24.07.2019
Pengkodean informasi teks. Mengapa pengkodean biner bersifat universal? Metode Pemrograman
Mari kita cari tahu bagaimana semuanya dilakukan mengubah teks menjadi kode digital? Omong-omong, di situs web kami, Anda dapat mengonversi teks apa pun menjadi kode desimal, heksadesimal, biner menggunakan Kalkulator Kode Online.
Pengkodean teks.
Menurut teori komputer, teks apa pun terdiri dari karakter individual. Karakter tersebut antara lain: huruf, angka, tanda baca huruf kecil, karakter khusus (“”, №, (), dll), juga menyertakan spasi antar kata.
Basis pengetahuan yang diperlukan. Kumpulan simbol yang saya gunakan untuk menulis teks disebut ALPHABET.
Jumlah simbol yang diambil dalam alfabet mewakili kekuatannya.
Banyaknya informasi dapat ditentukan dengan rumus: N = 2b
- N adalah pangkat yang sama (banyak simbol),
- b - Bit (bobot simbol yang diambil).
Alfabet yang berisi 256 dapat berisi hampir semua karakter yang diperlukan. Abjad seperti ini disebut CUKUP.
Jika kita mengambil abjad yang berkapasitas 256, dan perlu diingat bahwa 256 = 28
- 8 bit selalu disebut 1 byte:
- 1 byte = 8 bit.
Jika Anda mengubah setiap karakter menjadi kode biner, maka kode teks komputer ini akan menempati 1 byte.
Bagaimana tampilan informasi teks di memori komputer?
Teks apa pun diketik di keyboard, di tombol keyboard kita melihat tanda-tanda yang kita kenal (angka, huruf, dll.). Mereka memasukkan RAM komputer hanya dalam bentuk kode biner. Kode biner untuk setiap karakter terlihat seperti angka delapan digit, misalnya 00111111.
Karena byte adalah bagian terkecil dari memori yang dapat dialamatkan, dan memori dialamatkan ke setiap karakter secara terpisah, kemudahan pengkodean tersebut jelas terlihat. Namun, 256 karakter adalah jumlah yang sangat sesuai untuk informasi simbolis apa pun.
Tentu saja timbul pertanyaan: Yang mana secara spesifik? kode delapan digit milik masing-masing karakter? Dan bagaimana cara mengubah teks menjadi kode digital?
Proses ini bersyarat, dan kami berhak untuk memberikan solusi lain cara untuk menyandikan karakter. Setiap karakter alfabet memiliki nomornya sendiri dari 0 hingga 255. Dan setiap nomor diberi kode dari 00000000 hingga 11111111.
Tabel pengkodean adalah "lembar contekan" di mana karakter alfabet ditunjukkan sesuai dengan nomor seri. Berbagai jenis komputer menggunakan tabel pengkodean yang berbeda.
ASCII (atau Asci) telah menjadi standar internasional untuk komputer pribadi. Tabel ini memiliki dua bagian.
Babak pertama adalah untuk tabel ASCII. (Babak pertamalah yang menjadi standar.)
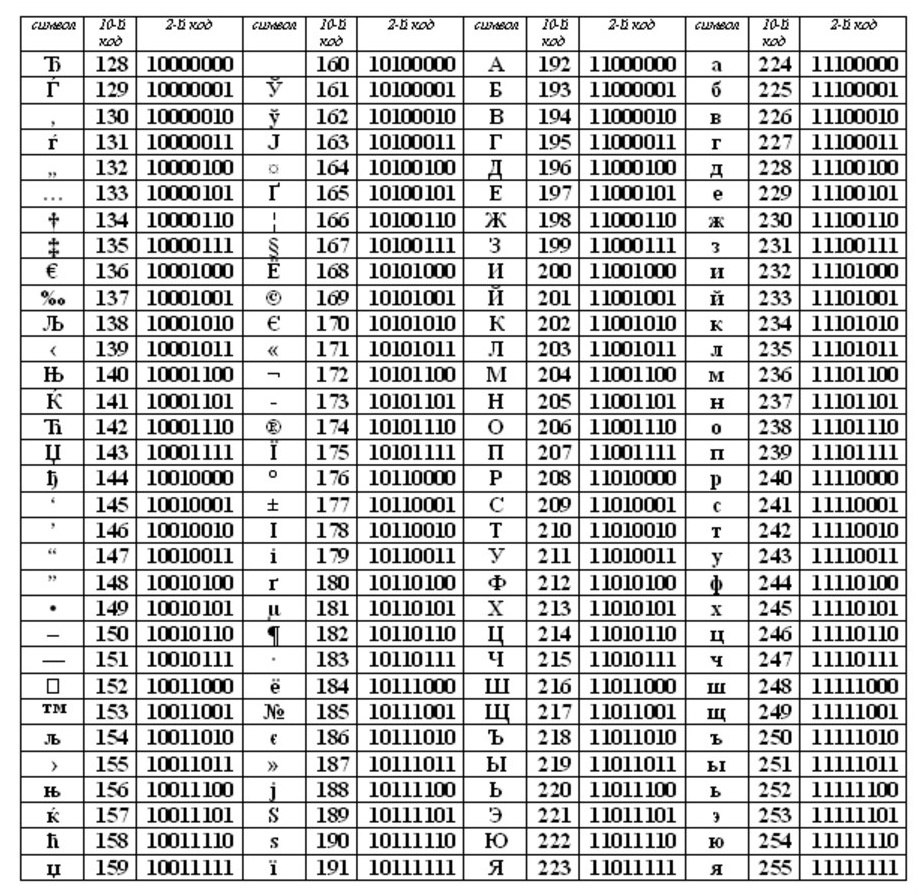
Kesesuaian dengan urutan leksikografis, yaitu dalam tabel huruf (huruf kecil dan huruf besar) ditunjukkan dalam urutan abjad yang ketat, dan angka-angka dalam urutan menaik, disebut prinsip pengkodean alfabet berurutan.
Alfabet Rusia juga diikuti prinsip pengkodean sekuensial.
Saat ini, di zaman kita, mereka menggunakan keseluruhan lima sistem pengkodean Alfabet Rusia (KOI8-R, Windows. MS-DOS, Macintosh dan ISO). Karena banyaknya sistem pengkodean dan kurangnya satu standar, sering kali timbul kesalahpahaman dalam mentransfer teks Rusia ke dalam bentuk komputernya.
Salah satu yang pertama standar untuk pengkodean alfabet Rusia dan pada komputer pribadi mereka menganggap KOI8 (“Kode pertukaran informasi, 8-bit”). Pengkodean ini digunakan pada pertengahan tahun tujuh puluhan pada serangkaian komputer ES, dan sejak pertengahan tahun delapan puluhan, pengkodean ini mulai digunakan pada sistem operasi UNIX pertama yang diterjemahkan ke dalam bahasa Rusia.
Sejak awal tahun sembilan puluhan, yang disebut masa ketika sistem operasi MS DOS mendominasi, sistem pengkodean CP866 telah muncul ("CP" adalah singkatan dari "Code Page").
Perusahaan komputer raksasa APPLE, dengan sistem inovatif tempat mereka bekerja (Mac OS), mulai menggunakan sistem mereka sendiri untuk menyandikan alfabet MAC.
Organisasi Standar Internasional (ISO) menetapkan standar lain untuk bahasa Rusia sistem pengkodean alfabet, yang disebut ISO 8859-5.
Dan sistem pengkodean alfabet yang paling umum saat ini ditemukan di Microsoft Windows dan disebut CP1251.
Sejak paruh kedua tahun sembilan puluhan, masalah standar untuk menerjemahkan teks ke dalam kode digital untuk bahasa Rusia dan tidak hanya diselesaikan dengan memperkenalkan sistem yang disebut Unicode ke dalam standar. Ini diwakili oleh pengkodean enam belas bit, yang berarti tepat dua byte dialokasikan untuk setiap karakter memori akses acak. Tentu saja, dengan pengkodean ini, biaya memori menjadi dua kali lipat. Namun, sistem kode seperti itu memungkinkan hingga 65.536 karakter diubah menjadi kode elektronik.
Kekhasan sistem Unicode standar adalah dimasukkannya alfabet apa pun, baik yang sudah ada, sudah punah, atau ditemukan. Pada akhirnya, alfabet apa pun, selain itu, sistem Unicode mencakup banyak simbol matematika, kimia, musik, dan umum.
Mari kita gunakan tabel ASCII untuk melihat seperti apa sebuah kata di memori komputer Anda.
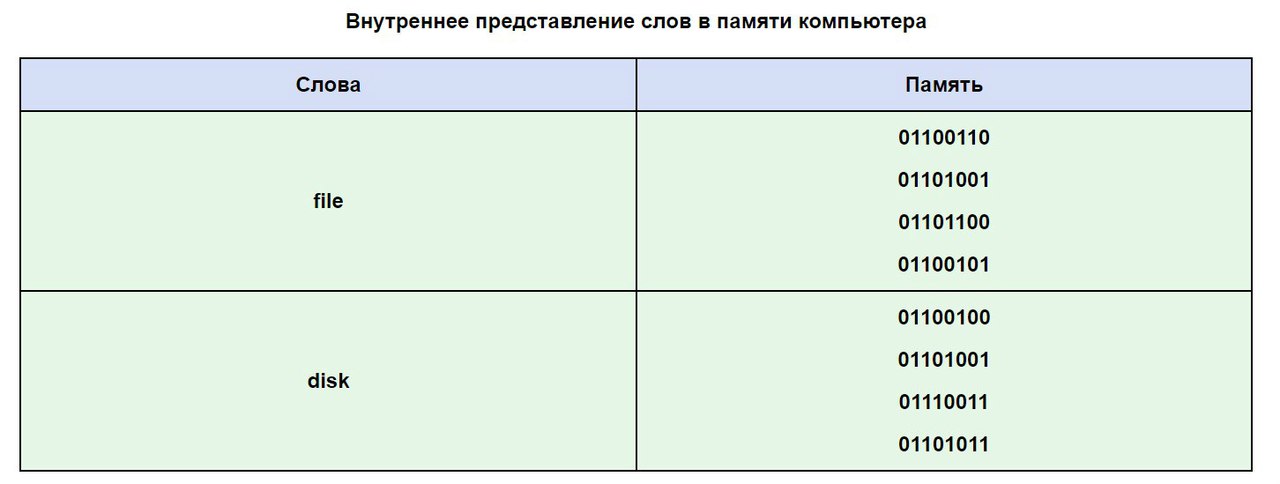
Seringkali teks Anda yang ditulis dengan huruf alfabet Rusia tidak terbaca, hal ini disebabkan oleh perbedaan sistem pengkodean alfabet pada komputer. Ini adalah masalah yang sangat umum dan cukup sering terjadi.
Satuan minimum informasi adalah bit dan byte.
Satu bit memungkinkan Anda untuk menyandikan 2 nilai (0 atau 1).
Menggunakan dua sedikit, dapat dikodekan 4 nilai: 00, 01, 10, 11.
Tiga bit dikodekan 8 nilai yang berbeda: 000, 001, 010, 011, 100, 101, 110, 111.
Dari contoh di atas terlihat bahwa menambahkan satu bit akan menggandakan jumlah nilai yang dapat dikodekan:
1 bit mengkodekan –> 2 nilai berbeda (2 1 = 2),
2 bit mengkodekan –> 4 nilai berbeda (2 2 = 4)
3 bit mengkodekan –> 8 nilai berbeda (2 3 = 8)
4 bit mengkodekan –> 16 nilai berbeda (2 4 = 16)
5 bit mengkodekan –> 32 nilai berbeda (2 5 = 32)
6 bit mengkodekan –> 64 nilai berbeda (2 6 = 64)
7 bit mengkodekan –> 128 nilai berbeda (2 7 = 128)
8 bit mengkodekan –> 256 nilai berbeda (2 8 = 256)
9 bit mengkodekan –> 512 nilai berbeda (2 9 = 512)
10 bit mengkodekan –> 1024 nilai berbeda (2 10 = 1024).
Kita ingat bahwa satu byte tidak memiliki 9 atau 10 bit, tetapi hanya 8. Oleh karena itu, dengan menggunakan satu byte, 256 karakter berbeda dapat dikodekan. Menurutmu ini banyak atau sedikit? Mari kita lihat contoh pengkodean informasi teks.
Bahasa Rusia memiliki 33 huruf dan oleh karena itu, diperlukan 33 byte untuk menyandikannya. Komputer membedakan antara huruf besar (kapital) dan kecil (huruf kecil) hanya jika dikodekan dalam kode yang berbeda. Artinya, untuk mengkodekan huruf besar dan kecil alfabet Rusia, diperlukan 66 byte.
Untuk huruf besar dan kecil alfabet Inggris, diperlukan 52 byte lagi. Hasilnya 66 + 52 = 118 byte. Di sini Anda juga perlu menambahkan angka (dari 0 hingga 9), simbol spasi, semua tanda baca: titik, koma, tanda hubung, tanda seru dan tanda tanya, tanda kurung: bulat, keriting dan persegi, serta simbol operasi matematika: + , –, =, / (ini pembagian), * (ini perkalian). Mari kita tambahkan juga karakter khusus: %, $, &, @, #, No., dll. Semua ini jika digabungkan berjumlah sekitar 256 karakter berbeda.
Dan tidak banyak lagi yang bisa dilakukan. Penting untuk memastikan bahwa semua orang di Bumi sepakat di antara mereka sendiri tentang kode mana (dari 0 hingga 255, yaitu total 256) yang akan ditetapkan ke simbol-simbol tersebut. Katakanlah semua orang sepakat bahwa kode 33 berarti tanda seru (!), dan kode 63 berarti tanda tanya (?). Dan hal yang sama untuk semua simbol yang digunakan. Artinya, teks yang diketik oleh satu orang di komputernya selalu dapat dibaca dan dicetak oleh orang lain di komputer lain.
tabel ASCII
Kesepakatan universal mengenai penggunaan sesuatu yang sama disebut standar. Dalam kasus kami, standarnya harus berupa tabel yang mencatat korespondensi kode (dari 0 hingga 255) dan simbol. Tabel seperti ini disebut tabel pengkodean.
Tapi itu tidak sesederhana itu. Lagi pula, simbol yang bagus, misalnya untuk Yunani, tidak cocok untuk Turki karena digunakan huruf lain di sana. Demikian pula, apa yang baik bagi Amerika Serikat tidak baik bagi Rusia, dan apa yang baik bagi Rusia juga tidak baik bagi Jerman.
Oleh karena itu, kami memutuskan untuk membagi tabel kode menjadi dua.
128 kode pertama (dari 0 hingga 127) harus menjadi standar dan wajib untuk semua negara dan untuk semua komputer, yaitu - internasional standar.
Dan dengan paruh kedua tabel kode (dari 128 hingga 255), setiap negara dapat melakukan apa pun yang mereka inginkan dan membuat standar mereka sendiri di paruh ini - Nasional.
Paruh pertama (internasional) dari tabel kode disebut mejaASCII, yang dibuat di AS dan diterima di seluruh dunia. Standar ASCII tidak bertanggung jawab atas paruh kedua tabel kode. Berbagai negara membuat tabel kode nasionalnya sendiri di sini. Mungkin juga dalam satu negara terdapat standar berbeda yang ditujukan untuk sistem komputer berbeda, namun hanya dalam paruh kedua tabel kode.
Kode dari tabel ASCII internasional
0-31 – karakter khusus yang tidak dicetak pada layar atau printer, tetapi digunakan untuk melakukan tindakan khusus (misalnya, untuk “carriage return” - memindahkan teks ke baris baru, atau untuk “tab” - menempatkan kursor di posisi khusus dalam teks baris, dll).
32 – spasi (pemisah antar kata juga merupakan karakter yang akan dikodekan, meskipun ditampilkan sebagai “spasi kosong” antara kata dan karakter),
33-47 – karakter khusus (tanda kurung, dll.) dan tanda baca (titik, koma, dll.),
48-57 – angka dari 0 hingga 9,
58-64 – simbol matematika (plus (+), minus (-), kalikan (*), bagi (/), dll.) dan tanda baca (titik dua, titik koma, dll.),
65-90 – huruf Inggris kapital (huruf kecil),
91-96 – karakter khusus (tanda kurung siku, dll.),
97-122 – huruf Inggris kecil (huruf kecil),
123-127 – karakter khusus (kurung kurawal, dll.).
Di luar tabel ASCII, mulai dari angka 128 hingga 159, terdapat huruf besar (huruf besar) Rusia, dan dari 160 hingga 170 dan dari 224 hingga 239, terdapat huruf kecil (huruf kecil) Rusia.
Pengkodean kata DUNIA
Dengan menggunakan pengkodean yang ditunjukkan, kita dapat membayangkan bagaimana komputer mengkodekan dan kemudian mereproduksi, misalnya kata DUNIA (dalam huruf kapital). Kata ini diwakili oleh tiga kode: huruf M sesuai dengan kode 140 (menurut sistem pengkodean nasional Rusia), I adalah kode 136 dan P adalah 144.
Namun seperti disebutkan sebelumnya, komputer hanya menerima informasi dalam bentuk biner, yaitu. sebagai barisan nol dan satu. Setiap byte yang sesuai dengan setiap huruf dari kata DUNIA berisi urutan delapan angka nol dan satu. Dengan menggunakan aturan untuk mengubah informasi desimal ke biner, Anda dapat mengganti nilai desimal kode huruf dengan nilai binernya.
Digit desimal 140 sama dengan bilangan biner 10001100. Hal ini dapat dibuktikan dengan melakukan perhitungan berikut: 2 7 + 2 3 +2 2 = 140. Pangkat yang dipangkatkan setiap “2” adalah bilangan posisi dari bilangan biner tersebut. 10001100, yang berisi “1” ", dan posisi diberi nomor dari kanan ke kiri, dimulai dari nomor posisi nol: 0, 1, 2, dst.
Anda dapat mempelajari lebih lanjut tentang mengonversi bilangan dari satu sistem bilangan ke sistem bilangan lainnya, misalnya dari buku teks ilmu komputer atau melalui Internet.
Dengan cara serupa, Anda dapat memverifikasi bahwa angka 136 sesuai dengan angka biner 10001000 (periksa: 2 7 + 2 3 = 136). Dan angka 144 sama dengan angka biner 10010000 (cek: 2 7 + 2 4 = 144).
Dengan demikian, kata DUNIA akan disimpan di komputer sebagai urutan angka nol dan satu (bit) berikut: 10001100 10001000 10010000.
Tentu saja, semua konversi data yang ditunjukkan di atas dilakukan menggunakan program komputer dan tidak terlihat oleh pengguna. Mereka hanya mengamati hasil kerja program-program tersebut, baik saat memasukkan informasi menggunakan keyboard maupun saat ditampilkan di layar monitor atau di printer.
Perlu diperhatikan bahwa pada tingkat literasi komputer, pengguna komputer tidak perlu mengetahui sistem bilangan biner. Pemahaman tentang kode karakter desimal saja sudah cukup. Hanya pemrogram sistem yang dalam praktiknya menggunakan sistem bilangan biner, heksadesimal, oktal, dan lainnya. Hal ini sangat penting bagi mereka ketika komputer menghasilkan pesan kesalahan perangkat lunak yang menunjukkan nilai yang salah tanpa mengonversi ke desimal.
Latihan Literasi Komputer, memungkinkan Anda melihat dan merasakan secara mandiri sistem pengkodean yang dijelaskan dalam artikel
P.S. Artikel sudah selesai, tapi Anda masih bisa membaca:
PPS Ke berlangganan untuk menerima artikel baru, yang belum ada di blog:
1) Masukkan alamat email Anda di formulir ini.
Pengkodean biner informasi teks
Sejak akhir tahun 60an, komputer semakin banyak digunakan untuk memproses informasi teks, dan saat ini sebagian besar komputer pribadi di dunia (dan sebagian besar waktu) terlibat dalam pemrosesan informasi teks.
Secara tradisional, untuk mengkodekan satu karakter, digunakan sejumlah informasi sebesar 1 byte, yaitu I = 1 byte = 8 bit.
Untuk mengkodekan satu karakter, diperlukan 1 byte informasi.
Jika kita menganggap simbol sebagai peristiwa yang mungkin terjadi, maka dengan menggunakan rumus (2.1) kita dapat menghitung berapa banyak simbol berbeda yang dapat dikodekan:
N = 2 Saya = 2 8 = 256.
Jumlah karakter ini cukup untuk mewakili informasi teks, termasuk huruf besar dan kecil alfabet Rusia dan Latin, angka, tanda, simbol grafik, dll.
Pengkodean terdiri dari pemberian kode desimal unik untuk setiap karakter dari 0 hingga 255 atau kode biner yang sesuai dari 00000000 hingga 11111111. Jadi, seseorang membedakan karakter berdasarkan desainnya, dan komputer berdasarkan kodenya.
Ketika informasi teks dimasukkan ke dalam komputer, informasi tersebut dikodekan secara biner; gambar simbol diubah menjadi kode binernya. Pengguna menekan tombol dengan simbol pada keyboard, dan urutan tertentu dari delapan pulsa listrik (kode biner dari simbol) dikirim ke komputer. Kode karakter disimpan dalam RAM komputer, yang menempati satu byte.
Dalam proses menampilkan suatu simbol di layar komputer, dilakukan proses sebaliknya - decoding, yaitu mengubah kode simbol menjadi gambarnya.
Penting bahwa pemberian kode tertentu pada suatu simbol adalah masalah kesepakatan, yang dicatat dalam tabel kode. 33 kode pertama (dari 0 hingga 32) tidak sesuai dengan karakter, tetapi dengan operasi (umpan baris, memasukkan spasi, dan sebagainya).
Kode 33 hingga 127 bersifat internasional dan sesuai dengan karakter alfabet Latin, angka, simbol aritmatika, dan tanda baca.
Kode dari 128 hingga 255 bersifat nasional, artinya, dalam pengkodean nasional, karakter yang berbeda sesuai dengan kode yang sama. Sayangnya, saat ini terdapat lima tabel pengkodean berbeda untuk huruf Rusia (KOI8, SR1251, SR866, Mac, ISO - Tabel 1.3), sehingga teks yang dibuat dalam satu pengkodean tidak akan ditampilkan dengan benar di pengkodean lain.
Saat ini, standar internasional baru Unicode telah tersebar luas, yang mengalokasikan bukan satu byte untuk setiap karakter, tetapi dua, sehingga dapat digunakan untuk menyandikan bukan 256 karakter, tetapi N = 216 = = 65536 karakter berbeda. Pengkodean ini didukung oleh versi terbaru platform Microsoft Windows & Office (sejak 1997).
Setiap pengkodean ditentukan oleh tabel kodenya sendiri. Seperti dapat dilihat dari tabel. 1.3, kode biner yang sama dalam pengkodean berbeda diberi simbol berbeda.
Misalnya, rangkaian kode numerik 221, 194, 204 pada pengkodean CP1251 membentuk kata "komputer", sedangkan pada pengkodean lain akan berupa kumpulan karakter yang tidak berarti.
Untungnya, dalam banyak kasus, pengguna tidak perlu khawatir tentang transcoding dokumen teks, karena ini dilakukan oleh program konverter khusus yang ada di dalam aplikasi.
Menentukan kode numerik suatu karakter
1. Luncurkan editor teks MS Word 2002. Masukkan perintah [Sisipkan-Simbol...]. Sebuah kotak dialog akan muncul di layar Simbol. Bagian tengah kotak dialog ditempati oleh tabel karakter untuk font tertentu (misalnya, Times New Roman).
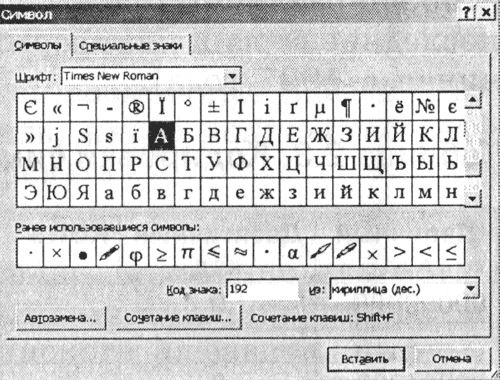 |
Tokoh-tokohnya disusun berurutan dari kiri ke kanan dan baris demi baris, dimulai dari tokohnya Ruang angkasa di pojok kiri atas dan diakhiri dengan huruf "I" di pojok kanan bawah tabel.
Pilih simbol dari daftar drop-down dari: jenis pengkodean. Di bidang teks Kode tanda tangan: kode numeriknya akan muncul.
Memasukkan karakter dengan kode numerik
1. Luncurkan program standar Buku catatan. Menggunakan keypad numerik tambahan sambil menahan tombol Alt, masukkan nomor 0224 dan lepaskan tombol Alt. Simbol "a" akan muncul di dokumen. Ulangi prosedur untuk kode numerik dari 0225 hingga 0233. Urutan 12 karakter "abvgdezhy" dalam pengkodean Windows (CP1251) akan muncul di dokumen.
2. Dengan menggunakan papan tombol angka tambahan sambil menekan tombol (Alt), masukkan angka 224, simbol “p” akan muncul di dokumen. Ulangi prosedur untuk kode numerik dari 225 hingga 233, urutan 12 karakter "rstufhtchshshch" dalam pengkodean MS-DOS (CP866) akan muncul di dokumen.
 |
Tugas praktis
1.29. Dengan menggunakan tabel karakter (MS Word), tuliskan urutan kode numerik desimal dalam pengkodean Windows (CP1251) untuk kata "komputer".
1.30. Dengan menggunakan Notepad, tentukan kata mana dalam pengkodean Windows (CP1251) yang ditentukan dengan urutan kode numerik: 225, 224, 233.242.
1.31. Urutan huruf apa dalam pengkodean KOI8 dan ISO yang sesuai dengan kata “komputer” yang ditulis dalam pengkodean CP1251?
Komputer memproses sejumlah besar informasi. File audio, gambar, teks - semua ini harus diputar atau ditampilkan di layar. Mengapa pengkodean biner merupakan metode universal untuk memprogram informasi peralatan teknis apa pun?
Apa perbedaan antara pengkodean dan enkripsi?
Seringkali orang menyamakan konsep “encoding” dan “enkripsi” padahal sebenarnya keduanya mempunyai arti yang berbeda. Jadi, enkripsi adalah proses mengubah informasi dengan tujuan menyembunyikannya. Orang yang mengubah teks, atau orang yang terlatih khusus, sering kali dapat menguraikannya. Pengkodean digunakan untuk memproses informasi dan menyederhanakan pekerjaan dengannya. Biasanya digunakan tabel pengkodean umum yang familiar bagi semua orang. Itu terpasang di komputer.
Prinsip pengkodean biner
Pengkodean biner didasarkan pada penggunaan dua karakter saja - 0 dan 1 - untuk memproses informasi yang digunakan oleh berbagai perangkat. Tanda-tanda ini disebut digit biner, dalam bahasa Inggris - digit biner, atau bit. Setiap karakter membutuhkan 1 bit memori komputer. Mengapa pengkodean biner merupakan metode pemrosesan informasi universal? Faktanya adalah lebih mudah bagi komputer untuk memproses lebih sedikit karakter. Produktivitas PC secara langsung bergantung pada hal ini: semakin sedikit tugas fungsional yang perlu dilakukan perangkat, semakin tinggi kecepatan dan kualitas pekerjaan. 
Prinsip pengkodean biner tidak hanya ditemukan dalam pemrograman. Dengan bergantian ketukan genderang yang tumpul dan nyaring, penduduk Polinesia saling menyampaikan informasi. Prinsip serupa berlaku ketika suara panjang dan pendek digunakan untuk menyampaikan pesan. "Alfabet telegraf" masih digunakan sampai sekarang.
Di mana pengkodean biner digunakan?
Biner digunakan di mana-mana di komputer. Setiap file, baik itu musik atau teks, harus diprogram agar mudah diproses dan dibaca nanti. Sistem pengkodean biner berguna untuk bekerja dengan simbol dan angka, file audio, dan grafik.
Pengkodean angka biner
Sekarang di komputer, angka-angka disajikan dalam bentuk kode yang tidak dapat dipahami oleh kebanyakan orang. Menggunakan angka Arab seperti yang kita bayangkan tidak rasional bagi teknologi. Alasannya adalah kebutuhan untuk menetapkan simbol uniknya sendiri pada setiap nomor, yang terkadang tidak mungkin dilakukan.

Ada dua sistem bilangan: posisional dan non-posisional. Sistem non-posisi didasarkan pada penggunaan huruf latin dan sudah tidak asing lagi bagi kita dalam bentuknya. Cara pencatatan ini cukup sulit untuk dipahami sehingga ditinggalkan.
Sistem bilangan posisi masih digunakan sampai sekarang. Ini termasuk pengkodean informasi biner, desimal, oktal dan bahkan heksadesimal.
Kami menggunakan sistem pengkodean desimal dalam kehidupan sehari-hari. Ini akrab bagi kita dan dapat dimengerti oleh setiap orang. Pengkodean angka biner dibedakan dengan hanya menggunakan nol dan satu.
Bilangan bulat diubah ke sistem kode biner dengan membaginya dengan 2. Hasil bagi yang dihasilkan juga dibagi 2 secara bertahap hingga hasilnya 0 atau 1. Misalnya bilangan 123 10 in sistem biner dapat direpresentasikan sebagai 1111011 2. Dan angka 20 10 akan terlihat seperti 10100 2.
Indeks 10 dan 2 masing-masing menunjukkan sistem pengkodean bilangan desimal dan biner. Simbol pengkodean biner digunakan untuk memudahkan bekerja dengan nilai-nilai yang direpresentasikan dalam sistem bilangan yang berbeda.
Metode pemrograman desimal didasarkan pada floating point. Untuk mengonversi nilai dari sistem kode desimal ke biner dengan benar, gunakan rumus N = M x qp. M adalah mantissa (ekspresi bilangan tanpa urutan apa pun), p adalah urutan nilai N, dan q adalah basis sistem pengkodean (dalam kasus kita, 2).
Tidak semua angka positif. Untuk membedakan bilangan positif dan negatif, komputer menyisakan 1 bit ruang untuk pengkodean tanda. Di sini, nol melambangkan tanda plus dan satu melambangkan tanda minus.
Penggunaan sistem bilangan ini memudahkan komputer dalam bekerja dengan bilangan. Inilah sebabnya mengapa pengkodean biner bersifat universal dalam proses komputasi.

Pengkodean biner informasi teks
Setiap karakter alfabet dikodekan dengan kumpulan angka nol dan satu sendiri. Teks terdiri dari karakter yang berbeda: huruf (huruf besar dan kecil), simbol aritmatika dan berbagai arti lainnya. Pengkodean informasi teks memerlukan penggunaan 8 nilai biner berurutan dari 00000000 hingga 11111111. Dengan cara ini, 256 karakter berbeda dapat dikonversi.
Untuk menghindari kebingungan dalam pengkodean teks, tabel nilai khusus digunakan untuk setiap karakter. Mereka berisi alfabet Latin, tanda aritmatika, dan tanda tujuan khusus (misalnya €, ¥, dan lain-lain). Karakter dalam kisaran 128-255 mengkodekan alfabet nasional negara tersebut.
Untuk mengkodekan 1 karakter, diperlukan memori 8 bit. Untuk menyederhanakan penghitungan, 8 bit sama dengan 1 byte, sehingga total ruang disk untuk informasi teks diukur dalam byte.

Kebanyakan komputer pribadi dilengkapi dengan meja standar Pengkodean ASCII(Kode Standar Amerika untuk Pertukaran Informasi). Tabel lain juga digunakan, yang sistem pengkodean informasi teksnya berbeda. Misalnya, pengkodean karakter pertama yang diketahui disebut KOI-8 (kode pertukaran informasi 8-bit), dan berfungsi pada komputer dengan OS UNIX. Juga banyak ditemukan adalah tabel kode CP1251, yang dibuat untuk sistem operasi jendela.
Pengkodean suara biner
Alasan lain mengapa pengkodean biner adalah metode universal dalam memprogram informasi adalah kemudahannya saat bekerja dengan file audio. Musik apa pun terdiri dari gelombang suara dengan amplitudo dan frekuensi getaran yang berbeda. Volume suara dan nadanya bergantung pada parameter ini.
Untuk memprogram gelombang suara, komputer membaginya menjadi beberapa bagian, atau “sampel”. Jumlah sampel tersebut bisa besar, sehingga terdapat 65536 kombinasi angka nol dan satu yang berbeda. Oleh karena itu, komputer modern dilengkapi dengan kartu suara 16-bit, yang berarti 16 digit biner digunakan untuk mengkodekan satu sampel gelombang audio.
Untuk memutar file audio, komputer memproses rangkaian kode biner yang diprogram dan menggabungkannya menjadi satu gelombang berkelanjutan. 
Pengkodean grafis
Informasi grafis dapat disajikan dalam bentuk gambar, diagram, gambar atau slide PowerPoint. Gambar apa pun terdiri dari titik-titik kecil - piksel, yang dapat dicat dengan warna berbeda. Warna setiap piksel dikodekan dan disimpan, dan pada akhirnya kita mendapatkan gambar utuh.
Jika gambarnya hitam putih, kode untuk setiap piksel bisa satu atau nol. Jika digunakan 4 warna, maka kode masing-masing terdiri dari dua angka: 00, 01, 10 atau 11. Berdasarkan prinsip ini, kualitas pemrosesan gambar apa pun dibedakan. Menambah atau mengurangi kecerahan juga mempengaruhi jumlah warna yang digunakan. DI DALAM skenario kasus terbaik komputer membedakan sekitar 16.777.216 warna.

Kesimpulan
Ada berbagai metode pemrograman informasi, di antaranya pengkodean biner adalah yang paling efektif. Hanya dengan dua karakter - 1 dan 0 - komputer dapat dengan mudah membaca sebagian besar file. Pada saat yang sama, kecepatan pemrosesan jauh lebih tinggi dibandingkan jika, misalnya, sistem pemrograman desimal digunakan. Kesederhanaan metode ini membuatnya sangat diperlukan untuk teknik apa pun. Inilah sebabnya mengapa pengkodean biner bersifat universal di antara pengkodean lainnya.
Semua orang tahu bahwa komputer dapat melakukan perhitungan pada kelompok data yang besar dengan kecepatan yang sangat tinggi. Tetapi tidak semua orang tahu bahwa tindakan ini hanya bergantung pada dua kondisi: apakah ada arus atau tidak dan berapa tegangannya.
Bagaimana komputer bisa memproses informasi yang begitu beragam?
Rahasianya terletak pada sistem bilangan biner. Semua data masuk ke komputer, disajikan dalam bentuk satu dan nol, yang masing-masing sesuai dengan satu keadaan kabel listrik: satu - tegangan tinggi, nol - rendah, atau satu - adanya tegangan, nol - tidak adanya tegangan. Mengubah data menjadi nol dan satu disebut konversi biner, dan sebutan akhirnya disebut kode biner.
Dalam notasi desimal, berdasarkan sistem bilangan desimal yang digunakan dalam kehidupan sehari-hari, nilai numerik diwakili oleh sepuluh digit dari 0 hingga 9, dan setiap tempat dalam angka tersebut memiliki nilai sepuluh kali lebih tinggi daripada tempat di sebelah kanannya. Untuk mewakili angka yang lebih besar dari sembilan dalam sistem desimal, angka nol ditempatkan di tempatnya, dan angka satu ditempatkan di tempat berikutnya yang lebih bernilai di sebelah kiri. Demikian pula, dalam sistem biner, yang hanya menggunakan dua digit – 0 dan 1, setiap tempat bernilai dua kali lipat dibandingkan tempat di sebelah kanannya. Jadi, dalam kode biner hanya nol dan satu yang dapat direpresentasikan sebagai bilangan tunggal, dan bilangan apa pun yang lebih besar dari satu memerlukan dua tempat. Setelah nol dan satu, tiga bilangan biner berikutnya adalah 10 (dibaca satu-nol) dan 11 (dibaca satu-satu) dan 100 (dibaca satu-nol-nol). 100 biner setara dengan 4 desimal. Tabel atas di sebelah kanan menunjukkan padanan BCD lainnya.
Bilangan apa pun dapat dinyatakan dalam biner, hanya saja memerlukan lebih banyak ruang daripada desimal. Alfabet juga dapat ditulis dalam sistem biner jika setiap huruf diberi bilangan biner tertentu.
Dua angka untuk empat tempat
16 kombinasi dapat dibuat dengan menggunakan bola gelap dan terang, menggabungkannya dalam set empat. Jika bola gelap diambil sebagai nol dan bola terang sebagai satu, maka 16 set akan menjadi kode biner 16 unit, nilai numerik dari yaitu dari nol sampai lima (lihat tabel atas di halaman 27). Bahkan dengan dua jenis bola dalam sistem biner, jumlah kombinasi yang tak terbatas dapat dibuat hanya dengan menambah jumlah bola di setiap kelompok - atau jumlah tempat dalam angka-angka tersebut.
Bit dan byte
Satuan terkecil dalam pemrosesan komputer, bit adalah satuan data yang dapat mempunyai salah satu dari dua kondisi yang memungkinkan. Misalnya, masing-masing angka satu dan nol (di sebelah kanan) mewakili 1 bit. Sebuah bit dapat direpresentasikan dengan cara lain: ada tidaknya arus listrik, ada tidaknya lubang, arah magnetisasi ke kanan atau kiri. Delapan bit membentuk satu byte. 256 kemungkinan byte dapat mewakili 256 karakter dan simbol. Banyak komputer memproses satu byte data dalam satu waktu.
Konversi biner. Kode biner empat digit dapat mewakili angka desimal dari 0 hingga 15.
Tabel kode
Ketika kode biner digunakan untuk merepresentasikan huruf alfabet atau tanda baca, diperlukan tabel kode yang menunjukkan kode mana yang sesuai dengan karakter mana. Beberapa kode tersebut telah dikompilasi. Kebanyakan PC dikonfigurasikan dengan kode tujuh digit yang disebut ASCII, atau American Standard Code for Information Interchange. Tabel di sebelah kanan menunjukkan kode ASCII untuk alfabet bahasa Inggris. Kode lainnya untuk ribuan karakter dan huruf bahasa lain di dunia.

Bagian dari tabel kode ASCII

