29.01.2019
データをバイナリコードでエンコードします。 データのエンコーディング
異なる種類に属するデータの処理を自動化するには、その表示形式を統一することが非常に重要です。このために、通常、この手法が使用されます。 コーディング、つまり、あるタイプのデータを別のタイプのデータで表現します。 自然な人間 言語 -それらは、音声を通じて思考を表現するための概念コーディング システムにすぎません。 舌にぴったりと隣接 ABCの(グラフィックシンボルを使用して言語コンポーネントをコーディングするためのシステム)。 歴史は、「普遍的な」言語とアルファベットを作成する試みが失敗に終わったにもかかわらず、興味深いことを知っています。 どうやら、それらを実装する試みが失敗したのは、国家的および社会的主体が、公共データのコーディングシステムを変更することは確実に社会的方法(つまり、法的および道徳的規範)の変更につながることを自然に理解しているという事実によるものです。社会的混乱に関連している可能性があります。
ユニバーサル コーディング ツールの同じ問題が、技術、科学、文化の特定の分野で非常にうまく実装されています。 例には、数式を書くためのシステム、電信アルファベット、海軍旗アルファベット、視覚障害者のための点字システムなどが含まれます。
コンピューター技術にも独自のシステムがあります。それは、 バイナリコーディングこれは、データを 0 と 1 の 2 文字だけのシーケンスとして表現することに基づいています。これらの文字は次のように呼ばれます。 2進数、英語で - 2進数または略して ヒット(ビット)。
1 ビットで 0 または 1 の 2 つの概念を表現できます。 (はいまたは いいえ、黒ですまたは 白、真実または 嘘等々。)。 ビット数を 2 に増やすと、次の 4 つの異なる概念を表現できます。
3 ビットで 8 つの異なる値をエンコードできます。
000 001 010 011 100 101 110 111
システムの桁数を 1 つ増やす バイナリコーディング、与えられたシステムで表現できる値の数を 2 倍にします、つまり、 一般式の形式は次のとおりです。
どこ N-独立したコード化された値の数。
た -このシステムで採用されているバイナリコーディングのビット深度。
整数と実数のエンコード
整数は非常に簡単にバイナリでエンコードされます。整数を取得し、商が 1 になるまで半分で割るだけです。 最後の商とともに右から左に書かれた各除算の余りのセットは、10 進数の 2 進数の類似物を形成します。
したがって、19= 10011; となります。
0 ~ 255 の整数をエンコードするには、8 ビットのバイナリ コード (8 ビット) があれば十分です。 16 ビットでは 0 ~ 65,535 の整数をエンコードでき、24 ビットでは 1,650 万を超える異なる値をエンコードできます。
実数をエンコードするには、80 ビット エンコードが使用されます。 この場合、数値は最初に次のように変換されます。 正規化された形式:
3,1415926 =0,31415926-10"
300 000 = 0,3 10 6
123 456 789 = 0,123456789 10 10
数値の最初の部分は次のように呼ばれます。 仮数、そして二番目 - 特性。 80 ビットの大部分は仮数 (符号とともに) を格納するために割り当てられ、特定の固定数のビットが特性 (これも符号付き) を格納するために割り当てられます。
テキストデータのエンコード
アルファベットの各文字が特定の整数 (シリアル番号など) に関連付けられている場合は、バイナリ コードを使用してテキスト情報をエンコードすることもできます。 256 個の異なる文字をエンコードするには、2 進数 8 桁で十分です。 これは、英語とロシア語のすべての文字 (小文字と大文字の両方)、句読点、基本的な算術演算の記号、一般に受け入れられている特殊文字 (記号「§」など) を 8 ビットのさまざまな組み合わせで表現するのに十分です。 ”。
技術的には非常に単純に見えますが、組織的には常に非常に大きな問題がありました。 コンピュータ技術の開発の初期には、これらは必要な標準の欠如と関連付けられていましたが、今日では逆に、同時に存在する矛盾した標準が豊富に存在することが原因となっています。 全世界が同じ方法でテキスト データをエンコードするには、統一されたエンコード テーブルが必要ですが、国のアルファベット間の矛盾や企業の矛盾により、これはまだ実現できません。
事実上、国際コミュニケーション手段のニッチな地位を獲得している英語にとって、矛盾はすでに取り除かれています。 米国規格協会 (ANSI - 米国規格協会)コーディングシステムを導入しました ASCII (American Standard Code for Information Interchange - 情報交換用の米国標準コード)。システム内 アスキー 2 つのコーディング テーブルが固定されています - 基本的なそして 延長されました。基本テーブルは0から127までのコード値を固定し、拡張テーブルは128から255までの番号を持つ文字を参照します。
ベース テーブルの最初の 32 コードは 0 で始まり、ハードウェア メーカー (主にコンピュータおよび印刷装置のメーカー) に与えられます。 この領域には、いわゆる 制御コード、これはどの言語記号にも対応しないため、これらのコードは画面にも印刷装置にも表示されませんが、他のデータの出力方法を制御できます。
コード 32 からコード 127 までには、英語のアルファベットの文字、句読点、数字、算術演算、およびいくつかの補助文字のコードがあります。
テキスト データをエンコードする同様のシステムが他の国でも開発されています。 たとえば、ソ連では、KOI-7 コーディング システムがこの地域で運用されていました。 (情報交換コード、7 桁)。ただし、ハードウェアおよびソフトウェアのメーカーからのサポートにより、アメリカのコードがもたらされました。 アスキー国際標準のレベルまで引き上げられ、各国のコーディング システムは、コードの意味を 128 から 255 まで定義する、コーディング システムの第 2 の拡張部分に「後退」する必要がありました。この分野における統一標準の欠如により、多数の同時エンコード。 ロシアでのみ、3 つの現在のエンコード標準とさらに 2 つの古いエンコード標準を示すことができます。
たとえば、エンコーディングとして知られるロシア語の文字エンコーディング Windows-1251、はマイクロソフトによって「外部から」導入されましたが、ロシアでは同社のオペレーティング システムやその他の製品が広く配布されていたため、深く定着し、広く使用されました。 このエンコーディングは、Windows プラットフォームで実行されているほとんどのローカル コンピューターで使用されます。
もう 1 つの一般的なエンコーディングは KOI-8 と呼ばれます。 (情報交換コード、8桁) -その起源は、東ヨーロッパ諸国相互経済援助評議会の時代にまで遡ります。 現在、KOI-8 エンコーディングはロシアのコンピュータ ネットワークおよびロシアのインターネット分野で広く使用されています。
ロシア語のアルファベットの文字のエンコーディングを規定する国際標準は、エンコーディングと呼ばれます。 ISO (国際標準化機構 - 国際標準化研究所)。実際には、このエンコーディングが使用されることはほとんどありません。
で実行されているコンピュータ上で オペレーティングシステム MS-DOSさらに 2 つのエンコーディングが有効である可能性があります (エンコーディング ゲストエンコーディング GOST 代替)。前者はパーソナル コンピューティングの出現の初期でも時代遅れであると考えられていましたが、後者は現在でも使用されています。
ロシアでは多数のテキスト データ エンコード システムが運用されているため、システム間のデータ変換の問題が発生します。これはコンピュータ サイエンスの一般的な問題の 1 つです。
ユニバーサルテキストデータエンコーディングシステム
創造に伴う組織的な困難を分析すると、 統一システムテキスト データをエンコードしていると、それらは限られたコード セット (256) によって引き起こされていると結論付けることができます。 同時に、たとえば文字を 8 ビット以外でエンコードすると、 2進数、桁数の多い数字を使用すると、可能なコード値の範囲がさらに大きくなります。 16 ビット文字エンコーディングに基づくこのシステムは、 ユニバーサル - UNICODE。 16 桁により、65,536 の異なる文字に一意のコードを提供できます。このフィールドは、地球上のほとんどの言語を 1 つの文字テーブルに収容するのに十分です。
このアプローチの自明性は自明であるにもかかわらず、このシステムへの単純な機械的移行は、 長い間コンピュータリソース(コーディングシステム)が不十分なため、実行が保留されました。 ユニコードすべてのテキスト文書は自動的に 2 倍の長さになります)。 90 年代後半には、技術的手段がリソースの提供に必要なレベルに達し、今日ではドキュメントとソフトウェアがユニバーサル コーディング システムに徐々に移行されつつあります。 個人ユーザーにとっては、異なるコーディングシステムで作成された文書とソフトウェアとの連携にさらなる不安が加わりましたが、これは過渡期の困難であると理解する必要があります。
グラフィックスデータのエンコーディング
新聞や本に印刷された白黒のグラフィック画像を虫眼鏡で見ると、それが小さな点で構成されており、「」と呼ばれる特徴的なパターンを形成していることがわかります。 ラスター(図1)。
米。 1. ラスターは、印刷業界で長い間受け入れられてきたグラフィック情報をエンコードする方法です。
線形座標と各点の個々の特性 (明るさ) は整数を使用して表現できるため、ラスター コーディングではバイナリ コードを使用してグラフィック データを表現できると言えます。 現在、白黒イラストは256階調の点の組み合わせで表現するのが一般的です。 グレーしたがって、通常、任意の点の明るさをエンコードするには 8 ビットの 2 進数で十分です。
カラーグラフィックスのエンコードに使用されます 分解原理メインコンポーネントのランダムな色。 このような要素として 3 原色が使用されます: 赤 (赤、R)、緑 (グリーン、G)そして青 (青、B)。実際には、人間の目に見えるあらゆる色は、これらの 3 原色を機械的に混合することによって得られると考えられています (理論的には完全に真実ではありませんが)。 このコーディングシステムはシステムと呼ばれます RGB原色の名前の最初の文字で表します。
ハーフトーンの白黒画像で一般的に行われているように、各主要コンポーネントの明るさをエンコードするために 256 の値 (8 つのバイナリ ビット) が使用される場合、1 つのポイントのカラーをエンコードするには 24 ビットを費やす必要があります。 同時に、このコーディング システムは、実際の感度に近い 1,650 万色の異なる色を明確に識別します。 人間の目。 24 バイナリ ビットを使用してカラー グラフィックスを表現するモードは、と呼ばれます。 フルカラー(トゥルーカラー)。
各原色は追加の色、つまり原色を白に補う色と関連付けることができます。 どの原色でも、補色は他の原色のペアの合計によって形成される色であることが簡単にわかります。 したがって、追加の色は次のとおりです: 青 (シアン、S)、紫 (マゼンタ、M)そして黄色( 黄色、Y)。任意の色をその構成成分に分解する原理は、原色だけでなく追加の色にも適用でき、あらゆる色をシアン、マゼンタ、イエローの成分の和として表現できます。 この色分け方法は印刷で受け入れられていますが、印刷では 4 番目のペイントである黒も使用されます。 (ブラック、K)。したがって、このコーディング システムは 4 つの文字で指定されます。 CMYK(黒色は文字で示されています) に、なぜならその手紙は ですでに青で占められています)、このシステムでカラー グラフィックスを表現するには、32 バイナリ ビットが必要です。 このモードはとも呼ばれます フルカラー。 (天然色)。
各ポイントの色のエンコードに使用されるバイナリ ビットの数を減らすと、データ量を減らすことができますが、エンコードされる色の範囲は大幅に減少します。 カラー グラフィックスを 16 ビット 2 進数でエンコードすることをモードと呼びます。 ハイカラー。
色情報が 8 データ ビットを使用してエンコードされる場合、伝達できる色調は 256 色のみです。 この色分け方法はと呼ばれます 索引。この名前の意味は、256 個の値では人間の目で認識できる色の範囲全体を伝えるには完全に不十分であるため、各ラスター ポイントのコードは色自体を表すのではなく、その番号のみを表すということです。 (インデックス)と呼ばれるいくつかのルックアップテーブル パレット。もちろん、このパレットはグラフィック データに添付する必要があります。これがないと、画面や紙上で情報を再現する方法を使用することはできません(つまり、もちろん使用できますが、データが不完全であるため) 、受け取った情報は適切ではありません。木の葉は赤く、空は緑になる可能性があります)。
音声情報のエンコード
オーディオ情報を扱うための技術と方法は、ごく最近になってコンピューター技術に導入されました。 さらに、数値データ、テキスト データ、グラフィック データとは異なり、サウンド レコーディングには、同じように長く証明されたコーディング履歴がありません。 その結果、バイナリ コードを使用してオーディオ情報をエンコードする方法は標準化からはほど遠いです。 多くの個々の企業が独自の企業標準を開発していますが、一般的には 2 つの主要な領域に区別できます。
FM方式 (周波数変調)これは、理論的には、あらゆる複雑な音をさまざまな周波数の単純な高調波信号のシーケンスに分解でき、それぞれが正弦波を表すため、数値パラメータ、つまりコードで記述することができるという事実に基づいています。 自然界では、音声信号は連続スペクトルを持ち、つまりアナログです。 それらを高調波系列に分解し、離散デジタル信号の形式で表現することは、特別なデバイスによって実行されます。 アナログデジタルコンバーター (ADC)。数値的にエンコードされた音声を再現するための逆変換が実行されます。 デジタルアナログコンバーター (DAC)。このような変換では、エンコード方法に関連する情報の損失は避けられないため、録音の品質は通常完全に満足のいくものではなく、電子音楽の色彩特性を持つ最も単純な電気楽器の音質に相当します。 同時に、このコーディング方法は非常にコンパクトなコードを提供するため、コンピューターのリソースが明らかに不足していた時代でも使用されていました。
テーブルウェーブ法 ( ウェーブテーブル)合成は現在の技術開発レベルによく対応しています。 簡単に言うと、事前に用意されたテーブルのどこかに、さまざまな楽器 (楽器に限らず) のサウンドのサンプルが保存されていると言えます。 テクノロジーでは、このようなサンプルは次のように呼ばれます。 サンプル。数値コードは、楽器の種類、モデル番号、ピッチ、音の長さと強さ、その変化のダイナミクス、音が発生する環境のいくつかのパラメーター、および音の特性を特徴付けるその他のパラメーターを表します。 本物の音をサンプルとして使用しているため、合成結果として得られる音の品質は非常に高く、本物の楽器の音質に近づきます。
基本的なデータ構造
大規模なデータセットの操作は、データが 順序付けられました、つまり、それらは特定の構造を形成します。 データ構造には主に 3 つのタイプがあります。 線形、階層的そして 表形式。一般的な書籍を例にして考えてみましょう。
本を別々のシートに分解したり、混ぜたりすると、本の目的が失われてしまいます。 これは依然としてデータのセットを表しますが、そこから情報を抽出する適切な方法を見つけるのは非常に困難です。 (本から各文字を個別に切り取った場合、状況はさらに悪化します。この場合、それを読むための適切な方法が存在する可能性はほとんどありません。)
本のすべてのシートを正しい順序で収集すると、最も単純なデータ構造が得られます。 線形。このような本はすでに読むことができますが、必要なデータを見つけるには最初から続けて読む必要があり、必ずしも便利ではありません。
データをすばやく検索するには、 階層構造。したがって、たとえば、本は部分、セクション、章、段落などに分割されます。下位レベルの構造の要素は、上位レベルの構造の要素に含まれています。つまり、セクションは章、章の段落などで構成されます。
大規模な配列の場合、階層構造でのデータの検索は線形構造でのデータ検索よりもはるかに簡単ですが、ここでもデータを検索する必要があります。 ナビゲーション、見る必要性に関連しています。 実際には、ほとんどの本には補助断面があるという事実により、このタスクは単純化されます。 テーブル、階層構造の要素を線形構造の要素と接続します。つまり、セクション、章、段落をページ番号で接続します。 順番に読むように設計された単純な階層構造を持つ書籍では、このテーブルは通常、 目次、選択的に読むことを可能にする複雑な構造を持つ本では、それはと呼ばれます コンテンツ。
1.6. データとそのコーディング
記憶媒体
データは情報の弁証法的な構成要素です。 それらは記録された信号を表します。 この場合、物理的な登録方法は、物体の機械的な動き、形状や表面品質パラメータの変化、電気的、磁気的、 光学特性, 化学組成そして(または)化学結合の性質、電子システムの状態の変化など。
記録方法に応じて、データはさまざまな種類のメディアに保存および転送できます。 最も一般的な記憶媒体は、最も経済的ではありませんが、紙のようです。 紙には、その表面の光学特性を変化させることでデータが記録されます。 光学特性の変更 (特定の波長範囲での表面の反射率の変更) は、反射コーティングを施したプラスチック メディア (CD-ROM) にレーザー ビームで記録するデバイスでも使用されます。 磁気特性の変化を利用する媒体には、磁気テープや磁気ディスクなどがあります。 担体の表面物質の化学組成を変化させることによってデータを記録することは、写真撮影において広く使用されている。 生化学レベルでは、生きた自然の中でデータが蓄積され、伝達されます。
データキャリアは、それ自体ではなく、情報の特性がそのキャリアの特性と非常に密接に関連している限り、私たちの興味を引きます。 どの媒体も、解像度パラメーター (媒体に採用された測定単位で記録されるデータ量) とダイナミック レンジ (記録された最大信号と最小信号の振幅強度の対数比) によって特徴付けることができます。 完全性、アクセスしやすさ、信頼性などの情報の特性は、多くの場合、媒体の特性に依存します。 したがって、たとえば、CD 上にあるデータベースの方が、フロッピー磁気ディスク上にある同様の目的のデータベースよりも情報の完全性を確保するのが簡単であるという事実を当てにすることができます。単位長さあたりのデータ記録はパスの方がはるかに長くなります。 すべての消費者が必要な機器を持っているわけではないため、平均的な消費者にとって、本の中の情報の入手可能性は、CD 上の同じ情報よりも著しく高くなります。 そして最後に知られているのは、 映像効果透過光の輝度信号の範囲は反射光よりも 2 ~ 3 桁大きいため、プロジェクターでスライドを見た場合の輝度は、紙に印刷された同様のイラストを見る場合よりもはるかに大きくなります。
メディアを変更する目的でデータを変換するタスクは、コンピューター サイエンスにおいて最も重要なタスクの 1 つです。 コンピューティング システムのコスト構造では、ストレージ メディアと連携してデータを入出力するためのデバイスがハードウェアのコストの最大 2 分の 1 を占めます。
データ操作
情報処理中に、データはメソッドを使用してあるタイプから別のタイプに変換されます。 データ処理にはさまざまな操作が含まれます。 科学技術の進歩と人間社会のつながりの一般的な複雑化に伴い、データ処理にかかる人件費は着実に増加しています。 まず第一に、これは生産と社会を管理する条件が絶えず複雑化しているためです。 2 番目の要因も、処理されるデータ量の一般的な増加を引き起こしますが、これも科学技術の進歩、つまり、データの保存と配信の手段である新しいデータ キャリアの出現と実装の急速なペースに関連しています。
構造上 可能な操作データを使用すると、次の主なものを区別できます。
データ収集 - 意思決定のための情報の十分な完全性を確保するためのデータの蓄積。
データの形式化 - 異なるソースからのデータを同じ形式にまとめて、相互に比較できるようにする、つまりアクセシビリティのレベルを高めること。
データのフィルタリング - 意思決定に必要のない「余分な」データをフィルタリングして除外します。 同時に、「ノイズ」のレベルが減少し、データの信頼性と適切性が向上するはずです。
データの並べ替え - 使いやすくするために、指定された基準に従ってデータを並べ替えます。 情報の入手可能性が高まります。
データのグループ化 - 使いやすさを向上させるために、特定の特性に従ってデータを結合します。 情報の入手可能性が高まります。
データのアーカイブ - データ ストレージを便利で簡単にアクセスできる形式に整理します。 データストレージの経済的コストを削減し、情報プロセス全体の信頼性を向上させるのに役立ちます。
データ保護は、データの損失、複製、変更を防ぐことを目的とした一連の対策です。
データ転送 - 情報プロセスにおける遠隔参加者間でのデータの受信と送信 (配信と配信)。 この場合、コンピュータ サイエンスにおけるデータ ソースは通常サーバーと呼ばれ、消費者はクライアントと呼ばれます。
データ変換とは、あるフォームから別のフォームへ、またはある構造から別の構造へのデータの転送です。 データ変換にはメディアの種類の変更が含まれることがよくあります。たとえば、書籍は通常の紙の形式で保存できますが、これには電子形式やマイクロ写真フィルムを使用できます。 データを転送するときにも、特にこのタイプのデータの転送を目的としていない手段でデータ変換を実行する場合、データ変換を繰り返す必要性が生じます。 例として、電話ネットワークのチャネル (当初は狭い周波数範囲でのアナログ信号の送信のみに焦点を当てていた) を介してデジタル データ ストリームを転送するには、デジタル データを何らかの種類のデータに変換する必要があることが挙げられます。これは、特別なデバイスである電話モデムが行うことです。
ここに示した典型的なデータ操作のリストは完全ではありません。 世界中の何百万人もの人々がデータを作成、処理、変換、転送しており、各職場は社会、経済、産業、科学、文化のプロセスを管理するために必要な独自の特定の操作を実行しています。 可能な操作の完全なリストを作成することは不可能ですし、その必要もありません。 ここで、私たちにとってもう 1 つの結論が重要です。それは、情報の操作は非常に労力を要する場合があり、自動化する必要があるということです。
バイナリデータのエンコーディング
異なるタイプに属するデータの処理を自動化するには、それらの表現形式を統一することが非常に重要です。このために、通常、コーディングが使用されます。つまり、あるタイプのデータを別のタイプのデータで表現します。 人間の自然言語は、音声を通じて思考を表現するための概念コーディング システムにすぎません。 言語と密接な関係があるのは、アルファベット(グラフィック記号を使用して言語コンポーネントをコーディングするためのシステム)です。 歴史は、「普遍的な」言語とアルファベットを作成する試みが失敗に終わったにもかかわらず、興味深いことを知っています。 どうやら、それらを実装する試みが失敗したのは、国家的および社会的主体が、公共データのコーディングシステムを変更することは確実に社会的方法(つまり、法的および道徳的規範)の変更につながることを自然に理解しているという事実によるものです。社会的混乱に関連している可能性があります。
ユニバーサル コーディング ツールの同じ問題が、技術、科学、文化の特定の分野で非常にうまく実装されています。 例には、数式を書くためのシステム、電信アルファベット、海軍旗アルファベット、視覚障害者のための点字システムなどが含まれます。
米。 1.8. さまざまなコーディング システムの例
コンピューター技術にも独自のシステムがあります。これはバイナリ コーディングと呼ばれ、データを 0 と 1 の 2 文字だけのシーケンスとして表現することに基づいています。これらの文字は、英語ではバイナリ ディジット、つまりバイナリ ディジット、または短く言えばビットと呼ばれます。 。
1 つのビットは、0 または 1 (はいまたはいいえ、黒か白、真か偽など) の 2 つの概念を表現できます。 ビット数を 2 に増やすと、次の 4 つの異なる概念を表現できます。
3 ビットで 8 つの異なる値をエンコードできます。
000 001 010 011 100 101 110 111
バイナリコーディングシステムのビット数を 1 増やすことにより、このシステムで表現できる値の数が 2 倍になります。
整数と実数のエンコード
0 ~ 255 の整数をエンコードするには、8 ビットのバイナリ コード (8 ビット) があれば十分です。
……………….
16 ビットでは 0 ~ 65535 の整数をエンコードでき、24 ビットでは 1,650 万を超える異なる値をエンコードできます。
実数をエンコードするには、80 ビット エンコードが使用されます。 この場合、数値はまず正規化された形式に変換されます。
3.1415926 = 0.31415926 101
300,000 = 0.3 106
123,456,789 = 0.123456789 109
数値の最初の部分は仮数と呼ばれ、2 番目の部分は特性と呼ばれます。 80 ビットの大部分は仮数 (符号とともに) を格納するために割り当てられ、特定の固定数のビットが特性 (これも符号付き) を格納するために割り当てられます。
テキストデータのエンコード
アルファベットの各文字が特定の整数 (シリアル番号など) に関連付けられている場合は、バイナリ コードを使用してテキスト情報をエンコードすることもできます。 256 個の異なる文字をエンコードするには、2 進数 8 桁で十分です。 これは、英語とロシア語のアルファベットのすべての文字 (小文字と大文字の両方)、句読点、基本的な算術演算の記号、および「§」などの一般的に受け入れられている特殊文字を 8 ビットのさまざまな組み合わせで表現するのに十分です。シンボル。
技術的には非常に単純に見えますが、組織的には常に非常に大きな問題がありました。 コンピュータ技術の開発の初期には、これらは必要な標準の欠如と関連付けられていましたが、今日では逆に、同時に存在する矛盾した標準が豊富に存在することが原因となっています。 全世界が同じ方法でテキスト データをエンコードするには、統一されたエンコード テーブルが必要ですが、国のアルファベット間の矛盾や企業の矛盾により、これはまだ実現できません。
のために 英語で、事実上、国際的な通信手段のニッチな領域を獲得しましたが、矛盾はすでに除去されています。 米国規格協会 (ANSI - アメリカ国家規格協会) は、ASCII (American Standard Code for Information Interchange) コーディング システムを導入しました。 ASCII システムには、基本と拡張の 2 つのエンコード テーブルがあります。 基本テーブルは0から127までのコード値を固定し、拡張テーブルは128から255までの番号を持つ文字を参照します。
ベース テーブルの最初の 32 コードは 0 で始まり、ハードウェア メーカー (主にコンピュータおよび印刷装置のメーカー) に与えられます。 この領域には、どの言語文字にも対応しない、いわゆる制御コードが含まれています。したがって、これらのコードは画面にも印刷装置にも表示されませんが、他のデータの出力方法を制御できます。
コード 32 からコード 127 までには、英語のアルファベットの文字、句読点、数字、算術演算、およびいくつかの補助文字のコードがあります。 ベーステーブル ASCIIエンコーディング表 1.1 に示します。

テキスト データをエンコードする同様のシステムが他の国でも開発されています。 たとえば、ソ連では、コーディング システム KOI-7 (7 桁の情報交換コード) がこの地域で運用されていました。 しかし、ハードウェアおよびソフトウェアのメーカーのサポートにより、アメリカの ASCII コードは国際標準のレベルに達し、各国のコーディング システムは、コードの値を定義するコーディング システムの 2 番目の拡張部分に「後退」する必要がありました。この領域には単一の標準が存在しないため、多数の同時エンコードが必要になります。 ロシアでのみ、3 つの現在のエンコード標準とさらに 2 つの古いエンコード標準を示すことができます。
たとえば、Windows-1251 エンコーディングとして知られるロシア語の文字エンコーディングは、Microsoft によって「外部から」導入されましたが、同社のオペレーティング システムやその他の製品がロシアで広く配布されていることを考えると、この文字エンコーディングは深く根付いていました。広く使用されています (表 1.2)。 このエンコーディングは、Windows プラットフォームで実行されているほとんどのローカル コンピューターで使用されます。 事実上、ワールドワイドウェブのロシア分野では標準となっています。

もう 1 つの一般的なエンコーディングは KOI-8 (情報交換コード、8 桁) と呼ばれます。その起源は東ヨーロッパ諸国相互経済援助評議会の時代に遡ります (表 1.3)。 このエンコーディングに基づいて、KOI8-R (ロシア語) および KOI8-U (ウクライナ語) エンコーディングが現在使用されています。 現在、KOI8-R エンコーディングはロシアのコンピュータ ネットワークやロシアのインターネット分野の一部のサービスで広く使用されています。 特にロシアでは、電子メール メッセージや電話会議において事実上の標準となっています。

ロシア語のアルファベットの文字のエンコーディングを規定する国際標準は、ISO (国際標準化機構) エンコーディング (国際標準化研究所) と呼ばれます。 実際には、このエンコーディングが使用されることはほとんどありません (表 1.4)。

MS-DOS オペレーティング システムを実行しているコンピュータでは、さらに 2 つのエンコーディング (GOST エンコーディングと GOST 代替エンコーディング) を実行できます。 前者はパーソナル コンピューティングの出現の初期でも時代遅れであると考えられていましたが、後者は現在でも使用されています (表 1.5 を参照)。

ロシアでは多数のテキスト データ エンコード システムが運用されているため、システム間のデータ変換の問題が発生します。これはコンピュータ サイエンスの一般的な問題の 1 つです。
ユニバーサルテキストデータエンコーディングシステム
テキスト データをコーディングするための統一システムの作成に伴う組織上の困難を分析すると、それらは限られたコード セットによって引き起こされているという結論に達することができます (256)。 同時に、たとえば、シンボルを 8 ビットの 2 進数ではなく、多数のビットを持つ数値でエンコードすると、可能なコード値の範囲がはるかに大きくなるのは明らかです。 16 ビット文字エンコーディングに基づくこのシステムは、ユニバーサル UNICODE と呼ばれます。 16 桁により、65,536 の異なる文字に一意のコードを提供できます。このフィールドは、地球上のほとんどの言語を 1 つの文字テーブルに収容するのに十分です。
このアプローチの些細な明白さにも関わらず、このシステムへの単純な機械的移行は、コンピュータ リソースの不足により長い間妨げられていました (UNICODE コーディング システムでは、すべてのテキスト ドキュメントは自動的に 2 倍の長さになります)。 90 年代後半には、技術的手段がリソースの提供に必要なレベルに達し、今日ではドキュメントとソフトウェアがユニバーサル コーディング システムに徐々に移行されつつあります。 個人ユーザーにとっては、異なるコーディングシステムで作成された文書とソフトウェアとの連携にさらなる不安が加わりましたが、これは過渡期の困難であると理解する必要があります。
グラフィックスデータのエンコーディング
新聞や本に印刷された白黒のグラフィック画像を虫眼鏡で観察すると、それがラスターと呼ばれる特徴的なパターンを形成する小さな点で構成されていることがわかります (図 1.9)。

米。 1.9. ラスターはグラフィック情報をエンコードする方法です。
印刷業界では長い間受け入れられてきました
線形座標と各点の個々の特性 (明るさ) は整数を使用して表現できるため、ラスター コーディングではバイナリ コードを使用してグラフィック データを表現できると言えます。 今日では、白黒のイラストを 256 階調のグレーのドットの組み合わせとして表現することが一般的に受け入れられているため、通常、ドットの明るさをエンコードするには 8 ビットの 2 進数で十分です。
カラー グラフィック イメージをエンコードするには、任意の色をその主成分に分解する原理が使用されます。 このような成分として、赤(Red、R)、緑(Green、G)、青(Blue、B)の 3 原色が使用されます。 実際には、人間の目に見えるあらゆる色は、これらの 3 原色を機械的に混合することによって得られると考えられています (理論的には完全に真実ではありませんが)。 このコーディング方式は、原色の名前の頭文字をとって RGB 方式と呼ばれます。
ハーフトーンの白黒画像で一般的に行われているように、各主要コンポーネントの明るさをエンコードするために 256 の値 (8 つのバイナリ ビット) が使用される場合、1 つのポイントのカラーをエンコードするには 24 ビットを費やす必要があります。 同時に、このコーディング システムは、実際に人間の目の感度に近い 1,650 万の異なる色を明確に識別します。 24 バイナリ ビットを使用してカラー グラフィックスを表現するモードは、トゥルー カラーと呼ばれます。
各原色は追加の色、つまり原色を白に補う色と関連付けることができます。 どの原色でも、補色は他の原色のペアの合計によって形成される色であることが簡単にわかります。 したがって、追加の色は、シアン (Cyan、C)、マゼンタ (Magenta、M)、およびイエロー (Yellow、Y) になります。 任意の色をその構成成分に分解する原理は、原色だけでなく追加の色にも適用でき、あらゆる色をシアン、マゼンタ、イエローの成分の和として表現できます。 この色分け方法は印刷で受け入れられていますが、印刷では 4 番目のインクである黒 (ブラック、K) も使用されます。 したがって、このコーディング システムは 4 つの文字 CMYK で示されます (文字 B はすでに青で占められているため、黒は文字 K で示されます)。このシステムでカラー グラフィックスを表現するには、2 進数 32 桁が必要です。 このモードはトゥルーカラーとも呼ばれます。
各ポイントの色のエンコードに使用されるバイナリ ビットの数を減らすと、データ量を減らすことができますが、エンコードされる色の範囲は大幅に減少します。 16 ビット 2 進数を使用してカラー グラフィックスをエンコードすることは、ハイ カラー モードと呼ばれます。
色情報が 8 データ ビットを使用してエンコードされる場合、伝達できる色調は 256 色のみです。 このカラーエンコーディング方法はインデックスと呼ばれます。 この名前の意味は、256 個の値では人間の目にアクセスできる色の全範囲を伝えるには完全に不十分であるため、各ラスター ポイントのコードは色そのものを表すのではなく、その番号 (インデックス) のみを表すということです。パレットと呼ばれる特定のルックアップ テーブル。 もちろん、このパレットはグラフィック データに添付する必要があります。これがないと、画面や紙上で情報を再現する方法を使用することはできません(つまり、もちろん使用できますが、データが不完全であるため) 、受け取った情報は適切ではありません。木の葉は赤く、空は緑になる可能性があります)。
音声情報のエンコード
オーディオ情報を扱うための技術と方法は、ごく最近になってコンピューター技術に導入されました。 さらに、数値データ、テキスト データ、グラフィック データとは異なり、サウンド レコーディングには、同じように長く証明されたコーディング履歴がありません。 その結果、バイナリ コードを使用してオーディオ情報をエンコードする方法は標準化からはほど遠いです。 多くの個別企業は独自の企業標準を開発しています。
講義その4。
バイナリデータのエンコーディング
さまざまな種類のデータを扱う作業を自動化するには、その表示形式を統一することが非常に重要です。 この目的のために、通常、コーディング技術が使用されます。 あるタイプのデータを別のタイプのデータで表現すること。
コード化システムの例: 人間の言語、アルファベット (図形記号を使用して言語をコード化する)、数式の記述、電信モールス信号、盲人用点字コード、海軍旗コードなど。
コンピューター技術にも独自のコーディング システムがあります。これはバイナリ コーディングと呼ばれ、データを 0 と 1 の 2 文字だけのシーケンスとして表現することに基づいています。これらの文字は 2 進数またはビットと呼ばれます。
1 つのビットは、0 または 1 (はいまたはいいえ、黒か白、真か偽など) の 2 つの概念を表現できます。 ビット数を 2 に増やすと、すでに 4 つの異なる概念 (00 01 10 11) を表現できます。3 ビットを使用すると、8 つの異なる概念 (000 001 010 100 101 110 101 111) をエンコードできます。
バイナリコーディングシステムのビット数を 1 増やすことで、エンコードできる値の数を 2 倍にすることができます。 N=2 私、 どこ 私– 桁数、 N- 値の数。
コンピュータは、数値、テキスト、グラフィック、サウンド、およびビデオ データを処理できます。 これらすべてのタイプのデータは、一連の電気パルスでエンコードされます。パルスがある (1)、パルスがない (0)。 0 と 1 のシーケンス。 このような 0 と 1 の論理的なシーケンスは、機械語と呼ばれます。
表記
番号制度とは何ですか?
位置番号体系と非位置番号体系があります。
で 非位置的システムでは、数字の重み (つまり、数字の値に対する寄与度) は、数字の表記上の位置に依存しません。 したがって、数字 XXXII (32) のローマ数字体系では、どの位置の数字 X の重みも単純に 10 になります。
で 位置的な記数法では、各数字の重みは、数字を表す一連の数字の位置 (位置) に応じて異なります。 たとえば、757.7 という数字では、最初の 7 は 700 を意味し、2 番目は 7 単位、3 番目は 10 分の 7 単位を意味します。
数字 757.7 の表記そのものが、次の式の短縮表記を意味します。
700 + 50 + 7 + 0,7 = 7 10 2 + 5 10 1 + 7 10 0 + 7 10 -1 = 757,7.
位置番号体系はその基数によって特徴付けられます。
2、3、4 など、任意の自然数を系の基数として使用できます。 その結果、2 値、3 値、4 値など、無限の数の位置システムが可能になります。 各記数法で基数を使用して数字を書く q略語表現を意味します
ある n-1 q n-1 +a n-2 q n-2 + ... + a 1 q 1 +a 0 q 0 +a -1 q -1 + ... +a -m q -m ,
どこ ある 私– 番号体系の番号。 nそして メートル– それぞれ整数と小数の桁数。
専門家がコンピュータと通信するために使用する番号体系は何ですか?
10 進数に加えて、基数が次のようなシステムもあります。 全体 2の累乗, つまり:
バイナリ (数字 0、1 が使用されます);
8 進数 (数字 0、1、...、7 が使用されます);
16 進数 (0 から 9 までの最初の整数には 0、1、...、9 の数字が使用され、次の数字 (10 から 15 まで) には文字 A、B、C、D、E、F が使用されます)数字として使用されます)。
なぜ人間は 10 進法を使用し、コンピューターは 2 進法を使用するのでしょうか?
人々が十進法を好むのは、昔から指で数を数える習慣があり、人の指と足の指が10本あるからでしょう。 常に、そしてどこでも 10 進数体系を使用しているわけではありません。 たとえば中国では、長い間 5 桁の番号体系が使用されていました。
また、コンピューターがバイナリ システムを使用するのは、バイナリ システムには他のシステムに比べて多くの利点があるためです。
これを実装するには、2 つの安定状態 (電流がある - 電流がない、磁化されている - 磁化されていないなど) を持つ技術的デバイスが必要であり、たとえば 10 進数の 10 ではありません。
2 つの状態のみを介した情報の提示は信頼性が高く、ノイズに耐性があります。
ブール代数の装置を使用して情報の論理変換を実行することが可能です。
2 進数の演算は 10 進数の演算よりもはるかに単純です。
2 進法の欠点は、数値を記録するために必要な桁数が急速に増加することです。
なぜコンピューターでも 8 進数と 16 進数の表記法が使用されるのでしょうか?
コンピュータにとって便利な二進法は、人間にとっては不便です。 かさばるそして 珍しい録音.
10 進数から 2 進数へ、またはその逆の数値の変換は機械によって実行されます。 ただし、コンピュータを専門的に使用するには、マシンという言葉を理解する必要があります。 これが、8 進法と 16 進法が開発された理由です。
これらのシステムの数値は、10 進数とほぼ同じくらい読みやすいため、それに応じた数値が必要になります。 3時に(8進数)と 4時に(16進数) の桁数の 1 倍少ない バイナリーシステム (結局のところ、8 と 16 という数字はそれぞれ 2 の 3 乗と 4 乗です)。
二進法
コンピューターサイエンスにおける 2 進数システムの特別な重要性は、コンピューター内のあらゆる情報の内部表現が 2 進数であるという事実によって決まります。 2 文字 (0 と 1) のみのセットで記述されます。
10 進数から 2 進数への変換
整数部分と小数部分は別々に翻訳されます。 数値の整数部分を変換するには、それを基数 2 で割り、商が 0 になるまで割り続ける必要があります。得られた余りの値は、逆の順序で取得されます。希望の 2 進数を形成します。
例えば、
25 (10) = 11001 (2)
小数部を変換するには、2 を掛ける必要があります。積の整数部は、2 進数の数値の最初の桁になります。 次に、結果の小数部分を破棄して、再度 2 を掛けます。 有限の小数分数は、無限の (周期的な) 二進数の分数になる可能性があります。
例えば、
0.73 * 2 = 1.46 (整数部 1)
0.46 * 2 = 0.92 (整数部 0)
0.92 * 2 = 1.84 (整数部 1)
0.84 * 2 = 1.68 (整数部 1) など 0.73 (10) = 0.1011… (2)
2 進数の算術演算
で 二項加算 1 + 1 は、10 進数の算術と同様に、最上位桁に 1 を繰り上げます。 例えば、
で バイナリ減算最も近い桁に 1 が入っていると、最下位桁が 2 単位になることに注意してください。 隣接する上位桁に 0 が含まれる場合、数桁後に 1 が占有されます。 この場合、最も近い有効な最上位桁にある単位は、最下位桁の 2 単位と、1 を取得した最下位桁と最上位桁の間にあるすべての 0 桁の 1 を与えます。
197 から 174 を引く

バイナリ除算バイナリ乗算および減算テーブルを使用して行われます。 430を10で割る

8 進数および 16 進数の体系
数値を 10 進数から 8 進数に変換する乗算と除算を使用するバイナリの場合と同じ方法で、2 ではなく 8 で実行されます。
たとえば、58.32 (10)
58:8 = 7 (2 残り)
7:8 = 0 (残り 7)
0,48 * 8 = 3,84, …
58,32 (10) = 72,243… (8)
10 進数体系から 16 進数への数値の変換も同じ方法で行われます。 567 (10)0 = 237 (16)
異なる番号体系における番号の対応関係
|
10進数 |
16進数 |
8進数 |
バイナリ |
整数の 2 進数を 8 進数に変換するにはこれを右から左に 3 桁のグループに分割し (左端のグループには 3 桁未満の 2 進数を含めることができます)、各グループを 8 進数に相当するものに割り当てる必要があります。 このようなグループはこう呼ばれます バイナリトライアド.
例えば、
11011001 = 11 011 001 = 331 (8)
整数の 2 進数を 16 進数に変換する指定された数値を 4 桁のグループに分割することによって生成されます - バイナリ四分数.
1100011011001 = 1 1000 1101 1001 = 18D9 (16)
2 進数の小数部分を 8 進数または 16 進数に変換するには、同様の 3 進数または 4 進数への除算がコンマから右に向かって実行されます (欠落している最後の桁はゼロで補われます)。
0,1100011101 (2) = 0,110 001 110 100 = 0,6164 (8)
0.1100011101 (2) = 0.1100 0111 0100 = C74 (16)
8 進数 (16 進数) から 2 進数への変換は、逆の方法で行われます。各番号記号を、対応する 3 倍 (4 倍) の 2 進数と照合します。
A1F (16) = 1010 0001 1111 (2)
127 (8) = 001 010 111 (2)
このような変換が簡単なのは、8 と 16 という数字が 2 の整数乗であるという事実によるものです。この単純さにより、8 進数と 16 進数の体系の人気が説明されます。
教師向けインターネットサイト一覧 (2)
書類パームズ アーカイブ 講義天文学では… コーディング, コーディング データ バイナリ コード, コーディング文章 データ、システム コーディング, コーディンググラフィック データ, コーディング音声情報。 ユニバーサルシステム コーディング文章 データ ...
専門分野(研修の方向性)における移動体通信システムの学問分野(学問分野名)の講義録
講義ノート... コーディング 講義 11. 検出と修正の基本 コード簡単な概要 講義: ... 情報ビット数 k、および for バイナリ コード: 、 。 上限...適用される転送方法 コーディング データ、直交と呼ばれます...
「電子産業機器」の講義資料 知識分野
書類... . コーディング情報。 主な種類 コード ................................................................. 19 講義 6. ...それを受け取る データ消費者; 関連性... バイナリ コードとその修正 - 対称 バイナリ コード. バイナリ コード ...
データのエンコーディング
バイナリデータのエンコーディング
異なる種類に属するデータの処理を自動化するには、その表示形式を統一することが非常に重要です。このために、通常、この手法が使用されます。 コーディング つまり、あるタイプのデータを別のタイプのデータで表現することです。 人間の自然言語は、音声を通じて思考を表現するための概念コーディング システムにすぎません。 言語と密接な関係があるのは、アルファベット(グラフィック記号を使用して言語コンポーネントをコーディングするためのシステム)です。 歴史は、「普遍的な」言語とアルファベットを作成する試みが失敗に終わったにもかかわらず、興味深いことを知っています。 どうやら、それらを実装する試みが失敗したのは、国家的および社会的主体が、公共データのコーディングシステムを変更することは確実に社会的方法(つまり、法的および道徳的規範)の変更につながることを自然に理解しているという事実によるものです。社会的混乱に関連している可能性があります。
ユニバーサル コーディング ツールの同じ問題が、技術、科学、文化の特定の分野で非常にうまく実装されています。 例には、数式を書くためのシステム、電信アルファベット、海軍旗アルファベット、視覚障害者のための点字システムなどが含まれます。
コンピューター技術にも独自のシステムがあります。これはバイナリ コーディングと呼ばれ、データを 0 と 1 の 2 つの文字のシーケンスとして表現することに基づいています。これらの文字は、英語ではバイナリ ディジット (binaiy digit、または略語でビット) と呼ばれます。
1 つのビットは、0 または 1 (はいまたはいいえ、黒か白、真か偽など) の 2 つの概念を表現できます。 ビット数を 2 に増やすと、次の 4 つの異なる概念を表現できます。
3 ビットで 8 つの異なる概念をエンコードできます。
000 001 010 011 100 101 110 111
つまり、バイナリコーディングシステムのビット数を 1 増やすことにより、このシステムで表現できる値の数が 2 倍になります。 一般式:
ここで、N は独立したエンコードされた値の数です。
m – このシステムで採用されているバイナリコーディングのビット深度。
データの表現および測定のより大きな単位はバイトです。
8ビット – 1バイト
1024 バイト – 1 キロバイト (KB)
1024 キロバイト – 1 メガバイト (MB)
1024 メガバイト – 1 ギガバイト (GB)
コンピューターによって処理されるデータの主な種類は次のとおりです。
整数と実数。
テキストデータ。
グラフィックデータ。
音声データです。
整数と実数のエンコード
整数は非常に簡単にバイナリでエンコードされます。整数を取得し、商が 1 になるまで半分で割るだけです。 各割り算の余りのセットは、最後の商とともに右から左に書かれ、10 進数の 2 進数の類似物を形成します。
したがって、19 10 = 100112 となります。
0 ~ 255 の整数をエンコードするには、8 ビットのバイナリ コード (8 ビット) があれば十分です。 16 ビットでは 0 ~ 65,535 の整数をエンコードでき、24 ビットでは 1,650 万を超える異なる値をエンコードできます。
実数をエンコードするには、80 ビット エンコードが使用されます。 この場合、数値はまず正規化された形式に変換されます。
3,1415926=0,31415926*10 1
300 000 = 0,3*10 6
123 456 789 = 0,123456789*10 10
数値の最初の部分は次のように呼ばれます。 仮数 、そして 2 番目 - 特性 。 80 ビットの大部分は仮数 (符号とともに) を格納するために割り当てられ、特定の固定数のビットが特性 (これも符号付き) を格納するために割り当てられます。
テキストデータのエンコード
アルファベットの各文字が特定の整数 (シリアル番号など) に関連付けられている場合は、バイナリ コードを使用してテキスト情報をエンコードすることもできます。 256 個の異なる文字をエンコードするには、2 進数 8 桁で十分です。 これは、英語とロシア語のすべての文字 (小文字と大文字の両方)、句読点、基本的な算術演算の記号、一般に受け入れられている特殊文字 (記号「§」など) を 8 ビットのさまざまな組み合わせで表現するのに十分です。 ”。
技術的には非常に単純に見えますが、組織的には常に非常に大きな問題がありました。 コンピュータ技術の開発の初期には、これらは必要な標準の欠如と関連付けられていましたが、今日では逆に、同時に存在する矛盾した標準が豊富に存在することが原因となっています。 全世界が同じ方法でテキスト データをエンコードするには、統一されたエンコード テーブルが必要ですが、国のアルファベット間の矛盾や企業の矛盾により、これはまだ実現できません。
事実上、国際コミュニケーション手段のニッチな地位を獲得している英語にとって、矛盾はすでに取り除かれています。 米国規格協会 (ANSI - アメリカ国家規格協会) は、ASCII (American Standard Code for Information Interchange) コーディング システムを導入しました。 ASCII システムには、基本と拡張の 2 つのエンコード テーブルがあります。 基本テーブルは0から127までのコード値を固定し、拡張テーブルは128から255までの番号を持つ文字を参照します。
ベース テーブルの最初の 32 コードは 0 で始まり、ハードウェア メーカー (主にコンピュータおよび印刷装置のメーカー) に与えられます。 この領域には、どの言語文字にも対応しない、いわゆる制御コードが含まれています。したがって、これらのコードは画面にも印刷装置にも表示されませんが、他のデータの出力方法を制御できます。
コード 32 からコード 127 までには、英語のアルファベットの文字、句読点、数字、算術演算、およびいくつかの補助文字のコードがあります。 基本的な ASCII エンコーディング テーブルを表 1.1 に示します。
|
表1.1。 |
基本的なエンコードテーブルアシアスキー |
||||||||||
|
32ティースパースペース |
|||||||||||
|
44 , |
|||||||||||
|
書類 講義その4。 コーディング データ作業を自動化するにはバイナリ コード データ、さまざまなタイプに属し、非常に重要です...このテクニックは通常使用されます コーディング、つまり 表現 データ 1種類を通して データ別のタイプ。 例... この作成物(説明書・faq)は随時追記・編集していきます。 ご要望、推奨事項、説明、コメントをフォーラムに残すか、お問い合わせフォームからご連絡ください。説明書ほとんどの人の聴覚。 のメソッドが呼び出されます コーディング感知。 そうは言っても...取得する必要があります。 コーディング. のメニュー項目によりポップアップ ウィンドウが表示されます... - これは回復スキームです データから コード化されたそれらがどのような形で伝わるのか… この教科書には、高等教育システムにおける専門家を育成するために必要なコンピュータ サイエンスのコース全体が含まれています。 村のテーマ構造エッセイ必要な情報。 1.3. パフォーマンス ( コーディング) データ 1.3.1. 番号体系はさまざまです...情報 6 1.1.4。 情報プロセス 9 1.3. パフォーマンス ( コーディング) データ 10 1.3.1. 数体系 10 1.3.2. パフォーマンス... 物理コーディング書類... コーディングそして論理的 コーディングシステムを形成する コーディング最低レベル。 システム コーディングシステム コーディング データ... 最も一般的に使用されるシステム コーディング:NRZ(ノン... 1. 情報コーディングの概念。 離散(デジタル)情報表現の普遍性。 位置および非位置番号システム。 アルゴリズム書類重要性のため 与えられたプロセスには特別な名前が付いています - コーディング情報。 コーディング情報は並外れたものです...離散法の例をいくつか挙げてください コーディング データ: テキスト、グラフィック、サウンド。 保存する... | |||||||||||
データの処理を自動化するには、コンピューターと呼ばれる特殊なタイプのデバイスが使用されます。
PC は汎用的な技術システムであり、その構成は必要に応じて柔軟に変更できます
7. PC周辺機器
この問題の解決策は、osi (Open System Interconnection) モデルに基づいています。
インターネットは基幹ネットワークを接続するインターネットワークです
ハイパーテキスト情報交換プロトコル
12 アルゴリズムの概念
13. オブジェクト指向プログラミング。 13 オブジェクト指向アプローチ
§ 2 データと情報のコーディング
データは情報の弁証法的な構成要素です。 それらは記録された信号を表します。
この場合、任意の物理的な登録方法を使用できます(物体または表面パラメータの動き、電気的、磁気的、または光学的特性の変化、化学組成など)。
記録方法に応じて、データはさまざまな種類のメディアに保存および転送できます。
情報の特性は、そのキャリアの特性と密接に関係していることに留意する必要があります。
平均的な消費者にとって、誰もがこの機器を持っているわけではないため、書籍の情報の入手可能性は、CD の同じ情報よりも著しく高くなります。
データ操作
情報処理中に、データはメソッドを使用してあるタイプから別のタイプに変換されます。
データ処理にはさまざまな操作が含まれますが、それらは次のように区別できます。
データ収集 – 意思決定に十分な情報を提供するための情報の蓄積
データの形式化とは、異なるソースから取得したデータを同じ形式にして、相互に比較できるようにすること、つまり、アクセシビリティのレベルを高めることです。
データのフィルタリング – 意思決定に必要のない不要なデータをフィルタリングして除外します。 同時に、ノイズ レベルが減少し、データの信頼性と適切性が向上するはずです。
データの並べ替え - 使いやすさを目的として、特定の特性に従ってデータを並べ替え、情報の信頼性を高めます。
データ アーカイブは、便利でアクセスしやすい形式でデータ ストレージを編成するもので、データ ストレージの経済的コストを削減し、情報プロセスの全体的な信頼性を向上させるのに役立ちます。
データ保護は、データの損失、複製、変更を確実に防止することを目的とした一連の対策です
データ転送 - 情報プロセスにおける遠隔参加者間でのデータの送受信。 この場合、データ ソースは通常サーバーと呼ばれ、コンシューマはクライアントと呼ばれます。
データ変換 - あるフォームから別のフォームへ、またはある構造から別の構造へデータを転送します。
バイナリデータのエンコーディング
………………………………………………………………………………
異なるタイプに属する場合、プレゼンテーションの形式を統一することが非常に重要です。
これを行うには、通常、コーディング技術が使用されます。つまり、あるタイプのデータを別のタイプのデータで表現します。 例には、数式を書くためのシステム、電信アルファベット、視覚障害者のための点字システム、海軍旗のアルファベットなどが含まれます。
コンピューター技術にも独自のシステムがあります。これはバイナリ コーディングと呼ばれ、データを 0 と 1 の 2 文字だけのシーケンスとして表現することに基づいています。
これらの文字は、バイナリ ディジット (英語では binary digit)、または短縮形でビット 1 ビットと呼ばれます。
1 つのビットは、0 または 1、はいまたはいいえ、黒または白、真または偽などの 2 つの概念を表現できます。 d.
ビット数を 2 に増やすと、すでに 4 つの異なる概念を表現できるようになります。
3 ビットで 8 つの異なる値をエンコードできます: 000 001 010 011 100 101 110 111
バイナリ コード化システムのビット数を 1 増やすと、このシステムで表現できる値の数は 2 倍になります。一般的な式は次のようになります。
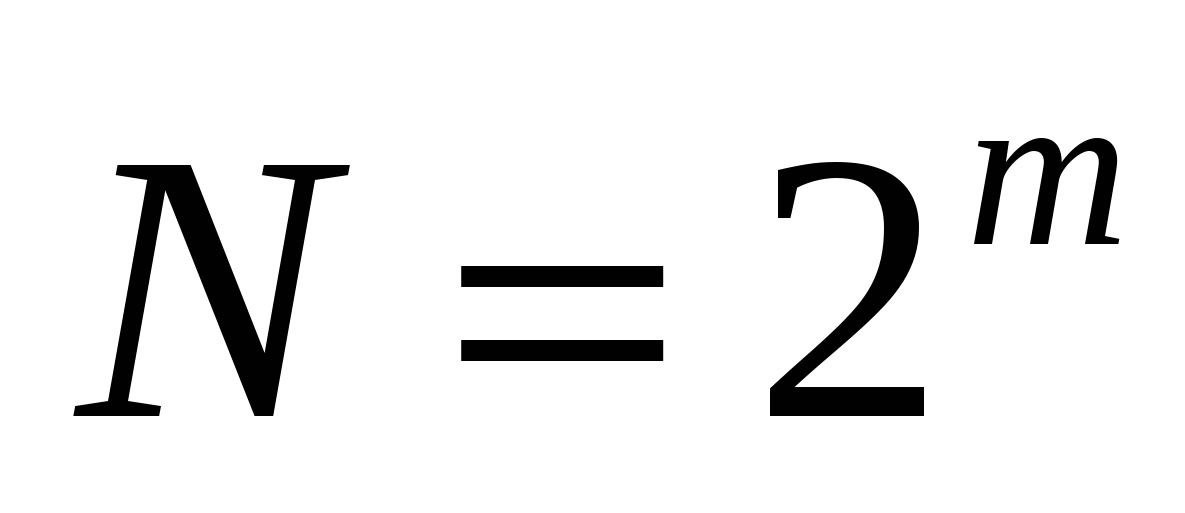
ここで、N は独立したエンコードされた値の数です。
M – このシステムで採用されているバイナリコーディングのビット深度
整数と実数のエンコード
整数は次のようにバイナリでエンコードされます。整数を取得し、余りが 0 または 1 になるまで半分に分割します。
各割り算の剰余のセットは、最後の剰余とともに右から左に書かれ、10 進数の 2 進数の類似物を形成します。
つまり、19 10 = 10011 2
0 ~ 255 の整数をエンコードするには、8 ビットのバイナリ コード (8 ビット) があれば十分です。
16 ビットを使用すると、0 ~ 65535 の整数をエンコードできます。
24 ビット – すでに 1,650 万を超える異なる値。
実数をエンコードするには、80 ビット エンコードが使用されます。
この場合、数値はまず正規化された形式に変換されます。
3,1415926 = 0,31415926 * 10 1
300000 = 0,3 * 10 6
123456789 = 0,123456789 * 10 10
数字の最初の部分は、、、 - 特性と呼ばれます。 80 ビットの大部分は、符号付き空間の仮数を格納するために割り当てられ、少数のビットは 10 符号特性を格納するために割り当てられます。
テキストデータのエンコード
アルファベットの各文字が特定の整数 (序数) に関連付けられている場合、テキスト情報はバイナリ コードを使用してエンコードできます。 八 バイナリ文字 256 の異なる文字をエンコードします。 英語の場合、米国標準化協会 (ANSI - 米国国家標準協会) は、米国標準の情報交換コードである ASCII (American Standard Code for Information Interchange) エンコード システムを導入しました。
ASCII システムには 2 つあります。 コーディング - 基本と高度。 基本テーブルは 0 から 127 までのコードの意味を固定しており、拡張テーブルは 128 から 255 までの番号を持つ文字を参照します。
ベース テーブルの最初の 32 コードはハードウェア メーカーに提供されます。 d はこの領域に配置されます。 a. どの言語文字にも一致しない制御コード。
これらのコードは画面や印刷デバイスには表示されませんが、他のデータの出力方法を制御します。
ASCII に加えて、KON - 8 (情報交換コード、8 桁)、Windows エンコード、ISO エンコード、UNICODE、GOST - 代替エンコードなどのエンコードがあります。
グラフィックスデータのエンコーディング
b/wを増やすと グラフィック画像新聞や本に印刷されると、それがラスターと呼ばれる特徴的なパターンを形成する小さな点で構成されていることがわかります。
各点の線形座標と色は整数で表現できるため、ラスターコーディングはバイナリコードを使用してグラフィックデータを表現すると言えます。
カラー画像をエンコードするには、任意の色をその主成分に分解する原理が使用されます。
このようなコンポーネントとして 3 原色が使用されます。
レッド(R)
グリーン(G)
ブルー(B)
このコーディング方式は、色の名前の頭文字をとって RGB 方式と呼ばれます。
16 ビット 2 進数を使用してカラー グラフィックスをエンコードすることは、ハイ カラー モードと呼ばれます。 そして、24 バイナリ ビットを使用してカラー グラフィックスを表現するモードは、カラーバイカラー (…………) と呼ばれます。

