24.07.2019
Kodierung von Textinformationen. Warum ist binäre Codierung universell? Programmiermethoden
Lassen Sie uns herausfinden, wie das alles gemacht wird Texte in digitalen Code umwandeln? Übrigens können Sie auf unserer Website jeden Text in Dezimal-, Hexadezimal-, Binärcode mit dem Online-Coderechner.
Textentschlüsselung.
Laut Computertheorie besteht jeder Text aus einzelnen Zeichen. Zu diesen Zeichen gehören: Buchstaben, Zahlen, Kleinbuchstaben, Sonderzeichen („“, №, () usw.) sowie Leerzeichen zwischen Wörtern.
Notwendige Wissensbasis. Der Satz von Symbolen, mit denen ich Texte schreibe, wird ALPHABET genannt.
Die Anzahl der Symbole in einem Alphabet repräsentiert seine Kraft.
Die Informationsmenge kann durch die Formel bestimmt werden: N = 2b
- N ist die gleiche Potenz (viele Symbole),
- b – Bit (Gewicht des genommenen Symbols).
Ein Alphabet mit 256 kann fast alle notwendigen Zeichen enthalten. Solche Alphabete werden als SUFFICIENT bezeichnet.
Nehmen wir ein Alphabet mit einer Kapazität von 256 und bedenken Sie, dass 256 = 28
- 8 Bits werden immer als 1 Byte bezeichnet:
- 1 Byte = 8 Bit.
Wenn Sie jedes Zeichen in Binärcode umwandeln, belegt dieser Computertextcode 1 Byte.
Wie können Textinformationen im Computerspeicher aussehen?
Jeder Text wird auf der Tastatur eingegeben, auf den Tastaturtasten sehen wir die uns bekannten Zeichen (Zahlen, Buchstaben usw.). Sie gelangen nur in Form eines Binärcodes in den Arbeitsspeicher des Computers. Der Binärcode für jedes Zeichen sieht aus wie eine achtstellige Zahl, zum Beispiel 00111111.
Da ein Byte der kleinste adressierbare Teil des Speichers ist und der Speicher für jedes Zeichen separat adressiert wird, liegt die Zweckmäßigkeit einer solchen Codierung auf der Hand. Allerdings sind 256 Zeichen eine sehr praktische Menge für symbolische Informationen.
Da stellte sich natürlich die Frage: Welche konkret? achtstelliger Code gehört zu jedem Charakter? Und wie wandelt man Text in digitalen Code um?
Dieser Prozess ist an Bedingungen geknüpft und wir haben das Recht, uns etwas anderes auszudenken Möglichkeiten, Zeichen zu kodieren. Jedes Zeichen des Alphabets hat eine eigene Nummer von 0 bis 255. Und jeder Nummer ist ein Code von 00000000 bis 11111111 zugeordnet.
Die Kodierungstabelle ist ein „Spickzettel“, in dem die Zeichen des Alphabets entsprechend der Seriennummer angegeben sind. Verschiedene Computertypen verwenden unterschiedliche Codierungstabellen.
ASCII (oder Asci) ist zu einem internationalen Standard für Personalcomputer geworden. Der Tisch besteht aus zwei Teilen.
Die erste Hälfte ist für die ASCII-Tabelle. (Es war die erste Hälfte, die zum Standard wurde.)
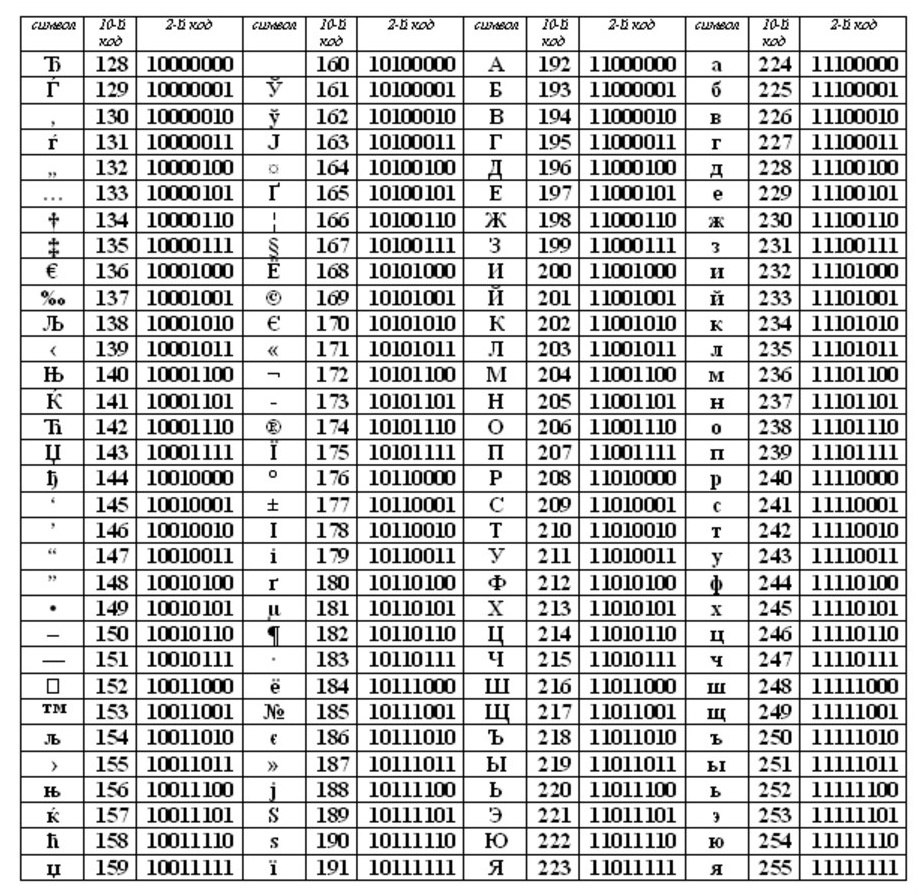
Die Einhaltung der lexikografischen Reihenfolge, d. h. in der Tabelle sind die Buchstaben (Klein- und Großbuchstaben) in streng alphabetischer Reihenfolge und die Zahlen in aufsteigender Reihenfolge angegeben, wird als Prinzip der sequentiellen Kodierung des Alphabets bezeichnet.
Für das russische Alphabet folgen sie ebenfalls Sequentielles Codierungsprinzip.
Heutzutage, in unserer Zeit, verwenden sie das Ganze fünf Kodierungssysteme Russisches Alphabet (KOI8-R, Windows. MS-DOS, Macintosh und ISO). Aufgrund der Vielzahl von Kodierungssystemen und des Fehlens eines einheitlichen Standards kommt es bei der Übertragung russischer Texte in ihre Computerform sehr häufig zu Missverständnissen.
Einer der Ersten Standards für die Kodierung des russischen Alphabets und auf PCs betrachten sie KOI8 („Informationsaustauschcode, 8-Bit“). Diese Kodierung wurde Mitte der siebziger Jahre auf einer Reihe von ES-Computern verwendet und ab Mitte der achtziger Jahre begann sie in den ersten ins Russische übersetzten UNIX-Betriebssystemen verwendet zu werden.
Seit den frühen neunziger Jahren, der sogenannten Zeit, als das MS-DOS-Betriebssystem dominierte, erschien das CP866-Codierungssystem („CP“ steht für „Code Page“).
Die riesigen Computerfirmen APPLE beginnen mit ihrem innovativen System, unter dem sie arbeiteten (Mac OS), ein eigenes System zur Kodierung des MAC-Alphabets zu verwenden.
Die International Standards Organization (ISO) legt einen weiteren Standard für die russische Sprache fest Alphabet-Kodierungssystem, die ISO 8859-5 genannt wird.
Und das heutzutage gebräuchlichste System zur Kodierung des Alphabets wurde in Microsoft Windows erfunden und heißt CP1251.
Seit der zweiten Hälfte der neunziger Jahre wurde das Problem eines Standards zur Übersetzung von Texten in digitalen Code für die russische Sprache nicht nur durch die Einführung eines Systems namens Unicode in den Standard gelöst. Es wird durch eine 16-Bit-Kodierung dargestellt, was bedeutet, dass jedem Zeichen genau zwei Bytes zugewiesen werden Arbeitsspeicher. Natürlich verdoppeln sich bei dieser Kodierung die Speicherkosten. Allerdings ermöglicht ein solches Codesystem die Umwandlung von bis zu 65.536 Zeichen in elektronischen Code.
Die Besonderheit des Standard-Unicode-Systems besteht in der Einbeziehung absolut jedes Alphabets, sei es existierend, ausgestorben oder erfunden. Letztlich absolut jedes Alphabet, darüber hinaus umfasst das Unicode-System viele mathematische, chemische, musikalische und allgemeine Symbole.
Lassen Sie uns anhand einer ASCII-Tabelle sehen, wie ein Wort im Speicher Ihres Computers aussehen könnte.
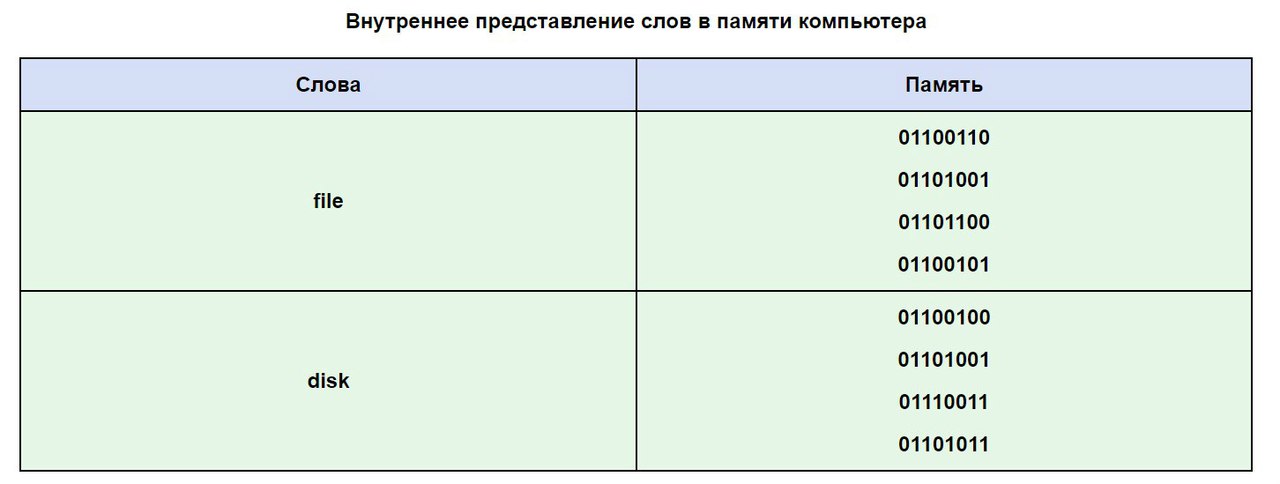
Es kommt häufig vor, dass Ihr Text, der in Buchstaben des russischen Alphabets geschrieben ist, nicht lesbar ist. Dies liegt an unterschiedlichen Alphabet-Kodierungssystemen auf Computern. Dies ist ein sehr häufiges Problem, das häufig auftritt.
Die minimalen Informationseinheiten sind Bits und Bytes.
Eins Bit ermöglicht Ihnen die Codierung 2 Werte (0 oder 1).
Benutzen zwei Bit, kann kodiert werden 4 Werte: 00, 01, 10, 11.
Drei Bits werden kodiert 8 verschiedene Werte: 000, 001, 010, 011, 100, 101, 110, 111.
Aus den obigen Beispielen ist ersichtlich, dass sich durch das Hinzufügen eines Bits die Anzahl der kodierbaren Werte verdoppelt:
1 Bit kodiert –> 2 verschiedene Werte (2 1 = 2),
2 Bits kodieren –> 4 verschiedene Werte (2 2 = 4)
3 Bits kodieren –> 8 verschiedene Werte (2 3 = 8)
4 Bits kodieren –> 16 verschiedene Werte (2 4 = 16)
5 Bits kodieren –> 32 verschiedene Werte (2 5 = 32)
6 Bit kodieren –> 64 verschiedene Werte (2 6 = 64)
7 Bits kodieren –> 128 verschiedene Werte (2 7 = 128)
8 Bit kodieren –> 256 verschiedene Werte (2 8 = 256)
9 Bits kodieren –> 512 verschiedene Werte (2 9 = 512)
10 Bits kodieren –> 1024 verschiedene Werte (2 10 = 1024).
Wir erinnern uns, dass ein Byte nicht 9 oder 10 Bits hat, sondern nur 8. Daher können mit einem Byte 256 verschiedene Zeichen codiert werden. Glaubst du, das ist viel oder wenig? Schauen wir uns ein Codierungsbeispiel an Textinformationen.
Die russische Sprache hat 33 Buchstaben und daher werden 33 Bytes benötigt, um sie zu kodieren. Der Computer unterscheidet zwischen Großbuchstaben (Großbuchstaben) und Kleinbuchstaben (Kleinbuchstaben) nur, wenn sie in unterschiedlichen Codes kodiert sind. Das bedeutet, dass zur Kodierung von Groß- und Kleinbuchstaben des russischen Alphabets 66 Bytes benötigt werden.
Für große und kleine Buchstaben des englischen Alphabets werden weitere 52 Byte benötigt. Das Ergebnis ist 66 + 52 = 118 Bytes. Hier müssen Sie auch Zahlen (von 0 bis 9), das Leerzeichen, alle Satzzeichen: Punkt, Komma, Bindestrich, Ausrufe- und Fragezeichen, Klammern: rund, geschweift und eckig sowie Symbole für mathematische Operationen hinzufügen: + , –, =, / (das ist Division), * (das ist Multiplikation). Fügen wir auch Sonderzeichen hinzu: %, $, &, @, #, Nr. usw. Insgesamt sind das etwa 256 verschiedene Zeichen.
Und dann gibt es wenig zu tun. Es muss sichergestellt werden, dass sich alle Menschen auf der Erde darauf einigen, welche Codes (von 0 bis 255, also insgesamt 256) den Symbolen zugeordnet werden sollen. Nehmen wir an, alle Menschen sind sich einig, dass Code 33 ein Ausrufezeichen (!) und Code 63 ein Fragezeichen (?) bedeutet. Und das Gleiche gilt für alle verwendeten Symbole. Das würde dann bedeuten, dass Texte, die eine Person auf ihrem Computer eingibt, jederzeit von einer anderen Person auf einem anderen Computer gelesen und gedruckt werden können.
ASCII-Tabelle
Eine solche allgemeine Vereinbarung über die gleiche Verwendung einer Sache nennt man Standard. In unserem Fall sollte der Standard eine Tabelle sein, die die Entsprechung von Codes (von 0 bis 255) und Symbolen aufzeichnet. Eine solche Tabelle heißt Codierungstabelle.
Aber so einfach ist es nicht. Denn Symbole, die beispielsweise für Griechenland gut sind, sind für die Türkei nicht geeignet, weil dort andere Buchstaben verwendet werden. Ebenso ist das, was gut für die Vereinigten Staaten ist, nicht gut für Russland, und was gut für Russland ist, ist nicht gut für Deutschland.
Aus diesem Grund haben wir uns entschieden, die Codetabelle in zwei Hälften zu teilen.
Die ersten 128 Codes (von 0 bis 127) sollten für alle Länder und für alle Computer Standard und obligatorisch sein. Dies sind: International Standard.
Und mit der zweiten Hälfte der Codetabelle (von 128 bis 255) kann jedes Land machen, was es will und in dieser Hälfte seinen eigenen Standard erstellen – National.
Die erste (internationale) Hälfte der Codetabelle wird aufgerufen TischASCII, das in den USA entwickelt und weltweit akzeptiert wurde. Der ASCII-Standard ist nicht für die zweite Hälfte der Codetabelle verantwortlich. Verschiedene Länder erstellen hier ihre eigenen nationalen Codetabellen. Es kann auch sein, dass es innerhalb eines Landes unterschiedliche Standards für verschiedene Computersysteme gibt, jedoch nur innerhalb der zweiten Hälfte der Codetabelle.
Codes aus der internationalen ASCII-Tabelle
0-31 – Sonderzeichen, die nicht auf dem Bildschirm oder Drucker gedruckt werden, sondern zum Ausführen besonderer Aktionen verwendet werden (z. B. für „Wagenrücklauf“ – Verschieben von Text in eine neue Zeile oder für „Tab“ – Platzieren des Cursors an Sonderpositionen in einem Zeilentext usw.).
32 – Leerzeichen (das Trennzeichen zwischen Wörtern ist ebenfalls ein zu kodierendes Zeichen, obwohl es als „Leerzeichen“ zwischen Wörtern und Zeichen angezeigt wird),
33-47 – Sonderzeichen (Klammern usw.) und Satzzeichen (Punkt, Komma usw.),
48-57 – Zahlen von 0 bis 9,
58-64 – mathematische Symbole (Plus (+), Minus (-), Multiplikation (*), Division (/) usw.) und Satzzeichen (Doppelpunkt, Semikolon usw.),
65-90 – englische Großbuchstaben (Kleinbuchstaben),
91-96 – Sonderzeichen (eckige Klammern usw.),
97-122 – kleine (kleine) englische Buchstaben,
123-127 – Sonderzeichen (geschweifte Klammern usw.).
Außerhalb der ASCII-Tabelle gibt es ab den Zahlen 128 bis 159 russische Großbuchstaben und von 160 bis 170 und von 224 bis 239 russische Kleinbuchstaben (Kleinbuchstaben).
Kodierung des Wortes WELT
Anhand der gezeigten Kodierung können wir uns vorstellen, wie ein Computer beispielsweise das Wort WELT (in Großbuchstaben) kodiert und dann wiedergibt. Dieses Wort wird durch drei Codes dargestellt: Der Buchstabe M entspricht dem Code 140 (gemäß dem nationalen russischen Kodierungssystem), I ist der Code 136 und P ist der Code 144.
Aber wie bereits erwähnt, nimmt der Computer Informationen nur in binärer Form wahr, d.h. als Folge von Nullen und Einsen. Jedes Byte, das jedem Buchstaben des Wortes WORLD entspricht, enthält eine Folge von acht Nullen und Einsen. Mithilfe der Regeln zum Konvertieren von Dezimalinformationen in Binärinformationen können Sie die Dezimalwerte von Buchstabencodes durch ihre binären Gegenstücke ersetzen.
Die Dezimalziffer 140 entspricht der Binärzahl 10001100. Dies kann durch die folgenden Berechnungen überprüft werden: 2 7 + 2 3 +2 2 = 140. Die Potenz, mit der jede „2“ erhöht wird, ist die Positionsnummer der Binärzahl 10001100, die „1“ enthält, und die Positionen werden von rechts nach links nummeriert, beginnend mit der Nullpositionsnummer: 0, 1, 2 usw.
Mehr über die Umrechnung von Zahlen von einem Zahlensystem in ein anderes erfahren Sie beispielsweise in Informatiklehrbüchern oder im Internet.
Auf ähnliche Weise können Sie überprüfen, ob die Zahl 136 der Binärzahl 10001000 entspricht (Prüfung: 2 7 + 2 3 = 136). Und die Zahl 144 entspricht der Binärzahl 10010000 (Prüfung: 2 7 + 2 4 = 144).
Somit wird das Wort WELT im Computer als folgende Folge von Nullen und Einsen (Bits) gespeichert: 10001100 10001000 10010000.
Natürlich werden alle oben gezeigten Datenkonvertierungen mithilfe von Computerprogrammen durchgeführt und sind für Benutzer nicht sichtbar. Sie beobachten lediglich die Ergebnisse der Arbeit dieser Programme, sowohl bei der Eingabe von Informationen über die Tastatur als auch bei der Anzeige auf einem Bildschirm oder einem Drucker.
Es ist zu beachten, dass Computerbenutzer auf der Ebene der Computerkenntnisse keine Kenntnisse des binären Zahlensystems benötigen. Es reicht aus, Dezimalzeichencodes zu verstehen. Nur Systemprogrammierer verwenden in der Praxis binäre, hexadezimale, oktale und andere Zahlensysteme. Dies ist für sie besonders wichtig, wenn Computer Softwarefehlermeldungen erzeugen, die auf fehlerhafte Werte hinweisen, ohne sie in Dezimalzahlen umzuwandeln.
Übungen zur Computerkompetenz, sodass Sie die im Artikel beschriebenen Kodierungssysteme unabhängig sehen und fühlen können
P.S. Der Artikel ist zu Ende, aber Sie können ihn noch lesen:
P.P.S. Zu Abonnieren Sie, um neue Artikel zu erhalten, die noch nicht auf dem Blog sind:
1) Geben Sie in diesem Formular Ihre E-Mail-Adresse ein.
Binäre Kodierung von Textinformationen
Seit den späten 60er Jahren werden Computer zunehmend zur Verarbeitung von Textinformationen eingesetzt, und derzeit sind die meisten Personalcomputer auf der Welt (und die meiste Zeit) mit der Verarbeitung von Textinformationen beschäftigt.
Traditionell wird zum Codieren eines Zeichens eine Informationsmenge von 1 Byte verwendet, d. h. I = 1 Byte = 8 Bit.
Um ein Zeichen zu kodieren, ist 1 Byte an Informationen erforderlich.
Wenn wir Symbole als mögliche Ereignisse betrachten, können wir mit Formel (2.1) berechnen, wie viele verschiedene Symbole codiert werden können:
N = 2 I = 2 · 8 = 256.
Diese Anzahl an Zeichen reicht völlig aus, um Textinformationen darzustellen, einschließlich Groß- und Kleinbuchstaben des russischen und lateinischen Alphabets, Zahlen, Zeichen, grafische Symbole usw.
Bei der Codierung wird jedem Zeichen ein eindeutiger Dezimalcode von 0 bis 255 oder ein entsprechender Binärcode von 00000000 bis 11111111 zugewiesen. So unterscheidet eine Person Zeichen anhand ihres Designs und ein Computer anhand ihrer Codes.
Wenn Textinformationen in einen Computer eingegeben werden, werden sie binär codiert; das Bild des Symbols wird in seinen Binärcode umgewandelt. Der Benutzer drückt eine Taste mit einem Symbol auf der Tastatur und eine bestimmte Folge von acht elektrischen Impulsen (Binärcode des Symbols) wird an den Computer gesendet. Der Zeichencode wird im RAM des Computers gespeichert und belegt dort ein Byte.
Bei der Anzeige eines Symbols auf einem Computerbildschirm wird der umgekehrte Vorgang durchgeführt – die Dekodierung, also die Umwandlung des Symbolcodes in sein Bild.
Es ist wichtig, dass die Zuordnung eines bestimmten Codes zu einem Symbol eine Vereinbarung ist, die in der Codetabelle festgehalten wird. Die ersten 33 Codes (von 0 bis 32) entsprechen nicht Zeichen, sondern Operationen (Zeilenvorschub, Eingabe eines Leerzeichens usw.).
Die Codes 33 bis 127 sind international und entsprechen Zeichen des lateinischen Alphabets, Zahlen, Rechenzeichen und Satzzeichen.
Codes von 128 bis 255 sind national, das heißt, in nationalen Codierungen entsprechen unterschiedliche Zeichen demselben Code. Leider gibt es derzeit fünf verschiedene Kodierungstabellen für russische Buchstaben (KOI8, SR1251, SR866, Mac, ISO – Tabelle 1.3), sodass Texte, die in einer Kodierung erstellt wurden, in einer anderen nicht korrekt angezeigt werden.
Derzeit hat sich der neue internationale Standard Unicode durchgesetzt, der jedem Zeichen nicht ein, sondern zwei Bytes zuweist, sodass damit nicht 256 Zeichen, sondern N = 216 = = 65536 verschiedene Zeichen kodiert werden können. Diese Kodierung wird von den neuesten Versionen der Microsoft Windows- und Office-Plattform (seit 1997) unterstützt.
Jede Kodierung wird durch eine eigene Codetabelle spezifiziert. Wie aus der Tabelle ersichtlich ist. 1.3 werden dem gleichen Binärcode in verschiedenen Kodierungen unterschiedliche Symbole zugewiesen.
Beispielsweise bildet die Folge der numerischen Codes 221, 194, 204 in der CP1251-Kodierung das Wort „Computer“, während es sich in anderen Kodierungen um einen bedeutungslosen Satz von Zeichen handelt.
Glücklicherweise muss sich der Benutzer in den meisten Fällen nicht um die Transkodierung von Textdokumenten kümmern, da dies durch spezielle, in Anwendungen integrierte Konverterprogramme erfolgt.
Bestimmen des numerischen Codes eines Zeichens
1. Starten Sie den Texteditor MS Word 2002. Geben Sie den Befehl [Symbol einfügen...] ein. Auf dem Bildschirm erscheint ein Dialogfeld Symbol. Der zentrale Teil des Dialogfelds wird von einer Zeichentabelle für eine bestimmte Schriftart (z. B. Times New Roman) eingenommen.
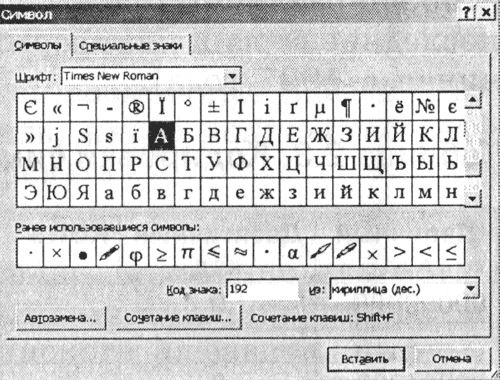 |
Die Zeichen werden der Reihe nach von links nach rechts und Zeile für Zeile angeordnet, beginnend mit dem Zeichen Raum in der oberen linken Ecke und endet mit dem Buchstaben „I“ in der unteren rechten Ecke der Tabelle.
Wählen Sie ein Symbol aus der Dropdown-Liste aus aus: Codierungstyp. In einem Textfeld Zeichencode: sein numerischer Code wird angezeigt.
Eingabe von Zeichen per Zahlencode
1. Starten Sie das Standardprogramm Notizbuch. Geben Sie über den zusätzlichen Ziffernblock bei gedrückter Alt-Taste die Zahl 0224 ein und lassen Sie die Alt-Taste los. Das Symbol „a“ erscheint im Dokument. Wiederholen Sie den Vorgang für die numerischen Codes von 0225 bis 0233. Im Dokument erscheint eine Folge von 12 „abvgdezhy“-Zeichen in Windows-Kodierung (CP1251).
2. Geben Sie über den zusätzlichen Ziffernblock bei gedrückter (Alt)-Taste die Zahl 224 ein; das Symbol „p“ erscheint im Dokument. Wiederholen Sie den Vorgang für numerische Codes von 225 bis 233. Im Dokument erscheint eine Folge von 12 Zeichen „rstufhtchshshch“ in MS-DOS-Kodierung (CP866).
 |
Praktische Aufgaben
1.29. Schreiben Sie mithilfe einer Zeichentabelle (MS Word) eine Folge dezimaler numerischer Codes in Windows-Kodierung (CP1251) für das Wort „Computer“ auf.
1.30. Bestimmen Sie mithilfe von Notepad, welches Wort in der Windows-Kodierung (CP1251) durch die Folge numerischer Codes angegeben wird: 225, 224, 233,242.
1.31. Welche Buchstabenfolgen in KOI8- und ISO-Kodierungen entsprechen dem in CP1251-Kodierung geschriebenen Wort „Computer“?
Der Computer verarbeitet große Menge Information. Audiodateien, Bilder, Texte – all das muss abgespielt oder auf dem Bildschirm angezeigt werden. Warum ist die binäre Codierung eine universelle Methode zur Programmierung von Informationen aller technischen Geräte?
Was ist der Unterschied zwischen Kodierung und Verschlüsselung?
Oft werden die Begriffe „Kodierung“ und „Verschlüsselung“ gleichgesetzt, obwohl sie tatsächlich unterschiedliche Bedeutungen haben. Verschlüsselung ist also der Prozess der Umwandlung von Informationen mit dem Ziel, sie zu verbergen. Die Person, die den Text geändert hat, oder speziell geschulte Personen können ihn oft entziffern. Codierung dient dazu, Informationen zu verarbeiten und die Arbeit damit zu vereinfachen. Normalerweise wird eine gemeinsame Codierungstabelle verwendet, die jedem bekannt ist. Es ist in den Computer integriert.
Binäres Codierungsprinzip
Binäre Codierung basiert auf der Verwendung von nur zwei Zeichen – 0 und 1 – zur Verarbeitung von Informationen, die von verschiedenen Geräten verwendet werden. Diese Zeichen wurden auf Englisch Binärziffern genannt – Binärziffer oder Bit. Jedes Zeichen belegt 1 Bit Computerspeicher. Warum ist die binäre Codierung eine universelle Methode der Informationsverarbeitung? Tatsache ist, dass es für einen Computer einfacher ist, weniger Zeichen zu verarbeiten. Davon hängt direkt die Produktivität des PCs ab: Je weniger Funktionsaufgaben das Gerät ausführen muss, desto höher sind Geschwindigkeit und Qualität der Arbeit. 
Das Prinzip der binären Codierung findet sich nicht nur in der Programmierung. Durch den Wechsel von dumpfen und sonoren Trommelschlägen übermittelten die Bewohner Polynesiens untereinander Informationen. Ein ähnliches Prinzip gilt, wenn lange und kurze Töne zur Übermittlung einer Nachricht verwendet werden. Das „Telegraphenalphabet“ wird noch heute verwendet.
Wo wird binäre Codierung verwendet?
Binär wird überall in Computern verwendet. Jede Datei, sei es Musik oder Text, muss so programmiert werden, dass sie später problemlos verarbeitet und gelesen werden kann. Das binäre Codierungssystem eignet sich für die Arbeit mit Symbolen und Zahlen, Audiodateien und Grafiken.
Binäre Kodierung von Zahlen
Heutzutage werden Zahlen in Computern in einer codierten Form dargestellt, die für den Durchschnittsmenschen unverständlich ist. Die Verwendung arabischer Ziffern in der Art und Weise, wie wir es uns vorstellen, ist für die Technologie irrational. Der Grund dafür ist die Notwendigkeit, jeder Zahl ein eigenes eindeutiges Symbol zuzuweisen, was manchmal unmöglich ist.

Es gibt zwei Zahlensysteme: positionelles und nicht-positionelles. Das nicht-positionelle System basiert auf der Verwendung lateinische Buchstaben und ist uns in der Form bekannt. Diese Aufnahmemethode ist recht schwer zu verstehen und wurde daher aufgegeben.
Das Positionszahlensystem wird auch heute noch verwendet. Dies umfasst die binäre, dezimale, oktale und sogar hexadezimale Kodierung von Informationen.
Wir verwenden im Alltag das Dezimalkodierungssystem. Diese sind uns vertraut und für jeden Menschen verständlich. Die binäre Kodierung von Zahlen zeichnet sich dadurch aus, dass nur Null und Eins verwendet werden.
Ganzzahlen werden in das binäre Codierungssystem umgewandelt, indem man sie durch 2 dividiert. Die resultierenden Quotienten werden ebenfalls schrittweise durch 2 dividiert, bis das Ergebnis 0 oder 1 ist. Beispielsweise kann die Zahl 123 10 im Binärsystem als 1111011 2 dargestellt werden. Und die Zahl 20 10 wird wie 10100 2 aussehen.
Die Indizes 10 und 2 bezeichnen das dezimale bzw. binäre Zahlencodierungssystem. Das binäre Kodierungssymbol wird verwendet, um die Arbeit mit Werten zu erleichtern, die in verschiedenen Zahlensystemen dargestellt werden.
Dezimale Programmiermethoden basieren auf Gleitkommazahlen. Um einen Wert korrekt vom dezimalen in das binäre Kodierungssystem umzuwandeln, verwenden Sie die Formel N = M x qp. M ist die Mantisse (ein Ausdruck einer Zahl ohne Ordnung), p ist die Ordnung des Wertes N und q ist die Basis des Kodierungssystems (in unserem Fall 2).
Nicht alle Zahlen sind positiv. Um zwischen positiven und negativen Zahlen zu unterscheiden, lässt der Computer 1 Bit Platz für die Kodierung des Vorzeichens. Dabei steht Null für das Pluszeichen und Eins für das Minuszeichen.
Die Verwendung dieses Zahlensystems erleichtert einem Computer die Arbeit mit Zahlen. Aus diesem Grund ist die binäre Codierung in Rechenprozessen universell.

Binäre Kodierung von Textinformationen
Jedes Zeichen des Alphabets ist mit einem eigenen Satz von Nullen und Einsen kodiert. Der Text besteht aus verschiedenen Zeichen: Buchstaben (Groß- und Kleinbuchstaben), Rechenzeichen und anderen verschiedenen Bedeutungen. Die Kodierung von Textinformationen erfordert die Verwendung von 8 aufeinanderfolgenden Binärwerten von 00000000 bis 11111111. Auf diese Weise können 256 verschiedene Zeichen konvertiert werden.
Um Verwirrung bei der Textkodierung zu vermeiden, werden für jedes Zeichen spezielle Wertetabellen verwendet. Sie enthalten das lateinische Alphabet, Rechenzeichen und Sonderzeichen (zum Beispiel €, ¥ und andere). Die Zeichen im Bereich 128–255 kodieren das nationale Alphabet des Landes.
Um 1 Zeichen zu kodieren, sind 8 Bit Speicher erforderlich. Zur Vereinfachung der Berechnungen entsprechen 8 Bit 1 Byte, sodass der gesamte Speicherplatz für Textinformationen in Bytes gemessen wird.

Die meisten Personalcomputer sind mit einer standardmäßigen ASCII-Codierungstabelle (American Standard Code for Information Interchange) ausgestattet. Es werden auch andere Tabellen verwendet, bei denen das Textinformationskodierungssystem unterschiedlich ist. Die erste bekannte Zeichenkodierung heißt beispielsweise KOI-8 (8-Bit-Informationsaustauschcode) und funktioniert auf Computern mit UNIX-Betriebssystem. Weit verbreitet ist auch die CP1251-Codetabelle, die für erstellt wurde Betriebssystem Windows.
Binäre Kodierung von Lauten
Ein weiterer Grund, warum die Binärcodierung eine universelle Methode zum Programmieren von Informationen ist, ist die einfache Arbeit mit Audiodateien. Jede Musik besteht aus Schallwellen unterschiedlicher Amplitude und Schwingungsfrequenz. Die Lautstärke des Tons und seine Tonhöhe hängen von diesen Parametern ab.
Um eine Schallwelle zu programmieren, teilt der Computer sie in mehrere Teile oder „Samples“ auf. Die Anzahl solcher Stichproben kann groß sein, sodass es 65536 verschiedene Kombinationen von Nullen und Einsen gibt. Dementsprechend sind moderne Computer mit 16-Bit-Soundkarten ausgestattet, was bedeutet, dass 16 Binärziffern verwendet werden, um ein Sample einer Audiowelle zu kodieren.
Um eine Audiodatei abzuspielen, verarbeitet ein Computer programmierte Sequenzen von Binärcode und kombiniert sie zu einer kontinuierlichen Welle. 
Grafikcodierung
Grafische Informationen können in Form von Zeichnungen, Diagrammen, Bildern oder PowerPoint-Folien dargestellt werden. Jedes Bild besteht aus kleinen Punkten – Pixeln, die in verschiedenen Farben bemalt werden können. Die Farbe jedes Pixels wird kodiert und gespeichert, und am Ende erhalten wir ein vollständiges Bild.
Wenn das Bild schwarzweiß ist, kann der Code für jedes Pixel entweder eins oder null sein. Wenn 4 Farben verwendet werden, besteht der Code für jede von ihnen aus zwei Zahlen: 00, 01, 10 oder 11. Basierend auf diesem Prinzip wird die Verarbeitungsqualität jedes Bildes unterschieden. Das Erhöhen oder Verringern der Helligkeit wirkt sich auch auf die Anzahl der verwendeten Farben aus. Im besten Fall kann der Computer etwa 16.777.216 Farbtöne unterscheiden.

Abschluss
Es gibt verschiedene Methoden zum Programmieren von Informationen, von denen die binäre Codierung die effektivste ist. Mit nur zwei Zeichen – 1 und 0 – kann der Computer die meisten Dateien problemlos lesen. Gleichzeitig ist die Verarbeitungsgeschwindigkeit deutlich höher, als wenn beispielsweise ein dezimales Programmiersystem verwendet würde. Die Einfachheit dieser Methode macht sie für jede Technik unverzichtbar. Aus diesem Grund ist die binäre Codierung unter ihren Gegenstücken universell.
Jeder weiß, dass Computer mit enormer Geschwindigkeit Berechnungen an großen Datenmengen durchführen können. Aber nicht jeder weiß, dass diese Aktionen nur von zwei Bedingungen abhängen: ob Strom vorhanden ist oder nicht und welche Spannung.
Wie schafft es ein Computer, eine solche Vielfalt an Informationen zu verarbeiten?
Das Geheimnis liegt im binären Zahlensystem. Alle Daten gelangen in den Computer und werden in Form von Einsen und Nullen dargestellt, die jeweils einem Zustand des Stromkabels entsprechen: Einsen – hohe Spannung, Nullen – niedrig oder Einsen – das Vorhandensein von Spannung, Nullen – deren Fehlen. Die Konvertierung von Daten in Nullen und Einsen wird als binäre Konvertierung bezeichnet, und ihre endgültige Bezeichnung heißt Binärcode.
In der Dezimalschreibweise, die auf dem im Alltag verwendeten Dezimalzahlensystem basiert, wird ein numerischer Wert durch zehn Ziffern von 0 bis 9 dargestellt, und jede Stelle in der Zahl hat einen zehnmal höheren Wert als die Stelle rechts davon. Um eine Zahl größer als neun im Dezimalsystem darzustellen, wird an ihrer Stelle eine Null und an der nächsten, wertvolleren Stelle links eine Eins platziert. Ebenso ist im Binärsystem, das nur zwei Ziffern verwendet – 0 und 1 – jede Stelle doppelt so wertvoll wie die Stelle rechts davon. Daher können im Binärcode nur Null und Eins als einzelne Zahlen dargestellt werden, und jede Zahl größer als Eins erfordert zwei Stellen. Nach null und eins die nächsten drei Binärzahlen Dies sind 10 (Eins-Null lesen) und 11 (Eins-Eins lesen) und 100 (Eins-Null-Null lesen). 100 binär entspricht 4 dezimal. Die obere Tabelle rechts zeigt andere BCD-Äquivalente.
Jede Zahl kann binär ausgedrückt werden, sie nimmt nur mehr Platz ein als dezimal. Das Alphabet kann auch im Binärsystem geschrieben werden, wenn jedem Buchstaben eine bestimmte Binärzahl zugeordnet wird.
Zwei Figuren für vier Plätze
Es können 16 Kombinationen aus dunklen und hellen Kugeln erstellt und in Vierergruppen kombiniert werden. Wenn dunkle Kugeln als Nullen und helle Kugeln als Einsen angenommen werden, ergeben sich aus 16 Sätzen ein 16-Einheiten-Binärcode, der numerische Wert von die zwischen null und fünf liegt (siehe obere Tabelle auf Seite 27). Selbst mit zwei Arten von Kugeln im Binärsystem können unendlich viele Kombinationen gebildet werden, indem einfach die Anzahl der Kugeln in jeder Gruppe – oder die Anzahl der Stellen in den Zahlen – erhöht wird.
Bits und Bytes
Ein Bit, die kleinste Einheit in der Computerverarbeitung, ist eine Dateneinheit, die einen von zwei möglichen Zuständen haben kann. Beispielsweise repräsentiert jede der Einsen und Nullen (rechts) 1 Bit. Ein Bit kann auf andere Weise dargestellt werden: das Vorhandensein oder Fehlen von elektrischem Strom, ein Loch oder dessen Fehlen, die Richtung der Magnetisierung nach rechts oder links. Acht Bits bilden ein Byte. 256 mögliche Bytes können 256 Zeichen und Symbole darstellen. Viele Computer verarbeiten jeweils ein Datenbyte.
Binäre Konvertierung. Der vierstellige Binärcode kann Dezimalzahlen von 0 bis 15 darstellen.
Codetabellen
Wenn Binärcode zur Darstellung von Buchstaben des Alphabets oder Satzzeichen verwendet wird, sind Codetabellen erforderlich, die angeben, welcher Code welchem Zeichen entspricht. Es wurden mehrere solcher Codes zusammengestellt. Die meisten PCs sind mit einem siebenstelligen Code namens ASCII oder American Standard Code for Information Interchange konfiguriert. Die Tabelle rechts zeigt ASCII-Codes für das englische Alphabet. Andere Codes gelten für Tausende von Zeichen und Alphabeten anderer Sprachen der Welt.

Teil einer ASCII-Codetabelle

