24.07.2019
Teksta informācijas kodēšana. Kāpēc binārā kodēšana ir universāla? Programmēšanas metodes
Izdomāsim, kā tas viss tiek darīts pārvērst tekstus ciparu kodā? Starp citu, mūsu vietnē jūs varat pārvērst jebkuru tekstu decimālajā, heksadecimālajā, binārajā kodā, izmantojot tiešsaistes kodu kalkulatoru.
Teksta kodējums.
Saskaņā ar datoru teoriju jebkurš teksts sastāv no atsevišķām rakstzīmēm. Šīs rakstzīmes ietver: burtus, ciparus, mazos pieturzīmes, speciālās rakstzīmes (“”, №, () utt.), tās ietver arī atstarpes starp vārdiem.
Nepieciešamā zināšanu bāze. Simbolu kopu, ar kuru es rakstu tekstu, sauc par ALFABĒTU.
Alfabētā ņemto simbolu skaits atspoguļo tā spēku.
Informācijas apjomu var noteikt pēc formulas: N = 2b
- N ir tāda pati jauda (daudzi simboli),
- b - bits (paņemtā simbola svars).
Alfabēts, kurā ir 256, var saturēt gandrīz visas nepieciešamās rakstzīmes. Šādus alfabētus sauc par PIETIEK.
Ja ņemam alfabētu ar ietilpību 256, un paturam prātā, ka 256 = 28
- 8 biti vienmēr tiek saukti par 1 baitu:
- 1 baits = 8 biti.
Ja jūs pārvēršat katru rakstzīmi binārā kodā, šis datora teksta kods aizņems 1 baitu.
Kā teksta informācija var izskatīties datora atmiņā?
Jebkurš teksts tiek rakstīts uz tastatūras, uz tastatūras taustiņiem, mēs redzam mums pazīstamās zīmes (ciparus, burtus utt.). Tie ievada datora operatīvo atmiņu tikai binārā koda veidā. Katras rakstzīmes binārais kods izskatās kā astoņciparu skaitlis, piemēram, 00111111.
Tā kā baits ir mazākā adresējamā atmiņas daļa un atmiņa tiek adresēta katrai rakstzīmei atsevišķi, šādas kodēšanas ērtības ir acīmredzamas. Tomēr 256 rakstzīmes ir ļoti ērts apjoms jebkurai simboliskai informācijai.
Protams, radās jautājums: kurš no tiem konkrēti? astoņu ciparu kods pieder katram tēlam? Un kā pārvērst tekstu ciparu kodā?
Šis process ir nosacīts, un mums ir tiesības nākt klajā ar dažādiem rakstzīmju kodēšanas veidi. Katrai alfabēta rakstzīmei ir savs cipars no 0 līdz 255. Un katram ciparam tiek piešķirts kods no 00000000 līdz 11111111.
Kodēšanas tabula ir “krāpšanās lapa”, kurā alfabēta rakstzīmes ir norādītas atbilstoši sērijas numuram. Dažādu veidu datoros tiek izmantotas dažādas kodēšanas tabulas.
ASCII (vai Asci) ir kļuvis par starptautisku standartu personālajiem datoriem. Tabulai ir divas daļas.
Pirmā puse paredzēta ASCII tabulai. (Tas bija pirmais puslaiks, kas kļuva par standartu.)
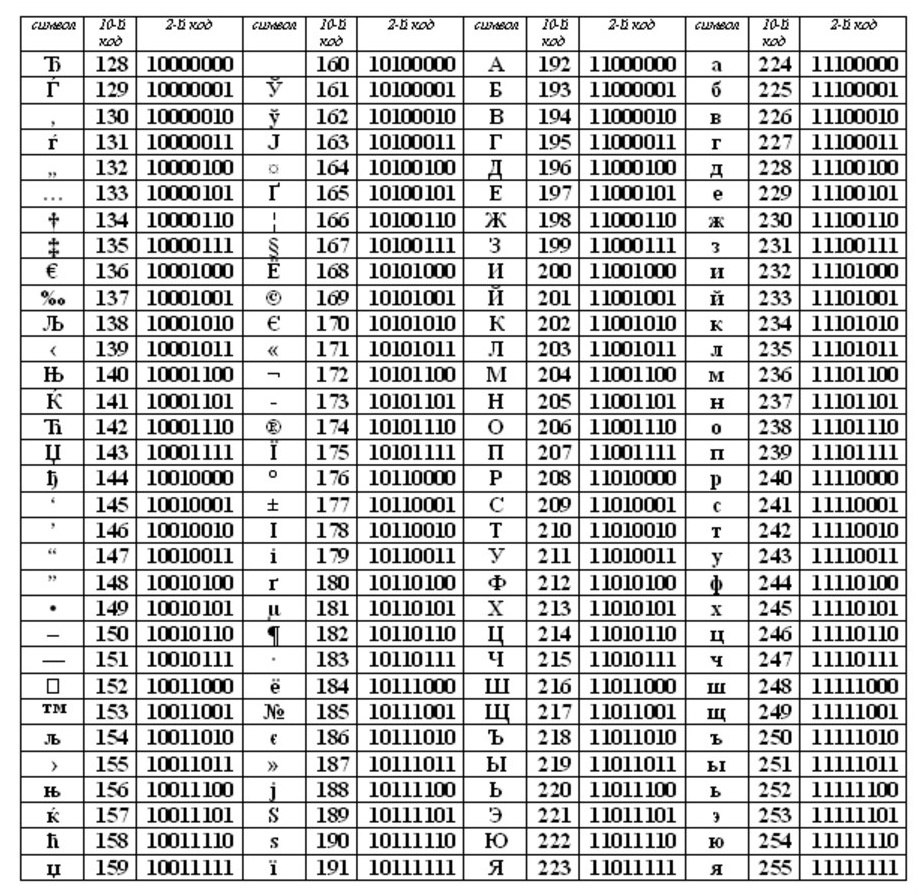
Atbilstība leksikogrāfiskajai secībai, tas ir, tabulā burti (mazie un lielie burti) ir norādīti stingrā alfabētiskā secībā, un cipari ir augošā secībā, tiek saukta par alfabēta secīgās kodēšanas principu.
Krievu alfabētam tie arī seko secīgās kodēšanas princips.
Mūsdienās, mūsu laikos, viņi izmanto veselu piecas kodēšanas sistēmas Krievu alfabēts (KOI8-R, Windows. MS-DOS, Macintosh un ISO). Kodēšanas sistēmu skaita un viena standarta trūkuma dēļ ļoti bieži rodas pārpratumi ar krievu valodas teksta pārsūtīšanu datorformā.
Viens no pirmajiem Krievu alfabēta kodēšanas standarti un personālajos datoros viņi uzskata KOI8 (“Informācijas apmaiņas kods, 8 biti”). Šis kodējums tika izmantots septiņdesmito gadu vidū ES datoru sērijā, un no astoņdesmito gadu vidus to sāka izmantot pirmajās UNIX operētājsistēmās, kas tika tulkotas krievu valodā.
Kopš deviņdesmito gadu sākuma, tā sauktā laika, kad dominēja MS DOS operētājsistēma, ir parādījusies kodēšanas sistēma CP866 ("CP" nozīmē "Code Page").
Milzu datoru uzņēmumi APPLE ar savu novatorisko sistēmu, kurā viņi strādāja (Mac OS), sāk izmantot savu sistēmu MAC alfabēta kodēšanai.
Starptautiskā standartu organizācija (ISO) nosaka citu standartu krievu valodai alfabēta kodēšanas sistēma, ko sauc par ISO 8859-5.
Un mūsdienās visizplatītākā alfabēta kodēšanas sistēma tika izgudrota operētājsistēmā Microsoft Windows, un to sauc par CP1251.
Kopš deviņdesmito gadu otrās puses, standarta problēma teksta tulkošanai ciparu kodā krievu valodā un ne tikai tika atrisināta, standartā ieviešot sistēmu ar nosaukumu Unicode. To attēlo sešpadsmit bitu kodējums, kas nozīmē, ka katrai rakstzīmei tiek piešķirti tieši divi baiti brīvpiekļuves atmiņa. Protams, ar šo kodējumu atmiņas izmaksas tiek dubultotas. Taču šāda kodu sistēma ļauj līdz pat 65 536 rakstzīmēm pārveidot elektroniskā kodā.
Standarta Unicode sistēmas specifika ir absolūti jebkura alfabēta iekļaušana neatkarīgi no tā, vai tas ir esošs, izmiris vai izgudrots. Galu galā, absolūti jebkurš alfabēts, papildus tam Unicode sistēma ietver daudz matemātisko, ķīmisko, muzikālo un vispārīgo simbolu.
Izmantosim ASCII tabulu, lai redzētu, kā vārds varētu izskatīties jūsu datora atmiņā.
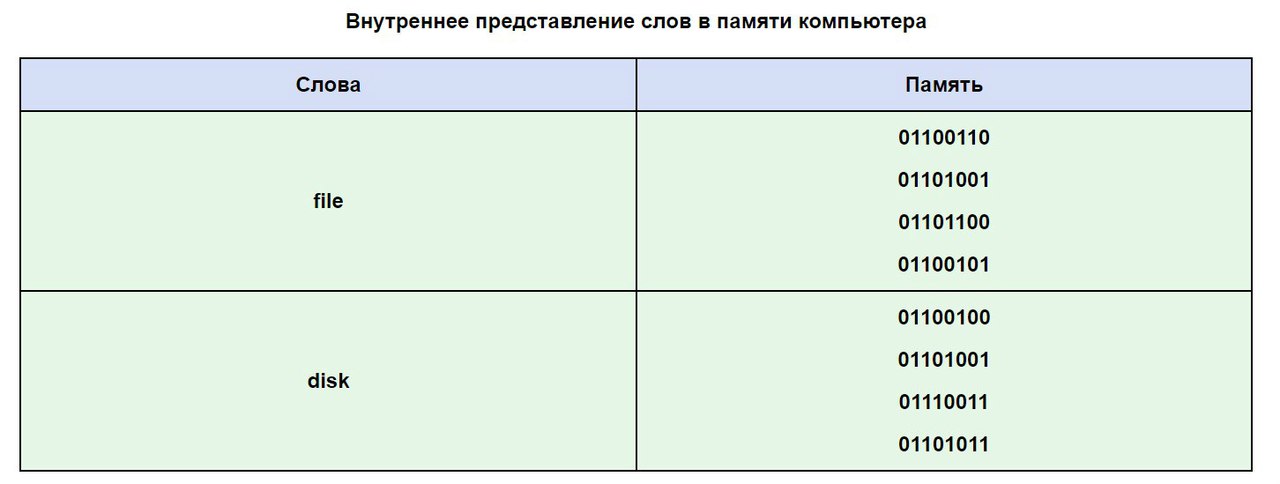
Bieži gadās, ka jūsu teksts, kas rakstīts ar krievu alfabēta burtiem, nav lasāms, tas ir saistīts ar alfabēta kodēšanas sistēmu atšķirībām datoros. Šī ir ļoti izplatīta problēma, kas tiek konstatēta diezgan bieži.
Minimālās informācijas vienības ir biti un baiti.
Viens bits ļauj kodēt 2 vērtības (0 vai 1).
Izmantojot divi bitu, var kodēt 4 vērtības: 00, 01, 10, 11.
Trīs biti ir kodēti 8 dažādas vērtības: 000, 001, 010, 011, 100, 101, 110, 111.
No iepriekš minētajiem piemēriem var redzēt, ka, pievienojot vienu bitu, divkāršojas vērtību skaits, ko var kodēt:
1 bits kodē -> 2 dažādas vērtības (2 1 = 2),
2 bitu kodēšana —> 4 dažādas vērtības (2 2 = 4)
3 bitu kodēšana —> 8 dažādas vērtības (2 3 = 8)
4 bitu kodēšana -> 16 dažādas vērtības (2 4 = 16)
5 bitu kodēšana —> 32 dažādas vērtības (2 5 = 32)
6 bitu kodēšana -> 64 dažādas vērtības (2 6 = 64)
7 bitu kodēšana —> 128 dažādas vērtības (2 7 = 128)
8 bitu kodēšana -> 256 dažādas vērtības (2 8 = 256)
9 bitu kodēšana -> 512 dažādas vērtības (2 9 = 512)
10 bitu kodēšana -> 1024 dažādas vērtības (2 10 = 1024).
Mēs atceramies, ka vienā baitā ir nevis 9 vai 10 biti, bet tikai 8. Tāpēc, izmantojot vienu baitu, var iekodēt 256 dažādas rakstzīmes. Vai jūs domājat, ka tas ir daudz vai maz? Apskatīsim kodēšanas piemēru teksta informācija.
Krievu valodā ir 33 burti, tāpēc to kodēšanai ir nepieciešami 33 baiti. Dators atšķir lielos (lielos) un mazos (mazos) burtus tikai tad, ja tie ir kodēti dažādos kodos. Tas nozīmē, ka, lai kodētu lielos un mazos krievu alfabēta burtus, ir nepieciešami 66 baiti.
Lieliem un maziem angļu alfabēta burtiem būs nepieciešami vēl 52 baiti. Rezultāts ir 66 + 52 = 118 baiti. Šeit jums jāpievieno arī cipari (no 0 līdz 9), atstarpes simbols, visas pieturzīmes: punkts, komats, domuzīme, izsaukuma un jautājuma zīmes, iekavas: apaļas, cirtainas un kvadrātveida, kā arī matemātisko darbību simboli: + , –, =, / (tas ir dalīšana), * (tas ir reizināšana). Pievienosim arī speciālās rakstzīmes: %, $, &, @, #, Nr. utt. Tas viss kopā ir aptuveni 256 dažādas rakstzīmes.
Un tad atliek maz ko darīt. Ir jāpārliecinās, ka visi cilvēki uz Zemes savā starpā vienojas, kādus kodus (no 0 līdz 255, t.i., kopā 256) piešķirt simboliem. Pieņemsim, ka visi cilvēki vienojās, ka kods 33 nozīmē izsaukuma zīmi (!), bet kods 63 nozīmē jautājuma zīmi (?). Un tas pats attiecas uz visiem izmantotajiem simboliem. Tas nozīmētu, ka viena persona savā datorā ierakstīto tekstu vienmēr var lasīt un izdrukāt cita persona citā datorā.
ASCII tabula
Tādu vispārēju vienošanos par kaut kā vienādu izmantošanu sauc standarta. Mūsu gadījumā standartam jābūt tabulai, kas reģistrē kodu (no 0 līdz 255) un simbolu atbilstību. Tādu tabulu sauc kodēšanas tabula.
Bet tas nav tik vienkārši. Galu galā simboli, kas ir labi, piemēram, Grieķijai, nav piemēroti Turcijai, jo tur tiek izmantoti citi burti. Tāpat tas, kas ir labs ASV, nav labs Krievijai, un tas, kas ir labs Krievijai, nav labs Vācijai.
Tāpēc mēs nolēmām sadalīt kodu tabulu uz pusēm.
Pirmajiem 128 kodiem (no 0 līdz 127) jābūt standarta un obligātiem visās valstīs un visiem datoriem, tie ir: starptautiskā standarta.
Un, izmantojot kodu tabulas otro pusi (no 128 līdz 255), katra valsts var darīt visu, ko vēlas, un šajā pusē izveidot savu standartu - Valsts.
Tiek izsaukta pirmā (starptautiskā) kodu tabulas puse tabulaASCII, kas tika radīts ASV un pieņemts visā pasaulē. ASCII standarts nav atbildīgs par kodu tabulas otro pusi. Šeit dažādas valstis izveido savas valsts kodu tabulas. Var arī būt, ka vienas valsts ietvaros dažādām datorsistēmām ir paredzēti dažādi standarti, bet tikai kodu tabulas otrajā pusē.
Kodi no starptautiskās ASCII tabulas
0-31 – speciālās rakstzīmes, kuras netiek drukātas uz ekrāna vai printera, bet tiek izmantotas, lai veiktu īpašas darbības (piemēram, lai “atgrieztu karieti” - pārvietotu tekstu uz jaunu rindiņu, vai “cilnei” - kursora novietošanai īpašas pozīcijas teksta rindiņā utt.).
32 – atstarpe (atdalītājs starp vārdiem ir arī kodējamā rakstzīme, lai gan tas tiek parādīts kā “tukša atstarpe” starp vārdiem un rakstzīmēm),
33-47 – speciālās rakstzīmes (iekavas utt.) un pieturzīmes (punkts, komats utt.),
48-57 - skaitļi no 0 līdz 9,
58-64 – matemātiskie simboli (plus (+), mīnus (-), reizināšana (*), dalīt (/) u.c.) un pieturzīmes (kols, semikols utt.),
65-90 — lielie (mazie) angļu burti,
91-96 – speciālās rakstzīmes (kvadrātiekavas utt.),
97-122 — mazie (mazie) angļu burti,
123-127 – speciālās rakstzīmes (cirtaini breketes utt.).
Ārpus ASCII tabulas, sākot no cipariem 128 līdz 159, ir lielie (lielie) krievu burti, un no 160 līdz 170 un no 224 līdz 239 ir mazie (mazie) krievu burti.
Vārda PASAULE kodējums
Izmantojot parādīto kodējumu, varam iedomāties, kā dators kodē un pēc tam atveido, piemēram, vārdu PASAULE (ar lielajiem burtiem). Šo vārdu apzīmē trīs kodi: burts M atbilst kodam 140 (saskaņā ar nacionālo Krievijas kodēšanas sistēmu), I ir kods 136 un P ir 144.
Bet, kā jau minēts iepriekš, dators informāciju uztver tikai binārā formā, t.i. kā nulles un vieninieku secība. Katrs baits, kas atbilst katram vārda PASAULE burtam, satur astoņu nulles un vieninieku secību. Izmantojot noteikumus decimālās informācijas pārvēršanai binārā, varat aizstāt burtu kodu decimālvērtības ar to binārajiem ekvivalentiem.
Decimālais cipars 140 atbilst binārajam skaitlim 10001100. To var pārbaudīt, veicot šādus aprēķinus: 2 7 + 2 3 +2 2 = 140. Jauda, līdz kurai tiek palielināts katrs “2”, ir binārā skaitļa pozīcijas numurs. 10001100, kurā ir “1”, un pozīcijas tiek numurētas no labās puses uz kreiso, sākot no nulles pozīcijas numura: 0, 1, 2 utt.
Vairāk par skaitļu pārveidošanu no vienas skaitļu sistēmas citā varat uzzināt, piemēram, no datorzinātņu mācību grāmatām vai izmantojot internetu.
Līdzīgā veidā varat pārbaudīt, vai skaitlis 136 atbilst binārajam skaitlim 10001000 (pārbaudiet: 2 7 + 2 3 = 136). Un skaitlis 144 atbilst binārajam skaitlim 10010000 (pārbaudiet: 2 7 + 2 4 = 144).
Tādējādi vārds PASAULE datorā tiks saglabāts šādā nulles un vieninieku (bitu) secībā: 10001100 10001000 10010000.
Protams, visas iepriekš redzamās datu konvertēšanas tiek veiktas, izmantojot datorprogrammas, un tās lietotājiem nav redzamas. Viņi tikai novēro šo programmu darba rezultātus, gan ievadot informāciju, izmantojot tastatūru, gan parādot to monitora ekrānā vai printerī.
Jāpiebilst, ka datorprasmes līmenī datorlietotājiem nav jāzina bināro skaitļu sistēma. Pietiek ar izpratni par decimālzīmju kodiem. Tikai sistēmu programmētāji praksē izmanto binārās, heksadecimālās, oktālās un citas skaitļu sistēmas. Tas viņiem ir īpaši svarīgi, ja datori rada programmatūras kļūdu ziņojumus, kas norāda uz kļūdainām vērtībām, nepārvēršot decimāldaļās.
Datorpratības vingrinājumi, ļaujot jums patstāvīgi redzēt un sajust aprakstītās kodēšanas sistēmas ir sniegtas rakstā
P.S. Raksts ir beidzies, bet jūs joprojām varat lasīt:
P.P.S. Uz abonējiet, lai saņemtu jaunus rakstus, kas vēl nav emuārā:
1) Šajā veidlapā ievadiet savu e-pasta adresi.
Teksta informācijas binārā kodēšana
Kopš 60. gadu beigām datori arvien vairāk tiek izmantoti teksta informācijas apstrādei, un šobrīd lielākā daļa pasaules personālo datoru (un lielāko daļu laika) nodarbojas ar teksta informācijas apstrādi.
Tradicionāli vienas rakstzīmes kodēšanai tiek izmantots informācijas apjoms, kas vienāds ar 1 baitu, tas ir, I = 1 baits = 8 biti.
Lai kodētu vienu rakstzīmi, ir nepieciešams 1 baits informācijas.
Ja par iespējamiem notikumiem uzskatām simbolus, tad izmantojot formulu (2.1) varam aprēķināt, cik dažādus simbolus var iekodēt:
N = 2 I = 2 8 = 256.
Šis rakstzīmju skaits ir pilnīgi pietiekams, lai attēlotu teksta informāciju, ieskaitot krievu un latīņu alfabēta lielos un mazos burtus, ciparus, zīmes, grafiskos simbolus utt.
Kodēšana sastāv no tā, ka katrai rakstzīmei tiek piešķirts unikāls decimālais kods no 0 līdz 255 vai atbilstošs binārs kods no 00000000 līdz 11111111. Tādējādi cilvēks atšķir rakstzīmes pēc to dizaina, bet dators pēc to kodiem.
Kad teksta informācija tiek ievadīta datorā, tā tiek bināri kodēta; simbola attēls tiek pārveidots tā binārajā kodā. Lietotājs uz tastatūras nospiež taustiņu ar simbolu, un uz datoru tiek nosūtīta noteikta astoņu elektrisko impulsu secība (simbola binārais kods). Rakstzīmju kods tiek saglabāts datora operatīvajā atmiņā, kur tas aizņem vienu baitu.
Simbola parādīšanas procesā datora ekrānā tiek veikts apgrieztais process - dekodēšana, tas ir, simbola koda pārvēršana tā attēlā.
Būtiski, ka konkrēta koda piešķiršana simbolam ir vienošanās jautājums, kas tiek ierakstīts kodu tabulā. Pirmie 33 kodi (no 0 līdz 32) atbilst nevis rakstzīmēm, bet operācijām (rindas padeve, atstarpes ievadīšana utt.).
Kodi no 33 līdz 127 ir starptautiski un atbilst latīņu alfabēta rakstzīmēm, cipariem, aritmētiskajiem simboliem un pieturzīmēm.
Kodi no 128 līdz 255 ir nacionāli, tas ir, nacionālajos kodējumos vienam un tam pašam kodam atbilst dažādas rakstzīmes. Diemžēl pašlaik ir piecas dažādas krievu burtu kodēšanas tabulas (KOI8, SR1251, SR866, Mac, ISO - 1.3. tabula), tāpēc vienā kodējumā izveidotie teksti netiks pareizi parādīti citā.
Šobrīd plaši izplatījies jaunais starptautiskais standarts Unicode, kas katrai rakstzīmei atvēl nevis vienu baitu, bet divus, tāpēc ar to var kodēt nevis 256 rakstzīmes, bet gan N = 216 = = 65536 dažādas rakstzīmes. Šo kodējumu atbalsta jaunākās Microsoft Windows un Office platformas versijas (kopš 1997. gada).
Katrs kodējums ir norādīts savā kodu tabulā. Kā redzams no tabulas. 1.3, vienam un tam pašam binārajam kodam dažādos kodējumos tiek piešķirti dažādi simboli.
Piemēram, ciparu kodu 221, 194, 204 secība CP1251 kodējumā veido vārdu "dators", savukārt citos kodējumos tā būs bezjēdzīga rakstzīmju kopa.
Par laimi, vairumā gadījumu lietotājam nav jāuztraucas par teksta dokumentu pārkodēšanu, jo to veic īpašas lietojumprogrammās iebūvētas pārveidotāju programmas.
Rakstzīmes ciparu koda noteikšana
1. Palaidiet teksta redaktoru MS Word 2002. Ievadiet komandu [Insert-Symbol...]. Ekrānā parādīsies dialoglodziņš Simbols. Dialoglodziņa centrālo daļu aizņem noteikta fonta rakstzīmju tabula (piemēram, Times New Roman).
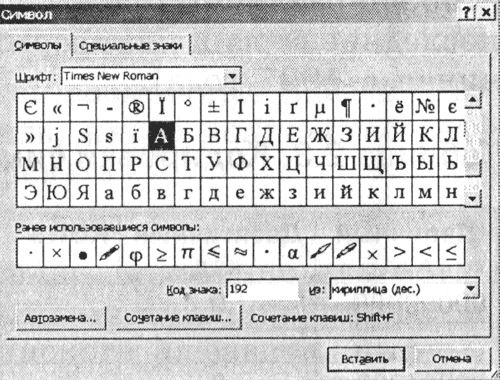 |
Rakstzīmes ir sakārtotas secīgi no kreisās puses uz labo un rindiņu pa rindiņai, sākot ar rakstzīmi Kosmoss augšējā kreisajā stūrī un beidzas ar burtu "I" tabulas apakšējā labajā stūrī.
Nolaižamajā sarakstā atlasiet simbolu no: kodēšanas veids. Teksta laukā Parakstīšanas kods: parādīsies tā ciparu kods.
Rakstzīmju ievadīšana ar ciparu kodu
1. Palaidiet standarta programmu Piezīmju grāmatiņa. Izmantojot papildu ciparu tastatūru, turot nospiestu taustiņu Alt, ievadiet numuru 0224 un atlaidiet taustiņu Alt. Dokumentā parādīsies simbols "a". Atkārtojiet procedūru ciparu kodiem no 0225 līdz 0233. Dokumentā tiks parādīta 12 “abvgdezhy” rakstzīmju secība Windows kodējumā (CP1251).
2. Izmantojot papildu ciparu tastatūru, vienlaikus nospiežot taustiņu (Alt), ievadiet skaitli 224; dokumentā parādīsies simbols “p”. Atkārtojiet procedūru ciparu kodiem no 225 līdz 233, dokumentā parādīsies 12 rakstzīmju secība “rstufhtchshshch” MS-DOS (CP866) kodējumā.
 |
Praktiski uzdevumi
1.29. Izmantojot rakstzīmju tabulu (MS Word), pierakstiet decimālo ciparu kodu secību Windows kodējumā (CP1251) vārdam "dators".
1.30. Izmantojot Notepad, nosakiet, kurš vārds Windows kodējumā (CP1251) ir norādīts ar ciparu kodu secību: 225, 224, 233,242.
1.31. Kādas burtu secības KOI8 un ISO kodējumos atbildīs vārdam “dators”, kas rakstīts CP1251 kodējumā?
Dators apstrādā liels skaits informāciju. Audio faili, attēli, teksti - tas viss ir jāatskaņo vai jāparāda ekrānā. Kāpēc binārā kodēšana ir universāla jebkura tehniskā aprīkojuma informācijas programmēšanas metode?
Kāda ir atšķirība starp kodēšanu un šifrēšanu?
Bieži vien cilvēki pielīdzina jēdzienus “kodēšana” un “šifrēšana”, lai gan patiesībā tiem ir atšķirīga nozīme. Tādējādi šifrēšana ir informācijas pārveidošanas process, lai to paslēptu. Persona, kas mainīja tekstu, vai īpaši apmācīti cilvēki bieži var to atšifrēt. Kodēšana tiek izmantota, lai apstrādātu informāciju un vienkāršotu darbu ar to. Parasti tiek izmantota kopēja kodēšanas tabula, kas ir pazīstama visiem. Tas ir iebūvēts datorā.
Binārās kodēšanas princips
Binārā kodēšana pamatā ir tikai divu rakstzīmju — 0 un 1 — izmantošana, lai apstrādātu informāciju, ko izmanto dažādas ierīces. Šīs zīmes sauca par binārajiem cipariem, angļu valodā - binary digit jeb bitu. Katra rakstzīme aizņem 1 bitu datora atmiņas. Kāpēc binārā kodēšana ir universāla informācijas apstrādes metode? Fakts ir tāds, ka datoram ir vieglāk apstrādāt mazāk rakstzīmju. No tā ir tieši atkarīga datora produktivitāte: jo mazāk funkcionālo uzdevumu ierīcei jāveic, jo lielāks ir darba ātrums un kvalitāte. 
Binārās kodēšanas princips ir atrodams ne tikai programmēšanā. Mainot blāvus un skanīgus bungu sitienus, Polinēzijas iedzīvotāji viens otram pārraidīja informāciju. Līdzīgs princips attiecas arī uz gadījumiem, kad ziņojuma nodošanai tiek izmantotas garas un īsas skaņas. "Telegrāfa alfabēts" tiek izmantots arī mūsdienās.
Kur tiek izmantota binārā kodēšana?
Datoros visur tiek izmantots binārs. Katrs fails, neatkarīgi no tā, vai tā ir mūzika vai teksts, ir jāieprogrammē tā, lai to vēlāk varētu viegli apstrādāt un lasīt. Binārā kodēšanas sistēma ir noderīga darbam ar simboliem un cipariem, audio failiem un grafiku.
Binārā skaitļu kodēšana
Tagad datoros skaitļi tiek parādīti kodētā formā, kas nav saprotama vidusmēra cilvēkam. Arābu ciparu izmantošana tādā veidā, kā mēs iedomājamies, tehnoloģijai ir neracionāla. Iemesls tam ir nepieciešamība piešķirt katram numuram savu unikālo simbolu, ko dažreiz nav iespējams izdarīt.

Ir divas skaitļu sistēmas: pozicionālā un nepozicionālā. Nepozicionālā sistēma ir balstīta uz izmantošanu Latīņu burti un mums ir pazīstama formā Šī ierakstīšanas metode ir diezgan grūti saprotama, tāpēc tā tika pamesta.
Pozicionālo skaitļu sistēma tiek izmantota arī mūsdienās. Tas ietver informācijas bināro, decimālo, oktālo un pat heksadecimālo kodējumu.
Ikdienā izmantojam decimālo kodēšanas sistēmu. Tie mums ir pazīstami un saprotami ikvienam. Ciparu binārā kodēšana atšķiras ar tikai nulles un viena izmantošanu.
Veseli skaitļi tiek pārvērsti binārajā kodēšanas sistēmā, dalot tos ar 2. Iegūtos koeficientus arī pakāpeniski dala ar 2, līdz rezultāts ir 0 vai 1. Piemēram, skaitlis 123 10 in binārā sistēma var attēlot kā 1111011 2. Un skaitlis 20 10 izskatīsies kā 10100 2.
Indeksi 10 un 2 apzīmē attiecīgi decimālo un bināro skaitļu kodēšanas sistēmas. Binārās kodēšanas simbols tiek izmantots, lai atvieglotu darbu ar vērtībām, kas attēlotas dažādās skaitļu sistēmās.
Decimālās programmēšanas metodes ir balstītas uz peldošo komatu. Lai pareizi pārvērstu vērtību no decimālskaitļa uz bināro kodēšanas sistēmu, izmantojiet formulu N = M x qp. M ir mantisa (skaitļa izteiksme bez jebkādas secības), p ir vērtības N secība un q ir kodēšanas sistēmas bāze (mūsu gadījumā 2).
Ne visi skaitļi ir pozitīvi. Lai atšķirtu pozitīvos un negatīvos skaitļus, dators atstāj 1 bitu vietas zīmes kodēšanai. Šeit nulle apzīmē plus zīmi un viens apzīmē mīnus zīmi.
Izmantojot šo skaitļu sistēmu, datoram ir vieglāk strādāt ar cipariem. Tāpēc binārā kodēšana ir universāla skaitļošanas procesos.

Teksta informācijas binārā kodēšana
Katra alfabēta rakstzīme ir kodēta ar savu nulles un vieninieku kopu. Tekstu veido dažādas rakstzīmes: burti (lielie un mazie), aritmētiskie simboli un citas dažādas nozīmes. Teksta informācijas kodēšanai ir jāizmanto 8 secīgas bināras vērtības no 00000000 līdz 11111111. Šādā veidā var konvertēt 256 dažādas rakstzīmes.
Lai izvairītos no neskaidrībām teksta kodēšanā, katrai rakstzīmei tiek izmantotas īpašas vērtību tabulas. Tie satur latīņu alfabētu, aritmētiskās zīmes un īpašas nozīmes zīmes (piemēram, €, ¥ un citas). Rakstzīmes diapazonā no 128 līdz 255 kodē valsts nacionālo alfabētu.
Lai kodētu 1 rakstzīmi, ir nepieciešami 8 biti atmiņas. Lai vienkāršotu aprēķinus, 8 biti ir vienādi ar 1 baitu, tāpēc kopējā diska vieta teksta informācijai tiek mērīta baitos.

Lielākā daļa personālo datoru ir aprīkoti ar standarta galdu ASCII kodējumi(Amerikas standarta informācijas apmaiņas kods). Tiek izmantotas arī citas tabulas, kurās teksta informācijas kodēšanas sistēma ir atšķirīga. Piemēram, pirmo zināmo rakstzīmju kodējumu sauc par KOI-8 (8 bitu informācijas apmaiņas kods), un tas darbojas datoros ar UNIX OS. Plaši atrodama arī CP1251 kodu tabula, kas tika izveidota operētājsistēma Windows.
Skaņu binārā kodēšana
Vēl viens iemesls, kāpēc binārais kodējums ir universāla informācijas programmēšanas metode, ir tā vienkāršība, strādājot ar audio failiem. Jebkura mūzika sastāv no dažādas amplitūdas un vibrācijas frekvences skaņas viļņiem. Skaņas skaļums un tā augstums ir atkarīgs no šiem parametriem.
Lai ieprogrammētu skaņas vilni, dators to sadala vairākās daļās jeb “paraugos”. Šādu paraugu skaits var būt liels, tāpēc ir 65536 dažādas nulles un vieninieku kombinācijas. Attiecīgi mūsdienu datori ir aprīkoti ar 16 bitu skaņas kartēm, kas nozīmē, ka viena audio viļņa parauga kodēšanai tiek izmantoti 16 binārie cipari.
Lai atskaņotu audio failu, dators apstrādā ieprogrammētas binārā koda secības un apvieno tās vienā nepārtrauktā vilnī. 
Grafikas kodēšana
Grafisko informāciju var attēlot zīmējumu, diagrammu, attēlu vai PowerPoint slaidu veidā. Jebkurš attēls sastāv no maziem punktiem - pikseļiem, kurus var krāsot dažādās krāsās. Katra pikseļa krāsa tiek kodēta un saglabāta, un beigās mēs iegūstam pilnu attēlu.
Ja attēls ir melnbalts, katra pikseļa kods var būt vai nu viens, vai nulle. Ja tiek izmantotas 4 krāsas, tad katras no tām kods sastāv no diviem cipariem: 00, 01, 10 vai 11. Pamatojoties uz šo principu, tiek izdalīta jebkura attēla apstrādes kvalitāte. Spilgtuma palielināšana vai samazināšana ietekmē arī izmantoto krāsu skaitu. IN labākais scenārijs dators izšķir aptuveni 16 777 216 toņus.

Secinājums
Ir dažādas informācijas programmēšanas metodes, starp kurām visefektīvākā ir binārā kodēšana. Izmantojot tikai divas rakstzīmes — 1 un 0, dators var viegli nolasīt lielāko daļu failu. Tajā pašā laikā apstrādes ātrums ir daudz lielāks nekā tad, ja, piemēram, tiktu izmantota decimālā programmēšanas sistēma. Šīs metodes vienkāršība padara to par neaizstājamu jebkurai tehnikai. Tāpēc binārā kodēšana ir universāla starp tā kolēģiem.
Ikviens zina, ka datori var veikt aprēķinus lielām datu grupām ar milzīgu ātrumu. Bet ne visi zina, ka šīs darbības ir atkarīgas tikai no diviem nosacījumiem: vai ir strāva vai nav un kāds spriegums.
Kā datoram izdodas apstrādāt tik daudzveidīgu informāciju?
Noslēpums slēpjas binārajā skaitļu sistēmā. Datorā tiek ievadīti visi dati, kas tiek parādīti vieninieku un nulles formā, no kuriem katrs atbilst vienam elektrības vada stāvoklim: vieninieki - augsts spriegums, nulles - zems vai vieninieki - sprieguma esamība, nulles - tā neesamība. Datu konvertēšanu uz nullēm un vieniniekiem sauc par bināro konvertēšanu, un tā galīgo apzīmējumu sauc par bināro kodu.
Decimālajā pierakstā, pamatojoties uz ikdienā lietoto decimālo skaitļu sistēmu, skaitliskā vērtība tiek attēlota ar desmit cipariem no 0 līdz 9, un katrai skaitļa vietai ir desmitreiz lielāka vērtība nekā vietai pa labi no tā. Lai decimālajā sistēmā attēlotu skaitli, kas ir lielāks par deviņiem, tā vietā tiek ievietota nulle, bet nākamajā, vērtīgākā vietā pa kreisi, tiek ievietots viens. Tāpat binārajā sistēmā, kas izmanto tikai divus ciparus – 0 un 1, katra vieta ir divreiz vērtīgāka par vietu pa labi no tās. Tādējādi binārajā kodā tikai nulli un vienu var attēlot kā atsevišķus skaitļus, un jebkuram skaitlim, kas ir lielāks par vienu, ir nepieciešamas divas vietas. Pēc nulles un viena nākamie trīs binārie skaitļi ir 10 (lasīt viens-nulle) un 11 (lasīt viens-viens) un 100 (lasīt viens-nulle-nulle). 100 binārais ir līdzvērtīgs 4 decimāldaļām. Augšējā tabula labajā pusē parāda citus BCD ekvivalentus.
Jebkuru skaitli var izteikt bināros, tas tikai aizņem vairāk vietas nekā decimāldaļās. Alfabētu var rakstīt arī binārajā sistēmā, ja katram burtam ir piešķirts noteikts binārais numurs.
Divi cipari četrām vietām
Izmantojot tumšās un gaišās bumbiņas var izveidot 16 kombinācijas, apvienojot tās komplektos pa četrām Ja tumšās bumbiņas ņem par nullēm un gaišās par vieniniekus, tad 16 komplekti izrādīsies 16 vienību binārais kods, kura skaitliskā vērtība kas ir no nulles līdz pieciem (skatīt augšējo tabulu 27. lpp.). Pat ar divu veidu bumbām binārajā sistēmā var izveidot bezgalīgu skaitu kombināciju, vienkārši palielinot bumbiņu skaitu katrā grupā – vai vietu skaitu skaitļos.
Biti un baiti
Mazākā vienība datorapstrādē, bits ir datu vienība, kurai var būt viena no divām iespējamie apstākļi. Piemēram, katrs no vieniniekiem un nullēm (labajā pusē) apzīmē 1 bitu. Mazumu var attēlot citos veidos: elektriskās strāvas esamība vai neesamība, caurums vai tā neesamība, magnetizācijas virziens pa labi vai pa kreisi. Astoņi biti veido baitu. 256 iespējamie baiti var attēlot 256 rakstzīmes un simbolus. Daudzi datori vienlaikus apstrādā vienu datu baitu.
Binārā konvertēšana. Četru ciparu binārais kods var attēlot decimālskaitļus no 0 līdz 15.
Kodu tabulas
Ja bināro kodu izmanto, lai attēlotu alfabēta burtus vai pieturzīmes, ir nepieciešamas kodu tabulas, kas norāda, kurš kods atbilst kādai rakstzīmei. Ir apkopoti vairāki šādi kodi. Lielākā daļa datoru ir konfigurēti ar septiņu ciparu kodu, ko sauc par ASCII jeb Amerikas standarta informācijas apmaiņas kodu. Labajā pusē redzamā tabula ASCII kodi angļu alfabētam. Citi kodi ir paredzēti tūkstošiem citu pasaules valodu rakstzīmju un alfabētu.

Daļa no ASCII kodu tabulas

