07.08.2019
कोडिंग और जानकारी बदलना। संख्याओं का उपयोग करके जानकारी एन्कोडिंग की एक विधि। बाइनरी कोडिंग बाइनरी नंबर सिस्टम
विकास की प्रक्रिया में, मानव जाति को इस या उस जानकारी को स्टोर करने और प्रसारित करने की आवश्यकता का एहसास हुआ है। बाद के मामले में, संकेतों में इसके रूपांतरण की आवश्यकता थी। इस प्रक्रिया को डेटा एन्कोडिंग कहा जाता है। पाठ संबंधी जानकारी के साथ-साथ ग्राफिक छवियों को संख्याओं में परिवर्तित किया जा सकता है। यह कैसे किया जा सकता है, इसके बारे में हमारा लेख बताएगा।
मस्तिष्क में रसायनों और विद्युत आवेगों का उपयोग करके कोडिंग प्राप्त की जाती है। न्यूरॉन्स के बीच तंत्रिका पथ या कनेक्शन वास्तव में एक प्रक्रिया के माध्यम से बनते या प्रवर्धित होते हैं, जिन्हें दीर्घकालिक पोटेंशिएनशन कहा जाता है, जो मस्तिष्क में सूचना के प्रवाह को बदलता है। दूसरे शब्दों में, चूंकि एक व्यक्ति नई घटनाओं या संवेदनाओं का अनुभव करता है, इसलिए मस्तिष्क इन नए इंप्रेशन को मेमोरी में स्टोर करने के लिए खुद को "प्रोसेस" करता है।
कोडिंग के चार मुख्य प्रकार दृश्य, ध्वनिक, विचारशील और अर्थ हैं। दृश्य कोडिंग छवियों और दृश्य संवेदी जानकारी को एन्कोडिंग करने की प्रक्रिया है। मानसिक चित्र बनाना उन तरीकों में से एक है जिन पर लोग दृश्य कोडिंग का उपयोग करते हैं। इस प्रकार की जानकारी अस्थायी रूप से प्रतीक मेमोरी में संग्रहीत की जाती है, और फिर भंडारण के लिए दीर्घकालिक स्मृति में स्थानांतरित कर दी जाती है। मिग्डाला यादों के दृश्य कोडिंग में एक बड़ी भूमिका निभाता है।
दूरी की जानकारी
- कूरियर पोस्ट;
- ध्वनिक (उदाहरण के लिए, लाउडस्पीकर के माध्यम से);
- एक विशेष दूरसंचार विधि (वायर्ड, रेडियो, ऑप्टिकल, रेडियो रिले, उपग्रह, फाइबर ऑप्टिक) पर आधारित है।
फिलहाल सबसे आम बाद के प्रकार के ट्रांसमिशन सिस्टम हैं। हालाँकि, उनका उपयोग करने के लिए, आपको पहले एन्कोडिंग जानकारी की एक या दूसरी विधि लागू करनी होगी। आधुनिक लोगों से परिचित दशमलव पथरी में संख्याओं की मदद से, यह करना बहुत मुश्किल है।
ध्वनिक कोडिंग श्रवण उत्तेजनाओं या प्रत्यारोपण यादों के लिए सुनवाई का उपयोग है। यह तथाकथित ध्वन्यात्मक लूप द्वारा सुविधाजनक है। ध्वन्यात्मक लूप वह प्रक्रिया है जिसके द्वारा ध्वनियाँ उप-स्वर की रिहर्सल की जाती हैं ताकि उन्हें याद रखा जा सके।
लैब कोडिंग पहले से ज्ञात जानकारी का उपयोग करता है और इसे नई जानकारी के साथ जोड़ता है। नई मेमोरी की प्रकृति पिछली सूचनाओं पर निर्भर हो जाती है क्योंकि यह नई सूचनाओं पर निर्भर है। अध्ययनों से पता चला है कि स्मार्ट कोडिंग के उपयोग के माध्यम से सूचना के दीर्घकालिक संरक्षण में बहुत सुधार होता है।
एन्क्रिप्शन

बाइनरी नंबर सिस्टम
कंप्यूटर युग की शुरुआत में, वैज्ञानिकों को एक उपकरण खोजने के लिए पहले से ही तैयार किया गया था जो कंप्यूटर में संख्याओं का प्रतिनिधित्व करने के लिए जितना संभव हो उतना सरल होगा। जब क्लॉड शैनन ने एक बाइनरी नंबर सिस्टम का उपयोग करने का प्रस्ताव किया तो सवाल हल हो गया। यह 17 वीं शताब्दी के बाद से जाना जाता है, और इसके कार्यान्वयन के लिए एक तार्किक "1" के अनुरूप 2 स्थिर राज्यों के साथ एक उपकरण और एक तार्किक "0" की आवश्यकता थी। उस समय उनमें से बहुत सारे थे - कोर से, जो या तो चुम्बकित या विघटित हो सकता था, एक ट्रांजिस्टर के लिए जो खुले में या बंद अवस्था में भी हो सकता है।
सिमेंटिक कोडिंग में स्पर्श इनपुट का उपयोग शामिल है, जिसका एक विशिष्ट अर्थ है या इसे संदर्भ में लागू किया जा सकता है। चूनिंग और mnemonics अर्थ कोडिंग में मदद करते हैं; कभी-कभी गहरी प्रसंस्करण और इष्टतम निष्कर्षण होते हैं। उदाहरण के लिए, आप किसी व्यक्ति के नाम या रंग द्वारा विशिष्ट भोजन के आधार पर एक विशिष्ट फोन नंबर याद कर सकते हैं।
संगठन-व्यापी कोडिंग अनुकूलन
सभी जानकारी समान रूप से अच्छी तरह से एन्कोडेड नहीं है। कंप्यूटर फ़ाइल में सहेजें पर क्लिक करने के बारे में फिर से सोचें। क्या आपने इसे सही फ़ोल्डर में सहेजा है? क्या आपने इसे सहेजते समय फ़ाइल पूरी की थी? क्या आप इसे बाद में पा सकते हैं? एक बुनियादी स्तर पर, एन्कोडिंग प्रक्रिया समान समस्याओं का सामना करती है: यदि जानकारी को ठीक से एन्कोड नहीं किया गया है, तो बाद में याद करना एक अधिक कठिन कार्य होगा। मस्तिष्क में कोडिंग यादों की प्रक्रिया को विभिन्न प्रकार से अनुकूलित किया जा सकता है, जिसमें मेनेमिक्स, विखंडन और राज्य-निर्भर सीखने शामिल हैं।
रंग चित्रों का प्रस्तुतिकरण
ऐसी छवियों के लिए संख्याओं का उपयोग करके जानकारी को एन्कोडिंग करने की विधि कुछ अधिक जटिल है। इस प्रयोजन के लिए, चित्र को 3 प्राथमिक रंगों (हरा, लाल और नीला) में पहले से विघटित करने की आवश्यकता होती है, क्योंकि उन्हें कुछ निश्चित अनुपातों में मिलाने के परिणामस्वरूप, मानव आँख द्वारा माना गया कोई भी शेड प्राप्त किया जा सकता है। 24 बिट्स का उपयोग करके संख्याओं का उपयोग करके किसी चित्र को एन्कोडिंग करने की इस विधि को आरजीबी या पूर्ण रंग (ट्रू कलर) कहा जाता है। 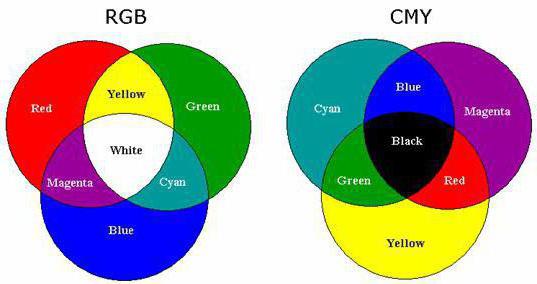
Mnemonic डिवाइस, जिसे कभी-कभी केवल mnemonics कहा जाता है, स्मृति में सरल सामग्री को एन्कोड करने में मदद करने का एक तरीका है। Mnemonics किसी भी संगठन विधि है जिसका उपयोग आप कुछ याद रखने के लिए कर सकते हैं। एक उदाहरण एक कोडवर्ड प्रणाली है जिसमें एक व्यक्ति "बांधता है" या उन वस्तुओं को बांधता है जिन्हें अन्य आसानी से याद किए गए तत्वों का उपयोग करके याद रखने की आवश्यकता होती है। इसका एक उदाहरण है "किंग फिलिप एक अच्छे सूप के लिए आया था," जीव विज्ञान में टैक्सोनोमिक श्रेणियों के आदेश को याद रखने के लिए शब्द कोड के लिए एक वाक्य, जो कि आपको याद रखने के लिए आवश्यक शब्दों के समान प्रारंभिक अक्षरों का उपयोग करता है: राज्य, प्रकार, वर्ग, क्रम, परिवार , दयालु, दयालु।
यदि हम मुद्रण के बारे में बात कर रहे हैं, तो CMYK प्रणाली का उपयोग किया जाता है। यह इस विचार पर आधारित है कि मुख्य आरजीबी घटकों में से प्रत्येक को एक रंग से मिलान किया जा सकता है जो इसे सफेद करने के लिए मजबूर करता है। वे सियान, मैजेंटा और पीले हैं। यद्यपि उनमें से पर्याप्त हैं, मुद्रण लागत को कम करने के लिए, वे चौथे घटक को जोड़ते हैं - काला। इस प्रकार, सीएमवाईके सिस्टम में ग्राफिक्स का प्रतिनिधित्व करने के लिए 32 बाइनरी अंकों की आवश्यकता होती है, और मोड को आमतौर पर पूर्ण रंग कहा जाता है।
एक अन्य प्रकार का निमोनी एक संक्षिप्त नाम है जिसमें एक व्यक्ति स्मृति पर भार को कम करने के लिए शब्दों की सूची को उनके प्रारंभिक अक्षरों में कम कर देता है। चुंकिंग वस्तुओं के भागों को सार्थक लक्ष्यों में व्यवस्थित करने की प्रक्रिया है। तब सब कुछ एक इकाई के रूप में याद किया जाता है, न कि व्यक्तिगत भागों के रूप में।
राज्य-आश्रित शिक्षा वह होती है जब कोई व्यक्ति मन की स्थिति के आधार पर जानकारी को याद रखता है जब वे इसे सीखते हैं। खोज संकेत राज्य-विशिष्ट सीखने का एक महत्वपूर्ण हिस्सा हैं। उदाहरण के लिए, यदि कोई व्यक्ति कुछ अवधारणाओं का अध्ययन करते हुए एक निश्चित गीत को सुनता है, तो इस गीत को बजाने से सबसे अधिक समझ में आने वाली अवधारणाओं को बताया जा सकता है। बदबू, आवाज़ या सीखने की जगह भी राज्य-विशिष्ट प्रशिक्षण का हिस्सा हो सकती है।

ध्वनि प्रस्तुति
इस सवाल के लिए कि क्या इसके लिए संख्याओं का उपयोग करके जानकारी को एन्कोड करने का एक तरीका है, जवाब हां होना चाहिए। हालांकि, फिलहाल, ऐसे तरीकों को सही नहीं माना जाता है। इनमें शामिल हैं:
- एफएम विधि। यह विभिन्न आवृत्तियों के प्रारंभिक हार्मोनिक संकेतों के अनुक्रम में किसी भी जटिल ध्वनि के अपघटन पर आधारित है, जिसे एक कोड द्वारा वर्णित किया जा सकता है।
- टेबुलर-वेव विधि। पूर्व-संकलित तालिकाओं में, नमूने संग्रहीत किए जाते हैं - विभिन्न संगीत वाद्ययंत्रों के लिए ध्वनियों के नमूने। संख्यात्मक कोड उपकरण, पिच, तीव्रता और ध्वनि की अवधि, आदि के प्रकार और मॉडल संख्या को व्यक्त करते हैं।
![]()
मेमोरी समेकन प्रक्रियाओं की एक श्रेणी है जो इसके प्रारंभिक अधिग्रहण के बाद मेमोरी ट्रेसिंग को स्थिर करती है। कोडिंग की तरह, समेकन तथ्य के बाद ईवेंट मेमोरी की उपलब्धता को प्रभावित करता है। हालांकि, कोडिंग ध्यान और चीजों को याद करने के लिए एक जागरूक प्रयास से अधिक प्रभावित होता है, जबकि समेकन से जुड़ी प्रक्रियाएं आमतौर पर बेहोश होती हैं और सेलुलर या न्यूरोलॉजिकल स्तर पर होती हैं। एक नियम के रूप में, कोडिंग केंद्रित है, और समेकन एक जैविक प्रक्रिया है।
नींद के दौरान भी समेकन होता है। अध्ययनों से पता चलता है कि सुगम स्मृतियों में मस्तिष्क को जानकारी को समेकित करने के लिए नींद सर्वोपरि है। जब हम सोते हैं, तो मस्तिष्क हाल की यादों का विश्लेषण करता है, उनका वर्गीकरण करता है, और उनकी रक्षा करता है। याददाश्त बढ़ाने का एक उपयोगी तरीका यह है कि जिस सूचना को आप याद रखना चाहते हैं, उसकी ऑडियो रिकॉर्डिंग का उपयोग करें और जब आप सोने की कोशिश कर रहे हों तो उसे बजाएं। जब आप वास्तव में नींद के पहले चरण में होते हैं, तो कोई सीख नहीं होती है, क्योंकि नींद के दौरान यादें सीखना मुश्किल होता है।
अब आप जानते हैं कि बाइनरी कोडिंग जानकारी प्रस्तुत करने के सामान्य तरीकों में से एक है, जिसने कंप्यूटर प्रौद्योगिकी के विकास में बहुत बड़ी भूमिका निभाई है।
कंप्यूटर का एक मुख्य लाभ यह है कि यह एक आश्चर्यजनक बहुमुखी मशीन है। हर कोई जिसने कभी उसका सामना किया है वह जानता है कि अंकगणित करना कंप्यूटर का उपयोग करने का मुख्य तरीका नहीं है। कंप्यूटर संगीत और वीडियो को पूरी तरह से पुन: पेश करते हैं, उन्हें इंटरनेट पर आवाज और वीडियो कॉन्फ्रेंस आयोजित करने, ग्राफिक चित्र बनाने और संसाधित करने के लिए इस्तेमाल किया जा सकता है, और पहली नज़र में कंप्यूटर गेम के क्षेत्र में कंप्यूटर का उपयोग करने की क्षमता एक सुपरमिथोमीटर की छवि के साथ पूरी तरह से असंगत लगती है, जो प्रति सेकंड लाखों अंकों को पीसती है।
स्मृति में ध्यान की भूमिका
हालाँकि, आप सोते हुए गिरने से पहले रिकॉर्डिंग पर जो सुनते हैं, वह आपके मन की शांत और केंद्रित स्थिति के कारण बने रहने की अधिक संभावना है। स्मृति में जानकारी को एनकोड करने के लिए, हमें पहले ध्यान देना चाहिए, एक प्रक्रिया जिसे ध्यान कैप्चर करने के रूप में जाना जाता है।
ध्यान खींचने और काम करने की स्मृति के बीच संबंध पर चर्चा करें। अनुसंधान कार्यशील मेमोरी के बीच एक करीबी संबंध दिखाता है और जिसे ध्यान खींचने के रूप में जाना जाता है, एक प्रक्रिया जिसमें एक व्यक्ति विशेष जानकारी पर ध्यान देता है। ध्यान का एक स्पष्ट कब्जा तब होता है जब एक उत्तेजना जिसे एक व्यक्ति ने दौरा नहीं किया है वह पर्याप्त रूप से ध्यान देने योग्य हो जाता है ताकि एक व्यक्ति उसका अनुसरण करना शुरू करे और उसके अस्तित्व का एहसास करे। ध्यान आकर्षित करना तब होता है जब कोई प्रोत्साहन जो किसी व्यक्ति का दौरा नहीं करता है वह किसी व्यक्ति के व्यवहार को प्रभावित करता है, भले ही वह इस प्रभाव या उत्तेजना से अवगत हो। स्पष्ट: बहुत विशिष्ट, स्पष्ट, या क्रिया। कार्यशील मेमोरी: एक प्रणाली जो क्रियात्मक और गैर-मौखिक कार्यों को करने के लिए मन में जानकारी के कई टुकड़ों को सक्रिय रूप से संग्रहीत करती है और उन्हें सूचना के आगे के प्रसंस्करण के लिए उपलब्ध कराती है।
- जानबूझकर कब्जा स्पष्ट और अंतर्निहित दोनों तरह से हो सकता है।
- कार्यशील मेमोरी में सक्रिय रूप से बहुत सारी जानकारी होती है और उनमें हेरफेर होती है।
- प्रत्यक्ष: अप्रत्यक्ष रूप से, बिना प्रत्यक्ष अभिव्यक्ति के।
किसी वस्तु या घटना के सूचना मॉडल को संकलित करते समय, हमें कुछ पदनामों को समझने के तरीके पर सहमत होना चाहिए। अर्थात्, सूचना के प्रस्तुतीकरण के प्रकार पर सहमत होना।
एक व्यक्ति अपने विचारों को शब्दों से बने वाक्यों के रूप में व्यक्त करता है। वे सूचना का एक वर्णनात्मक प्रतिनिधित्व करते हैं। किसी भी भाषा का आधार वर्णमाला है - संदेश बनाने वाले किसी भी प्रकृति के विभिन्न संकेतों (प्रतीकों) का एक निश्चित सेट।
जब कोई व्यक्ति किसी निश्चित जानकारी पर ध्यान देता है, तो इस प्रक्रिया को ध्यान खींचने वाला कहा जाता है। विशिष्ट जानकारी पर ध्यान देते हुए, एक व्यक्ति ऐसी यादें बनाता है जो एक ही स्थिति में दूसरों से भिन्न हो सकती हैं। यही कारण है कि दो लोग एक ही स्थिति को देख सकते हैं, लेकिन इसकी अलग-अलग यादें बना सकते हैं - प्रत्येक व्यक्ति ध्यान को कैप्चर करने का एक अलग तरीका करता है। ध्यान खींचने वाले दो मुख्य प्रकार हैं: स्पष्ट और अंतर्निहित।
यह बहुत सरल है जब कुछ नया आपका ध्यान आकर्षित करता है और आप जागरूक हो जाते हैं और इस नए प्रोत्साहन पर ध्यान केंद्रित करते हैं। यह तब होता है जब आप अपने होमवर्क पर काम करते हैं, और कोई आपका नाम पुकारता है, आपका पूरा ध्यान देता है। यदि आप अपने होमवर्क पर काम कर रहे हैं और पृष्ठभूमि में शांत और कष्टप्रद संगीत लगता है, तो आप इसके बारे में नहीं जानते होंगे, लेकिन आपका सामान्य ध्यान और आपके होमवर्क का प्रदर्शन प्रभावित हो सकता है।
एक और एक ही रिकॉर्ड अलग-अलग शब्दार्थ भार ले जा सकता है। उदाहरण के लिए, संख्या 251299 का एक सेट संकेत कर सकता है: किसी वस्तु का द्रव्यमान; वस्तु की लंबाई; वस्तुओं के बीच की दूरी; फ़ोन नंबर तारीख रिकॉर्ड 25 दिसंबर, 1999।
जानकारी का प्रतिनिधित्व करने के लिए विभिन्न कोड का उपयोग किया जा सकता है और, तदनुसार, आपको कुछ नियमों को जानने की आवश्यकता है - इन कोडों को लिखने के नियम, अर्थात्। कोड करने में सक्षम हो।
कार्य मेमोरी और डेटा संग्रह
ड्राइविंग करते समय ध्यान आकर्षित करना महत्वपूर्ण है, क्योंकि आप उत्तेजना के प्रभावों के बारे में नहीं जानते होंगे, जैसे कि ज़ोर से संगीत या असहज ड्राइविंग तापमान, आपका काम प्रभावित होगा। वर्किंग मेमोरी मेमोरी का एक हिस्सा है जो छोटी अवधि के लिए बहुत सारी जानकारी को सक्रिय रूप से संग्रहीत करता है और उनमें हेरफेर करता है। कार्यशील मेमोरी में, सबसिस्टम हैं जो दृश्य और मौखिक जानकारी का प्रबंधन करते हैं, और इसकी सीमित क्षमता है। हम हर पल हजारों सूचनाएं लेते हैं; यह हमारी कार्यशील मेमोरी में संग्रहीत है।
कोड - सूचना की प्रस्तुति के लिए प्रतीकों का एक सेट।
कोडिंग - कोड के रूप में जानकारी प्रस्तुत करने की प्रक्रिया।
एक दूसरे के साथ संवाद करने के लिए, हम कोड का उपयोग करते हैं - रूसी भाषा। बात करते समय, यह कोड ध्वनियों में प्रेषित होता है, जबकि लेखन में - अक्षरों में। चालक बीप के साथ या हेडलाइट्स को चमकाने के साथ एक संकेत प्रसारित करता है। आप ट्रैफ़िक सिग्नल के रूप में सड़क पार करते समय कोडिंग जानकारी का सामना करते हैं। इस प्रकार, कोडिंग कड़ाई से परिभाषित नियमों के अनुसार वर्णों के संयोजन का उपयोग करने के लिए नीचे आता है।
कार्य मेमोरी यह तय करती है कि क्या कोई विशेष जानकारी महत्वपूर्ण है। दूसरे शब्दों में, यदि जानकारी का उपयोग नहीं किया जाता है या महत्वपूर्ण नहीं माना जाता है, तो इसे भुला दिया जाएगा। अन्यथा, यह अल्पकालिक स्मृति से चलता है और दीर्घकालिक स्मृति से जुड़ जाता है।
ध्यान आकर्षित करने का एक प्रसिद्ध उदाहरण कॉकटेल पार्टी प्रभाव है, जो एक ऐसी घटना है जो आपको कई उत्तेजनाओं को छानकर एक विशिष्ट उत्तेजना पर अपना श्रवण ध्यान केंद्रित करने की अनुमति देती है, इसी तरह एक भागीदार एक शोर कमरे में एक वार्तालाप पर ध्यान केंद्रित कर सकता है। यह प्रभाव अधिकांश लोगों को एक स्वर में ट्यून करने और बाकी सभी को ट्यून करने की अनुमति देता है।
जानकारी को विभिन्न तरीकों से एन्कोड किया जा सकता है: मौखिक रूप से; लिखित रूप में; इशारों या किसी अन्य प्रकृति के संकेत।
बाइनरी डेटा एन्कोडिंग।
जैसे-जैसे तकनीक विकसित हुई, कोडिंग जानकारी के विभिन्न तरीके सामने आए। 19 वीं शताब्दी के उत्तरार्ध में, अमेरिकी आविष्कारक सैमुअल मोर्स ने एक अद्भुत कोड का आविष्कार किया जो अभी भी मानवता की सेवा करता है। सूचना को तीन वर्णों में एन्कोड किया गया है: लंबे संकेत (डैश), लघु संकेत (डॉट), कोई संकेत (ठहराव) - अलग-अलग अक्षरों के लिए।
अनुसंधान स्मृति और ध्यान आकर्षित करने या विशिष्ट जानकारी तक पहुंचने की प्रक्रिया के बीच घनिष्ठ संबंध का सुझाव देता है। एक व्यक्ति किसी दिए गए उत्तेजना पर, सचेतन रूप से या अनजाने में ध्यान देता है। इस उत्तेजना को तब कार्यशील मेमोरी में एन्कोड किया जाता है, और उस समय मेमोरी या तो इसे किसी अन्य परिचित अवधारणा से जोड़ने के लिए या मौजूदा स्थिति में किसी अन्य उत्तेजना से जोड़ने के लिए हेरफेर करती है। यदि जानकारी को अनिश्चित काल तक संग्रहीत करने के लिए पर्याप्त महत्वपूर्ण माना जाता है, तो अनुभव को दीर्घकालिक स्मृति में एन्कोड किया जाएगा।
यदि नहीं, तो वह अन्य महत्वहीन जानकारी के साथ भूल जाएगा। कई सिद्धांत हैं जो बताते हैं कि एन्कोडिंग के लिए कुछ जानकारी का चयन कैसे किया जाता है, जबकि अन्य जानकारी को छोड़ दिया जाता है। पहले से अपनाया गया फ़िल्टर मॉडल बताता है कि संवेदी से काम करने वाली मेमोरी तक जानकारी का यह फ़िल्टरिंग उत्तेजनाओं के विशिष्ट भौतिक गुणों पर आधारित है। प्रत्येक आवृत्ति के लिए एक अलग तंत्रिका मार्ग है; हमारा ध्यान चुनता है कि कौन सा मार्ग सक्रिय है और इससे यह नियंत्रित किया जा सकता है कि कार्यशील मेमोरी में कौन सी जानकारी स्थानांतरित की गई है।
एक कंप्यूटर प्रणाली भी मौजूद है - इसे कहा जाता है बाइनरी कोडिंगऔर केवल दो वर्णों के अनुक्रम द्वारा डेटा की प्रस्तुति पर आधारित है: 0 और 1. ये वर्ण कहलाते हैं बाइनरी अंक, अंग्रेजी में-अंक या संक्षिप्त बिट (बिट)।
दो अवधारणाओं को एक बिट के साथ व्यक्त किया जा सकता है: 0 या 1 हांया नहीं, कालाया सफेद, सच्चाईया एक झूठआदि)। यदि बिट्स की संख्या दो तक बढ़ जाती है, तो चार अलग-अलग अवधारणाएं पहले ही व्यक्त की जा सकती हैं:
इस प्रकार, एक व्यक्ति के शब्दों का एक निश्चित मुखर आवृत्ति के साथ पालन करना संभव है, भले ही आसपास के क्षेत्र में कई अन्य ध्वनियां हों। फिल्टर मॉडल पूरी तरह से पर्याप्त नहीं है। फिल्टर मॉडल के संशोधन, Attenuation सिद्धांत से पता चलता है कि हम ऐसी जानकारी को कमजोर करते हैं जो कम प्रासंगिक है, लेकिन इसे पूरी तरह से फ़िल्टर नहीं करता है। इस सिद्धांत के अनुसार, नजरअंदाज की गई आवृत्तियों के साथ सूचना का विश्लेषण किया जा सकता है, लेकिन उतनी ही कुशलता के साथ उतनी कुशलता से नहीं।
क्षीणन सिद्धांत देर से चयन के सिद्धांत से अलग है, जो प्रस्तावित करता है कि सभी सूचनाओं का पहले विश्लेषण किया जाए और महत्वपूर्ण या अप्रासंगिक के रूप में मूल्यांकन किया जाए; हालाँकि, यह सिद्धांत अनुसंधान द्वारा कम समर्थित है। कोई व्यक्ति जानकारी कैसे प्राप्त करता है, लेकिन इस जानकारी के साथ वे क्या करते हैं।
तीन बिट्स आठ अलग-अलग मानों को एनकोड कर सकते हैं:
000 001 010 011 100 101 110 111
एक बाइनरी कोडिंग सिस्टम में बिट्स की संख्या को बढ़ाते हुए, हम इस सिस्टम में व्यक्त किए जा सकने वाले मानों की संख्या को दोगुना कर देते हैं, अर्थात सामान्य फॉर्मूला है:
जहां एन स्वतंत्र एन्कोडेड मूल्यों की संख्या है;
मीटर - इस प्रणाली में अपनाई गई कोडिंग।

