29.01.2019
बायनरी कोडमध्ये डेटा एन्कोड करणे. डेटा एन्कोडिंग
विविध प्रकारच्या डेटासह कार्य स्वयंचलित करण्यासाठी, त्यांचे सादरीकरण फॉर्म एकत्र करणे खूप महत्वाचे आहे - यासाठी, तंत्र सहसा वापरले जाते कोडिंग,म्हणजे, एका प्रकारचा डेटा दुसऱ्या प्रकारच्या डेटाच्या संदर्भात व्यक्त करणे. नैसर्गिक मानव भाषा -ते भाषणाद्वारे विचार व्यक्त करण्यासाठी संकल्पना कोडिंग प्रणालींपेक्षा अधिक काही नाहीत. जिभेच्या अगदी जवळ ABC च्या(ग्राफिक चिन्हे वापरून भाषा घटक कोडींग करण्यासाठी प्रणाली). "सार्वत्रिक" भाषा आणि अक्षरे तयार करण्याचा अयशस्वी प्रयत्न असूनही, इतिहास मनोरंजक आहे. वरवर पाहता, त्यांची अंमलबजावणी करण्याच्या प्रयत्नांचे अपयश हे या वस्तुस्थितीमुळे आहे की राष्ट्रीय आणि सामाजिक संस्थांना स्वाभाविकपणे हे समजले आहे की सार्वजनिक डेटा कोडिंग सिस्टममध्ये बदल केल्याने नक्कीच सामाजिक पद्धतींमध्ये (म्हणजे कायदेशीर आणि नैतिक नियम) बदल होईल आणि हे सामाजिक उलथापालथीशी संबंधित असू शकते.
युनिव्हर्सल कोडिंग टूलची हीच समस्या तंत्रज्ञान, विज्ञान आणि संस्कृतीच्या काही शाखांमध्ये यशस्वीरित्या अंमलात आणली जात आहे. उदाहरणांमध्ये गणितीय अभिव्यक्ती लिहिण्यासाठी एक प्रणाली, तार वर्णमाला, नौदल ध्वज वर्णमाला, अंधांसाठी ब्रेल प्रणाली आणि बरेच काही समाविष्ट आहे.
संगणक तंत्रज्ञानाची स्वतःची प्रणाली देखील आहे - त्याला म्हणतात बायनरी कोडिंगआणि केवळ दोन वर्णांचा क्रम म्हणून डेटाचे प्रतिनिधित्व करण्यावर आधारित आहे: 0 आणि 1. या वर्णांना म्हणतात बायनरी अंक,इंग्रजी मध्ये - बायनरी अंककिंवा थोडक्यात दाबा (थोडा).
एक बिट दोन संकल्पना व्यक्त करू शकतो: 0 किंवा 1 (होयकिंवा नाही, काळाकिंवा पांढरा, खरेकिंवा खोटे बोलणेवगैरे.) जर बिट्सची संख्या दोन पर्यंत वाढवली तर चार भिन्न संकल्पना व्यक्त केल्या जाऊ शकतात:
तीन बिट आठ भिन्न मूल्ये एन्कोड करू शकतात:
000 001 010 011 100 101 110 111
सिस्टीममधील अंकांची संख्या एकाने वाढवणे बायनरी कोडिंग, आम्ही दिलेल्या सिस्टीममध्ये व्यक्त केल्या जाऊ शकणाऱ्या मूल्यांची संख्या दुप्पट करतो, म्हणजे, सामान्य सूत्रफॉर्म आहे:
कुठे N-स्वतंत्र कोडेड मूल्यांची संख्या;
ट -या प्रणालीमध्ये स्वीकारलेल्या बायनरी कोडिंगची bit depth.
एन्कोडिंग पूर्णांक आणि वास्तविक संख्या
पूर्णांक संख्या बायनरीमध्ये अगदी सोप्या पद्धतीने एन्कोड केल्या जातात - फक्त एक पूर्णांक घ्या आणि जोपर्यंत भागफल एक होत नाही तोपर्यंत त्याला अर्ध्यामध्ये विभाजित करा. शेवटच्या भागासह उजवीकडून डावीकडे लिहिलेल्या प्रत्येक विभागातील उर्वरित भागांचा संच दशांश संख्येचा बायनरी ॲनालॉग बनवतो.
अशा प्रकारे, 19= 10011;.
0 ते 255 पर्यंत पूर्णांक एन्कोड करण्यासाठी, बायनरी कोडचे 8 बिट (8 बिट्स) असणे पुरेसे आहे. सोळा बिट्स तुम्हाला 0 ते 65,535 पर्यंत पूर्णांक एन्कोड करण्याची परवानगी देतात आणि 24 बिट्स तुम्हाला 16.5 दशलक्षाहून अधिक भिन्न मूल्ये एन्कोड करण्याची परवानगी देतात.
वास्तविक संख्या एन्कोड करण्यासाठी, 80-बिट एन्कोडिंग वापरले जाते. या प्रकरणात, संख्या प्रथम मध्ये रूपांतरित केली जाते सामान्यीकृत फॉर्म:
3,1415926 =0,31415926-10"
300 000 = 0,3 10 6
123 456 789 = 0,123456789 10 10
नंबरचा पहिला भाग म्हणतात मँटिसा,आणि दुसरा - वैशिष्ट्यपूर्णबहुतेक 80 बिट्स मॅन्टिसा (चिन्हासह) संग्रहित करण्यासाठी वाटप केले जातात आणि वैशिष्ट्यपूर्ण (साइन केलेले) संग्रहित करण्यासाठी ठराविक बिट्सचे वाटप केले जाते.
मजकूर डेटा एन्कोडिंग
जर वर्णमालेतील प्रत्येक वर्ण विशिष्ट पूर्णांकाशी संबंधित असेल (उदाहरणार्थ, अनुक्रमांक), तर बायनरी कोड वापरून मजकूर माहिती देखील एन्कोड केली जाऊ शकते. 256 भिन्न वर्ण एन्कोड करण्यासाठी आठ बायनरी अंक पुरेसे आहेत. इंग्रजी आणि रशियन भाषेतील सर्व वर्ण, लोअरकेस आणि अपरकेस, तसेच विरामचिन्हे, मूलभूत अंकगणित ऑपरेशन्सची चिन्हे आणि काही सामान्यतः स्वीकारले जाणारे विशेष वर्ण, उदाहरणार्थ “§” हे चिन्ह आठ बिट्सच्या विविध संयोजनांमध्ये व्यक्त करण्यासाठी हे पुरेसे आहे. "
तांत्रिकदृष्ट्या हे अगदी सोपे दिसते, परंतु नेहमीच लक्षणीय संस्थात्मक अडचणी आल्या आहेत. संगणक तंत्रज्ञानाच्या विकासाच्या सुरुवातीच्या वर्षांमध्ये, ते आवश्यक मानकांच्या कमतरतेशी संबंधित होते, परंतु आजकाल ते एकाच वेळी विद्यमान आणि विरोधाभासी मानकांच्या विपुलतेमुळे होते. संपूर्ण जगाला त्याच प्रकारे मजकूर डेटा एन्कोड करण्यासाठी, युनिफाइड एन्कोडिंग टेबल्सची आवश्यकता आहे आणि हे राष्ट्रीय अक्षरांच्या वर्णांमधील विरोधाभास, तसेच कॉर्पोरेट विरोधाभासांमुळे अद्याप शक्य नाही.
इंग्रजी भाषेसाठी, ज्याने वास्तविक दळणवळणाच्या आंतरराष्ट्रीय माध्यमाचे स्थान मिळवले आहे, विरोधाभास आधीच काढून टाकले गेले आहेत. यूएस मानक संस्था (ANSI - अमेरिकन नॅशनल स्टँडर्ड इन्स्टिट्यूट)एक कोडिंग प्रणाली सादर केली ASCII (अमेरिकन स्टँडर्ड कोड फॉर इन्फॉर्मेशन इंटरचेंज - यूएस स्टँडर्ड कोड फॉर इन्फॉर्मेशन एक्सचेंज).प्रणाली मध्ये ASCIIदोन कोडिंग टेबल्स निश्चित आहेत - मूलभूतआणि विस्तारितमूलभूत सारणी 0 ते 127 पर्यंत कोड मूल्ये निश्चित करते आणि विस्तारित सारणी 128 ते 255 पर्यंतच्या संख्येसह वर्णांचा संदर्भ देते.
बेस टेबलचे पहिले 32 कोड, शून्यापासून सुरू होणारे, हार्डवेअर उत्पादकांना (प्रामुख्याने संगणक आणि प्रिंटिंग डिव्हाइस उत्पादक) दिले जातात. या क्षेत्रामध्ये तथाकथित समाविष्ट आहे नियंत्रण कोड,जे कोणत्याही भाषेच्या चिन्हांशी सुसंगत नाहीत आणि त्यानुसार, हे कोड स्क्रीनवर किंवा प्रिंटिंग उपकरणांवर प्रदर्शित होत नाहीत, परंतु ते इतर डेटा कसा आउटपुट होतो हे नियंत्रित करू शकतात.
कोड 32 पासून कोड 127 पर्यंत, इंग्रजी वर्णमाला, विरामचिन्हे, संख्या, अंकगणित क्रिया आणि काही सहायक वर्णांसाठी कोड आहेत.
मजकूर डेटा एन्कोडिंगसाठी तत्सम प्रणाली इतर देशांमध्ये विकसित केली गेली आहे. उदाहरणार्थ, यूएसएसआरमध्ये, KOI-7 कोडिंग प्रणाली या भागात कार्यरत होती (माहिती विनिमय कोड, सात अंक).तथापि, हार्डवेअर आणि सॉफ्टवेअर उत्पादकांच्या समर्थनामुळे अमेरिकन कोड आला ASCIIआंतरराष्ट्रीय मानकाच्या पातळीपर्यंत, आणि राष्ट्रीय कोडींग प्रणालींना कोडींग प्रणालीच्या एका सेकंदाच्या विस्तारित भागाकडे “माघार” घ्यावी लागली, कोडचा अर्थ 128 ते 255 पर्यंत परिभाषित केला आहे. या क्षेत्रात एकसमान मानक नसल्यामुळे एकाचवेळी एन्कोडिंगची अनेकता. केवळ रशियामध्ये तीन वर्तमान एन्कोडिंग मानक आणि आणखी दोन जुने दर्शविणे शक्य आहे.
उदाहरणार्थ, रशियन भाषेतील वर्ण एन्कोडिंग, ज्याला एन्कोडिंग म्हणून ओळखले जाते Windows-1251,"बाहेरून" - मायक्रोसॉफ्टने सादर केले होते, परंतु रशियामधील ऑपरेटिंग सिस्टम आणि या कंपनीच्या इतर उत्पादनांचे व्यापक वितरण पाहता, ते खोलवर रुजले आणि मोठ्या प्रमाणावर वापरले गेले. हे एन्कोडिंग Windows प्लॅटफॉर्मवर चालणाऱ्या बहुतेक स्थानिक संगणकांवर वापरले जाते.
आणखी एक सामान्य एन्कोडिंग KOI-8 म्हणतात (माहिती विनिमय कोड, आठ अंक) -त्याचे मूळ पूर्व युरोपीय राज्यांच्या परस्पर आर्थिक सहाय्य परिषदेच्या काळापासून आहे. आज, KOI-8 एन्कोडिंग रशियामधील संगणक नेटवर्क आणि इंटरनेटच्या रशियन क्षेत्रात मोठ्या प्रमाणावर वापरले जाते.
आंतरराष्ट्रीय मानक, जे रशियन वर्णमालाच्या वर्णांचे एन्कोडिंग प्रदान करते, त्याला एन्कोडिंग म्हणतात ISO (इंटरनॅशनल स्टँडर्ड ऑर्गनायझेशन - इंटरनॅशनल इन्स्टिट्यूट फॉर स्टँडर्डायझेशन).सराव मध्ये, हे एन्कोडिंग क्वचितच वापरले जाते.
चालू असलेल्या संगणकांवर ऑपरेटिंग सिस्टम एमएस-डॉसआणखी दोन एन्कोडिंग प्रभावी असू शकतात (एनकोडिंग पाहुणेएन्कोडिंग GOST-पर्यायी).वैयक्तिक संगणनाच्या सुरुवातीच्या काळातही त्यापैकी पहिला अप्रचलित मानला जात होता, परंतु दुसरा आजही वापरला जातो.
रशियामध्ये कार्यरत असलेल्या मजकूर डेटा एन्कोडिंग सिस्टमच्या विपुलतेमुळे, इंटरसिस्टम डेटा रूपांतरणाची समस्या उद्भवते - ही संगणक विज्ञानातील सामान्य समस्यांपैकी एक आहे.
युनिव्हर्सल टेक्स्ट डेटा एन्कोडिंग सिस्टम
आम्ही तयार करण्याशी संबंधित संस्थात्मक अडचणींचे विश्लेषण केल्यास युनिफाइड सिस्टममजकूर डेटा एन्कोडिंग, आम्ही असा निष्कर्ष काढू शकतो की ते कोडच्या मर्यादित संचामुळे झाले आहेत (256). त्याच वेळी, हे स्पष्ट आहे की जर, उदाहरणार्थ, तुम्ही आठ-बिट नसलेल्या वर्णांमध्ये एन्कोड करा. बायनरी संख्या, आणि मोठ्या संख्येने अंकांसह संख्या, नंतर संभाव्य कोड मूल्यांची श्रेणी खूप मोठी होईल. ही प्रणाली, 16-बिट वर्ण एन्कोडिंगवर आधारित, म्हणतात सार्वत्रिक - युनिकोड.सोळा अंकांमुळे 65,536 भिन्न वर्णांसाठी अद्वितीय कोड प्रदान करणे शक्य होते - हे फील्ड ग्रहातील बहुतेक भाषा वर्णांच्या सारणीमध्ये सामावून घेण्यासाठी पुरेसे आहे.
या दृष्टिकोनाची क्षुल्लक स्पष्टता असूनही, या प्रणालीमध्ये एक साधे यांत्रिक संक्रमण बर्याच काळासाठीअपर्याप्त संगणक संसाधनांमुळे (कोडिंग सिस्टममध्ये) मागे ठेवण्यात आले युनिकोडसर्व मजकूर दस्तऐवज आपोआप दुप्पट लांब होतात). 90 च्या दशकाच्या उत्तरार्धात, तांत्रिक माध्यमांनी संसाधनांच्या तरतुदीची आवश्यक पातळी गाठली आणि आज आपण सार्वत्रिक कोडिंग सिस्टममध्ये कागदपत्रे आणि सॉफ्टवेअरचे हळूहळू हस्तांतरण पाहत आहोत. वैयक्तिक वापरकर्त्यांसाठी, याने सॉफ्टवेअरसह वेगवेगळ्या कोडींग सिस्टीममध्ये बनवलेल्या दस्तऐवजांच्या समन्वयाबाबत आणखी चिंतेची भर पडली, परंतु हे संक्रमण काळातील अडचणी समजले पाहिजे.
ग्राफिक्स डेटा एन्कोडिंग
जर तुम्ही वर्तमानपत्रात किंवा पुस्तकात भिंगाने छापलेली काळी आणि पांढरी ग्राफिक प्रतिमा पाहिली तर तुम्ही पाहू शकता की त्यात लहान ठिपके असतात ज्याला एक वैशिष्ट्यपूर्ण नमुना म्हणतात. रास्टर(आकृती क्रं 1).
तांदूळ. 1. रास्टर ही ग्राफिक माहिती एन्कोड करण्याची एक पद्धत आहे जी प्रिंटिंगमध्ये बर्याच काळापासून स्वीकारली गेली आहे
रेखीय निर्देशांक आणि प्रत्येक बिंदूचे वैयक्तिक गुणधर्म (ब्राइटनेस) पूर्णांक वापरून व्यक्त केले जाऊ शकतात, आम्ही असे म्हणू शकतो की रास्टर कोडिंग ग्राफिक डेटाचे प्रतिनिधित्व करण्यासाठी बायनरी कोड वापरण्याची परवानगी देते. 256 ग्रेडेशनसह ठिपक्यांचे संयोजन म्हणून काळ्या आणि पांढर्या चित्रांचे प्रतिनिधित्व करणे आज सामान्यतः स्वीकारले जाते राखाडी, आणि अशा प्रकारे आठ-बिट बायनरी संख्या सहसा कोणत्याही बिंदूची चमक एन्कोड करण्यासाठी पुरेशी असते.
रंग ग्राफिक्स एन्कोडिंगसाठी वापरले जाते विघटन तत्त्वमुख्य घटकांसाठी यादृच्छिक रंग. असे घटक म्हणून तीन प्राथमिक रंग वापरले जातात: लाल (लाल, आर),हिरवा (हिरवा, जी)आणि निळा (निळा, ब).व्यवहारात असे मानले जाते (जरी सैद्धांतिकदृष्ट्या हे पूर्णपणे सत्य नाही) की मानवी डोळ्यांना दिसणारा कोणताही रंग यांत्रिकरित्या या तीन प्राथमिक रंगांचे मिश्रण करून मिळू शकतो. या कोडिंग प्रणालीला प्रणाली म्हणतात RGBप्राथमिक रंगांच्या नावांच्या पहिल्या अक्षरांद्वारे.
जर 256 मूल्ये (आठ बायनरी बिट्स) प्रत्येक मुख्य घटकाची चमक एन्कोड करण्यासाठी वापरली जातात, जसे की हाफटोन ब्लॅक-व्हाइट इमेजसाठी प्रथा आहे, तर एका बिंदूचा रंग एन्कोड करण्यासाठी 24 बिट्स खर्च करणे आवश्यक आहे. त्याच वेळी, कोडिंग सिस्टम 16.5 दशलक्ष भिन्न रंगांची अस्पष्ट ओळख प्रदान करते, जी प्रत्यक्षात संवेदनशीलतेच्या जवळ आहे. मानवी डोळा. 24 बायनरी बिट्स वापरून कलर ग्राफिक्सचे प्रतिनिधित्व करण्याच्या मोडला म्हणतात पूर्ण रंग (खरा रंग).
प्रत्येक प्राथमिक रंग अतिरिक्त रंगाशी संबंधित असू शकतो, म्हणजे, प्राथमिक रंग पांढऱ्याला पूरक करणारा रंग. हे पाहणे सोपे आहे की कोणत्याही प्राथमिक रंगासाठी, पूरक रंग हा इतर प्राथमिक रंगांच्या जोडीच्या बेरजेने तयार केलेला रंग असेल. त्यानुसार, अतिरिक्त रंग आहेत: निळा (निळसर, एस),जांभळा (किरमिजी, एम)आणि पिवळा ( पिवळा, Y).अनियंत्रित रंगाचे त्याच्या घटक घटकांमध्ये विघटन करण्याचे सिद्धांत केवळ प्राथमिक रंगांवरच लागू केले जाऊ शकत नाही, तर अतिरिक्त रंगांवर देखील लागू केले जाऊ शकते, म्हणजे, कोणताही रंग निळसर, किरमिजी आणि पिवळ्या घटकांच्या बेरीज म्हणून दर्शविला जाऊ शकतो. कलर कोडिंगची ही पद्धत छपाईमध्ये स्वीकारली जाते, परंतु छपाईमध्ये चौथा पेंट देखील वापरला जातो - काळा (काळा, के).म्हणून, ही कोडिंग प्रणाली चार अक्षरांनी नियुक्त केली आहे CMYK(काळा रंग अक्षराने दर्शविला जातो ते,कारण पत्र INआधीपासून निळ्याने व्यापलेले आहे), आणि या प्रणालीमध्ये रंग ग्राफिक्सचे प्रतिनिधित्व करण्यासाठी तुमच्याकडे 32 बायनरी बिट्स असणे आवश्यक आहे. या मोडला देखील म्हणतात पूर्ण रंगीत. (खरा रंग).
तुम्ही प्रत्येक बिंदूचा रंग एन्कोड करण्यासाठी वापरल्या जाणाऱ्या बायनरी बिट्सची संख्या कमी केल्यास, तुम्ही डेटाचे प्रमाण कमी करू शकता, परंतु एन्कोड केलेल्या रंगांची श्रेणी लक्षणीयरीत्या कमी होईल. 16-बिट बायनरी क्रमांकांसह रंग ग्राफिक्स एन्कोडिंगला मोड म्हणतात उच्च रंग.
जेव्हा रंग माहिती आठ डेटा बिट वापरून एन्कोड केली जाते, तेव्हा फक्त 256 रंग छटा दाखवल्या जाऊ शकतात. या कलर कोडिंग पद्धतीला म्हणतात निर्देशांकनावाचा अर्थ असा आहे की 256 मूल्ये मानवी डोळ्यांना प्रवेश करण्यायोग्य रंगांची संपूर्ण श्रेणी सांगण्यासाठी पूर्णपणे अपुरी आहेत, प्रत्येक रास्टर पॉइंटचा कोड स्वतः रंग व्यक्त करत नाही, परंतु फक्त त्याची संख्या (इंडेक्स) मध्येकाही लुकअप टेबल म्हणतात पॅलेटअर्थात, हे पॅलेट ग्राफिक डेटाशी संलग्न केले जाणे आवश्यक आहे - त्याशिवाय स्क्रीन किंवा कागदावर माहितीचे पुनरुत्पादन करण्याच्या पद्धती वापरणे अशक्य आहे (म्हणजेच, आपण नक्कीच ते वापरू शकता, परंतु डेटाच्या अपूर्णतेमुळे, प्राप्त माहिती पुरेशी नसेल: झाडांवरील पाने लाल होऊ शकतात आणि आकाश हिरवे आहे).
ऑडिओ माहितीचे एन्कोडिंग
ऑडिओ माहितीसह कार्य करण्याचे तंत्र आणि पद्धती अगदी अलीकडे संगणक तंत्रज्ञानात आल्या. याव्यतिरिक्त, संख्यात्मक, मजकूर आणि ग्राफिकल डेटाच्या विपरीत, ध्वनी रेकॉर्डिंगमध्ये समान दीर्घ आणि सिद्ध कोडिंग इतिहास नव्हता. परिणामी, बायनरी कोड वापरून ऑडिओ माहिती एन्कोड करण्याच्या पद्धती मानकीकरणापासून दूर आहेत. बऱ्याच वैयक्तिक कंपन्यांनी त्यांचे स्वतःचे कॉर्पोरेट मानक विकसित केले आहेत, परंतु सर्वसाधारणपणे, दोन मुख्य क्षेत्रे ओळखली जाऊ शकतात.
एफएम पद्धत (फ्रिक्वेंसी मॉड्युलेशन)सैद्धांतिकदृष्ट्या कोणताही जटिल ध्वनी वेगवेगळ्या फ्रिक्वेन्सीच्या साध्या हार्मोनिक सिग्नलच्या अनुक्रमात विघटित केला जाऊ शकतो या वस्तुस्थितीवर आधारित आहे, ज्यापैकी प्रत्येक एक नियमित साइनसॉइड दर्शवितो आणि म्हणून संख्यात्मक पॅरामीटर्सद्वारे वर्णन केले जाऊ शकते, म्हणजेच कोड. निसर्गात, ध्वनी सिग्नलमध्ये सतत स्पेक्ट्रम असतो, म्हणजेच ते ॲनालॉग असतात. त्यांचे हार्मोनिक मालिकेत विघटन करणे आणि वेगळ्या डिजिटल सिग्नलच्या स्वरूपात प्रतिनिधित्व विशेष उपकरणांद्वारे केले जाते - analog-to-digital converters (ADCs).संख्यात्मकपणे एन्कोड केलेल्या ऑडिओचे पुनरुत्पादन करण्यासाठी व्यस्त रूपांतरण केले जाते डिजिटल-टू-एनालॉग कन्व्हर्टर (डीएसी).अशा परिवर्तनांसह, एन्कोडिंग पद्धतीशी संबंधित माहितीचे नुकसान अपरिहार्य आहे, म्हणून ध्वनी रेकॉर्डिंगची गुणवत्ता सहसा पूर्णपणे समाधानकारक नसते आणि इलेक्ट्रॉनिक संगीताच्या रंग वैशिष्ट्यासह सर्वात सोप्या इलेक्ट्रिक वाद्य वाद्यांच्या आवाजाच्या गुणवत्तेशी संबंधित असते. त्याच वेळी, ही कोडिंग पद्धत एक अतिशय संक्षिप्त कोड प्रदान करते, आणि म्हणूनच संगणक संसाधने स्पष्टपणे अपुरी होती तेव्हा त्या वर्षांमध्ये अनुप्रयोग सापडला.
टेबल-वेव्ह पद्धत ( वेव्ह-टेबल)संश्लेषण तंत्रज्ञानाच्या विकासाच्या वर्तमान पातळीशी अधिक चांगले जुळते. सोप्या भाषेत सांगायचे तर, आम्ही असे म्हणू शकतो की पूर्व-तयार टेबलमध्ये कोठेतरी वेगवेगळ्या संगीत वाद्यांसाठी (जरी केवळ त्यांच्यासाठीच नाही) आवाजांचे नमुने संग्रहित केले जातात. तंत्रज्ञानामध्ये, अशा नमुन्यांना म्हणतात नमुनेसंख्यात्मक कोड उपकरणाचा प्रकार, त्याचा मॉडेल क्रमांक, पिच, कालावधी आणि आवाजाची तीव्रता, त्याच्या बदलाची गतिशीलता, आवाज ज्या वातावरणात होतो त्या वातावरणाचे काही मापदंड तसेच ध्वनीची वैशिष्ट्ये दर्शविणारे इतर मापदंड व्यक्त करतात. "वास्तविक" ध्वनी नमुने म्हणून वापरले जात असल्याने, संश्लेषणाच्या परिणामी प्राप्त झालेल्या ध्वनीची गुणवत्ता खूप उच्च आहे आणि वास्तविक संगीत वाद्यांच्या आवाजाच्या गुणवत्तेपर्यंत पोहोचते.
मूलभूत डेटा संरचना
मोठ्या डेटा संचांसह कार्य करणे डेटा असताना स्वयंचलित करणे सोपे आहे आज्ञा केली,म्हणजेच ते दिलेली रचना तयार करतात. डेटा स्ट्रक्चर्सचे तीन मुख्य प्रकार आहेत: रेखीय, श्रेणीबद्धआणि सारणीसामान्य पुस्तकाचे उदाहरण वापरून त्यांचा विचार केला जाऊ शकतो.
जर तुम्ही पुस्तक वेगळ्या शीटमध्ये घेतले आणि ते मिसळले तर पुस्तकाचा हेतू गमावेल. हे अद्याप डेटाच्या संचाचे प्रतिनिधित्व करेल, परंतु त्यातून माहिती काढण्यासाठी पुरेशी पद्धत निवडणे खूप कठीण आहे. (आपण पुस्तकातून प्रत्येक अक्षर वेगळे काढल्यास परिस्थिती आणखी वाईट होईल - या प्रकरणात, ते वाचण्यासाठी पुरेशी पद्धत असण्याची शक्यता नाही.)
जर आपण पुस्तकाची सर्व पत्रके योग्य क्रमाने गोळा केली तर आपल्याला सर्वात सोपी डेटा रचना मिळेल - रेखीयअसे पुस्तक आधीच वाचले जाऊ शकते, जरी आवश्यक डेटा शोधण्यासाठी आपल्याला ते अगदी सुरुवातीपासून सुरू करून सलग वाचावे लागेल, जे नेहमीच सोयीचे नसते.
त्वरीत डेटा शोधण्यासाठी आहे श्रेणीबद्ध रचना.म्हणून, उदाहरणार्थ, पुस्तके भाग, विभाग, अध्याय, परिच्छेद इत्यादींमध्ये विभागली जातात. खालच्या-स्तरीय संरचनेचे घटक उच्च-स्तरीय संरचनेच्या घटकांमध्ये समाविष्ट केले जातात: विभागांमध्ये अध्याय, परिच्छेदांचे अध्याय इ.
मोठ्या ॲरेसाठी, श्रेणीबद्ध संरचनेत डेटा शोधणे एका रेखीय पेक्षा खूप सोपे आहे, तथापि, येथे देखील ते आवश्यक आहे नेव्हिगेशन,पाहण्याच्या गरजेशी संबंधित. सराव मध्ये, बहुतेक पुस्तकांमध्ये सहायक क्रॉस-सेक्शन आहे या वस्तुस्थितीद्वारे कार्य सोपे केले जाते टेबलश्रेणीबद्ध संरचनेच्या घटकांना रेखीय संरचनेच्या घटकांसह जोडणे, म्हणजेच पृष्ठ क्रमांकांसह विभाग, अध्याय आणि परिच्छेद जोडणे. अनुक्रमिक वाचनासाठी डिझाइन केलेली साधी श्रेणीबद्ध रचना असलेल्या पुस्तकांमध्ये, या सारणीला सहसा म्हणतात सामग्री सारणी,आणि एक जटिल रचना असलेल्या पुस्तकांमध्ये जे निवडक वाचन करण्यास परवानगी देते, त्याला म्हणतात सामग्री
१.६. डेटा आणि त्याचे कोडिंग
स्टोरेज मीडिया
डेटा हा माहितीचा द्वंद्वात्मक घटक आहे. ते रेकॉर्ड केलेले सिग्नल दर्शवतात. या प्रकरणात, भौतिक नोंदणी पद्धत काहीही असू शकते: भौतिक शरीराची यांत्रिक हालचाल, त्यांच्या आकारात किंवा पृष्ठभागाच्या गुणवत्तेतील बदल, विद्युत, चुंबकीय बदल, ऑप्टिकल वैशिष्ट्ये, रासायनिक रचनाआणि (किंवा) रासायनिक बंधांचे स्वरूप, इलेक्ट्रॉनिक प्रणालीच्या स्थितीत बदल आणि बरेच काही.
रेकॉर्डिंग पद्धतीनुसार, विविध प्रकारच्या माध्यमांवर डेटा संग्रहित आणि वाहतूक केला जाऊ शकतो. सर्वात सामान्य स्टोरेज माध्यम, जरी सर्वात किफायतशीर नसले तरी ते कागदी असल्याचे दिसते. कागदावर, त्याच्या पृष्ठभागाची ऑप्टिकल वैशिष्ट्ये बदलून डेटा रेकॉर्ड केला जातो. ऑप्टिकल गुणधर्म बदलणे (विशिष्ट तरंगलांबी श्रेणीतील पृष्ठभागाचे प्रतिबिंब बदलणे) देखील अशा उपकरणांमध्ये वापरले जाते जे परावर्तक कोटिंग (CD-ROM) असलेल्या प्लास्टिक मीडियावर लेसर बीमसह रेकॉर्ड करतात. चुंबकीय गुणधर्मांमधील बदल वापरणाऱ्या माध्यमांमध्ये चुंबकीय टेप आणि डिस्कचा समावेश होतो. कॅरियरच्या पृष्ठभागाच्या पदार्थांची रासायनिक रचना बदलून रेकॉर्डिंग डेटा फोटोग्राफीमध्ये मोठ्या प्रमाणावर वापरला जातो. बायोकेमिकल स्तरावर, सजीव निसर्गात डेटा जमा आणि प्रसारित केला जातो.
डेटा वाहक आपल्याला स्वतःमध्ये स्वारस्य नसतात, परंतु माहितीचे गुणधर्म त्याच्या वाहकांच्या गुणधर्मांशी अगदी जवळून संबंधित असतात. कोणतेही माध्यम रिझोल्यूशन पॅरामीटर (माध्यमासाठी स्वीकारलेल्या मोजमापाच्या युनिटमध्ये रेकॉर्ड केलेल्या डेटाचे प्रमाण) आणि डायनॅमिक श्रेणी (जास्तीत जास्त आणि किमान रेकॉर्ड केलेल्या सिग्नलच्या मोठेपणाच्या तीव्रतेचे लॉगरिदमिक गुणोत्तर) द्वारे दर्शविले जाऊ शकते. पूर्णता, प्रवेशयोग्यता आणि विश्वासार्हता यासारख्या माहितीचे गुणधर्म बहुतेकदा या माध्यमाच्या गुणधर्मांवर अवलंबून असतात. म्हणून, उदाहरणार्थ, आम्ही या वस्तुस्थितीवर विश्वास ठेवू शकतो की सीडीवर असलेल्या डेटाबेसमध्ये फ्लॉपी मॅग्नेटिक डिस्कवर असलेल्या समान उद्देशाच्या डेटाबेसपेक्षा माहितीची पूर्णता सुनिश्चित करणे सोपे आहे, कारण पहिल्या प्रकरणात घनता प्रति युनिट लांबी डेटा रेकॉर्डिंग मार्ग जास्त आहेत. सरासरी ग्राहकांसाठी, पुस्तकातील माहितीची उपलब्धता सीडीवरील समान माहितीपेक्षा लक्षणीय आहे, कारण सर्व ग्राहकांकडे आवश्यक उपकरणे नसतात. आणि शेवटी, हे ज्ञात आहे व्हिज्युअल प्रभावप्रोजेक्टरमध्ये स्लाइड पाहणे हे कागदावर छापलेले समान चित्र पाहण्यापेक्षा खूप मोठे आहे, कारण प्रसारित प्रकाशातील ब्राइटनेस सिग्नलची श्रेणी परावर्तित प्रकाशापेक्षा दोन ते तीन ऑर्डरची परिमाण जास्त असते.
माध्यम बदलण्याच्या उद्देशाने डेटा रूपांतरित करणे हे संगणक विज्ञानातील सर्वात महत्वाचे कार्य आहे. संगणकीय प्रणालीच्या खर्चाच्या संरचनेत, डेटाच्या इनपुट आणि आउटपुटसाठी डिव्हाइसेस जे स्टोरेज मीडियासह कार्य करतात ते हार्डवेअरच्या निम्म्या खर्चापर्यंत असतात.
डेटा ऑपरेशन्स
माहिती प्रक्रियेदरम्यान, पद्धतींचा वापर करून डेटा एका प्रकारातून दुसऱ्या प्रकारात रूपांतरित केला जातो. डेटा प्रोसेसिंगमध्ये अनेक वेगवेगळ्या ऑपरेशन्सचा समावेश होतो. वैज्ञानिक आणि तांत्रिक प्रगतीच्या विकासासह आणि मानवी समाजातील कनेक्शनची सामान्य जटिलता, डेटा प्रोसेसिंगसाठी श्रमिक खर्च सतत वाढत आहेत. सर्वप्रथम, हे उत्पादन आणि समाज व्यवस्थापित करण्याच्या परिस्थितीच्या सतत गुंतागुंतीमुळे होते. दुसरा घटक, ज्यामुळे प्रक्रिया केलेल्या डेटाच्या व्हॉल्यूममध्ये सामान्य वाढ देखील होते, वैज्ञानिक आणि तांत्रिक प्रगतीशी देखील संबंधित आहे, म्हणजे नवीन डेटा वाहकांचा उदय आणि अंमलबजावणीचा वेग, डेटा स्टोरेज आणि वितरणाचे साधन.
रचना मध्ये संभाव्य ऑपरेशन्सडेटासह, खालील मुख्य ओळखले जाऊ शकतात:
डेटा संग्रह - निर्णय घेण्यासाठी माहितीची पुरेशी पूर्णता सुनिश्चित करण्यासाठी डेटाचे संचय;
डेटा फॉर्मलायझेशन - वेगवेगळ्या स्त्रोतांकडून येणारा डेटा एकमेकांशी तुलना करता येण्यासाठी, म्हणजेच त्यांच्या प्रवेशयोग्यतेची पातळी वाढवण्यासाठी समान स्वरूपात आणणे;
डेटा फिल्टरिंग - निर्णय घेण्यासाठी आवश्यक नसलेला "अतिरिक्त" डेटा फिल्टर करणे; त्याच वेळी, "आवाज" ची पातळी कमी झाली पाहिजे आणि डेटाची विश्वासार्हता आणि पर्याप्तता वाढली पाहिजे;
डेटा क्रमवारी - वापर सुलभतेसाठी दिलेल्या निकषानुसार डेटा ऑर्डर करणे; माहितीची उपलब्धता वाढवते;
डेटा ग्रुपिंग - वापरात सुलभता सुधारण्यासाठी दिलेल्या वैशिष्ट्यानुसार डेटा एकत्र करणे; माहितीची उपलब्धता वाढवते;
डेटा संग्रहण - सोयीस्कर आणि सहज प्रवेश करण्यायोग्य स्वरूपात डेटा संचयन आयोजित करणे; डेटा स्टोरेजचा आर्थिक खर्च कमी करण्यासाठी आणि संपूर्ण माहिती प्रक्रियेची संपूर्ण विश्वासार्हता वाढवते;
डेटा संरक्षण हा डेटाचे नुकसान, पुनरुत्पादन आणि बदल टाळण्यासाठी उपायांचा एक संच आहे;
डेटा वाहतूक - माहिती प्रक्रियेतील दूरस्थ सहभागींमधील डेटाचे रिसेप्शन आणि ट्रान्समिशन (वितरण आणि वितरण); या प्रकरणात, संगणक विज्ञानातील डेटा स्त्रोतास सामान्यतः सर्व्हर म्हणतात आणि ग्राहकास क्लायंट म्हणतात;
डेटा ट्रान्सफॉर्मेशन म्हणजे एका फॉर्ममधून दुसऱ्या फॉर्ममध्ये किंवा एका स्ट्रक्चरमधून दुसऱ्या फॉर्ममध्ये डेटाचे हस्तांतरण. डेटा रूपांतरणामध्ये अनेकदा माध्यमांचा प्रकार बदलणे समाविष्ट असते, उदाहरणार्थ, पुस्तके नियमित कागदाच्या स्वरूपात संग्रहित केली जाऊ शकतात, परंतु यासाठी इलेक्ट्रॉनिक फॉर्म आणि मायक्रोफोटोग्राफिक फिल्म वापरली जाऊ शकते. ते वाहतूक करताना पुनरावृत्ती डेटा रूपांतरणाची आवश्यकता देखील उद्भवते, विशेषत: जर ते या प्रकारच्या डेटाची वाहतूक करण्याच्या हेतूने नसलेल्या माध्यमाने केले जाते. उदाहरण म्हणून, आम्ही नमूद करू शकतो की टेलिफोन नेटवर्कच्या चॅनेलवर डिजिटल डेटा प्रवाहाची वाहतूक करण्यासाठी (जे सुरुवातीला फक्त अरुंद वारंवारता श्रेणीमध्ये ॲनालॉग सिग्नलच्या प्रसारणावर केंद्रित होते), डिजिटल डेटाचे काही प्रकारात रूपांतर करणे आवश्यक आहे. ऑडिओ सिग्नलचे, जे विशेष उपकरण - टेलिफोन मॉडेम - करतात.
येथे दिलेल्या ठराविक डेटा ऑपरेशन्सची यादी पूर्ण होण्यापासून दूर आहे. जगभरातील लाखो लोक डेटा तयार करतात, प्रक्रिया करतात, परिवर्तन करतात आणि वाहतूक करतात आणि प्रत्येक कार्यस्थळ सामाजिक, आर्थिक, औद्योगिक, वैज्ञानिक आणि सांस्कृतिक प्रक्रिया व्यवस्थापित करण्यासाठी आवश्यक असलेली स्वतःची विशिष्ट ऑपरेशन्स करते. संभाव्य ऑपरेशन्सची संपूर्ण यादी संकलित करणे अशक्य आहे आणि ते आवश्यक नाही. आता आणखी एक निष्कर्ष आमच्यासाठी महत्त्वाचा आहे: माहितीसह कार्य करणे अत्यंत श्रम-केंद्रित असू शकते आणि ते स्वयंचलित करणे आवश्यक आहे.
बायनरी डेटा एन्कोडिंग
वेगवेगळ्या प्रकारच्या डेटासह कार्य स्वयंचलित करण्यासाठी, त्यांच्या सादरीकरणाचे स्वरूप एकत्र करणे खूप महत्वाचे आहे - यासाठी, कोडिंग सहसा वापरले जाते, म्हणजेच, एका प्रकारचा डेटा दुसर्या प्रकारच्या डेटाद्वारे व्यक्त करणे. नैसर्गिक मानवी भाषा भाषणाद्वारे विचार व्यक्त करण्यासाठी संकल्पना कोडिंग प्रणालीपेक्षा अधिक काही नाहीत. भाषांशी जवळचा संबंध म्हणजे अक्षरे (ग्राफिक चिन्हे वापरून भाषा घटक कोडींग करण्याची प्रणाली). "सार्वत्रिक" भाषा आणि अक्षरे तयार करण्याचा अयशस्वी प्रयत्न असूनही, इतिहास मनोरंजक आहे. वरवर पाहता, त्यांची अंमलबजावणी करण्याच्या प्रयत्नांचे अपयश हे या वस्तुस्थितीमुळे आहे की राष्ट्रीय आणि सामाजिक संस्थांना स्वाभाविकपणे हे समजले आहे की सार्वजनिक डेटा कोडिंग सिस्टममध्ये बदल केल्याने नक्कीच सामाजिक पद्धतींमध्ये (म्हणजे कायदेशीर आणि नैतिक नियम) बदल होईल आणि हे सामाजिक उलथापालथीशी संबंधित असू शकते.
युनिव्हर्सल कोडिंग टूलची हीच समस्या तंत्रज्ञान, विज्ञान आणि संस्कृतीच्या काही शाखांमध्ये यशस्वीरित्या अंमलात आणली जात आहे. उदाहरणांमध्ये गणितीय अभिव्यक्ती लिहिण्यासाठी एक प्रणाली, तार वर्णमाला, नौदल ध्वज वर्णमाला, अंधांसाठी ब्रेल प्रणाली आणि बरेच काही समाविष्ट आहे.
तांदूळ. १.८. वेगवेगळ्या कोडिंग सिस्टमची उदाहरणे
संगणक तंत्रज्ञानाची स्वतःची प्रणाली देखील असते - याला बायनरी कोडिंग म्हणतात आणि ते फक्त दोन वर्णांचा क्रम म्हणून डेटाचे प्रतिनिधित्व करण्यावर आधारित आहे: 0 आणि 1. या वर्णांना बायनरी अंक म्हणतात, इंग्रजीमध्ये - बायनरी अंक, किंवा, थोडक्यात, बिट .
एक बिट दोन संकल्पना व्यक्त करू शकतो: 0 किंवा 1 (होय किंवा नाही, काळा किंवा पांढरा, खरे किंवा खोटे इ.). जर बिट्सची संख्या दोन पर्यंत वाढवली तर चार भिन्न संकल्पना व्यक्त केल्या जाऊ शकतात:
तीन बिट आठ भिन्न मूल्ये एन्कोड करू शकतात:
000 001 010 011 100 101 110 111
बायनरी कोडींग सिस्टीममधील बिट्सची संख्या एकाने वाढवून, आम्ही या सिस्टीममध्ये व्यक्त करता येणाऱ्या मूल्यांची संख्या दुप्पट करतो.
एन्कोडिंग पूर्णांक आणि वास्तविक संख्या
0 ते 255 पर्यंत पूर्णांक एन्कोड करण्यासाठी, बायनरी कोडचे 8 बिट (8 बिट्स) असणे पुरेसे आहे.
……………….
सोळा बिट्स तुम्हाला 0 ते 65535 पर्यंत पूर्णांक एन्कोड करण्याची परवानगी देतात आणि 24 बिट्स तुम्हाला 16.5 दशलक्ष भिन्न मूल्ये एन्कोड करण्याची परवानगी देतात.
वास्तविक संख्या एन्कोड करण्यासाठी, 80-बिट एन्कोडिंग वापरले जाते. या प्रकरणात, संख्या प्रथम सामान्यीकृत स्वरूपात रूपांतरित केली जाते.
३.१४१५९२६ = ०.३१४१५९२६ १०१
300,000 = 0.3 106
१२३,४५६,७८९ = ०.१२३४५६७८९ १०९
संख्येच्या पहिल्या भागाला मँटिसा म्हणतात आणि दुसरा वैशिष्ट्यपूर्ण आहे. बहुतेक 80 बिट्स मॅन्टिसा (चिन्हासह) संग्रहित करण्यासाठी वाटप केले जातात आणि वैशिष्ट्यपूर्ण (साइन केलेले) संग्रहित करण्यासाठी ठराविक बिट्सचे वाटप केले जाते.
मजकूर डेटा एन्कोडिंग
जर वर्णमालेतील प्रत्येक वर्ण विशिष्ट पूर्णांकाशी संबंधित असेल (उदाहरणार्थ, अनुक्रमांक), तर बायनरी कोड वापरून मजकूर माहिती देखील एन्कोड केली जाऊ शकते. 256 भिन्न वर्ण एन्कोड करण्यासाठी आठ बायनरी अंक पुरेसे आहेत. इंग्रजी आणि रशियन अक्षरे, लोअरकेस आणि अपरकेस दोन्ही वर्ण, तसेच विरामचिन्हे, मूलभूत अंकगणित क्रियांची चिन्हे आणि काही सामान्यतः स्वीकारले जाणारे विशेष वर्ण, जसे की “§” आठ बिट्सच्या विविध संयोजनांमध्ये व्यक्त करण्यासाठी हे पुरेसे आहे. चिन्ह.
तांत्रिकदृष्ट्या हे अगदी सोपे दिसते, परंतु नेहमीच लक्षणीय संस्थात्मक अडचणी आल्या आहेत. संगणक तंत्रज्ञानाच्या विकासाच्या सुरुवातीच्या वर्षांमध्ये, ते आवश्यक मानकांच्या कमतरतेशी संबंधित होते, परंतु आजकाल ते एकाच वेळी विद्यमान आणि विरोधाभासी मानकांच्या विपुलतेमुळे होते. संपूर्ण जगाला त्याच प्रकारे मजकूर डेटा एन्कोड करण्यासाठी, युनिफाइड एन्कोडिंग टेबल्सची आवश्यकता आहे आणि हे राष्ट्रीय अक्षरांच्या वर्णांमधील विरोधाभास, तसेच कॉर्पोरेट विरोधाभासांमुळे अद्याप शक्य नाही.
च्या साठी इंग्रजी मध्ये, ज्याने वास्तविक दळणवळणाच्या आंतरराष्ट्रीय माध्यमाचे स्थान मिळवले आहे, विरोधाभास आधीच काढून टाकले गेले आहेत. यूएस स्टँडर्ड्स इन्स्टिट्यूट (ANSI - अमेरिकन नॅशनल स्टँडर्ड इन्स्टिट्यूट) ने ASCII (अमेरिकन स्टँडर्ड कोड फॉर इन्फॉर्मेशन इंटरचेंज) कोडींग प्रणाली सादर केली. ASCII प्रणालीमध्ये दोन एन्कोडिंग सारण्या आहेत: मूलभूत आणि विस्तारित. मूलभूत सारणी 0 ते 127 पर्यंत कोड मूल्ये निश्चित करते आणि विस्तारित सारणी 128 ते 255 पर्यंतच्या संख्येसह वर्णांचा संदर्भ देते.
बेस टेबलचे पहिले 32 कोड, शून्यापासून सुरू होणारे, हार्डवेअर उत्पादकांना (प्रामुख्याने संगणक आणि प्रिंटिंग डिव्हाइस उत्पादक) दिले जातात. या क्षेत्रामध्ये तथाकथित नियंत्रण कोड आहेत, जे कोणत्याही भाषेच्या वर्णांशी संबंधित नाहीत आणि त्यानुसार, हे कोड स्क्रीनवर किंवा प्रिंटिंग डिव्हाइसेसवर प्रदर्शित केले जात नाहीत, परंतु ते इतर डेटा कसा आउटपुट होतो हे नियंत्रित करू शकतात.
कोड 32 पासून कोड 127 पर्यंत, इंग्रजी वर्णमाला, विरामचिन्हे, संख्या, अंकगणित क्रिया आणि काही सहायक वर्णांसाठी कोड आहेत. बेस टेबल ASCII एन्कोडिंगतक्ता 1.1 मध्ये दिले आहे.

मजकूर डेटा एन्कोडिंगसाठी तत्सम प्रणाली इतर देशांमध्ये विकसित केली गेली आहे. उदाहरणार्थ, यूएसएसआरमध्ये, कोडिंग सिस्टम KOI-7 (सात-अंकी माहिती एक्सचेंज कोड) या क्षेत्रात कार्यरत आहे. तथापि, हार्डवेअर आणि सॉफ्टवेअर उत्पादकांच्या समर्थनामुळे अमेरिकन एएससीआयआय कोड आंतरराष्ट्रीय मानकांच्या पातळीवर आणला गेला आणि राष्ट्रीय कोडिंग सिस्टमला कोडिंग सिस्टमच्या एका सेकंदापर्यंत "मागे" जावे लागले, कोडिंग सिस्टमच्या विस्तारित भागातून कोडची मूल्ये परिभाषित केली जातात. 128 ते 255. या क्षेत्रात एकच मानक नसल्यामुळे एकाचवेळी एन्कोडिंगची संख्या वाढली आहे. केवळ रशियामध्ये तीन वर्तमान एन्कोडिंग मानक आणि आणखी दोन जुने दर्शविणे शक्य आहे.
उदाहरणार्थ, रशियन भाषेचे कॅरेक्टर एन्कोडिंग, ज्याला Windows-1251 एन्कोडिंग म्हणून ओळखले जाते, मायक्रोसॉफ्टने "बाहेरून" सादर केले होते, परंतु रशियामधील ऑपरेटिंग सिस्टम आणि या कंपनीच्या इतर उत्पादनांचे व्यापक वितरण पाहता ते खोलवर रुजले होते. आणि मोठ्या प्रमाणावर वापरले जाते (तक्ता 1.2). हे एन्कोडिंग Windows प्लॅटफॉर्मवर चालणाऱ्या बहुतेक स्थानिक संगणकांवर वापरले जाते. वास्तविक, हे वर्ल्ड वाइड वेबच्या रशियन क्षेत्रात मानक बनले आहे.

आणखी एक सामान्य एन्कोडिंग KOI-8 (माहिती विनिमय कोड, आठ-अंकी) असे म्हणतात - त्याची उत्पत्ती पूर्व युरोपीय राज्यांच्या परस्पर आर्थिक सहाय्य परिषदेच्या काळापासून आहे (टेबल 1.3). या एन्कोडिंगवर आधारित, KOI8-R (रशियन) आणि KOI8-U (युक्रेनियन) एन्कोडिंग सध्या वापरात आहेत. आज, KOI8-R एन्कोडिंग रशियामधील संगणक नेटवर्क आणि रशियन इंटरनेट क्षेत्रातील काही सेवांमध्ये मोठ्या प्रमाणावर वापरले जाते. विशेषतः, रशियामध्ये हे ईमेल संदेश आणि टेलिकॉन्फरन्समध्ये वास्तविक मानक आहे.

आंतरराष्ट्रीय मानक, जे रशियन वर्णमालाच्या वर्णांचे एन्कोडिंग प्रदान करते, त्याला ISO (इंटरनॅशनल स्टँडर्ड ऑर्गनायझेशन) एन्कोडिंग (इंटरनॅशनल इंस्टिट्यूट फॉर स्टँडर्डायझेशन) म्हणतात. सराव मध्ये, हे एन्कोडिंग क्वचितच वापरले जाते (टेबल 1.4).

MS-DOS ऑपरेटिंग सिस्टीम चालवणाऱ्या संगणकांवर, आणखी दोन एन्कोडिंग कार्य करू शकतात (GOST एन्कोडिंग आणि GOST-पर्यायी एन्कोडिंग). वैयक्तिक संगणनाच्या सुरुवातीच्या काळातही त्यापैकी पहिला अप्रचलित मानला जात होता, परंतु दुसरा आजही वापरात आहे (तक्ता 1.5 पहा).

रशियामध्ये कार्यरत असलेल्या मजकूर डेटा एन्कोडिंग सिस्टमच्या विपुलतेमुळे, इंटरसिस्टम डेटा रूपांतरणाची समस्या उद्भवते - ही संगणक विज्ञानातील सामान्य समस्यांपैकी एक आहे.
युनिव्हर्सल टेक्स्ट डेटा एन्कोडिंग सिस्टम
जर आपण मजकूर डेटा कोडिंगसाठी युनिफाइड सिस्टमच्या निर्मितीशी संबंधित संस्थात्मक अडचणींचे विश्लेषण केले, तर आम्ही या निष्कर्षापर्यंत पोहोचू शकतो की ते कोडच्या मर्यादित संचामुळे (256) आहेत. त्याच वेळी, हे स्पष्ट आहे की, उदाहरणार्थ, जर तुम्ही आठ-बिट बायनरी संख्यांसह नव्हे तर मोठ्या संख्येने बिट्स असलेल्या संख्येसह चिन्हे एन्कोड केली, तर संभाव्य कोड मूल्यांची श्रेणी खूप मोठी होईल. 16-बिट कॅरेक्टर एन्कोडिंगवर आधारित या प्रणालीला युनिव्हर्सल - युनिकोड म्हणतात. सोळा अंकांमुळे 65,536 भिन्न वर्णांसाठी अद्वितीय कोड प्रदान करणे शक्य होते - हे फील्ड वर्णांच्या एका सारणीमध्ये ग्रहाच्या बहुतेक भाषांना सामावून घेण्यासाठी पुरेसे आहे.
या दृष्टिकोनाची क्षुल्लक स्पष्टता असूनही, संगणकाच्या अपुऱ्या संसाधनांमुळे (युनिकोड कोडिंग प्रणालीमध्ये, सर्व मजकूर दस्तऐवज आपोआप दुप्पट होतात) मुळे या प्रणालीमध्ये एक साधे यांत्रिक संक्रमण बराच काळ बाधित होते. 90 च्या दशकाच्या उत्तरार्धात, तांत्रिक माध्यमांनी संसाधनांच्या तरतुदीची आवश्यक पातळी गाठली आणि आज आपण सार्वत्रिक कोडिंग सिस्टममध्ये कागदपत्रे आणि सॉफ्टवेअरचे हळूहळू हस्तांतरण पाहत आहोत. वैयक्तिक वापरकर्त्यांसाठी, याने सॉफ्टवेअरसह वेगवेगळ्या कोडींग सिस्टीममध्ये बनवलेल्या दस्तऐवजांच्या समन्वयाबाबत आणखी चिंतेची भर पडली, परंतु हे संक्रमण काळातील अडचणी समजले पाहिजे.
ग्राफिक्स डेटा एन्कोडिंग
जर तुम्ही वर्तमानपत्रात किंवा पुस्तकात छापलेल्या काळ्या आणि पांढऱ्या ग्राफिक इमेजचे भिंगाने परीक्षण केले तर तुम्हाला दिसेल की त्यात लहान ठिपके असतात ज्यात रास्टर (चित्र 1.9) नावाचा वैशिष्ट्यपूर्ण नमुना तयार होतो.

तांदूळ. १.९. रास्टर ही ग्राफिक माहिती एन्कोड करण्याची एक पद्धत आहे,
बर्याच काळापासून छपाईमध्ये स्वीकारले गेले आहे
रेखीय निर्देशांक आणि प्रत्येक बिंदूचे वैयक्तिक गुणधर्म (ब्राइटनेस) पूर्णांक वापरून व्यक्त केले जाऊ शकतात, आम्ही असे म्हणू शकतो की रास्टर कोडिंग ग्राफिक डेटाचे प्रतिनिधित्व करण्यासाठी बायनरी कोड वापरण्याची परवानगी देते. 256 राखाडी छटा असलेल्या ठिपक्यांचे संयोजन म्हणून काळ्या आणि पांढऱ्या चित्रांचे प्रतिनिधित्व करणे आज सामान्यतः स्वीकारले जाते आणि अशा प्रकारे आठ-बिट बायनरी संख्या कोणत्याही बिंदूची चमक एन्कोड करण्यासाठी पुरेशी असते.
कलर ग्राफिक प्रतिमा एन्कोड करण्यासाठी, त्याच्या मुख्य घटकांमध्ये अनियंत्रित रंगाचे विघटन करण्याचे तत्त्व वापरले जाते. असे घटक म्हणून तीन प्राथमिक रंग वापरले जातात: लाल (लाल, आर), हिरवा (हिरवा, जी) आणि निळा (निळा, बी). व्यवहारात असे मानले जाते (जरी सैद्धांतिकदृष्ट्या हे पूर्णपणे सत्य नाही) की मानवी डोळ्यांना दिसणारा कोणताही रंग यांत्रिकरित्या या तीन प्राथमिक रंगांचे मिश्रण करून मिळू शकतो. या कोडींग प्रणालीला प्राथमिक रंगांच्या नावांच्या पहिल्या अक्षरानंतर RGB प्रणाली म्हणतात.
जर 256 मूल्ये (आठ बायनरी बिट्स) प्रत्येक मुख्य घटकाची चमक एन्कोड करण्यासाठी वापरली जातात, जसे की हाफटोन ब्लॅक-व्हाइट इमेजसाठी प्रथा आहे, तर एका बिंदूचा रंग एन्कोड करण्यासाठी 24 बिट्स खर्च करणे आवश्यक आहे. त्याच वेळी, कोडिंग प्रणाली 16.5 दशलक्ष वेगवेगळ्या रंगांची अस्पष्ट ओळख प्रदान करते, जी प्रत्यक्षात मानवी डोळ्याच्या संवेदनशीलतेच्या जवळ आहे. 24 बायनरी बिट्स वापरून कलर ग्राफिक्सचे प्रतिनिधित्व करण्याच्या मोडला खरे रंग म्हणतात.
प्रत्येक प्राथमिक रंग अतिरिक्त रंगाशी संबंधित असू शकतो, म्हणजे, प्राथमिक रंग पांढऱ्याला पूरक करणारा रंग. हे पाहणे सोपे आहे की कोणत्याही प्राथमिक रंगासाठी, पूरक रंग हा इतर प्राथमिक रंगांच्या जोडीच्या बेरजेने तयार केलेला रंग असेल. त्यानुसार, अतिरिक्त रंग आहेत: निळसर (निळसर, सी), किरमिजी (किरमिजी, एम) आणि पिवळा (पिवळा, वाई). अनियंत्रित रंगाचे त्याच्या घटक घटकांमध्ये विघटन करण्याचे सिद्धांत केवळ प्राथमिक रंगांवरच लागू केले जाऊ शकत नाही, तर अतिरिक्त रंगांवर देखील लागू केले जाऊ शकते, म्हणजे, कोणताही रंग निळसर, किरमिजी आणि पिवळ्या घटकांच्या बेरीज म्हणून दर्शविला जाऊ शकतो. कलर कोडिंगची ही पद्धत छपाईमध्ये स्वीकारली जाते, परंतु छपाईमध्ये चौथी शाई देखील वापरली जाते - काळी (ब्लॅक, के). म्हणून, ही कोडिंग प्रणाली चार अक्षरे CMYK द्वारे दर्शविली जाते (काळा अक्षर K ने दर्शविला जातो, कारण B अक्षर आधीपासूनच निळ्याने व्यापलेले आहे), आणि या प्रणालीमध्ये रंग ग्राफिक्सचे प्रतिनिधित्व करण्यासाठी आपल्याकडे 32 बायनरी अंक असणे आवश्यक आहे. या मोडला खरा रंग देखील म्हणतात.
तुम्ही प्रत्येक बिंदूचा रंग एन्कोड करण्यासाठी वापरल्या जाणाऱ्या बायनरी बिट्सची संख्या कमी केल्यास, तुम्ही डेटाचे प्रमाण कमी करू शकता, परंतु एन्कोड केलेल्या रंगांची श्रेणी लक्षणीयरीत्या कमी होईल. 16-बिट बायनरी नंबर वापरून रंग ग्राफिक्स एन्कोडिंगला हाय कलर मोड म्हणतात.
जेव्हा रंग माहिती आठ डेटा बिट वापरून एन्कोड केली जाते, तेव्हा फक्त 256 रंग छटा दाखवल्या जाऊ शकतात. या रंग एन्कोडिंग पद्धतीला अनुक्रमणिका म्हणतात. नावाचा अर्थ असा आहे की 256 मूल्ये मानवी डोळ्यात प्रवेश करण्यायोग्य रंगांची संपूर्ण श्रेणी सांगण्यासाठी पूर्णपणे अपुरी असल्याने, प्रत्येक रास्टर पॉइंटचा कोड स्वतः रंग व्यक्त करत नाही, परंतु केवळ त्याची संख्या (इंडेक्स) विशिष्ट लुक-अप टेबलला पॅलेट म्हणतात. अर्थात, हे पॅलेट ग्राफिक डेटाशी संलग्न केले जाणे आवश्यक आहे - त्याशिवाय स्क्रीन किंवा कागदावर माहितीचे पुनरुत्पादन करण्याच्या पद्धती वापरणे अशक्य आहे (म्हणजेच, आपण नक्कीच ते वापरू शकता, परंतु डेटाच्या अपूर्णतेमुळे, प्राप्त माहिती पुरेशी नसेल: झाडांवरील पाने लाल होऊ शकतात आणि आकाश हिरवे आहे).
ऑडिओ माहितीचे एन्कोडिंग
ऑडिओ माहितीसह कार्य करण्याचे तंत्र आणि पद्धती अगदी अलीकडे संगणक तंत्रज्ञानात आल्या. याव्यतिरिक्त, संख्यात्मक, मजकूर आणि ग्राफिकल डेटाच्या विपरीत, ध्वनी रेकॉर्डिंगमध्ये समान दीर्घ आणि सिद्ध कोडिंग इतिहास नव्हता. परिणामी, बायनरी कोड वापरून ऑडिओ माहिती एन्कोड करण्याच्या पद्धती मानकीकरणापासून दूर आहेत. अनेक वैयक्तिक कंपन्यांनी त्यांचे स्वतःचे कॉर्पोरेट मानक विकसित केले आहेत.
व्याख्यान क्र. 4.
बायनरी डेटा एन्कोडिंग
विविध प्रकारच्या डेटासह कार्य स्वयंचलित करण्यासाठी, त्यांचे सादरीकरण फॉर्म एकत्र करणे खूप महत्वाचे आहे. या उद्देशासाठी, कोडिंग तंत्र सहसा वापरले जाते, म्हणजे. एका प्रकारचा डेटा दुसऱ्या प्रकारच्या डेटाच्या संदर्भात व्यक्त करणे.
कोडिंग सिस्टमची उदाहरणे: मानवी भाषा, अक्षरे (ग्राफिक चिन्हे वापरून भाषा एन्कोड करणे), गणितीय अभिव्यक्ती लिहिणे, टेलिग्राफिक मोर्स कोड, अंधांसाठी ब्रेल कोड, नौदल ध्वज वर्णमाला इ.
संगणक तंत्रज्ञानाची स्वतःची कोडिंग प्रणाली देखील आहे - याला बायनरी कोडिंग म्हणतात आणि ते फक्त दोन वर्णांचा क्रम म्हणून डेटाचे प्रतिनिधित्व करण्यावर आधारित आहे: 0 आणि 1. या वर्णांना बायनरी अंक किंवा बिट म्हणतात.
एक बिट दोन संकल्पना व्यक्त करू शकतो: 0 किंवा 1 (होय किंवा नाही, काळा किंवा पांढरा, खरे किंवा खोटे इ.). जर तुम्ही बिट्सची संख्या दोन पर्यंत वाढवली, तर तुम्ही आधीच चार वेगवेगळ्या संकल्पना व्यक्त करू शकता - 00 01 10 11. तीन बिट्ससह तुम्ही आठ वेगवेगळ्या संकल्पना एन्कोड करू शकता - 000 001 010 100 101 110 101 111.
बायनरी कोडिंग सिस्टीममधील बिट्सची संख्या एकाने वाढवून, तुम्ही एन्कोड केलेल्या मूल्यांची संख्या दुप्पट करू शकता: एन=2 आय, कुठे आय- अंकांची संख्या, एन- मूल्यांची संख्या.
संगणक संख्यात्मक, मजकूर, ग्राफिक, ध्वनी आणि व्हिडिओ डेटावर प्रक्रिया करू शकतो. या सर्व प्रकारचे डेटा विद्युतीय डाळींच्या अनुक्रमात एन्कोड केलेले आहेत: तेथे एक नाडी (1), तेथे नाडी (0) नाही, म्हणजे. शून्य आणि एकाच्या क्रमाने. शून्य आणि एकाच्या अशा तार्किक अनुक्रमांना मशीन भाषा म्हणतात.
नोटेशन
संख्या प्रणाली म्हणजे काय?
पोझिशनल आणि नॉन-पोझिशनल नंबर सिस्टम आहेत.
IN अस्थानिकसिस्टीम, अंकाचे वजन (म्हणजे, संख्येच्या मूल्यामध्ये त्याचे योगदान) संख्येच्या नोटेशनमध्ये त्याच्या स्थानावर अवलंबून नाही. अशाप्रकारे, XXXII (बत्तीस) या संख्येतील रोमन क्रमांक प्रणालीमध्ये, कोणत्याही स्थितीत X या संख्येचे वजन फक्त दहा असते.
IN स्थितीसंबंधीसंख्या प्रणालीमध्ये, प्रत्येक अंकाचे वजन संख्या दर्शविणाऱ्या अंकांच्या क्रमानुसार त्याच्या स्थानावर (स्थिती) अवलंबून असते. उदाहरणार्थ, क्रमांक 757.7 मध्ये, पहिल्या सात म्हणजे 7 शेकडो, दुसरा - 7 युनिट्स आणि तिसरा - एका युनिटचा 7 दशांश.
संख्या 757.7 च्या अगदी नोटेशनचा अर्थ अभिव्यक्तीचे संक्षिप्त नोटेशन आहे
700 + 50 + 7 + 0,7 = 7 10 2 + 5 10 1 + 7 10 0 + 7 10 -1 = 757,7.
कोणतीही पोझिशनल नंबर सिस्टीम त्याच्या बेसद्वारे दर्शविली जाते.
प्रणालीचा आधार म्हणून कोणतीही नैसर्गिक संख्या घेतली जाऊ शकते - दोन, तीन, चार, इ. परिणामी, असीम संख्यात्मक स्थिती प्रणाली शक्य आहेत: बायनरी, टर्नरी, चतुर्थांश इ. प्रत्येक संख्या प्रणालीमध्ये बेससह संख्या लिहिणे qम्हणजे लघुलेखन अभिव्यक्ती
a n-1 q n-1 + अ n-2 q n-2 + ... + अ 1 q 1 + अ 0 q 0 + अ -1 q -1 + ... + अ -m q -m ,
कुठे a i- संख्या प्रणालीची संख्या; nआणि मी- अनुक्रमे पूर्णांक आणि अंशात्मक अंकांची संख्या.
संगणकाशी संवाद साधण्यासाठी तज्ञ कोणती संख्या प्रणाली वापरतात?
दशांश व्यतिरिक्त, बेस असलेली प्रणाली संपूर्ण 2 ची शक्ती, म्हणजे:
बायनरी (अंक 0, 1 वापरले जातात);
ऑक्टल (अंक 0, 1, ..., 7 वापरले जातात);
हेक्साडेसिमल (शून्य ते नऊ पर्यंतच्या पहिल्या पूर्णांकांसाठी 0, 1, ..., 9 हे अंक वापरले जातात आणि पुढील संख्यांसाठी - दहा ते पंधरा पर्यंत - A, B, C, D, E, F ही अक्षरे आहेत. अंक म्हणून वापरले).
लोक दशांश प्रणाली का वापरतात आणि संगणक बायनरी प्रणाली का वापरतात?
लोक दशांश प्रणालीला प्राधान्य देतात कारण ते प्राचीन काळापासून त्यांच्या बोटांवर मोजत आहेत आणि लोकांना दहा बोटे आणि बोटे आहेत. लोक नेहमी आणि सर्वत्र दशांश संख्या प्रणाली वापरत नाहीत. चीनमध्ये, उदाहरणार्थ, त्यांनी दीर्घकाळ पाच-अंकी संख्या प्रणाली वापरली.
आणि संगणक बायनरी प्रणाली वापरतात कारण त्याचे इतर प्रणालींपेक्षा बरेच फायदे आहेत:
ते अंमलात आणण्यासाठी, दोन स्थिर स्थितींसह तांत्रिक उपकरणे आवश्यक आहेत (तेथे करंट आहे - वर्तमान नाही, चुंबकीकृत - चुंबकीकृत नाही, इ.), आणि नाही, उदाहरणार्थ, दहासह, दशांश प्रमाणे;
केवळ दोन राज्यांद्वारे माहितीचे सादरीकरण विश्वसनीय आणि आवाज-प्रतिरोधक आहे;
माहितीचे तार्किक परिवर्तन करण्यासाठी बुलियन बीजगणित यंत्र वापरणे शक्य आहे;
बायनरी अंकगणित दशांश अंकगणितापेक्षा खूप सोपे आहे.
बायनरी सिस्टमचा तोटा म्हणजे संख्या रेकॉर्ड करण्यासाठी आवश्यक असलेल्या अंकांच्या संख्येत जलद वाढ.
संगणक देखील ऑक्टल आणि हेक्साडेसिमल संख्या प्रणाली का वापरतात?
बायनरी प्रणाली, संगणकासाठी सोयीस्कर, मानवांसाठी गैरसोयीची आहे घनताआणि असामान्य रेकॉर्डिंग.
दशांश प्रणालीपासून बायनरी प्रणालीमध्ये संख्यांचे रूपांतरण आणि त्याउलट मशीनद्वारे केले जाते. तथापि, व्यावसायिकरित्या संगणक वापरण्यासाठी, आपण मशीन हा शब्द समजून घेणे शिकले पाहिजे. त्यामुळे अष्टाधारी आणि हेक्साडेसिमल प्रणाली विकसित केल्या गेल्या.
या सिस्टीममधील संख्या दशांश प्रमाणे वाचण्यास जवळजवळ सोप्या आहेत, त्यानुसार आवश्यक आहेत तीन वाजता(ऑक्टल) आणि चार वाजता(हेक्साडेसिमल) पेक्षा पट कमी अंक बायनरी प्रणाली (शेवटी, संख्या 8 आणि 16 अनुक्रमे, क्रमांक 2 ची तिसरी आणि चौथी शक्ती आहेत).
बायनरी संख्या प्रणाली
संगणक विज्ञानातील बायनरी संख्या प्रणालीचे विशेष महत्त्व यावरून निश्चित केले जाते की संगणकातील कोणत्याही माहितीचे अंतर्गत प्रतिनिधित्व बायनरी आहे, म्हणजे. केवळ दोन वर्णांच्या संचाद्वारे वर्णन केले आहे (0 आणि 1).
दशांश वरून बायनरीमध्ये रूपांतरित करणे
संपूर्ण आणि अंशात्मक भाग स्वतंत्रपणे अनुवादित केले आहेत. एका संख्येचा पूर्णांक भाग रूपांतरित करण्यासाठी, त्याला आधार 2 ने भागणे आवश्यक आहे आणि भागाकार 0 च्या बरोबरीचे होईपर्यंत भागाकार भागाकार करणे सुरू ठेवा. परिणामी उर्वरितांची मूल्ये, उलट क्रमाने घेतली जातात, इच्छित बायनरी संख्या तयार करा.
उदाहरणार्थ,
25 (10) = 11001 (2)
फ्रॅक्शनल भाग रूपांतरित करण्यासाठी, तुम्हाला तो 2 ने गुणाकार करणे आवश्यक आहे. उत्पादनाचा पूर्णांक भाग हा बायनरी सिस्टममधील संख्येचा पहिला अंक असेल. नंतर, परिणामाचा अंशात्मक भाग टाकून, आम्ही पुन्हा 2 ने गुणाकार करतो, इ. मर्यादित दशांश अपूर्णांक अनंत (नियतकालिक) बायनरी अपूर्णांक बनू शकतो.
उदाहरणार्थ,
0.73 * 2 = 1.46 (पूर्णांक भाग 1)
0.46 * 2 = 0.92 (पूर्णांक भाग 0)
0.92 * 2 = 1.84 (पूर्णांक भाग 1)
0.84 * 2 = 1.68 (पूर्णांक भाग 1), इ. ०.७३ (१०) = ०.१०११… (२)
बायनरी संख्यांसह अंकगणित क्रिया
येथे बायनरी जोडणे 1 + 1 दशांश अंकगणिताप्रमाणे 1 सर्वात लक्षणीय अंकापर्यंत नेतो. उदाहरणार्थ,
येथे बायनरी वजाबाकीहे लक्षात ठेवले पाहिजे की जवळच्या अंकामध्ये 1 व्यापलेला सर्वात कमी अंकाची दोन एकके देतो. समीप उच्च-ऑर्डर अंकांमध्ये शून्य असल्यास, 1 नंतर अनेक अंक व्यापले जाते. या प्रकरणात, जवळच्या महत्त्वाच्या सर्वात लक्षणीय अंकामध्ये व्यापलेले एकक सर्वात कमी महत्त्वाच्या अंकाची दोन एकके देते आणि सर्वात कमी आणि सर्वात लक्षणीय अंकांच्या दरम्यान उभे असलेले सर्व शून्य अंकांचे एकक देते.
197 मधून 174 वजा करा

बायनरी विभागणीबायनरी गुणाकार आणि वजाबाकी सारण्या वापरून उद्भवते. 430 ला 10 ने भागा

ऑक्टल आणि हेक्साडेसिमल संख्या प्रणाली
संख्यांचे दशांश ते ऑक्टलमध्ये रूपांतर करत आहेगुणाकार आणि भागाकार वापरून बायनरी प्रमाणेच केले जाते, केवळ 2 ने नाही तर 8 ने.
उदाहरणार्थ, 58.32 (10)
58: 8 = 7 (2 शिल्लक)
७:८ = ० (७ बाकी)
0,48 * 8 = 3,84, …
58,32 (10) = 72,243… (8)
दशांश संख्या प्रणालीपासून हेक्साडेसिमलमध्ये संख्यांचे रूपांतर त्याच प्रकारे केले जाते. ५६७ (१०)० = २३७ (१६)
भिन्न संख्या प्रणालींमध्ये संख्यांचा पत्रव्यवहार
|
दशांश |
हेक्साडेसिमल |
ऑक्टल |
बायनरी |
पूर्णांक बायनरी संख्या ऑक्टल मध्ये रूपांतरित करण्यासाठीतुम्हाला ते उजवीकडून डावीकडे 3 अंकांच्या गटांमध्ये विभाजित करणे आवश्यक आहे (सर्वात डावीकडील गटात तीन बायनरी अंकांपेक्षा कमी असू शकतात), आणि नंतर प्रत्येक गटाला त्याच्या अष्टक समतुल्य असाइन करा. असे गट म्हणतात बायनरी ट्रायड्स.
उदाहरणार्थ,
11011001 = 11 011 001 = 331 (8)
पूर्णांक बायनरी संख्या हेक्साडेसिमलमध्ये रूपांतरित करणेदिलेल्या संख्येला 4 अंकांच्या गटात विभागून तयार केले जाते - बायनरी टेट्राड्स.
1100011011001 = 1 1000 1101 1001 = 18D9 (16)
बायनरी संख्यांचे अपूर्णांक ऑक्टल किंवा हेक्साडेसिमल सिस्टीममध्ये रूपांतरित करण्यासाठी, ट्रायड्स किंवा टेट्राड्समध्ये समान विभागणी स्वल्पविरामापासून उजवीकडे केली जाते (शून्यांसह पूरक नसलेल्या शेवटच्या अंकांसह)
0,1100011101 (2) = 0,110 001 110 100 = 0,6164 (8)
0.1100011101 (2) = 0.1100 0111 0100 = C74 (16)
ऑक्टल (हेक्साडेसिमल) संख्यांना बायनरीमध्ये रूपांतरित करणे उलट पद्धतीने केले जाते - प्रत्येक संख्येचे चिन्ह बायनरी अंकांच्या संबंधित तिप्पट (चतुर्भुज) शी जुळवून.
A1F (16) = 1010 0001 1111 (2)
127 (8) = 001 010 111 (2)
8 आणि 16 संख्या 2 च्या पूर्णांक शक्ती आहेत या वस्तुस्थितीमुळे अशा परिवर्तनांची साधेपणा आहे. ही साधेपणा ऑक्टल आणि हेक्साडेसिमल संख्या प्रणालीची लोकप्रियता स्पष्ट करते.
शिक्षकांसाठी इंटरनेट साइट्सची यादी (2)
दस्तऐवजपाम्स संग्रहण व्याख्यानेखगोलशास्त्रात... कोडिंग, कोडिंग डेटा बायनरी कोड, कोडिंगमजकूर डेटा, प्रणाली कोडिंग, कोडिंगग्राफिक डेटा, कोडिंगध्वनी माहिती. सार्वत्रिक प्रणाली कोडिंगमजकूर डेटा ...
विशिष्टतेमध्ये (प्रशिक्षणाची दिशा) हलत्या वस्तूंसह संप्रेषण प्रणालीच्या शैक्षणिक विषयावरील व्याख्यान नोट्स (शैक्षणिक शिस्तीचे नाव)
लेक्चर नोट्स... कोडिंग व्याख्यान 11. शोधणे आणि दुरुस्त करणे या मूलभूत गोष्टी कोड्सथोडक्यात सारांश व्याख्याने: ... माहिती बिट्सची संख्या k, आणि साठी बायनरी कोड: , . अप्पर बाउंड... हस्तांतरण पद्धत लागू केली कोडिंग डेटा, ज्याला ऑर्थोगोनल म्हणतात...
"इलेक्ट्रॉनिक औद्योगिक उपकरणे" ज्ञानाचे क्षेत्र या विषयावरील व्याख्यान साहित्य
दस्तऐवज... . कोडिंगमाहिती मुख्य प्रकार कोड ................................................................. 19 व्याख्यान 6. ...ते प्राप्त करणे डेटाग्राहक; प्रासंगिकता... बायनरी कोडआणि त्याचे बदल - सममितीय बायनरी कोड. बायनरी कोड ...
डेटा एन्कोडिंग
बायनरी डेटा एन्कोडिंग
विविध प्रकारच्या डेटासह कार्य स्वयंचलित करण्यासाठी, त्यांचे सादरीकरण फॉर्म एकत्र करणे खूप महत्वाचे आहे - यासाठी, तंत्र सहसा वापरले जाते कोडिंग , म्हणजे, दुसऱ्या प्रकारच्या डेटाच्या संदर्भात एका प्रकारच्या डेटाची अभिव्यक्ती. नैसर्गिक मानवी भाषा भाषणाद्वारे विचार व्यक्त करण्यासाठी संकल्पना कोडिंग प्रणालीपेक्षा अधिक काही नाहीत. भाषांशी जवळचा संबंध म्हणजे अक्षरे (ग्राफिक चिन्हे वापरून भाषा घटक कोडींग करण्याची प्रणाली). "सार्वत्रिक" भाषा आणि अक्षरे तयार करण्याचा अयशस्वी प्रयत्न असूनही, इतिहास मनोरंजक आहे. वरवर पाहता, त्यांची अंमलबजावणी करण्याच्या प्रयत्नांचे अपयश हे या वस्तुस्थितीमुळे आहे की राष्ट्रीय आणि सामाजिक संस्थांना स्वाभाविकपणे हे समजले आहे की सार्वजनिक डेटा कोडिंग सिस्टममध्ये बदल केल्याने नक्कीच सामाजिक पद्धतींमध्ये (म्हणजे कायदेशीर आणि नैतिक नियम) बदल होईल आणि हे सामाजिक उलथापालथीशी संबंधित असू शकते.
युनिव्हर्सल कोडिंग टूलची हीच समस्या तंत्रज्ञान, विज्ञान आणि संस्कृतीच्या काही शाखांमध्ये यशस्वीरित्या अंमलात आणली जात आहे. उदाहरणांमध्ये गणितीय अभिव्यक्ती लिहिण्यासाठी एक प्रणाली, तार वर्णमाला, नौदल ध्वज वर्णमाला, अंधांसाठी ब्रेल प्रणाली आणि बरेच काही समाविष्ट आहे,
संगणक तंत्रज्ञानाची स्वतःची प्रणाली देखील आहे - याला बायनरी कोडिंग म्हणतात आणि फक्त दोन वर्णांचा क्रम म्हणून डेटाचे प्रतिनिधित्व करण्यावर आधारित आहे: 0 आणि 1. या वर्णांना बायनरी अंक म्हणतात, इंग्रजीमध्ये - binaiy अंक किंवा संक्षिप्त बिट (बिट).
एक बिट दोन संकल्पना व्यक्त करू शकतो: 0 किंवा 1 (होय किंवा नाही, काळा किंवा पांढरा, खरे किंवा खोटे इ.). जर बिट्सची संख्या दोन पर्यंत वाढवली तर चार भिन्न संकल्पना व्यक्त केल्या जाऊ शकतात:
तीन बिट आठ भिन्न संकल्पना एन्कोड करू शकतात:
000 001 010 011 100 101 110 111
म्हणजेच, बायनरी कोडिंग सिस्टममधील बिट्सची संख्या एकने वाढवून, आम्ही या प्रणालीमध्ये व्यक्त केल्या जाऊ शकणाऱ्या मूल्यांची संख्या दुप्पट करतो. सामान्य सूत्र:
जेथे N ही स्वतंत्र एन्कोड केलेल्या मूल्यांची संख्या आहे;
m – या प्रणालीमध्ये स्वीकारलेल्या बायनरी कोडिंगची थोडी खोली.
डेटाचे प्रतिनिधित्व आणि मापनाचे मोठे एकक म्हणजे बाइट.
8 बिट - 1 बाइट
1024 बाइट्स - 1 किलोबाइट (KB)
1024 किलोबाइट - 1 मेगाबाइट (MB)
1024 मेगाबाइट - 1 गीगाबाइट (GB)
संगणकाद्वारे प्रक्रिया केलेल्या डेटाचे मुख्य प्रकार:
पूर्णांक आणि वास्तविक संख्या.
मजकूर डेटा.
ग्राफिक डेटा.
ध्वनी डेटा.
एन्कोडिंग पूर्णांक आणि वास्तविक संख्या
पूर्णांक संख्या बायनरीमध्ये अगदी सोप्या पद्धतीने एन्कोड केल्या जातात - फक्त एक पूर्णांक घ्या आणि जोपर्यंत भागफल एक होत नाही तोपर्यंत त्याला अर्ध्यामध्ये विभाजित करा. शेवटच्या भागासह उजवीकडून डावीकडे लिहिलेल्या प्रत्येक विभागातील उर्वरित भागांचा संच दशांश संख्येचा बायनरी ॲनालॉग बनवतो:
अशा प्रकारे, 19 10 = 100112.
0 ते 255 पर्यंत पूर्णांक एन्कोड करण्यासाठी, बायनरी कोडचे 8 बिट (8 बिट्स) असणे पुरेसे आहे. सोळा बिट्स तुम्हाला 0 ते 65,535 पर्यंत पूर्णांक एन्कोड करण्याची परवानगी देतात आणि 24 बिट्स तुम्हाला 16.5 दशलक्षाहून अधिक भिन्न मूल्ये एन्कोड करण्याची परवानगी देतात.
वास्तविक संख्या एन्कोड करण्यासाठी, 80-बिट एन्कोडिंग वापरले जाते. या प्रकरणात, संख्या प्रथम सामान्यीकृत स्वरूपात रूपांतरित केली जाते:
3,1415926=0,31415926*10 1
300 000 = 0,3*10 6
123 456 789 = 0,123456789*10 10
नंबरचा पहिला भाग म्हणतात मंटिसा , आणि दुसरा - वैशिष्ट्यपूर्ण . बहुतेक 80 बिट्स मॅन्टिसा (चिन्हासह) संग्रहित करण्यासाठी वाटप केले जातात आणि वैशिष्ट्यपूर्ण (साइन केलेले) संग्रहित करण्यासाठी ठराविक बिट्सचे वाटप केले जाते.
मजकूर डेटा एन्कोडिंग
जर वर्णमालेतील प्रत्येक वर्ण विशिष्ट पूर्णांकाशी संबंधित असेल (उदाहरणार्थ, अनुक्रमांक), तर बायनरी कोड वापरून मजकूर माहिती देखील एन्कोड केली जाऊ शकते. 256 भिन्न वर्ण एन्कोड करण्यासाठी आठ बायनरी अंक पुरेसे आहेत. इंग्रजी आणि रशियन भाषेतील सर्व वर्ण, लोअरकेस आणि अपरकेस, तसेच विरामचिन्हे, मूलभूत अंकगणित ऑपरेशन्सची चिन्हे आणि काही सामान्यतः स्वीकारले जाणारे विशेष वर्ण, उदाहरणार्थ “§” हे चिन्ह आठ बिट्सच्या विविध संयोजनांमध्ये व्यक्त करण्यासाठी हे पुरेसे आहे. "
तांत्रिकदृष्ट्या हे अगदी सोपे दिसते, परंतु नेहमीच लक्षणीय संस्थात्मक अडचणी आल्या आहेत. संगणक तंत्रज्ञानाच्या विकासाच्या सुरुवातीच्या वर्षांमध्ये, ते आवश्यक मानकांच्या कमतरतेशी संबंधित होते, परंतु आजकाल ते एकाच वेळी विद्यमान आणि विरोधाभासी मानकांच्या विपुलतेमुळे होते. संपूर्ण जगाला त्याच प्रकारे मजकूर डेटा एन्कोड करण्यासाठी, युनिफाइड एन्कोडिंग टेबल्सची आवश्यकता आहे आणि हे राष्ट्रीय अक्षरांच्या वर्णांमधील विरोधाभास, तसेच कॉर्पोरेट विरोधाभासांमुळे अद्याप शक्य नाही.
इंग्रजी भाषेसाठी, ज्याने वास्तविक दळणवळणाच्या आंतरराष्ट्रीय माध्यमाचे स्थान मिळवले आहे, विरोधाभास आधीच काढून टाकले गेले आहेत. यूएस स्टँडर्ड्स इन्स्टिट्यूट (ANSI - अमेरिकन नॅशनल स्टँडर्ड इन्स्टिट्यूट) ने ASCII (अमेरिकन स्टँडर्ड कोड फॉर इन्फॉर्मेशन इंटरचेंज) कोडींग प्रणाली सादर केली. ASCII प्रणालीमध्ये दोन एन्कोडिंग टेबल्स आहेत - मूलभूत आणि विस्तारित. मूलभूत सारणी 0 ते 127 पर्यंत कोड मूल्ये निश्चित करते आणि विस्तारित सारणी 128 ते 255 पर्यंतच्या संख्येसह वर्णांचा संदर्भ देते.
बेस टेबलचे पहिले 32 कोड, शून्यापासून सुरू होणारे, हार्डवेअर उत्पादकांना (प्रामुख्याने संगणक आणि प्रिंटिंग डिव्हाइस उत्पादक) दिले जातात. या क्षेत्रामध्ये तथाकथित नियंत्रण कोड आहेत, जे कोणत्याही भाषेच्या वर्णांशी संबंधित नाहीत आणि त्यानुसार, हे कोड स्क्रीनवर किंवा प्रिंटिंग डिव्हाइसेसवर प्रदर्शित केले जात नाहीत, परंतु ते इतर डेटा कसा आउटपुट होतो हे नियंत्रित करू शकतात.
कोड 32 पासून कोड 127 पर्यंत, इंग्रजी वर्णमाला, विरामचिन्हे, संख्या, अंकगणित क्रिया आणि काही सहायक वर्णांसाठी कोड आहेत. मूलभूत ASCII एन्कोडिंग सारणी तक्ता 1.1 मध्ये दर्शविली आहे:
|
तक्ता 1.1. |
मूलभूत एन्कोडिंग सारणीASCIIASCII |
||||||||||
|
32 teasprrr जागा |
|||||||||||
|
44 , |
|||||||||||
|
दस्तऐवज व्याख्यान क्र. 4. कोडिंग डेटाबायनरी कोडसह कार्य स्वयंचलित करण्यासाठी डेटा, विविध प्रकारच्या संबंधित, हे खूप महत्वाचे आहे... तंत्र सहसा वापरले जाते कोडिंग, म्हणजे अभिव्यक्ती डेटामाध्यमातून एक प्रकार डेटादुसरा प्रकार. उदाहरणे... ही निर्मिती (सूचना/FAQ) सतत पूरक आणि संपादित केली जाईल. तुम्ही तुमच्या शुभेच्छा, शिफारसी, वर्णन, टिप्पण्या फोरमवर सोडू शकता किंवा संपर्क फॉर्मद्वारे माझ्याशी संपर्क साधू शकता.सूचनाबहुतेक लोकांची सुनावणी. दपद्धत म्हणतात कोडिंगसमज असे म्हटले जात आहे... तुम्हाला नंतर एक मिळणे आवश्यक आहे कोडिंग. दमेनू आयटम पॉप-अप विंडोला कारणीभूत ठरते... - मग ही एक पुनर्प्राप्ती योजना आहे डेटापासून कोड केलेलेज्या स्वरूपात ते प्रसारित केले जातात... या पाठ्यपुस्तकात उच्च शिक्षण प्रणालीतील तज्ञांना प्रशिक्षण देण्यासाठी आवश्यक असलेला संपूर्ण संगणक विज्ञान अभ्यासक्रम आहे. गावाची थीमॅटिक रचनानिबंधआवश्यक माहिती. १.३. कामगिरी ( कोडिंग) डेटा१.३.१. संख्या प्रणाली विविध आहेत... माहिती 6 1.1.4. माहिती प्रक्रिया 9 1.3. कामगिरी ( कोडिंग) डेटा 10 1.3.1. संख्या प्रणाली 10 1.3.2. कामगिरी... भौतिक कोडिंगदस्तऐवज... कोडिंगआणि तार्किक कोडिंगएक प्रणाली तयार करा कोडिंगसर्वात खालची पातळी. प्रणाली कोडिंगप्रणाली कोडिंग डेटा... सर्वाधिक वापरल्या जाणाऱ्या प्रणाली कोडिंग: NRZ (गैर... 1. माहिती कोडिंगची संकल्पना. स्वतंत्र (डिजिटल) माहितीच्या प्रतिनिधित्वाची सार्वत्रिकता. पोझिशनल आणि नॉन-पोझिशनल नंबर सिस्टम. अल्गोरिदमदस्तऐवजमहत्त्वामुळे दिलेप्रक्रियेला एक विशेष नाव आहे - कोडिंगमाहिती कोडिंगमाहिती विलक्षण आहे... वेगळ्या पद्धतींची काही उदाहरणे द्या कोडिंग डेटा: मजकूर, ग्राफिक्स, ध्वनी. जतन करण्यासाठी... | |||||||||||
डेटासह कार्य स्वयंचलित करण्यासाठी, संगणक नावाची विशेष प्रकारची उपकरणे वापरली जातात.
पीसी ही एक सार्वत्रिक तांत्रिक प्रणाली आहे; त्याचे कॉन्फिगरेशन आवश्यकतेनुसार लवचिकपणे बदलले जाऊ शकते
7. पीसी परिधीय
या समस्येचे निराकरण osi (ओपन सिस्टम इंटरकनेक्शन) मॉडेलवर आधारित आहे
इंटरनेट हे एक इंटरनेटवर्क आहे जे बॅकबोन नेटवर्क्सना जोडते
हायपरटेक्स्ट माहिती एक्सचेंज प्रोटोकॉल
12 अल्गोरिदमची संकल्पना
13. ऑब्जेक्ट ओरिएंटेड प्रोग्रामिंग. 13 ऑब्जेक्ट ओरिएंटेड दृष्टीकोन
§ 2 डेटा आणि माहिती कोडिंग
डेटा हे माहितीचे द्वंद्वात्मक घटक आहेत. ते रेकॉर्ड केलेले सिग्नल दर्शवतात.
या प्रकरणात, नोंदणीची कोणतीही भौतिक पद्धत वापरली जाऊ शकते (भौतिक शरीराची हालचाल किंवा पृष्ठभागाच्या पॅरामीटर्स, इलेक्ट्रिकल, चुंबकीय किंवा ऑप्टिकल वैशिष्ट्यांमधील बदल, रासायनिक रचना इ.)
रेकॉर्डिंग पद्धतीनुसार, विविध प्रकारच्या माध्यमांवर डेटा संग्रहित आणि वाहतूक केला जाऊ शकतो.
हे लक्षात ठेवणे आवश्यक आहे की माहितीचे गुणधर्म त्याच्या वाहकांच्या गुणधर्मांशी जवळून संबंधित आहेत.
सरासरी ग्राहकांसाठी, पुस्तकातील माहितीची उपलब्धता सीडीवरील समान माहितीपेक्षा लक्षणीय आहे, कारण प्रत्येकाकडे ही उपकरणे नसतात.
डेटा ऑपरेशन्स
माहिती प्रक्रियेदरम्यान, पद्धतींचा वापर करून डेटा एका प्रकारातून दुसऱ्या प्रकारात रूपांतरित केला जातो.
डेटा प्रोसेसिंगमध्ये अनेक भिन्न ऑपरेशन्स समाविष्ट आहेत, ज्यापैकी खालील ओळखले जाऊ शकतात:
डेटा संग्रह - निर्णय घेण्यासाठी पुरेशी माहिती प्रदान करण्यासाठी माहितीचे संचय
डेटा फॉर्मलायझेशन म्हणजे वेगवेगळ्या स्त्रोतांकडून येणारा डेटा एकाच फॉर्ममध्ये आणणे जेणेकरून ते एकमेकांशी तुलना करता येतील, म्हणजेच त्यांच्या प्रवेशयोग्यतेची पातळी वाढवता येईल.
डेटा फिल्टरिंग - निर्णय घेण्यासाठी आवश्यक नसलेला अनावश्यक डेटा फिल्टर करणे; त्याच वेळी, आवाज पातळी कमी झाली पाहिजे आणि डेटाची विश्वासार्हता आणि पर्याप्तता वाढली पाहिजे.
डेटा सॉर्टिंग - वापरण्यास सुलभतेच्या उद्देशाने दिलेल्या वैशिष्ट्यानुसार डेटा ऑर्डर करणे, ज्यामुळे माहितीची विश्वासार्हता वाढते
डेटा संग्रहण ही सोयीस्कर आणि प्रवेशयोग्य स्वरूपात डेटा स्टोरेजची संस्था आहे, डेटा स्टोरेजचा आर्थिक खर्च कमी करते आणि माहिती प्रक्रियेची एकूण विश्वासार्हता वाढवते.
डेटा संरक्षण हा डेटाचे नुकसान, पुनरुत्पादन आणि बदल सुनिश्चित करण्याच्या उद्देशाने उपायांचा एक संच आहे
डेटा वाहतूक - माहिती प्रक्रियेतील दूरस्थ सहभागींमधील डेटाचे स्वागत आणि प्रसारण; या प्रकरणात, डेटा स्त्रोतास सहसा सर्व्हर म्हणतात आणि ग्राहकास क्लायंट म्हणतात
डेटा ट्रान्सफॉर्मेशन - एका फॉर्ममधून दुसऱ्या फॉर्ममध्ये किंवा एका स्ट्रक्चरमधून दुसऱ्या फॉर्ममध्ये डेटा ट्रान्सफर करणे
बायनरी डेटा एन्कोडिंग
………………………………………………………………………………
विविध प्रकारचे, त्यांच्या सादरीकरणाचे स्वरूप एकत्र करणे खूप महत्वाचे आहे.
हे करण्यासाठी, कोडिंग तंत्र सामान्यतः वापरले जाते, म्हणजे, एका प्रकारचा डेटा दुसर्या प्रकारच्या डेटाच्या संदर्भात व्यक्त करणे. उदाहरणांमध्ये गणितीय अभिव्यक्ती लिहिण्यासाठी प्रणाली, टेलिग्राफ वर्णमाला, अंधांसाठी ब्रेल प्रणाली, नौदल ध्वज वर्णमाला इ.
संगणक तंत्रज्ञानाची स्वतःची प्रणाली देखील आहे - त्याला बायनरी कोडिंग म्हणतात आणि केवळ दोन वर्ण, 0 आणि 1 च्या क्रमाने डेटाचे प्रतिनिधित्व करण्यावर आधारित आहे.
या वर्णांना बायनरी अंक (इंग्रजीमध्ये बायनरी अंक) किंवा संक्षिप्त बिट 1 बिट म्हणतात.
एक बिट दोन संकल्पना व्यक्त करू शकतो: 0 किंवा 1, होय किंवा नाही, काळा किंवा पांढरा, खरे किंवा खोटे इ. d
जर बिट्सची संख्या 2 पर्यंत वाढवली तर चार वेगवेगळ्या संकल्पना आधीच व्यक्त केल्या जाऊ शकतात.
तीन बिट आठ भिन्न मूल्ये एन्कोड करू शकतात: 000 001 010 011 100 101 110 111
बायनरी कोडींग सिस्टीममधील बिट्सची संख्या एकाने वाढवून, या सिस्टीममध्ये व्यक्त केलेल्या मूल्यांची संख्या दुप्पट होते, सामान्य सूत्र असे दिसते:
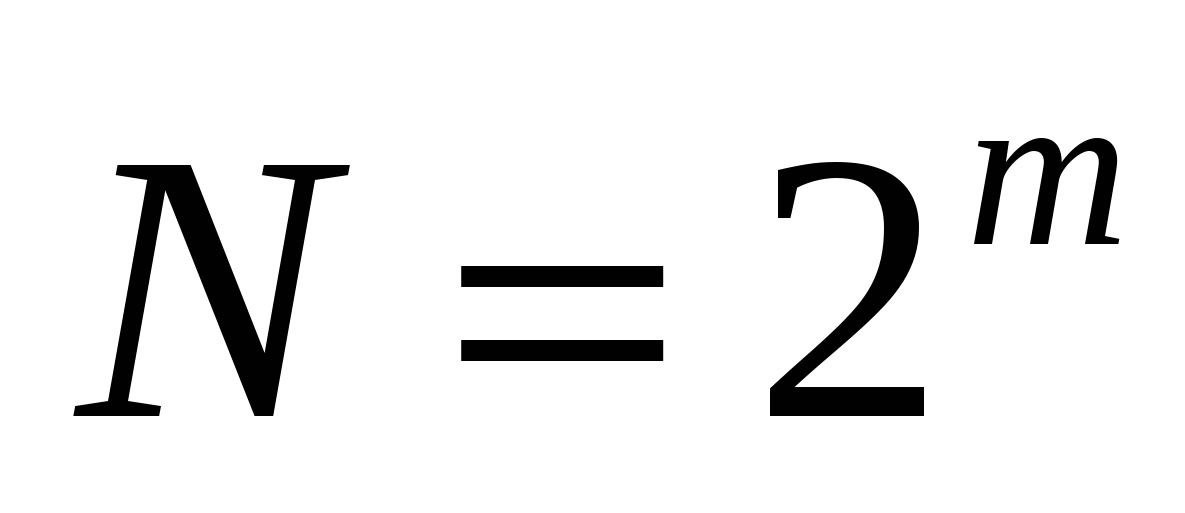
जेथे N ही स्वतंत्र एन्कोड केलेल्या मूल्यांची संख्या आहे
या प्रणालीमध्ये स्वीकारलेल्या बायनरी कोडिंगची M – बिट खोली
एन्कोडिंग पूर्णांक आणि वास्तविक संख्या
पूर्णांक खालीलप्रमाणे बायनरीमध्ये एन्कोड केले जातात: पूर्णांक घ्या आणि उर्वरित शून्य किंवा एक होईपर्यंत अर्ध्या भागामध्ये विभाजित करा.
प्रत्येक विभागातील उर्वरित भागांचा संच, शेवटच्या भागासह उजवीकडून डावीकडे लिहिलेला, दशांश संख्येचा बायनरी ॲनालॉग बनवतो
म्हणजे, 19 10 = 10011 2
0 ते 255 पर्यंत पूर्णांक एन्कोड करण्यासाठी, बायनरी कोडचे 8 बिट असणे पुरेसे आहे (8 बिट)
16 बिट्स तुम्हाला 0 ते 65535 पर्यंत पूर्णांक एन्कोड करण्याची परवानगी देतात
24 बिट्स - आधीच 16.5 दशलक्ष पेक्षा जास्त भिन्न मूल्ये.
वास्तविक संख्या एन्कोड करण्यासाठी, 80-बिट एन्कोडिंग वापरले जाते.
या प्रकरणात, संख्या प्रथम सामान्यीकृत स्वरूपात रूपांतरित केली जाते:
3,1415926 = 0,31415926 * 10 1
300000 = 0,3 * 10 6
123456789 = 0,123456789 * 10 10
संख्येच्या पहिल्या भागाला , , , - वैशिष्ट्य म्हणतात. स्वाक्षरी केलेल्या जागेत मॅन्टीसा संग्रहित करण्यासाठी बहुतेक 80 बिट्सचे वाटप केले जाते आणि 10-चिन्हांचे वैशिष्ट्य संग्रहित करण्यासाठी थोड्या प्रमाणात बिट वाटप केले जातात.
मजकूर डेटा एन्कोडिंग
वर्णमाला प्रत्येक वर्ण विशिष्ट पूर्णांक संख्या (ऑर्डिनल नंबर) शी संबंधित असल्यास, बायनरी कोड वापरून मजकूर माहिती एन्कोड केली जाऊ शकते. आठ बायनरी वर्ण 256 भिन्न वर्ण एन्कोड करण्यासाठी. इंग्रजी भाषेसाठी, यूएस स्टँडर्डायझेशन इन्स्टिट्यूट (ANSI - अमेरिकन नॅशनल स्टँडर्ड इन्स्टिट्यूट) ने ASCII (अमेरिकन स्टँडर्ड कोड फॉर इन्फॉर्मेशन इंटरचेंज) एन्कोडिंग सिस्टीम - मानक यूएस माहिती एक्सचेंज कोड सादर केला.
ASCII प्रणालीमध्ये दोन आहेत. कोडिंग - मूलभूत आणि प्रगत. मूलभूत सारणी 0 ते 127 मधील कोडचा अर्थ निश्चित करते आणि विस्तारित सारणी 128 ते 255 पर्यंतच्या संख्येसह वर्णांचा संदर्भ देते.
बेस टेबलचे पहिले 32 कोड हार्डवेअर उत्पादकांना दिले आहेत. d या भागात ठेवले आहेत. a नियंत्रण कोड जे कोणत्याही भाषेतील वर्णांशी जुळत नाहीत.
हे कोड स्क्रीनवर किंवा प्रिंटिंग डिव्हाइसेसवर प्रदर्शित होत नाहीत, परंतु इतर डेटा कसा आउटपुट होतो हे ते नियंत्रित करतात.
ASCII व्यतिरिक्त, KON - 8 (माहिती विनिमय कोड, 8-अंकी), विंडोज एन्कोडिंग, ISO एन्कोडिंग, UNICODE, GOST - वैकल्पिक एन्कोडिंग सारखे एन्कोडिंग आहेत.
ग्राफिक्स डेटा एन्कोडिंग
तुम्ही b/w वाढवल्यास ग्राफिक प्रतिमावर्तमानपत्र किंवा पुस्तकात मुद्रित केलेले, आपण पाहू शकता की त्यात लहान ठिपके असतात ज्यात रास्टर नावाचा वैशिष्ट्यपूर्ण नमुना बनतो.
प्रत्येक बिंदूचे रेखीय समन्वय आणि रंग पूर्णांक वापरून व्यक्त केले जाऊ शकतात, रास्टर कोडिंगला ग्राफिक डेटाचे प्रतिनिधित्व करण्यासाठी बायनरी कोड वापरणे म्हटले जाऊ शकते.
कलर इमेजेस एन्कोड करण्यासाठी, त्याच्या मुख्य घटकांमध्ये अनियंत्रित रंगाचे विघटन करण्याचे तत्त्व वापरले जाते.
असे घटक म्हणून तीन प्राथमिक रंग वापरले जातात:
लाल (R)
हिरवा (G)
निळा (B)
या कोडींग प्रणालीला रंगांच्या नावांच्या पहिल्या अक्षरांनंतर RGB प्रणाली म्हणतात.
16-बिट बायनरी नंबर वापरून रंग ग्राफिक्स एन्कोडिंगला हाय कलर मोड म्हणतात. आणि २४ बायनरी बिट्स वापरून कलर ग्राफिक्स दाखवण्याच्या मोडला कलर बाय कलर (………) म्हणतात.

