समय, ऐसी सामग्री होती है जिसमें कई बार दसियों बार संपीड़न करने के लिए कई प्रतिशत जानकारी का त्याग करने लायक होता है। इनमें फोटोग्राफिक चित्र, वीडियो और संगीत रचनाएं शामिल हैं। इस तरह की सामग्री में संपीड़न और बाद में अनपैकिंग के दौरान जानकारी का नुकसान कुछ अतिरिक्त "शोर" की उपस्थिति के रूप में माना जाता है। लेकिन चूंकि इन सामग्रियों को बनाते समय अभी भी एक निश्चित "शोर" है, इसकी मामूली वृद्धि हमेशा महत्वपूर्ण नहीं लगती है, और फ़ाइल आकार में लाभ बहुत बड़ा है (संगीत के लिए 10-15 गुना, फोटो और वीडियो के लिए 20-30 बार)।
जानकारी के नुकसान के साथ संपीड़न एल्गोरिदम में जेपीईजी और एमपीईजी जैसे प्रसिद्ध एल्गोरिदम शामिल हैं। JPEG एल्गोरिथ्म का उपयोग चित्रों को कंप्रेस करते समय किया जाता है। इस विधि से संपीड़ित छवि फ़ाइलों का विस्तार jpg है। वीडियो और संगीत को संपीड़ित करते समय एमपीईजी एल्गोरिदम का उपयोग किया जाता है। इन फ़ाइलों में विशिष्ट कार्यक्रम के आधार पर विभिन्न एक्सटेंशन हो सकते हैं, लेकिन सबसे प्रसिद्ध हैं। वीडियो के लिए एमपीजी और संगीत के लिए एमपी 3।
सूचना हानि संपीड़न एल्गोरिदम का उपयोग केवल उपभोक्ता कार्यों के लिए किया जाता है। इसका मतलब है, उदाहरण के लिए, कि अगर एक तस्वीर देखने के लिए प्रसारित की जाती है, और प्लेबैक के लिए संगीत है, तो ऐसे एल्गोरिदम को लागू किया जा सकता है। यदि उन्हें आगे की प्रक्रिया के लिए स्थानांतरित किया जाता है, उदाहरण के लिए संपादन के लिए, तो स्रोत सामग्री में जानकारी का कोई नुकसान स्वीकार्य नहीं है।
संपीड़न में स्वीकार्य नुकसान की भयावहता को आमतौर पर नियंत्रित किया जा सकता है। यह आपको इष्टतम आकार / गुणवत्ता अनुपात का उपयोग करने और प्राप्त करने की अनुमति देता है। एक स्क्रीन पर प्रदर्शित किए जाने वाले फोटोग्राफिक चित्र में, आमतौर पर 5% जानकारी का नुकसान सामान्य है, और कुछ मामलों में 20-25% को सहन किया जा सकता है।
दोषरहित संपीड़न एल्गोरिदम
शैनन फेनो कोड
आगे की चर्चा के लिए, पाठ के साथ हमारी स्रोत फ़ाइल को वर्णों के स्रोत के रूप में प्रस्तुत करना सुविधाजनक होगा, जो इसके आउटपुट पर एक बार दिखाई देते हैं। हमें पहले से पता नहीं है कि कौन सा चरित्र अगला होगा, लेकिन हम जानते हैं कि संभावना p1 के साथ "a" अक्षर दिखाई देगा, संभाव्यता P2 के साथ अक्षर "b" दिखाई देगा, आदि।
सबसे सरल मामले में, हम पाठ के सभी पात्रों को एक-दूसरे से स्वतंत्र होने पर विचार करेंगे, अर्थात्। अगले चरित्र की उपस्थिति की संभावना पिछले चरित्र के मूल्य पर निर्भर नहीं करती है। बेशक, यह एक सार्थक पाठ के लिए ऐसा नहीं है, लेकिन अब हम एक बहुत ही सरल स्थिति पर विचार कर रहे हैं। इस मामले में, बयान "प्रतीक अधिक जानकारी प्राप्त करता है, इसकी घटना की संभावना कम होती है।"
आइए एक ऐसे पाठ की कल्पना करें जिसकी वर्णमाला में केवल 16 अक्षर हैं: ए, बी, सी, डी, ई, एफ, जेड, आई, के, एल, एम, एच, ओ, पी, पी। इनमें से प्रत्येक वर्ण हो सकता है। केवल 4 बिट्स के साथ सांकेतिक शब्दों में बदलना: 0000 से 1111 तक। अब कल्पना करें कि इन पात्रों की घटना की संभावना निम्नानुसार वितरित की गई है:
इन संभावनाओं का योग, निश्चित रूप से, एक है। हम इन प्रतीकों को दो समूहों में विभाजित करते हैं, ताकि प्रत्येक समूह के प्रतीकों की कुल संभावना ~ 0.5 (छवि) हो। हमारे उदाहरण में, ये समूह होंगे अक्षर AB और जी.आर. वर्णों के समूहों को निरूपित करते हुए आकृति को वृत्त, वर्टिकल या नोड्स कहा जाता है और इन नोड्स की संरचना को बाइनरी ट्री (बी-ट्री) कहा जाता है। प्रत्येक नोड को अपना कोड असाइन करें, एक नोड को संख्या 0 के साथ नामित करें, और दूसरा नंबर 1 के साथ।
फिर से, हम पहले समूह (AB) को दो उपसमूहों में विभाजित करते हैं ताकि उनकी कुल संभावनाएं एक-दूसरे के जितना संभव हो सके। पहले उपसमूह के कोड में नंबर 0, और नंबर 1 को दूसरे के कोड में जोड़ें। 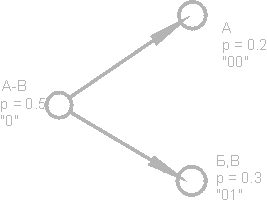
हम इस ऑपरेशन को तब तक दोहराएंगे जब तक कि एक प्रतीक हमारे "पेड़" के प्रत्येक शीर्ष पर नहीं रहता। हमारे वर्णमाला के एक पूर्ण पेड़ में 31 नोड होंगे।
वर्ण कोड (पेड़ के दूर दाएं नोड्स) में असमान लंबाई के कोड होते हैं। तो, अक्षर A, जिसमें हमारे काल्पनिक पाठ के लिए प्रायिकता p \u003d 0.2 है, केवल दो बिट्स के साथ एन्कोडेड है, और अक्षर P (आकृति में नहीं दिखाया गया है), जिसमें प्रायिकता p \u003d 0.013 है, छह-बिट संयोजन के साथ एन्कोडेड है।
तो, सिद्धांत स्पष्ट है - अक्सर होने वाले वर्ण कम बिट्स के साथ एन्कोड किए जाते हैं, शायद ही कभी होने वाले अक्षर अधिक एन्कोड किए जाते हैं। नतीजतन, प्रति चरित्र बिट्स की औसत संख्या के बराबर होगी
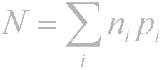
जहाँ n i-th वर्ण को कूटने वाली बिट्स की संख्या है, pi i-th वर्ण के घटित होने की संभावना है।
हफमैन कोड।
हफमैन एल्गोरिथ्म इनायत उपसर्ग सेट का उपयोग कर सांख्यिकीय कोडिंग के सामान्य विचार को लागू करता है और निम्नानुसार काम करता है:
1. हम एक पंक्ति में वर्णमाला के सभी वर्णों को पाठ में उनकी घटना की संभावना की आरोही या अवरोही क्रम में लिखते हैं।
2. लगातार दो प्रतीकों को एक नए समग्र प्रतीक में होने की कम से कम संभावनाओं के साथ मिलाएं, ऐसा होने की संभावना को इसके घटक प्रतीकों की संभावनाओं के योग के बराबर माना जाता है। अंत में, हम एक पेड़ का निर्माण करेंगे, जिसके प्रत्येक नोड में इसके नीचे सभी नोड्स की कुल संभावना है।
3. हम पेड़ के प्रत्येक पत्ते के लिए मार्ग का पता लगाते हैं, प्रत्येक नोड के लिए दिशा को चिह्नित करते हैं (उदाहरण के लिए, दाएं - 1, बाईं ओर - 0)। परिणामी अनुक्रम प्रत्येक वर्ण (छवि) के अनुरूप एक कोडवर्ड देता है।
निम्नलिखित वर्णमाला वाले संदेश के लिए एक कोड ट्री बनाएं:
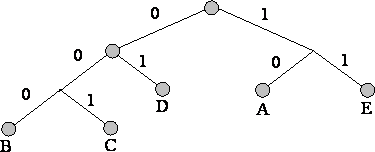
तरीकों का नुकसान
कोडों के साथ सबसे बड़ी कठिनाई, पिछली चर्चा के अनुसार, प्रत्येक प्रकार के संपीड़ित डेटा के लिए प्रायिकता तालिकाओं की आवश्यकता है। यह एक समस्या नहीं है यदि यह ज्ञात है कि अंग्रेजी या रूसी पाठ संकुचित हो रहा है; हम केवल अंग्रेजी या रूसी पाठ के लिए उपयुक्त कोड ट्री के साथ एनकोडर और डिकोडर प्रदान करते हैं। सामान्य स्थिति में, जब इनपुट डेटा के लिए वर्णों की संभावना अज्ञात होती है, तो हफमैन के स्थिर कोड अक्षम रूप से काम करते हैं।
इस समस्या का समाधान एन्कोडेड डेटा का एक सांख्यिकीय विश्लेषण है, जो डेटा के माध्यम से पहले पास के दौरान किया जाता है, और इसके आधार पर एक कोड ट्री को संकलित करता है। दरअसल, एन्कोडिंग दूसरा पास द्वारा किया जाता है।
कोड का एक और नुकसान यह है कि उनके लिए न्यूनतम कोडवर्ड की लंबाई एक से कम नहीं हो सकती है, जबकि संदेश एन्ट्रापी अच्छी तरह से 0.1 और 0.01 बिट्स / अक्षर हो सकता है। इस स्थिति में, कोड काफी अनावश्यक हो जाता है। एल्गोरिदम को वर्णों के ब्लॉक पर लागू करने से समस्या हल हो जाती है, लेकिन फिर एन्कोडिंग / डिकोडिंग प्रक्रिया जटिल होती है और कोड ट्री का काफी विस्तार होता है, जिसे अंततः कोड के साथ सहेजा जाना चाहिए।
ये कोड लगभग किसी भी पाठ में मौजूद वर्णों के बीच संबंध को ध्यान में नहीं रखते हैं। उदाहरण के लिए, यदि हम एक अंग्रेजी पाठ में अक्षर q देखते हैं, तो हम आत्मविश्वास से कह सकते हैं कि अक्षर u इसका अनुसरण करेगा।
समूह कोडिंग - रन लेंथ एन्कोडिंग (RLE) - सबसे पुराने और सबसे आसान संग्रह एल्गोरिदम में से एक। आरएलई में संपीड़न काउंटर, मूल्य जोड़े के साथ समान बाइट्स के तारों की जगह लेता है। ("लाल, लाल, ..., लाल" को "एन लाल" के रूप में लिखा जाता है)।
एल्गोरिथ्म के कार्यान्वयन में से एक निम्नानुसार है: वे कम से कम अक्सर बाइट का सामना करते हैं, इसे एक उपसर्ग कहते हैं, और त्रिकोणीय "उपसर्ग, काउंटर, मूल्य" के साथ समान वर्णों के तारों को प्रतिस्थापित करते हैं। यदि यह बाइट एक या दो बार स्रोत फ़ाइल में एक पंक्ति में मिलती है, तो इसे "उपसर्ग, 1" या "उपसर्ग, 2" की एक जोड़ी के साथ बदल दिया जाता है। एक अप्रयुक्त जोड़ी "उपसर्ग, 0" बनी हुई है, जिसे पैक्ड डेटा के अंत के संकेत के रूप में इस्तेमाल किया जा सकता है।
जब फ़ाइलों को एन्कोडिंग करते हैं, तो आप प्रपत्र AxAyAzAwAt ... के अनुक्रमों को खोज और पैकेज कर सकते हैं, जो अक्सर संसाधनों में पाए जाते हैं (यूनिकोड एन्कोडिंग में तार)
एल्गोरिथ्म के सकारात्मक पहलुओं में यह तथ्य शामिल है कि काम करते समय इसे अतिरिक्त मेमोरी की आवश्यकता नहीं होती है, और जल्दी से निष्पादित होता है। एल्गोरिथ्म का उपयोग पीसीएक्स, टीआईएफएफ, बीएमपी प्रारूप में किया जाता है। पीसीएक्स में समूह कोडिंग की एक दिलचस्प विशेषता यह है कि छवि पैलेट में रंगों के क्रम को बदलकर कुछ छवियों के लिए संग्रह की डिग्री में काफी वृद्धि की जा सकती है।
LZW कोड (Lempel-Ziv & Welch) अब तक का सबसे सामान्य दोषरहित संपीड़न कोड है। यह LZW कोड की मदद से है कि TIFF और GIF जैसे ग्राफिक फॉर्मेट में कम्प्रेशन किया जाता है, LZW संशोधनों की मदद से बहुत सारे यूनिवर्सल आर्काइव अपने कार्य करते हैं। एल्गोरिथ्म उन वर्णों के बार-बार अनुक्रम के लिए इनपुट फ़ाइल में खोज पर आधारित है जो लंबाई में 8 से 12 बिट्स के संयोजन में एन्कोड किए गए हैं। इस प्रकार, इस एल्गोरिथ्म में पाठ फ़ाइलों और ग्राफिक फ़ाइलों पर सबसे बड़ी दक्षता है, जिसमें बड़े एकल-रंग अनुभाग या पिक्सेल के दोहराव अनुक्रम हैं।
एलजेडडब्ल्यू कोडिंग के दौरान सूचना के नुकसान की अनुपस्थिति ने इसके आधार पर टीआईएफएफ प्रारूप का व्यापक उपयोग किया। यह प्रारूप छवि के आकार और रंग की गहराई पर कोई प्रतिबंध नहीं लगाता है और उदाहरण के लिए, मुद्रण में व्यापक है। एक और LZW- आधारित प्रारूप - GIF - अधिक आदिम है - यह आपको 8 बिट्स या पिक्सेल से अधिक नहीं की रंग गहराई के साथ छवियों को संग्रहीत करने की अनुमति देता है। GIF फ़ाइल की शुरुआत में एक पैलेट है - एक तालिका जो रंग सूचकांक के बीच पत्राचार सेट करती है - 0 से 255 तक की सीमा में एक संख्या और एक सच्चे, 24-बिट रंग मान।
सूचना हानि संपीड़न एल्गोरिदम
JPEG एल्गोरिथम को संयुक्त फोटोग्राफिक विशेषज्ञ समूह नामक कंपनियों के समूह द्वारा विकसित किया गया था। परियोजना का उद्देश्य काले और सफेद और रंगीन चित्रों दोनों के लिए एक अत्यधिक कुशल संपीड़न मानक बनाना था, और यह लक्ष्य डेवलपर्स द्वारा हासिल किया गया था। वर्तमान में, जेपीईजी का व्यापक रूप से उपयोग किया जाता है जहां उच्च स्तर की संपीड़न की आवश्यकता होती है - उदाहरण के लिए, इंटरनेट पर।
LZW एल्गोरिथ्म के विपरीत, JPEG एन्कोडिंग हानिपूर्ण एन्कोडिंग है। एन्कोडिंग एल्गोरिथ्म स्वयं बहुत जटिल गणित पर आधारित है, लेकिन सामान्य शब्दों में इसे निम्नानुसार वर्णित किया जा सकता है: छवि को 8 * 8 पिक्सेल के वर्गों में विभाजित किया गया है, और फिर प्रत्येक वर्ग 64 पिक्सेल की अनुक्रमिक श्रृंखला में बदल दिया जाता है। इसके अलावा, प्रत्येक ऐसी श्रृंखला तथाकथित डीसीटी परिवर्तन के अधीन है, जो असतत फूरियर रूपांतरण की किस्मों में से एक है। यह इस तथ्य में निहित है कि पिक्सल के इनपुट अनुक्रम को कई आवृत्तियों (तथाकथित हार्मोनिक्स) के साथ साइनसोइडल और कोसाइन घटकों के योग के रूप में दर्शाया जा सकता है। इस मामले में, हमें पर्याप्त मात्रा में सटीकता के साथ इनपुट अनुक्रम को पुनर्स्थापित करने के लिए इन घटकों के केवल आयामों को जानना होगा। हम जितना अधिक हार्मोनिक घटकों को जानते हैं, उतना ही मूल और संकुचित छवि के बीच एक विसंगति होगी। अधिकांश JPEG एनकोडर आपको संपीड़न अनुपात को समायोजित करने की अनुमति देते हैं। यह एक बहुत ही सरल तरीके से हासिल किया गया है: संपीड़न अनुपात जितना अधिक होगा, प्रत्येक 64-पिक्सेल ब्लॉक में कम हार्मोनिक्स का प्रतिनिधित्व किया जाएगा।
बेशक, मूल रंग की गहराई को बनाए रखते हुए इस प्रकार की कोडिंग की ताकत एक बड़ा संपीड़न अनुपात है। यह वह संपत्ति है जिसने इंटरनेट पर इसके व्यापक उपयोग का कारण बना, जहां फ़ाइल आकार में कमी का महत्वपूर्ण महत्व है, मल्टीमीडिया विश्वकोषों में, जहां संभव के रूप में अधिक ग्राफिक्स को सीमित मात्रा में संग्रहीत करने की आवश्यकता होती है।
इस प्रारूप की एक नकारात्मक संपत्ति किसी भी तरह से अप्राप्य है, छवि गुणवत्ता में अंतर्निहित अंतर्निहित गिरावट। यह दुख की बात है कि इसका उपयोग मुद्रण में नहीं होता है, जहां गुणवत्ता सर्वोपरि है।
हालाँकि, JPEG प्रारूप अंतिम फ़ाइल के आकार को कम करने की इच्छा में पूर्णता की सीमा नहीं है। हाल ही में, तथाकथित तरंगिका परिवर्तन (या फट परिवर्तन) के क्षेत्र में गहन शोध किया जा रहा है। सबसे जटिल गणितीय सिद्धांतों के आधार पर, वेवलेट एनकोडर आपको जेपीईजी की तुलना में अधिक संपीड़न प्राप्त करने की अनुमति देते हैं, कम जानकारी के नुकसान के साथ। तरंगिका परिवर्तन की गणित की जटिलता के बावजूद, यह जेपीईजी की तुलना में सॉफ्टवेयर कार्यान्वयन में सरल है। हालांकि वेवलेट कम्प्रेशन एल्गोरिदम अभी भी अपनी शैशवावस्था में हैं, लेकिन उनके पास एक महान भविष्य है।
भग्न संपीड़न
भग्न छवि संपीड़न छवियों के लिए चलने योग्य फ़ंक्शन सिस्टम (IFS, जो आमतौर पर परिशोधन परिवर्तन हैं) के आवेदन के आधार पर एक हानिरहित छवि संपीड़न एल्गोरिदम है। इस एल्गोरिथ्म को इस तथ्य के लिए जाना जाता है कि कुछ मामलों में यह प्राकृतिक वस्तुओं की वास्तविक तस्वीरों के लिए बहुत उच्च संपीड़न अनुपात (सबसे अच्छा उदाहरण स्वीकार्य दृश्य गुणवत्ता के साथ 1000 गुना तक) प्राप्त करने की अनुमति देता है, जो सिद्धांत रूप में अन्य छवि संपीड़न एल्गोरिदम के लिए उपलब्ध नहीं है। पेटेंट के साथ कठिन स्थिति के कारण, एल्गोरिथ्म का व्यापक रूप से उपयोग नहीं किया गया था।
फ्रैक्टल आर्काइविंग इस तथ्य पर आधारित है कि सिस्टम के चलने योग्य कार्यों के गुणांक का उपयोग करते हुए, छवि को अधिक कॉम्पैक्ट रूप में प्रस्तुत किया जाता है। इससे पहले कि हम संग्रह की प्रक्रिया देखें, आइए देखें कि IFS एक छवि कैसे बनाता है।
कड़ाई से बोलते हुए, IFS तीन आयामी affine परिवर्तनों का एक सेट है जो एक छवि को दूसरे में अनुवाद करता है। त्रि-आयामी अंतरिक्ष में बिंदु परिवर्तित होते हैं (x निर्देशांक, y समन्वय, चमक)।
भग्न कोडिंग विधि का आधार छवि में स्व-समान वर्गों का पता लगाना है। छवि संपीड़न की समस्या के लिए चलने योग्य फ़ंक्शन सिस्टम (IFS) के सिद्धांत को लागू करने की संभावना सबसे पहले माइकल बार्न्सले और एलन स्लोन द्वारा जांच की गई थी। उन्होंने 1990 और 1991 में अपने विचार का पेटेंट कराया। जैक्विन ने एक भग्न कोडिंग पद्धति शुरू की जो डोमेन का उपयोग करती है और संपूर्ण छवि को कवर करने वाले वर्ग-आकार के ब्लॉक को सीमित करती है। यह दृष्टिकोण आज इस्तेमाल की जाने वाली अधिकांश भग्न कोडिंग विधियों का आधार बन गया है। इसे युवल फिशर और कई अन्य शोधकर्ताओं द्वारा विकसित किया गया था।
इस पद्धति के अनुसार, छवि को कई गैर-ओवरलैपिंग रैंक सबमेज (रेंज सबमेज) में विभाजित किया जाता है और बहुत सारे ओवरलैपिंग डोमेन सबमेज (डोमेन सबमेज) निर्धारित किए जाते हैं। प्रत्येक रैंक ब्लॉक के लिए, एन्कोडिंग एल्गोरिथ्म सबसे उपयुक्त डोमेन ब्लॉक पाता है और एफाइन ट्रांसफॉर्मेशन जो इस डोमेन ब्लॉक को दिए गए रैंक ब्लॉक में बदल देता है। छवि संरचना को रैंक ब्लॉक, डोमेन ब्लॉक और रूपांतरित करने की प्रणाली में मैप किया जाता है।
यह विचार यह है: मान लीजिए कि मूल छवि किसी प्रकार की संपीड़ित मानचित्रण का एक निश्चित बिंदु है। फिर, छवि के बजाय, इस प्रदर्शन को किसी तरह से याद रखना संभव है, और बहाली के लिए यह प्रदर्शन को किसी भी शुरुआती छवि पर बार-बार लागू करने के लिए पर्याप्त है।
बानाच के प्रमेय द्वारा, इस तरह के पुनरावृत्तियों को हमेशा एक निश्चित बिंदु तक ले जाया जाता है, अर्थात मूल छवि तक। व्यवहार में, पूरी कठिनाई छवि से और कॉम्पैक्ट भंडारण में सबसे उपयुक्त संपीड़ित प्रदर्शन खोजने में निहित है। एक नियम के रूप में, खोज एल्गोरिदम (यानी, संपीड़न एल्गोरिदम) की मैपिंग भारी बल है और बड़ी कम्प्यूटेशनल लागत की आवश्यकता होती है। इसी समय, रिकवरी एल्गोरिदम काफी कुशल और तेज हैं।
संक्षेप में, बार्न्सली द्वारा प्रस्तावित विधि को निम्नानुसार वर्णित किया जा सकता है। छवि को कई सरल परिवर्तनों (हमारे मामले में, affine) द्वारा एन्कोड किया गया है, अर्थात, यह इन परिवर्तनों के गुणांक (हमारे मामले में ए, बी, सी, डी, ई, एफ) द्वारा निर्धारित किया गया है।
उदाहरण के लिए, कोच वक्र की छवि को चार एफाइन परिवर्तनों के साथ एन्कोड किया जा सकता है, हम केवल 24 गुणांक का उपयोग करके इसे विशिष्ट रूप से निर्धारित करेंगे।
नतीजतन, बिंदु मूल छवि में काले क्षेत्र के अंदर आवश्यक रूप से कहीं जाएगा। इस ऑपरेशन को कई बार करने के बाद, हम सभी ब्लैक स्पेस को भर देंगे, जिससे तस्वीर फिर से आ जाएगी।

सबसे प्रसिद्ध दो चित्र IFS का उपयोग करके प्राप्त किए गए हैं: सीरपिन्स्की त्रिकोण और बार्न्सले फ़र्न। पहला तीन द्वारा परिभाषित किया गया है, और दूसरा पांच एफाइन ट्रांसफॉर्मेशन (या, हमारी शब्दावली, लेंस में)। प्रत्येक रूपांतरण सचमुच बाइट्स द्वारा निर्दिष्ट किया जाता है, जबकि उनकी मदद से बनाई गई छवि कई मेगाबाइट ले सकती है।
यह स्पष्ट हो जाता है कि अभिलेखागार कैसे काम करता है, और इसमें इतना समय क्यों लगता है। वास्तव में, भग्न संपीड़न छवि में स्व-समान क्षेत्रों के लिए एक खोज है और उनके लिए affine परिवर्तनों के मापदंडों का निर्धारण है।
सबसे खराब स्थिति में, यदि अनुकूलन एल्गोरिथ्म का उपयोग नहीं किया जाता है, तो उसे विभिन्न आकारों के सभी संभव छवि टुकड़ों की गणना और तुलना की आवश्यकता होगी। यहां तक \u200b\u200bकि छोटी छवियों को ध्यान में रखते हुए, हमें खोजे जाने वाले विकल्पों की एक खगोलीय संख्या मिलती है। यहां तक \u200b\u200bकि परिवर्तन वर्गों की एक तेज संकीर्णता, उदाहरण के लिए, केवल एक निश्चित संख्या में स्केलिंग के कारण, स्वीकार्य समय प्राप्त करने की अनुमति नहीं देगा। इसके अलावा, छवि गुणवत्ता खो जाती है। भग्न संपीड़न के क्षेत्र में अध्ययन के विशाल बहुमत अब उच्च गुणवत्ता वाले चित्र प्राप्त करने के लिए आवश्यक संग्रह समय को कम करने के उद्देश्य से हैं।
एक भग्न संपीड़न एल्गोरिथ्म के लिए, साथ ही अन्य हानिपूर्ण संपीड़न एल्गोरिदम के लिए, तंत्र जिसके साथ संपीड़न अनुपात को नियंत्रित करना संभव होगा और नुकसान की डिग्री बहुत महत्वपूर्ण है। आज तक, इस तरह के तरीकों का पर्याप्त रूप से बड़ा सेट विकसित किया गया है। सबसे पहले, परिवर्तनों की संख्या को सीमित करना संभव है, स्पष्ट रूप से एक निश्चित मूल्य से कम नहीं का संपीड़न अनुपात प्रदान करना। दूसरे, आप आवश्यकता कर सकते हैं कि ऐसी स्थिति में जहां संसाधित टुकड़ा और इसके सर्वश्रेष्ठ सन्निकटन के बीच अंतर एक निश्चित सीमा मूल्य से अधिक है, यह टुकड़ा आवश्यक रूप से विभाजित है (कई लेंस इसके लिए घाव होना चाहिए)। तीसरी बात, चार बिंदुओं की तुलना में छोटे टुकड़ों के खंडन को रोकना संभव है। थ्रेसहोल्ड मान और इन स्थितियों की प्राथमिकता को बदलकर, आप बहुत लचीले ढंग से छवि के संपीड़न अनुपात को नियंत्रित कर सकते हैं: बिटवाइज मिलान से किसी भी संपीड़न अनुपात तक।
जेपीईजी के साथ तुलना
आज, सबसे आम ग्राफिक्स संग्रह एल्गोरिथ्म JPEG है। इसकी तुलना भग्न संपीड़न से करें।
सबसे पहले, हम ध्यान दें कि एक और दूसरे दोनों 8-बिट (ग्रेस्केल में) और 24-बिट पूर्ण-रंग चित्रों के साथ काम करते हैं। दोनों हानिपूर्ण संपीड़न एल्गोरिदम हैं और करीब अभिलेखीय अनुपात प्रदान करते हैं। भग्न एल्गोरिथ्म और जेपीईजी दोनों में नुकसान को बढ़ाकर संपीड़न अनुपात को बढ़ाने का अवसर है। इसके अलावा, दोनों एल्गोरिदम बहुत अच्छी तरह से समानांतर हैं।
यदि हम एल्गोरिदम को संग्रह / अनज़िप करने के लिए लगने वाले समय पर विचार करते हैं तो मतभेद शुरू हो जाते हैं। तो, भग्न एल्गोरिथ्म JPEG की तुलना में सैकड़ों और यहां तक \u200b\u200bकि हजारों बार लंबे समय तक संपीड़ित करता है। छवि को खोलना, इसके विपरीत, 5-10 गुना तेजी से होगा। इसलिए, यदि छवि को केवल एक बार संकुचित किया जाएगा, और नेटवर्क पर प्रेषित किया जाएगा और कई बार अनपैक किया जाएगा, तो यह फ्रैक्चर एल्गोरिथ्म का उपयोग करने के लिए अधिक लाभदायक है।
जेपीईजी छवि के अपघटन का उपयोग कोजाई कार्यों में करता है, इसलिए इसमें नुकसान (यहां तक \u200b\u200bकि निर्दिष्ट न्यूनतम नुकसान पर) लहरों में प्रकट होता है और तेज रंग संक्रमण की सीमा पर प्रकट होता है। यह इस प्रभाव के लिए है कि वे उच्च गुणवत्ता वाले मुद्रण के लिए तैयार की गई छवियों को संपीड़ित करते समय इसका उपयोग करना पसंद नहीं करते हैं: वहां यह प्रभाव बहुत ध्यान देने योग्य हो सकता है।
भग्न एल्गोरिथ्म इस दोष से मुक्त है। इसके अलावा, जब एक छवि को प्रिंट करते हैं, तो आपको प्रत्येक बार स्केलिंग ऑपरेशन करना पड़ता है, क्योंकि मुद्रण डिवाइस का रेखापुंज (या लाइन्रेट) छवि रेखापुंज से मेल नहीं खाता है। परिवर्तित करते समय, कई अप्रिय प्रभाव भी हो सकते हैं, जो या तो छवि को प्रोग्रामेटिक रूप से (पारंपरिक लेजर और इंकजेट प्रिंटर जैसे कम लागत वाले मुद्रण उपकरणों के लिए) स्केलिंग करके, या मुद्रण डिवाइस को अपने प्रोसेसर, हार्ड ड्राइव और छवि प्रसंस्करण कार्यक्रमों के सेट (महंगे फोटोग्राफिक टाइपसेट के लिए) से जोड़कर किया जा सकता है। जैसा कि आप अनुमान लगा सकते हैं, भग्न एल्गोरिथ्म का उपयोग करते समय, ऐसी समस्याएं व्यावहारिक रूप से उत्पन्न नहीं होती हैं।
व्यापक उपयोग में भग्न एल्गोरिथ्म द्वारा जेपीईजी को बाहर करना जल्द ही नहीं होगा (कम से कम उत्तरार्द्ध को संग्रहीत करने की कम गति के कारण), हालांकि, कंप्यूटर गेम में मल्टीमीडिया अनुप्रयोगों के क्षेत्र में, इसका उपयोग उचित है।
पहले भाग में, हम ऑडियो प्रारूपों को देखेंगे। FLAC, WavPack, TAK, मंकी ऑडियो, OptimFROG, ALAC, WMA, शॉर्टेन, LA, TTA, LPAC, MPEG-4 ALS, MPEG-4 SLS, रियल लॉसलेस है? क्या आपको पता है कि ऑडियो कितने प्रकार का होता है? फ़ाइलें? अब तक, हम दोषरहित ऑडियो संपीड़न प्रारूपों के साथ काम कर रहे हैं, और हम लेख के बहुत अंत में ऑडियो एक्सटेंशन की संख्या के बारे में प्रश्न के उत्तर को देखते हैं।
इसलिए, पहले हम शर्तों को परिभाषित करते हैं:
« एल्गोरिथ्म "यह एक सटीक पर्चे है जो कम्प्यूटेशनल प्रक्रिया को परिभाषित करता है जो चर स्रोत डेटा से वांछित परिणाम तक जाता है।"
« कोडेक (eng। कोडेक, कोडर / डिकोडर से - एनकोडर / डिकोडर - एनकोडर / डिकोडर या कंप्रेसर / डिकम्प्रेसर) - एक उपकरण या प्रोग्राम जो डेटा या सिग्नल रूपांतरण कर सकता है। कोडेक या तो एक स्ट्रीम / सिग्नल (अक्सर ट्रांसमिशन, स्टोरेज या एन्क्रिप्शन के लिए) को एनकोड कर सकते हैं, या इसे उस फॉरमेट में देखने या बदलने के लिए डिकोड कर सकते हैं, जो इन ऑपरेशंस के लिए अधिक उपयुक्त है। कोडेक का उपयोग अक्सर वीडियो और ध्वनि के डिजिटल प्रसंस्करण में किया जाता है।
ऑडियो और विज़ुअल डेटा के लिए अधिकांश कोडक समाप्त (संपीड़ित) फ़ाइल का स्वीकार्य आकार प्राप्त करने के लिए हानिपूर्ण संपीड़न का उपयोग करते हैं। दोषरहित संपीड़न कोडेक्स भी हैं। "
« दोषरहित संपीड़न (अंग्रेजी दोषरहित डेटा संपीड़न) सूचना संपीड़न की एक विधि है, जिसके उपयोग से एन्कोडेड जानकारी को बिट्स पर सटीक रूप से पुनर्स्थापित किया जा सकता है। इस मामले में, मूल डेटा संपीड़ित स्थिति से पूरी तरह से बहाल है। प्रत्येक प्रकार की डिजिटल जानकारी के लिए, एक नियम के रूप में, अपने स्वयं के दोषरहित संपीड़न एल्गोरिदम हैं। "
दोषरहित डेटा संपीड़न का उपयोग तब किया जाता है जब संपीड़ित डेटा की मूल में पहचान महत्वपूर्ण होती है। एक सामान्य उदाहरण निष्पादन योग्य फाइलें, दस्तावेज और स्रोत कोड है। दोषरहित संपीड़न प्रारूपों का उपयोग करने वाले कार्यक्रमों को अभिलेखागार कहा जाता है, हर कोई लोकप्रिय फ़ाइल प्रारूप ज़िप, या आरएआर, यूनिक्स-उपयोगिता गज़िप आदि जानता है। ये सभी कार्यक्रम लागू किए गए एल्गोरिदम (एक या कई) में भिन्न होते हैं और इसलिए विभिन्न फ़ाइलों के अलग-अलग संपीड़न गुण होते हैं।
भाग I - सिद्धांत:
संपीड़न विधियों या दोषरहित संपीड़न एल्गोरिदम को उस प्रकार के डेटा द्वारा वितरित किया जा सकता है जिसके लिए वे बनाए गए थे। डेटा के तीन मुख्य प्रकार हैं: पाठ, चित्र और ध्वनि।
सिद्धांत रूप में, किसी भी दोषरहित बहुउद्देशीय डेटा संपीड़न एल्गोरिथ्म (बहुउद्देशीय का अर्थ है कि यह किसी भी प्रकार के बाइनरी डेटा को संसाधित कर सकता है) का उपयोग किसी भी प्रकार के डेटा के लिए किया जा सकता है, लेकिन उनमें से अधिकांश प्रत्येक मुख्य प्रकार के लिए अक्षम हैं। ध्वनि डेटा, उदाहरण के लिए, एक पाठ संपीड़न एल्गोरिथ्म द्वारा अच्छी तरह से संपीड़ित नहीं किया जा सकता है और इसके विपरीत।
संपीड़न विधियों के बीच, निम्नलिखित पर ध्यान दिया जा सकता है - एन्ट्रापी संपीड़न, शब्दकोश विधियाँ, सांख्यिकीय विधियाँ। प्रत्येक विधि एक निश्चित प्रकार के डेटा के लिए अच्छा है और इसमें कई एल्गोरिदम शामिल हैं।
एन्ट्रापी संपीड़न: हफ़मैन एल्गोरिथ्म · हफ़मैन अनुकूली एल्गोरिथम · अंकगणित कोडिंग (शैनन - फ़ानो एल्गोरिथम · अंतराल) · गोलाकार कोड · डेल्टा · यूनिवर्सल कोड (एलियास - फिबोनाची)
शब्दावली विधियाँ: RLE डिफ्लैट LZ (LZ77 / LZ78 LZSS LZW LZWL LZO LZMA LZMA LZRW LZRW LZJB LZT)
पाठ के लिए सांख्यिकीय मॉडल एल्गोरिदम (या निष्पादन योग्य फ़ाइलों जैसे द्विआधारी पाठ डेटा) में शामिल हैं: बैरो-व्हीलर परिवर्तन (ब्लॉक-सॉर्टिंग प्री-प्रोसेसिंग जो संपीड़न को अधिक कुशल बनाता है) · LZ77 और LZ78 (DEFLATE का उपयोग करके) · LZW।
अन्य: RLE · CTW · BWT · MTF · PPM · DMC
अक्सर, केवल अच्छी तरह से विकसित एल्गोरिदम को एक नाम मिलता है, जबकि हालिया विकास केवल सामान्य रूप से उपयोग (सामान्य उपयोग, मानकीकरण, आदि) या निर्दिष्ट नहीं होते हैं।
लेकिन वापस हमारे विषय पर। एन्कोडिंग ऑडियो डेटा उपयुक्त एल्गोरिदम के लिए:
हफ़मैन एल्गोरिथ्म (भी DEFLATE का उपयोग किया गया), अंकगणित कोडिंग
Apple दोषरहित — ALAC (Apple दोषरहित ऑडियो कोडेक)
ऑडियो दोषरहित कोडिंग — mPEG-4 ALS के रूप में भी जाना जाता है
मुफ्त दोषरहित ऑडियो कोडेक — FLAC
मेरिडियन दोषरहित पैकिंग — MLP
बंदर का ऑडियो — बंदर
OptimFROG
वी.ओ. — RealAudio दोषरहित
छोटा — SHN
TAK — (T) ओम का शब्दशः (ए) udio (के) ओमप्रेस (जर्मन)
TTA — सच्चा ऑडियो दोषरहित
WavPack — Wavpack दोषरहित
वामा दोषरहित — विंडोज मीडिया दोषरहित
डीटीएस — DTS सराउंड साउंड
Lempel-Ziv परिवार के एल्गोरिदम, RLE (रन-लंबाई एन्कोडिंग)
FLAC (मुफ्त दोषरहित ऑडियो कोडेक)
बंदर का ऑडियो (बंदर)
TTA (सच्चा ऑडियो)
TTE
ला(LosslessAudio)
RealAudio दोषरहित
WavPack और अन्य
जैसा कि आपने देखा, दोषरहित संपीड़न के लिए अधिकांश कोडक दो (कभी-कभी अधिक) विभिन्न प्रकार के एल्गोरिदम का उपयोग करते हैं: एक आने वाले डेटा के लिए एक सांख्यिकीय मॉडल उत्पन्न करता है, दूसरा एक बिट प्रतिनिधित्व में आने वाले डेटा को प्रदर्शित करता है, एक मॉडल का उपयोग करके "संभाव्य" (जो अक्सर सामने आया) डेटा जो "अविश्वसनीय" की तुलना में अधिक बार उपयोग किया जाता है। लाभ - आकार कम करना, गणना करना - एन्कोडिंग / डिकोडिंग के लिए अधिक प्रोसेसर समय की आवश्यकता होती है।
जब हम एक छोटे से सिद्धांत का पता लगाते हैं, तो हम ऑडियो डेटा को संपीड़ित करने के लिए अपने कोडेक्स पर चले जाएंगे, जो कई महान लोगों द्वारा लिखे गए हैं: फ्री दोषरहित ऑडियो कोडेक, वावैक, टीएके, बंदर का ऑडियो (.ape, apl), OptimFROG (.ofr), Apple दोषरहित ऑडियो कोडेक। डब्लूएमए, शॉर्टेन (.SHN), लॉसलेसएडियो, ट्रू ऑडियो, लॉसलेस प्रेडिक्टिव ऑडियो कोडर (.LPAC), एमपीईजी -4 एएलएस, एमपीईजी -4 एसएलएस (.mp4), रियल लॉसलेस या रियलिडियो लॉसलेस, विंडोज मीडिया ऑडियो लॉसलेस, डीटीएस ..। और यह सभी से बहुत दूर है, पेशेवर रिकॉर्डिंग उपकरण बनाने वाली कई कंपनियों ने अपने स्वयं के स्वरूपों का आविष्कार किया और जारी रखा।
ऑडियो डेटा कम्प्रेशन के ऐसे कई बेहतरीन प्रारूप प्लेटफ़ॉर्म की तकनीकी खराबी (90 के दशक में सूचीबद्ध अधिकांश कोडेक्स में लिखे गए थे), मार्केटिंग (ALAC के मामले में) के कारण होते हैं, और गणितीय और विश्वविद्यालय के दर्शकों को डेटा कंप्रेशर्स में बहुत दिलचस्पी है।
उपरोक्त के अलावा, वहाँ (अस्तित्व में) एक महान कई योग्य या नहीं लायक ऑडियो अभिलेखागार और ऑडियो कोडेक भूल गए हैं। कुछ की तकनीकी विशेषताओं को तालिका में पाया जा सकता है:
क्लिक करने योग्य:
हम केवल उन लोगों पर अधिक विस्तार से विचार करेंगे जो व्यापक उपयोग में हैं और जो, लेखन के समय, इंटरनेट पर पाए जा सकते हैं। इनमें से केवल एक दर्जन हैं।
भाग II - अभ्यास:
बाएं से दाएं: 1. नीला क्षेत्र एसएसडीएस (सोनी डायनामिक डिजिटल साउंड), 2. ग्रे जोन डॉल्बी डिजिटल (पंचिंग के बीच), 3. एनालॉग ऑडियो (रिकॉर्ड के अनुसार), और 4. समय कोड डीटीएस (नीला)।
और यहाँ उपरोक्त नौ में से 2009 के लिए एक नई तुलना है:
भाग III - परीक्षण:
तुलना प्लेटफॉर्म पर की गई:
CPU: ड्यूलकोर इंटेल कोर i3 530, 2933 मेगाहर्ट्ज (x86, x86-64, MMX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2)
मदरबोर्ड। बोर्ड: आसुस P7H55-V
RAM: 2x2Gb DDR3-1333
HDD: सीगेट SATA 160GB 8 MB कैश (सिस्टम), हिताची SATA-II 500GB 16 MB कैश (स्रोत), Hitachi SATA-II 1000GB 32 MB कैश (गंतव्य)
1. दोषरहित ऑडियो (LA) - यह बहुत पुराना कोडेक (2004) संपीड़न में निर्विवाद विजेता बन गया। उसी समय, यह ध्यान दिया जाना चाहिए कि एन्कोडिंग की गति काफी स्वीकार्य है (समान ऑप्टिमोर्ग या WavPack की तुलना में), साथ ही साथ पर्याप्त डिकोडिंग गति भी। हालाँकि LA फ़ाइल को foo_benchmark प्लगइन का उपयोग करके डिकोड नहीं किया गया था, यह पूरी तरह से बिना स्टंबिंग या स्क्रॉल देरी के खेला गया।
केवल एक ही आश्चर्य हो सकता है कि लेखक ने स्रोत कोड को खोले बिना इस तरह के एक सुंदर कोडेक को क्यों छोड़ दिया।
2. OptimFROG - एलए से बहुत पीछे नहीं। लेकिन इसकी गति को शायद ही तेज कहा जा सकता है। इसके अलावा, एक फ़ाइल के माध्यम से स्क्रॉल करते समय एक उच्च देरी एक अप्रिय क्षण है - कभी-कभी यह बहुत कष्टप्रद होता है।
3. बंदर का ऑडियो - एक लोकप्रिय लेकिन संसाधन-गहन कोडेक। यह वास्तव में उच्च संपीड़न देता है, लेकिन फिर से स्क्रॉलिंग मुद्दे हैं। (परीक्षण के लेखक ने "पागल" विकल्प के साथ फाइल को जकड़ लिया है, जो अभी भी नुकसान से भरा हुआ है)।
4. TAK - यह सक्रिय रूप से विकसित कोडेक कृपया खुश नहीं करता है। यदि आप सभी तीन मापदंडों (संपीड़न, एन्कोडिंग, डिकोडिंग) को ध्यान में रखते हैं, तो TAK सबसे आकर्षक लगता है। प्रोसेसर ऑप्टिमाइज़ेशन (SSSE3 सहित) के सक्रिय उपयोग से ऑपरेशन की उच्च गति को समझाया गया है। और दो कोर का उपयोग एन्कोडिंग गति में लगभग दोगुना वृद्धि देता है! इस प्रकार, TAK के मामले में, आधुनिक प्रोसेसर का उपयोग करने का लाभ सबसे अधिक ध्यान देने योग्य है।
5. WavPack - ईमानदार होने के लिए, मुझे नहीं पता कि इस कोडेक ने लोकप्रियता क्यों हासिल की है। मध्यम संपीड़न कोडिंग पैदावार FLAC की तुलना में परिणाम है, और उच्च संपीड़न मोड का उपयोग गति में एक अनुचित कमी की ओर जाता है। हालाँकि, इस कोडेक का मुख्य लाभ इसका विस्तृत समर्थन और कार्यक्षमता (मल्टी-चैनल ऑडियो, हाइब्रिड मोड के लिए समर्थन सहित) है, लेकिन मैं आपको याद दिलाता हूं कि हम इस परीक्षण में इस मुद्दे पर विचार नहीं करते हैं।
6. ट्रू ऑडियो (TTA) - यहाँ यह ध्यान दिया जाना चाहिए कि एक बहुत ही उच्च गति और एक स्वीकार्य संपीड़न अनुपात (FLAC की तुलना में थोड़ा अधिक) को छोड़कर। इसके अलावा, डिकोडिंग की गति को बहुत अधिक नहीं कहा जा सकता है।
7. FLAC- संपीड़न अनुपात औसत है, लेकिन डिकोडिंग गति प्रसन्न है। सच है, जनता के बीच इस कोडेक के नेतृत्व का मुख्य कारण खुला स्रोत है, और, परिणामस्वरूप, व्यापक हार्डवेयर / सॉफ़्टवेयर समर्थन।
8. Apple दोषरहित (ALAC) - उन कोडेक्स में से एक जो अचूक हैं, लेकिन डेवलपर्स द्वारा सक्रिय रूप से प्रत्यारोपित किया जाना जारी है (इस मामले में, Apple)। कम संपीड़न और डिकोडिंग गति। संपीड़न की गति औसत है। IPod उपयोगकर्ताओं को छोड़कर, उनके पास कोई विकल्प नहीं है।
9. वामा दोषरहित - ALAC के समान मामला, लेकिन यहां हम विशाल निगम Microsoft के साथ काम कर रहे हैं। यहां तक \u200b\u200bकि कम संपीड़न, औसत संपीड़न दर। डिकोडिंग की गति अपेक्षाकृत अधिक है। ऐसे मामले की कल्पना करना मुश्किल है जिसमें इस विशेष दोषरहित कोडेक का उपयोग करना आवश्यक होगा।
भाग IV - सामान्य निष्कर्ष:
चुनाव सरल है और इसमें दो बिंदु शामिल हैं:
यदि डिस्क स्थान महत्वपूर्ण है, तो हम बंदर के ऑडियो का उपयोग करते हैं (जो कि FLAC की तुलना में 8-12% बेहतर है, जो 1TB डिस्क पर लगभग 100GB या लगभग 300 मानक सीडी एल्बम होगा) वही इंटरनेट पर वितरण के लिए जाता है। मैं अपना संग्रह रखता हूं। यह अतिरिक्त उच्च संपीड़न विकल्प के साथ बंदर के ऑडियो प्रारूप में है। मैं विभिन्न एलए और अन्य का उपयोग नहीं करता हूं, क्योंकि बंदर के ऑडियो की तुलना में उनके उपयोग से लाभ छोटा है।
यदि लिनक्स के तहत काम करने वाले विभिन्न खिलाड़ियों और मीडिया के लोहे के टुकड़ों के साथ संगतता महत्वपूर्ण है और न केवल FLAC का उपयोग करें। हालांकि खिलाड़ियों के लिए IMHO यह अपने और एमपी के लिए काफी उपयुक्त है, क्योंकि मुख्य बात ध्वनि नहीं है, लेकिन संगीत!
भविष्य में, हम टीटीए के विकास को देखेंगे, लेकिन मेरा व्यक्तिपरक विचार यह है कि "बेघर दूरी" के लिए भाप लोकोमोटिव के लिए टीटीए को पहले ही देर हो चुकी थी।
"खसखस ड्राइवरों" और "ऐ-फ़ॉन्ट्स" के लिए - जहां तक \u200b\u200bमुझे पता है कि पसंद एक है - एक टैम्बोरिन और ALAC प्रारूप में विभिन्न ट्रांसकोडर के आसपास नृत्य करता है।
और याद रखें, आप हमेशा फ़ाइलों को एक कोडेक से दूसरे में स्थानांतरित कर सकते हैं, और गुणवत्ता के नुकसान के बिना, यह वही है जो हानिरहित संपीड़न कोडेक्स हानिपूर्ण संपीड़न कोडेक के विपरीत अच्छा है।
पाचन "गीतात्मक" संख्या ONCE।
"उडीफिलोव" के लिए। ध्वनि स्वरूपों में अंतर - नहीं! "उच्च का प्राकृतिक रंग नहीं", "पंच की आसान अवैधता", जैसे "दृश्य के धब्बा के साथ बीच का पर्दा" - यह आपके सिस्टम में है। Codecs नहीं खेलते हैं, वे कुछ भी नहीं हटाते हैं, और कुछ भी नहीं हटाते हैं।
विषयांतर "गीतात्मक" संख्या TWO है।
यह लेख संगीत प्रेमियों और संगीत कलेक्टरों के लिए लिखा गया है - शुरुआती और मध्य किसान, एक ही संगीत प्रेमी और कलेक्टर।
ऑडियो की दुनिया के साथ-साथ मिलिटेंट यूडीफिल्स के गुरुम, क्वॉड्स, सेंसी और अन्य महान हेल्मेन यहां रुचि नहीं लेंगे। अपना लेख "लाठी और कोडेक्स के साथ लिखें।"
रोचक जानकारी:
वर्तमान में, 1154 फाइल एक्सटेंशन एक ही तरीके से पंजीकृत हैं या किसी अन्य ऑडियो डेटा के साथ जुड़ा हुआ है!
सूत्रों का कहना है:
wiki.hydrogenaudio.org/
ru.wikipedia.org/
साथ ही आधिकारिक कार्यक्रम साइटें।
शुभ दिन।
आज मैं दोषरहित डेटा संपीड़न के विषय पर स्पर्श करना चाहता हूं। इस तथ्य के बावजूद कि हब पर पहले से ही कुछ एल्गोरिदम के लिए समर्पित लेख थे, मैं इस बारे में थोड़ा और विस्तार से बात करना चाहता था।
मैं गणितीय विवरण और विवरण दोनों को सामान्य तरीके से देने की कोशिश करूंगा, ताकि हर कोई अपने लिए कुछ दिलचस्प पा सके।
इस लेख में मैं संपीड़न के मूल क्षणों और मुख्य प्रकार के एल्गोरिदम पर स्पर्श करूंगा।
संपीड़न। क्या आजकल इसकी जरूरत है?
हां, बिल्कुल। बेशक, हम सभी समझते हैं कि अब हम बड़ी मात्रा में स्टोरेज मीडिया और हाई-स्पीड डेटा ट्रांसमिशन चैनल दोनों का उपयोग कर सकते हैं। हालांकि, एक ही समय में, संचरित जानकारी के वॉल्यूम बढ़ रहे हैं। अगर कुछ साल पहले हम 700-मेगाबाइट फिल्में देखते थे जो एक डिस्क पर फिट होती हैं, तो आज एचडी-गुणवत्ता वाली फिल्में दसियों गीगाबाइट्स पर कब्जा कर सकती हैं।
बेशक, सब कुछ और सब कुछ को संपीड़ित करने के लाभ इतने अधिक नहीं हैं। लेकिन अभी भी ऐसी परिस्थितियां हैं जिनमें संपीड़न अत्यंत उपयोगी है, यदि आवश्यक नहीं है।
- ईमेल दस्तावेज़ (विशेषकर मोबाइल उपकरणों का उपयोग करने वाले दस्तावेज़ों की बड़ी मात्रा)
- वेबसाइटों पर दस्तावेज़ प्रकाशित करते समय, ट्रैफ़िक को बचाने की आवश्यकता है
- स्टोरेज को बदलते या जोड़ते समय डिस्क स्थान सहेजें। उदाहरण के लिए, यह उन मामलों में होता है जहां पूंजी व्यय के लिए बजट प्राप्त करना आसान नहीं होता है, और पर्याप्त डिस्क स्थान नहीं होता है।
बेशक, आप कई अलग-अलग स्थितियों के साथ आ सकते हैं जिनमें संपीड़न उपयोगी होगा, लेकिन ये कुछ उदाहरण हमारे लिए पर्याप्त हैं।
सभी संपीड़न विधियों को दो बड़े समूहों में विभाजित किया जा सकता है: हानिपूर्ण संपीड़न और दोषरहित संपीड़न। दोषरहित संपीड़न का उपयोग उन मामलों में किया जाता है जहां जानकारी को बिट्स के लिए सटीक रूप से बहाल करने की आवश्यकता होती है। संपीड़ित करते समय यह दृष्टिकोण केवल एक ही संभव है, उदाहरण के लिए, पाठ डेटा।
कुछ मामलों में, हालांकि, सटीक जानकारी पुनर्प्राप्ति की आवश्यकता नहीं होती है और इसे एल्गोरिदम का उपयोग करने की अनुमति होती है जो हानिरहित संपीड़न को लागू करते हैं, जो दोषरहित संपीड़न के विपरीत, आमतौर पर लागू करना आसान होता है और उच्च स्तर की संग्रह प्रदान करता है।
तो, चलो दोषरहित संपीड़न एल्गोरिदम पर चलते हैं।
सार्वभौमिक दोषरहित संपीड़न विधियाँ
सामान्य मामले में, तीन बुनियादी विकल्प हैं जिन पर संपीड़न एल्गोरिदम का निर्माण किया जाता है।
पहला समूह तरीके - धारा रूपांतरण। यह पहले से ही संसाधित के माध्यम से नए आने वाले असम्पीडित डेटा का विवरण देता है। इस मामले में, किसी भी संभाव्यता की गणना नहीं की जाती है, चरित्र एन्कोडिंग केवल उस डेटा के आधार पर किया जाता है जिसे पहले से ही संसाधित किया गया है, जैसे कि एलजेड विधियों (अब्राहम लेम्पेल और जैकब जिवा के नाम पर)। इस मामले में, एनकोडर को पहले से ज्ञात एक सबस्ट्रिंग की दूसरी और आगे की घटनाओं को इसकी पहली घटना के संदर्भों से बदल दिया जाता है।
दूसरा समूह विधियाँ सांख्यिकीय संपीड़न विधियाँ हैं। बदले में, इन विधियों को अनुकूली (या प्रवाह), और ब्लॉक में विभाजित किया गया है।
पहले (अनुकूली) संस्करण में, नए डेटा के लिए संभावनाओं की गणना एन्कोडिंग के दौरान पहले से संसाधित किए गए डेटा पर आधारित है। इन विधियों में हफ़मैन और शैनन-फ़ानो एल्गोरिदम के अनुकूली संस्करण शामिल हैं।
दूसरे (ब्लॉक) मामले में, प्रत्येक डेटा ब्लॉक के आंकड़ों को अलग-अलग गणना की जाती है, और सबसे संकुचित ब्लॉक में जोड़ा जाता है। इनमें हफ़मैन, शैनन-फ़ानो, और अंकगणित कोडिंग विधियों के स्थिर संस्करण शामिल हैं।
तीसरा समूह विधियाँ तथाकथित ब्लॉक रूपांतरण विधियाँ हैं। आने वाले डेटा को ब्लॉक में विभाजित किया जाता है, जो तब संपूर्ण रूप में बदल जाते हैं। हालांकि, कुछ विधियां, विशेष रूप से ब्लॉकों के क्रमांकन के आधार पर, डेटा की मात्रा में महत्वपूर्ण (या कोई भी) कमी नहीं ला सकती है। हालांकि, इस तरह के प्रसंस्करण के बाद, डेटा संरचना में काफी सुधार होता है, और अन्य एल्गोरिदम द्वारा बाद में संपीड़न अधिक सफल और तेज होता है।
सामान्य सिद्धांत जिस पर डेटा संपीड़न आधारित है
सभी डेटा संपीड़न विधियाँ एक सरल तार्किक सिद्धांत पर आधारित हैं। यदि हम कल्पना करते हैं कि सबसे अधिक बार होने वाले तत्व कम कोड के साथ एन्कोड किए जाते हैं, और कम बार होने वाले लोग लंबे समय तक एन्कोडेड होते हैं, तो सभी डेटा को स्टोर करने के लिए, कम जगह की आवश्यकता होती है अगर सभी तत्वों को समान लंबाई के कोड द्वारा दर्शाया गया था।
तत्व घटनाओं की आवृत्ति और इष्टतम कोड लंबाई के बीच सटीक संबंध तथाकथित शैनन के स्रोत कोडिंग प्रमेय में वर्णित है, जो दोषरहित अधिकतम संपीड़न सीमा और शैनन की एन्ट्रापी को परिभाषित करता है।
थोड़ा सा गणित
यदि किसी तत्व के i की उत्पत्ति की संभावना p (s i) के बराबर है, तो इस तत्व का प्रतिनिधित्व करने के लिए सबसे अधिक फायदेमंद होगा - 2 p (s i) बिट्स लॉग करें। यदि एन्कोडिंग के दौरान यह सुनिश्चित करना संभव है कि सभी तत्वों की लंबाई 2 पी (एस आई) बिट्स लॉग करने के लिए कम हो जाती है, तो पूरे एन्कोडेड अनुक्रम की लंबाई सभी संभव एन्कोडिंग विधियों के लिए न्यूनतम होगी। इसके अलावा, यदि सभी तत्वों F \u003d (p (s i)) की संभाव्यता वितरण अपरिवर्तित है, और तत्वों की संभाव्यता परस्पर स्वतंत्र हैं, तो कोड की औसत लंबाई की गणना की जा सकती है
इस मान को प्रायिकता वितरण F की एन्ट्रापी या किसी निश्चित समय पर स्रोत की एन्ट्रॉपी कहा जाता है।
हालांकि, आमतौर पर एक तत्व की उपस्थिति की संभावना स्वतंत्र नहीं हो सकती है, इसके विपरीत, यह कुछ कारकों पर निर्भर करता है। इस मामले में, प्रत्येक नए एन्कोडेड एलिमेंट के लिए, प्रायिकता डिस्ट्रीब्यूशन F कुछ वैल्यू F k लेगा, यानी प्रत्येक एलिमेंट F \u003d F k और H \u003d H k के लिए।
दूसरे शब्दों में, हम कह सकते हैं कि स्रोत राज्य k में है, जो सभी तत्वों के लिए निश्चित संभावनाओं p k (s i) से मेल खाता है।
इसलिए, इस सुधार को देखते हुए, हम कोड की औसत लंबाई को व्यक्त कर सकते हैं
जहां पी के राज्य में स्रोत को खोजने की संभावना है।
इसलिए, इस स्तर पर, हम जानते हैं कि संपीड़न छोटे कोड के साथ अक्सर होने वाले तत्वों की जगह पर आधारित है, और इसके विपरीत, और हम यह भी जानते हैं कि कोड की औसत लंबाई कैसे निर्धारित करें। लेकिन कोड, कोडिंग क्या है और यह कैसे होता है?
मेमोरीलेस एनकोडिंग
मेमोरी के बिना कोड सबसे सरल कोड हैं जिनके आधार पर डेटा को संपीड़ित किया जा सकता है। मेमोरीलेस कोड में, एन्कोडेड डेटा वेक्टर में प्रत्येक वर्ण को बाइनरी अनुक्रमों या शब्दों के उपसर्ग सेट से कोडवर्ड के साथ बदल दिया जाता है।
मेरी राय में, सबसे स्पष्ट परिभाषा नहीं। इस विषय पर अधिक विस्तार से विचार करें।
कुछ अक्षर बताए जाएं ![]() कुछ (परिमित) अक्षरों से मिलकर। हम इस वर्णमाला के वर्णों के प्रत्येक परिमित अनुक्रम को कहते हैं (A \u003d a 1, a 2, ..., a) एक शब्द में, और संख्या n इस शब्द की लंबाई है।
कुछ (परिमित) अक्षरों से मिलकर। हम इस वर्णमाला के वर्णों के प्रत्येक परिमित अनुक्रम को कहते हैं (A \u003d a 1, a 2, ..., a) एक शब्द में, और संख्या n इस शब्द की लंबाई है।
एक अन्य वर्णमाला भी बताइए ![]() । इसी तरह, इस वर्णमाला के शब्द को B के रूप में निरूपित करें।
। इसी तरह, इस वर्णमाला के शब्द को B के रूप में निरूपित करें।
हम वर्णमाला के सभी गैर-रिक्त शब्दों के सेट के लिए दो और संकेतन प्रस्तुत करते हैं। आज्ञा दें - पहले वर्णमाला में गैर-खाली शब्दों की संख्या, और - दूसरे में।
आइए एक मैपिंग F भी दें जो कि प्रत्येक शब्द A के साथ पहले वर्णमाला के दूसरे शब्द B \u003d F (A) से जुड़ा हो। तब B शब्द कहा जाएगा कोड शब्द A, और मूल शब्द से उसके कोड में परिवर्तन को कहा जाएगा कोडिंग.
चूँकि शब्द में एक अक्षर भी हो सकता है, इसलिए हम पहले वर्णमाला के अक्षरों के पत्राचार और दूसरे से संबंधित शब्दों की पहचान कर सकते हैं:
एक १<-> बी १
एक २<-> बी २
…
a n<-> बी एन
इस मैच को कहा जाता है योजना, और निरूपित करें ∑।
इस स्थिति में, बी 1, बी 2, ..., बी एन शब्दों को कहा जाता है प्राथमिक कोड, और उनकी मदद से कोडिंग का प्रकार - वर्णमाला कोडिंग। बेशक, हम में से अधिकांश इस तरह के कोडिंग के साथ आए हैं, भले ही हम उन सभी को नहीं जानते हैं जो मैंने ऊपर वर्णित किया था।
इसलिए, हमने अवधारणाओं पर फैसला किया वर्णमाला, शब्द, कोड, और कोडिंग। अब हम अवधारणा पेश करते हैं उपसर्ग.
B शब्द को B \u003d B "B" का रूप दें। तब B को शुरुआत कहा जाता है, या उपसर्ग शब्द बी, और बी "" - इसका अंत। यह एक काफी सरल परिभाषा है, लेकिन यह ध्यान दिया जाना चाहिए कि किसी भी शब्द बी के लिए, एक निश्चित शब्द ʌ ("स्थान") और बी शब्द ही दोनों शुरुआत और अंत माना जा सकता है।
तो, हम मेमोरी के बिना कोड की परिभाषा को समझने के करीब आते हैं। अंतिम परिभाषा जिसे हमें समझने की जरूरत है वह उपसर्ग सेट है। एक योजना for में एक उपसर्ग की संपत्ति होती है यदि, किसी भी 1≤i, jr, i, j के लिए, B शब्द I, B शब्द का उपसर्ग नहीं है।
सीधे शब्दों में कहें, एक उपसर्ग सेट एक परिमित सेट है जिसमें कोई तत्व किसी अन्य तत्व का उपसर्ग (या शुरुआत) नहीं है। इस तरह के एक सेट का एक सरल उदाहरण है, उदाहरण के लिए, नियमित वर्णमाला।
इसलिए, हमने आधारभूत परिभाषाएं निकालीं। तो मेमोरीलेस कोडिंग कैसे होती है?
यह तीन चरणों में होता है।
- मूल संदेश के वर्णों का एक वर्णमाला Ψ संकलित किया जाता है, और वर्णमाला के पात्रों को संदेश में उनके होने की संभावना के अवरोही क्रम में क्रमबद्ध किया जाता है।
- प्रत्येक प्रतीक i, वर्णमाला से Ψ उपसर्ग सेट Ω से एक निश्चित शब्द B i से जुड़ा हुआ है।
- प्रत्येक वर्ण को कूटबद्ध किया जाता है, जिसके बाद कोडों को एक एकल डेटा स्ट्रीम में संयोजित किया जाता है, जो संपीड़न का परिणाम होगा।
इस विधि का वर्णन करने वाले विहित एल्गोरिदम में से एक हफ़मैन एल्गोरिथम है।
हफ़मैन एल्गोरिदम
हफमैन एल्गोरिथ्म इनपुट डेटा ब्लॉक में एक ही बाइट्स की घटना की आवृत्ति का उपयोग करता है, और छोटी लंबाई के बिट्स की एक श्रृंखला के लगातार ब्लॉक से मेल खाता है, और इसके विपरीत। यह कोड न्यूनतम बेमानी है। मामले पर विचार करें, जब इनपुट स्ट्रीम की परवाह किए बिना, आउटपुट स्ट्रीम की वर्णमाला में केवल 2 वर्ण होते हैं - शून्य और एक।
सबसे पहले, हफ़मैन एल्गोरिथ्म के साथ कोडिंग करते समय, हमें सर्किट cod के निर्माण की आवश्यकता होती है। यह निम्नानुसार किया जाता है:
- इनपुट वर्णमाला के सभी अक्षरों को संभाव्यता के अवरोही क्रम में क्रमबद्ध किया जाता है। आउटपुट स्ट्रीम की वर्णमाला के सभी शब्द (जो हम एनकोड करेंगे) को शुरू में खाली माना जाता है (मुझे याद है कि आउटपुट स्ट्रीम की वर्णमाला में केवल वर्ण (0,1) होते हैं)।
- दो वर्णों में एक j-1 और एक इनपुट स्ट्रीम, जिसमें घटना होने की संभावना सबसे कम होती है, को संभाव्यता के साथ एक "छद्म-प्रतीक" में जोड़ा जाता है। पी इसके घटक पात्रों की संभावनाओं के योग के बराबर। फिर हम B शब्द के आरंभ में B j-1, और 1 से B शब्द की शुरुआत करते हैं, जो बाद में क्रमशः a-1 और j अक्षर का कोड होगा।
- हम इन पात्रों को मूल संदेश की वर्णमाला से हटा देते हैं, लेकिन इस वर्णमाला में उत्पन्न छद्म-चिह्न को जोड़ते हैं (स्वाभाविक रूप से, इसे सही जगह पर वर्णमाला में डाला जाना चाहिए, इसकी संभावना को ध्यान में रखते हुए)।
चरण 2 और 3 तब तक दोहराए जाते हैं जब तक कि वर्णमाला में केवल 1 छद्म चरित्र न बचा हो, जिसमें वर्णमाला के सभी मूल वर्ण शामिल हों। इसके अलावा, प्रत्येक चरण पर और प्रत्येक वर्ण के लिए, संबंधित शब्द B i (एक या शून्य जोड़कर) बदलता है, इस प्रक्रिया के पूरा होने के बाद, एक निश्चित कोड B i वर्णमाला के प्रत्येक प्रारंभिक वर्ण i के अनुरूप होगा।
बेहतर चित्रण के लिए, एक छोटे से उदाहरण पर विचार करें।
मान लीजिए कि हमारे पास केवल चार वर्णों से युक्त एक वर्णमाला है - (1, 2, 3, 4)। यह भी मान लें कि इन प्रतीकों की घटना की संभावनाएं समान हैं, क्रमशः, पी 1 \u003d 0.5; पी 2 \u003d 0.24; पी 3 \u003d 0.15; पी 4 \u003d 0.11 (सभी संभावनाओं का योग स्पष्ट रूप से एक के बराबर है)।
इसलिए, हम इस वर्णमाला के लिए योजना का निर्माण करेंगे।
- दो अक्षरों को कम से कम संभावनाओं (0.11 और 0.15) के साथ p "छद्म चरित्र" में मिलाएं।
- हम दो वर्णों को कम से कम प्रायिकता (0.24 और 0.26) के साथ p छद्म वर्ण में संयोजित करते हैं।
- हम संयुक्त वर्णों को हटाते हैं, और परिणामस्वरूप छद्म वर्ण को वर्णमाला में सम्मिलित करते हैं।
- अंत में, शेष दो पात्रों को मिलाएं और पेड़ की चोटी प्राप्त करें।
यदि आप इस प्रक्रिया का वर्णन करते हैं, तो आपको निम्न जैसा कुछ मिलेगा:
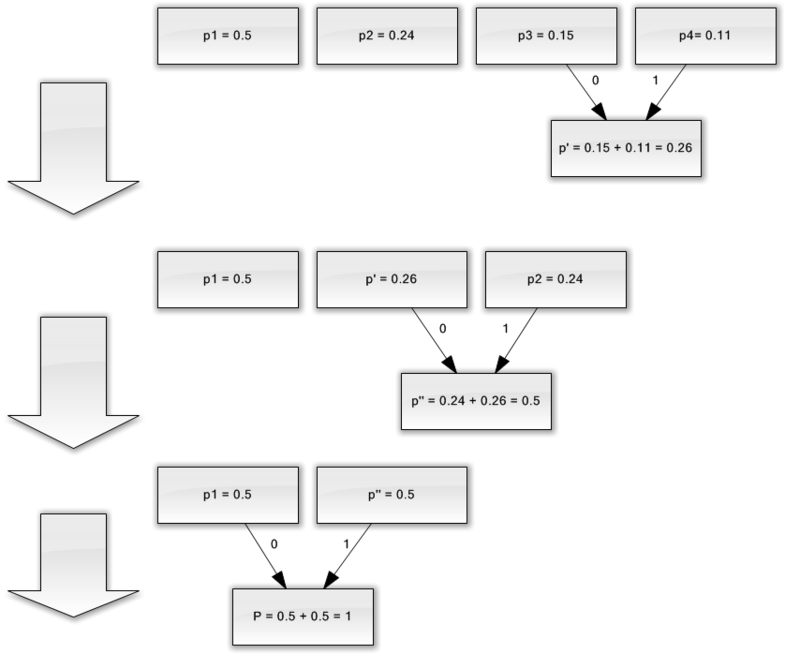
जैसा कि आप देख सकते हैं, प्रत्येक मर्ज के साथ, हम वर्णों को मर्ज किए जाने वाले वर्णों को 0 और 1 असाइन करते हैं।
इस प्रकार, जब पेड़ बनाया जाता है, तो हम आसानी से प्रत्येक वर्ण के लिए कोड प्राप्त कर सकते हैं। हमारे मामले में, कोड इस तरह दिखाई देंगे:
एक १ \u003d ०
एक 2 \u003d 11
एक 3 \u003d 100
एक 4 \u003d 101
चूंकि इनमें से कोई भी कोड किसी अन्य का उपसर्ग नहीं है (अर्थात, हमें कुख्यात उपसर्ग सेट मिला है), हम उत्पादन कोड में प्रत्येक कोड को विशिष्ट रूप से पहचान सकते हैं।
इसलिए, हमने पाया है कि सबसे अक्सर चरित्र सबसे छोटे कोड द्वारा एन्कोड किया गया है, और इसके विपरीत।
यदि हम मानते हैं कि शुरू में, प्रत्येक चरित्र को संग्रहीत करने के लिए एक बाइट का उपयोग किया गया था, तो हम गणना कर सकते हैं कि हम डेटा को कम करने में कितना सक्षम थे।
मान लीजिए कि हमारे पास इनपुट में 1000 वर्णों की एक स्ट्रिंग है, जिसमें चरित्र 1 1 बार 500 बार, 2 - 240, 3 - 150, और 4 - 110 बार हुआ।
प्रारंभ में, इस स्ट्रिंग ने 8000 बिट्स पर कब्जा कर लिया। कोडिंग के बाद, हमें lp i l i \u003d 500 * 1 + 240 * 2 + 150 * 3 + 110 * 3 \u003d 1760 बिट्स की लंबाई के साथ एक स्ट्रिंग मिलती है। इसलिए, हम प्रत्येक स्ट्रीम प्रतीक के एन्कोडिंग पर औसतन 1.76 बिट्स खर्च करते हुए, डेटा को 4.54 बार सेक करने में सक्षम थे।
आपको याद दिला दूं कि शैनन के अनुसार, कोड की औसत लंबाई है ![]() । इस समीकरण में हमारे संभाव्यता मानों को प्रतिस्थापित करते हुए, हम औसत कोड की लंबाई 1.75496602732291 के बराबर प्राप्त करते हैं, जो कि हमारे द्वारा प्राप्त किए गए परिणाम के बहुत करीब है।
। इस समीकरण में हमारे संभाव्यता मानों को प्रतिस्थापित करते हुए, हम औसत कोड की लंबाई 1.75496602732291 के बराबर प्राप्त करते हैं, जो कि हमारे द्वारा प्राप्त किए गए परिणाम के बहुत करीब है।
फिर भी, यह ध्यान में रखा जाना चाहिए कि डेटा के अलावा, हमें एन्कोडिंग तालिका को संग्रहीत करने की आवश्यकता है, जो एन्कोडेड डेटा के अंतिम आकार को थोड़ा बढ़ा देगा। जाहिर है, अलग-अलग मामलों में एल्गोरिथ्म के विभिन्न रूपों का उपयोग किया जा सकता है - उदाहरण के लिए, पूर्वनिर्धारित संभाव्यता तालिका का उपयोग करने के लिए कभी-कभी यह अधिक कुशल होता है, और कभी-कभी इसे संकुचित डेटा के माध्यम से गतिशील रूप से संकलित करना आवश्यक होता है।
निष्कर्ष
इसलिए, इस लेख में मैंने उन सामान्य सिद्धांतों के बारे में बात करने की कोशिश की जिनके द्वारा दोषरहित संपीड़न होता है, और एक कैनोनिकल एल्गोरिदम - हफ़मैन कोडिंग की भी जांच की।
यदि लेख हाबोर-समुदाय के स्वाद के लिए है, तो मुझे अगली कड़ी लिखने में खुशी होगी, क्योंकि दोषरहित संपीड़न के बारे में कई और दिलचस्प बातें हैं; ये दोनों शास्त्रीय एल्गोरिदम और प्रारंभिक डेटा रूपांतरण हैं (उदाहरण के लिए, बरोज़-व्हीलर ट्रांसफ़ॉर्म), और, निश्चित रूप से, ध्वनि, वीडियो और छवियों को संपीड़ित करने के लिए विशिष्ट एल्गोरिदम (सबसे दिलचस्प विषय, मेरी राय में)।
साहित्य
- वैटोलिन डी।, रतुश्नायक ए।, स्मिरनोव एम। युकिन वी। डेटा संपीड़न के तरीके। डिवाइस अभिलेखागार, छवि और वीडियो संपीड़न; आईएसबीएन 5-86404-170-एक्स; 2003 वर्ष
- डी। सलोमन। डेटा, छवि और ध्वनि का संपीड़न; आईएसबीएन 5-94836-027-एक्स; 2004।
नुकसान के बिना ध्वनि सेक करने वाले कोडेक्स पोर्टेबल एमपी 3 खिलाड़ियों की दुनिया में अपेक्षाकृत लोकप्रिय हो गए हैं। तथ्य यह है कि ये कोडेक्स ऐसे विशाल संपीड़न अनुपात को वहन नहीं कर सकते हैं जो कि गुणवत्ता के नुकसान के साथ ध्वनि को संकुचित करने वाले कोडक घमंड कर सकते हैं। एमपी 3 खिलाड़ियों के उपयोगकर्ताओं के लिए बड़ी मात्रा में स्मृति केवल पिछले तीन या चार वर्षों में व्यापक रूप से उपलब्ध हो गई - और एमपी 3 खिलाड़ियों में मेमोरी की बड़ी मात्रा के आगमन के साथ, दोषरहित संगीत संपीड़न लोकप्रिय हो गया है। बेशक, जो गुणवत्ता के नुकसान के बिना संगीत सुनना चाहते थे, उन्होंने हमेशा ऐसा किया (उदाहरण के लिए, ऑडियो सीडी-खिलाड़ियों का उपयोग करके), और आजकल हर कोई (स्वाभाविक रूप से, अपने खिलाड़ियों द्वारा संबंधित कोडेक्स के समर्थन के साथ) कार्रवाई में हानिरहित-कोडेक्स की कोशिश कर सकता है ।
कोडेक्स के बीच मुख्य अंतर यह है कि ऑडियो डेटा को कोडेक्स से गुणवत्ता के नुकसान के बिना संपीड़ित करता है जो नुकसान के साथ संपीडित होता है गुणवत्ता के नुकसान के बिना कोडेक ऑडियो स्ट्रीम से जानकारी को नहीं हटाते हैं जो नुकसान के साथ संकुचित होने पर अनावश्यक माना जा सकता है। दोषरहित कोडक का मुख्य कार्य मूल ध्वनि जानकारी को संपीड़ित करना है, बिना किसी सूचना को खोए।
लॉसलेस कोडेक्स के समर्थन के साथ स्थिति वर्तमान में ऐसी है कि सबसे व्यापक समर्थन एएलएसी कोडेक है, जो सीधे ऐप्पल और उसके खिलाड़ियों से संबंधित है। बाकी कोडेक्स अभी भी कुछ खिलाड़ियों द्वारा समर्थित हैं, कभी-कभी खिलाड़ी को कोडेक का समर्थन करने के लिए, खिलाड़ी को खिलाड़ी को चमकाने की आवश्यकता होती है, और शायद हानिरहित कोडेक का समर्थन करने वाले खिलाड़ियों के लिए सबसे प्रसिद्ध फर्मवेयर, रॉकबॉक्स एक विकल्प है, और आधिकारिक नहीं, फर्मवेयर।
दोषरहित कोडेक्स के साथ काम करते समय, आप तथाकथित क्यू फाइलें या फ़ाइल इंडेक्स कार्ड देख सकते हैं। क्यू-फाइलें वितरित की जाती हैं, उदाहरण के लिए, एफएलएसी या एपीई-फाइलों के साथ, कम अक्सर - एमपी 3 और डब्ल्यूएवी-फाइलों के साथ, जो एक बड़ी (लगभग 300 एमबी) फ़ाइल होती है जिसमें पूरा एल्बम संग्रहीत होता है। क्यू - फ़ाइल - इसमें एक बड़ी फ़ाइल को पटरियों में विभाजित करने और इन पटरियों के नाम के बारे में जानकारी है। यह व्यक्तिगत फ़ाइलों के साथ काम करने के लिए अधिक सुविधाजनक है, हालांकि, भले ही आप अपने हाथों में आते हैं, कहते हैं, CUE फ़ाइल के साथ एक बड़ी FLAC फ़ाइल, CUE फ़ाइल में निहित जानकारी के आधार पर, स्रोत फ़ाइल को अलग-अलग पटरियों में विभाजित किया जा सकता है - हम सॉफ्टवेयर पर विचार करेंगे इस समस्या को हल कर सकते हैं।
आइए लोकप्रिय FLAC प्रारूप के साथ दोषरहित डेटा संपीड़न स्वरूपों का वर्णन शुरू करें।
FLAC
FLAC (फ्री दोषरहित ऑडियो कोडेक) Xiph द्वारा विकसित एक दोषरहित ऑडियो संपीड़न प्रारूप है। संगठन फाउंडेशन। यह एक बिल्कुल मुफ्त प्रारूप है जिसका उपयोग हर कोई कर सकता है।
एफएलएसी और अन्य कोडेक्स का संचालन जो दोषरहित ऑडियो डेटा को संग्रहीत करता है, पारंपरिक आर्काइव के समान है। हालांकि, विशेष एल्गोरिदम के कारण, ऑडियो जानकारी को संपीड़ित करने में ऐसे कोडेक्स की दक्षता पारंपरिक अभिलेखागार की तुलना में बहुत अधिक है।
FLAC प्रारूप को एक स्ट्रीम प्रारूप के रूप में विकसित किया गया था - FLAC फ़ाइल में जानकारी को फ़्रेम (फ़्रेम) में विभाजित किया गया है, जिनमें से प्रत्येक को अन्य फ़्रेमों से अलग से डिकोड किया जा सकता है।
आमतौर पर, FLAC स्रोत फ़ाइल को संपीड़ित करने में सक्षम है, उदाहरण के लिए, ऑडियो सीडी गुणवत्ता 40-50%। नतीजतन, परिणामी रिकॉर्ड की बिटरेट लगभग 800 Kbit / s के बराबर है।
एफएलएसी प्रारूप में, सीडी को इस तरह से सहेजना संभव है कि यदि आवश्यक हो तो आप मूल डिस्क को पूरी तरह से फिर से बना सकते हैं - यह उन लोगों के लिए बहुत सुविधाजनक है जो बाद की वसूली की संभावना के साथ अपनी सीडी की डिजिटल प्रतियां बनाना चाहते हैं।
FLAC फ़ाइलों की एन्कोडिंग और डिकोडिंग गति समान नहीं है। एन्कोडिंग की गति संपीड़न स्तर पर और सिस्टम की गति पर निर्भर करती है - संपीड़न के उच्च स्तर पर, यह काफी धीमा हो सकता है। हालांकि, डिकोडिंग बहुत तेज है - आधुनिक एमपी 3 प्लेयर आसानी से इसका सामना कर सकते हैं।
मुफ्त मुफ्त उपयोग की संभावना के कारण, FLAC के साथ आप लगभग किसी भी आधुनिक ओएस के आधार पर काम कर सकते हैं, अधिक से अधिक एमपी 3 प्लेयर इस प्रारूप का समर्थन करते हैं।
FLAC प्रारूप में एन्कोडिंग
आप FLAC फ़ाइलों को एन्कोडिंग के लिए उपयोगिता डाउनलोड कर सकते हैं। इसमें स्वयं कोडेक और तथाकथित फ्रंटेंड शामिल हैं - कोडेक के लिए एक सॉफ्टवेयर शेल। वितरण का आकार लगभग 2.5 एमबी है। कोडेक के साथ काम करना सरल है: आप प्रोग्राम विंडो (छवि। 4.1) में रुचि की फ़ाइलों को जोड़ते हैं, फ़ाइलें जोड़ें बटन का उपयोग करके एन्कोडिंग विकल्पों को कॉन्फ़िगर करें और एनकोड बटन पर क्लिक करें - प्रोग्राम एक FLAC फ़ाइल बनाता है।
अंजीर। 4.1।
आइए सबसे महत्वपूर्ण कोडेक सेटिंग्स को देखें। सबसे पहले, आइए मापदंडों के एन्कोडिंग विकल्प समूह पर ध्यान दें।
स्तर पैरामीटर डेटा संपीड़न के स्तर के लिए जिम्मेदार है। यह 0 से 8 तक भिन्न हो सकता है। उच्चतर संपीड़न स्तर, तदनुसार, छोटी फ़ाइल समाप्त हो जाती है, लेकिन फ़ाइलों को एन्कोड करने के लिए आवश्यक लंबा समय। तेज कंप्यूटर पर, एन्कोडिंग के स्तर 0 और स्तर 8 के बीच का अंतर, कहते हैं, 30-मेगाबाइट WAV फ़ाइल कई सेकंड हो सकती है। आकार मूल फ़ाइल आकार से लगभग 10% भिन्न होता है। आपको अपने पीसी पर इस विकल्प के साथ प्रयोग करना चाहिए - शायद अगर आप कई सौ फ़ाइलों को एन्कोड करते हैं, तो आप काम की उच्च गति पर कम संपीड़न स्तर पसंद करेंगे।
सत्यापन पैरामीटर आउटपुट फाइल की जांच करने के लिए एनकोडर को निर्देश देता है।
टैग टैग पैरामीटर समाप्त फ़ाइल में टैग जोड़ता है (उदाहरण के लिए, उनमें गीत, लेखक, आदि का नाम हो सकता है) - आप टैग कॉन्फ बटन पर क्लिक करके उन्हें कॉन्फ़िगर कर सकते हैं। (टैग अनुकूलन)।
रिप्लेगैन पैरामीटर फ़ाइल के वॉल्यूम स्तर को इंगित करने वाली फ़ाइलों के लिए एक पैरामीटर जोड़ता है। यदि पैरामीटर "इनपुट इनपुट फ़ाइलों को एक एल्बम" के रूप में सेट किया गया है, तो एल्बम में सभी प्रविष्टियां एक ही वॉल्यूम पर ध्वनि करेंगी।
सामान्य विकल्प पैरामीटर समूह में दो पैरामीटर होते हैं। शायद, ओजीजी-फ्लैक पैरामीटर को यहां नोट किया जाना चाहिए। यदि यह पैरामीटर रीसेट है, तो FLAC डेटा मानक FLAC कंटेनर में पैक किया जाता है। यदि आप केवल प्राप्त FLAC फ़ाइलों को सुनने की योजना बनाते हैं, तो आप इस पैरामीटर को सेट नहीं कर सकते हैं, और यदि इन फ़ाइलों के लिए आपकी योजनाएँ अधिक व्यापक हैं - उदाहरण के लिए, आप उन्हें संपादित करने की योजना बनाते हैं, उन्हें फ़िल्मों में सम्मिलित करने के लिए उपयोग करते हैं, तो Ogg-FLAC पैरामीटर को सक्षम करना सबसे अच्छा है।
आउटपुट डायरेक्टरी पैरामीटर में डायरेक्टरी का पथ होता है जहाँ आउटपुट फाइल समाहित होगी।
Decoding विकल्प पैरामीटर समूह में Dec. पैरामीटर होता है। त्रुटियों के माध्यम से - यदि आप डिकोडिंग के दौरान त्रुटियां हैं तो भी फाइल को डीकोड करना चाहते हैं तो इसे सेट करें। डिकोडिंग एन्कोडिंग का उल्टा है - अर्थात, आप FLAC फ़ाइलों को WAV फ़ाइलों में बदलकर डिकोड कर सकते हैं। डिकोडिंग के लिए, निश्चित रूप से, आपको प्रोग्राम विंडो में FLAC फ़ाइलों को जोड़ना होगा।
सब कुछ कॉन्फ़िगर होने के बाद, बस FLAC फाइलें बनाने के लिए Encode बटन पर क्लिक करें, या यदि आप मौजूदा FLAC फाइलों को डीकोड करना चाहते हैं, तो Decode बटन पर क्लिक करें।
उपरोक्त के अतिरिक्त, अन्य प्रोग्राम FLAC को एन्कोड कर सकते हैं। उदाहरण के लिए, यह आपको पहले से ही ज्ञात है ImTOO ऑडियो एनकोडर - FLAC प्रारूप में एन्कोडिंग के लिए, बस इसे स्वरूपों की सूची (छवि 4.2) से चुनें, जिसके बाद आप तुरंत कट बटन पर क्लिक कर सकते हैं या इसे थोड़ा बाद में कर सकते हैं, फ़ाइल नाम सेट करने के बाद।

