29.06.2019
أي تنسيق الصوت هو الأفضل. ما هو "ضياع" أو حول ضغط الموسيقى ضياع
يوم جيد.
اليوم أود أن أتطرق إلى موضوع ضغط البيانات المفقودة. على الرغم من أن هناك بالفعل مقالات على المحور مخصصة لبعض الخوارزميات ، أردت أن أتحدث عن هذا بمزيد من التفصيل.
سأحاول تقديم وصف رياضي ووصفًا بالطريقة المعتادة ، بحيث يمكن للجميع العثور على شيء مثير للاهتمام لأنفسهم.
في هذه المقالة سأتطرق إلى لحظات الضغط الأساسية وأنواع الخوارزميات الرئيسية.
ضغط. هل هناك حاجة في الوقت الحاضر؟
نعم بالطبع. بالطبع ، نحن نفهم جميعًا أنه يمكننا الآن الوصول إلى كل من وسائط التخزين كبيرة الحجم وقنوات نقل البيانات عالية السرعة. ومع ذلك ، في الوقت نفسه ، فإن حجم المعلومات المنقولة ينمو. إذا شاهدنا قبل بضع سنوات 700 ميغا بايت من الأفلام التي تتلاءم مع قرص واحد ، يمكن أن تشغل الأفلام عالية الجودة اليوم عشرات غيغا بايت.
بالطبع ، فوائد ضغط كل شيء وكل شيء ليست كبيرة. ولكن لا تزال هناك حالات يكون فيها الضغط مفيدًا للغاية ، إن لم يكن ضروريًا.
- إرسال المستندات بالبريد الإلكتروني (لا سيما الكميات الكبيرة من المستندات التي تستخدم الأجهزة المحمولة)
- عند نشر الوثائق على المواقع ، والحاجة إلى توفير حركة المرور
- توفير مساحة على القرص عند تغيير أو إضافة تخزين أمر صعب. على سبيل المثال ، يحدث هذا في الحالات التي لا يكون فيها من السهل الحصول على ميزانية للنفقات الرأسمالية ، ولا توجد مساحة كافية على القرص.
بالطبع ، يمكنك الخروج بالعديد من المواقف المختلفة التي سيكون فيها الضغط مفيدًا ، لكن هذه الأمثلة القليلة كافية لنا.
يمكن تقسيم جميع أساليب الضغط إلى مجموعتين كبيرتين: الضغط الضياع والضغط غير المفقود. يتم استخدام الضغط بدون فقد في الحالات التي تحتاج إلى استعادة المعلومات بدقة إلى البتات. هذا النهج هو الوحيد الممكن عند الضغط ، على سبيل المثال ، البيانات النصية.
ومع ذلك ، في بعض الحالات ، ليس من الضروري استعادة المعلومات بدقة ويسمح باستخدام خوارزميات تقوم بتنفيذ الضغط الناقص ، والذي ، على عكس الضغط غير المفقود ، يكون عادة أسهل في التنفيذ ويوفر درجة أعلى من الأرشفة.
لذلك ، دعنا ننتقل إلى خوارزميات ضغط ضياع.
أساليب ضغط ضياع العالمي
في الحالة العامة ، هناك ثلاثة خيارات أساسية تعتمد عليها خوارزميات الضغط.المجموعة الأولى طرق - تحويل تيار. يتضمن هذا وصفًا للبيانات الجديدة غير المضغوطة الواردة من خلال معالجتها بالفعل. في هذه الحالة ، لا يتم احتساب أي احتمالات ، ويتم تنفيذ تشفير الحروف فقط على أساس البيانات التي تمت معالجتها بالفعل ، كما هو الحال في أساليب LZ (سميت باسم أبراهام لمبل وجاكوب زيفا). في هذه الحالة ، يتم استبدال التكرارات الثانية والمزيد من سلسلة فرعية معروفة بالفعل لبرنامج التشفير بمراجع إلى أول ظهور لها.
المجموعة الثانية الطرق هي طرق ضغط إحصائية. في المقابل ، يتم تقسيم هذه الأساليب إلى التكيف (أو التدفق) ، وكتلة.
في الإصدار الأول (التكيفي) ، يستند حساب احتمالات البيانات الجديدة إلى البيانات التي تمت معالجتها بالفعل أثناء الترميز. تتضمن هذه الطرق إصدارات قابلة للتكيف من خوارزميات Huffman و Shannon-Fano.
في الحالة الثانية (الكتلة) ، يتم حساب إحصائيات كل كتلة بيانات بشكل منفصل ، وتضاف إلى الكتلة الأكثر ضغطًا. تتضمن هذه الإصدارات الثابتة طرق Huffman و Shannon-Fano و الترميز الحسابي.
المجموعة الثالثة الطرق هي ما يسمى طرق تحويل الكتلة. يتم تقسيم البيانات الواردة إلى كتل ، والتي يتم تحويلها بعد ذلك ككل. ومع ذلك ، قد لا تؤدي بعض الطرق ، لا سيما استنادًا إلى التقليب بين الكتل ، إلى انخفاض كبير (أو حتى أي) في كمية البيانات. ومع ذلك ، بعد هذه المعالجة ، تتحسن بنية البيانات بشكل ملحوظ ، ويكون الضغط اللاحق بواسطة الخوارزميات الأخرى أكثر نجاحًا وأسرع.
المبادئ العامة التي يعتمد عليها ضغط البيانات
تعتمد جميع أساليب ضغط البيانات على مبدأ منطقي بسيط. إذا تخيلنا أن العناصر الأكثر تكرارًا يتم تشفيرها برموز أقصر ، وأن العناصر الأقل تكرارًا يتم ترميزها بأخرى أطول ، ثم لتخزين جميع البيانات ، يلزم مساحة أقل مما لو كانت جميع العناصر ممثلة برموز من نفس الطول.
يتم وصف العلاقة الدقيقة بين تواتر تكرارات العناصر وأطوال الكود الأمثل في ما يسمى بنظرية ترميز مصدر شانون ، والتي تحدد حد الانضغاط الأقصى للضغط الأقصى ونترون شانون.
قليلا من الرياضيات
إذا كان احتمال حدوث عنصر s i يساوي p (s i) ، فسيكون من الأفضل تمثيل هذا العنصر - بت 2 p (s i) بت. إذا كان من الممكن أثناء التشفير التأكد من تقليل طول جميع العناصر إلى 2 بت (s i) ، فإن طول التسلسل المشفر بالكامل سيكون ضئيلًا لجميع طرق التشفير الممكنة. علاوة على ذلك ، إذا لم يتغير توزيع الاحتمال لجميع العناصر F \u003d (p (s i)) ، وكانت احتمالات العناصر مستقلة عن بعضها البعض ، فيمكن حساب متوسط \u200b\u200bطول الرموز على النحوتسمى هذه القيمة إنتروبيا توزيع الاحتمالات F ، أو إنتروبيا المصدر في وقت معين.
ومع ذلك ، عادةً ما لا يكون احتمال ظهور عنصر مستقلًا ، بل على العكس ، يعتمد على بعض العوامل. في هذه الحالة ، لكل توزيع مشفر جديد s i ، يأخذ توزيع الاحتمال F بعض القيمة F k ، أي لكل عنصر F \u003d F k و H \u003d H k.
بمعنى آخر ، يمكننا القول أن المصدر في الحالة k ، وهو ما يتوافق مع مجموعة معينة من الاحتمالات p k (s i) لجميع العناصر s i.
لذلك ، بالنظر إلى هذا التصحيح ، يمكننا التعبير عن متوسط \u200b\u200bطول الرموز كـ
حيث P k هو احتمال العثور على المصدر في الحالة k.
لذلك ، في هذه المرحلة ، نعلم أن الضغط يعتمد على استبدال العناصر التي تحدث كثيرًا برموز قصيرة ، والعكس بالعكس ، ونعرف أيضًا كيفية تحديد متوسط \u200b\u200bطول الرموز. ولكن ما هو الكود ، الترميز ، وكيف يحدث؟
ترميز بلا ذاكرة
الرموز بدون ذاكرة هي أبسط الرموز على أساسها يمكن ضغط البيانات. في التعليمات البرمجية الخالية من الذاكرة ، يتم استبدال كل حرف في متجه البيانات المشفرة بكلمة مرور من مجموعة بادئة من المتواليات الثنائية أو الكلمات.في رأيي ، وليس التعريف الأكثر وضوحا. النظر في هذا الموضوع بمزيد من التفصيل.
اسمحوا بعض الأبجدية تعطى ![]() يتكون من عدد (محدد) من الحروف. نسمي كل تسلسل محدد من الأحرف من هذه الأبجدية (A \u003d a 1 ، 2 ، ... ، n) في كلمة واحدة، والرقم n هو طول هذه الكلمة.
يتكون من عدد (محدد) من الحروف. نسمي كل تسلسل محدد من الأحرف من هذه الأبجدية (A \u003d a 1 ، 2 ، ... ، n) في كلمة واحدة، والرقم n هو طول هذه الكلمة.
واسمحوا أيضا الأبجدية الأخرى تعطى ![]() . وبالمثل ، يُشار إلى الكلمة في هذه الأبجدية ب
. وبالمثل ، يُشار إلى الكلمة في هذه الأبجدية ب
نقدم اثنين من الرموز الأخرى لمجموعة من جميع الكلمات غير الفارغة في الأبجدية. اسمحوا - عدد الكلمات غير الفارغة في الأبجدية الأولى ، و - في الثانية.
دع أيضًا تعيين F يقترن بكل كلمة A من الأبجدية الأولى كلمة B \u003d F (A) من الثانية. ثم سيتم استدعاء الكلمة B قانون سيتم استدعاء الكلمات A ، والانتقال من الكلمة الأصلية إلى رمزها الترميز.
نظرًا لأن الكلمة يمكن أن تتكون أيضًا من حرف واحد ، يمكننا تحديد مراسلات الأحرف الأبجدية الأولى والكلمات المقابلة من الثانية:
1<-> ب 1
2<-> ب 2
…
ن<-> ب ن
هذه المباراة تسمى مخطط، ويشير ∑.
في هذه الحالة ، تسمى الكلمات B 1 ، B 2 ، ... ، B n رموز الابتدائية، ونوع الترميز مع مساعدتهم - الترميز الأبجدي. بالطبع ، صادف معظمنا هذا النوع من الترميز ، حتى لو كنا لا نعرف كل ما وصفته أعلاه.
لذلك ، قررنا على المفاهيم الأبجدية ، كلمة ، رمز ، و الترميز. الآن نحن نقدم هذا المفهوم بادئة.
دع الكلمة B لها النموذج B \u003d B "B" ". ثم B" تسمى البداية ، أو بادئة الكلمات B ، و B "" - نهايته. هذا تعريف بسيط إلى حد ما ، ولكن تجدر الإشارة إلى أنه بالنسبة لكل كلمة B ، يمكن اعتبار كل من الكلمة الفارغة ʌ ("الفضاء") والكلمة B نفسها بدايات ونهايات.
لذلك ، نقترب من فهم تعريف الرموز بدون ذاكرة. التعريف الأخير الذي نحتاج إلى فهمه هو مجموعة البادئة. يحتوي المخطط property على خاصية البادئة إذا كانت الكلمة B i ليست البادئة للكلمة B j ، بالنسبة لأي 1≤i ، j≤r ، i ≠ j ،
ببساطة ، مجموعة البادئة هي مجموعة محدودة لا يوجد فيها عنصر هو البادئة (أو البداية) لأي عنصر آخر. مثال بسيط على مثل هذه المجموعة ، على سبيل المثال ، الأبجدية العادية.
لذلك ، اكتشفنا التعاريف الأساسية. فكيف يحدث الترميز بدون ذاكرة نفسه؟
يحدث في ثلاث مراحل.
- يتم تجميع الأبجدية Ψ من أحرف الرسالة الأصلية ، مع فرز الأحرف الأبجدية بترتيب تنازلي لاحتمالية حدوثها في الرسالة.
- يرتبط كل رمز a i من الأبجدية word بكلمة معينة B i من مجموعة البادئة Ω.
- يتم تشفير كل حرف ، يليه دمج الرموز في دفق بيانات واحد ، والذي سيكون نتيجة للضغط.
إحدى خوارزميات الكنسي التي توضح هذه الطريقة هي خوارزمية هوفمان.
خوارزمية هوفمان
تستخدم خوارزمية هوفمان تردد حدوث وحدات البايت المتطابقة في كتلة بيانات المدخلات ، وترتبط بالكتل التي تحدث بشكل متكرر لسلسلة من البتات ذات الطول الأقصر ، والعكس بالعكس. هذا الرمز هو الحد الأدنى زائدة. ضع في اعتبارك الحالة عندما تتكون الأبجدية لتيار الإخراج ، بصرف النظر عن دفق الإدخال ، من حرفين فقط - صفر وواحد.بادئ ذي بدء ، عند الترميز باستخدام خوارزمية هوفمان ، نحتاج إلى بناء الدائرة ∑. ويتم ذلك على النحو التالي:
- جميع حروف الأبجدية المدخلة مرتبة بترتيب تنازلي للاحتمال. جميع الكلمات من الأبجدية في دفق الإخراج (أي ما سنقوم بتشفيره) تعتبر في البداية فارغة (أتذكر أن أبجدية دفق الإخراج تتكون فقط من أحرف (0،1)).
- يتم الجمع بين حرفين ، j-1 و j من تدفق المدخلات ، اللذين لهما أقل احتمال لحدوث ، في "رمز زائف" واحد مع احتمال ص يساوي مجموع احتمالات الشخصيات المكونة لها. ثم نلحق 0 ببداية الكلمة B j-1 ، و 1 إلى بداية الكلمة B j ، والتي ستكون فيما بعد رموز الحرف j-1 و j ، على التوالي.
- نزيل هذه الأحرف من أبجدية الرسالة الأصلية ، لكننا نضيف الرمز الزائف الذي تم إنشاؤه إلى هذه الأبجدية (وبطبيعة الحال ، يجب إدراجه في الأبجدية في المكان المناسب ، مع الأخذ في الاعتبار احتماله).
للحصول على توضيح أفضل ، فكر في مثال صغير.
لنفترض أن لدينا أبجدية تتكون من أربعة أحرف فقط - (أ 1 ، 2 ، 3 ، 4). افترض أيضًا أن احتمالية حدوث هذه الرموز متساوية ، على التوالي ، p 1 \u003d 0.5 ؛ ع 2 \u003d 0.24 ؛ ص 3 \u003d 0.15 ؛ ع 4 \u003d 0.11 (مجموع كل الاحتمالات يساوي بوضوح واحد).
لذلك ، سوف نبني مخطط لهذه الأبجدية.
- اجمع الحرفين مع أقل الاحتمالات (0.11 و 0.15) في p "الحرف الزائف".
- نحن ندمج الحرفين مع الاحتمال الأقل (0.24 و 0.26) في الحرف pseudo-character.
- نقوم بإزالة الأحرف المدمجة ، وإدراج الحرف الزائف الناتج في الأبجدية.
- أخيرًا ، اجمع بين الحرفين المتبقيين واحصل على أعلى الشجرة.
إذا أوضحت هذه العملية ، فستحصل على شيء مثل التالي:
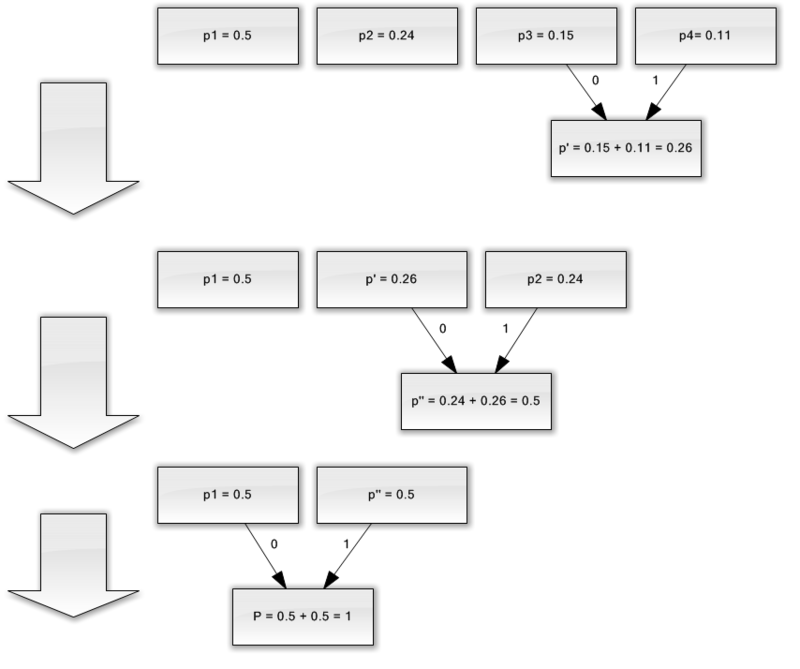
كما ترون ، مع كل دمج ، نقوم بتعيين الأحرف 0 و 1 إلى الأحرف المراد دمجها.
وبالتالي ، عندما يتم بناء الشجرة ، يمكننا بسهولة الحصول على رمز لكل حرف. في حالتنا ، ستبدو الرموز كما يلي:
1 \u003d 0
2 \u003d 11
3 \u003d 100
4 \u003d 101
نظرًا لأن أيا من هذه الرموز يمثل بادئة لأي رمز آخر (أي ، لقد حصلنا على مجموعة بادئة سيئة السمعة) ، يمكننا تحديد كل رمز بشكل فريد في دفق الإخراج.
لذلك ، لقد حققنا أن الشخصية الأكثر شيوعًا يتم تشفيرها بواسطة أقصر الكود ، والعكس.
إذا افترضنا أنه في البداية ، تم استخدام بايت واحد لتخزين كل حرف ، فيمكننا حساب مقدار قدرتنا على تقليل البيانات.
لنفترض أنه كان لدينا سلسلة من 1000 حرف عند الإدخال ، حيث حدث الحرف 1 500 مرة ، و 2 240 ، و 3 150 ، و 4 110 مرة.
في البداية ، احتلت هذه السلسلة 8000 بت. بعد الترميز ، نحصل على سلسلة بطول ∑p i l i \u003d 500 * 1 + 240 * 2 + 150 * 3 + 110 * 3 \u003d 1760 بت. لذلك ، تمكنا من ضغط البيانات 4.54 مرة ، وإنفاق 1.76 بت في المتوسط \u200b\u200bعلى تشفير كل رمز تيار.
دعني أذكرك أنه وفقًا لشانون ، يبلغ متوسط \u200b\u200bطول الرموز. باستبدال قيم الاحتمالات الخاصة بنا في هذه المعادلة ، نحصل على متوسط \u200b\u200bطول الكود الذي يساوي 1.75496602732291 ، وهو قريب جدًا جدًا من النتيجة التي حصلنا عليها.
ومع ذلك ، يجب مراعاة أنه بالإضافة إلى البيانات نفسها ، نحتاج إلى تخزين جدول الترميز ، مما سيزيد قليلاً الحجم النهائي للبيانات المشفرة. من الواضح ، في حالات مختلفة ، يمكن استخدام أشكال مختلفة من الخوارزمية - على سبيل المثال ، يكون في بعض الأحيان أكثر فعالية استخدام جدول الاحتمالات المحدد مسبقًا ، وأحيانًا يكون من الضروري تجميعه ديناميكيًا من خلال تصفح البيانات القابلة للضغط.
استنتاج
لذا ، في هذا المقال حاولت التحدث عنه المبادئ العامة، والذي يحدث به ضغط بدون فقدان ، ويعتبر أيضًا إحدى الخوارزميات الكنسي - تشفير هوفمان.إذا كانت المقالة حسب ذوق مجتمع habro ، فسأكون سعيدًا لكتابة تكملة ، لأن هناك العديد من الأشياء الأكثر إثارة للاهتمام فيما يتعلق بالضغط غير المفقود ؛ هذه خوارزميات كلاسيكية وتحولات بيانات أولية (على سبيل المثال ، تحويل بوروز-ويلر) ، وبطبيعة الحال ، خوارزميات محددة لضغط الصوت والفيديو والصور (الموضوع الأكثر إثارة للاهتمام ، في رأيي).
أدب
- Vatolin D. ، Ratushnyak A. ، Smirnov M. Yukin V. أساليب ضغط البيانات. أرشفة الجهاز والصورة وضغط الفيديو. ISBN 5-86404-170-X ؛ عام 2003
- د. سالومون. ضغط البيانات والصورة والصوت ؛ ISBN 5-94836-027-X ؛ 2004.
محاضرة رقم 4. ضغط المعلومات
مبادئ ضغط المعلومات
الغرض من ضغط البيانات هو توفير تمثيل مضغوط للبيانات التي تم إنشاؤها بواسطة المصدر ، لتخزينها ونقلها بشكل أكثر اقتصادا عبر قنوات الاتصال.
افترض أن لدينا ملف بحجم 1 (واحد) ميغابايت. نحن بحاجة إلى الحصول على ملف أصغر منه. لا يوجد شيء معقد - نبدأ أرشيفي ، على سبيل المثال ، برنامج لضغط الملفات ، ونتيجة لذلك ، نحصل ، على سبيل المثال ، على ملف بحجم 600 كيلو بايت. أين ذهبت 424 كيلو بايت المتبقية؟
يعد ضغط المعلومات أحد طرق ترميزها. بشكل عام ، يتم تقسيم الرموز إلى ثلاث مجموعات كبيرة - رموز الضغط (الرموز الفعالة) ، الرموز المقاومة للضوضاء ، وأكواد التشفير. وتنقسم الرموز المصممة لضغط المعلومات ، بدورها ، إلى رموز ضائعة وأكواد ضائعة. يتضمن الترميز الضياع استعادة بيانات دقيقة تمامًا بعد فك التشفير ويمكن استخدامه لضغط أي معلومات. عادةً ما يكون للترميز الفاسد معدل ضغط أعلى بكثير من الترميز غير المفقود ، ولكنه يسمح ببعض الانحرافات للبيانات المشفرة من الأصل.
أنواع الضغط
يمكن تقسيم جميع أساليب ضغط المعلومات إلى فئتين كبيرتين مفكويتين: الضغط باستخدام خسارة المعلومات والضغط بدون خسارة المعلومات.
ضغط دون فقدان المعلومات.
تهمنا أساليب الضغط هذه أولاً وقبل كل شيء ، حيث يتم استخدامها بدقة عند إرسال المستندات والبرامج النصية ، أو عند إصدار العمل المكتمل إلى أحد العملاء ، أو عند إنشاء نسخ احتياطية من المعلومات المخزنة على جهاز كمبيوتر.
لا يمكن أن تسمح طرق الضغط في هذه الفئة بفقدان المعلومات ، وبالتالي فهي تعتمد فقط على التخلص من التكرار ، كما أن المعلومات لها تكرار دائمًا تقريبًا (على الرغم من عدم قيام شخص ما بتكثيفها من قبل). إذا لم يكن هناك تكرار ، فلن يكون هناك شيء للضغط.
هنا مثال بسيط. تحتوي اللغة الروسية على 33 حرفًا وعشرة أرقام وحوالي عشرة علامات ترقيم وشخصيات خاصة أخرى. للنص الذي يتم تسجيله فقط في الحروف الروسية العاصمة (كما هو الحال في البرقيات والأشعة) ستون معاني مختلفة كانت كافية. ومع ذلك ، عادةً ما يتم تشفير كل حرف في بايت يحتوي على 8 بت ويمكن التعبير عن 256 رموز مختلفة. هذا هو الأساس الأول للتكرار. بالنسبة للنص "التلغرافي" الخاص بنا ، ستكون ستة بتات لكل حرف كافية.
هنا مثال آخر. في ترميز الأحرف الدولية ASCII يتم تخصيص نفس عدد البتات لترميز أي حرف (8) ، بينما كان الجميع يدركون جيدًا أن الأحرف الأكثر شيوعًا لها معنى في الترميز باستخدام عدد أقل من الأحرف. لذلك ، على سبيل المثال ، في "شفرة مورس" ، يتم تشفير الأحرف "E" و "T" ، التي يتم العثور عليها غالبًا ، بحرف واحد (على التوالي ، هذه نقطة وشرطة). ويتم ترميز الأحرف النادرة مثل "Yu" (- -) و "Ts" (- -) بأربعة أحرف. الترميز غير الفعال هو السبب الثاني للتكرار. يمكن أن تقوم البرامج التي تقوم بضغط البيانات بإدخال الترميز الخاص بها (مختلف عن الملفات المختلفة) وتعيين جدول معين (قاموس) للملف المضغوط ، والذي سيكتشف منه برنامج فك الحزم كيفية ترميز بعض الرموز أو مجموعاتها في هذا الملف. تسمى الخوارزميات القائمة على تحويل الشفرة للمعلومات خوارزميات هوفمان.
وجود شظايا مكررة هو السبب الثالث للتكرار. هذا أمر نادر الحدوث في النصوص ، لكن تكرار الرموز في الجداول والرسوم البيانية أمر شائع. لذلك ، على سبيل المثال ، إذا تم تكرار الرقم 0 عشرين مرة متتالية ، فلا معنى لذلك وضع عشرين بايت صفر. وبدلاً من ذلك ، وضعوا صفراً واحداً ومعاملاً لـ 20. وتسمى هذه الخوارزميات القائمة على كشف التكرار طرقRLE (جولة طول ترميز).
تتميز تسلسلات التكرار الكبيرة من البايتات المتماثلة بشكل خاص بالرسومات التوضيحية ، ولكن ليس بالتصوير الفوتوغرافي (هناك الكثير من الضوضاء والنقاط المجاورة تختلف اختلافًا كبيرًا في المعلمات) ، ولكن تلك التي يرسمها الفنانون بلون "سلس" ، كما في الأفلام المتحركة.
ضغط ضائع.
يعني الضغط مع فقد المعلومات أنه بعد تفريغ الأرشيف المضغوط ، سنتلقى مستندًا مختلفًا قليلاً عن المستند الذي كان في البداية. من الواضح أنه كلما زادت درجة الانضغاط ، زاد حجم الخسارة والعكس بالعكس.
بالطبع ، لا تنطبق هذه الخوارزميات على المستندات النصية ، وجداول قواعد البيانات ، وخاصة بالنسبة للبرامج. يمكنك التغلب بطريقة أو بأخرى على التشوهات البسيطة في نص عادي وغير منسق ، لكن تشويه جزء واحد على الأقل في البرنامج سيجعله غير فعال تمامًا.
في الوقت نفسه ، توجد مواد تستحق التضحية بعدة بالمائة من المعلومات من أجل الحصول على ضغط عشرات المرات. وتشمل هذه الرسوم التوضيحية ، وأشرطة الفيديو ، والمؤلفات الموسيقية. يُعتبر فقدان المعلومات أثناء الضغط والتفريغ اللاحق في مثل هذه المواد مظهرًا لبعض "الضوضاء" الإضافية. ولكن نظرًا لأنه لا يزال هناك "ضجيج" معين عند إنشاء هذه المواد ، فإن الزيادة الصغيرة لا تبدو دائمًا حرجة ، ويعطي المكسب في أحجام الملفات زيادة كبيرة (10-15 مرة على الموسيقى ، و 20-30 مرة على مواد الصور والفيديو).
تتضمن خوارزميات الضغط المفقودة خوارزميات معروفة مثل JPEG و MPEG. يتم استخدام خوارزمية JPEG عند ضغط الصور. تحتوي ملفات الصور المضغوطة بهذه الطريقة على امتداد jpg. تستخدم خوارزميات MPEG عند ضغط الفيديو والموسيقى. يمكن أن يكون لهذه الملفات امتدادات متعددة ، اعتمادًا على البرنامج المحدد ، ولكن الأكثر شهرة هي .MPG للفيديو و MP3 للموسيقى.
يتم استخدام خوارزميات ضغط فقد المعلومات فقط من أجل مهام المستهلك. هذا يعني ، على سبيل المثال ، أنه في حالة إرسال صورة للعرض ، والموسيقى للتشغيل ، يمكن تطبيق هذه الخوارزميات. إذا تم نقلها لمزيد من المعالجة ، على سبيل المثال للتحرير ، فلا يجوز فقدان المعلومات في المادة المصدر.
يمكن عادة التحكم في حجم الخسارة المسموح بها في الضغط. هذا يسمح لك بتجربة وتحقيق نسبة الحجم / الجودة الأمثل. في الرسوم التوضيحية الفوتوغرافية المراد عرضها على الشاشة ، عادة ما يكون فقدان 5٪ من المعلومات غير حاسم ، وفي بعض الحالات يمكن تحمل نسبة تتراوح بين 20 و 25٪.
خوارزميات ضغط ضياع
شانون فينو كود
لمزيد من المناقشة ، سيكون من المناسب تقديم ملف المصدر الخاص بنا مع النص كمصدر للأحرف التي تظهر واحدة في كل مرة عند إخراجها. لا نعرف مقدمًا ما هي الشخصية التي ستكون التالية ، لكننا نعرف أنه مع الاحتمال p1 ، ستظهر الرسالة "a" ، مع الاحتمال p2 ، تظهر الحرف "b" ، إلخ.
في أبسط الحالات ، سنعتبر أن جميع أحرف النص مستقلة عن بعضها البعض ، أي لا يعتمد احتمال ظهور الحرف التالي على قيمة الحرف السابق. بالطبع ، ليس هذا بالنسبة لنص ذي معنى ، لكننا الآن نفكر في وضع مبسط للغاية. في هذه الحالة ، العبارة "يحمل الرمز مزيدًا من المعلومات ، وأقل احتمال حدوثه."
دعونا نتخيل نصًا يتكون حرفه من 16 حرفًا فقط: A ، B ، C ، D ، D ، E ، F ، Z ، I ، K ، L ، M ، H ، O ، P ، P. تشفير مع 4 بتات فقط: من 0000 إلى 1111. تخيل الآن أن احتمال حدوث هذه الأحرف يتم توزيعه على النحو التالي:
مجموع هذه الاحتمالات هو ، بالطبع ، واحد. نقسم هذه الرموز إلى مجموعتين بحيث يكون الاحتمال الكلي لرموز كل مجموعة ~ 0.5 (الشكل). في مثالنا ، ستكون هذه مجموعات الشخصيات AB و GR. تسمى الدوائر الموجودة في الشكل ، والتي تشير إلى مجموعات من الأحرف ، رؤوسًا أو عقدًا ، وتسمى بنية هذه العقد باسم شجرة ثنائية (شجرة B). عيّن كل عقدة الكود الخاص بها ، مع تحديد عقدة واحدة بالرقم 0 ، والأخرى بالرقم 1.
مرة أخرى ، نقسم المجموعة الأولى (AB) إلى مجموعتين فرعيتين بحيث يكون مجموع الاحتمالات قريبة من بعضها البعض قدر الإمكان. أضف الرقم 0 إلى رمز المجموعة الفرعية الأولى ، والرقم 1 إلى رمز المجموعة الثانية. 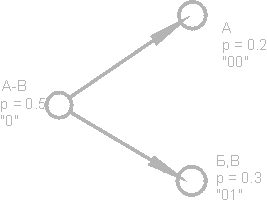
سنكرر هذه العملية حتى يبقى رمز واحد في كل قمة من "شجرة" لدينا. شجرة كاملة للأبجدية لدينا لديها 31 العقد.
رموز الأحرف (العقد أقصى اليمين من الشجرة) لها رموز طول غير متساو. لذلك ، يتم تشفير الحرف A ، الذي له الاحتمال p \u003d 0.2 لنصنا الوهمي ، ببتين فقط ، والحرف P (غير موضح في الشكل) ، والذي له الاحتمال p \u003d 0.013 ، يتم ترميزه بمجموعة مكونة من ست بتات.
لذلك ، المبدأ واضح - يتم ترميز الأحرف التي تحدث بشكل متكرر مع عدد أقل من البتات ، ونادراً ما يتم ترميز الأحرف التي تحدث. نتيجة لذلك ، فإن متوسط \u200b\u200bعدد البتات لكل حرف يساوي
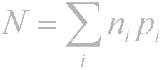
حيث ni هو عدد البتات التي تشفر الحرف i-th ، pi هو احتمال حدوث الحرف i.
كود هوفمان.
تطبق خوارزمية هوفمان بأمان الفكرة العامة للتشفير الإحصائي باستخدام مجموعات بادئة وتعمل على النحو التالي:
1. نكتب في صف واحد كل حروف الأبجدية بترتيب تصاعدي أو تنازلي لاحتمالية حدوثها في النص.
2. ضم باستمرار بين الرمزين مع أقل احتمالات الحدوث في رمز مركب جديد ، يفترض أن احتمال حدوثه يساوي مجموع احتمالات الرموز المكونة له. في النهاية ، سنقوم ببناء شجرة ، لكل عقدة منها احتمال كامل لجميع العقد تحتها.
3. نقوم بتتبع المسار إلى كل ورقة من الشجرة ، مع تحديد الاتجاه إلى كل عقدة (على سبيل المثال ، إلى اليمين - 1 ، إلى اليسار - 0). يعطي التسلسل الناتج كلمة مشفرة تقابل كل حرف (الشكل).
بناء شجرة رمز لرسالة مع الأبجدية التالية:
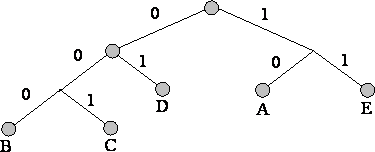
عيوب الطرق
أكبر صعوبة في الرموز ، كما يلي من المناقشة السابقة ، هي الحاجة إلى وجود جداول الاحتمالات لكل نوع من البيانات القابلة للضغط. هذه ليست مشكلة إذا كان من المعروف أن النص باللغة الإنجليزية أو الروسية يتم ضغطه ؛ نحن ببساطة نوفر التشفير وفك الشفرة مع شجرة رمز مناسبة للنصوص الإنجليزية أو الروسية. في الحالة العامة ، عندما يكون احتمال وجود أحرف لبيانات الإدخال غير معروف ، فإن الرموز الثابتة لهوفمان تعمل بكفاءة.
يتمثل حل هذه المشكلة في التحليل الإحصائي للبيانات المشفرة ، والذي يتم إجراؤه أثناء التمرير الأول للبيانات ، وتجميع شجرة الكود استنادًا إلى ذلك. في الواقع ، يتم تنفيذ الترميز بواسطة التمريرة الثانية.
عيب آخر من الرموز هو أن الحد الأدنى لطول كلمة المرور بالنسبة لهم لا يمكن أن يكون أقل من واحد ، في حين أن entropy الرسالة يمكن أن يكون 0.1 و 0.01 بت / حرف. في هذه الحالة ، يصبح الرمز زائداً عن الحاجة. يتم حل المشكلة عن طريق تطبيق الخوارزمية على كتل من الأحرف ، ولكن بعد ذلك يتم إجراء تشفير / فك تشفير معقد وتوسعة شجرة الكود بشكل كبير ، والتي يجب حفظها في النهاية مع الكود.
لا تأخذ هذه الرموز في الاعتبار العلاقة بين الأحرف الموجودة في أي نص تقريبًا. على سبيل المثال ، إذا رأينا الحرف q في نص باللغة الإنجليزية ، فيمكننا أن نقول بثقة أن الحرف u سوف يتبعه.
ترميز المجموعة - ترميز طول التشغيل (RLE) - واحدة من أقدم وأسهل خوارزميات الأرشفة. يحدث الضغط في RLE عن طريق استبدال سلاسل البايتات المتماثلة بأزواج العداد والقيمة. ("أحمر ، أحمر ، ... ، أحمر" مكتوب كـ "أحمر أحمر").
أحد تطبيقات الخوارزمية هو كما يلي: يبحثون عن البايتات الأقل تكرارًا ، ويسمونها بادئة ، ويستبدلون سلاسل الأحرف المتطابقة بـ "البادئة ، العداد ، القيمة". إذا تم العثور على هذه البايت في الملف المصدر مرة أو مرتين على التوالي ، فسيتم استبداله بزوج من "البادئة ، 1" أو "البادئة ، 2". لا يزال هناك زوج واحد غير مستخدم "بادئة ، 0" ، والذي يمكن استخدامه كعلامة على نهاية البيانات المحزومة.
عند ترميز ملفات exe ، يمكنك البحث وحزم تسلسلات النموذج AxAyAzAwAt ... ، والتي غالبًا ما توجد في الموارد (سلاسل في ترميز Unicode)
تتضمن الجوانب الإيجابية للخوارزمية حقيقة أنها لا تتطلب ذاكرة إضافية عند العمل ، ويتم تنفيذها بسرعة. يتم استخدام الخوارزمية في تنسيقات PCX و TIFF و BMP. من الميزات المهمة في ترميز المجموعات في PCX أنه يمكن زيادة درجة الأرشفة لبعض الصور بشكل كبير فقط عن طريق تغيير ترتيب الألوان في لوحة الصورة.
يعد كود LZW (Lempel-Ziv & Welch) واحدًا من أكثر رموز الضغط شيوعًا. بمساعدة التعليمات البرمجية LZW ، يتم إجراء الضغط بتنسيقات رسومية مثل TIFF و GIF ، بمساعدة تعديلات LZW ، يقوم الكثير من المحفوظات العالمية بأداء وظائفهم. تعتمد الخوارزمية على البحث في ملف الإدخال عن تسلسلات متكررة من الأحرف المشفرة في مجموعات من 8 إلى 12 بت في الطول. وبالتالي ، تتمتع هذه الخوارزمية بأكبر قدر من الكفاءة في الملفات النصية وملفات الرسومات ، حيث توجد أقسام كبيرة أحادية اللون أو تسلسلات متكررة من البيكسلات.
أدى غياب فقدان المعلومات أثناء تشفير LZW إلى الاستخدام الواسع النطاق لتنسيق TIFF بناءً عليه. لا يفرض هذا التنسيق أي قيود على حجم الصورة وعمقها ولونها واسع الانتشار ، على سبيل المثال ، في الطباعة. يعد التنسيق الآخر المستند إلى LZW - GIF - أكثر بدائية - فهو يتيح لك تخزين الصور بعمق ألوان لا يزيد عن 8 بت / بكسل. في بداية ملف GIF توجد لوحة - جدول يحدد المراسلات بين فهرس الألوان - رقمًا في النطاق من 0 إلى 255 وقيمة ألوان حقيقية 24 بت.
خوارزميات ضغط فقدان المعلومات
تم تطوير خوارزمية JPEG بواسطة مجموعة من الشركات تسمى مجموعة خبراء التصوير المشترك. كان الهدف من المشروع هو إنشاء معيار ضغط عالي الكفاءة لكل من الصور بالأبيض والأسود والألوان ، وقد تم تحقيق هذا الهدف بواسطة المطورين. حاليًا ، يتم استخدام JPEG على نطاق واسع حيث يتطلب الأمر درجة عالية من الضغط - على سبيل المثال ، على الإنترنت.
على عكس خوارزمية LZW ، فإن تشفير JPEG هو ترميز ضياع. تعتمد خوارزمية الترميز نفسها على رياضيات معقدة للغاية ، ولكن بشكل عام يمكن وصفها على النحو التالي: يتم تقسيم الصورة إلى مربعات من 8 * 8 بكسل ، ثم يتم تحويل كل مربع إلى سلسلة متسلسلة من 64 بكسل. علاوة على ذلك ، تتعرض كل سلسلة من هذه المحولات إلى ما يسمى تحويل DCT ، والذي يعد أحد أنواع تحويل فورييه المنفصل. يكمن في حقيقة أن تسلسل إدخال البكسل يمكن تمثيله كمجموع المكونات الجيبية وجيب التمام مع ترددات متعددة (ما يسمى التوافقيات). في هذه الحالة ، نحتاج إلى معرفة سعة هذه المكونات فقط لاستعادة تسلسل الإدخال بدرجة كافية من الدقة. كلما زادت المكونات التوافقية التي نعرفها ، قل التناقض بين الصورة الأصلية والصورة المضغوطة. تسمح لك معظم برامج تشفير JPEG بضبط نسبة الضغط. يتم تحقيق ذلك بطريقة بسيطة للغاية: فكلما ارتفعت نسبة الضغط ، انخفض التوافقيات لكل كتلة 64 بكسل.
بطبيعة الحال ، قوة هذا النوع من الترميز هي نسبة ضغط كبيرة مع الحفاظ على عمق اللون الأصلي. هذه الخاصية هي التي تسببت في استخدامها على نطاق واسع على شبكة الإنترنت ، حيث يكون لخفض حجم الملف أهمية قصوى ، في الموسوعات متعددة الوسائط ، حيث يلزم تخزين أكبر قدر ممكن من الرسومات في كمية محدودة.
لا يمكن استرداد خاصية سلبية لهذا التنسيق بأي حال من الأحوال ، وتدهورها المتأصل في جودة الصورة. هذه هي الحقيقة المحزنة التي لا تسمح باستخدامها في الطباعة ، حيث الجودة هي الأهمية القصوى.
ومع ذلك ، فإن تنسيق JPEG ليس حد الكمال في الرغبة في تقليل حجم الملف النهائي. في الآونة الأخيرة ، يجري البحث المكثف في مجال ما يسمى تحويل المويجات (أو تحويل الاندفاع). استنادًا إلى المبادئ الرياضية الأكثر تعقيدًا ، تسمح لك برامج تشفير المويجات بالحصول على ضغط أكبر من JPEG ، مع فقد معلومات أقل. على الرغم من تعقيد رياضيات تحويل المويجات ، إلا أنه أبسط في تنفيذ البرامج من JPEG. على الرغم من أن خوارزميات ضغط المويجات لا تزال في بدايتها ، إلا أنها تتمتع بمستقبل رائع.
ضغط كسورية
ضغط الصورة النمطي هندسي متكرر هو عبارة عن خوارزمية ضغط الصورة المفقودة استنادًا إلى تطبيق أنظمة الوظائف القابلة للتكرار (IFS ، والتي عادة ما تكون تحويلات متقاربة) إلى الصور. تُعرف هذه الخوارزمية بحقيقة أنها تسمح في بعض الحالات بالحصول على نسب انضغاط عالية جدًا (أفضل الأمثلة تصل إلى 1000 مرة بجودة مرئية مقبولة) للصور الحقيقية للكائنات الطبيعية ، والتي لا تتوفر لخوارزميات ضغط الصور الأخرى من حيث المبدأ. بسبب الوضع الصعب مع تسجيل براءات الاختراع ، لم يتم استخدام الخوارزمية على نطاق واسع.
يعتمد الأرشفة النمطي هندسي متكرر على حقيقة أنه باستخدام معاملات نظام من الوظائف القابلة للتكرار ، يتم تقديم الصورة في شكل أكثر إحكاما. قبل أن ننظر إلى عملية الأرشفة ، دعونا نلقي نظرة على كيفية قيام IFS بإنشاء صورة.
بالمعنى الدقيق للكلمة ، IFS هي مجموعة من التحولات ثلاثية الأبعاد التي تترجم صورة واحدة إلى أخرى. يتم تحويل النقاط في الفضاء ثلاثي الأبعاد (إحداثي س ، إحداثي ص ، سطوع).
أساس طريقة الترميز النمطي هندسي متكرر هو اكتشاف مقاطع متشابهة ذاتياً في الصورة. تم دراسة إمكانية تطبيق نظرية أنظمة الوظائف القابلة للتكرار (IFS) على مشكلة ضغط الصور بواسطة مايكل بارنسلي وألان سلون. لقد قاموا ببراءة فكرتهم في عامي 1990 و 1991. قدم Jacquin طريقة ترميز كسورية تستخدم كتل النطاق الفرعي والمجال ، كتل مربعة الشكل تغطي الصورة بأكملها. أصبح هذا النهج الأساس لمعظم طرق الترميز كسورية المستخدمة اليوم. تم تطويره من قبل يوفال فيشر وعدد من الباحثين الآخرين.
وفقًا لهذه الطريقة ، يتم تقسيم الصورة إلى العديد من الصفحات الفرعية غير المتداخلة (النطاقات الفرعية للنطاق) ويتم تحديد الكثير من الحدود الفرعية للنطاقات المتداخلة (النطاقات الفرعية للنطاق). لكل كتلة تصنيف ، تعثر خوارزمية الترميز على أنسب مجال وتحويل تقريبي يترجم كتلة المجال هذه إلى كتلة تصنيف معينة. يتم تعيين بنية الصورة إلى نظام من كتل التصنيف ، وكتل المجال ، والتحويلات.
الفكرة هي: افترض أن الصورة الأصلية هي نقطة ثابتة لنوع من التعيينات المضغوطة. بعد ذلك ، بدلاً من الصورة نفسها ، من الممكن أن تتذكر هذا العرض بطريقة أو بأخرى ، وبالنسبة للاستعادة يكفي تطبيق هذه الشاشة بشكل متكرر على أي صورة بدء.
وفقًا لنظرية Banach ، تؤدي مثل هذه التكرارات دائمًا إلى نقطة ثابتة ، أي إلى الصورة الأصلية. في الممارسة العملية ، تكمن الصعوبة بأكملها في العثور على العرض الانضغاطي الأنسب من الصورة وفي مساحة التخزين المدمجة. كقاعدة عامة ، تعتبر خوارزميات البحث عن الخرائط (أي خوارزميات الضغط) قوة شديدة وتتطلب تكاليف حسابية كبيرة. في نفس الوقت ، خوارزميات الاسترداد فعالة وسريعة للغاية.
باختصار ، يمكن وصف الطريقة التي اقترحها بارنسلي على النحو التالي. يتم تشفير الصورة من خلال العديد من التحولات البسيطة (في حالتنا ، affine) ، أي أنه يتم تحديدها بواسطة معاملات هذه التحولات (في حالتنا A و B و C و D و E و F).
على سبيل المثال ، يمكن ترميز صورة منحنى Koch بأربعة تحويلات متقاربة ، وسوف نحددها بشكل فريد باستخدام 24 معاملات فقط.
نتيجة لذلك ، ستنتقل النقطة بالضرورة إلى مكان ما داخل المنطقة السوداء في الصورة الأصلية. بعد القيام بهذه العملية عدة مرات ، سنملأ كل المساحة السوداء ، وبالتالي استعادة الصورة.

الأكثر شهرة هي صورتين تم الحصول عليها باستخدام IFS: مثلث Sierpinski و السرخس Barnsley. يتم تعريف الأول بثلاثة ، والثاني بخمسة تحويلات متقاربة (أو ، في مصطلحاتنا ، العدسات). يتم تحديد كل تحويل بواسطة وحدات البايت المقروءة حرفيًا ، في حين أن الصورة التي تم إنشاؤها بمساعدتها قد تستغرق عدة ميغابايت.
يصبح من الواضح كيف يعمل الأرشيف ، ولماذا يستغرق الكثير من الوقت. في الواقع ، فإن الضغط الكسري هو البحث عن مناطق متشابهة ذاتياً في الصورة وتحديد معلمات التحولات الخاصة بهم.
في أسوأ الحالات ، إذا لم يتم استخدام خوارزمية التحسين ، فسيتطلب ذلك تعداد ومقارنة جميع أجزاء الصورة الممكنة ذات الأحجام المختلفة. حتى بالنسبة للصور الصغيرة مع مراعاة السرية ، نحصل على عدد من الخيارات الفلكية للبحث فيها. حتى التضييق الحاد في فئات التحويل ، على سبيل المثال ، بسبب التوسع في عدد معين من المرات ، لن يسمح بتحقيق وقت مقبول. بالإضافة إلى ذلك ، يتم فقد جودة الصورة. تهدف الغالبية العظمى من الدراسات في مجال الانضغاط النمطي هندسيًا إلى تقليل وقت الأرشفة المطلوب للحصول على صور عالية الجودة.
بالنسبة إلى خوارزمية الانكسار الانضغاطي ، وكذلك خوارزميات الانضغاط الضاغطة الأخرى ، فإن الآليات التي من خلالها يمكن التحكم في نسبة الضغط ودرجة الضياع مهمة للغاية. حتى الآن ، تم تطوير مجموعة كبيرة بما فيه الكفاية من هذه الأساليب. أولاً ، من الممكن الحد من عدد التحويلات ، مع توفير نسبة ضغط لا تقل عن قيمة ثابتة. ثانياً ، يمكنك أن تطلب في المواقف التي يكون فيها الفرق بين الشظية التي تتم معالجتها وأفضل تقريب لها أعلى من قيمة عتبة معينة ، يتم بالضرورة سحق هذه القطعة (يجب أن تكون هناك عدسات عديدة مجروحة). ثالثًا ، من الممكن منع تجزئة الأجزاء الأصغر من ، على سبيل المثال ، أربع نقاط. عن طريق تغيير قيم العتبة وأولوية هذه الشروط ، يمكنك التحكم بمرونة كبيرة في نسبة ضغط الصورة: من المطابقة في اتجاه البت إلى أي نسبة ضغط.
مقارنة مع JPEG
اليوم ، خوارزمية أرشفة الرسومات الأكثر شيوعًا هي JPEG. قارن ذلك مع ضغط كسورية.
أولاً ، نلاحظ أن كل من الآخر والآخر يعملان بصور كاملة الألوان 8 بت (بتدرج الرمادي) و 24 بت بالألوان الكاملة. كلاهما خوارزميات ضغط ضياع ويوفر نسب الأرشفة وثيق. كل من الخوارزمية كسورية و JPEG لديهم الفرصة لزيادة نسبة الضغط عن طريق زيادة الخسائر. بالإضافة إلى ذلك ، كلتا الخوارزميات متوازنة بشكل جيد للغاية.
تبدأ الاختلافات إذا أخذنا في الاعتبار الوقت الذي تستغرقه الخوارزميات لأرشفة / فك الضغط. لذلك ، الخوارزمية كسورية يضغط المئات وحتى آلاف المرات أطول من JPEG. تفريغ الصورة ، على العكس من ذلك ، سوف يحدث أسرع 5-10 مرات. لذلك ، إذا كان سيتم ضغط الصورة مرة واحدة فقط ، ويتم نقلها عبر الشبكة وتفريغها عدة مرات ، فسيكون من الأفضل استخدام الخوارزمية الكسورية.
يستخدم JPEG تحلل الصورة في وظائف جيب التمام ، بحيث تظهر الخسارة فيه (حتى في الحد الأدنى المحدد للخسارة) في الأمواج والهالات على حدود التحولات اللونية الحادة. لهذا الغرض لا يرغبون في استخدامه عند ضغط الصور المعدة للطباعة عالية الجودة: يمكن أن يصبح هذا التأثير ملحوظًا للغاية.
الخوارزمية كسورية خالية من هذا العيب. علاوة على ذلك ، عند طباعة صورة ، يجب عليك إجراء عملية تحجيم في كل مرة ، لأن خطوط المسح (أو الخطوط) لجهاز الطباعة لا تتزامن مع خطوط المسح. عند التحويل ، يمكن أن تحدث أيضًا العديد من التأثيرات غير السارة ، والتي يمكن مكافحتها إما عن طريق تحجيم الصورة برمجيًا (لأجهزة الطباعة منخفضة التكلفة مثل طابعات الليزر التقليدية وطابعات نفث الحبر) ، أو عن طريق تزويد جهاز الطباعة بمعالجها الخاص ، ومحركها الصلب ، ومجموعة من برامج معالجة الصور (لأنواع الصور الفوتوغرافية باهظة الثمن). كما قد تتخيل ، عند استخدام الخوارزمية كسورية ، لا تنشأ مثل هذه المشاكل من الناحية العملية.
لن يحدث الإطاحة بتنسيق JPEG بواسطة الخوارزمية الكسورية للاستخدام الواسع قريبًا (على الأقل بسبب انخفاض سرعة أرشفة الأخير) ، ومع ذلك ، في مجال تطبيقات الوسائط المتعددة ، في ألعاب الكمبيوتر ، يكون استخدامه مبررًا.
في الجزء الأول ، سننظر في تنسيقات الصوت. ما هي FLAC و WavPack و TAK و Monkey's Audio و OptimFROG و ALAC و WMA و Shorten و LA و TTA و LPAC و MPEG-4 ALS و MPEG-4 SLS و Real Lossless؟ هل تعرف عدد أنواع الصوت؟ الملفات ، حتى الآن ، نحن نتعامل مع تنسيقات ضغط الصوت بدون فقدان ، وننظر في إجابة السؤال حول عدد امتدادات الصوت في نهاية المقالة.
لذلك ، أولاً نحدد المصطلحات:
« خوارزمية "هذا وصف دقيق يحدد العملية الحسابية التي تنتقل من بيانات المصدر المتغير إلى النتيجة المرجوة."
« الترميز (برنامج ترميز إنجليزي ، من جهاز تشفير / وحدة فك تشفير - جهاز تشفير / وحدة فك تشفير - جهاز تشفير / وحدة فك تشفير أو ضاغط / أداة فك ضغط) - جهاز أو برنامج قادر على تحويل البيانات أو الإشارة. بإمكان برامج الترميز إما تشفير دفق / إشارة (غالبًا للإرسال أو التخزين أو التشفير) أو فك تشفيرها لعرضها أو تغييرها بتنسيق أكثر ملاءمة لهذه العمليات. غالبًا ما تستخدم برامج الترميز في المعالجة الرقمية للفيديو والصوت.
تستخدم معظم برامج الترميز للبيانات الصوتية والمرئية ضغطًا ضياعًا للحصول على حجم مقبول للملف النهائي (المضغوط). هناك أيضًا برامج ترميز ضغط بدون فقد. "
« ضغط ضياع (ضغط البيانات باللغة الإنجليزية المفقودة) هي طريقة لضغط المعلومات ، والتي يمكن من خلالها استعادة المعلومات المشفرة بدقة إلى البتات. في هذه الحالة ، تتم استعادة البيانات الأصلية تمامًا من الحالة المضغوطة. لكل نوع من أنواع المعلومات الرقمية ، كقاعدة عامة ، هناك خوارزميات ضغط ضياع الخاصة بهم. "
يتم استخدام ضغط البيانات المفقود عندما تكون هوية البيانات المضغوطة إلى الأصل مهمة. مثال شائع هو الملفات القابلة للتنفيذ والمستندات والكود المصدري. تسمى البرامج التي تستخدم تنسيقات الضغط غير المفقودة بأرشيفات ، ويعرف الجميع تنسيقات الملفات الشائعة ZIP أو RAR أو Unix-utility Gzip وما إلى ذلك. كل هذه البرامج تختلف في الخوارزميات المطبقة (واحدة أو عدة) ، وبالتالي فإن خصائص الضغط المختلفة لملفات مختلفة.
الجزء الأول - النظرية:
يمكن توزيع طرق الضغط أو خوارزميات الضغط غير المفقودة حسب نوع البيانات التي تم إنشاؤها من أجلها. هناك ثلاثة أنواع رئيسية من البيانات: النص والصور والصوت.
من حيث المبدأ ، يمكن استخدام أي خوارزمية لضغط البيانات متعددة الأغراض بدون فقدان (تعني متعددة الأغراض أنه يمكن معالجة أي نوع من البيانات الثنائية) لأي نوع من البيانات ، ولكن معظمها غير فعال لكل نوع رئيسي. على سبيل المثال ، لا يمكن ضغط بيانات الصوت جيدًا بواسطة خوارزمية ضغط النص والعكس.
من بين طرق الضغط ، يمكن ملاحظة ما يلي - ضغط الإنتروبيا ، طرق القاموس ، الأساليب الإحصائية. كل طريقة جيدة لنوع معين من البيانات وتتضمن عددًا من الخوارزميات.
ضغط الانتروبي: خوارزمية هوفمان · خوارزمية هوفمان التكيفية · ترميز الحساب (شانون - خوارزمية الفانو · الفاصل الزمني) · رموز غولومب · دلتا · الكود العالمي (إلياس · فيبوناتشي)
أساليب المفردات: RLE · يدحض · LZ (LZ77 / LZ78 · LZSS · LZW · LZWL · LZO · LZMA · LZX · LZRW · LZJB · LZT)
تتضمن خوارزميات النماذج الإحصائية للنص (أو البيانات النصية الثنائية مثل الملفات القابلة للتنفيذ) ما يلي: تحويل Barrows-Wheeler (المعالجة المسبقة لفرز البلوك التي تجعل الضغط أكثر فعالية) · LZ77 و LZ78 (باستخدام DEFLATE) · LZW.
أخرى: RLE · CTW · BWT · MTF · PPM · DMC
غالبًا ما تحصل فقط الخوارزميات المطورة جيدًا على اسم ، في حين أن التطورات الأخيرة لا تعني سوى (الاستخدام العام ، والتوحيد القياسي ، وما إلى ذلك) أو غير محددة على الإطلاق.
لكن العودة إلى موضوعنا. لتشفير الخوارزميات المناسبة للبيانات الصوتية:
خوارزمية هوفمان (تستخدم أيضًا DEFLATE) ، الترميز الحسابي
أبل ضياع — ALAC (برنامج الترميز الصوتي بدون فقدان لـ Apple)
ترميز الصوت ضياع — المعروف أيضًا باسم MPEG-4 ALS
ضياع ترميز الصوت الحر — FLAC
الزوال التعبئة ضياع — MLP
قرد الصوت — القرد
OptimFROG
ريال بلاير — RealAudio ضياع
تقصير — SHN
TAK — (T) om "verlustfreier (A) udio (K) ompressor (German)
TTA — صحيح ضياع الصوت
WavPack — Wavpack ضياع
ماجدة الرومي ضياع — ويندوز بلا خسائر
DTS — DTS الصوت المحيطي
عائلة Lempel-Ziv من الخوارزميات ، RLE (ترميز طول التشغيل)
FLAC (مجاني ترميز الصوت ضياع)
صوت القرد (القرد)
TTA (صوت حقيقي)
TTE
LA(LosslessAudio)
RealAudio ضياع
WavPack وغيرها
كما لاحظت ، تستخدم معظم برامج الترميز للضغط بدون ضياع نوعين مختلفين من الخوارزميات (في بعض الأحيان): أحدهما ينشئ نموذجًا إحصائيًا لبيانات الإدخال ، والآخر يعرض بيانات الإدخال في تمثيل بت ، باستخدام النموذج للحصول على "احتمالي" (أي ، كثيرا ما تتم مصادفته) البيانات التي يتم استخدامها أكثر من "لا تصدق". الفائدة - تقليل الحجم ، والحساب - مزيد من وقت المعالج المطلوب للتشفير / فك التشفير.
عندما اكتشفنا نظرية صغيرة ، سننتقل إلى برامج الترميز الخاصة بنا لضغط البيانات الصوتية ، والتي كتبها عدد كبير منها: Free Codless Audio Codec ، WavPack ، TAK ، Monkey's Audio (.ape ، apl) ، OptimFROG (.ofr) ، Apple Lossless Audio Codec ، WMA ، اختصار (.SHN) ، LosslessAudio ، صوت حقيقي ، برنامج ترميز صوتي بلا خسائر (.LPAC) ، MPEG-4 ALS ، MPEG-4 SLS (.mp4) ، Reallessless أو RealAudio Lossless ، Windows Media Audio Lossless ، DTS .. وهذا أبعد ما يكون عن كل شيء ، فقد اخترعت العديد من الشركات التي تنتج معدات تسجيل احترافية وتستمر في ابتكار أشكالها الخاصة.
ينتج عن هذا العدد الكبير من تنسيقات ضغط البيانات الصوتية عيوب تقنية في الأنظمة الأساسية (معظم برامج الترميز المدرجة كانت مكتوبة في أواخر التسعينيات) والتسويق (في حالة ALAC) والجمهور الرياضي والجامعي مهتمون للغاية بخوارزميات ضغط البيانات.
بالإضافة إلى ما سبق ، يوجد (يوجد) عدد كبير من النسيان بجدارة أو لا يستحقون أرشفة الصوت والترميز الصوتي بجدارة. يمكن العثور على الخصائص التقنية لبعض في الجدول:
يمكن النقر عليها:
سننظر بمزيد من التفصيل في فقط تلك التي تستخدم على نطاق واسع والتي ، في وقت كتابة هذا التقرير ، يمكن العثور عليها على شبكة الإنترنت. لا يوجد سوى عشرات منهم.
الجزء الثاني - الممارسة:
من اليسار إلى اليمين: 1. SSDS للمنطقة الزرقاء (الصوت الرقمي الديناميكي من Sony) ، 2. المنطقة الرمادية Dolby Digital (بين التثقيب) ، 3. الصوت التناظري (كما في السجل) ، و 4. رمز التوقيت DTS (الأزرق).
وإليك مقارنة جديدة لعام 2009 بين تسعة مما سبق:
الجزء الثالث. - الاختبار:
تم إجراء المقارنة على المنصة:
وحدة المعالجة المركزية: DualCore Intel Core i3 530 و 2933 MHz (x86 و x86-64 و MMX و SSE و SSE2 و SSE3 و SSSE3 و SSE4.1 و SSE4.2)
اللوحة الأم. اللوحة: آسوس P7H55-V
ذاكرة الوصول العشوائي: 2x2GB DDR3-1333
محرك الأقراص الصلبة: ذاكرة التخزين المؤقت Seagate SATA 160GB 8 ميجابايت (النظام) ، ذاكرة التخزين المؤقت (Hitachi SATA-II) سعة 500 جيجابايت سعة 16 جيجابايت (المصدر) ، ذاكرة التخزين المؤقت (Hitachi SATA-II) سعة 1000 ميجابايت بسعة 32 جيجابايت (الوجهة)
1. أغنية بلا خسائر (LA) - أصبح برنامج الترميز القديم (2004) هو الفائز بلا منازع في الضغط. في الوقت نفسه ، تجدر الإشارة إلى أن سرعة الترميز مقبولة تمامًا (مقارنة بنفس OptimFROG أو WavPack) ، فضلاً عن سرعة فك التشفير الكافية. على الرغم من أن ملف LA لم يتم فك تشفيره باستخدام البرنامج المساعد foo_benchmark ، فقد تم تشغيله بشكل مثالي ، دون أي تأخير أو تمرير.
لا يسع المرء إلا أن يتساءل لماذا تخلى المؤلف عن مثل هذا الترميز الجميل دون حتى فتح الكود المصدري.
2. OptimFROG - ليس بعيدا وراء لوس انجليس. ولكن سرعته لا يمكن أن يسمى بسرعة. بالإضافة إلى ذلك ، التأخير الشديد عند التمرير عبر ملف ما هو لحظة غير سارة - أحيانًا تكون مزعجة جدًا.
3. قرد الصوت - ترميز شعبية ولكن كثيفة الاستخدام للموارد. إنه يوفر ضغطًا عاليًا حقًا ، لكن مرة أخرى لديه مشكلات في التمرير. (يبدو أن مؤلف الاختبار قد فرض الملف على خيار "مجنون" ، والذي لا يزال محفوفًا بفقدان البيانات).
4. TAK - لا يتوقف برنامج الترميز هذا المطوَّر بنشاط عن إرضاءه. إذا أخذت في الاعتبار جميع المعلمات الثلاثة (الضغط ، الترميز ، فك التشفير) ، فإن TAK تبدو أكثر جاذبية. يتم تفسير سرعة التشغيل العالية من خلال الاستخدام الفعال لتحسينات المعالج (بما في ذلك SSSE3). واستخدام اثنين من النوى يعطي زيادة مضاعفة تقريبا في سرعة الترميز! وبالتالي ، في حالة TAK ، تكون ميزة استخدام المعالجات الحديثة أكثر وضوحًا.
5. WavPack - لأكون صادقًا ، لا أعرف لماذا اكتسب برنامج الترميز هذا شعبية. ينتج عن تشفير الضغط المتوسط \u200b\u200bنتائج مماثلة لـ FLAC ، ويؤدي استخدام أوضاع الضغط العالية إلى انخفاض غير مبرر في السرعة. على الرغم من أن الميزة الرئيسية لهذا الترميز هي دعمها ووظائفها الواسعة (بما في ذلك دعم الصوت متعدد القنوات ، الوضع المختلط) ، لكنني أذكرك بأننا لا نعتبر هذا الجانب من المشكلة في هذا الاختبار.
6. صوت حقيقي (TTA) - تجدر الإشارة هنا إلى أن سرعة التشفير عالية جدًا ونسبة ضغط مقبولة (أعلى قليلاً من سرعة FLAC). علاوة على ذلك ، لا يمكن استدعاء سرعة فك التشفير عالية جدًا.
7. FLAC- نسبة الضغط متوسطة ، لكن سرعة فك التشفير مسرورة. صحيح أن السبب الرئيسي لقيادة برنامج الترميز هذا بين الجمهور هو المصدر المفتوح ، ونتيجة لذلك ، أوسع دعم للأجهزة / البرمجيات.
8. آبل بلا خسائر (ALAC) - أحد برامج الترميز هذه غير ملحوظة ، لكن يواصل المطورون زراعتها بنشاط (في هذه الحالة ، Apple). انخفاض ضغط وسرعة فك التشفير. سرعة الضغط متوسطة. باستثناء مستخدمي iPod ، ليس لديهم أي خيار.
9. ماجدة الرومي ضياع - حالة مماثلة لـ ALAC ، لكننا نتعامل هنا مع شركة Microsoft العملاقة. حتى أقل ضغط ، متوسط \u200b\u200bمعدل الضغط. سرعة فك التشفير عالية نسبيا. من الصعب تخيل حالة يكون من الضروري فيها استخدام برنامج الترميز هذا بدون فقدان.
الجزء الرابع - الاستنتاجات العامة:
الاختيار بسيط ويتألف من نقطتين:
إذا كانت مساحة القرص مهمة ، فإننا نستخدم صوت Monkey's (يضغط من 8 إلى 12٪ أفضل من FLAC ، والذي سيكون على قرص 1 تيرابايت حوالي 100 جيجابايت أو حوالي 300 ألبوم مضغوط قياسي). ينطبق الأمر نفسه على التوزيع على الإنترنت. إنه بتنسيق صوت Monkey مع خيار ضغط إضافي عالي. لا أستخدم العديد من القوانين المحلية وغيرها ، لأن المكسب من استخدامها مقارنةً بـ Monkey's Audio صغير.
إذا كان التوافق مع مختلف اللاعبين وقطع الوسائط من الحديد التي تعمل تحت Linux أمرًا مهمًا وليس فقط استخدام FLAC. على الرغم من أن IMHO بالنسبة إلى اللاعبين ، إلا أنه مناسب تمامًا لنفسه ولغة MP3 ، لأن الشيء الرئيسي ليس صوتًا ، بل هو موسيقى!
في المستقبل ، سننظر في تطوير TTA ، لكن رأيي الشخصي هو أن TTA قد تأخرت بالفعل في قاطرة البخار إلى "مسافة المشردين".
بالنسبة إلى "برامج تشغيل الخشخاش" و "الخطوط العريضة" - الخيار بقدر ما أعرف حتى الآن هو خيار واحد - الدف والرقص حول أجهزة إرسال مختلفة في تنسيق ALAC.
وتذكر أنه يمكنك دائمًا نقل الملفات من برنامج ترميز واحد إلى آخر ، وبدون فقد الجودة ، هذا ما تعتبره برامج ترميز الضغط غير المفقودة جيدة على عكس برامج ترميز الضغط المفقودة.
رقم الانحدار "الغنائي" مرة واحدة.
ل "Udifilov". الاختلافات في تنسيقات الصوت - لا! "ليس اللون الطبيعي للأعلى" ، "عدم شرعية سهلة لكمة" ، مثل "حجاب الوسط مع تلطيخ المشهد" - وهذا في نظامك. لا يتم تشغيل برامج الترميز ، فهي تقوم بفك تشفيرها ، ولا تضيف أي شيء ، ولا تحذف أي شيء.
الاستطراد هو الرقم "الغنائي" TWO.
كُتب هذا المقال لعشاق الموسيقى وجامعي الموسيقى - المبتدئين والفلاحين الأوسطين ، ونفس محبي الموسيقى وجامعيها.
لن تكون مهتمة هنا Gurams و Kvods و Sensei و Helmsmen العظماء الآخرون من World of Audio ، فضلاً عن المسلحين Udifils. اكتب مقالك "مع لعبة ورق والترميز."
معلومات مثيرة للاهتمام:
حاليا ، يتم تسجيل 1154 امتدادات الملفات بطريقة أو بأخرى متصلة مع البيانات الصوتية!
مصادر:
wiki.hydrogenaudio.org/
ru.wikipedia.org/
وكذلك مواقع البرامج الرسمية.
يوم جيد.
اليوم أود أن أتطرق إلى موضوع ضغط البيانات المفقودة. على الرغم من أن هناك بالفعل مقالات على المحور مخصصة لبعض الخوارزميات ، أردت أن أتحدث عن هذا بمزيد من التفصيل.
سأحاول تقديم وصف رياضي ووصفًا بالطريقة المعتادة ، بحيث يمكن للجميع العثور على شيء مثير للاهتمام لأنفسهم.
في هذه المقالة سأتطرق إلى لحظات الضغط الأساسية وأنواع الخوارزميات الرئيسية.
ضغط. هل هناك حاجة في الوقت الحاضر؟
نعم بالطبع. بالطبع ، نحن نفهم جميعًا أنه يمكننا الآن الوصول إلى كل من وسائط التخزين كبيرة الحجم وقنوات نقل البيانات عالية السرعة. ومع ذلك ، في الوقت نفسه ، فإن حجم المعلومات المنقولة ينمو. إذا شاهدنا قبل بضع سنوات 700 ميغا بايت من الأفلام التي تتلاءم مع قرص واحد ، يمكن أن تشغل الأفلام عالية الجودة اليوم عشرات غيغا بايت.
بالطبع ، فوائد ضغط كل شيء وكل شيء ليست كبيرة. ولكن لا تزال هناك حالات يكون فيها الضغط مفيدًا للغاية ، إن لم يكن ضروريًا.
- إرسال المستندات بالبريد الإلكتروني (لا سيما الكميات الكبيرة من المستندات التي تستخدم الأجهزة المحمولة)
- عند نشر الوثائق على المواقع ، والحاجة إلى توفير حركة المرور
- توفير مساحة على القرص عند تغيير أو إضافة تخزين أمر صعب. على سبيل المثال ، يحدث هذا في الحالات التي لا يكون فيها من السهل الحصول على ميزانية للنفقات الرأسمالية ، ولا توجد مساحة كافية على القرص.
بالطبع ، يمكنك الخروج بالعديد من المواقف المختلفة التي سيكون فيها الضغط مفيدًا ، لكن هذه الأمثلة القليلة كافية لنا.
يمكن تقسيم جميع أساليب الضغط إلى مجموعتين كبيرتين: الضغط الضياع والضغط غير المفقود. يتم استخدام الضغط بدون فقد في الحالات التي تحتاج إلى استعادة المعلومات بدقة إلى البتات. هذا النهج هو الوحيد الممكن عند الضغط ، على سبيل المثال ، البيانات النصية.
ومع ذلك ، في بعض الحالات ، لا يلزم استرداد معلومات دقيقة ويسمح باستخدام خوارزميات تقوم بتنفيذ الضغط الناقص ، والذي ، على عكس الضغط غير المفقود ، يكون عادة أسهل في التنفيذ ويوفر درجة أعلى من الأرشفة.
لذلك ، دعنا ننتقل إلى خوارزميات ضغط ضياع.
أساليب ضغط ضياع العالمي
في الحالة العامة ، هناك ثلاثة خيارات أساسية تعتمد عليها خوارزميات الضغط.
المجموعة الأولى طرق - تحويل تيار. يتضمن هذا وصفًا للبيانات الجديدة غير المضغوطة الواردة من خلال معالجتها بالفعل. في هذه الحالة ، لا يتم احتساب أي احتمالات ، ويتم تنفيذ تشفير الحروف فقط على أساس البيانات التي تمت معالجتها بالفعل ، كما هو الحال في أساليب LZ (سميت باسم أبراهام لمبل وجاكوب زيفا). في هذه الحالة ، يتم استبدال التكرارات الثانية والمزيد من سلسلة فرعية معروفة بالفعل لبرنامج التشفير بمراجع إلى أول ظهور لها.
المجموعة الثانية الطرق هي طرق ضغط إحصائية. في المقابل ، يتم تقسيم هذه الأساليب إلى التكيف (أو التدفق) ، وكتلة.
في الإصدار الأول (التكيفي) ، يستند حساب احتمالات البيانات الجديدة إلى البيانات التي تمت معالجتها بالفعل أثناء الترميز. تتضمن هذه الطرق إصدارات قابلة للتكيف من خوارزميات Huffman و Shannon-Fano.
في الحالة الثانية (الكتلة) ، يتم حساب إحصائيات كل كتلة بيانات بشكل منفصل ، وتضاف إلى أكثر المجموعات ضغطًا. تتضمن هذه الإصدارات الثابتة طرق Huffman و Shannon-Fano و الترميز الحسابي.
المجموعة الثالثة الطرق هي ما يسمى طرق تحويل الكتلة. يتم تقسيم البيانات الواردة إلى كتل ، والتي يتم تحويلها بعد ذلك ككل. ومع ذلك ، قد لا تؤدي بعض الطرق ، لا سيما استنادًا إلى التقليب بين الكتل ، إلى انخفاض كبير (أو حتى أي) في كمية البيانات. ومع ذلك ، بعد هذه المعالجة ، تتحسن بنية البيانات بشكل ملحوظ ، ويكون الضغط اللاحق بواسطة الخوارزميات الأخرى أكثر نجاحًا وأسرع.
المبادئ العامة التي يعتمد عليها ضغط البيانات
تعتمد جميع أساليب ضغط البيانات على مبدأ منطقي بسيط. إذا تخيلنا أن العناصر الأكثر تكرارًا يتم تشفيرها برموز أقصر ، وأن العناصر الأقل تكرارًا يتم ترميزها بأخرى أطول ، ثم لتخزين جميع البيانات ، يلزم مساحة أقل مما لو كانت جميع العناصر ممثلة برموز من نفس الطول.
يتم وصف العلاقة الدقيقة بين تواتر تكرارات العناصر وأطوال الكود الأمثل في ما يسمى بنظرية ترميز مصدر شانون ، والتي تحدد حد الانضغاط الأقصى للضغط الأقصى ونترون شانون.
قليلا من الرياضيات
إذا كان احتمال حدوث عنصر s i يساوي p (s i) ، فسيكون من الأفضل تمثيل هذا العنصر - بت 2 p (s i) بت. إذا كان من الممكن أثناء التشفير التأكد من تقليل طول كل العناصر إلى 2 بت (s) ، فإن طول التسلسل المشفر بالكامل سيكون ضئيلًا لجميع طرق التشفير الممكنة. علاوة على ذلك ، إذا لم يتغير توزيع الاحتمال لجميع العناصر F \u003d (p (s i)) ، وكانت احتمالات العناصر مستقلة عن بعضها البعض ، فيمكن حساب متوسط \u200b\u200bطول الرموز على النحو
تسمى هذه القيمة إنتروبيا توزيع الاحتمالات F ، أو إنتروبيا المصدر في وقت معين.
ومع ذلك ، عادةً ما لا يكون احتمال ظهور عنصر مستقلًا ، بل على العكس ، يعتمد على بعض العوامل. في هذه الحالة ، لكل توزيع مشفر جديد s i ، يأخذ توزيع الاحتمال F بعض القيمة F k ، أي لكل عنصر F \u003d F k و H \u003d H k.
بمعنى آخر ، يمكننا القول أن المصدر في الحالة k ، وهو ما يتوافق مع مجموعة معينة من الاحتمالات p k (s i) لجميع العناصر s i.
لذلك ، بالنظر إلى هذا التصحيح ، يمكننا التعبير عن متوسط \u200b\u200bطول الرموز كـ
حيث P k هو احتمال العثور على المصدر في الحالة k.
لذلك ، في هذه المرحلة ، نعلم أن الضغط يعتمد على استبدال العناصر التي تحدث كثيرًا برموز قصيرة ، والعكس بالعكس ، ونعرف أيضًا كيفية تحديد متوسط \u200b\u200bطول الرموز. ولكن ما هو الكود ، الترميز ، وكيف يحدث؟
ترميز بلا ذاكرة
الرموز بدون ذاكرة هي أبسط الرموز على أساسها يمكن ضغط البيانات. في التعليمات البرمجية الخالية من الذاكرة ، يتم استبدال كل حرف في متجه البيانات المشفرة بكلمة مرور من مجموعة بادئة من المتواليات الثنائية أو الكلمات.
في رأيي ، وليس التعريف الأكثر وضوحا. النظر في هذا الموضوع بمزيد من التفصيل.
اسمحوا بعض الأبجدية تعطى ![]() يتكون من عدد (محدد) من الحروف. نسمي كل تسلسل محدد من الأحرف من هذه الأبجدية (A \u003d a 1 ، 2 ، ... ، n) في كلمة واحدة، والرقم n هو طول هذه الكلمة.
يتكون من عدد (محدد) من الحروف. نسمي كل تسلسل محدد من الأحرف من هذه الأبجدية (A \u003d a 1 ، 2 ، ... ، n) في كلمة واحدة، والرقم n هو طول هذه الكلمة.
واسمحوا أيضا الأبجدية الأخرى تعطى ![]() . وبالمثل ، يُشار إلى الكلمة في هذه الأبجدية ب
. وبالمثل ، يُشار إلى الكلمة في هذه الأبجدية ب
نقدم اثنين من الرموز الأخرى لمجموعة من جميع الكلمات غير الفارغة في الأبجدية. دع - عدد الكلمات غير الفارغة في الأبجدية الأولى ، و - في الثانية.
دع أيضًا تعيين F يقترن بكل كلمة A من الأبجدية الأولى كلمة B \u003d F (A) من الثانية. ثم سيتم استدعاء الكلمة B قانون سيتم استدعاء الكلمات A ، والانتقال من الكلمة الأصلية إلى رمزها الترميز.
نظرًا لأن الكلمة يمكن أن تتكون أيضًا من حرف واحد ، يمكننا تحديد مراسلات الأحرف الأبجدية الأولى والكلمات المقابلة من الثانية:
1<-> ب 1
2<-> ب 2
…
ن<-> ب ن
هذه المباراة تسمى مخطط، ويشير ∑.
في هذه الحالة ، تسمى الكلمات B 1 ، B 2 ، ... ، B n رموز الابتدائية، ونوع الترميز مع مساعدتهم - الترميز الأبجدي. بالطبع ، صادف معظمنا هذا النوع من الترميز ، حتى لو كنا لا نعرف كل ما وصفته أعلاه.
لذلك ، قررنا على المفاهيم الأبجدية ، كلمة ، رمز ، و الترميز. الآن نحن نقدم هذا المفهوم بادئة.
دع الكلمة B لها النموذج B \u003d B "B" ". ثم B" تسمى البداية ، أو بادئة الكلمات B ، و B "" - نهايته. هذا تعريف بسيط إلى حد ما ، ولكن تجدر الإشارة إلى أنه بالنسبة لكل كلمة B ، يمكن اعتبار كل من الكلمة الفارغة ʌ ("الفضاء") والكلمة B نفسها بدايات ونهايات.
لذلك ، نقترب من فهم تعريف الرموز بدون ذاكرة. التعريف الأخير الذي نحتاج إلى فهمه هو مجموعة البادئة. يحتوي المخطط property على خاصية البادئة إذا كانت الكلمة B i ليست البادئة للكلمة B j ، بالنسبة لأي 1≤i ، j≤r ، i ≠ j ،
ببساطة ، مجموعة البادئة هي مجموعة محدودة لا يوجد فيها عنصر هو البادئة (أو البداية) لأي عنصر آخر. مثال بسيط على مثل هذه المجموعة ، على سبيل المثال ، الأبجدية العادية.
لذلك ، اكتشفنا التعاريف الأساسية. فكيف يحدث الترميز بدون ذاكرة نفسه؟
يحدث في ثلاث مراحل.
- يتم تجميع الأبجدية Ψ من أحرف الرسالة الأصلية ، مع فرز الأحرف الأبجدية بترتيب تنازلي لاحتمالية حدوثها في الرسالة.
- يرتبط كل رمز a i من الأبجدية word بكلمة معينة B i من مجموعة البادئة Ω.
- يتم تشفير كل حرف ، يليه دمج الرموز في دفق بيانات واحد ، والذي سيكون نتيجة للضغط.
إحدى خوارزميات الكنسي التي توضح هذه الطريقة هي خوارزمية هوفمان.
خوارزمية هوفمان
تستخدم خوارزمية هوفمان تردد حدوث نفس البايتات في كتلة بيانات المدخلات ، وتطابق الكتل المتكررة لسلسلة من البتات ذات الأطوال الأقصر ، والعكس بالعكس. هذا الرمز هو الحد الأدنى زائدة. ضع في اعتبارك الحالة عندما تتكون الأبجدية لتيار الإخراج ، بصرف النظر عن دفق الإدخال ، من حرفين فقط - صفر وواحد.
بادئ ذي بدء ، عند الترميز باستخدام خوارزمية هوفمان ، نحتاج إلى بناء الدائرة ∑. ويتم ذلك على النحو التالي:
- جميع حروف الأبجدية المدخلة مرتبة بترتيب تنازلي للاحتمال. جميع الكلمات من الأبجدية في دفق الإخراج (أي ما سنقوم بتشفيره) تعتبر في البداية فارغة (أتذكر أن أبجدية دفق الإخراج تتكون فقط من أحرف (0،1)).
- يتم الجمع بين حرفين ، j-1 و j من تدفق المدخلات ، اللذين لهما أقل احتمال لحدوث ، في "رمز زائف" واحد مع احتمال ص يساوي مجموع احتمالات الشخصيات المكونة لها. ثم نلحق 0 ببداية الكلمة B j-1 ، و 1 إلى بداية الكلمة B j ، والتي ستكون فيما بعد رموز الحرف j-1 و j ، على التوالي.
- نزيل هذه الأحرف من أبجدية الرسالة الأصلية ، لكننا نضيف الرمز الزائف الذي تم إنشاؤه إلى هذه الأبجدية (وبطبيعة الحال ، يجب إدراجه في الأبجدية في المكان المناسب ، مع الأخذ في الاعتبار احتماله).
يتم تكرار الخطوتين 2 و 3 حتى يبقى حرف زائف واحد فقط في الأبجدية التي تحتوي على جميع الأحرف الأبجدية الأصلية. علاوة على ذلك ، حيث أنه في كل خطوة ولكل حرف ، تتغير الكلمة المقابلة B i (بإضافة واحد أو صفر) ، وبعد اكتمال هذا الإجراء ، هناك كود معين B i سيتوافق مع كل حرف أولي من الأبجدية a i.
للحصول على توضيح أفضل ، فكر في مثال صغير.
لنفترض أن لدينا أبجدية تتكون من أربعة أحرف فقط - (أ 1 ، 2 ، 3 ، 4). افترض أيضًا أن احتمالية حدوث هذه الرموز متساوية ، على التوالي ، p 1 \u003d 0.5 ؛ ع 2 \u003d 0.24 ؛ ص 3 \u003d 0.15 ؛ ع 4 \u003d 0.11 (مجموع كل الاحتمالات يساوي بوضوح واحد).
لذلك ، سوف نبني مخطط لهذه الأبجدية.
- اجمع الحرفين مع أقل الاحتمالات (0.11 و 0.15) في p "الحرف الزائف".
- نحن ندمج الحرفين مع الاحتمال الأقل (0.24 و 0.26) في الحرف pseudo-character.
- نقوم بإزالة الأحرف المدمجة ، وإدراج الحرف الزائف الناتج في الأبجدية.
- أخيرًا ، اجمع بين الحرفين المتبقيين واحصل على أعلى الشجرة.
إذا أوضحت هذه العملية ، فستحصل على شيء مثل التالي:
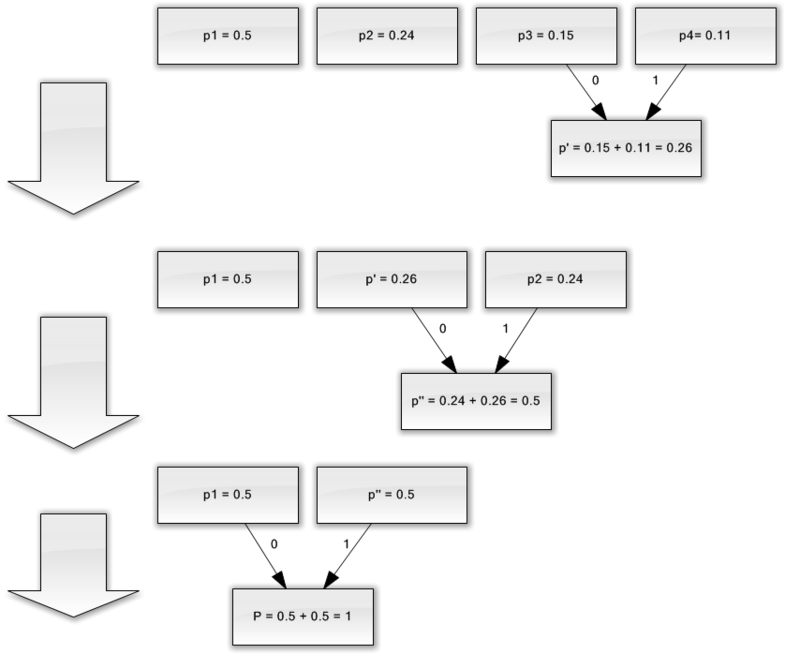
كما ترون ، مع كل دمج ، نقوم بتعيين الأحرف 0 و 1 إلى الأحرف المراد دمجها.
وبالتالي ، عندما يتم بناء الشجرة ، يمكننا بسهولة الحصول على رمز لكل حرف. في حالتنا ، ستبدو الرموز كما يلي:
1 \u003d 0
2 \u003d 11
3 \u003d 100
4 \u003d 101
نظرًا لأن أيا من هذه الرموز يمثل بادئة لأي رمز آخر (أي ، لقد حصلنا على مجموعة بادئة سيئة السمعة) ، يمكننا تحديد كل رمز بشكل فريد في دفق الإخراج.
لذلك ، لقد حققنا أن الشخصية الأكثر شيوعًا يتم تشفيرها بواسطة أقصر الكود ، والعكس.
إذا افترضنا أنه في البداية ، تم استخدام بايت واحد لتخزين كل حرف ، فيمكننا حساب مقدار قدرتنا على تقليل البيانات.
لنفترض أن لدينا سلسلة من 1000 حرف عند الإدخال ، حيث حدث الحرف 1 500 مرة ، و 2 240 ، و 3 150 ، و 4 110 مرة.
في البداية ، احتلت هذه السلسلة 8000 بت. بعد الترميز ، نحصل على سلسلة بطول ∑p i l i \u003d 500 * 1 + 240 * 2 + 150 * 3 + 110 * 3 \u003d 1760 بت. لذلك ، تمكنا من ضغط البيانات 4.54 مرة ، وإنفاق 1.76 بت في المتوسط \u200b\u200bعلى تشفير كل رمز تيار.
دعني أذكرك أنه وفقًا لشانون ، يبلغ متوسط \u200b\u200bطول الرموز ![]() . باستبدال قيم الاحتمالات الخاصة بنا في هذه المعادلة ، نحصل على متوسط \u200b\u200bطول الكود الذي يساوي 1.75496602732291 ، وهو قريب جدًا جدًا من النتيجة التي حصلنا عليها.
. باستبدال قيم الاحتمالات الخاصة بنا في هذه المعادلة ، نحصل على متوسط \u200b\u200bطول الكود الذي يساوي 1.75496602732291 ، وهو قريب جدًا جدًا من النتيجة التي حصلنا عليها.
ومع ذلك ، يجب مراعاة أنه بالإضافة إلى البيانات نفسها ، نحتاج إلى تخزين جدول الترميز ، مما سيزيد قليلاً الحجم النهائي للبيانات المشفرة. من الواضح ، في حالات مختلفة ، يمكن استخدام أشكال مختلفة من الخوارزمية - على سبيل المثال ، يكون في بعض الأحيان أكثر فعالية استخدام جدول الاحتمالات المحدد مسبقًا ، وأحيانًا يكون من الضروري تجميعه ديناميكيًا من خلال تصفح البيانات القابلة للضغط.
استنتاج
لذا ، في هذا المقال ، حاولت التحدث عن المبادئ العامة التي يحدث بها الضغط غير المفقود ، وفحصت أيضًا إحدى الخوارزميات الأساسية - ترميز هوفمان.
إذا كانت المقالة حسب ذوق مجتمع habro ، فسأكون سعيدًا لكتابة تكملة ، لأن هناك العديد من الأشياء الأكثر إثارة للاهتمام فيما يتعلق بالضغط غير المفقود ؛ هذه خوارزميات كلاسيكية وتحولات بيانات أولية (على سبيل المثال ، تحويل بوروز-ويلر) ، وبطبيعة الحال ، خوارزميات محددة لضغط الصوت والفيديو والصور (الموضوع الأكثر إثارة للاهتمام ، في رأيي).
أدب
- Vatolin D. ، Ratushnyak A. ، Smirnov M. Yukin V. أساليب ضغط البيانات. أرشفة الجهاز والصورة وضغط الفيديو. ISBN 5-86404-170-X ؛ عام 2003
- د. سالومون. ضغط البيانات والصورة والصوت ؛ ISBN 5-94836-027-X ؛ 2004.
أصبحت برامج الترميز التي تضغط الصوت دون فقد شعبية كبيرة في عالم مشغلات MP3 المحمولة. والحقيقة هي أن برامج الترميز هذه لا يمكنها تحمل نسب الضغط الضخمة التي يمكن أن تتفاخر بها برامج الترميز التي تضغط الصوت مع فقدان الجودة. أصبحت كميات كبيرة من الذاكرة متاحة على نطاق واسع لمستخدمي مشغلات MP3 فقط في السنوات الثلاث أو الأربع الماضية - ومع ظهور كميات كبيرة من الذاكرة في مشغلات MP3 ، أصبح ضغط الموسيقى الذي لا يتم فقده شائعًا. بالطبع ، أولئك الذين أرادوا الاستماع إلى الموسيقى دون فقدان الجودة فعلوا ذلك دائمًا (على سبيل المثال ، باستخدام مشغلات أقراص صوتية مضغوطة) ، وفي الوقت الحاضر ، يمكن للجميع (بشكل طبيعي ، بدعم من برامج الترميز المقابلة من قِبل مشغلاتهم) تجربة برامج ترميز بلا خسائر أثناء العمل .
الفرق الرئيسي بين برامج الترميز التي تقوم بضغط البيانات الصوتية دون فقدان الجودة من برامج الترميز التي يتم ضغطها مع الخسارة هو أن برامج الترميز دون فقدان الجودة لا تؤدي إلى إزالة المعلومات من دفق الصوت التي قد تعتبر زائدة عند الضغط عليها. تتمثل المهمة الرئيسية لبرنامج الترميز Lossless في ضغط معلومات الصوت الأصلية قدر الإمكان دون فقد جزء صغير من المعلومات.
الموقف مع دعم برامج الترميز بلا فقد هو حاليا أن الدعم الأكثر انتشارا هو ترميز ALAC ، والذي يرتبط مباشرة بـ Apple ومشغلاتها. لا يزال يتم دعم بقية برامج الترميز بواسطة عدد قليل من اللاعبين ، وفي بعض الأحيان حتى يدعم المشغل برنامج الترميز ، يتطلب المشغل وميض المشغل ، وربما يكون البرنامج الثابت الأكثر شهرة بالنسبة للاعبين الذين يدعمون برامج ترميز بلا فقد ، يعد RockBox أحد البرامج الثابتة البديلة وليس الرسمية.
عند العمل مع برامج الترميز Lossless ، قد ترى ما يسمى ملفات Cue أو بطاقات فهرس الملفات. يتم توزيع ملفات جديلة ، على سبيل المثال ، مع ملفات FLAC أو APE ، أقل في كثير من الأحيان - مع ملفات MP3 و WAV ، وهي ملف واحد كبير (حوالي 300 ميجابايت) يتم تخزين الألبوم بأكمله فيه. يحتوي ملف Cue - على معلومات حول تقسيم ملف كبير إلى مسارات وأسماء هذه المسارات. من الأنسب التعامل مع الملفات الفردية ، ومع ذلك ، حتى لو كنت بين يديك ، على سبيل المثال ، ملف FLAC كبير به ملف CUE ، استنادًا إلى المعلومات الموجودة في ملف CUE ، يمكن تقسيم الملف المصدر إلى مسارات منفصلة - سننظر في البرامج التي يمكن أن تحل هذه المشكلة.
لنبدأ في وصف تنسيقات ضغط البيانات غير المفقودة بتنسيق FLAC الشهير.
FLAC
FLAC (Free Codless Audio Codec) هو تنسيق لضغط الصوت بدون فقدان تم تطويره بواسطة Xiph. مؤسسة ORG. هذا شكل مجاني تمامًا يمكن للجميع استخدامه.
يشبه تشغيل FLAC وبرامج الترميز الأخرى التي تخزن البيانات الصوتية غير المفقودة تشغيل ملفات الأرشفة التقليدية. ومع ذلك ، وبسبب الخوارزميات الخاصة ، فإن كفاءة برامج الترميز هذه في ضغط المعلومات الصوتية أعلى بكثير من كفاءة المحفوظات التقليدية.
تم تطوير تنسيق FLAC كتنسيق دفق - تنقسم المعلومات الموجودة في ملف FLAC إلى إطارات (إطارات) ، يمكن فك تشفير كل منها بشكل منفصل عن الإطارات الأخرى.
عادةً ما يكون FLAC قادرًا على ضغط الملف المصدر ، على سبيل المثال ، جودة القرص المضغوط الصوتي بنسبة 40-50٪. ونتيجة لذلك ، فإن معدل البت الناتج يساوي حوالي 800 كيلوبت / ثانية.
في تنسيق FLAC ، من الممكن حفظ الأقراص المضغوطة بطريقة يمكنك إعادة إنشاء القرص الأصلي تمامًا إذا لزم الأمر - وهذا مناسب جدًا لأولئك الذين يرغبون في إنشاء نسخ رقمية من الأقراص المضغوطة الخاصة بهم مع إمكانية الاسترداد اللاحق.
سرعة فك التشفير والترميز لملفات FLAC ليست هي نفسها. تعتمد سرعة التشفير على مستوى الضغط وعلى سرعة النظام - عند مستويات الضغط العالية ، يمكن أن تكون بطيئة للغاية. ومع ذلك ، فك التشفير سريع جدًا - يمكن لمشغلات MP3 الحديثة التعامل معه بسهولة.
نظرًا لإمكانية الاستخدام المجاني المجاني ، يمكنك العمل مع FLAC على أساس أي نظام تشغيل حديث تقريبًا ، ويدعم المزيد والمزيد من مشغلات MP3 هذا التنسيق.
الترميز إلى تنسيق FLAC
يمكنك تنزيل الأداة المساعدة لترميز ملفات FLAC على. ويشمل برنامج الترميز نفسه وما يسمى Frontend - برنامج شل لبرنامج الترميز. حجم التوزيع يستغرق حوالي 2.5 ميغابايت. العمل مع برنامج الترميز بسيط: يمكنك إضافة الملفات التي تهم نافذة البرنامج (الشكل 4.1). باستخدام زر "إضافة ملفات" ، قم بتكوين خيارات الترميز وانقر فوق الزر "ترميز" - يقوم البرنامج بإنشاء ملف FLAC.
التين. 4.1.
دعونا نلقي نظرة على إعدادات الترميز الأكثر أهمية. أولاً ، دعنا نتحدث عن مجموعة معلمات خيارات التشفير.
المعلمة المستوى هي المسؤولة عن مستوى ضغط البيانات. يمكن أن تختلف من 0 إلى 8. كلما ارتفع مستوى الضغط ، كلما كان الملف النهائي أصغر ، ولكن كلما طال الوقت اللازم لترميز الملفات. على أجهزة الكمبيوتر السريعة ، يمكن أن يكون الفرق بين المستوى 0 والمستوى 8 عند الترميز ، مثلاً ، ملف WAV سعة 30 ميجابايت عدة ثوانٍ. يختلف الحجم بحوالي 10٪ عن حجم الملف الأصلي. يجب عليك تجربة هذا الخيار على جهاز الكمبيوتر الخاص بك - ربما إذا قمت بترميز عدة مئات من الملفات ، فإنك تفضل مستوى ضغط أقل على سرعة عمل أعلى.
تقوم المعلمة Verify بتوجيه برنامج التشفير للتحقق من ملفات الإخراج.
تضيف المعلمة Add tags علامات إلى الملف النهائي (على سبيل المثال ، قد تحتوي على اسم الأغنية أو المؤلف أو ما إلى ذلك) - يمكنك تكوينها بالنقر فوق الزر Tag Conf. (التخصيص العلامة).
تضيف المعلمة Replaygain معلمة إلى الملفات التي تشير إلى مستوى صوت الملف. إذا تم تعيين المعلمة "إدخال ملفات الإدخال كألبوم واحد" ، فستظهر جميع الإدخالات في الألبوم بنفس مستوى الصوت.
تحتوي مجموعة معلمات الخيارات العامة على معلمتين. ربما ، يجب الإشارة إلى المعلمة OGG-Flac هنا. إذا تمت إعادة تعيين هذه المعلمة ، فسيتم تعبئة بيانات FLAC في حاوية FLAC قياسية. إذا كنت تخطط للاستماع فقط إلى ملفات FLAC المستلمة ، لا يمكنك تعيين هذه المعلمة ، وإذا كانت خططك لهذه الملفات أكثر شمولاً - على سبيل المثال ، كنت تخطط لتحريرها ، واستخدامها لإدراجها في الأفلام ، فمن الأفضل تمكين المعلمة Ogg-FLAC.
تحتوي المعلمة دليل الإخراج على المسار إلى الدليل حيث سيتم احتواء ملفات الإخراج.
تحتوي مجموعة معلمات خيارات فك الترميز على معلمة Dec. من خلال الأخطاء - قم بتعيينها إذا كنت ترغب في فك تشفير ملف حتى لو كانت هناك أخطاء أثناء فك التشفير. فك الترميز هو عكس الترميز - أي أنه يمكنك فك تشفير ملفات FLAC عن طريق تحويلها إلى ملفات WAV. لفك التشفير ، بالطبع ، سيكون عليك إضافة ملفات FLAC إلى نافذة البرنامج.
بعد تكوين كل شيء ، ما عليك سوى النقر على زر Encode لإنشاء ملفات FLAC ، أو إذا كنت ترغب في فك تشفير ملفات FLAC الحالية ، انقر فوق الزر Decode.
بالإضافة إلى ما سبق ، يمكن لبرامج أخرى ترميز FLAC. على سبيل المثال ، هذا معروف لك بالفعل ImTOO Audio Encoder - للترميز إلى تنسيق FLAC ، ما عليك سوى تحديده من قائمة التنسيقات (الشكل 4.2.) ، وبعد ذلك يمكنك النقر فورًا على الزر "قص" أو القيام بذلك لاحقًا ، بعد إعداد أسماء الملفات.

