29.01.2019
მონაცემთა ორობითი კოდირება. მონაცემთა კოდირება
სხვადასხვა ტიპის მონაცემებთან მუშაობის ავტომატიზაციისთვის, ძალიან მნიშვნელოვანია მათი პრეზენტაციის ფორმის გაერთიანება - ეს ჩვეულებრივ კეთდება ტექნიკის გამოყენებით. კოდირება,ანუ ერთი ტიპის მონაცემების გამოხატვა სხვა ტიპის მონაცემებით. ბუნებრივი ადამიანი ენები -ისინი სხვა არაფერია, თუ არა კონცეფციის კოდირების სისტემები აზრების მეტყველებით გამოხატვისთვის. ენები მჭიდრო კავშირშია ანბანი(ენის კომპონენტების დაშიფვრის სისტემები გრაფიკული სიმბოლოების გამოყენებით). ისტორიამ იცის საინტერესო, თუმცა წარუმატებელი მცდელობები შექმნას "უნივერსალური" ენები და ანბანები. როგორც ჩანს, მათი განხორციელების მცდელობების წარუმატებლობა განპირობებულია იმით, რომ ეროვნულ და სოციალურ ფორმირებებს ბუნებრივად ესმით, რომ საჯარო მონაცემების კოდირების სისტემის ცვლილება აუცილებლად გამოიწვევს საზოგადოებრივი მეთოდების შეცვლას (ანუ იურიდიული და მორალური ნორმები). და ეს შეიძლება დაკავშირებული იყოს სოციალურ აჯანყებასთან.
უნივერსალური კოდირების ინსტრუმენტის იგივე პრობლემა საკმაოდ წარმატებით არის დანერგილი ტექნოლოგიის, მეცნიერებისა და კულტურის გარკვეულ დარგებში. მაგალითებია მათემატიკური გამონათქვამების ჩაწერის სისტემა, ტელეგრაფის ანბანი, საზღვაო დროშის ანბანი, ბრაილის სისტემა უსინათლოთათვის და მრავალი სხვა.
კომპიუტერულ ტექნოლოგიასაც აქვს თავისი სისტემა – ე.წ ბინარული კოდირებადა ეფუძნება მონაცემთა წარმოდგენას მხოლოდ ორი სიმბოლოს თანმიმდევრობით: 0 და 1. ეს სიმბოლოები ე.წ. ორობითი ციფრები,ინგლისურად - ორობითი ციფრიან შემოკლებით მოხვდა (ბიტი).
ორი ცნება შეიძლება გამოისახოს ერთ ბიტში: 0 ან 1 (დიახან არა, შავიან თეთრი, მართალიაან ტყუილიდა ასე შემდეგ.). თუ ბიტების რაოდენობა ორამდე გაიზარდა, მაშინ უკვე შესაძლებელია ოთხი განსხვავებული ცნების გამოხატვა:
სამ ბიტს შეუძლია რვა განსხვავებული მნიშვნელობის დაშიფვრა:
000 001 010 011 100 101 110 111
სისტემაში ბიტების რაოდენობის გაზრდა ერთით ბინარული კოდირება, ჩვენ გავაორმაგებთ მნიშვნელობების რაოდენობას, რომელიც შეიძლება გამოისახოს ამ სისტემაში, ანუ ზოგადი ფორმულაროგორც ჩანს:
სად N-დამოუკიდებელი კოდირებული მნიშვნელობების რაოდენობა;
T -მოცემულ სისტემაში მიღებული ბინარული კოდირების ბიტის სიღრმე.
მთელი და რეალური რიცხვების კოდირება
მთელი რიცხვები დაშიფრულია ორობითი კოდისაკმარისად მარტივი - უბრალოდ აიღეთ მთელი რიცხვი და გაყავით იგი შუაზე, სანამ კოეფიციენტი არ იქნება ერთის ტოლი. ნაშთების სიმრავლე თითოეული გაყოფიდან, რომელიც იწერება მარჯვნიდან მარცხნივ ბოლო კოეფიციენტთან ერთად, ქმნის ათობითი რიცხვის ორობით ანალოგს.
ამრიგად, 19= 10011;.
0-დან 255-მდე მთელი რიცხვების დაშიფვრისთვის საკმარისია ორობითი კოდის 8 ბიტი (8 ბიტი). თექვსმეტი ბიტი საშუალებას გაძლევთ დაშიფვროთ მთელი რიცხვები 0-დან 65535-მდე, ხოლო 24 ბიტი - 16,5 მილიონზე მეტი სხვადასხვა მნიშვნელობის.
რეალური რიცხვები დაშიფრულია 80-ბიტიანი კოდირებით. ამ შემთხვევაში, რიცხვი პირველად გარდაიქმნება ნორმალიზებული ფორმა:
3,1415926 =0,31415926-10"
300 000 = 0,3 10 6
123 456 789 = 0,123456789 10 10
ნომრის პირველ ნაწილს ეძახიან მანტისადა მეორე - დამახასიათებელი. 80 ბიტიდან უმეტესი ნაწილი გამოყოფილია მანტისას შესანახად (ნიშანთან ერთად) და გარკვეული ფიქსირებული რაოდენობის ბიტი გამოიყოფა მახასიათებლის შესანახად (ასევე ხელმოწერილი).
ტექსტური მონაცემების კოდირება
თუ ანბანის თითოეული სიმბოლო ასოცირდება გარკვეულ მთელ რიცხვთან (მაგალითად, სერიულ ნომერთან), მაშინ ბინარული კოდის დახმარებით შესაძლებელია ტექსტური ინფორმაციის დაშიფვრაც. რვა ბიტი საკმარისია 256 სხვადასხვა სიმბოლოს დაშიფვრისთვის. ეს საკმარისია იმისათვის, რომ გამოვხატოთ რვა ბიტის სხვადასხვა კომბინაციით ინგლისური და რუსული ენების ყველა სიმბოლო, როგორც მცირე, ასევე დიდი, ასევე პუნქტუაციის ნიშნები, ძირითადი არითმეტიკული მოქმედებების სიმბოლოები და ზოგიერთი ზოგადად მიღებული სპეციალური სიმბოლო, როგორიცაა სიმბოლო "§ ".
ტექნიკურად, ეს ძალიან მარტივია, მაგრამ ყოველთვის იყო საკმაოდ მნიშვნელოვანი ორგანიზაციული სირთულეები. კომპიუტერული ტექნოლოგიების განვითარების ადრეულ წლებში ისინი დაკავშირებული იყო საჭირო სტანდარტების ნაკლებობასთან, ახლა კი ისინი გამოწვეულია, პირიქით, ერთდროულად მოქმედი და ურთიერთსაწინააღმდეგო სტანდარტების სიმრავლით. იმისთვის, რომ მთელმა მსოფლიომ ტექსტური მონაცემების ანალოგიურად დაშიფვრა, საჭიროა კოდირების ერთიანი ცხრილები და ეს ჯერ კიდევ შეუძლებელია ეროვნული ანბანის სიმბოლოებს შორის წინააღმდეგობებისა და კორპორატიული წინააღმდეგობების გამო.
ინგლისური ენისთვის, რომელმაც დე ფაქტო დაიპყრო კომუნიკაციის საერთაშორისო საშუალების ნიშა, წინააღმდეგობები უკვე მოიხსნა. შეერთებული შტატების სტანდარტების ინსტიტუტი (ANSI - ამერიკის ეროვნული სტანდარტების ინსტიტუტი)დანერგა კოდირების სისტემა ASCII (American Standard Code for Information Interchange - აშშ-ის სტანდარტული კოდი ინფორმაციის ურთიერთგაცვლისთვის).სისტემაში ASCIIდაფიქსირებულია კოდირების ორი ცხრილი - ძირითადიდა გაფართოებული.საბაზო ცხრილი აფიქსირებს კოდის მნიშვნელობებს 0-დან 127-მდე, ხოლო გაფართოებული ცხრილი ეხება სიმბოლოებს 128-დან 255-მდე რიცხვებით.
საბაზისო ცხრილის პირველი 32 კოდი, ნულიდან დაწყებული, გადაეცა ტექნიკის მწარმოებლებს (პირველ რიგში კომპიუტერების და საბეჭდი მოწყობილობების მწარმოებლებს). ეს ტერიტორია შეიცავს ე.წ კონტროლის კოდები,რომლებიც არ შეესაბამება ენის არცერთ სიმბოლოს და, შესაბამისად, ეს კოდები არ არის ნაჩვენები არც ეკრანზე და არც ბეჭდვის მოწყობილობებზე, მაგრამ მათი კონტროლი შესაძლებელია სხვა მონაცემების გამოტანით.
32 კოდიდან დაწყებული 127 კოდამდე, არსებობს ინგლისური ანბანის სიმბოლოების, პუნქტუაციის ნიშნების, რიცხვების, არითმეტიკული ოპერაციების და ზოგიერთი დამხმარე სიმბოლოს კოდები.
ტექსტის მონაცემთა კოდირების მსგავსი სისტემები შემუშავებულია სხვა ქვეყნებში. მაგალითად, სსრკ-ში, ამ სფეროში მოქმედებდა KOI-7 კოდირების სისტემა. (საკომუნიკაციო კოდი, შვიდი ციფრი).თუმცა, ტექნიკისა და პროგრამული უზრუნველყოფის მწარმოებლების მხარდაჭერამ მოიტანა ამერიკული კოდი ASCIIსაერთაშორისო სტანდარტის დონემდე, ხოლო კოდირების ეროვნულ სისტემებს მოუწიათ "უკან დახევა" კოდირების სისტემის მეორე, გაფართოებულ ნაწილზე, რომელიც განსაზღვრავს კოდების მნიშვნელობებს 128-დან 255-მდე. ერთიანი სტანდარტის არარსებობა ამ ზონამ გამოიწვია ერთდროულად მოქმედი კოდირების სიმრავლე. მხოლოდ რუსეთში შეგიძლიათ მიუთითოთ სამი მიმდინარე კოდირების სტანდარტი და კიდევ ორი მოძველებული.
მაგალითად, რუსული ენის სიმბოლოების კოდირება, რომელიც ცნობილია როგორც კოდირება Windows-1251,დაინერგა "გარედან" - Microsoft-ის მიერ, მაგრამ, იმის გათვალისწინებით, რომ ოპერაციული სისტემები და ამ კომპანიის სხვა პროდუქტები ფართოდ გამოიყენება რუსეთში, იგი ღრმად არის ფესვგადგმული და ფართოდ გამოიყენება. ეს კოდირება გამოიყენება უმეტეს ლოკალურ კომპიუტერებზე, რომლებიც მუშაობენ Windows პლატფორმაზე.
კიდევ ერთი გავრცელებული კოდირება ეწოდება KOI-8 (საკომუნიკაციო კოდი, რვა ციფრი) -მისი წარმოშობა თარიღდება აღმოსავლეთ ევროპის სახელმწიფოთა ურთიერთეკონომიკური დახმარების საბჭოს დროიდან. დღეს KOI-8 კოდირება ფართოდ გამოიყენება კომპიუტერულ ქსელებში რუსეთში და ინტერნეტის რუსულ სექტორში.
საერთაშორისო სტანდარტს, რომელიც ითვალისწინებს რუსული ანბანის სიმბოლოების დაშიფვრას, კოდირება ეწოდება ISO (საერთაშორისო სტანდარტების ორგანიზაცია - სტანდარტიზაციის საერთაშორისო ინსტიტუტი).პრაქტიკაში, ეს კოდირება იშვიათად გამოიყენება.
გაშვებულ კომპიუტერებზე ოპერატიული სისტემა MS DOS,კიდევ ორი კოდირება შეიძლება ფუნქციონირებდეს (კოდირება სტუმრებიკოდირება GOST- ალტერნატივა).პირველი მათგანი მოძველებულად ითვლებოდა პერსონალური გამოთვლების გაჩენის პირველ წლებშიც კი, მაგრამ მეორე გამოიყენება დღემდე.
რუსეთში მოქმედი ტექსტური მონაცემთა კოდირების სისტემების სიმრავლის გამო, ჩნდება სისტემური მონაცემების კონვერტაციის პრობლემა - ეს არის კომპიუტერული მეცნიერების ერთ-ერთი საერთო ამოცანა.
უნივერსალური ტექსტური მონაცემთა კოდირების სისტემა
თუ გავაანალიზებთ შექმნასთან დაკავშირებულ ორგანიზაციულ სირთულეებს ერთიანი სისტემატექსტური მონაცემების კოდირებით, შეიძლება დავასკვნათ, რომ ისინი გამოწვეულია კოდების შეზღუდული ნაკრებით (256). ამავდროულად, აშკარაა, რომ თუ, მაგალითად, სიმბოლოები დაშიფრულია არა რვა-ბიტიანი ორობითი რიცხვებით, არამედ ციფრებით დიდი რაოდენობით, მაშინ შესაძლო კოდის მნიშვნელობების დიაპაზონი გაცილებით დიდი გახდება. ასეთ სისტემას, რომელიც დაფუძნებულია 16-ბიტიან სიმბოლოზე, ე.წ უნივერსალური - UNICODE.თექვსმეტი ციფრი შესაძლებელს ხდის უნიკალური კოდების მიწოდებას 65536 სხვადასხვა სიმბოლოსთვის - ეს ველი საკმარისია იმისთვის, რომ მსოფლიოს ენების უმეტესობა ერთ სიმბოლოთა ცხრილში განთავსდეს.
მიუხედავად ასეთი მიდგომის ტრივიალური აშკარაობისა, ამ სისტემაზე მარტივი მექანიკური გადასვლა დიდი ხანის განმვლობაშიშეზღუდულია კომპიუტერული აღჭურვილობის არასაკმარისი რესურსის გამო (კოდირების სისტემაში UNICODEყველა ტექსტური დოკუმენტი ავტომატურად ხდება ორჯერ გრძელი). 1990-იანი წლების მეორე ნახევარში ტექნიკურმა საშუალებებმა მიაღწიეს რესურსებით უზრუნველყოფის საჭირო დონეს და დღეს ჩვენ ვხედავთ დოკუმენტებისა და პროგრამული უზრუნველყოფის ეტაპობრივ გადასვლას უნივერსალურ კოდირების სისტემაზე. ცალკეული მომხმარებლებისთვის, ეს დაემატა სხვადასხვა კოდირების სისტემაში შედგენილი დოკუმენტების კოორდინაციის შეშფოთებას პროგრამული ინსტრუმენტებით, მაგრამ ეს უნდა იქნას გაგებული, როგორც გარდამავალი პერიოდის სირთულეები.
სურათის მონაცემების კოდირება
თუ გამადიდებელი შუშით უყურებთ გაზეთში ან წიგნში დაბეჭდილ შავ-თეთრ გრაფიკულ გამოსახულებას, ხედავთ, რომ იგი შედგება პაწაწინა წერტილებისგან, რომლებიც ქმნიან დამახასიათებელ ნიმუშს ე.წ. რასტრული(ნახ. 1).
ბრინჯი. 1. რასტერი არის გრაფიკული ინფორმაციის კოდირების მეთოდი, რომელიც დიდი ხანია მიღებულია ბეჭდვის ინდუსტრიაში.
ვინაიდან თითოეული წერტილის წრფივი კოორდინატები და ინდივიდუალური თვისებები (სიკაშკაშე) შეიძლება გამოისახოს მთელი რიცხვების გამოყენებით, შეიძლება ითქვას, რომ რასტრული კოდირება იძლევა ორობითი კოდის გამოყენებას გრაფიკული მონაცემების წარმოსადგენად. დღეს საყოველთაოდ მიღებულია შავ-თეთრი ილუსტრაციების წარმოდგენა, როგორც წერტილების კომბინაცია 256 გრადაციის მქონე. ნაცრისფერი ფერიდა, შესაბამისად, რვა ბიტიანი ორობითი რიცხვი, როგორც წესი, საკმარისია ნებისმიერი წერტილის სიკაშკაშის დასაშიფრად.
გამოიყენება ფერადი გრაფიკის კოდირებისთვის. დაშლის პრინციპითვითნებური ფერი ძირითად კომპონენტებში. ასეთ კომპონენტებად გამოიყენება სამი ძირითადი ფერი: წითელი (წითელი, R),მწვანე (მწვანე, G)და ლურჯი (ლურჯი, V).პრაქტიკაში ითვლება (თუმცა თეორიულად ეს მთლად მართალი არ არის) რომ ადამიანის თვალით ხილული ნებისმიერი ფერის მიღება შესაძლებელია ამ სამი ძირითადი ფერის მექანიკური შერევით. კოდირების ასეთ სისტემას სისტემა ეწოდება RGBძირითადი ფერების სახელების პირველი ასოებით.
თუ 256 მნიშვნელობა (რვა ბიტი) გამოიყენება თითოეული ძირითადი კომპონენტის სიკაშკაშის დაშიფვრისთვის, როგორც ეს ჩვეულებრივ ხდება შავ-თეთრი ნახატების ნახევარტონისთვის, მაშინ 24 ბიტი უნდა დაიხარჯოს ერთი წერტილის ფერის დაშიფვრაზე. ამავდროულად, კოდირების სისტემა იძლევა 16.5 მილიონი სხვადასხვა ფერის ცალსახა განმარტებას, რაც რეალურად ახლოსაა მგრძნობელობასთან. ადამიანის თვალი. 24 ბიტის გამოყენებით ფერადი გრაფიკის წარმოდგენის რეჟიმი ეწოდება სრული ფერი (True Color).
თითოეულ ძირითად ფერს შეიძლება მიენიჭოს დამატებითი ფერი, ანუ ფერი, რომელიც ავსებს ძირითად ფერს თეთრს. ადვილი მისახვედრია, რომ ნებისმიერი ძირითადი ფერისთვის, დამატებითი ფერი იქმნება სხვა ძირითადი ფერის წყვილის ჯამით. შესაბამისად, დამატებითი ფერებია: ლურჯი (ციანი, C),მეწამული (მაჯენტა, M)და ყვითელი ( ყვითელი, Y).თვითნებური ფერის შემადგენელ კომპონენტებად დაშლის პრინციპი შეიძლება გამოყენებულ იქნას არა მხოლოდ ძირითად ფერებზე, არამედ დამატებით ფერებზეც, ანუ ნებისმიერი ფერი შეიძლება წარმოდგენილი იყოს როგორც ციანი, მაგენტა და ყვითელი კომპონენტების ჯამი. ფერადი კოდირების ეს მეთოდი მიღებულია ბეჭდვის ინდუსტრიაში, მაგრამ მეოთხე მელანი ასევე გამოიყენება ბეჭდვის ინდუსტრიაში - შავი. (შავი, K).მაშასადამე, ეს კოდირების სისტემა ოთხი ასოთი აღინიშნება CMYK(შავი ასოებით არის მითითებული TO,რადგან წერილი INუკვე დაკავებულია ლურჯით) და ამ სისტემაში ფერადი გრაფიკის წარმოსადგენად, თქვენ უნდა გქონდეთ 32 ბიტი. ამ რეჟიმს ასევე უწოდებენ სრული ფერი. (Ნამდვილი ფერი).
თუ თქვენ შეამცირებთ ბიტების რაოდენობას, რომლებიც გამოიყენება თითოეული წერტილის ფერის დაშიფვრისთვის, შეგიძლიათ შეამციროთ მონაცემების რაოდენობა, მაგრამ დაშიფრული ფერების დიაპაზონი შესამჩნევად შემცირდება. ფერადი გრაფიკის დაშიფვრას 16-ბიტიანი ბინარული რიცხვებით რეჟიმი ეწოდება მაღალი ფერი.
ფერის ინფორმაციის რვა ბიტიანი მონაცემებით კოდირებისას შესაძლებელია მხოლოდ 256 ფერის ჩრდილის გადაცემა. ფერის კოდირების ამ მეთოდს ე.წ ინდექსი.სახელის მნიშვნელობა ის არის, რომ რადგან 256 მნიშვნელობა სრულიად არასაკმარისია ადამიანის თვალისთვის ხელმისაწვდომი ფერების მთელი დიაპაზონის გადმოსაცემად, რასტერის თითოეული პიქსელის კოდი არ გამოხატავს თავად ფერს, არამედ მხოლოდ მის რაოდენობას. (ინდექსი) inზოგიერთი საძიებო ცხრილი ე.წ პალიტრა.რა თქმა უნდა, ეს პალიტრა უნდა იყოს გამოყენებული გრაფიკულ მონაცემებზე - ამის გარეშე შეუძლებელია ეკრანზე ან ქაღალდზე ინფორმაციის რეპროდუცირების მეთოდების გამოყენება (ეს, რა თქმა უნდა, შეგიძლიათ გამოიყენოთ იგი, მაგრამ მონაცემების არასრულყოფილების გამო , მიღებული ინფორმაცია არ იქნება ადეკვატური: ხეებზე ფოთლები შეიძლება წითელი აღმოჩნდეს, ცა კი მწვანე).
აუდიო კოდირება
ხმოვან ინფორმაციასთან მუშაობის ტექნიკა და მეთოდები უახლესი მოვიდა კომპიუტერულ ტექნოლოგიაში. გარდა ამისა, რიცხვითი, ტექსტური და გრაფიკული მონაცემებისგან განსხვავებით, ხმის ჩანაწერებს არ ჰქონდათ კოდირების იგივე გრძელი და დადასტურებული ისტორია. შედეგად, ორობითი კოდით ხმის ინფორმაციის კოდირების მეთოდები შორს არის სტანდარტიზაციისგან. ბევრმა ინდივიდუალურმა კომპანიამ შეიმუშავა საკუთარი კორპორატიული სტანდარტები, მაგრამ ზოგადად, ორი ძირითადი მიმართულება შეიძლება გამოიყოს.
FM მეთოდი (სიხშირის მოდულაცია)ემყარება იმ ფაქტს, რომ თეორიულად ნებისმიერი რთული ბგერა შეიძლება დაიშალოს სხვადასხვა სიხშირის უმარტივესი ჰარმონიული სიგნალების თანმიმდევრობაში, რომელთაგან თითოეული არის რეგულარული სინუსოიდი და, შესაბამისად, შეიძლება აღწერილი იყოს რიცხვითი პარამეტრებით, ანუ კოდით. ბუნებაში, აუდიო სიგნალებს აქვთ უწყვეტი სპექტრი, ანუ ისინი ანალოგურია. მათი გაფართოება ჰარმონიულ სერიებად და წარმოდგენა დისკრეტული ციფრული სიგნალების სახით ხორციელდება სპეციალური მოწყობილობებით - ანალოგური ციფრული გადამყვანები (ADC).შესრულებულია რიცხვითი კოდით დაშიფრული ბგერის რეპროდუცირების შებრუნებული ტრანსფორმაცია ციფრული ანალოგური გადამყვანები (DAC).ასეთი გარდაქმნებით, კოდირების მეთოდთან დაკავშირებული ინფორმაციის დაკარგვა გარდაუვალია, ამიტომ ხმის ჩაწერის ხარისხი, როგორც წესი, არ არის სრულიად დამაკმაყოფილებელი და შეესაბამება ელექტრონული მუსიკის დამახასიათებელი ფერის უმარტივესი ელექტრო მუსიკალური ინსტრუმენტების ხმის ხარისხს. ამავდროულად, კოდირების ეს მეთოდი იძლევა ძალიან კომპაქტურ კოდს და, შესაბამისად, მან იპოვა გამოყენება იმ წლებშიც კი, როდესაც კომპიუტერული ტექნოლოგიების რესურსები აშკარად არასაკმარისი იყო.
მაგიდის ტალღის მეთოდი ( ტალღის მაგიდა)სინთეზი უკეთესად შეეფერება თანამედროვე ტექნიკის მდგომარეობას. მარტივად რომ ვთქვათ, შეგვიძლია ვთქვათ, რომ სადღაც წინასწარ მომზადებულ ცხრილებში, ხმის ნიმუშები ინახება მრავალი სხვადასხვა მუსიკალური ინსტრუმენტისთვის (თუმცა არა მხოლოდ მათთვის). ინჟინერიაში ასეთ ნიმუშებს ე.წ ნიმუშები.რიცხვითი კოდები გამოხატავს ინსტრუმენტის ტიპს, მის მოდელის ნომერს, სიმაღლეს, ხმის ხანგრძლივობას და ინტენსივობას, მისი ცვლილების დინამიკას, გარემოს ზოგიერთ პარამეტრს, რომელშიც ხმა წარმოიქმნება, აგრეთვე სხვა პარამეტრებს, რომლებიც ახასიათებს ხმის თავისებურებებს. . ვინაიდან „რეალური“ ბგერები გამოიყენება ნიმუშებად, სინთეზის შედეგად მიღებული ხმის ხარისხი ძალიან მაღალია და უახლოვდება რეალური მუსიკალური ინსტრუმენტების ხმის ხარისხს.
მონაცემთა ძირითადი სტრუქტურები
მონაცემთა დიდ ნაკრებებთან მუშაობა უფრო ადვილია ავტომატიზირება, როდესაც მონაცემები უბრძანა,ანუ ქმნიან მოცემულ სტრუქტურას. არსებობს მონაცემთა სტრუქტურების სამი ძირითადი ტიპი: ხაზოვანი, იერარქიულიდა ცხრილის.ისინი შეიძლება ჩაითვალოს ჩვეულებრივი წიგნის მაგალითზე.
თუ წიგნს ცალკე ფურცლებად დაშლით და აურიეთ, წიგნი დანიშნულებას დაკარგავს. ის მაინც წარმოადგენს მონაცემთა ერთობლიობას, მაგრამ ძალიან რთულია მისგან ინფორმაციის მოპოვების ადეკვატური მეთოდის პოვნა. (სიტუაცია კიდევ უფრო გაუარესდება, თუ წიგნიდან ცალ-ცალკე ამოიჭრება თითოეული ასო - ამ შემთხვევაში, ნაკლებად სავარაუდოა, რომ საერთოდ არსებობდეს მისი წაკითხვის ადეკვატური მეთოდი.)
თუ ჩვენ შევაგროვებთ წიგნის ყველა ფურცელს სწორი თანმიმდევრობით, მივიღებთ მონაცემთა უმარტივეს სტრუქტურას - ხაზოვანი.თქვენ უკვე შეგიძლიათ წაიკითხოთ ასეთი წიგნი, თუმცა იმისთვის, რომ საჭირო მონაცემები იპოვოთ, მოგიწევთ მისი წაკითხვა ზედიზედ, თავიდანვე, რაც ყოველთვის არ არის მოსახერხებელი.
მონაცემთა სწრაფი აღდგენისთვის, არსებობს იერარქიული სტრუქტურა.ასე მაგალითად, წიგნები იყოფა ნაწილებად, განყოფილებებად, თავებად, აბზაცებად და ა.შ. ქვედა დონის სტრუქტურის ელემენტები შედის უფრო მაღალი დონის სტრუქტურის ელემენტებში: სექციები შედგება თავებისგან, აბზაცების თავებისგან და ა.შ.
დიდი მასივებისთვის, იერარქიულ სტრუქტურაში მონაცემების ძებნა ბევრად უფრო ადვილია, ვიდრე ხაზოვანი, მაგრამ აქაც აუცილებელია ნავიგაცია,დაკავშირებულია ნახვის საჭიროებასთან. პრაქტიკაში, ამოცანა გამარტივებულია იმით, რომ უმეტეს წიგნებში არის დამხმარე ჯვარედინი მაგიდა,იერარქიული სტრუქტურის ელემენტების დაკავშირება ხაზოვანი სტრუქტურის ელემენტებთან, ანუ სექციების, თავებისა და აბზაცების დაკავშირება გვერდის ნომრებით. მარტივი იერარქიული სტრუქტურის მქონე წიგნებში, რომლებიც განკუთვნილია თანმიმდევრული კითხვისთვის, ამ ცხრილს ჩვეულებრივ უწოდებენ სარჩევიხოლო რთული სტრუქტურის მქონე წიგნებში, რომლებიც შერჩევითი კითხვის საშუალებას იძლევა, ე.წ შინაარსი.
1.6. მონაცემები და კოდირება
მონაცემთა მატარებლები
მონაცემები ინფორმაციის დიალექტიკური კომპონენტია. ისინი რეგისტრირებული სიგნალებია. ამ შემთხვევაში რეგისტრაციის ფიზიკური მეთოდი შეიძლება იყოს ნებისმიერი: ფიზიკური სხეულების მექანიკური მოძრაობა, მათი ფორმის ან ზედაპირის ხარისხის პარამეტრების შეცვლა, ელექტრული, მაგნიტური, ოპტიკური მახასიათებლები, ქიმიური შემადგენლობადა (ან) ქიმიური ბმების ბუნება, ელექტრონული სისტემის მდგომარეობის ცვლილებები და მრავალი სხვა.
რეგისტრაციის მეთოდის მიხედვით, მონაცემების შენახვა და ტრანსპორტირება შესაძლებელია სხვადასხვა ტიპის მედიაზე. ყველაზე გავრცელებული შესანახი საშუალება, თუმცა არა ყველაზე ეკონომიური, როგორც ჩანს, ქაღალდია. ქაღალდზე მონაცემები ჩაიწერება მისი ზედაპირის ოპტიკური მახასიათებლების შეცვლით. ოპტიკური თვისებების შეცვლა (ზედაპირის არეკვლის შეცვლა ტალღის სიგრძის გარკვეულ დიაპაზონში) ასევე გამოიყენება მოწყობილობებში, რომლებიც ჩაწერენ ლაზერის სხივით პლასტმასის მედიაზე ამრეკლავი საფარით (CD-ROM). როგორც მედია, რომელიც იყენებს მაგნიტური თვისებების ცვლილებას, შეგვიძლია დავასახელოთ მაგნიტური ფირები და დისკები. მონაცემების ჩაწერა მატარებლის ზედაპირის ნივთიერებების ქიმიური შემადგენლობის შეცვლით ფართოდ გამოიყენება ფოტოგრაფიაში. ბიოქიმიურ დონეზე ველურ ბუნებაში ხდება მონაცემთა დაგროვება და გადაცემა.
მონაცემთა მატარებლები ჩვენთვის საინტერესოა არა თავისთავად, არამედ იმდენად, რამდენადაც ინფორმაციის თვისებები ძალიან მჭიდროდ არის დაკავშირებული მისი მატარებლების თვისებებთან. ნებისმიერი მედია შეიძლება ხასიათდებოდეს გარჩევადობის პარამეტრით (მონაცემთა რაოდენობა, რომელიც ჩაწერილია მედიისთვის მიღებულ გაზომვის ერთეულში) და დინამიური დიაპაზონი (მაქსიმალური და მინიმალური ჩაწერილი სიგნალების ამპლიტუდების ინტენსივობის ლოგარითმული თანაფარდობა). ინფორმაციის ისეთი თვისებები, როგორიცაა სისრულე, ხელმისაწვდომობა და სანდოობა, ხშირად დამოკიდებულია გადამზიდველის ამ თვისებებზე. ასე, მაგალითად, შეგვიძლია ვიმედოვნოთ, რომ CD-ზე მდებარე მონაცემთა ბაზაში უფრო ადვილია ინფორმაციის სისრულის უზრუნველყოფა, ვიდრე მსგავსი დანიშნულების მონაცემთა ბაზაში, რომელიც მდებარეობს ფლოპი დისკზე, რადგან პირველ შემთხვევაში სიმკვრივე მონაცემთა ჩაწერის ერთეული სიგრძის ბილიკები გაცილებით მაღალია. საშუალო მომხმარებლისთვის, წიგნში ინფორმაციის ხელმისაწვდომობა შესამჩნევად უფრო მაღალია, ვიდრე იგივე ინფორმაცია CD-ზე, რადგან ყველა მომხმარებელს არ აქვს საჭირო აღჭურვილობა. და ბოლოს, ცნობილია, რომ ვიზუალური ეფექტიპროექტორში სლაიდის ყურება გაცილებით მეტია, ვიდრე ქაღალდზე დაბეჭდილი მსგავსი ილუსტრაციის ნახვისას, ვინაიდან სიკაშკაშის სიგნალების დიაპაზონი გადაცემულ შუქზე არის ორი-სამი რიგით მეტი, ვიდრე არეკლილი სინათლე.
მატარებლის შეცვლის მიზნით მონაცემთა ტრანსფორმაციის ამოცანა ინფორმატიკის ერთ-ერთი ყველაზე მნიშვნელოვანი ამოცანაა. გამოთვლითი სისტემების ღირებულების სტრუქტურაში მონაცემების შეყვანისა და გამომავალი მოწყობილობები, რომლებიც მუშაობენ შესანახ მედიასთან, შეადგენს ტექნიკის ღირებულების ნახევარს.
მონაცემთა ოპერაციები
საინფორმაციო პროცესის დროს მონაცემთა ტრანსფორმაცია ხდება ერთი ტიპიდან მეორეზე მეთოდების გამოყენებით. მონაცემთა დამუშავება მოიცავს მრავალ განსხვავებულ ოპერაციას. სამეცნიერო და ტექნოლოგიური პროგრესის განვითარებით და ადამიანთა საზოგადოებაში კომუნიკაციების საერთო გართულებით, მონაცემთა დამუშავების შრომის ხარჯები სტაბილურად იზრდება. უპირველეს ყოვლისა, ეს გამოწვეულია წარმოებისა და საზოგადოების მართვის პირობების მუდმივი გართულებით. მეორე ფაქტორი, რომელიც ასევე იწვევს დამუშავებული მონაცემების მოცულობის ზოგად ზრდას, ასევე ასოცირდება სამეცნიერო და ტექნოლოგიურ პროგრესთან, კერძოდ, მონაცემთა ახალი მატარებლების, მონაცემთა შენახვისა და მიწოდების საშუალებების სწრაფ გაჩენასა და დანერგვასთან.
სტრუქტურაში შესაძლო ოპერაციებიმონაცემებით შეიძლება განვასხვავოთ შემდეგი ძირითადი:
მონაცემთა შეგროვება - მონაცემების დაგროვება გადაწყვეტილების მიღებისათვის ინფორმაციის საკმარისი სისრულის უზრუნველსაყოფად;
მონაცემთა ფორმალიზაცია - სხვადასხვა წყაროდან მონაცემების ერთსა და იმავე ფორმაში მოყვანა, რათა მოხდეს მათი შედარება, ანუ მათი ხელმისაწვდომობის დონის ამაღლება;
მონაცემთა გაფილტვრა - „ზედმეტი“ მონაცემების ამოღება, რომელიც არ არის აუცილებელი გადაწყვეტილების მიღებისთვის; ამასთან, უნდა შემცირდეს „ხმაურის“ დონე, გაიზარდოს მონაცემთა სანდოობა და ადეკვატურობა;
მონაცემთა დახარისხება - მონაცემების დალაგება მოცემული ატრიბუტის მიხედვით მარტივად გამოყენების მიზნით; ზრდის ინფორმაციის ხელმისაწვდომობას;
მონაცემთა დაჯგუფება - მონაცემების გაერთიანება მოცემული ატრიბუტის მიხედვით გამოყენების სიმარტივის გაზრდის მიზნით; ზრდის ინფორმაციის ხელმისაწვდომობას;
მონაცემთა დაარქივება - მონაცემთა შენახვის ორგანიზება მოსახერხებელი და ადვილად ხელმისაწვდომი ფორმით; ემსახურება მონაცემთა შენახვის ეკონომიკური ხარჯების შემცირებას და მთლიანობაში საინფორმაციო პროცესის ზოგად სანდოობას ზრდის;
მონაცემთა დაცვა - ღონისძიებების ერთობლიობა, რომელიც მიზნად ისახავს მონაცემთა დაკარგვის, რეპროდუქციისა და მოდიფიკაციის თავიდან აცილებას;
მონაცემთა ტრანსპორტირება - ინფორმაციის მიღება და გადაცემა (მიწოდება და მიწოდება) ინფორმაციის პროცესის დისტანციურ მონაწილეებს შორის; ამავდროულად, ინფორმატიკაში მონაცემთა წყაროს ჩვეულებრივ სერვერს უწოდებენ, ხოლო მომხმარებელს - კლიენტს;
მონაცემთა ტრანსფორმაცია არის მონაცემთა გადაცემა ერთი ფორმიდან მეორეში ან ერთი სტრუქტურიდან მეორეზე. მონაცემთა კონვერტაცია ხშირად ასოცირდება მედიის ტიპის ცვლილებასთან, მაგალითად, წიგნების შენახვა შესაძლებელია ჩვეულებრივი ქაღალდის ფორმით, მაგრამ ამისთვის შეიძლება გამოყენებულ იქნას როგორც ელექტრონული ფორმა, ასევე მიკროფილმი. მონაცემთა მრავალჯერადი ტრანსფორმაციის აუცილებლობა წარმოიქმნება მათი ტრანსპორტირების დროსაც, განსაკუთრებით მაშინ, თუ ის ხორციელდება ამ ტიპის მონაცემების ტრანსპორტირებისთვის არ არის განკუთვნილი საშუალებებით. მაგალითად, შეიძლება აღინიშნოს, რომ ციფრული მონაცემების ნაკადების გადასატანად სატელეფონო ქსელების არხებზე (რომლებიც თავდაპირველად ორიენტირებული იყო მხოლოდ ანალოგური სიგნალების გადაცემაზე ვიწრო სიხშირის დიაპაზონში), აუცილებელია ციფრული მონაცემების გადაყვანა ზოგიერთად. სახის აუდიო სიგნალები, რასაც აკეთებენ სპეციალური მოწყობილობები - სატელეფონო მოდემები.
აქ მოცემული ტიპიური მონაცემთა ოპერაციების ჩამონათვალი შორს არის დასრულებული. მილიონობით ადამიანი მთელს მსოფლიოში ჩართულია მონაცემთა შექმნაში, დამუშავებაში, ტრანსფორმაციასა და ტრანსპორტირებაში და თითოეული სამუშაო ადგილი ასრულებს თავის სპეციფიკურ ოპერაციებს, რომლებიც აუცილებელია სოციალური, ეკონომიკური, ინდუსტრიული, სამეცნიერო და კულტურული პროცესების მართვისთვის. შეუძლებელია შესაძლო ოპერაციების სრული სიის შედგენა და არც არის აუცილებელი. ახლა ჩვენთვის მნიშვნელოვანია კიდევ ერთი დასკვნა: ინფორმაციასთან მუშაობა შეიძლება იყოს ძალიან შრომატევადი და ის უნდა იყოს ავტომატიზირებული.
მონაცემთა ორობითი კოდირება
სხვადასხვა ტიპის მონაცემებთან მუშაობის ავტომატიზაციისთვის, ძალიან მნიშვნელოვანია მათი პრეზენტაციის ფორმის გაერთიანება - ამისათვის ჩვეულებრივ გამოიყენება კოდირების ტექნიკა, ანუ ერთი ტიპის მონაცემების გამოხატვა სხვა ტიპის მონაცემებით. ბუნებრივი ადამიანური ენები სხვა არაფერია, თუ არა კონცეფციის კოდირების სისტემები სიტყვის საშუალებით აზრების გამოხატვისთვის. ენები მჭიდრო კავშირშია ანბანებთან (ენის კომპონენტების დაშიფვრის სისტემები გრაფიკული სიმბოლოების გამოყენებით). ისტორიამ იცის საინტერესო, თუმცა წარუმატებელი მცდელობები შექმნას "უნივერსალური" ენები და ანბანები. როგორც ჩანს, მათი განხორციელების მცდელობების წარუმატებლობა განპირობებულია იმით, რომ ეროვნულ და სოციალურ ფორმირებებს ბუნებრივად ესმით, რომ საჯარო მონაცემების კოდირების სისტემის ცვლილება აუცილებლად გამოიწვევს საზოგადოებრივი მეთოდების შეცვლას (ანუ იურიდიული და მორალური ნორმები). და ეს შეიძლება დაკავშირებული იყოს სოციალურ აჯანყებასთან.
უნივერსალური კოდირების ინსტრუმენტის იგივე პრობლემა საკმაოდ წარმატებით არის დანერგილი ტექნოლოგიის, მეცნიერებისა და კულტურის გარკვეულ დარგებში. მაგალითებია მათემატიკური გამონათქვამების ჩაწერის სისტემა, ტელეგრაფის ანბანი, საზღვაო დროშის ანბანი, ბრაილის სისტემა უსინათლოთათვის და მრავალი სხვა.
ბრინჯი. 1.8. სხვადასხვა კოდირების სისტემების მაგალითები
კომპიუტერულ ტექნოლოგიასაც აქვს თავისი სისტემა - მას ორობითი კოდირება ჰქვია და ეფუძნება მონაცემების გამოსახვას მხოლოდ ორი სიმბოლოს თანმიმდევრობით: 0 და 1. ამ სიმბოლოებს ორობითი ციფრები ეწოდება, ინგლისურად - ორობითი ციფრი, ან მოკლედ , ბიტი (ბიტი).
ორი ცნება შეიძლება გამოიხატოს ერთ ბიტში: 0 ან 1 (დიახ ან არა, შავი ან თეთრი, ჭეშმარიტი ან მცდარი და ა.შ.). თუ ბიტების რაოდენობა ორამდე გაიზარდა, მაშინ უკვე შესაძლებელია ოთხი განსხვავებული ცნების გამოხატვა:
სამ ბიტს შეუძლია რვა განსხვავებული მნიშვნელობის დაშიფვრა:
000 001 010 011 100 101 110 111
ორობით კოდირების სისტემაში ციფრების ერთით გაზრდით, ჩვენ გავაორმაგებთ მნიშვნელობების რაოდენობას, რომლებიც შეიძლება გამოისახოს ამ სისტემაში.
მთელი და რეალური რიცხვების კოდირება
0-დან 255-მდე მთელი რიცხვების დაშიფვრისთვის საკმარისია ორობითი კოდის 8 ბიტი (8 ბიტი).
……………….
თექვსმეტი ბიტი საშუალებას გაძლევთ დაშიფვროთ მთელი რიცხვები 0-დან 65535-მდე, ხოლო 24 ბიტი - 16,5 მილიონზე მეტი სხვადასხვა მნიშვნელობის.
რეალური რიცხვები დაშიფრულია 80-ბიტიანი კოდირებით. ამ შემთხვევაში, რიცხვი წინასწარ გარდაიქმნება ნორმალიზებულ ფორმაში.
3.1415926 = 0.31415926 101
300000 = 0.3 106
123456789 = 0.123456789 109
რიცხვის პირველ ნაწილს ეწოდება მანტისა, ხოლო მეორე ნაწილს - მახასიათებელი. 80 ბიტიდან უმეტესი ნაწილი გამოყოფილია მანტისას შესანახად (ნიშანთან ერთად) და გარკვეული ფიქსირებული რაოდენობის ბიტი გამოიყოფა მახასიათებლის შესანახად (ასევე ხელმოწერილი).
ტექსტური მონაცემების კოდირება
თუ ანბანის თითოეული სიმბოლო ასოცირდება გარკვეულ მთელ რიცხვთან (მაგალითად, სერიულ ნომერთან), მაშინ ბინარული კოდის დახმარებით შესაძლებელია ტექსტური ინფორმაციის დაშიფვრაც. რვა ბიტი საკმარისია 256 სხვადასხვა სიმბოლოს დაშიფვრისთვის. ეს საკმარისია იმისათვის, რომ რვა ბიტის სხვადასხვა კომბინაციით გამოვხატოთ ინგლისური და რუსული ანბანის ყველა სიმბოლო, როგორც მცირე, ასევე დიდი, ასევე პუნქტუაციის ნიშნები, ძირითადი არითმეტიკული ოპერაციების სიმბოლოები და ზოგიერთი ზოგადად მიღებული სპეციალური სიმბოლო, მაგალითად, სიმბოლო ". §".
ტექნიკურად, ეს ძალიან მარტივია, მაგრამ ყოველთვის იყო საკმაოდ მნიშვნელოვანი ორგანიზაციული სირთულეები. კომპიუტერული ტექნოლოგიების განვითარების ადრეულ წლებში ისინი დაკავშირებული იყო საჭირო სტანდარტების ნაკლებობასთან, ახლა კი ისინი გამოწვეულია, პირიქით, ერთდროულად მოქმედი და ურთიერთსაწინააღმდეგო სტანდარტების სიმრავლით. იმისთვის, რომ მთელმა მსოფლიომ ტექსტური მონაცემების ანალოგიურად დაშიფვრა, საჭიროა კოდირების ერთიანი ცხრილები და ეს ჯერ კიდევ შეუძლებელია ეროვნული ანბანის სიმბოლოებს შორის წინააღმდეგობებისა და კორპორატიული წინააღმდეგობების გამო.
ამისთვის ინგლისურად, რომელმაც საერთაშორისო საკომუნიკაციო საშუალებების დე ფაქტო ნიშა წაართვა, წინააღმდეგობები უკვე მოიხსნა. აშშ-ს სტანდარტების ინსტიტუტმა (ANSI - ამერიკული ეროვნული სტანდარტების ინსტიტუტი) დანერგა ASCII (American Standard Code for Information Interchange) კოდირების სისტემა. ASCII სისტემას აქვს ორი კოდირების ცხრილი: ძირითადი და გაფართოებული. საბაზო ცხრილი აფიქსირებს კოდის მნიშვნელობებს 0-დან 127-მდე, ხოლო გაფართოებული ცხრილი ეხება სიმბოლოებს 128-დან 255-მდე რიცხვებით.
საბაზისო ცხრილის პირველი 32 კოდი, ნულიდან დაწყებული, გადაეცა ტექნიკის მწარმოებლებს (პირველ რიგში კომპიუტერების და საბეჭდი მოწყობილობების მწარმოებლებს). ეს ზონა შეიცავს ეგრეთ წოდებულ საკონტროლო კოდებს, რომლებიც არ შეესაბამება რომელიმე ენის სიმბოლოს და, შესაბამისად, ეს კოდები არ არის ნაჩვენები არც ეკრანზე და არც საბეჭდ მოწყობილობებზე, მაგრამ მათი კონტროლი შესაძლებელია სხვა მონაცემების გამოტანის გზით.
32 კოდიდან დაწყებული 127 კოდამდე, არსებობს ინგლისური ანბანის სიმბოლოების, პუნქტუაციის ნიშნების, რიცხვების, არითმეტიკული ოპერაციების და ზოგიერთი დამხმარე სიმბოლოს კოდები. ბაზის მაგიდა ASCII კოდირებებიმოცემულია ცხრილში 1.1.

ტექსტის მონაცემთა კოდირების მსგავსი სისტემები შემუშავებულია სხვა ქვეყნებში. ასე, მაგალითად, სსრკ-ში ამ სფეროში მოქმედებდა KOI-7 კოდირების სისტემა (ინფორმაციის გაცვლის შვიდნიშნა კოდი). თუმცა, ტექნიკისა და პროგრამული უზრუნველყოფის მწარმოებლების მხარდაჭერამ ამერიკული ASCII კოდი საერთაშორისო სტანდარტის დონემდე მიიყვანა და კოდირების ეროვნულმა სისტემებმა იძულებული გახადეს "უკან დაბრუნებულიყვნენ" კოდირების სისტემის მეორე, გაფართოებულ ნაწილზე, რომელიც განსაზღვრავს მნიშვნელობებს. კოდების 128-დან 255-მდე. ამ სფეროში ერთი სტანდარტის ნაკლებობამ გამოიწვია ერთდროულად მოქმედი კოდირების სიმრავლე. მხოლოდ რუსეთში შეგიძლიათ მიუთითოთ სამი მიმდინარე კოდირების სტანდარტი და კიდევ ორი მოძველებული.
ასე, მაგალითად, რუსული ენის სიმბოლოების კოდირება, რომელიც ცნობილია როგორც Windows-1251 კოდირება, დაინერგა "გარედან" Microsoft-ის მიერ, მაგრამ იმის გათვალისწინებით, რომ ოპერაციული სისტემები და ამ კომპანიის სხვა პროდუქტები რუსეთში ფართოდ გამოიყენება, ეს არის ღრმად ჩაძირული და ფართოდ გამოყენებული (ცხრილი 1.2). ეს კოდირება გამოიყენება უმეტეს ლოკალურ კომპიუტერებზე, რომლებიც მუშაობენ Windows პლატფორმაზე. დე ფაქტო, ის გახდა სტანდარტი მსოფლიო ქსელის რუსულ სექტორში.

კიდევ ერთი გავრცელებული კოდირება ჰქვია KOI-8 (ინფორმაციის გაცვლის კოდი, რვანიშნა) - მისი წარმოშობა თარიღდება აღმოსავლეთ ევროპის სახელმწიფოთა ურთიერთ ეკონომიკური დახმარების საბჭოს დროიდან (ცხრილი 1.3). ამ კოდირების საფუძველზე ახლა მოქმედებს კოდირების KOI8-R (რუსული) და KOI8-U (უკრაინული). დღეს KOI8-R კოდირება ფართოდ გამოიყენება რუსეთში კომპიუტერულ ქსელებში და ინტერნეტის რუსული სექტორის ზოგიერთ სერვისში. კერძოდ, რუსეთში ის დე ფაქტო სტანდარტია ელექტრონული ფოსტის შეტყობინებებში და ტელეკონფერენციაში.

საერთაშორისო სტანდარტს, რომელიც ითვალისწინებს რუსული ანბანის სიმბოლოების დაშიფვრას, ეწოდება ISO კოდირება (საერთაშორისო სტანდარტების ორგანიზაცია). პრაქტიკაში, ეს კოდირება იშვიათად გამოიყენება (ცხრილი 1.4).

კომპიუტერებზე, რომლებიც მუშაობენ MS-DOS ოპერაციულ სისტემებზე, შეიძლება მუშაობდეს კიდევ ორი კოდირება (GOST კოდირება და GOST-ალტერნატიული კოდირება). პირველი მათგანი მოძველებულად ითვლებოდა პერსონალური გამოთვლის პირველ დღეებშიც კი, მაგრამ მეორე დღესაც გამოიყენება (იხ. ცხრილი 1.5).

რუსეთში მოქმედი ტექსტური მონაცემთა კოდირების სისტემების სიმრავლის გამო, ჩნდება სისტემური მონაცემების კონვერტაციის პრობლემა - ეს არის კომპიუტერული მეცნიერების ერთ-ერთი საერთო ამოცანა.
უნივერსალური ტექსტური მონაცემთა კოდირების სისტემა
თუ გავაანალიზებთ ორგანიზაციულ სირთულეებს, რომლებიც დაკავშირებულია ერთიანი ტექსტური მონაცემთა კოდირების სისტემის შექმნასთან, შეგვიძლია დავასკვნათ, რომ ისინი გამოწვეულია კოდების შეზღუდული ნაკრებით (256). ამავდროულად, აშკარაა, რომ თუ, მაგალითად, სიმბოლოები დაშიფრულია არა რვა-ბიტიანი ორობითი რიცხვებით, არამედ ციფრებით დიდი რაოდენობით, მაშინ შესაძლო კოდის მნიშვნელობების დიაპაზონი გაცილებით დიდი გახდება. ასეთ სისტემას, რომელიც დაფუძნებულია 16-ბიტიან სიმბოლოზე, ეწოდა უნივერსალური - UNICODE. თექვსმეტი ციფრი შესაძლებელს ხდის უნიკალური კოდების მიწოდებას 65536 სხვადასხვა სიმბოლოსთვის - ეს ველი საკმარისია იმისთვის, რომ მსოფლიოს ენების უმეტესობა ერთ სიმბოლოთა ცხრილში განთავსდეს.
მიუხედავად ასეთი მიდგომის ტრივიალური აშკარაობისა, ამ სისტემაზე მარტივი მექანიკური გადასვლა დიდი ხნის განმავლობაში შეჩერდა არასაკმარისი კომპიუტერული რესურსების გამო (UNICODE კოდირების სისტემაში ყველა ტექსტური დოკუმენტი ავტომატურად ხდება ორჯერ გრძელი). 1990-იანი წლების მეორე ნახევარში ტექნიკურმა საშუალებებმა მიაღწიეს რესურსებით უზრუნველყოფის საჭირო დონეს და დღეს ჩვენ ვხედავთ დოკუმენტებისა და პროგრამული უზრუნველყოფის ეტაპობრივ გადასვლას უნივერსალურ კოდირების სისტემაზე. ცალკეული მომხმარებლებისთვის, ეს დაემატა სხვადასხვა კოდირების სისტემაში შედგენილი დოკუმენტების კოორდინაციის შეშფოთებას პროგრამული ინსტრუმენტებით, მაგრამ ეს უნდა იქნას გაგებული, როგორც გარდამავალი პერიოდის სირთულეები.
სურათის მონაცემების კოდირება
თუ გამადიდებელი შუშით უყურებთ გაზეთში ან წიგნში დაბეჭდილ შავ-თეთრ გრაფიკულ გამოსახულებას, ხედავთ, რომ იგი შედგება პაწაწინა წერტილებისგან, რომლებიც ქმნიან დამახასიათებელ ნიმუშს, რომელსაც რასტრს უწოდებენ (ნახ. 1.9).

ბრინჯი. 1.9. რასტერი არის გრაფიკული ინფორმაციის კოდირების მეთოდი,
დიდი ხანია მიღებული ბეჭდვის ინდუსტრიაში
ვინაიდან თითოეული წერტილის წრფივი კოორდინატები და ინდივიდუალური თვისებები (სიკაშკაშე) შეიძლება გამოისახოს მთელი რიცხვების გამოყენებით, შეიძლება ითქვას, რომ რასტრული კოდირება იძლევა ორობითი კოდის გამოყენებას გრაფიკული მონაცემების წარმოსადგენად. დღეს საყოველთაოდ მიღებულია შავ-თეთრი ილუსტრაციების წარმოდგენა წერტილების კომბინაციით ნაცრისფერი 256 ელფერით და, ამრიგად, რვა ბიტიანი ორობითი რიცხვი, როგორც წესი, საკმარისია ნებისმიერი წერტილის სიკაშკაშის დასაშიფრად.
ფერადი გრაფიკული გამოსახულების კოდირებისთვის გამოიყენება თვითნებური ფერის ძირითად კომპონენტებად დაშლის პრინციპი. სამი ძირითადი ფერი გამოიყენება, როგორც ასეთი კომპონენტები: წითელი (წითელი, R), მწვანე (მწვანე, G) და ლურჯი (ლურჯი, B). პრაქტიკაში ითვლება (თუმცა თეორიულად ეს მთლად მართალი არ არის) რომ ადამიანის თვალით ხილული ნებისმიერი ფერის მიღება შესაძლებელია ამ სამი ძირითადი ფერის მექანიკური შერევით. ასეთი კოდირების სისტემას ეწოდება RGB სისტემა, ძირითადი ფერების სახელების პირველი ასოების მიხედვით.
თუ 256 მნიშვნელობა (რვა ბიტი) გამოიყენება თითოეული ძირითადი კომპონენტის სიკაშკაშის დაშიფვრისთვის, როგორც ეს ჩვეულებრივ ხდება შავ-თეთრი ნახატების ნახევარტონისთვის, მაშინ 24 ბიტი უნდა დაიხარჯოს ერთი წერტილის ფერის დაშიფვრაზე. ამავდროულად, კოდირების სისტემა იძლევა 16,5 მილიონი სხვადასხვა ფერის ცალსახა განმარტებას, რაც რეალურად ახლოსაა ადამიანის თვალის მგრძნობელობასთან. ფერადი გრაფიკის წარმოდგენის რეჟიმს 24 ბინარული ციფრის გამოყენებით ეწოდება სრული ფერი (True Color).
თითოეულ ძირითად ფერს შეიძლება მიენიჭოს დამატებითი ფერი, ანუ ფერი, რომელიც ავსებს ძირითად ფერს თეთრს. ადვილი მისახვედრია, რომ ნებისმიერი ძირითადი ფერისთვის, დამატებითი ფერი იქმნება სხვა ძირითადი ფერის წყვილის ჯამით. შესაბამისად, დამატებითი ფერებია: ციანი (Cyan, C), მეწამული (Magenta, M) და ყვითელი (Yellow, Y). თვითნებური ფერის შემადგენელ კომპონენტებად დაშლის პრინციპი შეიძლება გამოყენებულ იქნას არა მხოლოდ ძირითად ფერებზე, არამედ დამატებით ფერებზეც, ანუ ნებისმიერი ფერი შეიძლება წარმოდგენილი იყოს როგორც ციანი, მაგენტა და ყვითელი კომპონენტების ჯამი. ფერადი კოდირების ეს მეთოდი მიღებულია ბეჭდვის ინდუსტრიაში, მაგრამ მეოთხე მელანი ასევე გამოიყენება ბეჭდვის ინდუსტრიაში - შავი (Black, K). ამრიგად, კოდირების ეს სისტემა ოთხი CMYK ასოთი აღინიშნება (შავი აღინიშნება ასო K-ით, რადგან ასო B უკვე დაკავებულია ლურჯით), ხოლო ამ სისტემაში ფერადი გრაფიკის წარმოსადგენად საჭიროა გქონდეთ 32 ბიტი. ამ რეჟიმს ასევე უწოდებენ სრულ ფერს (True Color).
თუ თქვენ შეამცირებთ ბიტების რაოდენობას, რომლებიც გამოიყენება თითოეული წერტილის ფერის დაშიფვრისთვის, შეგიძლიათ შეამციროთ მონაცემების რაოდენობა, მაგრამ დაშიფრული ფერების დიაპაზონი შესამჩნევად შემცირდება. ფერადი გრაფიკის კოდირებას 16-ბიტიანი ბინარული რიცხვებით ეწოდება მაღალი ფერის რეჟიმი.
ფერის ინფორმაციის რვა ბიტიანი მონაცემებით კოდირებისას შესაძლებელია მხოლოდ 256 ფერის ჩრდილის გადაცემა. ფერის კოდირების ამ მეთოდს ინდექსი ეწოდება. სახელის მნიშვნელობა ის არის, რომ რადგან 256 მნიშვნელობა სრულიად არასაკმარისია ადამიანის თვალისთვის ხელმისაწვდომი ფერების მთელი დიაპაზონის გადმოსაცემად, რასტერის თითოეული პიქსელის კოდი არ გამოხატავს თავად ფერს, არამედ მხოლოდ მის რაოდენობას (ინდექსი ) ზოგიერთ საცნობარო ცხრილში, რომელსაც ეწოდება პალიტრა. რა თქმა უნდა, ეს პალიტრა უნდა იყოს გამოყენებული გრაფიკულ მონაცემებზე - ამის გარეშე შეუძლებელია ეკრანზე ან ქაღალდზე ინფორმაციის რეპროდუცირების მეთოდების გამოყენება (ეს, რა თქმა უნდა, შეგიძლიათ გამოიყენოთ იგი, მაგრამ მონაცემების არასრულყოფილების გამო , მიღებული ინფორმაცია არ იქნება ადეკვატური: ხეებზე ფოთლები შეიძლება წითელი აღმოჩნდეს, ცა კი მწვანე).
აუდიო კოდირება
ხმოვან ინფორმაციასთან მუშაობის ტექნიკა და მეთოდები უახლესი მოვიდა კომპიუტერულ ტექნოლოგიაში. გარდა ამისა, რიცხვითი, ტექსტური და გრაფიკული მონაცემებისგან განსხვავებით, ხმის ჩანაწერებს არ ჰქონდათ კოდირების იგივე გრძელი და დადასტურებული ისტორია. შედეგად, ორობითი კოდით ხმის ინფორმაციის კოდირების მეთოდები შორს არის სტანდარტიზაციისგან. ბევრმა ინდივიდუალურმა კომპანიამ შეიმუშავა საკუთარი კორპორატიული სტანდარტები.
ლექცია ნომერი 4.
მონაცემთა ორობითი კოდირება
სხვადასხვა ტიპის მონაცემებთან მუშაობის ავტომატიზაციისთვის ძალიან მნიშვნელოვანია მათი პრეზენტაციის ფორმის გაერთიანება. ამისთვის ჩვეულებრივ გამოიყენება კოდირების ტექნიკა, ე.ი. ერთი ტიპის მონაცემების გამოხატვა სხვა ტიპის მონაცემებით.
კოდირების სისტემების მაგალითები: ადამიანის ენები, ABC (ენის კოდირება გრაფიკული სიმბოლოების გამოყენებით), მათემატიკური გამონათქვამების წერა, ტელეგრაფიული მორზეს კოდი, ბრაილის კოდი უსინათლოთათვის, საზღვაო დროშები და ა.შ.
კომპიუტერულ ტექნოლოგიასაც აქვს საკუთარი კოდირების სისტემა - მას ორობითი კოდირება ეწოდება და ეფუძნება მონაცემების მხოლოდ ორი სიმბოლოს მიმდევრობით წარმოდგენას: 0 და 1. ამ სიმბოლოებს ორობითი ციფრები ან ბიტები ეწოდება.
ერთ ბიტს შეუძლია გამოხატოს ორი ცნება: 0 ან 1 (დიახ ან არა, შავი ან თეთრი, ჭეშმარიტი ან მცდარი და ა.შ.). თუ ბიტების რაოდენობას ორამდე გაზრდით, მაშინ უკვე შეგიძლიათ ოთხი განსხვავებული ცნების გამოხატვა - 00 01 10 11. სამ ბიტს უკვე შეუძლია რვა განსხვავებული ცნების კოდირება - 000 001 010 100 101 110 101 111.
ბინარული კოდირების სისტემაში ბიტების რაოდენობის ერთით გაზრდით, შეგიძლიათ გააორმაგოთ მნიშვნელობების რაოდენობა, რომლებიც შეიძლება იყოს კოდირებული: ნ=2 მე, სად მე- ციფრების რაოდენობა, ნ- მნიშვნელობების რაოდენობა.
კომპიუტერს შეუძლია ციფრული, ტექსტური, გრაფიკული, ხმოვანი და ვიდეო მონაცემების დამუშავება. ყველა ამ ტიპის მონაცემი დაშიფრულია ელექტრული იმპულსების თანმიმდევრობით: არის იმპულსი (1), არ არის იმპულსი (0), ე.ი. ნულების და ერთეულების თანმიმდევრობით. ნულების და ერთეულების ასეთ ლოგიკურ თანმიმდევრობას მანქანის ენა ეწოდება.
აღნიშვნა
რა არის რიცხვითი სისტემა?
არსებობს პოზიციური და არაპოზიციური რიცხვითი სისტემები.
IN არაპოზიციურისისტემებში, ციფრის წონა (ანუ წვლილი, რომელსაც იგი ასრულებს რიცხვის მნიშვნელობაში) არ არის დამოკიდებული მის პოზიციაზე რიცხვის აღნიშვნაში. ასე რომ, რომაულ რიცხვთა სისტემაში XXXII რიცხვში (ოცდათორმეტი), X ციფრის წონა ნებისმიერ პოზიციაზე უბრალოდ ათია.
IN პოზიციურირიცხვითი სისტემები, თითოეული ციფრის წონა იცვლება მისი პოზიციის (პოზიციის) მიხედვით რიცხვის გამომსახველი ციფრების თანმიმდევრობაში. მაგალითად, 757,7 რიცხვში პირველი შვიდი ნიშნავს 7 ასეულს, მეორე - 7 ერთეულს, ხოლო მესამე - 7 მეათედი ერთეულის.
757.7 რიცხვის თავად ჩანაწერი ნიშნავს შემოკლებულ გამონათქვამს
700 + 50 + 7 + 0,7 = 7 10 2 + 5 10 1 + 7 10 0 + 7 10 -1 = 757,7.
ნებისმიერი პოზიციური რიცხვითი სისტემა ხასიათდება მისი ფუძით.
სისტემის საფუძვლად შეიძლება მივიღოთ ნებისმიერი ნატურალური რიცხვი - ორი, სამი, ოთხი და ა.შ. ამიტომ შესაძლებელია უსასრულო რაოდენობის პოზიციური სისტემები: ორობითი, სამეული, მეოთხეული და ა.შ. რიცხვების ჩაწერა თითოეულ რიცხვთა სისტემაში ფუძით ქნიშნავს გამოხატვის შემოკლებას
ა n-1 ქ n-1 +ა n-2 ქ n-2 + ... + ა 1 ქ 1 +ა 0 ქ 0 +ა -1 ქ -1 + ... + ა -მ ქ -მ ,
სად ა მე- რიცხვითი სისტემის ნომრები; ნდა მარის მთელი და წილადი ციფრების რაოდენობა, შესაბამისად.
რა რიცხვების სისტემებს იყენებენ ექსპერტები კომპიუტერთან კომუნიკაციისთვის?
ათწილადის გარდა, სისტემები ფუძით, რომელიც არის მთლიანი სიმძლავრე 2, კერძოდ:
ორობითი (გამოიყენება ციფრები 0, 1);
რვატული (გამოიყენება ციფრები 0, 1, ..., 7);
თექვსმეტობითი (პირველი მთელი რიცხვებისთვის ნულიდან ცხრამდე გამოიყენება ციფრები 0, 1, ..., 9, ხოლო შემდეგი რიცხვებისთვის - ათიდან თხუთმეტამდე, სიმბოლოები A, B, C, D, E, F არის გამოიყენება როგორც ციფრები).
რატომ იყენებენ ადამიანები ათობითი სისტემას და კომპიუტერები ორობითს?
ხალხს ურჩევნია ათობითი სისტემა, ალბათ იმიტომ, რომ უძველესი დროიდან ისინი თითებზე ითვლიდნენ, ადამიანებს კი ათი თითი აქვთ ხელებსა და ფეხებზე. ყოველთვის და არა ყველგან ადამიანები იყენებენ ათობითი რიცხვების სისტემას. მაგალითად, ჩინეთში, კვინარული რიცხვების სისტემა დიდი ხნის განმავლობაში გამოიყენებოდა.
და კომპიუტერები იყენებენ ორობით სისტემას, რადგან მას აქვს მრავალი უპირატესობა სხვა სისტემებთან შედარებით:
მისი დანერგვა მოითხოვს ტექნიკურ მოწყობილობებს ორი სტაბილური მდგომარეობით (არის დენი - არ არის დენი, მაგნიტიზებულია - არ არის მაგნიტიზებული და ა.შ.), და არა, მაგალითად, ათობით, როგორც ათწილადში;
ინფორმაციის წარმოდგენა მხოლოდ ორი მდგომარეობის საშუალებით არის სანდო და ხმაურისადმი მდგრადი;
ინფორმაციის ლოგიკური გარდაქმნების შესასრულებლად შესაძლებელია ლოგიკური ალგებრის აპარატის გამოყენება;
ორობითი არითმეტიკა გაცილებით მარტივია ვიდრე ათობითი არითმეტიკა.
ბინარული სისტემის მინუსი არის რიცხვების ჩასაწერად საჭირო ციფრების სწრაფი ზრდა.
რატომ იყენებენ კომპიუტერები რვადიან და თექვსმეტობით რიცხვთა სისტემებს?
ორობითი სისტემა, მოსახერხებელი კომპიუტერებისთვის, მისი გამო ადამიანებისთვის მოუხერხებელია ნაყარიდა უჩვეულო ჩანაწერი.
რიცხვების გადაყვანა ათწილადიდან ორობითად და პირიქით ხდება მანქანით. თუმცა, იმისთვის, რომ კომპიუტერი პროფესიონალურად გამოიყენო, უნდა ისწავლო სიტყვა მანქანა. ეს არის ის, რისთვისაც შექმნილია ოქტალური და თექვსმეტობითი სისტემები.
ამ სისტემებში რიცხვები თითქმის ისეთივე ადვილად იკითხება, როგორც ათწილადები; სამ საათზე(რვაფეხა) და ოთხზე(თექვსმეტობითი) ჯერ ნაკლები ციფრი, ვიდრე ბინარული სისტემა (ბოლოს და ბოლოს, რიცხვები 8 და 16 არის რიცხვი 2-ის მესამე და მეოთხე ხარისხები, შესაბამისად).
ორობითი რიცხვების სისტემა
კომპიუტერულ მეცნიერებაში ბინარული რიცხვების სისტემის განსაკუთრებული მნიშვნელობა განისაზღვრება იმით, რომ კომპიუტერში ნებისმიერი ინფორმაციის შიდა წარმოდგენა ორობითია, ე.ი. აღწერილია მხოლოდ ორი სიმბოლოს ნაკრებით (0 და 1).
ათწილადიდან ორობითში გადაყვანა
მთელი და წილადი ნაწილები ითარგმნება ცალ-ცალკე. რიცხვის მთელი ნაწილის გადასათარგმნად აუცილებელია მისი გაყოფა 2 რიცხვების სისტემის ფუძეზე და გავაგრძელოთ გაყოფის კოეფიციენტების გაყოფა მანამ, სანამ კოეფიციენტი არ გახდება 0-ის ტოლი. მიღებული ნაშთების მნიშვნელობები. საპირისპირო თანმიმდევრობით აღებული, ჩამოაყალიბეთ სასურველი ორობითი რიცხვი.
Მაგალითად,
25 (10) = 11001 (2)
წილადი ნაწილის თარგმნისთვის საჭიროა მისი გამრავლება 2-ზე. ნამრავლის მთელი რიცხვი იქნება ორობითი სისტემის რიცხვის პირველი ციფრი. შემდეგ, შედეგის წილადი ნაწილის გადაგდება, კვლავ ვამრავლებთ 2-ზე და ა.შ. ამ შემთხვევაში, საბოლოო ათობითი წილადი შეიძლება გახდეს უსასრულო (პერიოდული) ორობითი.
Მაგალითად,
0.73 * 2 = 1.46 (1-ის მთელი ნაწილი)
0.46 * 2 = 0.92 (0-ის მთელი ნაწილი)
0,92 * 2 = 1,84 (1-ის მთელი ნაწილი)
0.84 * 2 = 1.68 (1-ის მთელი ნაწილი) და ა.შ. 0.73 (10) = 0.1011… (2)
არითმეტიკული მოქმედებები ორობითი რიცხვებით
ზე ორობითი დამატება 1 + 1 ატარებს 1-ს ყველაზე მნიშვნელოვან ბიტამდე, ისევე როგორც ათობითი არითმეტიკაში. Მაგალითად,
ზე ორობითი გამოკლებაუნდა გვახსოვდეს, რომ დაკავებულია უახლოეს ციფრში 1, იძლევა ყველაზე ნაკლებად მნიშვნელოვანი ციფრის ორ ერთეულს. თუ მეზობელ მაღალ ბიტებში არის ნულები, მაშინ 1 დაიკავებს რამდენიმე ბიტის შემდეგ. ამავდროულად, ერთეული, რომელიც დაკავებულია უახლოეს მნიშვნელოვან უფროს ციფრში, იძლევა ორ ერთეულს ყველაზე ნაკლებად მნიშვნელოვან ციფრში და ერთს ყველა ნულოვან ციფრში, რომელიც დგას უმცროს და იმ უფროს ციფრს შორის, საიდანაც არის აღებული ერთეული.
გამოვაკლოთ 174 197-ს

ორობითი რიცხვების დაყოფახდება ორობითი გამრავლებისა და გამოკლების ცხრილების გამოყენებით. გაყავით 430 10-ზე

ოქტალური და თექვსმეტობითი რიცხვების სისტემები
რიცხვების გადაყვანა ათწილადიდან რვადიანადიწარმოება ისევე, როგორც ორობითში გამრავლებისა და გაყოფის გამოყენებით, მხოლოდ არა 2-ზე, არამედ 8-ზე.
მაგალითად, 58.32 (10)
58: 8 = 7 (დარჩენილია 2)
7: 8 = 0 (დარჩენილია 7)
0,48 * 8 = 3,84, …
58,32 (10) = 72,243… (8)
რიცხვების გადაყვანა ათწილადიდან თექვსმეტობით რიცხვებში ანალოგიურად ხდება. 567 (10)0 = 237 (16)
რიცხვების შესაბამისობა სხვადასხვა რიცხვთა სისტემაში
|
ათწილადი |
თექვსმეტობითი |
რვაფეხა |
ორობითი |
ორობითი მთელი რიცხვის რვიანად გადაქცევააუცილებელია მისი მარჯვნიდან მარცხნივ დაყოფა 3 ციფრიან ჯგუფებად (ყველაზე მარცხენა ჯგუფი შეიძლება შეიცავდეს სამზე ნაკლებ ორობით ციფრს), შემდეგ კი თითოეულ ჯგუფს მივანიჭოთ მისი რვავიანი ეკვივალენტი. ასეთ ჯგუფებს ე.წ ორობითი ტრიადები.
Მაგალითად,
11011001 = 11 011 001 = 331 (8)
გადაიყვანეთ ორობითი მთელი რიცხვი თექვსმეტობითწარმოიქმნება მოცემული რიცხვის 4 ციფრიან ჯგუფებად დაყოფით - ბინარული ტეტრადები.
1100011011001 = 1 1000 1101 1001 = 18D9 (16)
ბინარული რიცხვების წილადი ნაწილების რვიან ან თექვსმეტობით სისტემებად გადასაყვანად, მსგავსი დაყოფა ტრიადებად ან ტეტრადებად კეთდება მძიმიდან მარჯვნივ (გამოტოვებული ბოლო ციფრების დამატებით ნულებთან ერთად)
0,1100011101 (2) = 0,110 001 110 100 = 0,6164 (8)
0.1100011101 (2) = 0.1100 0111 0100 = C74 (16)
რვაობითი (თექვსმეტობითი) რიცხვების ორობითად გადაქცევა საპირისპირო გზით ხდება - რიცხვის თითოეული ნიშნის შესაბამის სამმაგ (ოთხ) ორობით ციფრთან შედარებით.
A1F (16) = 1010 0001 1111 (2)
127 (8) = 001 010 111 (2)
ასეთი გარდაქმნების სიმარტივე განპირობებულია იმით, რომ რიცხვები 8 და 16 არის რიცხვი 2-ის მთელი ხარისხები. ეს სიმარტივე ხსნის რვადი და თექვსმეტობითი რიცხვების სისტემების პოპულარობას.
მასწავლებლების ვებსაიტების სია (2)
დოკუმენტიპალმების არქივი ლექციებიასტრონომიაში... კოდირება, კოდირება მონაცემები ორობითი კოდი, კოდირებატექსტი მონაცემები, სისტემები კოდირება, კოდირებაგრაფიკული მონაცემები, კოდირებახმის ინფორმაცია. უნივერსალური სისტემა კოდირებატექსტი მონაცემები ...
ლექციების რეზიუმე მობილურ ობიექტებთან საკომუნიკაციო სისტემის აკადემიური დისციპლინის შესახებ (აკადემიური დისციპლინის დასახელება) სპეციალობაში (სასწავლო დარგში)
Ლექციის ჩანაწერები... კოდირება ლექცია 11. დეტექტივისა და კორექტივის საფუძვლები კოდებიმოკლე ანოტაცია ლექციები: ... საინფორმაციო ბიტების რაოდენობა k და for ორობითი კოდები: , . ზედა ზღვარი... გამოყენებულია გადაცემის მეთოდი კოდირება მონაცემებიორთოგონალური ეწოდება...
სალექციო მასალები თემაზე "ელექტრონული სამრეწველო მოწყობილობები" ცოდნის სფერო
დოკუმენტი... . კოდირებაინფორმაცია. ძირითადი ტიპები კოდები ................................................................. 19 ლექცია 6. ... მისი მიღება მონაცემებიმომხმარებელი; შესაბამისობა... ორობითი კოდიხოლო მისი მოდიფიკაცია - სიმეტრიული ორობითი კოდი. ორობითი კოდები ...
მონაცემთა კოდირება
მონაცემთა ორობითი კოდირება
სხვადასხვა ტიპის მონაცემებთან მუშაობის ავტომატიზაციისთვის, ძალიან მნიშვნელოვანია მათი პრეზენტაციის ფორმის გაერთიანება - ეს ჩვეულებრივ კეთდება ტექნიკის გამოყენებით. კოდირება , ანუ ერთი ტიპის მონაცემების გამოხატვა სხვა ტიპის მონაცემებით. ბუნებრივი ადამიანური ენები სხვა არაფერია, თუ არა კონცეფციის კოდირების სისტემები სიტყვის საშუალებით აზრების გამოხატვისთვის. ენები მჭიდრო კავშირშია ანბანებთან (ენის კომპონენტების დაშიფვრის სისტემები გრაფიკული სიმბოლოების გამოყენებით). ისტორიამ იცის საინტერესო, თუმცა წარუმატებელი მცდელობები შექმნას "უნივერსალური" ენები და ანბანები. როგორც ჩანს, მათი განხორციელების მცდელობების წარუმატებლობა განპირობებულია იმით, რომ ეროვნულ და სოციალურ ფორმირებებს ბუნებრივად ესმით, რომ საჯარო მონაცემების კოდირების სისტემის ცვლილება აუცილებლად გამოიწვევს საზოგადოებრივი მეთოდების შეცვლას (ანუ იურიდიული და მორალური ნორმები). და ეს შეიძლება დაკავშირებული იყოს სოციალურ აჯანყებასთან.
უნივერსალური კოდირების ინსტრუმენტის იგივე პრობლემა საკმაოდ წარმატებით არის დანერგილი ტექნოლოგიის, მეცნიერებისა და კულტურის გარკვეულ დარგებში. მაგალითები მოიცავს მათემატიკური გამონათქვამების ჩაწერის სისტემას, ტელეგრაფის ანბანს, საზღვაო დროშის ანბანს, ბრაილის სისტემას უსინათლოთათვის და მრავალი სხვა.
კომპიუტერულ ტექნოლოგიასაც აქვს თავისი სისტემა - მას ორობითი კოდირება ჰქვია და ეფუძნება მონაცემთა წარმოდგენას მხოლოდ ორი სიმბოლოს თანმიმდევრობით: 0 და 1. ამ სიმბოლოებს ორობითი ციფრები ეწოდება, ინგლისურად - binaiy digit ან შემოკლებული bit (bit ).
ორი ცნება შეიძლება გამოიხატოს ერთ ბიტში: 0 ან 1 (დიახ ან არა, შავი ან თეთრი, ჭეშმარიტი ან მცდარი და ა.შ.). თუ ბიტების რაოდენობა ორამდე გაიზარდა, მაშინ უკვე შესაძლებელია ოთხი განსხვავებული ცნების გამოხატვა:
სამ ბიტს შეუძლია რვა განსხვავებული ცნების დაშიფვრა:
000 001 010 011 100 101 110 111
ანუ ბინარული კოდირების სისტემაში ციფრების ერთით გაზრდით, ჩვენ გავაორმაგებთ მნიშვნელობების რაოდენობას, რომელიც შეიძლება გამოისახოს ამ სისტემაში. ზოგადი ფორმულა:
სადაც N არის დამოუკიდებელი კოდირებული მნიშვნელობების რაოდენობა;
m არის ამ სისტემაში მიღებული ბინარული კოდირების ბიტის სიღრმე.
მონაცემთა წარმოდგენისა და გაზომვის უფრო დიდი ერთეული არის ბაიტი.
8 ბიტი - 1 ბაიტი
1024 ბაიტი - 1 კილობაიტი (კბ)
1024 კილობაიტი - 1 მეგაბაიტი (MB)
1024 მეგაბაიტი - 1 გიგაბაიტი (GB)
კომპიუტერის მიერ დამუშავებული მონაცემების ძირითადი ტიპები:
მთელი და რეალური რიცხვები.
ტექსტური მონაცემები.
გრაფიკული მონაცემები.
ხმის მონაცემები.
მთელი და რეალური რიცხვების კოდირება
მთელი რიცხვები დაშიფრულია ბინარულ კოდში საკმაოდ მარტივად - უბრალოდ აიღეთ მთელი რიცხვი და გაყავით იგი შუაზე, სანამ კოეფიციენტი არ იქნება ერთის ტოლი. ნაშთების სიმრავლე თითოეული გაყოფიდან, დაწერილი მარჯვნიდან მარცხნივ ბოლო კოეფიციენტთან ერთად, ქმნის ათობითი რიცხვის ორობით ანალოგს:
ასე რომ, 19 10 = 100112.
0-დან 255-მდე მთელი რიცხვების დაშიფვრისთვის საკმარისია ორობითი კოდის 8 ბიტი (8 ბიტი). თექვსმეტი ბიტი საშუალებას გაძლევთ დაშიფვროთ მთელი რიცხვები 0-დან 65535-მდე, ხოლო 24 ბიტი - 16,5 მილიონზე მეტი სხვადასხვა მნიშვნელობის.
რეალური რიცხვები დაშიფრულია 80-ბიტიანი კოდირებით. ამ შემთხვევაში, რიცხვი პირველად გარდაიქმნება ნორმალიზებულ ფორმაში:
3,1415926=0,31415926*10 1
300 000 = 0,3*10 6
123 456 789 = 0,123456789*10 10
ნომრის პირველ ნაწილს ეძახიან მანტისა და მეორე - დამახასიათებელი . 80 ბიტიდან უმეტესი ნაწილი გამოყოფილია მანტისას შესანახად (ნიშანთან ერთად) და გარკვეული ფიქსირებული რაოდენობის ბიტი გამოიყოფა მახასიათებლის შესანახად (ასევე ხელმოწერილი).
ტექსტური მონაცემების კოდირება
თუ ანბანის თითოეული სიმბოლო ასოცირდება გარკვეულ მთელ რიცხვთან (მაგალითად, სერიულ ნომერთან), მაშინ ბინარული კოდის დახმარებით შესაძლებელია ტექსტური ინფორმაციის დაშიფვრაც. რვა ბიტი საკმარისია 256 სხვადასხვა სიმბოლოს დაშიფვრისთვის. ეს საკმარისია იმისათვის, რომ გამოვხატოთ რვა ბიტის სხვადასხვა კომბინაციით ინგლისური და რუსული ენების ყველა სიმბოლო, როგორც მცირე, ასევე დიდი, ასევე პუნქტუაციის ნიშნები, ძირითადი არითმეტიკული მოქმედებების სიმბოლოები და ზოგიერთი ზოგადად მიღებული სპეციალური სიმბოლო, როგორიცაა სიმბოლო "§ ".
ტექნიკურად, ეს ძალიან მარტივია, მაგრამ ყოველთვის იყო საკმაოდ მნიშვნელოვანი ორგანიზაციული სირთულეები. კომპიუტერული ტექნოლოგიების განვითარების ადრეულ წლებში ისინი დაკავშირებული იყო საჭირო სტანდარტების ნაკლებობასთან, ახლა კი ისინი გამოწვეულია, პირიქით, ერთდროულად მოქმედი და ურთიერთსაწინააღმდეგო სტანდარტების სიმრავლით. იმისთვის, რომ მთელმა მსოფლიომ ტექსტური მონაცემების ანალოგიურად დაშიფვრა, საჭიროა კოდირების ერთიანი ცხრილები და ეს ჯერ კიდევ შეუძლებელია ეროვნული ანბანის სიმბოლოებს შორის წინააღმდეგობებისა და კორპორატიული წინააღმდეგობების გამო.
ინგლისური ენისთვის, რომელმაც დე ფაქტო დაიპყრო კომუნიკაციის საერთაშორისო საშუალების ნიშა, წინააღმდეგობები უკვე მოიხსნა. აშშ-ს სტანდარტების ინსტიტუტმა (ANSI - ამერიკული ეროვნული სტანდარტების ინსტიტუტი) დანერგა ASCII (American Standard Code for Information Interchange) კოდირების სისტემა. ASCII სისტემას აქვს ორი კოდირების ცხრილი - ძირითადი და გაფართოებული. საბაზო ცხრილი აფიქსირებს კოდის მნიშვნელობებს 0-დან 127-მდე, ხოლო გაფართოებული ცხრილი ეხება სიმბოლოებს 128-დან 255-მდე რიცხვებით.
საბაზისო ცხრილის პირველი 32 კოდი, ნულიდან დაწყებული, გადაეცა ტექნიკის მწარმოებლებს (პირველ რიგში კომპიუტერების და საბეჭდი მოწყობილობების მწარმოებლებს). ეს ზონა შეიცავს ეგრეთ წოდებულ საკონტროლო კოდებს, რომლებიც არ შეესაბამება რომელიმე ენის სიმბოლოს და, შესაბამისად, ეს კოდები არ არის ნაჩვენები არც ეკრანზე და არც საბეჭდ მოწყობილობებზე, მაგრამ მათი კონტროლი შესაძლებელია სხვა მონაცემების გამოტანის გზით.
32 კოდიდან დაწყებული 127 კოდამდე, არსებობს ინგლისური ანბანის სიმბოლოების, პუნქტუაციის ნიშნების, რიცხვების, არითმეტიკული ოპერაციების და ზოგიერთი დამხმარე სიმბოლოს კოდები. ძირითადი ASCII კოდირების ცხრილი ნაჩვენებია ცხრილში 1.1:
|
ცხრილი 1.1. |
ბაზის კოდირების ცხრილიASCIIASCII |
||||||||||
|
32 ჩაის ადგილი |
|||||||||||
|
44 , |
|||||||||||
|
დოკუმენტი ლექცია ნომერი 4. კოდირება მონაცემებიორობითი კოდი მუშაობის ავტომატიზაციისთვის მონაცემებისხვადასხვა ტიპის კუთვნილება ძალიან მნიშვნელოვანია... როგორც წესი, ისინი იყენებენ ხრიკს კოდირება, ე.ი. გამოხატულება მონაცემებიერთი ტიპის მეშვეობით მონაცემებისხვადასხვა ტიპის. მაგალითები... ეს შექმნა (ინსტრუქცია / faq) მუდმივად დაემატება და რედაქტირდება. თქვენ შეგიძლიათ დატოვოთ თქვენი სურვილები, რეკომენდაციები, აღწერილობები, კომენტარები ფორუმზე ან დამიკავშირდეთ საკონტაქტო ფორმის საშუალებით.ინსტრუქციაადამიანების უმეტესობის მოსმენა. Theმეთოდი ეწოდება კოდირებააღქმა. როგორც ითქვა... თქვენ უნდა მიიღოთ ერთი, შემდეგ კოდირება. Theმენიუს ელემენტი იწვევს ამომხტარ ფანჯარას... - მაშინ ეს არის აღდგენის სქემა მონაცემებისაწყისი კოდირებულიმათი მიწოდების გზა... ეს სახელმძღვანელო შეიცავს ინფორმატიკის მთელ კურსს, რომელიც აუცილებელია უმაღლესი განათლების სისტემაში სპეციალისტების მომზადებისთვის. სოფლის თემატური სტრუქტურაესესაჭირო ინფორმაცია. 1.3. Შესრულება ( კოდირება) მონაცემები 1.3.1. რიცხვითი სისტემები არსებობს სხვადასხვა ... ინფორმაცია 6 1.1.4. საინფორმაციო პროცესები 9 1.3. Შესრულება ( კოდირება) მონაცემები 10 1.3.1. რიცხვითი სისტემები 10 1.3.2. Შესრულება... ფიზიკური კოდირებადოკუმენტი... კოდირებადა ლოგიკური კოდირებაჩამოაყალიბეთ სისტემა კოდირებაყველაზე დაბალი დონე. სისტემები კოდირებასისტემები კოდირება მონაცემები... ყველაზე ხშირად გამოყენებული სისტემები კოდირება: NRZ (არა ... 1. ინფორმაციის კოდირების ცნება. ინფორმაციის დისკრეტული (ციფრული) წარმოდგენის უნივერსალურობა. პოზიციური და არაპოზიციური რიცხვითი სისტემები. ალგორითმებიდოკუმენტიმნიშვნელობის გამო მოცემულიპროცესი, მას აქვს სპეციალური სახელი - კოდირებაინფორმაცია. კოდირებაინფორმაცია არაჩვეულებრივია... მიეცით დისკრეტული მეთოდების მაგალითები კოდირება მონაცემები: ტექსტები, გრაფიკა, ხმა. Შენახვა... | |||||||||||
მონაცემებთან მუშაობის ავტომატიზაციისთვის გამოიყენება სპეციალური ტიპის მოწყობილობები, რომლებსაც კომპიუტერები ეწოდება.
კომპიუტერი არის უნივერსალური ტექნიკური სისტემა, მისი კონფიგურაცია შეიძლება მოქნილად შეიცვალოს საჭიროებისამებრ.
7. კომპიუტერის პერიფერიული მოწყობილობები
ამ პრობლემის გადაწყვეტა ეფუძნება osi (ღია სისტემის ურთიერთდაკავშირების) მოდელს
ინტერნეტი არის ურთიერთდაკავშირება, რომელიც არის ხერხემლის (ზურგის) ქსელების კავშირი
ჰიპერტექსტის ინფორმაციის გაცვლის პროტოკოლი
12 ალგორითმის კონცეფცია
13. ობიექტზე ორიენტირებული პროგრამირება. 13 ობიექტზე ორიენტირებული მიდგომა
§ 2 მონაცემთა და ინფორმაციის კოდირება
მონაცემები ინფორმაციის დიალექტიკური სამშენებლო ბლოკია. ისინი რეგისტრირებული სიგნალებია.
ამავდროულად, ნებისმიერი მ/ვ-ის ჩაწერის ფიზიკური მეთოდი (მოძრავი ფიზიკური სხეულები ან ზედაპირის პარამეტრები, ელექტრული, მაგნიტური ან ოპტიკური მახასიათებლების შეცვლა, ქიმიური შემადგენლობა და ა.შ.)
რეგისტრაციის მეთოდის მიხედვით, მონაცემების შენახვა და ტრანსპორტირება შესაძლებელია სხვადასხვა ტიპის მედიაზე.
ამავე დროს, გასათვალისწინებელია, რომ ინფორმაციის თვისებები მჭიდრო კავშირშია მისი მატარებლების თვისებებთან.
ჩვეულებრივი მომხმარებლისთვის, წიგნში ინფორმაციის ხელმისაწვდომობა შესამჩნევად უფრო მაღალია, ვიდრე იგივე ინფორმაცია CD-ზე, რადგან ყველას არ აქვს ეს მოწყობილობა.
მონაცემთა ოპერაციები
საინფორმაციო პროცესის დროს მონაცემთა ტრანსფორმაცია ხდება ერთი ტიპიდან მეორეზე მეთოდების გამოყენებით.
მონაცემთა დამუშავება მოიცავს მრავალ განსხვავებულ ოპერაციას, რომელთაგან შეიძლება გამოიყოს შემდეგი:
მონაცემთა შეგროვება - ინფორმაციის დაგროვება გადაწყვეტილების მიღებისათვის საკმარისი ინფორმაციის მიწოდების მიზნით
მონაცემთა ფორმალიზაცია არის სხვადასხვა წყაროდან შემოსული მონაცემების დაქვეითება ერთსა და იმავე ფორმაზე, რათა მოხდეს ისინი ერთმანეთთან შედარებით, ანუ გაიზარდოს მათი ხელმისაწვდომობის დონე.
მონაცემთა გაფილტვრა - არასაჭირო მონაცემების გაფილტვრა, რომელიც არ არის აუცილებელი გადაწყვეტილების მისაღებად; ამ შემთხვევაში ხმაურის დონე უნდა შემცირდეს, ხოლო მონაცემების სანდოობა და ადეკვატურობა უნდა გაიზარდოს.
მონაცემთა დახარისხება - მონაცემების დალაგება მოცემული ატრიბუტის მიხედვით მარტივად გამოყენების მიზნით, რაც ზრდის ინფორმაციის სანდოობას
მონაცემთა არქივირება არის მონაცემთა შენახვის ორგანიზება მოსახერხებელი და ხელმისაწვდომი ფორმით, ის ემსახურება მონაცემთა შენახვის ეკონომიკური ხარჯების შემცირებას და ზრდის ინფორმაციის პროცესის მთლიან საიმედოობას.
მონაცემთა დაცვა - ღონისძიებების ერთობლიობა, რომელიც მიზნად ისახავს მონაცემთა დაკარგვის, რეპროდუქციისა და მოდიფიკაციის უზრუნველყოფას
მონაცემთა ტრანსპორტირება - ინფორმაციის მიღება და გადაცემა ინფორმაციის პროცესის დისტანციურ მონაწილეებს შორის; ამ შემთხვევაში, მონაცემთა წყაროს ჩვეულებრივ უწოდებენ სერვერს, ხოლო მომხმარებელს ეწოდება კლიენტი.
მონაცემთა ტრანსფორმაცია - მონაცემთა გადაცემა ერთი ფორმიდან მეორეში ან ერთი სტრუქტურიდან მეორეში
მონაცემთა ორობითი კოდირება
………………………………………………………………………………
სხვადასხვა ტიპს მიეკუთვნება, ძალიან მნიშვნელოვანია მათი წარმოდგენის ფორმის გაერთიანება.
ამისათვის ჩვეულებრივ გამოიყენება კოდირების ტექნიკა, ანუ ერთი ტიპის მონაცემების გამოხატვა სხვა ტიპის მონაცემებით. მაგალითებია მათემატიკური დამწერლობის სისტემა, ტელეგრაფის ანბანი, ბრაილის სისტემა უსინათლოთათვის, საზღვაო დროშის ანბანი და ა.შ.
კომპიუტერულ ტექნოლოგიასაც აქვს თავისი სისტემა - მას ორობითი კოდირება ეწოდება და ეფუძნება მონაცემების წარმოდგენას მხოლოდ ორი სიმბოლოს 0 და 1-ის თანმიმდევრობით.
ამ სიმბოლოებს ეწოდება ორობითი ციფრები (ინგლისურად ორობითი ციფრი) ან შემოკლებით ბიტი 1 ბიტი.
ერთი ბიტი m/b გამოხატავს ორ ცნებას: 0 ან 1, დიახ ან არა, შავი ან თეთრი, ჭეშმარიტი ან მცდარი და ა.შ. დ.
თუ ბიტების რაოდენობა გაიზარდა 2-მდე, მაშინ უკვე შესაძლებელია ოთხი განსხვავებული ცნების გამოხატვა.
სამ ბიტს შეუძლია რვა განსხვავებული მნიშვნელობის დაშიფვრა: 000 001 010 011 100 101 110 111
ორობით კოდირების სისტემაში ციფრების ერთით გაზრდით, მნიშვნელობების რაოდენობა, რომლებიც m/b არის გამოხატული ამ სისტემაში, იზრდება 2-ჯერ, ზოგადი ფორმულა ასე გამოიყურება:
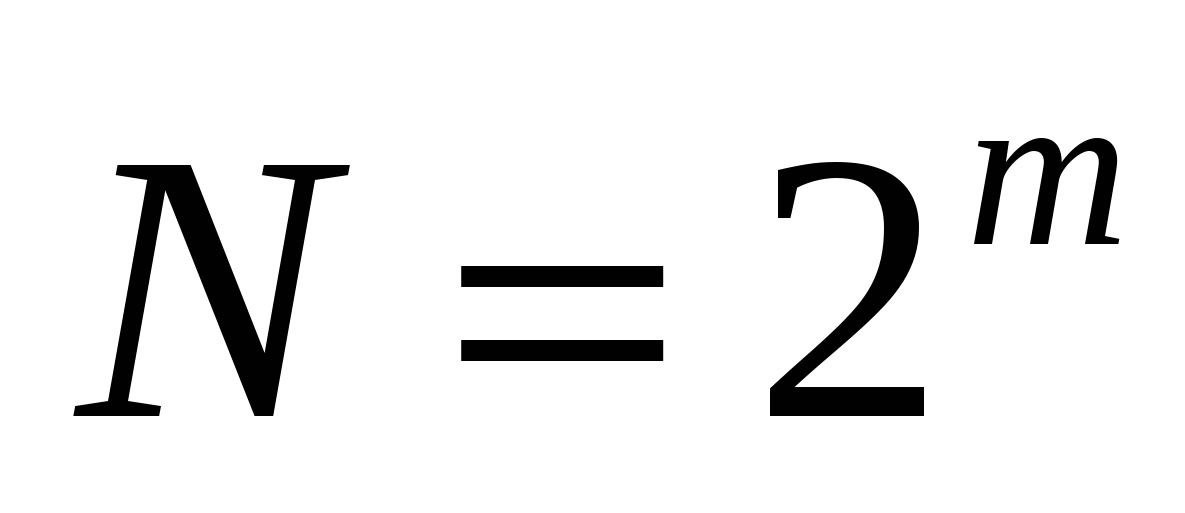
სადაც N არის დამოუკიდებელი კოდირებული მნიშვნელობების რაოდენობა
M - ამ სისტემაში მიღებული ორობითი კოდირების ბიტის სიღრმე
მთელი და რეალური რიცხვების კოდირება
მთელი რიცხვები დაშიფრულია ორობით კოდში, შემდეგნაირად: მთელი რიცხვი აღებულია და იყოფა ნახევრად, სანამ ნაშთი არ იქნება ნული ან ერთი.
ნაშთების სიმრავლე თითოეული გაყოფიდან, დაწერილი მარჯვნიდან მარცხნივ, ბოლო ნაშთთან ერთად, ქმნის ათობითი რიცხვის ორობით ანალოგს.
ანუ 19 10 = 10011 2
მთელი რიცხვების 0-დან 255-მდე დაშიფვრისთვის საკმარისია გქონდეთ 8 ბიტიანი ორობითი კოდი (8 ბიტი)
16 ბიტი საშუალებას გაძლევთ დაშიფვროთ მთელი რიცხვები 0-დან 65535-მდე
24 ბიტი - უკვე 16,5 მილიონზე მეტი განსხვავებული მნიშვნელობა.
რეალური რიცხვები დაშიფრულია 80-ბიტიანი კოდირებით.
ამ შემთხვევაში, რიცხვი პირველად გარდაიქმნება ნორმალიზებულ ფორმაში:
3,1415926 = 0,31415926 * 10 1
300000 = 0,3 * 10 6
123456789 = 0,123456789 * 10 10
რიცხვის პირველ ნაწილს ჰქვია,,,, - დამახასიათებელი. 80 ბიტიდან უმეტესი ნაწილი გამოყოფილია მანტისას ხელმოწერილ სივრცეში შესანახად, ხოლო ზოგიერთი გაფანტული ბიტი გამოყოფილია 10 სიმბოლოს მახასიათებლის შესანახად.
ტექსტური მონაცემების კოდირება
თუ ანბანის თითოეული სიმბოლო ასოცირდება გარკვეულ მთელ რიცხვთან (სერიულ ნომერთან), მაშინ ბინარული კოდის გამოყენებით შეგიძლიათ ტექსტური ინფორმაციის დაშიფვრა. რვა ორობითი სიმბოლოები 256 სხვადასხვა სიმბოლოს დაშიფვრა. ინგლისური ენისთვის აშშ-ს სტანდარტების ინსტიტუტმა (ANSI - American National Standard Institute) დანერგა ASCII (American Standard Code for Information Interchange) კოდირების სისტემა - აშშ-ს სტანდარტული კოდი ინფორმაციის გაცვლისთვის.
ASCII სისტემაში არის ორი ……. კოდირება - ძირითადი და მოწინავე. საბაზისო ცხრილი აფიქსირებს კოდების მნიშვნელობას 0-დან 127-მდე, ხოლო გაფართოებული ცხრილი ეხება სიმბოლოებს 128-დან 255-მდე რიცხვებით.
პირველი 32 საბაზისო ცხრილის კოდი გადაეცემა ტექნიკის მწარმოებლებს. ეს ტერიტორია შეიცავს დ. ა. საკონტროლო კოდები, რომლებიც არ შეესაბამება რომელიმე ენის სიმბოლოს.
ეს კოდები არ ჩანს ეკრანზე ან საბეჭდ მოწყობილობებზე, მაგრამ ისინი აკონტროლებენ სხვა მონაცემების გამოტანას.
ASCII-ის გარდა, არსებობს ისეთი დაშიფვრები, როგორიცაა KON - 8 (ინფორმაციის გაცვლის კოდი, 8 ციფრი), Windows კოდირება, ISO კოდირება, UNICODE, GOST - ალტერნატიული კოდირება.
სურათის მონაცემების კოდირება
თუ გაზრდით ბ/წ გრაფიკული სურათებიგაზეთში ან წიგნში დაბეჭდილი, ხედავთ, რომ იგი შედგება პატარა წერტილებისგან, რომლებიც ქმნიან დამახასიათებელ ნიმუშს, რომელსაც რასტრს უწოდებენ.
ვინაიდან თითოეული წერტილის წრფივი კოორდინატები და ფერი შეიძლება გამოისახოს მთელი რიცხვების გამოყენებით, შეიძლება ითქვას, რომ რასტრული კოდირება იყენებს ორობით კოდს გრაფიკული მონაცემების წარმოსადგენად.
ფერადი სურათების კოდირებისთვის გამოიყენება თვითნებური ფერის ძირითად კომპონენტებად დაშლის პრინციპი.
როგორც ასეთი კომპონენტები, გამოიყენება 3 ძირითადი ფერი:
წითელი (წითელი, R)
მწვანე (მწვანე, G)
ლურჯი (ლურჯი, B)
ასეთი კოდირების სისტემას უწოდებენ RGB სისტემას, ფერების სახელების პირველი ასოების მიხედვით.
ფერადი გრაფიკის კოდირებას 16 ბიტიანი ორობითი რიცხვებით ეწოდება მაღალი ფერის რეჟიმი. ხოლო ფერადი გრაფიკის პრეზენტაციის რეჟიმს 24 ბინარული ციფრის გამოყენებით ეწოდება ფერი-ფერი (…………).

