29.01.2019
Кодування даних бінарним кодом. Кодування даних
Для автоматизації роботи з даними, що належать до різних типів, дуже важливо уніфікувати їх форму подання - для цього зазвичай використовується прийом кодування,тобто вираз даних одного типу через дані іншого типу. Природні людські мови -це не що інше, як системи кодування понять для вираження думок у вигляді мови. До мов близько примикають абетки(Системи кодування компонентів мови за допомогою графічних символів). Історія знає цікаві, хоч і безуспішні спроби створення «універсальних» мов та абет. Очевидно, безуспішність спроб їх застосування пов'язана з тим, що національні та соціальні освіти природно розуміють, що зміна системи кодування суспільних даних неодмінно призводить до зміни суспільних методів (тобто норм права та моралі), а це може бути пов'язано з соціальними потрясіннями .
Та сама проблема універсального засобу кодування досить успішно реалізується в окремих галузях техніки, науки та культури. Як приклади можна навести систему запису математичних виразів, телеграфну абетку, морську прапорцеву абетку, систему Брайля для сліпих та багато іншого.
Своя система існує і в обчислювальній техніці – вона називається двійковим кодуваннямі заснована на поданні даних послідовністю всього двох знаків: 0 та 1. Ці знаки називаються двійковими цифрами,по англійськи - binary digitабо скорочено hit (біт).
Одним бітом можуть бути виражені два поняття: 0 чи 1 (такабо ні, чорнеабо біле, істинаабо брехняі т.п.). Якщо кількість бітів збільшити до двох, то вже можна виразити чотири різні поняття:
Три біти можна закодувати вісім різних значень:
000 001 010 011 100 101 110 111
Збільшуючи на одиницю кількість розрядів у системі двійкового кодування, ми збільшуємо вдвічі кількість значень, яка може бути виражена в даній системі, тобто загальна формуламає вигляд:
де N-кількість незалежних значень, що кодуються;
т -розрядність двійкового кодування, прийнята у цій системі.
Кодування цілих та дійсних чисел
Цілі числа кодуються двійковим кодом досить просто - достатньо взяти ціле число і ділити його навпіл до тих пір, поки приватне не буде рівним одиниці. Сукупність залишків від кожного поділу, записана праворуч наліво разом із останнім приватним, і утворює двійковий аналог десяткового числа.
Таким чином, 19 = 10011;
Для кодування цілих чисел від 0 до 255 достатньо мати 8 розрядів двійкового коду (8 біт). Шістнадцять біт дозволяють закодувати цілі числа від 0 до 65535, а 24 біти - вже більше 16,5 мільйонів різних значень.
Для кодування дійсних чисел використовують 80-розрядне кодування. При цьому число попередньо перетворюється на нормалізовану форму:
3,1415926 =0,31415926-10"
300 000 = 0,3 10 6
123 456 789 = 0,123456789 10 10
Перша частина числа називається мантисою,а друга - характеристикою.Більшість з 80 біт відводять для зберігання мантиси (разом зі знаком) і деяку фіксовану кількість розрядів відводять для зберігання характеристики (теж зі знаком).
Кодування текстових даних
Якщо кожному символу алфавіту можна порівняти певне ціле число (наприклад, порядковий номер), то за допомогою двійкового коду можна кодувати текстову інформацію. Восьми двійкових розрядів достатньо для кодування 256 різних символів. Цього вистачить, щоб висловити різними комбінаціями восьми бітів всі символи англійської та російської мов, як малі, так і великі, а також розділові знаки, символи основних арифметичних дій і деякі загальноприйняті спеціальні символи, наприклад символ «§».
Технічно це виглядає дуже просто, проте завжди існували досить значні організаційні складності. У перші роки розвитку обчислювальної техніки вони пов'язані з відсутністю необхідних стандартів, а нині викликані, навпаки, достатком одночасно діючих і суперечливих стандартів. Для того, щоб весь світ однаково кодував текстові дані, потрібні єдині таблиці кодування, а це поки що неможливо через протиріччя між символами національних алфавітів, а також протиріччя корпоративного характеру.
Для англійської мови, яка захопила де-факто нішу міжнародного засобу спілкування, протиріччя вже знято. Інститут стандартизації США (ANSI - American National Standard Institute)ввів у дію систему кодування ASCII (American Standard Code for Information Interchange – стандартний код інформаційного обміну США).В системі ASCIIзакріплено дві таблиці кодування - базоваі розширена.Базова таблиця закріплює значення кодів від 0 до 127, а розширена відноситься до символів із номерами від 128 до 255.
Перші 32 коди базової таблиці, починаючи з нульового, віддано виробникам апаратних засобів (насамперед виробникам комп'ютерів та друкувальних пристроїв). У цій галузі розміщуються так звані керуючі коди,яким не відповідають жодні символи мов, і, відповідно, ці коди не виводяться ні на екран, ні на пристрої друку, але ними можна керувати тим, як проводиться виведення інших даних.
Починаючи з коду 32 по код 127 розміщені коди символів англійського алфавіту, розділових знаків, цифр, арифметичних дій і деяких допоміжних символів.
Аналогічні системи кодування текстових даних розробили й інших країнах. Так, наприклад, у СРСР у цій галузі діяла система кодування КОІ-7 (код обміну інформацією, семизначний).Однак підтримка виробників обладнання та програм вивела американський код ASCIIна рівень міжнародного стандарту, і національним системам кодування довелося «відступити» у другу, розширену частину системи кодування, що визначає значення кодів з 128 по 255. Відсутність єдиного стандарту в цій галузі призвела до множинності кодувань, що одночасно діють. Тільки в Росії можна вказати три діючі стандарти кодування та ще два застарілі.
Так, наприклад, кодування символів російської мови, відоме як кодування Windows-1251,була введена "ззовні" - компанією Microsoft, але, враховуючи широке поширення операційних систем та інших продуктів цієї компанії в Росії, вона глибоко закріпилася і знайшла широке поширення. Це кодування використовується на більшості локальних комп'ютерів, які працюють на платформі Windows.
Інше поширене кодування зветься КОІ-8 (код обміну інформацією, восьмизначний) -її походження відноситься до часів дії Ради Економічної Взаємодопомоги держав Східної Європи. Сьогодні кодування КОІ-8 має широке поширення в комп'ютерних мережах на території Росії та в російському секторі Інтернету.
Міжнародний стандарт, в якому передбачено кодування символів російського алфавіту, має назву кодування ISO (International Standard Organization – Міжнародний інститут стандартизації).На практиці це кодування використовується рідко.
На комп'ютерах, що працюють у операційні системи MS-DOS,можуть діяти ще два кодування (кодування ГОСТ такодування ГОСТ-альтернативна).Перша з них вважалася застарілою навіть у перші роки появи персональної обчислювальної техніки, але друга використовується і сьогодні.
У зв'язку з достатком систем кодування текстових даних, які у Росії, виникає завдання міжсистемного перетворення даних - це з поширених завдань інформатики.
Універсальна система кодування текстових даних
Якщо проаналізувати організаційні проблеми, пов'язані зі створенням єдиної системикодування текстових даних, можна дійти висновку, що вони викликані обмеженим набором кодів (256). У той же час очевидно, що якщо, наприклад, кодувати символи не є восьмирозрядними двійковими числамиа числами з великою кількістю розрядів, то і діапазон можливих значень кодів стане набагато більшим. Така система, що базується на 16-розрядному кодуванні символів, отримала назву універсальна - UNICODE.Шістнадцять розрядів дозволяють забезпечити унікальні коди для 65536 різних символів - цього поля достатньо для розміщення в одній таблиці символів більшості мов планети.
Незважаючи на очевидну очевидність такого підходу, простий механічний перехід на цю систему довгий часстримувався через недостатні ресурси засобів обчислювальної техніки (у системі кодування UNICODEвсі текстові документи автоматично стають удвічі довшими). У другій половині 90-х років технічні засоби досягли необхідного рівня забезпеченості ресурсами, і сьогодні ми спостерігаємо поступове переведення документів та програмних засобів на універсальну систему кодування. Для індивідуальних користувачів це ще більше додало турбот за узгодженням документів, виконаних у різних системах кодування, з програмними засобами, але це треба розуміти як труднощі перехідного періоду.
Кодування графічних даних
Якщо розглянути за допомогою збільшувального скла чорно-біле графічне зображення, надруковане в газеті або книзі, то можна побачити, що воно складається з найдрібніших точок, що утворюють характерний візерунок. растром(Рис.1).
Мал. 1. Растр - це метод кодування графічної інформації, здавна прийнятий у поліграфії
Оскільки лінійні координати та індивідуальні властивості кожної точки (яскравість) можна виразити за допомогою цілих чисел, можна сказати, що растрове кодування дозволяє використовувати двійковий код для представлення графічних даних. Загальноприйнятим на сьогоднішній день вважається представлення чорно-білих ілюстрацій у вигляді комбінації крапок із 256 градаціями сірого кольору, і, таким чином, для кодування яскравості будь-якої точки зазвичай достатньо восьмирозрядного двійкового числа.
Для кодування кольорових графічних зображень застосовується принцип декомпозиціїдовільного кольору основні складові. Як такі складові використовують три основні кольори: червоний (Red, R),зелений (Green, G)і синій (Blue, B).Насправді вважається (хоча теоретично це зовсім так), що будь-який колір, видимий людським оком, можна отримати шляхом механічного змішування цих трьох основних кольорів. Така система кодування називається системою RGBза першими буквами назв основних кольорів.
Якщо для кодування яскравості кожної з основних складових використовувати по 256 значень (вісім двійкових розрядів), як це прийнято для напівтонових чорно-білих зображень, то кодування кольору однієї точки треба витратити 24 розряду. При цьому система кодування забезпечує однозначне визначення 16,5 млн різних кольорів, що насправді близько до чутливості. людського ока. Режим представлення кольорової графіки з використанням 24 двійкових розрядів називається повнокольоровим (True Color).
Кожному з основних кольорів можна поставити додатковий колір, тобто колір, що доповнює основний колір до білого. Неважко помітити, що для будь-якого з основних кольорів додатковим буде колір, утворений сумою кількох основних кольорів. Відповідно, додатковими кольорами є: блакитний (Cyan, С),пурпурний (Magenta, М)і жовтий ( Yellow, Y).Принцип декомпозиції довільного кольору на компоненти можна застосовувати не тільки для основних кольорів, але і для додаткових, тобто будь-який колір можна представити у вигляді суми блакитної, пурпурової та жовтої складової. Такий метод кодування кольору прийнято в поліграфії, але в поліграфії використовується ще й четверта фарба - чорна (Black, К).Тому дана система кодування позначається чотирма літерами. CMYK(чорний колір позначається буквою До,тому, що буква Увже зайнята синім кольором), і для представлення кольорової графіки в цій системі треба мати 32 двійкові розряди. Такий режим теж називається повнокольоровим. (True Color).
Якщо зменшити кількість двійкових розрядів, що використовуються для кодування кольору кожної точки, можна скоротити обсяг даних, але при цьому діапазон кодованих кольорів помітно скорочується. Кодування кольорової графіки 16-розрядними двійковими числами називається режимом High Color.
При кодуванні інформації про колір за допомогою восьми біт даних можна передати лише 256 відтінків кольорів. Такий метод кодування кольору називається індексним.Сенс назви в тому, що оскільки 256 значень зовсім недостатньо, щоб передати весь діапазон кольорів, доступний людському оку, код кожної точки растру виражає не колір сам по собі, а тільки його номер (індекс) уякоїсь довідкової таблиці, яка називається палітрою.Зрозуміло, ця палітра повинна прикладатися до графічних даних - без неї не можна скористатися методами відтворення інформації на екрані або папері (тобто скористатися, звичайно, можна, але через неповноту даних отримана інформація не буде адекватною: листя на деревах може виявитися червоним, а небо – зеленим).
Кодування звукової інформації
Прийоми та методи роботи зі звуковою інформацією прийшли до обчислювальної техніки найпізніше. До того ж, на відміну від числових, текстових і графічних даних, звукозаписи не мали такої ж тривалої та перевіреної історії кодування. У результаті способи кодування звукової інформації двійковим кодом далекі від стандартизації. Багато окремих компаній розробили свої корпоративні стандарти, але якщо говорити узагальнено, то можна виділити два основні напрямки.
Метод FM (Frequency Modulation)заснований на тому, що теоретично будь-який складний звук можна розкласти на послідовність найпростіших гармонійних сигналів різних частот, кожен з яких є правильною синусоїдою, а отже, може бути описаний числовими параметрами, тобто кодом. У природі звукові сигнали мають безперервний спектр, тобто аналогові. Їх розкладання в гармонійні ряди та подання у вигляді дискретних цифрових сигналів виконують спеціальні пристрої. аналогово-іфрові перетворювачі (АЦП).Зворотне перетворення для відтворення звуку, закодованого числовим кодом, виконують цифра-аналогові перетворювачі (ЦАП).При таких перетвореннях неминучими є втрати інформації, пов'язані з методом кодування, тому якість звукозапису зазвичай виходить не цілком задовільною і відповідає якості звучання найпростіших електромузичних інструментів з забарвленням, характерним для електронної музики. У той самий час даний метод кодування забезпечує дуже компактний код, і тому знайшов застосування ще роки, коли ресурси засобів обчислювальної техніки були явно недостатні.
Метод таблично-хвильового ( Wave-Table)синтезу найкраще відповідає сучасному рівню розвитку техніки. Якщо говорити спрощено, то можна сказати, що десь у заздалегідь підготовлених таблицях зберігаються зразки звуків для багатьох різних музичних інструментів (хоча не тільки для них). У техніці такі зразки називають семпламі.Числові коди виражають тип інструменту, номер його моделі, висоту тону, тривалість та інтенсивність звуку, динаміку його зміни, деякі параметри середовища, в якому відбувається звучання, а також інші параметри, що характеризують особливості звуку. Оскільки як зразки використовуються «реальні» звуки, то якість звуку, отриманого в результаті синтезу, виходить дуже високою і наближається до якості звучання реальних музичних інструментів.
Основні структури даних
Робота з великими наборами даних автоматизується простіше, коли дані упорядковані,тобто утворюють задану структуру. Існує три основні типи структур даних: лінійна, ієрархічнаі таблична.Їх можна розглянути з прикладу звичайної книги.
Якщо розібрати книгу на окремі аркуші та перемішати їх, книга втратить своє призначення. Вона, як і раніше, представлятиме набір даних, але підібрати адекватний метод для отримання з неї інформації дуже непросто. (Ще гірше справа буде, якщо з книги вирізати кожну букву окремо - у цьому випадку навряд чи взагалі знайдеться адекватний метод для її прочитання.)
Якщо ж зібрати всі аркуші книги у правильній послідовності, ми отримаємо найпростішу структуру даних. лінійну.Таку книгу вже можна читати, хоча для пошуку потрібних даних її доведеться прочитати поспіль, починаючи від початку, що не завжди зручно.
Для швидкого пошуку даних існує ієрархічна структура.Так, наприклад, книги розбивають на частини, розділи, розділи, параграфи тощо, п. Елементи структури нижчого рівня входять до елементів структури вищого рівня: розділи складаються з розділів, розділи з параграфів тощо.
Для великих масивів пошук даних в ієрархічній структурі набагато простіше, ніж у лінійній, однак і тут потрібна навігація,пов'язана із необхідністю перегляду. Насправді завдання спрощують тим, що у більшості книжок є допоміжна перехресна таблиця,зв'язує елементи ієрархічної структури з елементами лінійної структури, тобто зв'язує розділи, розділи та параграфи з номерами сторінок. У книгах із простою ієрархічною структурою, розрахованих на послідовне читання, цю таблицю прийнято називати змістом,а в книгах зі складною структурою, що допускає вибіркове читання, її називають змістом.
1.6. дані та їх кодування
Носії даних
Дані – діалектична складова частина інформації. Вони є зареєстрованими сигналами. При цьому фізичний метод реєстрації може бути будь-яким: механічне переміщення фізичних тіл, зміна їх форми або параметрів якості поверхні, зміна електричних, магнітних, оптичних характеристик, хімічного складута (або) характеру хімічних зв'язків, зміна стану електронної системи та багато іншого.
Відповідно до методу реєстрації дані можуть зберігатися та транспортуватися на носіях різних видів. Найпоширенішим носієм даних, хоч і не найекономічнішим, мабуть, є папір. На папері дані реєструються шляхом зміни оптичних характеристик поверхні. Зміна оптичних властивостей (зміна коефіцієнта відбиття поверхні в певному діапазоні довжин хвиль) використовується також у пристроях, що здійснюють запис лазерним променем на пластмасових носіях з покриттям, що відбиває (CD-ROM). Як носії, що використовують зміну магнітних властивостей, можна назвати магнітні стрічки та диски. Реєстрація даних шляхом зміни хімічного складу поверхневих речовин носія широко використовується у фотографії. На біохімічному рівні відбувається накопичення та передача даних у живій природі.
Носії даних цікавлять нас самі по собі, а остільки, оскільки властивості інформації дуже тісно пов'язані з властивостями її носіїв. Будь-який носій можна характеризувати параметром роздільної здатності (кількістю даних, записаних у прийнятій для носія одиниці виміру) і динамічним діапазоном (логарифмічним відношенням інтенсивності амплітуд максимального та мінімального сигналів, що реєструються). Від цих властивостей носія часто залежать такі характеристики інформації, як повнота, доступність і достовірність. Так, наприклад, ми можемо розраховувати на те, що в базі даних, що розміщується на компакт-диску, простіше забезпечити повноту інформації, ніж в аналогічній за призначенням базі даних, розміщеній на гнучкому магнітному диску, оскільки в першому випадку щільність запису даних на одиниці довжини доріжки набагато вищі. Для звичайного споживача доступність інформації в книзі помітно вища, ніж тієї ж інформації на компакт-диску, оскільки не всі споживачі мають необхідне обладнання. І, нарешті, відомо, що візуальний ефектвід перегляду слайда в проекторі набагато більше, ніж від перегляду аналогічної ілюстрації, надрукованої на папері, оскільки діапазон яскравих сигналів у світлі, що проходить, на два-три порядки більше, ніж у відображеному.
Завдання перетворення даних із метою зміни носія належить до однієї з найважливіших завдань інформатики. У структурі вартості обчислювальних систем пристрою для введення та виведення даних, що працюють з носіями інформації, становлять до половини вартості апаратних засобів.
Операції з даними
У ході інформаційного процесу дані перетворюються з одного виду на інший за допомогою методів. Обробка даних включає безліч різних операцій. З розвитком науково-технічного прогресу та загального ускладнення зв'язків у суспільстві трудовитрати на обробку даних неухильно зростають. Насамперед, це пов'язано з постійним ускладненням умов управління виробництвом та суспільством. Другий фактор, що також викликає загальне збільшення обсягів даних, що обробляються, теж пов'язаний з науково-технічним прогресом, а саме зі швидкими темпами появи і впровадження нових носіїв даних, засобів зберігання і доставки даних.
У структурі можливих операційз даними можна виділити такі основні:
Збір даних - накопичення даних з метою забезпечення достатньої повноти інформації для ухвалення рішень;
Формалізація даних - приведення даних, що надходять з різних джерел, до однакової форми, щоб зробити їх порівнянними між собою, тобто підвищити рівень доступності;
Фільтрування даних - відсіювання «зайвих» даних, у яких немає необхідності прийняття рішень; при цьому має зменшуватися рівень «шуму», а достовірність та адекватність даних мають зростати;
Сортування даних – упорядкування даних за заданою ознакою з метою зручності використання; підвищує доступність інформації;
Угруповання даних - об'єднання даних за заданою ознакою з метою підвищення зручності використання; підвищує доступність інформації;
Архівація даних - організація зберігання даних у зручній та легкодоступній формі; служить зниження економічних витрат за зберігання даних і підвищує загальну надійність інформаційного процесу загалом;
Захист даних-комплекс заходів, спрямованих на запобігання втраті, відтворенню та модифікації даних;
Транспортування даних - прийом та передача (доставка та постачання) даних між віддаленими учасниками інформаційного процесу; при цьому джерело даних в інформатиці прийнято називати сервером, а споживача клієнтом;
Перетворення даних - переклад даних із однієї форми на іншу чи з однієї структури на іншу. Перетворення даних часто пов'язане зі зміною типу носія, наприклад, книги можна зберігати у звичайній паперовій формі, але можна використовувати для цього і електронну форму, і мікрофотоплівку. Необхідність у багаторазовому перетворенні даних виникає також при їх транспортуванні, особливо якщо вона здійснюється засобами, які не призначені для транспортування даного виду даних. Як приклад можна згадати, що для транспортування цифрових потоків даних каналами телефонних мереж (які спочатку були орієнтовані тільки на передачу аналогових сигналів у вузькому діапазоні частот) необхідне перетворення цифрових даних в подібність звукових сигналів, чим і займаються спеціальні пристрої - телефонні модеми.
Наведений тут список типових операцій із даними далеко не повний. Мільйони людей у всьому світі займаються створенням, обробкою, перетворенням та транспортуванням даних, і на кожному робочому місці виконуються свої специфічні операції, необхідні для управління соціальними, економічними, промисловими, науковими та культурними процесами. Повний перелік можливих операцій скласти неможливо, та й не потрібно. Зараз нам важливий інший висновок: робота з інформацією може мати величезну трудомісткість, і її треба автоматизувати.
Кодування даних двійковим кодом
Для автоматизації роботи з даними, що належать до різних типів, дуже важливо уніфікувати їх форму подання - для цього зазвичай використовується прийом кодування, тобто вираз даних одного типу через дані іншого типу. Природні людські мови - це не що інше, як системи кодування понять для вираження думок у вигляді мови. До мов близько примикають абетки (системи кодування компонентів мови за допомогою графічних символів). Історія знає цікаві, хоч і безуспішні спроби створення «універсальних» мов та абет. Очевидно, безуспішність спроб їх застосування пов'язана з тим, що національні та соціальні освіти природно розуміють, що зміна системи кодування суспільних даних неодмінно призводить до зміни суспільних методів (тобто норм права та моралі), а це може бути пов'язано з соціальними потрясіннями .
Та сама проблема універсального засобу кодування досить успішно реалізується в окремих галузях техніки, науки та культури. Як приклади можна навести систему запису математичних виразів, телеграфну абетку, морську прапорцеву абетку, систему Брайля для сліпих та багато іншого.
Мал. 1,8. Приклади різних систем кодування
Своя система існує і в обчислювальній техніці - вона називається двійковим кодуванням і заснована на поданні даних послідовністю всього двох знаків: 0 і 1. Ці знаки називаються двійковими цифрами, англійською мовою - binary digit, або, скорочено, bit (біт).
Одним бітом можуть бути виражені два поняття: 0 або 1 (так чи ні, чорне чи біле, істина чи брехня тощо). Якщо кількість бітів збільшити до двох, то вже можна виразити чотири різні поняття:
Три біти можна закодувати вісім різних значень:
000 001 010 011 100 101 110 111
Збільшуючи на одиницю кількість розрядів у системі двійкового кодування, ми збільшуємо вдвічі кількість значень, що може бути виражено у цій системі.
Кодування цілих та дійсних чисел
Для кодування цілих чисел від 0 до 255 достатньо мати 8 розрядів двійкового коду (8 біт).
……………….
Шістнадцять біт дозволяють закодувати цілі числа від 0 до 65 535, а 24 біти - вже понад 16,5 мільйонів різних значень.
Для кодування дійсних чисел використовують 80-розрядне кодування. У цьому число попередньо перетворюється на нормалізовану форму.
3,1415926 = 0,31415926 · 101
300 000 = 0,3 · 106
123456789 = 0,123456789 · 109
Перша частина числа називається мантисою, а друга – характеристикою. Більшість з 80 біт відводять для зберігання мантиси (разом зі знаком) і деяку фіксовану кількість розрядів відводять для зберігання характеристики (теж зі знаком).
Кодування текстових даних
Якщо кожному символу алфавіту зіставити певне ціле число (наприклад, порядковий номер), то за допомогою двійкового коду можна кодувати і текстову інформацію. Восьми двійкових розрядів достатньо для кодування 256 різних символів. Цього вистачить, щоб висловити різними комбінаціями восьми бітів всі символи англійського та російського алфавітів, як малі, так і великі, а також розділові знаки, символи основних арифметичних дій і деякі загальноприйняті спеціальні символи, наприклад символ «§».
Технічно це виглядає дуже просто, проте завжди існували досить значні організаційні складності. У перші роки розвитку обчислювальної техніки вони пов'язані з відсутністю необхідних стандартів, а нині викликані, навпаки, достатком одночасно діючих і суперечливих стандартів. Для того, щоб весь світ однаково кодував текстові дані, потрібні єдині таблиці кодування, а це поки що неможливо через протиріччя між символами національних алфавітів, а також протиріччя корпоративного характеру.
Для англійської мови, Який захопив де-факто нішу міжнародного засобу спілкування, протиріччя вже зняті. Інститут стандартизації США (ANSI - American National Standard Institute) ввів у дію систему кодування ASCII (American Standard Code for Information Interchange - стандартний код інформаційного обміну США). У системі ASCII закріплено дві таблиці кодування: базова та розширена. Базова таблиця закріплює значення кодів від 0 до 127, а розширена відноситься до символів із номерами від 128 до 255.
Перші 32 коди базової таблиці, починаючи з нульового, віддано виробникам апаратних засобів (насамперед виробникам комп'ютерів та друкувальних пристроїв). У цій області розміщуються так звані керуючі коди, яким не відповідають жодні символи мов, і, відповідно, ці коди не виводяться ні на екран, ні на пристрої друку, але ними можна керувати тим, як виводиться інші дані.
Починаючи з коду 32 по код 127 розміщені коди символів англійського алфавіту, розділових знаків, цифр, арифметичних дій і деяких допоміжних символів. Базова таблиця кодування ASCIIнаведено у таблиці 1.1.

Аналогічні системи кодування текстових даних розробили й інших країнах. Так, наприклад, в СРСР у цій галузі діяла система кодування КОІ-7 (код обміну інформацією, семизначний). Однак підтримка виробників обладнання та програм вивела американський код ASCII на рівень міжнародного стандарту, і національним системам кодування довелося «відступити» в другу, розширену частину системи кодування, що визначає значення кодів з 128 по 255. Відсутність єдиного стандарту в цій галузі призвела до множинності одночасно діючих кодувань. Тільки в Росії можна вказати три діючі стандарти кодування та ще два застарілі.
Так, наприклад, кодування символів російської мови, відоме як кодування Windows-1251, було введено "ззовні" - компанією Microsoft, але, враховуючи широке поширення операційних систем та інших продуктів цієї компанії в Росії, вона глибоко закріпилася і знайшла широке поширення (таблиця 1.2 ). Це кодування використовується на більшості локальних комп'ютерів, які працюють на платформі Windows. Де-факто вона стала стандартною у російському секторі World Wide Web.

Інше поширене кодування зветься КОІ-8 (код обміну інформацією, восьмизначний) - його походження відноситься до часів дії Ради Економічної Взаємодопомоги держав Східної Європи (таблиця 1.3). На базі цього кодування нині діють кодування КОІ8-Р (російське) та КОІ8-У (українське). Сьогодні кодування КОІ8-Р має широке поширення в комп'ютерних мережах на території Росії та в деяких службах російського сектору Інтернету. Зокрема, у Росії вона де-факто є стандартною у повідомленнях електронної пошти та телеконференцій.

Міжнародний стандарт, у якому передбачено кодування символів російського алфавіту, зветься кодування ISO (International Standard Organization) (Міжнародний інститут стандартизації). На практиці це кодування використовується рідко (таблиця 1.4).

На комп'ютерах, що працюють в операційних системах MS-DOS, можуть діяти ще два кодування (кодування ГОСТ та кодування ГОСТ-альтернативне). Перша з них вважалася застарілою навіть у перші роки появи персональної обчислювальної техніки, але друга використовується і сьогодні (див. таблицю 1.5).

У зв'язку з достатком систем кодування текстових даних, які у Росії, виникає завдання міжсистемного перетворення даних - це з поширених завдань інформатики.
Універсальна система кодування текстових даних
Якщо проаналізувати організаційні проблеми, пов'язані зі створенням єдиної системи кодування текстових даних, можна дійти невтішного висновку, що вони викликані обмеженим набором кодів (256). У той самий час очевидно, що й, наприклад, кодувати символи не восьмиразрядными двійковими числами, а числами з великою кількістю розрядів, то діапазон можливих значень кодів стане набагато більше. Така система, що базується на 16-розрядному кодуванні символів, отримала назву універсальної - UNICODE. Шістнадцять розрядів дозволяють забезпечити унікальні коди для 65 536 різних символів - цього поля достатньо для розміщення в одній таблиці символів більшості мов планети.
Незважаючи на очевидну очевидність такого підходу, простий механічний перехід на цю систему довгий час стримувався через недостатні ресурси засобів обчислювальної техніки (у системі кодування UNICODE всі текстові документи автоматично стають удвічі довшими). У другій половині 90-х років технічні засоби досягли необхідного рівня забезпеченості ресурсами, і сьогодні ми спостерігаємо поступове переведення документів та програмних засобів на універсальну систему кодування. Для індивідуальних користувачів це ще більше додало турбот за узгодженням документів, виконаних у різних системах кодування, з програмними засобами, але це треба розуміти як труднощі перехідного періоду.
Кодування графічних даних
Якщо розглянути за допомогою збільшувального скла чорно-біле графічне зображення, надруковане в газеті або книзі, то можна побачити, що воно складається з найдрібніших точок, що утворюють характерний візерунок, званий растром (рис. 1.9).

Мал. 1.9. Растр - це метод кодування графічної інформації,
здавна прийнятий у поліграфії
Оскільки лінійні координати та індивідуальні властивості кожної точки (яскравість) можна виразити за допомогою цілих чисел, можна сказати, що растрове кодування дозволяє використовувати двійковий код для представлення графічних даних. Загальноприйнятим на сьогоднішній день вважається представлення чорно-білих ілюстрацій у вигляді комбінації крапок із 256 градаціями сірого кольору, і, таким чином, для кодування яскравості будь-якої точки зазвичай достатньо восьмирозрядного двійкового числа.
Для кодування кольорових графічних зображень застосовується принцип декомпозиції довільного кольору основні складові. Як такі складові використовують три основні кольори: червоний (Red, R), зелений (Green, G) та синій (Blue, В). Насправді вважається (хоча теоретично це зовсім так), що будь-який колір, видимий людським оком, можна отримати шляхом механічного змішування цих трьох основних кольорів. Така система кодування називається системою RGB за першими літерами назв основних кольорів.
Якщо для кодування яскравості кожної з основних складових використовувати по 256 значень (вісім двійкових розрядів), як це прийнято для напівтонових чорно-білих зображень, то кодування кольору однієї точки треба витратити 24 розряду. При цьому система кодування забезпечує однозначне визначення 16,5 млн. різних кольорів, що насправді близько до чутливості людського ока. Режим представлення кольорової графіки з використанням 24 двійкових розрядів називається повнокольоровим (True Color).
Кожному з основних кольорів можна поставити додатковий колір, тобто колір, що доповнює основний колір до білого. Неважко помітити, що для будь-якого з основних кольорів додатковим буде колір, утворений сумою кількох основних кольорів. Відповідно, додатковими кольорами є: блакитний (Cyan, С), пурпуровий (Magenta, M) та жовтий (Yellow, Y). Принцип декомпозиції довільного кольору на компоненти можна застосовувати не тільки для основних кольорів, але і для додаткових, тобто будь-який колір можна представити у вигляді суми блакитної, пурпурової та жовтої складової. Такий метод кодування кольору прийнятий у поліграфії, але у поліграфії використовується ще й четверта фарба – чорна (Black, К). Тому дана система кодування позначається чотирма літерами CMYK (чорний колір позначається літерою К, тому що буква вже зайнята синім кольором), і для представлення кольорової графіки в цій системі треба мати 32 двійкових розряду. Такий режим також називається повнокольоровим (True Color).
Якщо зменшити кількість двійкових розрядів, що використовуються для кодування кольору кожної точки, можна скоротити обсяг даних, але при цьому діапазон кодованих кольорів помітно скорочується. Кодування кольорової графіки 16-розрядними двійковими числами називається режимом High Color.
При кодуванні інформації про колір за допомогою восьми біт даних можна передати лише 256 відтінків кольорів. Такий метод кодування кольору називається індексним. Сенс назви в тому, що оскільки 256 значень зовсім недостатньо, щоб передати весь діапазон кольорів, доступний людському оку, код кожної точки растру виражає не колір сам по собі, а тільки його номер (індекс) в якійсь довідковій таблиці, яка називається палітрою. Зрозуміло, ця палітра повинна прикладатися до графічних даних - без неї не можна скористатися методами відтворення інформації на екрані або папері (тобто скористатися, звичайно, можна, але через неповноту даних отримана інформація не буде адекватною: листя на деревах може виявитися червоним, а небо – зеленим).
Кодування звукової інформації
Прийоми та методи роботи зі звуковою інформацією прийшли до обчислювальної техніки найпізніше. До того ж, на відміну від числових, текстових і графічних даних, звукозаписи не мали такої ж тривалої та перевіреної історії кодування. У результаті способи кодування звукової інформації двійковим кодом далекі від стандартизації. Безліч окремих компаній розробили свої корпоративні стандарти.
Лекція №4.
Кодування даних двійковим кодом
Для автоматизації роботи з даними, що належать до різних типів, дуже важливо уніфікувати їхню форму подання. І тому зазвичай використовують прийом кодування, тобто. вираз даних одного типу через дані іншого типу.
Приклади систем кодування: людські мови, абетки (кодування мови за допомогою графічних символів), запис математичних виразів, телеграфна абетка Морзе, код Брайля для сліпих, морська абетка прапорця і т.п.
Своя система кодування існує і в обчислювальній техніці - вона називається двійковим кодуванням і заснована на поданні даних послідовністю всього двох знаків: 0 та 1. Ці знаки називаються двійковими цифрами або біт.
Одним бітом можна виразити два поняття: 0 або 1 (та йди ні, чорне чи біле, істина чи брехня тощо). Якщо збільшити кількість бітів до двох, то можна виразити чотири різних поняття – 00 01 10 11. Трьома бітами можна закодувати вже вісім різних понять – 000 001 010 100 101 110 101 111.
Збільшуючи на одиницю кількість розрядів у системі двійкового кодування, можна збільшити вдвічі кількість значень, яку можна закодувати: N=2 I, де I- Число розрядів, N- Кількість значень.
Комп'ютер може обробляти цифрові, текстові, графічні, звукові та відео дані. Усі ці види даних кодуються у послідовності електричних імпульсів: є імпульс (1), немає імпульсу (0), тобто. у послідовності нулів та одиниць. Такі логічні послідовності нулів та одиниць називаються машинною мовою.
Система зчислення
Що таке система числення?
Існують позиційні та непозиційні системи числення.
У непозиційнихсистемах вага цифри (тобто той внесок, який вона вносить у значення числа) не залежить від її позиції у записі числа. Так, у римській системі числення в числі ХХХII (тридцять два) вага цифри Х у будь-якій позиції дорівнює просто десяти.
У позиційнихсистемах числення вага кожної цифри змінюється в залежності від її положення (позиції) у послідовності цифр, що зображують число. Наприклад, серед 757,7 перша сімка означає 7 сотень, друга – 7 одиниць, а третя – 7 десятих часток одиниці.
Сама ж запис числа 757,7 означає скорочений запис виразу
700 + 50 + 7 + 0,7 = 7 10 2 + 5 10 1 + 7 10 0 + 7 10 -1 = 757,7.
Будь-яка позиційна система числення характеризується своєю основою.
За основу системи можна прийняти будь-яке натуральне число – два, три, чотири тощо. Отже, можливо безліч позиційних систем: двійкова, трійкова, четвіркова і т.д. Запис чисел у кожній із систем числення з основою qозначає скорочений запис виразу
a n-1 q n-1 + a n-2 q n-2 + ... + a 1 q 1 + a 0 q 0 + a -1 q -1 + ... + a -m q -m ,
де a i- Цифри системи числення; nі m- Число цілих і дробових розрядів, відповідно.
Які системи числення використовують фахівці для спілкування з комп'ютером?
Крім десяткової широко використовуються системи з основою, що є цілою ступенем числа 2, а саме:
двійкова (використовуються цифри 0, 1);
вісімкова (використовуються цифри 0, 1, ..., 7);
шістнадцяткова (для перших цілих чисел від нуля до дев'яти використовуються цифри 0, 1, ..., 9, а для наступних чисел - від десяти до п'ятнадцяти – як цифри використовуються символи A, B, C, D, E, F).
Чому люди користуються десятковою системою, а комп'ютери – двійковою?
Люди віддають перевагу десятковій системі, мабуть, тому, що з давніх часів рахували на пальцях, а пальців у людей по десять на руках і ногах. Не завжди і скрізь люди користуються десятковою системою числення. У Китаї, наприклад, тривалий час користувалися п'ятирічною системою числення.
А комп'ютери використовують двійкову систему тому, що вона має низку переваг перед іншими системами:
для її реалізації потрібні технічні пристрої з двома стійкими станами (є струм - немає струму, намагнічний - не намагнічний тощо), а не, наприклад, з десятьма, - як у десятковій;
подання інформації у вигляді лише двох станів надійно і завадостійке;
можливе застосування апарату булевої алгебри для виконання логічних перетворень інформації;
двійкова арифметика набагато простіша за десяткову.
Недолік двійкової системи - швидке зростання числа розрядів, необхідні записи чисел.
Чому в комп'ютерах використовуються також вісімкова та шістнадцяткова системи числення?
Двійкова система, зручна для комп'ютерів, для людини незручна через неї громіздкостіі незвичного запису.
Переведення чисел із десяткової системи у двійкову і навпаки виконує машина. Однак, щоб професійно використовувати комп'ютер, слід навчитися розуміти слово машини. Для цього і розроблено вісімкову та шістнадцяткову системи.
Числа в цих системах читаються майже так само легко, як десяткові, вимагають відповідно о третій(вісімкова) та о четвертій(шістнадцяткова) рази менше розрядів, ніж у двійковій системі (адже числа 8 та 16 – відповідно, третій та четвертий ступеня числа 2).
Двійкова система числення
p align="justify"> Особлива значимість двійкової системи числення в інформатиці визначається тим, що внутрішнє уявлення будь-якої інформації в комп'ютері є двійковим, тобто. описуваним наборами тільки двох знаків (0 і 1).
Переведення з десяткової системи до двійкової
Ціла та дробова частини переводяться порізно. Для перекладу цілої частини числа необхідно її розділити на основу системи числення 2 і продовжувати ділити приватні від поділу до тих пір, поки приватне не стане рівним 0. Значення залишків, взяті в зворотній послідовності, утворюють шукане двійкове число.
Наприклад,
25 (10) = 11001 (2)
Для перекладу дробової частини треба помножити її на 2. Ціла частина добутку буде першою цифрою числа у двійковій системі. Потім, відкидаючи у результату дробову частину, знову множимо на 2 і т.д. Кінцевий десятковий дріб при цьому цілком може стати нескінченним (періодичним) двійковим.
Наприклад,
0,73 * 2 = 1,46 (ціла частина 1)
0,46 * 2 = 0,92 (ціла частина 0)
0,92 * 2 = 1,84 (ціла частина 1)
0,84 * 2 = 1,68 (ціла частина 1) і т.д. 0,73 (10) = 0,1011 ... (2)
Арифметичні операції з двійковими числами
При двійковому додаванні 1 + 1 виникає перенесення 1 до старшого розряду, як і в десятковій арифметиці. Наприклад,
При двійковому відніманніНеобхідно пам'ятати, що зайнята у найближчому розряді 1, дає дві одиниці молодшого розряду. Якщо сусідніх старших розрядах стоять нулі, то 1 займається через кілька розрядів. При цьому одиниця, зайнята в найближчому значущому старшому розряді, дає дві одиниці молодшого розряду та одиниці у всіх нульових розрядах, що стоять між молодшим і старшим розрядом, у якого бралася одиниця.
Віднімемо 174 з 197

Розподіл двійкових чиселвідбувається з використанням двійкових таблиць множення та віднімання. Розділимо 430 на 10

Вісімкова та шістнадцяткова системи числення
Переведення чисел із десяткової системи у вісімковувиробляється також як і двійкову за допомогою множення і поділу, тільки не на 2, а на 8.
Наприклад, 58,32 (10)
58: 8 = 7 (2 у залишку)
7: 8 = 0 (7 у залишку)
0,48 * 8 = 3,84, …
58,32 (10) = 72,243… (8)
Переведення чисел із десяткової системи числення в 16-річну проводиться аналогічно. 567(10)0 = 237(16)
Відповідність чисел у різних системах числення
|
Десяткова |
Шістнадцяткова |
Вісімкова |
Двійкова |
Для переведення цілого двійкового числа у вісімковенеобхідно розбити його праворуч наліво на групи по 3 цифри (найліва група може містити менше трьох двійкових цифр), а потім кожній групі поставити у відповідність її вісімковий еквівалент. Такі групи називають двійковими тріадами.
Наприклад,
11011001 = 11 011 001 = 331 (8)
Переведення цілого двійкового числа до шістнадцятковогопровадиться шляхом розбиття даного числа на групи по 4 цифри – двійкові зошити.
1100011011001 = 1 1000 1101 1001 = 18D9 (16)
Для переведення дробових частин двійкових чисел у вісімкову або шістнадцяткову системи аналогічне розбиття на тріади або зошити проводиться від коми вправо (з доповненням останніх цифр, що відсутні, нулями)
0,1100011101 (2) = 0,110 001 110 100 = 0,6164 (8)
0,1100011101 (2) = 0,1100 0111 0100 = С74 (16)
Переведення вісімкових (шістнадцяткових) чисел у двійкові здійснюється зворотним шляхом – зіставленням кожному знаку числа відповідної трійки (четвірки) двійкових цифр.
А1F (16) = 1010 0001 1111 (2)
127 (8) = 001 010 111 (2)
Простота подібних перетворень пов'язана з тим, що числа 8 і 16 є цілими ступенями числа 2. Цією простотою пояснюється популярність восьмирічної та шістнадцяткової систем числення.
Список веб-сайтів для вчителів (2)
ДокументДолоні Архів лекційз астрономії... кодування, кодування даних двійковим кодом, кодуваннятекстових даних, системи кодування, кодуванняграфічних даних, кодуваннязвукової інформації Універсальна система кодуваннятекстових даних ...
Конспект лекцій з навчальної дисципліни системи зв'язку з рухомими об'єктами (найменування навчальної дисципліни) за спеціальністю (напрямок підготовки)
Конспект лекцій... Кодування Лекція 11. ОСНОВИ ВИНАХОДАЮЧИХ І КОРЕКТУЮЧИХ КОДІВКоротка інструкція лекції: ... числа інформаційних розрядів k, і для двійкових кодів: , . Верхня межа... передачі застосовується метод кодування даних, Званий ортогональним...
Матеріали лекцій на предмет «Електронні промислові пристрої» Сфера знань
Документ... . Кодуванняінформації. Основні види кодів ................................................................. 19 Лекція 6. ... її отримання данимиспоживачем; релевантність... двійковий кодта його модифікація - симетричний двійковий код. Двійкові коди ...
Кодування даних
Кодування даних двійковим кодом
Для автоматизації роботи з даними, що належать до різних типів, дуже важливо уніфікувати їх форму подання - для цього зазвичай використовується прийом кодування тобто вираз даних одного типу через дані іншого типу. Природні людські мови - це не що інше, як системи кодування понять для вираження думок у вигляді мови. До мов близько примикають абетки (системи кодування компонентів мови за допомогою графічних символів). Історія знає цікаві, хоч і безуспішні спроби створення «універсальних» мов та абет. Очевидно, безуспішність спроб їх застосування пов'язана з тим, що національні та соціальні освіти природно розуміють, що зміна системи кодування суспільних даних неодмінно призводить до зміни суспільних методів (тобто норм права та моралі), а це може бути пов'язано з соціальними потрясіннями .
Та сама проблема універсального засобу кодування досить успішно реалізується в окремих галузях техніки, науки та культури. Як приклади можна навести систему запису математичних виразів, телеграфну абетку, морську прапорцеву абетку, систему Брайля для сліпих та багато іншого,
Своя система існує і в обчислювальній техніці - вона називається двійковим кодуванням і заснована на поданні даних послідовністю всього двох знаків: 0 і 1. Ці знаки називаються двійковими цифрами, англійською мовою - binaiy digit або скорочено bit (біт).
Одним бітом можуть бути виражені два поняття: 0 або 1 (так чи ні, чорне чи біле, істина чи брехня тощо). Якщо кількість бітів збільшити до двох, то вже можна виразити чотири різні поняття:
Три біти можна закодувати вісім різних понять:
000 001 010 011 100 101 110 111
Тобто, збільшуючи на одиницю кількість розрядів у системі двійкового кодування, ми збільшуємо вдвічі кількість значень, яка може бути виражена в цій системі. Загальна формула:
де N – кількість незалежних значень, що кодуються;
m – розрядність двійкового кодування, прийнята у цій системі.
Найбільшою одиницею уявлення, і навіть вимірювання даних є байт.
8 біт – 1 байт
1024 байти – 1 кілобайт (Кбайт)
1024 кілобайти – 1 мегабайт (Мбайт)
1024 мегабайти – 1 гігабайт (Гбайт)
Основні типи даних, що обробляються комп'ютером:
Цілі та дійсні числа.
Текстові дані
графічні дані.
Звукові дані.
Кодування цілих та дійсних чисел
Цілі числа кодуються двійковим кодом досить просто - достатньо взяти ціле число і ділити його навпіл до тих пір, поки приватне не буде рівним одиниці. Сукупність залишків від кожного поділу, записана праворуч наліво разом з останнім приватним, і утворює двійковий аналог десяткового числа:
Таким чином, 1910 = 100112.
Для кодування цілих чисел від 0 до 255 достатньо мати 8 розрядів двійкового коду (8 біт). Шістнадцять біт дозволяють закодувати цілі числа від 0 до 65535, а 24 біти - вже більше 16,5 мільйонів різних значень.
Для кодування дійсних чисел використовують 80-розрядне кодування. При цьому число попередньо перетворюється на нормалізовану форму:
3,1415926=0,31415926*10 1
300 000 = 0,3*10 6
123 456 789 = 0,123456789*10 10
Перша частина числа називається мантисою , а друга - характеристикою . Більшість з 80 біт відводять для зберігання мантиси (разом зі знаком) і деяку фіксовану кількість розрядів відводять для зберігання характеристики (теж зі знаком).
Кодування текстових даних
Якщо кожному символу алфавіту можна порівняти певне ціле число (наприклад, порядковий номер), то за допомогою двійкового коду можна кодувати текстову інформацію. Восьми двійкових розрядів достатньо для кодування 256 різних символів. Цього вистачить, щоб висловити різними комбінаціями восьми бітів всі символи англійської та російської мов, як малі, так і великі, а також розділові знаки, символи основних арифметичних дій і деякі загальноприйняті спеціальні символи, наприклад символ «§».
Технічно це виглядає дуже просто, проте завжди існували досить значні організаційні складності. У перші роки розвитку обчислювальної техніки вони пов'язані з відсутністю необхідних стандартів, а нині викликані, навпаки, достатком одночасно діючих і суперечливих стандартів. Для того, щоб весь світ однаково кодував текстові дані, потрібні єдині таблиці кодування, а це поки що неможливо через протиріччя між символами національних алфавітів, а також протиріччя корпоративного характеру.
Для англійської мови, яка захопила де-факто нішу міжнародного засобу спілкування, протиріччя вже знято. Інститут стандартизації США (ANSI - American National Standard Institute) ввів у дію систему кодування ASCII (American Standard Code for Information Interchange - стандартний код інформаційного обміну США). У системі ASCII закріплені дві таблиці кодування – базова та розширена. Базова таблиця закріплює значення кодів від 0 до 127, а розширена відноситься до символів із номерами від 128 до 255.
Перші 32 коди базової таблиці, починаючи з нульового, віддано виробникам апаратних засобів (насамперед виробникам комп'ютерів та друкувальних пристроїв). У цій області розміщуються так звані керуючі коди, яким не відповідають жодні символи мов, і, відповідно, ці коди не виводяться ні на екран, ні на пристрої друку, але ними можна керувати тим, як виводиться інші дані.
Починаючи з коду 32 по код 127 розміщені коди символів англійського алфавіту, розділових знаків, цифр, арифметичних дій і деяких допоміжних символів. Базова таблиця кодування ASCII наведена у таблиці 1.1:
|
Таблиця 1.1. |
Базова таблиця кодуванняASCIIASCII |
||||||||||
|
32 чаївипрррпробіл |
|||||||||||
|
44 , |
|||||||||||
|
Документ Лекція №4. Кодування данихдвійковим кодом Для автоматизації роботи з даними, що відносяться до різних типів, дуже важливо... зазвичай використовують прийом кодування, тобто. вираз даниходного типу через данііншого типу. Приклади... Даний витвір (інструкція / faq) буде постійно доповнюватись та редагуватись. Свої побажання, рекомендації, описи, зауваження можна залишати на форумі або звертатись до мене через форму Контакти.ІнструкціяЧутка більшості людей. Данийметод називають кодуваннямсприйняття. При цьому... потрібно отримати один, після кодування. Данийпункт меню викликає вікно, що спливає... - то це схема відновлення данихз кодованоговиду, в якому вони передаються... Даний навчальний посібник містить у собі весь курс інформатики, яка потрібна на підготовки фахівців у системі вищої освіти. Тематична структура посРефератНеобхідну інформацію. 1.3. Подання ( кодування) даних 1.3.1. Системи числення Існують різні... інформації 6 1.1.4. Інформаційні 9 1.3. Подання ( кодування) даних 10 1.3.1. Системи числення 10 1.3.2. Подання... Фізичне кодуванняДокумент... кодуваннята логічне кодуванняутворюють систему кодуваннянайнижчого рівня. Системи кодуванняСистеми кодування даних... Найчастіше використовувані системи кодування: NRZ (Non ... 1. Поняття кодування інформації. Універсальність дискретного (цифрового) подання інформації. Позиційні та непозиційні системи числення. АлгоритмиДокументВнаслідок важливості даногопроцесу він має спеціальну назву - кодуванняінформації. Кодуванняінформації надзвичайно... навести деякі приклади методів дискретного кодування даних: тексти, графіка, звук. Для економії... | |||||||||||
Для автоматизації робіт з даними використовують спеціальні види пристроїв, які називають обчислювальною технікою.
Пк це універсальна технічна система, його конфігурацію можна гнучко змінювати при необхідності
7. Периферійні пристрої пк
Вирішення цієї задачі засноване на моделі osi (Open System Interconnection)
Інтернет це міжмережа, що представляє собою з'єднання опорних (маагістарльних) мереж.
Протокол обміну гіпертекстовою інформацією
12 Поняття алгоритму
13. Об'єктно-орієнтоване програмування. 13 Об'єктно-орієнтований підхід
§ 2 Дані та кодування інформації
Дані – це діалектичні складові інформації. Вони є зареєстрованими сигналами.
При цьому фізичний метод реєстрації будь-яким м/б (переміщення фізичних тіл або параметрів поверхні, зміна електричних, магнітних або оптичних характеристик, хімічного складу і т. д.)
Відповідно до методу реєстрації дані можуть зберігатися та транспортуватися на носіях різних типів.
При цьому необхідно на увазі, що властивості інформації тісно пов'язані з властивостями її носіїв.
Для звичайного споживача доступність інформації в книзі помітно вище, ніж тієї ж інформації на компакт-диску, тому що не всі мають ці обладнання.
Операції з даними
У ході інформаційного процесу дані перетворюються з одного виду на інший за допомогою методів.
Обробка даних включає безліч різних операцій, з яких можна виділити наступні:
Збір даних – накопичення інформації з метою забезпечення достатньої для прийняття рішень
Формалізація даних – приведення даних, які з різних джерел до однакової формі, щоб зробити їх порівнянними між собою, т. е. підвищити рівень доступності.
Фільтрація даних – відсіювання непотрібних даних, у яких немає необхідності прийняття рішень; при цьому має зменшуватися рівень шуму, а достовірність та адекватність даних мають зростати.
Сортування даних – упорядкування даних за заданою ознакою з метою зручності використання, що підвищує достовірність інформації
Архівація даних – організація зберігання даних у зручній та доступній формі, служить для зниження економічних витрат із зберігання даних та підвищує загальну надійність інформаційного процесу
Захист даних – комплекс заходів, спрямованих на надання втрати, відтворення та модифікації даних
Транспортування даних – прийом та передача даних між віддаленими учасниками інформаційного процесу; при цьому джерело даних прийнято називати сервером, а споживача клієнтом
Перетворення даних – переведення даних з однієї форми на іншу або з однієї структури на іншу
Кодування даних двійковим кодом
………………………………………………………………………………
що відносяться до різних типів, дуже важливо уніфікувати їх форму уявлення.
Для цього зазвичай використовується прийом кодування, тобто вираз даних одного типу через дані іншого типу. Як приклади можна навести систему запису математичних виразів, телеграфну абетку, систему Брайле для сліпих, морську прапорцеву абетку тощо.
Своя система існує і в обчислювальній техніці - вона називається двійковим кодуванням і заснована на поданні даних послідовністю всього двох знаків 0 та 1.
Ці знаки називаються двійковими цифрами (англійською binary digit) або скорочено bit 1 біт.
Одним бітом м/б виражені два поняття: 0 або 1, так чи ні, чорне чи біле, істина чи брехня. буд.
Якщо кількість бітів збільшити до 2 то можна висловити чотири різних поняття.
Три біти можна закодувати вісім різних значень: 000 001 010 011 100 101 110 111
Збільшуючи на одиницю кількість розрядів у системі двійкового кодування, збільшується в 2 рази кількість значень, що м/б виражено в даній системі, загальна формула має вигляд:
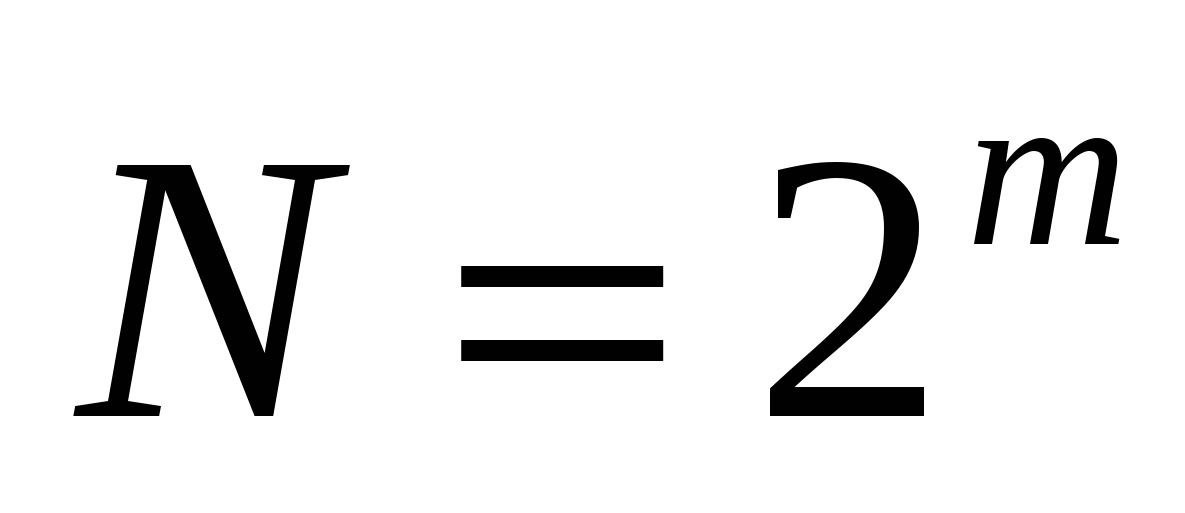
Де N – кількість незалежних значень, що кодуються
M – розрядність двійкового кодування, прийняте у цій системі
Кодування цілих та дійсних чисел
Цілі числа кодуються двійковим кодом, таким чином: береться ціле число і ділиться навпіл доти, поки в залишку не утворюється нуль або одиниця.
Сукупність залишків від кожного поділу, записана справа наліво разом із останнім залишком утворює двійковий аналог десяткового числа
Т. е. 19 10 = 10011 2
Для кодування цілих чисел від 0 до 255 достатньо мати 8 розрядів двійкового коду (8 біт)
16 біт дозволяють закодувати цілі числа від 0 до 65535
24 біти – вже понад 16,5 мільйонів різних значень.
Для кодування дійсних чисел використовують 80-розрядне кодування.
При цьому число попередньо перетворюється на нормалізовану форму:
3,1415926 = 0,31415926 * 10 1
300000 = 0,3 * 10 6
123456789 = 0,123456789 * 10 10
Перша частина числа називається,,, - характеристикою. Більшу частину з 80 біт відводять для зберігання мантиси в місці зі знаком, і деяку кількість розрядів, що флісують, відводять для зберігання характеристики 10 знаків.
Кодування текстових даних
Якщо кожному символу алфавіту можна порівняти певне ціле число (порядковий номер), то за допомогою двійкового коду можна кодувати текстову інформацію. Восьми двійкових символівдля кодування 256 різних символів. Для англійської мови інститут стандартизації США (ANSI – American National Standard Institute) ввів у дію систему кодування ASCII (American Standard Code for Information Interchange) – стандартний код інформаційного обміну США.
У системі ASCII дві ……. кодування – базова та розширена. Базова таблиця закріплює значення кодів від 0 до 127, а розширена відноситься до символів із номерами від 128 до 255.
Перші 32 коди базової таблиці віддано виробникам апаратних засобів. У цій галузі розміщуються d. a. керуючі коди, яким не відповідає жодних символів мов.
Ці коди не виводяться не виводяться не на екран, ні на пристрої друку, але вони керують тим, як виводиться інші дані.
Крім ASCII існують такі кодування як KON - 8 (код обміну інформацією, 8-значний), кодування Windows, кодування ISO, UNICODE, ГОСТ - альтернативне кодування.
Кодування графічних даних
Якщо збільшити ч/б графічні зображення, надруковані в газеті або книзі, можна побачити, що воно складається з дрібних точок, що утворює характерний візерунок, званий растром.
Оскільки лінійні координати і колір кожної точки можна виразити за допомогою цілих чисел, можна сказати, що растрове кодування використовує двійковий код для представлення графічних даних.
Для кодування кольорових зображень застосовується принцип декомпозиції довільного кольору основні складові.
Як такі складові використовують 3 основні кольори:
Червоний (Red, R)
Зелений (Green, G)
Синій (Blue, B)
Така система кодування називається RGB за першими буквами назв кольорів.
Кодування кольорової графіки 16-розрядними двійковими числами називається режимом High Color. А режим подання кольорової графіки з використанням 24 двійкових розрядів називається поанокольоровим (…………).

