24.07.2019
Codificação de informações de texto. Por que a codificação binária é universal? Métodos de programação
Vamos descobrir como traduzir textos em código digital? A propósito, em nosso site você pode converter qualquer texto em código decimal, hexadecimal ou binário usando a Calculadora de Código Online.
Codificação de texto.
De acordo com a teoria da computação, qualquer texto consiste em caracteres individuais. Esses caracteres incluem: letras, números, sinais de pontuação em minúsculas, caracteres especiais ("", №, (), etc.), eles também incluem espaços entre as palavras.
Base de conhecimento necessária. O conjunto de símbolos com os quais escrevo o texto chama-se ALFABETO.
O número de símbolos tomados no alfabeto representa seu poder.
A quantidade de informação pode ser determinada pela fórmula: N = 2b
- N - o mesmo poder (conjunto de caracteres),
- b - Bit (peso do símbolo tomado).
Um alfabeto em que haverá 256 pode acomodar quase todos os caracteres necessários. Esses alfabetos são chamados SUFICIENTES.
Se pegarmos um alfabeto com uma potência de 256 e lembrarmos que 256 \u003d 28
- 8 bits é sempre chamado de 1 byte:
- 1 byte = 8 bits.
Se traduzirmos cada caractere em um código binário, esse código de texto do computador terá 1 byte.
Como pode ser a informação textual na memória do computador?
Qualquer texto é digitado no teclado, nas teclas do teclado, vemos sinais familiares para nós (números, letras, etc.). Eles entram na RAM do computador apenas na forma de um código binário. O código binário de cada caractere se parece com um número de oito dígitos, como 00111111.
Como um byte é a menor unidade de memória endereçável e a memória é endereçada a cada caractere separadamente, a conveniência de tal codificação é óbvia. No entanto, 256 caracteres é uma quantidade muito conveniente para qualquer informação de caractere.
Naturalmente, surgiu a pergunta: Qual código de oito dígitos pertence a cada personagem? E como traduzir texto em código digital?
Este processo é condicional, e temos o direito de apresentar várias maneiras de codificar caracteres. Cada caractere do alfabeto tem seu próprio número de 0 a 255. E a cada número é atribuído um código de 00000000 a 11111111.
A tabela de codificação é uma "folha de dicas" na qual os caracteres do alfabeto são indicados de acordo com o número de série. Para diferentes tipos de computadores, diferentes tabelas são usadas para codificação.
ASCII (ou Asci) tornou-se o padrão internacional para computadores pessoais. A mesa tem duas partes.
A primeira metade é para uma tabela ASCII. (Foi a primeira metade que se tornou o padrão.)
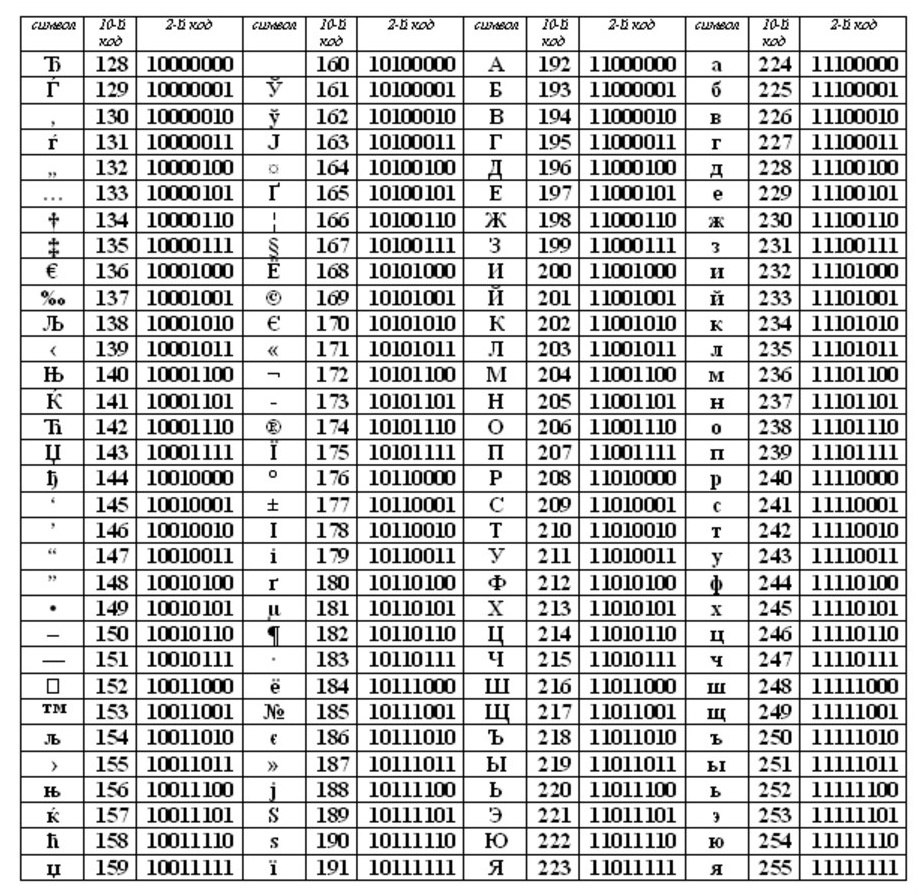
O cumprimento da ordem lexicográfica, ou seja, na tabela, as letras (minúsculas e maiúsculas) são indicadas em estrita ordem alfabética, e os números em ordem crescente, é chamado de princípio da codificação sequencial do alfabeto.
Para o alfabeto russo, eles também observam princípio de codificação sequencial.
Agora, em nosso tempo, todo cinco sistemas de codificação Alfabeto russo (KOI8-R, Windows. MS-DOS, Macintosh e ISO). Devido ao número de sistemas de codificação e à falta de um padrão, muitas vezes surgem mal-entendidos com a transferência de texto russo para seu formato de computador.
Um dos primeiros padrões para codificação do alfabeto russo e em computadores pessoais eles consideram KOI8 ("Código de troca de informações, 8 bits"). Essa codificação foi usada em meados dos anos setenta em uma série de computadores ES e, desde meados dos anos oitenta, tem sido usada nos primeiros sistemas operacionais UNIX traduzidos para o russo.
Desde o início dos anos noventa, a chamada época em que o sistema operacional MS DOS dominava, o sistema de codificação CP866 apareceu ("CP" significa "Code Page", "code page").
A gigante da computação APPLE, com seu sistema inovador sob o qual operam (Mac OS), está começando a usar seu próprio sistema para codificar o alfabeto MAC.
A International Standards Organization (ISO) nomeia outro padrão para o idioma russo sistema de codificação do alfabeto chamado ISO 8859-5.
E o sistema mais comum, hoje em dia, para codificar o alfabeto, inventado no Microsoft Windows, chama-se CP1251.
Desde a segunda metade dos anos noventa, o problema do padrão para traduzir texto em código digital para o idioma russo e não apenas foi resolvido com a introdução de um sistema chamado Unicode no padrão. Ele é representado por uma codificação de dezesseis bits, o que significa que exatamente dois bytes são alocados para cada caractere. memória de acesso aleatório. Obviamente, com essa codificação, os custos de memória são dobrados. No entanto, esse sistema de código permite converter até 65.536 caracteres em um código eletrônico.
A especificidade do sistema Unicode padrão é a inclusão de absolutamente qualquer alfabeto, seja ele existente, extinto, inventado. Em última análise, absolutamente qualquer alfabeto, além disso, o sistema Unicode, inclui muitos símbolos matemáticos, químicos, musicais e gerais.
Vamos usar uma tabela ASCII para ver como uma palavra pode ficar na memória do seu computador.
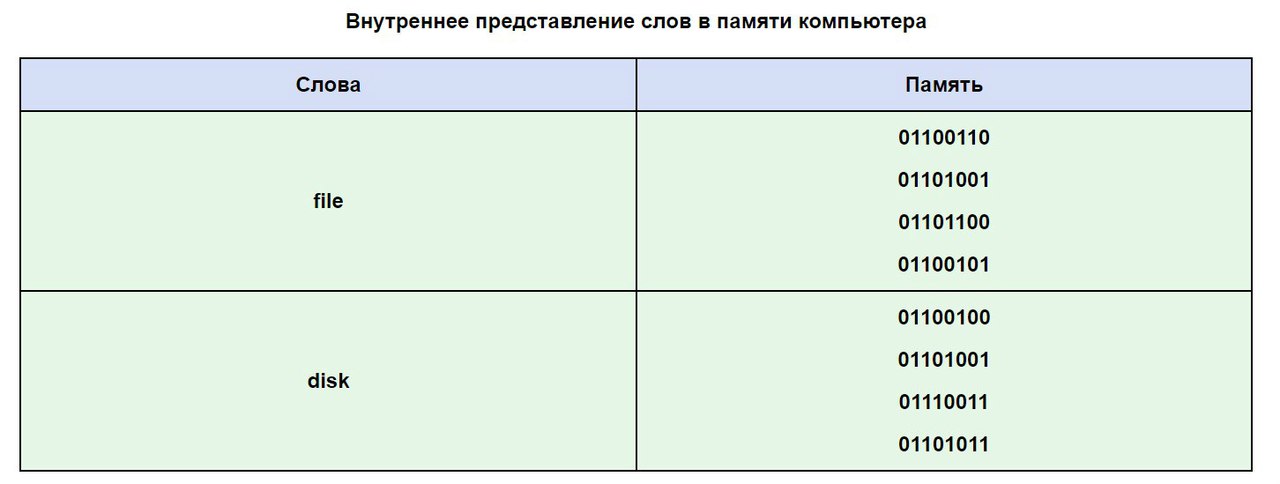
Muitas vezes acontece que seu texto, escrito em letras do alfabeto russo, não é legível, devido à diferença nos sistemas de codificação do alfabeto nos computadores. Este é um problema muito comum que é encontrado com bastante frequência.
As unidades mínimas de medida para informação são bits e bytes.
Um bit permite que você codifique 2 valores (0 ou 1).
Usando dois bit, pode ser codificado 4 valores: 00, 01, 10, 11.
Três bits codificados 8 valores diferentes: 000, 001, 010, 011, 100, 101, 110, 111.
Dos exemplos acima, pode-se ver que adicionar um bit dobra o número de valores que podem ser codificados:
1 bit codifica –> 2 valores diferentes (2 1 = 2),
2 bits codificam –> 4 valores diferentes (2 2 = 4),
3 bits codificam –> 8 valores diferentes (2 3 = 8),
4 bits de codificação –> 16 valores diferentes (2 4 = 16),
5 bits de codificação –> 32 valores diferentes (2 5 = 32),
6 bits de codificação –> 64 valores diferentes (2 6 = 64),
7 bits de codificação –> 128 valores diferentes (2 7 = 128),
8 bits de codificação –> 256 valores diferentes (2 8 = 256),
9 bits de codificação –> 512 valores diferentes (2 9 = 512),
10 bits codificam –> 1024 valores diferentes (2 10 = 1024).
Lembramos que em um byte não há 9 ou 10 bits, mas apenas 8. Portanto, usando um byte, podem ser codificados 256 caracteres diferentes. O que você acha, é muito ou pouco? Vejamos um exemplo de codificação informações de texto.
Existem 33 letras em russo, o que significa que são necessários 33 bytes para codificá-las. Um computador distingue entre letras grandes (maiúsculas) e letras pequenas (minúsculas) apenas se estiverem codificadas em códigos diferentes. Isso significa que para codificar letras grandes e pequenas do alfabeto russo, são necessários 66 bytes.
Para letras grandes e pequenas do alfabeto inglês, são necessários outros 52 bytes. O resultado é 66 + 52 = 118 bytes. Aqui você também precisa adicionar números (de 0 a 9), um caractere de espaço, todos os sinais de pontuação: ponto, vírgula, traço, exclamação e interrogação, colchetes: redondo, curvo e quadrado, além de sinais de operações matemáticas: + , -, =, / (isto é divisão), * (isto é multiplicação). Vamos também adicionar caracteres especiais: %, $, &, @, #, #, etc. Tudo isso somado forma cerca de 256 caracteres diferentes.
E então o assunto permaneceu pequeno. É necessário garantir que todas as pessoas na Terra concordem entre si sobre quais códigos (de 0 a 255, ou seja, 256 no total) atribuir aos símbolos. Suponha que todas as pessoas concordam que o código 33 significa um ponto de exclamação (!), e o código 63 significa um ponto de interrogação (?). E o mesmo vale para todos os símbolos usados. Isso significa que o texto digitado por uma pessoa em seu computador sempre poderá ser lido e impresso por outra pessoa em outro computador.
Tabela ASCII
Este acordo geral para usar algo da mesma maneira é chamado padrão. No nosso caso, o padrão deve ser uma tabela na qual é registrada a correspondência de códigos (de 0 a 255) e símbolos. Tal tabela é chamada tabela de codificação.
Mas nem tudo é tão simples. Afinal, símbolos que são bons, por exemplo, para a Grécia, não são adequados para a Turquia porque outras letras são usadas lá. Da mesma forma, o que é bom para os EUA não é bom para a Rússia, e o que é bom para a Rússia não é bom para a Alemanha.
Portanto, decidimos dividir a tabela de códigos ao meio.
Os primeiros 128 códigos (de 0 a 127) devem ser padrão e obrigatórios para todos os países e para todos os computadores, são internacional padrão.
E com a segunda metade da tabela de códigos (de 128 a 255), cada país pode fazer o que quiser e criar seu próprio padrão nesta metade - Nacional.
A primeira metade (internacional) da tabela de códigos é chamada tabelaASCII, que foi criado nos EUA e aceito em todo o mundo. O padrão ASCII não é responsável pela segunda metade da tabela de códigos. Diferentes países criam suas próprias tabelas de códigos nacionais aqui. Pode ser que dentro do mesmo país existam diferentes padrões projetados para diferentes sistemas de computador, mas apenas na segunda metade da tabela de códigos.
Códigos da tabela ASCII internacional
0-31 - caracteres especiais que não são impressos na tela ou na impressora, mas são usados para realizar ações especiais (por exemplo, para "retorno de carro" - mover o texto para uma nova linha, ou para "tabulação" - colocar o cursor em posições especiais em um texto de linha, etc.).
32 - espaço (o separador entre palavras também é um caractere a ser codificado, embora seja exibido como um "espaço vazio" entre palavras e caracteres),
33-47 - caracteres especiais (parênteses, etc.) e sinais de pontuação (ponto, vírgula, etc.),
48-57 - números de 0 a 9,
58-64 - símbolos matemáticos (mais (+), menos (-), multiplicar (*), dividir (/), etc.) e sinais de pontuação (dois pontos, ponto e vírgula, etc.),
65-90 - letras maiúsculas (maiúsculas) inglesas,
91-96 - caracteres especiais (colchetes, etc.),
97-122 - letras inglesas pequenas (minúsculas),
123-127 - caracteres especiais (colchetes, etc.).
Fora da tabela ASCII, a partir do número 128 a 159, há letras russas maiúsculas (maiúsculas) e de 160 a 170 e de 224 a 239, letras russas pequenas (minúsculas).
Codificação de palavras MUNDIAL
Usando a codificação mostrada, podemos imaginar como um computador codifica e depois reproduz, por exemplo, a palavra MUNDO (em maiúsculas). Esta palavra é representada por três códigos: a letra M corresponde ao código 140 (de acordo com o sistema nacional de codificação russo), I é o código 136 e R é 144.
Mas, como mencionado anteriormente, um computador percebe a informação apenas na forma binária, ou seja, como uma sequência de zeros e uns. Cada byte correspondente a cada letra da palavra MUNDO contém uma sequência de oito zeros e uns. Usando as regras para converter informações decimais em binárias, você pode substituir os valores decimais dos códigos de letras por suas contrapartes binárias.
O dígito decimal 140 corresponde ao número binário 10001100. Isso pode ser verificado fazendo os seguintes cálculos: 2 7 + 2 3 +2 2 = 140. A potência à qual cada “dois” é elevado é o número da posição do número binário 10001100, em que “1” representa. ”, e as posições são numeradas da direita para a esquerda, a partir do número da posição zero: 0, 1, 2, etc.
Você pode aprender mais sobre como converter números de um sistema numérico para outro, por exemplo, em livros didáticos de ciência da computação ou pela Internet.
Da mesma forma, você pode verificar se o número 136 corresponde ao número binário 10001000 (verifique: 2 7 + 2 3 = 136). E o número 144 corresponde ao número binário 10010000 (verifique: 2 7 + 2 4 = 144).
Assim, em um computador, a palavra MUNDO será armazenada na seguinte sequência de zeros e uns (bits): 10001100 10001000 10010000.
Obviamente, todas as transformações de dados mostradas acima são realizadas usando programas de computador e não são visíveis para os usuários. Eles apenas observam os resultados do trabalho desses programas, tanto ao inserir informações usando o teclado, quanto quando são exibidas na tela do monitor ou na impressora.
Deve-se notar que, ao nível do estudo da alfabetização em informática, os usuários de computador não precisam conhecer o sistema numérico binário. Basta ter uma ideia sobre os códigos de caracteres decimais. Apenas programadores de sistemas na prática usam sistemas numéricos binários, hexadecimais, octais e outros. Isso é especialmente importante para eles quando os computadores exibem mensagens de erro em softwares que indicam valores incorretos sem converter para um sistema decimal.
Exercícios de alfabetização em informática, permitindo que você veja e sinta independentemente os sistemas de codificação descritos, são fornecidos no artigo
P.S. O artigo acabou, mas você pode ler mais:
P.P.S. Para inscreva-se para receber novos artigos, que ainda não estão no blog:
1) Digite seu endereço de e-mail neste formulário.
Codificação binária de informações de texto
Desde o final dos anos 60, os computadores têm sido cada vez mais usados para processar informações textuais, e atualmente a maioria dos computadores pessoais do mundo (e na maioria das vezes) está ocupada com o processamento de informações textuais.
Tradicionalmente, para codificar um caractere, é usada a quantidade de informações igual a 1 byte, ou seja, I \u003d 1 byte \u003d 8 bits.
É preciso 1 byte de informação para codificar um caractere.
Se considerarmos os símbolos como eventos possíveis, usando a fórmula (2.1) podemos calcular quantos símbolos diferentes podem ser codificados:
N = 2 I = 2 8 = 256.
Esse número de caracteres é suficiente para representar informações textuais, incluindo letras maiúsculas e minúsculas dos alfabetos russo e latino, números, sinais, símbolos gráficos, etc.
A codificação consiste no fato de que a cada caractere é atribuído um código decimal único de 0 a 255 ou o código binário correspondente de 00000000 a 11111111. Assim, uma pessoa distingue os caracteres por seus estilos e um computador por seus códigos.
Quando as informações de texto são inseridas em um computador, elas são codificadas em binário, a imagem do símbolo é convertida em seu código binário. O usuário pressiona uma tecla com um símbolo no teclado, e uma certa sequência de oito impulsos elétricos (o código binário do símbolo) entra no computador. O código de caractere é armazenado na RAM do computador, onde ocupa um byte.
No processo de exibição de um caractere na tela do computador, é realizado o processo inverso - decodificação, ou seja, conversão do código do caractere em sua imagem.
É importante que a atribuição de um código específico a um símbolo seja uma questão de concordância, que é fixada na tabela de códigos. Os primeiros 33 códigos (de 0 a 32) não correspondem a caracteres, mas a operações (alimentação de linha, entrada de espaço etc.).
Os códigos 33 a 127 são internacionais e correspondem a caracteres latinos, números, aritmética e sinais de pontuação.
Os códigos de 128 a 255 são nacionais, ou seja, nas codificações nacionais, diferentes caracteres correspondem ao mesmo código. Infelizmente, atualmente existem cinco tabelas de códigos diferentes para letras russas (KOI8, СР1251, СР866, Mac, ISO - Tabela 1.3), portanto os textos criados em uma codificação não serão exibidos corretamente em outra.
Atualmente, o novo padrão internacional Unicode tornou-se difundido, que atribui não um byte, mas dois, a cada caractere, de modo que pode ser usado para codificar não 256 caracteres, mas N = 216 = 65536 caracteres diferentes. Esta codificação é suportada pelas versões mais recentes da plataforma Microsoft Windows&Office (desde 1997).
Cada codificação é especificada por sua própria tabela de códigos. Como pode ser visto na Tabela. 1.3, diferentes caracteres são atribuídos ao mesmo código binário em diferentes codificações.
Por exemplo, a sequência de códigos numéricos 221, 194, 204 na codificação CP1251 forma a palavra "computador", enquanto em outras codificações será um conjunto de caracteres sem sentido.
Felizmente, na maioria dos casos, o usuário não precisa se preocupar com a transcodificação de documentos de texto, pois isso é feito por programas conversores especiais integrados aos aplicativos.
Determinando o código de caractere numérico
1. Inicie o editor de texto do MS Word 2002. Digite o comando [Insert-Symbol...]. Uma caixa de diálogo aparecerá na tela. Símbolo. A parte central da caixa de diálogo é ocupada pela tabela de caracteres de uma fonte específica (por exemplo, Times New Roman).
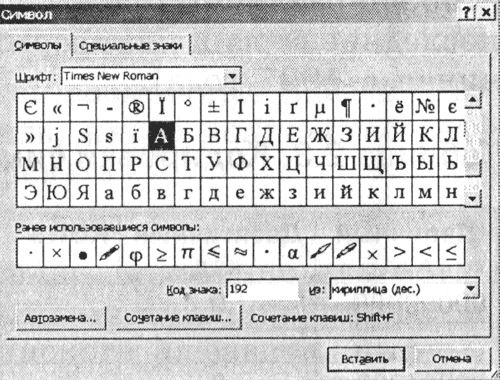 |
Os caracteres são organizados sequencialmente da esquerda para a direita e linha por linha, começando com o caractere Espaço no canto superior esquerdo e terminando com a letra "i" no canto inferior direito da tabela.
Selecione um símbolo e na lista suspensa a partir de: tipo de codificação. Em um campo de texto Código do sinal: seu código numérico aparecerá.
Inserindo caracteres por código numérico
1. Execute o programa padrão Caderno. Usando o teclado numérico adicional, enquanto mantém pressionada a tecla (Alt), digite o número 0224, solte a tecla (Alt). O símbolo "a" aparecerá no documento. Repita o procedimento para códigos numéricos de 0225 a 0233. Uma sequência de 12 caracteres "abcgdej" na codificação do Windows (CP1251) aparecerá no documento.
2. Usando o teclado numérico adicional, enquanto mantém pressionada a tecla (Alt), digite o número 224, o símbolo "p" aparecerá no documento. Repita o procedimento para códigos numéricos de 225 a 233, uma sequência de 12 caracteres "rstufhtschshsch" na codificação MS-DOS (CP866) aparecerá no documento.
 |
Tarefas práticas
1.29. Usando uma tabela de caracteres (MS Word), anote uma sequência de códigos numéricos decimais em codificação Windows (CP1251) para a palavra "computador".
1,30. Usando o Bloco de Notas, determine qual palavra na codificação do Windows (CP1251) é fornecida pela sequência de códigos numéricos: 225, 224, 233.242.
1.31. Que sequências de letras nos códigos KOI8 e ISO corresponderão à palavra "computador" escrita na codificação CP1251?
Processos de computador um grande número de em formação. Arquivos de áudio, fotos, textos - tudo isso precisa ser reproduzido ou exibido na tela. Por que a codificação binária é um método universal para programação de informações em qualquer equipamento técnico?
Como a criptografia é diferente da criptografia?
Muitas vezes as pessoas equacionam os conceitos de "codificação" e "criptografia", quando na verdade eles têm significados diferentes. Assim, a criptografia é o processo de conversão de informações para ocultá-las. A pessoa que alterou o texto, ou pessoas especialmente treinadas, muitas vezes podem decifrá-lo. A codificação é usada para processar informações e simplificar o trabalho com elas. Normalmente, é usada uma tabela de codificação comum, que é familiar a todos. Também está embutido no computador.
O princípio da codificação binária
Codificação binária baseia-se no uso de apenas dois caracteres - 0 e 1 - para processar informações usadas por vários dispositivos. Esses sinais eram chamados de dígitos binários, em inglês - dígito binário, ou bit. Cada caractere ocupa 1 bit da memória do computador. Por que a codificação binária é um método universal de processamento de informações? O ponto é que é mais fácil para um computador processar menos caracteres. A produtividade do PC depende diretamente disso: quanto menos tarefas funcionais um dispositivo precisar executar, maior será a velocidade e a qualidade do trabalho. 
O princípio da codificação binária não é encontrado apenas na programação. Com a ajuda de tambores surdos e sonoros alternados, os habitantes da Polinésia transmitiam informações uns aos outros. Um princípio semelhante se aplica quando sons longos e curtos são usados para transmitir uma mensagem. O "alfabeto telegráfico" ainda está em uso hoje.
Onde a codificação binária é usada?
O binário é onipresente em computadores. Cada arquivo, seja música ou texto, deve ser programado para que possa ser facilmente processado e lido posteriormente. O sistema de codificação binária é útil para trabalhar com símbolos e números, arquivos de áudio, gráficos.
Codificação binária de números
Agora, nos computadores, os números são apresentados em uma forma codificada que é incompreensível para uma pessoa comum. O uso de algarismos arábicos, como imaginamos, é irracional para a tecnologia. A razão para isso é a necessidade de atribuir um símbolo único a cada número, o que às vezes é impossível de fazer.

Existem dois sistemas numéricos: posicionais e não posicionais. O sistema não posicional é baseado no uso letras latinas e nos é familiar na forma Esta forma de gravação é bastante difícil de entender, por isso foi abandonada.
O sistema de numeração posicional ainda é usado hoje. Isso inclui codificação binária, decimal, octal e até hexadecimal de informações.
Usamos o sistema de codificação decimal na vida cotidiana. Estes são habituais para nós e são claros para todas as pessoas. A codificação binária de números difere no uso de apenas zero e um.
Os inteiros são convertidos para o sistema de codificação binário dividindo-os por 2. Os quocientes resultantes também são divididos por 2 em etapas até que o resultado seja 0 ou 1. Por exemplo, o número 123 10 em Sistema Binário pode ser representado como 1111011 2 . E o número 20 10 se parecerá com 10100 2 .
Os índices 10 e 2 são indicados, respectivamente, pelos sistemas de codificação de números decimal e binário. O caractere binário é usado para facilitar o trabalho com valores representados em diferentes sistemas de numeração.
Os métodos de programação decimal são baseados em "ponto flutuante". Para converter corretamente o valor do sistema de codificação decimal para binário, use a fórmula N = M x qp. M é a mantissa (uma expressão de um número sem qualquer ordem), p é a ordem do valor de N e q é a base do sistema de codificação (no nosso caso 2).
Nem todos os números são positivos. Para distinguir entre números positivos e negativos, o computador deixa espaço para 1 bit codificar o sinal. Aqui zero representa o sinal de mais e um representa o sinal de menos.
O uso de tal sistema numérico torna mais fácil para um computador trabalhar com números. É por isso que a codificação binária é universal nos processos de computação.

Codificação binária de informações de texto
Cada caractere do alfabeto é codificado por seu próprio conjunto de zeros e uns. O texto consiste em diferentes caracteres: letras (maiúsculas e minúsculas), sinais aritméticos e vários outros valores. A codificação de informações textuais requer o uso de 8 valores binários consecutivos de 00000000 a 11111111. Desta forma, 256 caracteres diferentes podem ser convertidos.
Para evitar confusão na codificação de texto, são usadas tabelas de valores especiais para cada caractere. Eles contêm o alfabeto latino, sinais aritméticos e sinais especiais (por exemplo, €, ¥ e outros). Os caracteres de intervalo 128-255 codificam o alfabeto nacional do país.
São necessários 8 bits de memória para codificar 1 caractere. Para simplificar os cálculos, 8 bits equivalem a 1 byte, portanto, o espaço total em disco para informações de texto é medido em bytes.

A maioria dos computadores pessoais está equipada com uma mesa padrão Codificações ASCII(Código Padrão Americano para Intercâmbio de Informações). Outras tabelas também são usadas, nas quais o sistema de codificação de informações de texto é diferente. Por exemplo, a primeira codificação de caracteres conhecida é chamada KOI-8 (código de troca de informações de 8 bits) e funciona em computadores que executam UNIX. Também amplamente encontrada é a tabela de códigos CP1251, que foi criada para sistema operacional Janelas.
Codificação binária de sons
Outra razão pela qual a codificação binária é um método tão versátil para programar informações é sua facilidade de uso ao trabalhar com arquivos de áudio. Qualquer música é ondas sonoras de diferentes amplitudes e frequências. O volume do som e seu tom dependem desses parâmetros.
Para programar uma onda sonora, o computador a divide condicionalmente em várias partes, ou "amostras". O número de tais amostras pode ser grande, então existem 65.536 combinações diferentes de zeros e uns. Assim, os computadores modernos são equipados com placas de som de 16 bits, o que significa usar 16 dígitos binários para codificar uma amostra de uma onda sonora.
Para reproduzir um arquivo de áudio, o computador processa as sequências programadas de código binário e as combina em uma onda contínua. 
Codificação de gráficos
As informações gráficas podem ser apresentadas na forma de desenhos, diagramas, imagens ou slides em PowerPoint. Qualquer imagem consiste em pequenos pontos - pixels, que podem ser pintados em cores diferentes. A cor de cada pixel é codificada e armazenada e, como resultado, obtemos uma imagem completa.
Se a imagem for preto e branco, o código de cada pixel pode ser um ou zero. Se forem usadas 4 cores, o código de cada uma delas consiste em dois dígitos: 00, 01, 10 ou 11. Por esse princípio, a qualidade do processamento de qualquer imagem é diferenciada. Aumentar ou diminuir o brilho também afeta o número de cores usadas. Na melhor das hipóteses, o computador distingue cerca de 16.777.216 tons.

Conclusão
Existem diferentes métodos de programação de informações, entre os quais a codificação binária é a mais eficaz. Com apenas dois caracteres - 1 e 0 - o computador pode ler facilmente a maioria dos arquivos. Ao mesmo tempo, a velocidade de processamento é muito maior do que, por exemplo, um sistema de programação decimal seria usado. A simplicidade deste método o torna indispensável para qualquer técnica. É por isso que a codificação binária é universal entre suas contrapartes.
Todo mundo sabe que os computadores podem realizar cálculos em grandes grupos de dados a uma velocidade tremenda. Mas nem todos sabem que essas ações dependem de apenas duas condições: se há ou não corrente e qual tensão.
Como um computador consegue processar informações tão diversas?
O segredo está no sistema binário. Todos os dados entram no computador, apresentados na forma de unidades e zeros, cada um dos quais corresponde a um estado do fio elétrico: unidades - alta tensão, zeros - baixa ou uns - a presença de tensão, zeros - sua ausência. A conversão de dados em zeros e uns é chamada de conversão binária, e sua designação final é chamada de código binário.
Na notação decimal, baseada no sistema decimal utilizado na vida cotidiana, um valor numérico é representado por dez dígitos de 0 a 9, e cada casa do número tem um valor dez vezes maior que a casa à sua direita. Para representar um número maior que nove no sistema decimal, um zero é colocado em seu lugar e uma unidade é colocada no próximo lugar mais valioso à esquerda. Da mesma forma, em binário, onde apenas dois dígitos, 0 e 1, são usados, cada lugar é duas vezes mais valioso que o lugar à sua direita. Assim, em código binário, apenas zero e um podem ser representados como números únicos, e qualquer número maior que um requer duas casas. Depois de zero e um, os próximos três números binários são 10 (leia um-zero) e 11 (leia um-um) e 100 (leia um-zero-zero). 100 binários equivalem a 4 casas decimais. A tabela superior à direita mostra outros equivalentes BCD.
Qualquer número pode ser expresso em binário, apenas ocupa mais espaço do que em notação decimal. No sistema binário, o alfabeto também pode ser escrito se um determinado número binário for atribuído a cada letra.
Dois dígitos para quatro lugares
16 combinações podem ser feitas usando bolas escuras e claras, combinando-as em conjuntos de quatro. Se as bolas escuras forem tomadas como zeros e as claras como uns, então 16 conjuntos serão um código binário de 16 unidades, o valor numérico dos quais é de zero a cinco (consulte a tabela superior na página 27). Mesmo com dois tipos de bolas em binário, você pode construir um número infinito de combinações simplesmente aumentando o número de bolas em cada grupo - ou o número de casas nos números.
Bits e bytes
A menor unidade em processamento de computador, um bit é uma unidade de dados que pode ter uma das duas condições possíveis. Por exemplo, cada um e zeros (à direita) significa 1 bit. Um bit pode ser representado de outras maneiras: a presença ou ausência de uma corrente elétrica, um buraco e sua ausência, a direção da magnetização para a direita ou para a esquerda. Oito bits formam um byte. Os 256 bytes possíveis podem representar 256 caracteres e símbolos. Muitos computadores processam bytes de dados ao mesmo tempo.
conversão binária. Um código binário de quatro dígitos pode representar números decimais de 0 a 15.
Tabelas de códigos
Quando um código binário é usado para denotar letras do alfabeto ou sinais de pontuação, são necessárias tabelas de códigos que indicam qual código corresponde a qual caractere. Vários desses códigos foram compilados. A maioria dos PCs é configurada com um código de sete dígitos chamado ASCII, ou American Standard Code for Information Interchange. A tabela à direita mostra Códigos ASCII para o alfabeto inglês. Outros códigos são para milhares de caracteres e alfabetos de outros idiomas do mundo.

Parte da tabela de códigos ASCII

