17.07.2019
การถอดรหัสรหัส ASCII การเข้ารหัส ASCII
วัสดุสำหรับ การศึกษาด้วยตนเองในหัวข้อการบรรยายครั้งที่ 2
ตารางการเข้ารหัส ASCII (ASCII - รหัส American Standard สำหรับการแลกเปลี่ยนข้อมูล - รหัส American Standard สำหรับการแลกเปลี่ยนข้อมูล)
โดยรวมแล้วสามารถเข้ารหัสอักขระที่แตกต่างกันได้ 256 ตัวโดยใช้ตารางการเข้ารหัส ASCII (รูปที่ 1) ตารางนี้แบ่งออกเป็นสองส่วน: ส่วนหลัก (พร้อมรหัสตั้งแต่ OOh ถึง 7Fh) และส่วนเพิ่มเติม (ตั้งแต่ 80h ถึง FFh โดยที่ตัวอักษร h ระบุว่ารหัสนั้นเป็นของระบบเลขฐานสิบหก)
ภาพที่ 1
ในการเข้ารหัสอักขระหนึ่งตัวจากตาราง จะมีการจัดสรร 8 บิต (1 ไบต์) เมื่อประมวลผลข้อมูลข้อความ หนึ่งไบต์อาจมีรหัสของอักขระบางตัว เช่น ตัวอักษร ตัวเลข เครื่องหมายวรรคตอน เครื่องหมายการกระทำ ฯลฯ อักขระแต่ละตัวมีรหัสของตัวเองในรูปของจำนวนเต็ม ในกรณีนี้ รหัสทั้งหมดจะถูกรวบรวมไว้ในตารางพิเศษที่เรียกว่าตารางการเข้ารหัส ด้วยความช่วยเหลือของพวกเขา รหัสสัญลักษณ์จะถูกแปลงเป็นการแสดงที่มองเห็นได้บนหน้าจอมอนิเตอร์ ด้วยเหตุนี้ ข้อความใดๆ ในหน่วยความจำคอมพิวเตอร์จึงแสดงเป็นลำดับไบต์พร้อมรหัสอักขระ
เช่น คำว่า Hello! จะถูกเข้ารหัสดังนี้ (ตารางที่ 1)
ตารางที่ 1
รูปที่ 1 แสดงอักขระที่รวมอยู่ในการเข้ารหัส ASCII มาตรฐาน (อังกฤษ) และแบบขยาย (รัสเซีย)
ครึ่งแรกของตาราง ASCII เป็นมาตรฐาน ประกอบด้วยรหัสควบคุม (ตั้งแต่ 00 ชม. ถึง 20 ชม. และ 77 ชม.) รหัสเหล่านี้ถูกลบออกจากตารางแล้ว เนื่องจากใช้ไม่ได้กับองค์ประกอบข้อความ เครื่องหมายวรรคตอนและสัญลักษณ์ทางคณิตศาสตร์ก็อยู่ที่นี่เช่นกัน: 2lh - !, 26h - &, 28h - (, 2Bh -+,..., ใหญ่และเล็ก ตัวอักษร: 41 ชม. - ก, 61 ชม. – ก.
ครึ่งหลังของตารางประกอบด้วยแบบอักษรประจำชาติ สัญลักษณ์เทียมที่ใช้สร้างตาราง และสัญลักษณ์ทางคณิตศาสตร์พิเศษ ส่วนล่างของตารางการเข้ารหัสสามารถแทนที่ได้โดยใช้ไดรเวอร์ที่เหมาะสม - ควบคุมโปรแกรมเสริม เทคนิคนี้ช่วยให้คุณใช้แบบอักษรและแบบอักษรได้หลายแบบ
การแสดงรหัสสัญลักษณ์แต่ละรายการควรแสดงรูปภาพของสัญลักษณ์ ไม่ใช่แค่รหัสดิจิทัล แต่เป็นรูปภาพที่เกี่ยวข้องกัน เนื่องจากแต่ละสัญลักษณ์มีรูปร่างของตัวเอง คำอธิบายรูปร่างของอักขระแต่ละตัวจะถูกจัดเก็บไว้ในหน่วยความจำแสดงผลพิเศษ - เครื่องกำเนิดอักขระ ตัวอย่างเช่น การเน้นอักขระบนหน้าจอของจอแสดงผล IBM PC นั้นดำเนินการโดยใช้จุดที่สร้างเมทริกซ์อักขระ แต่ละพิกเซลในเมทริกซ์ดังกล่าวเป็นองค์ประกอบภาพและอาจสว่างหรือมืดได้ จุดมืดจะถูกเข้ารหัสเป็น 0 จุดสว่าง (สว่าง) เป็น 1 หากคุณแสดงพิกเซลสีเข้มในช่องเมทริกซ์ของเครื่องหมายเป็นจุด และพิกเซลแสงเป็นเครื่องหมายดอกจัน คุณสามารถแสดงรูปร่างของสัญลักษณ์เป็นกราฟิกได้
ผู้คนในประเทศต่างๆ ใช้สัญลักษณ์เพื่อเขียนคำในภาษาของตนเอง ในปัจจุบัน แอปพลิเคชันส่วนใหญ่ รวมถึงระบบอีเมลและเว็บเบราว์เซอร์เป็นแบบ 8 บิต ซึ่งหมายความว่าสามารถแสดงและยอมรับเฉพาะอักขระ 8 บิตได้อย่างถูกต้องเท่านั้น ตามมาตรฐาน ISO-8859-1
ในโลกนี้มีตัวละครมากกว่า 256 ตัว (หากพิจารณาจากซีริลลิก อารบิก จีน ญี่ปุ่น เกาหลี และไทย) และตัวละครใหม่ ๆ ก็ปรากฏขึ้นมากขึ้นเรื่อยๆ และสิ่งนี้ทำให้เกิดช่องว่างสำหรับผู้ใช้จำนวนมากดังต่อไปนี้:
ไม่สามารถใช้อักขระจากชุดการเข้ารหัสที่แตกต่างกันในเอกสารเดียวกันได้ เนื่องจากเอกสารข้อความแต่ละฉบับใช้ชุดการเข้ารหัสของตัวเอง จึงเป็นเรื่องยากมากในการจดจำข้อความอัตโนมัติ
สัญลักษณ์ใหม่ปรากฏขึ้น (เช่น: ยูโร) ซึ่งเป็นผลมาจากการที่ ISO กำลังพัฒนามาตรฐานใหม่ ISO-8859-15 ซึ่งคล้ายกับมาตรฐาน ISO-8859-1 มาก ข้อแตกต่างก็คือตารางการเข้ารหัส ISO-8859-1 แบบเก่าได้ลบสัญลักษณ์สำหรับสกุลเงินเก่าที่ไม่ได้ใช้ในปัจจุบันออก เพื่อให้มีที่ว่างสำหรับสัญลักษณ์ที่เพิ่งเปิดตัว (เช่น ยูโร) เป็นผลให้ผู้ใช้อาจมีเอกสารเดียวกันบนดิสก์ แต่มีการเข้ารหัสต่างกัน วิธีแก้ปัญหาเหล่านี้คือการนำชุดการเข้ารหัสสากลชุดเดียวมาใช้ เรียกว่า การเข้ารหัสสากลหรือยูนิโค้ด
เมื่อ ASCII ถูกสร้างขึ้น อักขระควบคุมที่มีอยู่ในโทรพิมพ์และเครื่องพิมพ์ดีดจะรวมอยู่ด้วยที่จุดเริ่มต้นของการเข้ารหัส และเมื่อเวลาผ่านไป อักขระเหล่านั้นก็ติดอยู่ที่นั่นอย่างแน่นหนา แม้ว่าในศตวรรษที่ 21 อักขระเหล่านี้จะไม่ได้ใช้งานจริงก็ตาม
นี่คือข้อมูลโดยละเอียดเกี่ยวกับการเข้ารหัส ASCII:
แอสกี(ภาษาอังกฤษ) กชาวเมริกัน สมาตรฐาน คบทกวีสำหรับ ฉันข้อมูล ฉัน nterchange, [ˈæs.ki]) เป็นชื่อของตาราง (การเข้ารหัส, ชุด) ซึ่งรหัสตัวเลขเชื่อมโยงกับอักขระทั่วไปบางตัวที่พิมพ์และไม่สามารถพิมพ์ได้ โต๊ะได้รับการพัฒนาและเป็นมาตรฐานในประเทศสหรัฐอเมริกาเมื่อปี พ.ศ. 2506 ชื่อ "ASCII" ในภาษารัสเซียมักออกเสียงว่า [ ถามฉัน].
ตาราง ASCII กำหนดรหัสสำหรับอักขระ:
- เลขทศนิยม
- อักษรละติน;
- ตัวอักษรประจำชาติ
- เครื่องหมายวรรคตอน;
- อักขระควบคุม
เรื่องราว
ในขั้นต้น (พ.ศ. 2506) ASCII ได้รับการพัฒนาเพื่อเข้ารหัสอักขระที่มีโค้ดอยู่ใน 7 บิต (128 อักขระ; 27 = 128) ในขณะที่บิตที่ 7 ที่สำคัญที่สุด (นับจากศูนย์) ใช้เพื่อควบคุมข้อผิดพลาดที่เกิดขึ้นระหว่างการส่งข้อมูล
เมื่อเวลาผ่านไป การเข้ารหัสได้ขยายเป็น 256 อักขระ (28=256) รหัส 128 ตัวอักษรแรกไม่มีการเปลี่ยนแปลง ASCII เริ่มถูกมองว่าเป็นครึ่งหนึ่งของการเข้ารหัส 8 บิต และ "Extensed ASCII" ถูกเรียกว่า ASCII โดยเกี่ยวข้องกับบิตที่ 8 (เช่น KOI-8)
การซ้อนทับอักขระ
อักขระ Backspace (BS) ช่วยให้เครื่องพิมพ์ของคุณสามารถพิมพ์อักขระหนึ่งตัวทับอักขระอื่นได้ ใน ASCII คุณสามารถเพิ่มตัวกำกับเสียงให้กับตัวอักษรได้ในลักษณะเดียวกัน ตัวอย่างเช่น
- BS ‘ → á
- BS ` → à
- บี ^ → â
- o บี / → ø
- ค BS , → ç
- n BS ~ → с
บันทึก: ในแบบอักษรรุ่นเก่า เครื่องหมายอะพอสทรอฟี "'" ถูกลากไปทางซ้าย (เปรียบเทียบ "`" และ "´") และเครื่องหมายตัวหนอน "~" เอียงขึ้นด้านบน (เปรียบเทียบ "~" และ "~") เพื่อให้พอดี อักขระที่ถูกต้องคือ "´" แบบเฉียบพลันและ "ตัวหนอนอยู่ด้านบน"
หากคุณพิมพ์อักขระตัวเดียวกันสองครั้งในตำแหน่งเดียวกัน คุณจะได้อักขระตัวหนา หากคุณพิมพ์อักขระในตำแหน่งเดียวแล้วขีดล่าง “_” คุณจะได้รับอักขระขีดล่าง
- วิทยาศาสตรบัณฑิต → ก
- เอบีเอส_→ก
เทคนิคนี้ยังคงใช้อยู่ในปัจจุบัน เช่น ในระบบช่วยคน
ตัวแปร ASCII แห่งชาติ
มาตรฐาน ISO 646 (ECMA-6) กำหนดให้มีความเป็นไปได้ในการวางอักขระประจำชาติในรูปแบบ ASCII ในการดำเนินการนี้ ขอเสนอให้แทนที่สัญลักษณ์ “@”, "[”, “\”, “]”, “^”, “`”, “(”, “แถบแนวตั้ง”, “)”, “~ ". นอกจากนี้ แทนที่เครื่องหมายแฮช “#” อาจมีสัญลักษณ์ปอนด์ “£” และแทนที่สัญลักษณ์ดอลลาร์ “$” อาจมีสัญลักษณ์สกุลเงิน “¤” ระบบนี้เหมาะสมอย่างยิ่งกับภาษายุโรป เนื่องจากภาษาเหล่านี้ใช้อักขระละตินและอักขระเพิ่มเติมเพียงไม่กี่ตัว เวอร์ชัน ASCII ที่ไม่มีอักขระประจำชาติเรียกว่า "US-ASCII" หรือ "เวอร์ชันอ้างอิงสากล"
สำหรับบางภาษาที่มีสคริปต์ที่ไม่ใช่ละติน (รัสเซีย, กรีก, อารบิก, ฮีบรู) มีการปรับเปลี่ยน ASCII ที่รุนแรงมากขึ้น ในการปรับเปลี่ยนอย่างใดอย่างหนึ่งเหล่านี้ สัญลักษณ์ประจำชาติถูกวางแทนที่ตัวอักษรละตินตัวพิมพ์เล็ก (สำหรับรัสเซียและกรีก - ตัวพิมพ์ใหญ่) การปรับเปลี่ยนอื่นสำหรับการสลับระหว่าง US-ASCII และเวอร์ชันประจำชาติ การสลับดำเนินการ "ทันที" - โดยใช้สัญลักษณ์ SO (อังกฤษ สกะ โอ ut) และ SI (อังกฤษ สกะ ฉัน n); ในกรณีนี้ในเวอร์ชันระดับชาติสามารถแทนที่ตัวอักษรละตินด้วยสัญลักษณ์ประจำชาติได้อย่างสมบูรณ์ ดูเพิ่มเติมที่: KOI-7
ต่อจากนั้นการใช้การเข้ารหัส 8 บิตจะสะดวกกว่า ( หน้ารหัส) ซึ่งครึ่งล่างของตารางโค้ด (0-127) ถูกครอบครองโดยอักขระ US-ASCII และครึ่งบน (128-255) ถูกครอบครองโดยอักขระเพิ่มเติม รวมถึงชุดอักขระประจำชาติด้วย
ดังนั้นครึ่งบนของตาราง ASCII ก่อนที่จะมีการนำ Unicode มาใช้อย่างแพร่หลายจึงถูกนำมาใช้เพื่อแสดงอักขระที่แปลเป็นภาษาท้องถิ่นและตัวอักษรของภาษาท้องถิ่น
การขาดมาตรฐานแบบรวมสำหรับการวางอักขระซีริลลิกในตาราง ASCII ทำให้เกิดปัญหามากมายกับการเข้ารหัส (KOI-8, Windows-1251 ฯลฯ ) ภาษาอื่น ๆ ที่ไม่มีสคริปต์ที่ไม่ใช่ภาษาละตินก็ประสบปัญหาจากการเข้ารหัสที่แตกต่างกันหลายอย่าง
อักขระ 128 ตัวแรกของมาตรฐาน Unicode จะเหมือนกับอักขระ US-ASCII ที่สอดคล้องกัน
ตาราง ASCII
.0 .1 .2 .3 .4 .5 .6 .7 .8 .9 .ก .บี .ค .ดี .จ .ฟ 0. น.ล สโอ เอสทีเอ็กซ์ อีทีเอ็กซ์ อีโอที ENQ อ๊ากก เบล บี.เอส. HT แอลเอฟ เวอร์มอนต์ เอฟเอฟ CR ดังนั้น เอสไอ 1. เดล ดีซี1 ดีซี2 ดีซี3 ดีซี4 นาเค ซิน อีทีบี สามารถ อี.เอ็ม. ย่อย เอสซี เอฟเอส จี.เอส. อาร์.เอส. เรา 2. ! « # $ % & ‘ ( ) * + , - . / 3. 0 1 2 3 4 5 6 7 8 9 : ; < = > ? 4. @ ก บี ค ดี อี เอฟ ช ชม ฉัน เจ เค ล ม เอ็น โอ 5. ป ถาม ร ส ต ยู วี ว เอ็กซ์ ย ซี [ \ ] ^ _ 6. ` ก ข ค ง จ ฉ ก ชม. ฉัน เจ เค ล ม n โอ 7. พี ถาม ร ส ที ยู โวลต์ ว x ย z { | } ~ เดล ในเวอร์ชันแรกของมาตรฐาน ASCII (1963) ตำแหน่ง 0x5e (94) และ 0x5f (95) มีสัญลักษณ์ลูกศรขึ้นและลูกศรซ้ายตามลำดับ มาตรฐาน ECMA-6 (1965) แทนที่ด้วยอักขระคาเร็ต (ซึ่งใช้เป็นอักขระหมวก "^") และอักขระขีดล่าง "_" ตามลำดับ
อักขระควบคุม
ตาราง ASCII ถูกสร้างขึ้นเพื่อการแลกเปลี่ยนข้อมูลผ่านทางโทรพิมพ์ ชุดนี้รวมอักขระที่ไม่พิมพ์ซึ่งใช้เป็นคำสั่งในการควบคุมอุปกรณ์โทรพิมพ์ คำสั่งที่คล้ายกันนี้ถูกนำมาใช้ในวิธีการส่งข้อความก่อนคอมพิวเตอร์อื่นๆ (รหัสมอร์ส รหัสเซมาฟอร์) โดยคำนึงถึงลักษณะเฉพาะของอุปกรณ์
- น.ล, 00 - ว่าง, ว่างเปล่า อักขระ null จะถูกละเว้นเสมอ บนเทปกระดาษที่เจาะ ตัวเลข "1" จะถูกระบุด้วยรู และหมายเลข "0" จะถูกระบุโดยไม่มีรู ส่วนของเทปเจาะที่ไม่มีการบันทึกข้อมูลไม่มีรูนั่นคือมีอักขระว่าง ส่วนดังกล่าวอยู่ที่จุดเริ่มต้นและจุดสิ้นสุดของเทป อักขระ null ยังคงใช้ในภาษาการเขียนโปรแกรมหลายภาษาในปัจจุบันเป็นตัวยุติบรรทัดและแสดงด้วย "\0" (คำว่า "สตริง" หมายถึงลำดับของอักขระ) ในระบบปฏิบัติการบางระบบ ค่า null คืออักขระตัวสุดท้ายของไฟล์ข้อความ
ข้อความที่ส่งผ่านช่องทางการสื่อสารแบ่งออกเป็นสองส่วน:
- "ชื่อ";
- "ข้อความ".
“ส่วนหัว” ประกอบด้วยที่อยู่ผู้ส่งและผู้รับ ผลรวมตรวจสอบ ฯลฯ และอาจวางไว้ก่อนหรือหลัง “ข้อความ” คำว่า "ข้อความ" เป็นส่วนหนึ่งของข้อความที่มีไว้สำหรับการพิมพ์
- สโอ, 01 - สทาร์ต โอฉ ชม. eding จุดเริ่มต้นของ "หัวเรื่อง"
- เอสทีเอ็กซ์, 02 - สทาร์ตของ ทีจ x t จุดเริ่มต้นของ "ข้อความ" สัญลักษณ์นี้ถูกใช้เป็นคำสั่งในการเปิดอุปกรณ์การพิมพ์แบบโทรพิมพ์ ข้อความที่พิมพ์อยู่ระหว่างสัญลักษณ์ STX และ ETX
- อีทีเอ็กซ์, 03 - จอันดับของ ทีจ x t จุดสิ้นสุดของ "ข้อความ" สัญลักษณ์นี้ใช้เพื่อปิดอุปกรณ์การพิมพ์แบบโทรพิมพ์ ปัจจุบันนี้ รหัส 03 ใช้เพื่อส่งสัญญาณ SIGINT ไปยังกระบวนการ ซิกจริง ภายในผิดพลาด) และสามารถส่งได้โดยการกดคีย์ผสม Ctrl + C เมื่อได้รับสัญญาณดังกล่าวแล้ว กระบวนการจะต้องยุติลง
- อีโอที, 04 - จ nd โอฉ ที ransmission สิ้นสุดการส่งสัญญาณ สัญลักษณ์นี้ถูกใช้โดยโปรแกรมจำลองเทอร์มินัลเพื่อหมายถึง "จุดสิ้นสุดของไฟล์" (EOF) จ nd โอฉ ฉ ile) และสามารถส่งได้โดยการกดคีย์ผสม Ctrl + D . เมื่อได้รับอักขระดังกล่าว เทอร์มินัลอีมูเลเตอร์จะกำหนดกระบวนการที่ทำงานกับเทอร์มินัลในปัจจุบัน และตั้งค่าแฟล็ก end-of-file (EOF) ให้เป็นสตรีมอินพุตมาตรฐาน (stdin) เซนต์อันดาร์ ง ในใส่กระแส) ของกระบวนการนี้ เป็นผลให้กระบวนการหยุดอ่าน stdin และเริ่มประมวลผลข้อมูลที่อ่าน
- ENQ, 05 - Enq uire. "กรุณายืนยัน."
- อ๊ากก, 06 - อ๊ากความมุ่งมั่น. "ผมยืนยัน." สัญลักษณ์ NAK มีความหมายตรงกันข้าม - “ฉันไม่ยืนยัน”
- เบล, 07 - เบลล, เบลล์, บี๊บ สัญลักษณ์นี้มักแสดงเป็น "\a" และใช้เพื่อสร้างเสียงบี๊บ ในพีซียุคใหม่ เสียงจะถูกสร้างขึ้นจากลำโพงในตัว ตัวอย่างเช่น คำสั่งต่อไปนี้สามารถเล่นเสียงได้: echo -e “\a” หรือ echo -e “\007″ (bash); echo ^G (cmd.exe; เพื่อเข้าสู่ ^G กด Ctrl + G), printf("\a"); (รหัสในภาษาการเขียนโปรแกรม C)
- บี.เอส., 08 - ขอ๊าก สก้าว ส่งคืนอักขระหนึ่งตัว ปุ่ม ← Backspace ใช้เพื่อลบอักขระก่อนหน้า
- แท็บ, 09 - ที ab แท็บแนวนอน แสดงเป็น "\t" บางครั้งเรียกว่า HT จากภาษาอังกฤษ ชม.แนวนอน ทีการระเหย.
- แอลเอฟ, 0เอ - ลฉัน ฉ eed, ฟีดบรรทัด คำสั่งให้ลดแคร่อุปกรณ์การพิมพ์ลงหนึ่งบรรทัด สัญลักษณ์นี้ใช้เพื่อระบุจุดสิ้นสุดของบรรทัดในไฟล์ข้อความใน OSUNIX ลำดับอักขระ CR LF หมายถึงจุดสิ้นสุดของบรรทัดในไฟล์ข้อความใน Windows สัญลักษณ์ในภาษาโปรแกรมหลายภาษาจะแสดงเป็น "\n" การกดปุ่ม ↵ Enter เมื่อพิมพ์ข้อความจะส่งผลให้มีการป้อนบรรทัด
- เวอร์มอนต์, 0B - โวลต์แนวตั้ง ที ab แท็บแนวตั้ง
- เอฟเอฟ, 0ซี - ฉออม ฉ eed, การรันเพจ, เพจใหม่ คำสั่งเครื่องพิมพ์: พิมพ์ต่อจากจุดเริ่มต้นของแผ่นงานถัดไป
- CR, 0D - คการมาถึง รขากลับ, การกลับรถ. คำสั่งเครื่องพิมพ์: พิมพ์ต่อจากจุดเริ่มต้นของบรรทัดปัจจุบัน (ไม่ใช่จากบรรทัดใหม่) ในภาษาการเขียนโปรแกรมหลายภาษา อักขระ CR จะแสดงเป็น "\r" ใน Mac OS อักขระ CR จะทำเครื่องหมายที่จุดสิ้นสุดของบรรทัดในไฟล์ข้อความ จากแป้นพิมพ์สามารถป้อนสัญลักษณ์ CR ได้โดยกดคีย์ผสม Ctrl + M
- ดังนั้น, 0อี - สกะ โอให้เปลี่ยนไปใช้ฟีดอื่น ริบบิ้นอีกอันมักเป็นสีแดง ต่อจากนั้นจึงใช้สัญลักษณ์นี้เพื่อสลับไปใช้การเข้ารหัสระดับประเทศ
- เอสไอ, 0F - สกะ ฉัน n. คำสั่งให้ทำสิ่งที่ตรงกันข้ามกับ SO: สลับไปที่เทปต้นทางหรือสลับเป็นการเข้ารหัสต้นทาง
- เดล, 10 - งอาต ลหมึก จ scape การปล่อยช่องข้อมูล อักขระใดๆ ที่ตามหลัง DLE จะต้องถือเป็นข้อมูล ไม่ใช่อักขระควบคุม
- ดีซี1, 11 - งอุปกรณ์ คควบคุม 1 , อักขระควบคุมอุปกรณ์ที่ 1 คำสั่ง: เปิดเครื่องอ่านเทปแบบเจาะ
- ดีซี2, 12 - งอุปกรณ์ คควบคุม 2 , อักขระควบคุมอุปกรณ์ตัวที่ 2 คำสั่ง: เปิดสว่านกระแทก
- ดีซี3, 13 - งอุปกรณ์ คควบคุม 3 , อักขระควบคุมอุปกรณ์ตัวที่ 3 คำสั่ง: ปิดเครื่องอ่านเทปแบบเจาะ
- ดีซี4, 14 - งอุปกรณ์ คควบคุม 4 , อักขระควบคุมอุปกรณ์ที่ 4 คำสั่ง: ปิดสว่านกระแทก
- นาเค, 15 - nเชิงลบ กค เคตอนนี้ฉันไม่ยืนยัน การย้อนกลับของอักขระ ACK
- ซิน, 16 - ซินโครไนซ์ อักขระนี้ถูกส่งเมื่อมีบางสิ่งจำเป็นต้องส่งเพื่อการซิงโครไนซ์
- อีทีบี, 17 - จอันดับของ ทีต่อ ขล็อค จุดสิ้นสุดของบล็อกข้อความ บางครั้งข้อความก็ถูกแบ่งออกเป็นบล็อกด้วยเหตุผลทางเทคนิค
- สามารถ, 18 - สามารถ cel, ยกเลิก (สิ่งที่ถูกส่งไปก่อนหน้านี้)
- อี.เอ็ม., 19 - จอันดับของ ม edium, สิ้นสุดสื่อสิ่งพิมพ์ (เทปพันช์, กระดาษ ฯลฯ หมด)
- ย่อย, 1A - ย่อยสถาบัน, ทดแทน. สัญลักษณ์จะถูกวางไว้ในตำแหน่งของสัญลักษณ์ที่ความหมายสูญหายหรือเสียหายระหว่างการส่งสัญญาณ หรือสัญลักษณ์วางอยู่หน้าสัญลักษณ์ที่ต้องสลับไปใช้ชุดอักขระเพิ่มเติมเพื่อตีความ หรือสัญลักษณ์วางไว้หน้าสัญลักษณ์ที่ต้องพิมพ์เป็นสีอื่น ขณะนี้สัญลักษณ์ถูกแทรกโดยการกดปุ่ม Ctrl + Z และใช้เพื่อระบุจุดสิ้นสุดของไฟล์ใน DOS และ Windows
- เอสซี, 1B - เอสซีเอป อักขระที่ตามหลังอักขระ ESC มีความหมายอื่นนอกเหนือจากที่กำหนดไว้ใน ASCII โดยทั่วไปแล้วอักขระ ESC จะตามด้วยลำดับการหลีกเลี่ยง ใน DOS ไดรเวอร์ ANSI.SYS ถูกนำมาใช้
รองรับการแบ่งข้อมูลเป็น 4 ระดับ:
- ข้อความอาจประกอบด้วยไฟล์
- ไฟล์อาจประกอบด้วยกลุ่ม
- กลุ่มอาจประกอบด้วยบันทึก
- บันทึกอาจประกอบด้วยหน่วย
- เอฟเอส, 1C - ฉ ile สตัวแยก, ตัวแยกไฟล์
- จี.เอส., 1D - กกลุ่ม สตัวคั่น, ตัวคั่นกลุ่ม
- อาร์.เอส., 1E - รบันทึก สตัวคั่น, ตัวคั่นบันทึก
- เรา, ชั้น 1 - ยูจู้จี้จุกจิก สตัวคั่น, ตัวแยกหน่วย
- เดล, 7F - เดลเอต ลบอักขระตัวสุดท้าย สัญลักษณ์ DEL ซึ่งประกอบด้วยสัญลักษณ์ทั้งหมดในรหัสไบนารี่ สามารถใช้เพื่อ "ให้คะแนน" สัญลักษณ์ใดก็ได้ อุปกรณ์และโปรแกรมละเว้น DEL และ NUL รหัสสำหรับอักขระนี้มาจากโปรแกรมประมวลผลคำตัวแรกที่มีหน่วยความจำบนเทปเจาะ: ในนั้นการลบอักขระเกิดจากการ "อุดตัน" โค้ดที่มีรู (ระบุหน่วยลอจิคัล)
คุณสมบัติโครงสร้างของตาราง
- รหัสตัวอักษรตัวเลข "0" - "9" นิ้ว ระบบไบนารี่ตัวเลขเริ่มต้นด้วย 00112 และลงท้ายด้วยค่าเลขฐานสอง ตัวอย่างเช่น 01012 คือตัวเลข 5 และ 0011 01012 คือสัญลักษณ์ "5" เมื่อทราบสิ่งนี้แล้ว คุณสามารถแปลงเลขทศนิยมแบบไบนารี (BCD) ให้เป็นสตริง ASCII ได้โดยการเพิ่ม 00112 ทางด้านซ้ายของ BCD nibble แต่ละตัว
- ตัวอักษร "A" - "Z" ของตัวพิมพ์ใหญ่และตัวพิมพ์เล็กแตกต่างกันในการแสดงเพียงบิตเดียว ซึ่งช่วยลดความยุ่งยากในการแปลงตัวพิมพ์และตรวจสอบว่าโค้ดอยู่ในช่วงของค่าหรือไม่ ตัวอักษรจะแสดงด้วยเลขลำดับในตัวอักษร ซึ่งเขียนเป็นเลขฐานสองห้าหลัก นำหน้าด้วย 0102 (สำหรับตัวอักษรตัวพิมพ์ใหญ่) หรือ 0112 (สำหรับตัวอักษรตัวพิมพ์เล็ก)
การแสดง ASCII ในคอมพิวเตอร์
ในคอมพิวเตอร์สมัยใหม่ส่วนใหญ่ หน่วยหน่วยความจำขั้นต่ำที่สามารถระบุแอดเดรสได้คือไบต์ 8 บิต นั่นเป็นเหตุผลว่าทำไมจึงใช้อักขระ 8 บิตมากกว่า 7 บิต โดยทั่วไป อักขระ ASCII จะถูกขยายเป็น 8 บิตโดยการเพิ่มศูนย์บิตหนึ่งบิตเป็นบิตที่สำคัญที่สุด
รหัส ASCII ใช้ในการเขียนโปรแกรมเป็นรหัสข้ามแพลตฟอร์มระดับกลางของปุ่มที่กด (ตรงข้ามกับรหัสสแกน IBM PC และรหัสภายในอื่นๆ)
สำหรับรูปแบบแป้นพิมพ์ QWERTY ตารางโค้ดจะเป็นดังแสดงในตารางต่อไปนี้:
หนี F1 F2 F3 F4 F5 F6 F7 F8 F9 F10 F11 F12 บันทึกหน้าจอ, พิมพ์หน้าจอ เลื่อนล็อค หยุดชั่วคราว `อี 1 2 3 4 5 6 7 8 9 0 - =+ พื้นที่ด้านหลัง แทรก บ้าน เลื่อนหน้าขึ้น ล็อคหมายเลข / พิเศษ * เพิ่มเติม + พิเศษ แท็บ ถาม ว อี ร ต ย ยู ฉัน โอ ป [ ] ลบ จบ เลื่อนหน้าลง เพิ่มเติม 7 รายการ 8 พิเศษ 9 พิเศษ แคปล็อค ก ส ดี เอฟ ช ชม เจ เค ล ;และ 'เอ่อ เข้า เพิ่มอีก 4 อัน พิเศษ 5 รายการ พิเศษ 6 รายการ เข้ามาเพิ่มเติม กะ ซี เอ็กซ์ ค วี บี เอ็น ม ,< .> / กะ \| ขึ้น เพิ่มอีก 1 อัน เพิ่มเติม 2 รายการ เพิ่มเติม 3 รายการ Ctrl ชนะ Alt สเปซบาร์ Alt ชนะ รายการ Ctrl ซ้าย ลง ขวา อิน/0 เดล/. 46/110
ไม่มีตัวอักษรรัสเซียในรูปแบบแป้นพิมพ์นี้และยังมีความไม่ถูกต้องบางประการด้วย แต่คุณสมบัติหลักจะสะท้อนให้เห็น
ฉันขอเชิญทุกคนออกมาพูดออกมา
การเข้ารหัสข้อมูลข้อความ การเข้ารหัส ASCII รหัสซีริลลิกที่ใช้หลัก
ข้อความใดๆ คือลำดับอักขระจากตัวอักษรบางตัว หากอักขระแต่ละตัวของตัวอักษรที่ใช้ถูกเข้ารหัสด้วยตัวเลข ข้อความจะแสดงเป็นลำดับตัวเลข เมื่อประมวลผลข้อความ คอมพิวเตอร์จะใช้การแสดงตัวเลขแบบไบนารี
ในการตีความข้อความที่เข้ารหัสอย่างถูกต้อง คุณจำเป็นต้องทราบว่ารหัสไบนารี่ของอักขระตัวหนึ่งในตัวอักษรต้นฉบับสิ้นสุดที่ใด และรหัสไบนารี่ของอักขระตัวอื่นเริ่มต้นที่ใด คุณสามารถเข้ารหัสอักขระแต่ละตัวเป็นลำดับ 8 บิต - หนึ่งไบต์
ในแปดหลักคุณสามารถเขียน 28 = 256 จำนวนเต็มต่างกันได้ เลขฐานสอง- จาก 000000002 ถึง 111111112 ซึ่งเพียงพอที่จะกำหนดอักษรตัวพิมพ์ใหญ่และตัวพิมพ์เล็กแต่ละตัวของตัวอักษรภาษาอังกฤษและรัสเซีย เลขอารบิคทั้งหมด เครื่องหมายวรรคตอน สัญลักษณ์ที่จำเป็นอื่น ๆ รวมถึงรหัสบริการสำหรับการส่งข้อมูล การกำหนดแปดบิตที่ไม่ซ้ำกัน (ไม่ซ้ำกัน)
เพื่อความสะดวกในการเข้ารหัสแบบดิจิทัลและการถอดรหัสในภายหลัง ตารางโค้ดจะถูกคอมไพล์ คอมพิวเตอร์ประเภทต่างๆ ที่มีระบบปฏิบัติการต่างกันจะใช้ตารางรหัสที่แตกต่างกัน หนึ่งในมาตรฐานสำหรับการเข้ารหัสอักขระบนแป้นพิมพ์คอมพิวเตอร์ด้วยตัวเลข 8 บิตคือตารางรหัส ASCII (American Standard Code for Information Interchange) ครึ่งแรก (รหัส 0-127) ซึ่งมีเครื่องหมายวรรคตอน เลขอารบิค และสัญลักษณ์ของตัวอักษรภาษาอังกฤษ เป็นไปตามข้อตกลงที่ยอมรับกันทั่วโลก รหัส 128 - 255 ของตาราง ASCII (รหัส ASCII แบบขยาย) ใช้สำหรับตัวอักษรประจำชาติเป็นหลัก
คุณสามารถสร้างตารางรหัสใหม่ได้โดยพิมพ์หมายเลขที่ต้องการตั้งแต่ 0 ถึง 255 บนแป้นพิมพ์ตัวเลขขนาดเล็กขณะกดปุ่ม Alt ค้างไว้ รูปที่ 1 แสดงตารางรหัสที่ได้รับในลักษณะนี้
♫ ☼ ◄ ↕ | ||||||||||
← ∟ ↔ |
||||||||||
M N O P R S T U F | ||||||||||
Ts Ch Sh Sh Sh Shch y b E Yu Ya |
||||||||||
รูปที่ 1 – ตารางรหัส
รหัสนี้สร้างขึ้นจากหมายเลขแถวและหมายเลขคอลัมน์ ตัวอย่างเช่น รหัส 50 ตรงกับหมายเลข 2 รหัส 134 ถึงตัวอักษร Z รหัสตั้งแต่ 0 ถึง 32 คือรหัสบริการ
การมีตารางโค้ดหลายรูปแบบซึ่งเน้นไปที่การใช้ตัวอักษรในภาษาประจำชาติต่างๆ ถือเป็นความไม่สะดวกอย่างยิ่ง เพื่อจัดระเบียบตาราง พวกเขาเริ่มกำหนดชื่อและหมายเลขพิเศษ (เช่น
KOI-8) แต่สิ่งนี้ไม่ได้แก้ปัญหาในการสร้าง ระบบแบบครบวงจรรหัสที่รวมตัวอักษรประจำชาติต่างๆ
การกำจัดความไม่สะดวกและข้อจำกัดเหล่านี้เกิดขึ้นได้ด้วยมาตรฐานสากล Unicode ใหม่ ซึ่งสนับสนุนโดยเวอร์ชันล่าสุด ระบบปฏิบัติการไมโครซอฟต์ วินโดวส์. ปัจจุบัน มาตรฐานการเข้ารหัสอักขระนี้จัดสรรสองไบต์ต่ออักขระ การเข้ารหัสนี้อนุญาตให้แสดงอักขระที่แตกต่างกัน 216 = 65,536 ตัวในตัวอักษรไบนารี อักขระ 128 ตัวแรกมีรหัส ASCII เหมือนกัน
ปริมาณข้อมูลของข้อความ
ปัญหาเกี่ยวกับแนวทางแก้ไข
งาน. สมมติว่าอักขระแต่ละตัวถูกเข้ารหัส 1 ไบต์ (KOI-8) ประเมินปริมาณข้อมูลของข้อความ
ฉันรู้กฎสำหรับการบวกเลขฐานสอง
ข้อความประกอบด้วยอักขระ 39 ตัว ดังนั้น 1 ไบต์/อักขระจึงจำเป็นต้องเข้ารหัส *39 ตัวอักษร = 39 ไบต์
หรือ 8 บิต/ไบต์ * 39 ไบต์ = 312 บิต
1. ในข้อความตัวอย่างก่อนหน้านี้ คำว่า "binary" ถูกแทนที่ด้วยคำว่า "decimal" ปริมาณข้อมูลของข้อความเปลี่ยนแปลงไปเป็นบิตและไบต์อย่างไร
คำตอบ: ปริมาณข้อมูลของข้อความเพิ่มขึ้น 2 ไบต์ 16 บิต
2. สมมติว่าอักขระแต่ละตัวถูกเข้ารหัส 1 ไบต์ (KOI-8) ประเมินปริมาณข้อมูลของข้อความ
ฉันสามารถประเมินปริมาณข้อมูลได้
คำตอบ: ปริมาณข้อมูลของข้อความคือ 48 ไบต์
3. สมมติว่าอักขระแต่ละตัวถูกเข้ารหัสเป็น 2 ไบต์ (Unicode) ประเมินปริมาณข้อมูลของข้อความ
ฉันรู้ว่าการเข้ารหัสดังกล่าวคือ KOI - 8
คำตอบ: ปริมาณข้อมูลของข้อความคือ 68 ไบต์
4. สมมติว่าอักขระแต่ละตัวถูกเข้ารหัสเป็น 2 ไบต์ (Unicode) ประเมินปริมาณข้อมูลของข้อความ
อัลกอริทึมสามารถเขียนเป็นภาษาธรรมชาติได้
คำตอบ: ปริมาณข้อมูลของข้อความคือ 92 ไบต์
5. ข้อความข้อมูลเป็นภาษารัสเซีย ซึ่งเดิมเขียนด้วย Unicode 16 บิต ถูกแปลงใหม่เป็นการเข้ารหัส KOI-8 8 บิต ในเวลาเดียวกัน ข้อความข้อมูลก็ลดลง 480 บิต ข้อความมีความยาวกี่ตัวอักษร?
คำตอบ: ความยาวข้อความคือ 60 ตัวอักษร
6. ข้อความข้อมูลในภาษารัสเซีย ซึ่งเดิมบันทึกไว้ในโค้ด KOI-8 แบบ 8 บิต ได้รับการบันทึกใหม่เป็นการเข้ารหัส Unicode แบบ 16 บิต ในเวลาเดียวกัน ระดับเสียงของข้อความข้อมูลเพิ่มขึ้น 568 บิต ข้อความมีความยาวกี่ตัวอักษร?
คำตอบ: ความยาวข้อความคือ 71 ตัวอักษร
7. ข้อความข้อมูลในภาษารัสเซีย ซึ่งเดิมบันทึกไว้ในโค้ด KOI-8 แบบ 8 บิต ได้รับการบันทึกใหม่เป็นการเข้ารหัส Unicode แบบ 16 บิต ปริมาณข้อความข้อมูลมีการเปลี่ยนแปลงอย่างไร?
คำตอบ: ปริมาณข้อความข้อมูลเพิ่มขึ้นสองเท่า
8. ข้อความมีกี่อักขระ ปริมาณข้อมูลในการเข้ารหัส Unicode คือ 200 บิต
คำตอบ: ข้อความมีอักขระ 25 ตัว
9 . ข้อความมีกี่อักขระ ปริมาณข้อมูลในการเข้ารหัส KOI-8 คือ 240 บิต
คำตอบ: ข้อความมีอักขระ 30 ตัว
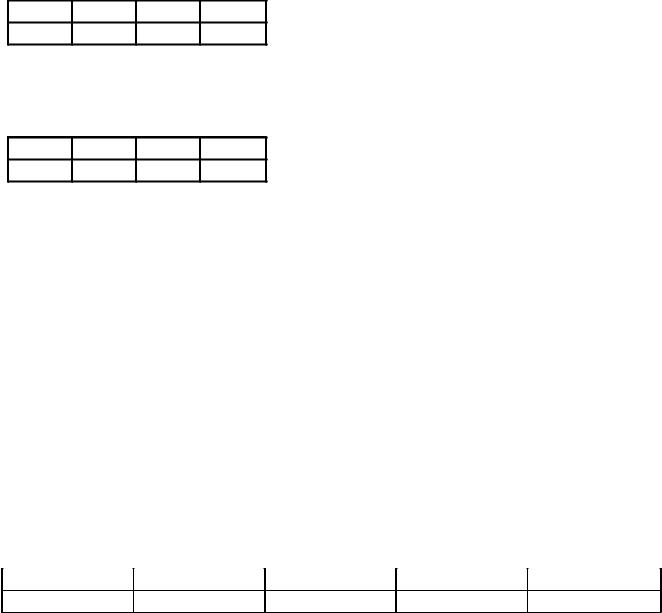
การเข้ารหัสและการถอดรหัสข้อมูล
ปัญหาเกี่ยวกับแนวทางแก้ไข
1. ในการเข้ารหัสตัวอักษร A, B, C, D ให้ใช้ตัวเลขสี่หลัก รหัสไบนารี่จาก 1,000 ถึง 1,011 ตามลำดับ สำหรับลำดับอักขระ B, D, C, A ให้จดรหัสไบนารี่และนำเสนอผลการเข้ารหัสเป็นรหัสฐานแปด
รหัสอักขระแสดงอยู่ในตารางที่ 1: ตารางที่ 1
รหัสไบนารี่ที่เกี่ยวข้องประกอบด้วย 16 บิต: 1001101110101000 จะสะดวกกว่าในการเขียนหมายเลขนี้สำหรับการแปลงเป็นรหัสฐานแปดซึ่งแบ่งออกเป็นสามกลุ่ม: 1 001 101 110 101 000 เป็นที่ชัดเจนว่าเลขฐานแปดที่เกี่ยวข้องมีรูปแบบดังต่อไปนี้: 115650
หากต้องการแปลงตัวเลขที่แสดงในรูปแบบไบนารี่เป็นเลขฐานสิบหก จะสะดวกในการแบ่งสัญกรณ์ไบนารี่ออกเป็นเตตราด (กลุ่ม 4 หลัก) โดยเริ่มจากด้านขวา
2. สำหรับตัวอักษรรัสเซีย 5 ตัวจะมีการระบุรหัสไบนารี่ซึ่งอาจมีตัวเลข 2 หรือ 3 หลัก รหัสจะถูกบันทึกไว้ในตารางที่ 3:
1) 110100000100110111
2) 101010000010010011
3) 110100001001100111
4) 110110000100110010.
เราจะถอดรหัสข้อความทั้งสี่ข้อความตามลำดับ โดยแบ่งออกเป็นกลุ่มบิตตามตารางที่ 3:
1) 11 01 000 001 001 10 111 กลุ่มตัวเลขสุดท้ายไม่สามารถเชื่อมโยงกับสัญลักษณ์ได้
ตามตารางที่ 3 ข้อความมีข้อผิดพลาด
2) 10 10 10 000 01 001 001 1 ข้อความมีข้อผิดพลาด
3) 11 01 000 01 001 10 01 11
สามารถถอดรหัสข้อความได้ 4) 11 01 10 000 10 01 10 010 ข้อความมีข้อผิดพลาด
คำตอบ: 3) 110100001001100111
ภารกิจสำหรับการแก้ปัญหาอย่างอิสระ
1. ในการเข้ารหัสตัวอักษร M, N, P, Q ให้ใช้รหัสไบนารี่สี่บิตตั้งแต่ 1000 ถึง 1011 ตามลำดับ สำหรับลำดับอักขระ N, Q, P, M ให้จดรหัสไบนารี่และนำเสนอผลการเข้ารหัสเป็นรหัสฐานแปด
คำตอบ: รหัสไบนารี 1 001 101 110 101 000 รหัสฐานแปด 115650
2. ในการเข้ารหัสตัวอักษร A, B, C, D จะใช้รหัสไบนารีสี่หลักตั้งแต่ 1,000 ถึง 1,011 ตามลำดับ สำหรับลำดับอักขระ B, D, C, A ให้จดรหัสไบนารี่และนำเสนอผลการเข้ารหัสเป็นรหัสฐานสิบหก
คำตอบ: รหัสไบนารี่ 1001 1011 1010 1,000 รหัสเลขฐานสิบหก 9BA9
3. ในการเข้ารหัสตัวอักษร M, N, O, P ใช้รหัสไบนารี่สามหลักตั้งแต่ 000 ถึง 111 ตามลำดับ สำหรับลำดับอักขระ O, N, M, P ให้จดรหัสไบนารี่และนำเสนอผลการเข้ารหัสเป็นรหัสฐานแปด
คำตอบ: รหัสไบนารี 110 101 100 111 รหัสฐานแปด 6547
4. ในการเข้ารหัสตัวอักษร M, N, O, P จะใช้รหัสไบนารี่สามหลักตั้งแต่ 100 ถึง 111 ตามลำดับ สำหรับลำดับอักขระ O, N, M, P ให้จดรหัสไบนารี่และนำเสนอผลการเข้ารหัสเป็นรหัสฐานสิบหก
คำตอบ: รหัสไบนารี 1101 0110 0111 รหัสฐานสิบหก B67
∙ หลักที่สองไม่สามารถเป็น 3 ได้
6. ในการเขียนตัวเลขสี่หลัก ให้ใช้ตัวเลข 1, 2, 3, 4, 5 และต้องปฏิบัติตามกฎต่อไปนี้:
∙ อันดับแรกอาจเป็นหมายเลข 1, 3, 4;
∙ ในการเขียนตัวเลข เลขคู่และเลขคี่สลับกัน
∙ หลักที่สามไม่สามารถเป็น 4 ได้
เขียนตัวเลขที่เป็นไปได้ทั้งหมดที่ประกอบขึ้นตามกฎเหล่านี้
7. ในการเขียนตัวเลขสี่หลัก ให้ใช้ตัวเลข 1, 2, 3, 4, 5 และต้องปฏิบัติตามกฎต่อไปนี้:
∙ อันดับแรกอาจเป็นหมายเลข 2, 4, 5;
∙ ในการเขียนตัวเลข เลขคู่และเลขคี่สลับกัน
∙ ตัวเลขตัวที่สองและตัวสุดท้ายต้องไม่เหมือนกัน เขียนตัวเลขที่เป็นไปได้ทั้งหมดที่ประกอบขึ้นตามกฎเหล่านี้
8. สำหรับตัวอักษรรัสเซีย 5 ตัวจะได้รับรหัสไบนารี่ซึ่งอาจมีตัวเลข 2 หรือ 3 หลัก รหัสเขียนอยู่ในตาราง:
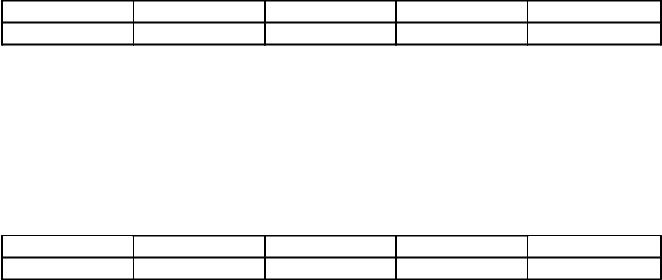
จากสี่ข้อความในการเข้ารหัสนี้ มีเพียงข้อความเดียวที่ส่งผ่านโดยไม่มีข้อผิดพลาด มีเพียงข้อความเท่านั้นที่สามารถถอดรหัสได้อย่างถูกต้อง ค้นหาข้อความนี้จากรายการ:
1) 110100000100110011
2) 111010000010010011
3) 110100001001100111
4) 110110000100110010 คำตอบ: 110100001001100111
9. สำหรับตัวอักษรรัสเซีย 5 ตัวจะได้รับรหัสไบนารี่ซึ่งอาจมีตัวเลข 2 หรือ 3 หลัก รหัสเขียนอยู่ในตาราง:
เข้ารหัสลำดับ FIGHT แนะนำข้อผิดพลาดในรหัสที่จะไม่อนุญาตให้ถอดรหัสข้อความอย่างถูกต้อง
แบบทดสอบการฝึกอบรม
2 สมมติว่าอักขระแต่ละตัวถูกเข้ารหัส 1 1) 384 บิตไบต์(ก้อย-8) ข้อมูลอัตรา 2) 192 บิต
ปริมาณคำ 24 ตัวอักษรในนี้ | ||||||
การเข้ารหัส | ||||||
3 ผลิตแล้ว | การเข้ารหัส | |||||
ข้อความข้อมูล | ||||||
ภาษาเดิมเขียนด้วย 8- | ||||||
รหัสบิต KOI-8 เป็นการเข้ารหัสแบบ 16 บิต | ||||||
ยูนิโค้ด ขณะเดียวกันก็มีปริมาณข้อมูล | ||||||
ข้อความเพิ่มขึ้น 336 บิต คืออะไร | ||||||
ความยาวข้อความเป็นตัวอักษร? | ||||||
4 มีตัวอักษรกี่ตัว? | ||||||
ข้อความ, | ข้อมูล | |||||
ซึ่งในการเข้ารหัส KOI-8 คือ 240 | ||||||
5 มีตัวอักษรกี่ตัว? | ||||||
ข้อความ, | ข้อมูล | |||||
ซึ่งใน Unicode คือ | ||||||
6 เข้ารหัสตัวอักษร A, B, C, D | ||||||
ใช้รหัสไบนารี่สามหลัก | ||||||
ถูกต้อง | ||||||

