24.07.2019
Кодиране на текстова информация. Защо бинарното кодиране е универсално? Методи за програмиране
Да видим как всички еднакви дигитализиране на текстове? Между другото, на нашия сайт можете да превеждате всеки текст в десетичен, шестнадесетичен, двоичен код Използване на онлайн калкулатор на код.
Кодиране на текст
Според компютърната теория всеки текст се състои от отделни знаци. Тези знаци включват: букви, цифри, малки препинателни знаци, специални знаци ("", №, () и т.н.), те също включват интервали между думите.
Необходими знания. Наборът от знаци, с които записвам текста, се нарича ALFAVIT.
Броят на знаците, взети в азбуката, представлява неговата сила.
Количеството информация може да се определи по формулата: N \u003d 2b
- N е същата сила (много знаци),
- b - бит (тегло на взетия знак).
Азбуката, в която ще има 256, може да побере почти всички необходими знаци. Такива азбуки се наричат \u200b\u200bСЪЩНОСТ.
Ако вземем азбуката с капацитет 256 и имайте предвид, че 256 \u003d 28
- 8 бита винаги се наричат \u200b\u200b1 байт:
- 1 байт \u003d 8 бита.
Ако преведете всеки символ в двоичен код, този код на компютърен текст ще заеме 1 байт.
Как може да изглежда текстова информация в компютърната памет?
Всеки текст е въведен на клавиатурата, на клавишите на клавиатурата, виждаме знаци, познати ни (цифри, букви и т.н.). Те въвеждат оперативната памет на компютъра само като двоичен код. Двоичният код на всеки символ изглежда като осемцифрено число, например 00111111.
Тъй като байтът е най-малката адресируема частица от паметта и паметта е адресирана до всеки символ поотделно, удобството на такова кодиране е очевидно. 256 знака обаче са много удобна сума за всяка информация за символи.
Естествено, възникна въпросът: Кое конкретно осем битов код принадлежи на всеки герой? И как да преведем текст в цифров код?
Този процес е условен и имаме право да измисляме различни методи за кодиране на символи, Всеки символ на азбуката има число от 0 до 255. И на всяко число е присвоен код от 00000000 до 11111111.
Таблицата за кодирането е „мамян лист“, който указва символите на азбуката в съответствие със серийния номер. За различни видове компютри използвайте различни таблици за кодиране.
ASCII (или Asuka) се превърна в международен стандарт за персонални компютри. Масата има две части.
Първото полувреме за таблицата на ASCII. (Това беше първото полувреме, което стана стандарт.)
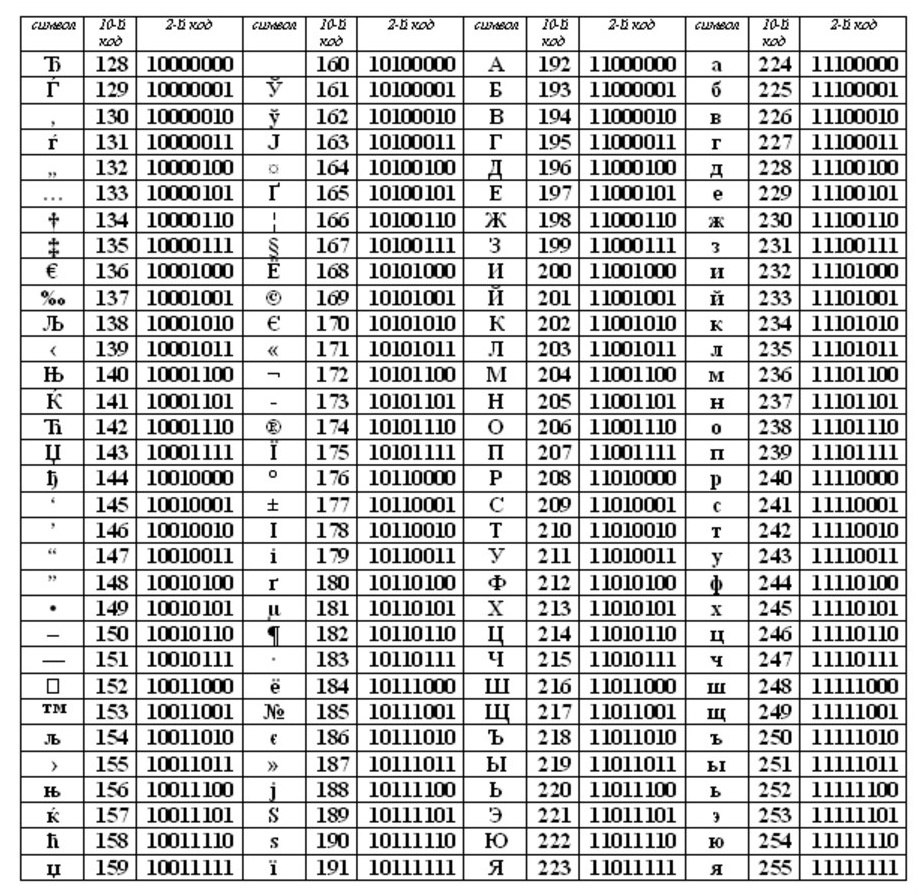
Съответствие с лексикографския ред, тоест в таблицата буквите (малки и големи букви) са посочени в строг азбучен ред, а числата във възходящ ред се наричат \u200b\u200bпринцип на последователно кодиране на азбуката.
За руската азбука също спазвайте принцип на последователно кодиране.
В днешно време те използват цяло пет кодиращи системи Руска азбука (KOI8-P, Windows. MS-DOS, Macintosh и ISO). Поради броя на кодиращите системи и липсата на един стандарт, много често възникват недоразумения с прехвърлянето на руски текст в неговата компютърна форма.
Един от първите стандарти за кодиране на руската азбукаа на личните компютри помислете за KOI8 („Код за обмен на информация, 8-битов“). Това кодиране се използва в средата на седемдесетте на поредица от компютри от ЕС, а от средата на осемдесетте години започва да се използва в първите операционни системи UNIX, преведени на руски език.
От началото на деветдесетте години, така нареченото време, когато операционната система MS DOS доминира, се появява кодиращата система CP866 („CP“ означава „Code Page“, „code page“).
Компютърният гигант APPLE, с иновативната си система под техен контрол (Mac OS), започва да използва собствена система за кодиране на MAC азбуката.
Международната организация за стандартизация (ISO) определя друг стандарт за руския език азбучна система за кодираненаречен ISO 8859-5.
И най-разпространената днес система за кодиране на азбуката, изобретена в Microsoft Windows и се нарича CP1251.
От втората половина на деветдесетте години беше решен проблемът със стандарта за превод на текст в цифров код за руския език, а не само чрез въвеждане на система, наречена Unicode. Тя е представена от шестнадесет битово кодиране, което означава, че точно два байта RAM са разпределени за всеки символ. Разбира се, при това кодиране разходите за памет се удвояват. Такава кодова система обаче позволява да се превежда до 65536 символа в електронен код.
Спецификата на стандартната система Unicode е включването на абсолютно всяка азбука, независимо дали тя съществува, изчезнала, измислена. В крайна сметка абсолютно всяка азбука, в допълнение към това, системата Unicode, включва много математически, химически, музикални и общи символи.
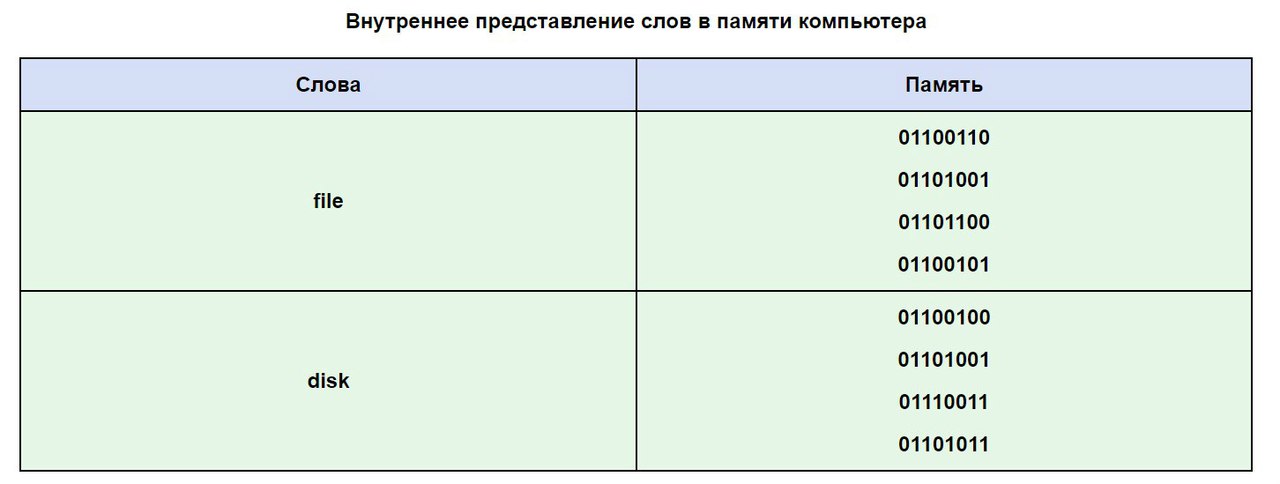
Нека използваме таблицата ASCII, за да видим как може да изглежда дума в паметта на вашия компютър.
Често се случва текстът ви, който е написан с букви от руската азбука, да не е четим, това се дължи на разликата в системите за кодиране на азбуката на компютрите. Това е много често срещан проблем, който често се открива.
Минималните единици информация са битове и байтове.
един бит ви позволява да кодирате 2 стойности (0 или 1).
използване две битове могат да бъдат кодирани 4 Стойности: 00, 01, 10, 11.
три битовете са кодирани 8 различни стойности: 000, 001, 010, 011, 100, 101, 110, 111.
От горните примери се вижда, че добавянето на един бит удвоява броя на стойностите, които могат да бъдат кодирани:
1 бит кодира -\u003e 2 различни стойности (2 1 \u003d 2),
2 бита кодират -\u003e 4 различни стойности (2 2 \u003d 4),
3 бита кодират -\u003e 8 различни стойности (2 3 \u003d 8),
4 бита кодират -\u003e 16 различни стойности (2 4 \u003d 16),
5 бита кодират -\u003e 32 различни стойности (2 5 \u003d 32),
6 бита кодират -\u003e 64 различни стойности (2 6 \u003d 64),
7 бита кодират -\u003e 128 различни стойности (2 7 \u003d 128),
8 бита кодират -\u003e 256 различни стойности (2 8 \u003d 256),
9 бита кодират -\u003e 512 различни стойности (2 9 \u003d 512),
10 бита кодират -\u003e 1024 различни стойности (2 10 \u003d 1024).
Спомняме си, че в един байт не 9 или 10 бита, а само 8. Следователно, използвайки един байт, можете да кодирате 256 различни символа. Мислите ли, че е много или малко? Нека да разгледаме пример за кодиране текстова информация.
На руски език има 33 букви и следователно за тяхното кодиране са необходими 33 байта. Компютърът прави разлика между големи (малки) и малки (малки) букви, само ако са кодирани с различни кодове. Така че, за да се кодират големи и малки букви от руската азбука, са необходими 66 байта.
За главни и малки букви на английската азбука са необходими още 52 байта. Резултатът е 66 + 52 \u003d 118 байта. Тук също трябва да добавите числа (от 0 до 9), интервал, всички препинателни знаци: точка, запетая, тире, възклицателни и въпросителни, скоби: кръгли, къдрави и квадратни, както и знаци на математическите операции: +, -, \u003d, / (това е деление), * (това е умножение). Добавяме и специални знаци:%, $, &, @, #, No. и т.н. Всичко това взето заедно е около 256 различни знака.
И тогава материята беше оставена на малките. Необходимо е да се уверите, че всички хора на Земята се споразумеят помежду си по кои конкретни кодове (от 0 до 255, т.е. общо 256), които да присвоите на символите. Да предположим, че всички хора са съгласни, че код 33 означава удивителен знак (!), А код 63 означава въпрос на знак (?). А също и за всички приложими герои. Тогава това ще означава, че текстът, въведен от един човек на неговия компютър, винаги може да бъде прочетен и отпечатан от друг човек на друг компютър.
ASCII таблица
Такова универсално споразумение за равното използване на нещо се нарича стандарт, В нашия случай стандартът трябва да е таблица, в която е фиксирана съответствието на кодове (от 0 до 255) и знаци. Подобна таблица се нарича таблица за кодиране
Но не е толкова просто. В крайна сметка героите, които са добри, например за Гърция, няма да работят за Турция, защото там се използват други букви. По същия начин това, което е добро за САЩ, не е подходящо за Русия, а това, което е добро за Русия, не е подходящо за Германия.
Затова решиха да разделят кодовата таблица наполовина.
Първите 128 кода (от 0 до 127) трябва да са стандартни и задължителни за всички страни и за всички компютри, това е - международенстандарт.
И с втората половина на таблицата с кодове (от 128 до 255) всяка държава може да направи всичко и да създаде свой стандарт в тази половина - национален.
Извиква се първата (международна) половина от таблицата с кодове масаASCII, която е създадена в САЩ и приета в цял свят. Стандартът ASCII не носи отговорност за втората половина на таблицата с кодове. Тук различни държави създават свои собствени кодови таблици. Възможно е също така, че в рамките на една държава има различни стандарти за различни компютърни системи, но само във втората половина на таблицата с кодове.
Кодове от международната таблица на ASCII
0-31 - специални символи, които не се отпечатват на екрана или на принтера, но се използват за извършване на специални действия (например за „прехвърляне на карета“ - за преместване на текст на нов ред или за „раздел“ - за задаване на курсора на специални позиции в ред текст и т.н.).
32 - интервал (разделителят между думите също е символ, който трябва да бъде кодиран, въпреки че се показва като "празно пространство" между думи и знаци),
33-47 - специални знаци (скоби и др.) И препинателни знаци (период, запетая и т.н.),
48-57 - числа от 0 до 9,
58-64 - математически символи (плюс (+), минус (-), умножение (*), разделяне (/) и т.н.) и препинателни знаци (двоеточие, запетая и т.н.),
65-90 - малки букви на английски,
91-96 - специални знаци (квадратни скоби и т.н.),
97-122 - малки (малки) английски букви,
123-127 - специални знаци (къдрави скоби и др.).
Извън таблицата на ASCII, започваща с цифрите 128 до 159, има големи букви (главни букви) руски букви, а от 160 до 170 и от 224 до 239 букви са малки (малки букви) руски букви.
Мирно кодиране на думи
Използвайки показаното кодиране, можем да си представим как компютърът кодира и след това възпроизвежда например думата MIR (с главни букви). Тази дума е представена от три кода: буквата M съответства на код 140 (според националната руска система за кодиране), и - това е код 136 и P - това е 144.
Но както беше споменато по-рано, компютърът възприема информация само в двоична форма, т.е. като последователност от нули и такива. Всеки байт, съответстващ на всяка буква от думата MIR, съдържа поредица от осем нули и единица. Използвайки правилата за преобразуване на десетичната информация в двоична, можете да замените десетичните стойности на буквените кодове с техните двоични колеги.
Десетичната цифра 140 съответства на двоичното число 10001100. Това може да се провери, ако се направят следните изчисления: 2 7 + 2 3 +2 2 \u003d 140. Степента, до която се повдигат всеки „двама“, е позиционният номер на двоичното число 10001100, в което има „1 », А позициите са номерирани от дясно на ляво, започвайки от номера на нулевата позиция: 0, 1, 2 и т.н.
Можете да научите повече за прехвърлянето на номера от една система с номера към друга, например от учебниците по компютърни науки или чрез интернет.
По същия начин можете да проверите дали цифрата 136 съответства на двоичното число 10001000 (проверете: 2 7 + 2 3 \u003d 136). И числото 144 съответства на двоичното число 10010000 (проверете: 2 7 + 2 4 \u003d 144).
Така в компютъра думата MIR ще се съхранява под формата на следната последователност от нули и единици (битове): 10001100 10001000 10010000.
Разбира се, всички трансформации на данни, показани по-горе, се извършват с помощта на компютърни програми и те не са видими за потребителите. Те наблюдават само резултатите от тези програми, както при въвеждане на информация с помощта на клавиатурата, така и когато тя се показва на екрана на монитора или на принтер.
Трябва да се отбележи, че на нивото на изучаване на компютърната грамотност компютърните потребители не е необходимо да познават двоичната система с числа. Достатъчно е да имате представа за кодовете с десетични знаци. Само системните програмисти на практика използват двоични, шестнадесетични, осмични и други системи с числа. Това е особено важно за тях, когато компютрите показват съобщения за грешки в софтуер, които показват грешни стойности без преобразуване в десетични.
Упражнения за компютърна грамотносткоито ви позволяват да видите и почувствате описаните системи за кодиране са дадени в статията
Послепис Статията свърши, но все още можете да прочетете:
P.P.S.че абонирайте се за получаване на нови статиикоито все още не са в блога:
1) Въведете своя имейл адрес в тази форма.
Кодиране на двоичен текст
От края на 60-те компютрите започват да се използват все повече и повече за обработка на текстова информация, а сега по-голямата част от личните компютри в света (и през повечето време) са заети с обработката на текстова информация.
Традиционно за кодиране на един символ се използва количество информация, равна на 1 байт, тоест I \u003d 1 байт \u003d 8 бита.
За да се кодира един знак, е необходим 1 байт информация.
Ако считаме символите за възможни събития, тогава според формула (2.1) можем да изчислим колко различни символа могат да бъдат кодирани:
N \u003d 2 I \u003d 2 8 \u003d 256.
Такъв брой знаци е достатъчен за представяне на текстова информация, включително главни и малки букви на руската и латинската азбука, цифри, знаци, графични символи и т.н.
Кодирането се състои в това, че на всеки символ е присвоен уникален десетичен код от 0 до 255 или съответния двоичен код от 00000000 до 11111111. По този начин човек различава символите по стиловете си, а компютърът по техните кодове.
Когато текстовата информация бъде въведена в компютър, тя е двоично кодирана, изображението на героя се преобразува в двоичния му код. Потребителят натиска клавиш със символ на клавиатурата и определена последователност от осем електрически импулса (двоичен код на символа) влиза в компютъра. Символният код се съхранява в оперативната памет на компютъра, където заема един байт.
В процеса на показване на символ на екрана на компютъра се извършва обратният процес - декодиране, тоест преобразуване на символния код в неговото изображение.
Важно е, че присвояването на конкретен код на символ е въпрос на съгласие, което е фиксирано в таблицата с кодове. Първите 33 кода (от 0 до 32) съответстват не на знаци, а на операции (ред на подаване, въвеждане на пространство и т.н.).
Кодовете от 33 до 127 са международни и съответстват на знаците на латинската азбука, числата, знаците на аритметичните операции и препинателните знаци.
Кодовете 128 до 255 са национални, тоест в националните кодировки различни символи съответстват на един и същ код. За съжаление, в момента има пет различни кодови таблици за руски букви (KOI8, CP1251, CP866, Mac, ISO - таблица 1.3), така че текстовете, създадени в едно кодиране, няма да бъдат правилно показани в друго.
В момента е широко разпространен новият международен стандарт Unicode, който разпределя не един байт, а два за всеки символ, така че с негова помощ можете да кодирате не 256 знака, а N \u003d 216 \u003d \u003d 65536 различни знака. Това кодиране се поддържа от най-новите версии на платформата Microsoft Windows & Office (от 1997 г.).
Всяко кодиране се задава от собствена кодова таблица. Както се вижда от таблицата. 1.3, различни символи са присвоени на един и същ двоичен код в различни кодировки.
Например, последователност от цифрови кодове 221, 194, 204 в CP1251 кодиране формира думата "компютър", докато в други кодировки това ще бъде безсмислен набор от знаци.
За щастие в повечето случаи потребителят не трябва да се притеснява от прекодиране на текстови документи, тъй като това се прави от специални програми за конвертор, вградени в приложения.
Дефиниране на цифров код
1. Стартирайте текстовия редактор MS Word 2002. Въведете командата [Insert-Symbol ...]. На екрана ще се появи диалогов прозорец. символ, Централната част на диалоговия прозорец е заета от таблица с символи за определен шрифт (например Times New Roman).
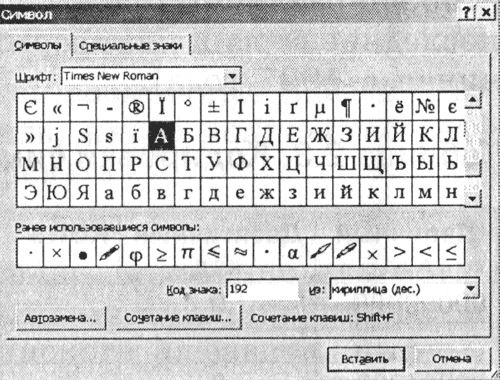 |
Символите са подредени последователно отляво надясно и ред по ред, като се започне със символа празнина в горния ляв ъгъл и завършва с буквата „I“ в долния десен ъгъл на таблицата.
Изберете знак и от падащия списък от: вид кодиране. В текстовото поле Регистрационен код: ще се появи нейният цифров код.
Въвеждане на знаци чрез цифров код
1. Стартирайте стандартната програма тетрадка, Използвайки допълнителната цифрова клавиатура, задръжте клавиша (Alt), въведете номер 0224, освободете бутона (Alt). В документа се появява символ. Повторете процедурата за цифрови кодове от 0225 до 0233. Документът ще покаже последователност от 12 знака за „домашна сигурност“ в кодиращия Windows (CP1251).
2. Използвайки незадължителната цифрова клавиатура, докато натискате клавиша (Alt), въведете номер 224, символът "p" ще се появи в документа. Повторете процедурата за цифрови кодове от 225 до 233, документът ще покаже последователност от 12 символа "rstuhtschshshsh" в кодиращия MS-DOS (CP866).
 |
Практически упражнения
1.29. Използвайки таблица с символи (MS Word), запишете последователност от десетични цифрови кодове в кодирането на Windows (CP1251) за думата "компютър".
1.30. С помощта на Notepad определете коя дума в кодиращия Windows (CP1251) е дадена от поредица от цифрови кодове: 225, 224, 233,242.
1.31. В каква последователност от букви кодирането KOI8 и ISO съответстват на думата "компютър", записана в кодирането CP1251?
Компютърът обработва голямо количество информация. Аудио файлове, снимки, текстове - всичко това трябва да бъде възпроизведено или показано. Защо бинарното кодиране е универсален метод за програмиране на информация на всяко техническо оборудване?
Каква е разликата между криптиране и криптиране?
Често хората идентифицират понятията „кодиране“ и „криптиране“, когато всъщност имат различно значение. И така, криптирането е процес на преобразуване на информация, за да се прикрие. Лицето, което е променило текста, или специално обучени хора, често може да дешифрира. Кодирането се използва за обработка на информация и опростяване на работата с нея. Обикновено се използва обща таблица за кодиране, която е позната на всички. Той е вграден в компютъра.
Принцип на двоично кодиране
Двоично кодиране въз основа на използването само на два знака - 0 и 1 - за обработка на информация, използвана от различни устройства. Тези знаци се наричаха двоични цифри, на английски - двоична цифра или бит. Всеки герой заема 1 бит компютърна памет. Защо бинарното кодиране е универсален метод за обработка на информация? Факт е, че на компютъра е по-лесно да обработва по-малко знаци. Производителността на компютъра също пряко зависи от това: колкото по-малко функционални задачи трябва да изпълнява устройството, толкова по-висока е скоростта и качеството на работа. 
Принципът на двоичното кодиране се среща не само в програмирането. Редувайки глухи и звучни удари по барабаните, жителите на Полинезия предавали информация един на друг. Подобен принцип се прилага, когато дълги и къси звуци се използват за предаване на съобщение. "Телеграфна азбука" се използва днес.
Къде се използва двоично кодиране?
Двоичното в компютъра се използва навсякъде. Всеки файл, независимо дали е музика или текст, трябва да бъде програмиран така, че по-късно да може лесно да се обработва и чете. Двоичната система за кодиране е полезна за работа със символи и цифри, аудио файлове, графика.
Кодиране на двоични числа
Сега в компютрите числата се представят в кодирана форма, непонятна за обикновения човек. Използването на арабски цифри, както си представяме, е ирационално за технологиите. Причината за това е необходимостта да се присвои уникален символ на всяко число, което понякога е невъзможно да се направи.

Съществуват две цифрови системи: позиционна и непозиционна. Непозиционната система се основава на използването на латински букви и е позната ни под формата.Този метод на запис е доста труден за разбиране, затова са го изоставили.
Днес се използва позиционна система от числа. Това включва двоично, десетично, осмо и дори шестнадесетично кодиране на информация.
Използваме системата за десетично кодиране в ежедневието. Това са ни познати, които са разбираеми за всеки човек. Двоичното кодиране на числата се различава, като се използват само нула и едно.
Целите числа се превеждат в двоична система за кодиране, като се разделят на 2. Резултатните коефициенти също се поетапно завършват с 2, докато не се получат общо 0 или 1. Например числото 123 10 в двоична система може да бъде представено като 1111011 2. И числото 20 10 ще изглежда като 10100 2.
Индексите 10 и 2 са обозначени, съответно, система за кодиране на десетични и двоични числа. Символът на двоично кодиране се използва за опростяване на работата със стойности, представени в различни системи с числа.
Десетичните методи за програмиране се основават на плаваща точка. За да преведете правилно стойността от десетична в двоична система за кодиране, използвайте формулата N \u003d M x qp. M е мантисата (израз на число без никакъв ред), p е редът на стойността на N, а q е основата на кодиращата система (в нашия случай 2).
Не всички числа са положителни. За да разграничи положителните и отрицателните числа, компютърът оставя пространство от 1 бит за кодиране на символи. Тук нулата представлява знак плюс, а един представлява знак минус.
Използването на такава система от числа улеснява работата на компютър с числа. Ето защо бинарното кодиране е универсално в изчислителните процеси.

Кодиране на двоичен текст
Всеки символ на азбуката е кодиран от собствен набор от нули и такива. Текстът се състои от различни знаци: букви (главни и малки букви), аритметични знаци и други различни значения. Кодирането на текстова информация изисква използването на 8 последователни двоични стойности от 00000000 до 11111111. По този начин могат да бъдат конвертирани 256 различни символа.
За да се избегне объркване в текстовото кодиране, за всеки знак се използват специални таблици със стойност. Те имат латинската азбука, аритметичните знаци и специалните знаци (например €, ¥ и други). Променливите символи 128-255 кодират националната азбука на страната.
За да кодирате 1 символ, са необходими 8 бита памет. За опростяване на подсметките 8 бита са равни на 1 байт, така че общото дисково пространство за текстова информация се измерва в байтове.

Повечето персонални компютри имат стандартна таблица. aSCII кодировки (Американски стандартен код за обмен на информация). Използват се и други таблици, в които системата за кодиране на текст е различна. Например, първото известно кодиране на символи се нарича KOI-8 (8-битов код за обмен на информация) и работи на компютри, работещи с UNIX. Широко се намира и кодовата таблица CP1251, създадена за операционната система Windows.
Двоично кодиране на звук
Друга причина, поради която бинарното кодиране е универсален метод за програмиране на информация, е неговата простота при работа с аудио файлове. Всяка музика е звукови вълни с различна амплитуда и честота на трептене. Силата на звука и неговата височина зависят от тези параметри.
За да програмира звукова вълна, компютърът я разделя условно на няколко части или "проби". Броят на такива проби може да бъде голям, така че има 65 536 различни комбинации от нули и такива. Съответно съвременните компютри са оборудвани с 16-битови звукови карти, което означава използване на 16 двоични цифри за кодиране на една проба от звуковата вълна.
За да възпроизвежда аудио файл, компютърът обработва програмираните последователности от двоичен код и ги комбинира в една непрекъсната вълна. 
Графично кодиране
Графичната информация може да бъде представена под формата на чертежи, диаграми, снимки или слайдове в PowerPoint. Всяка картина се състои от малки точки - пиксели, които могат да бъдат боядисани в различни цветове. Цветът на всеки пиксел е кодиран и запазен и в резултат получаваме пълноценно изображение.
Ако картината е черно-бяла, кодът за всеки пиксел може да бъде едно или нула. Ако се използват 4 цвята, кодът на всеки от тях се състои от две цифри: 00, 01, 10 или 11. По този принцип се отличава качеството на обработка на всяко изображение. Увеличаването или намаляването на яркостта също влияе върху броя на използваните цветове. В най-добрия случай компютърът отличава около 16 777 216 нюанса.

заключение
Съществуват различни методи за програмиране на информация, сред които бинарното кодиране е най-ефективно. Само с два знака - 1 и 0 - компютърът чете повечето файлове лесно. В същото време скоростта на обработка е много по-висока, отколкото например би се използвала система за десетично програмиране. Простотата на този метод го прави незаменим за всяка техника. Ето защо бинарното кодиране е универсално сред своите връстници.
Всеки знае, че компютрите могат да извършват изчисления с големи групи данни с огромна скорост. Но не всеки знае, че тези действия зависят само от две условия: дали има ток и какво напрежение.
Как компютърът успява да обработва толкова разнообразна информация?
Тайната се крие в бинарната система. Всички данни влизат в компютъра, представени под формата на единици и нули, всяка от които съответства на едно състояние на електрическия проводник: единици - високо напрежение, нули - ниско или единици - наличието на напрежение, нули - неговото отсъствие. Преобразуването на данни в нули и такива се нарича двоично преобразуване, а крайното му обозначаване се нарича двоичен код.
В десетична нотация въз основа на десетичната система на смятане, която се използва в ежедневието, числовата стойност се представя с десет цифри от 0 до 9 и всяко място в числото има стойност десет пъти по-висока от мястото вдясно от него. За да представлява число, по-голямо от девет в десетичната система, на неговото място се поставя нула и едно се поставя на следващото, по-ценно място отляво. По същия начин в бинарната система, където се използват само две цифри - 0 и 1, всяко място е два пъти по-ценно от мястото вдясно от него. Така в двоичен код само нула и едно могат да бъдат представени като единични числа, а всяко число, по-голямо от едно, изисква две места. След нула и едно следващите три двоични числа са 10 (прочетете едно-нула) и 11 (прочетете едно-едно) и 100 (прочетете едно-нула-нула). 100 двоични системи са еквивалентни на 4 десетични. Горната таблица вдясно показва други двоични десетични еквиваленти.
Всяко число може да бъде изразено в двоично, то просто заема повече място, отколкото в десетичната нотация. В двоичната система можете също да напишете азбуката, ако на всяка буква е зададен определен двоичен номер.
Две цифри за четири места
16 комбинации могат да бъдат направени с помощта на тъмни и светли топки, комбинирайки ги в групи от по четири. Ако вземете тъмните топки като нули, а светлите като единици, тогава 16 комплекта ще се окажат двоичен код с 16 единици, числената стойност на която е от нула до пет ( вижте горната таблица на страница 27). Дори с два вида топки в двоичната система можете да изградите безкраен брой комбинации, като просто увеличите броя на топките във всяка група - или броя на местата в числа.
Битове и байтове
Най-малката единица в компютърната обработка, бит е единица данни, която може да има едно от двете възможни условия. Например, всеки от тях и нули (вдясно) означава 1 бит. Малко може да бъде представено по други начини: чрез наличието или отсъствието на електрически ток, чрез дупка и нейното отсъствие, по посоката на намагнетизиране вдясно или вляво. Осем бита съставят байт. 256 възможни байта могат да представляват 256 знака и знака. Много компютри обработват байтове с данни едновременно.
Бинарна конверсия Четирицифрен двоичен код може да представлява десетични числа от 0 до 15.
Таблици с кодове
Когато двоичен код се използва за обозначаване на букви от азбуката или препинателните знаци, са необходими кодови таблици, които показват кой код съвпада с кой знак. Съставени са няколко такива кодове. Повечето компютри са адаптирани за седемцифрен код, наречен ASCII, или американски стандартен код за обмен на информация. Таблицата вдясно показва aSCII кодове за английската азбука. Други кодове са предназначени за хиляди знаци и азбуки на други езици на света.

Част от таблицата с кодове на ASCII

